1. Introduction
Nonvolatile memory express (NVMe) is a storage interface designed for fast nonvolatile storage media such as solid-state drives (SSDs) [
1]. Unlike an advanced host controller interface (AHCI), which has only one queue, NVMe provides numerous submission queues that can be scaled for parallel I/O processing within SSDs. To take full advantage of the numerous queues in this NVMe SSD architecture, the previous single-queue block layer was replaced with a multiqueue block layer in the Linux operating system [
2]. Consequently, the multiple queues in the NVMe interface and Linux support enable many I/O requests to be handled simultaneously.
This scalable architecture offers a high I/O bandwidth and a high number of IOPS, but no quality of service (QoS) support is provided for each I/O request. If there are numerous pending I/O requests in the submission queues, I/O requests that should be urgently processed cannot be serviced immediately. For example, application startup or foreground process execution that requires low latency can be delayed when an SSD is processing numerous I/O requests. Since the host operating systems cannot control pending I/O requests in the NVMe submission queues, the existing I/O scheduling algorithms at the block I/O layer are not very effective in this case [
3,
4].
To solve this problem, we present a scheme in which urgent I/O requests are not delayed even when there are many pending I/O requests in the submission queues. To this end, we exploit the host memory buffer (HMB), which is one of the extended features provided by NVMe. It allows an SSD to utilize a portion of the DRAM of the host when it needs more memory. If an SSD supports the HMB feature, the SSD controller can access the host memory via the high-speed NVMe interface backed by peripheral component interconnect express (PCIe), and it can use a portion of the host’s memory as a storage cache for an address mapping table or regular data [
5,
6,
7,
8].
As the HMB is a part of the host DRAM, it can be accessed from the host operating system as well as the SSD controller [
9]. It is regarded as a shared region of the host and SSD controller, so urgent I/O requests can be handled immediately by communicating via the HMB. When there are many pending I/O requests in the submission queues, causing a bottleneck, the HMB can be used as a fast I/O path for processing urgent I/O requests. Usually, normal I/O requests issued by file systems are sent to the SSD controller via software and hardware queues in the block I/O layer and submission queues in the NVMe interface. If urgent I/O requests are issued, they are sent via the HMB directly, bypassing those queues. In other words, the host sends an urgent I/O request by writing it in the HMB and the SSD controller responds by writing a response to the HMB. In our scheme, it is important not to violate the protocol of the NVMe interface while providing QoS for urgent I/O requests. This issue is addressed by adding another submission queue or using an administration queue, which is a queue for processing NVMe administration commands. Various experiments performed using our emulator demonstrated that the proposed scheme reduces both the average and tail latencies of urgent I/O requests and thus reduces the application launch time significantly.
The remainder of this paper is organized as follows.
Section 2 provides an overview of the related previous works.
Section 3 describes the bottleneck for urgent I/O requests that can be caused by many I/O requests waiting in the submission queues when I/O traffic is bursty.
Section 4 explains our HMB I/O scheme, which is a fast track for urgent I/O requests using the HMB.
Section 5 presents an evaluation of our scheme with various workloads. Finally,
Section 6 concludes the paper.
3. I/O latency with High Workload
As mentioned above, I/O requests originating from file systems are passed to SSD devices via software and hardware queues in the Linux block I/O layer and submission queues in the NVMe interface. If an I/O request leaves the hardware queue, the host can no longer control it. When I/O requests are added at any moment, they must wait in the submission queues, which adversely affects the processing of urgent I/O requests. In this section, we provide an experimental analysis of the number of I/O requests that are queued in the submission queue when the I/O workload is high and show how much this queueing can delay the processing of urgent I/O requests.
In fact, it is difficult to know exactly how many I/O requests are waiting in the submission queue at any given time. Both the head and tail positions are required to determine the number of I/O requests in the submission queue, but the host manages only the tail, the next insertion point, and not the head, the next deletion point. The head information can be obtained by SQ Head Pointer, which is part of the completion queue entry, but it is updated only when the SSD device finishes I/O processing and inserts the entry into the completion queue. Due to this limitation of NVMe, the average number of entries in each submission queue is updated in our method whenever the host dequeues the completion queue entries.
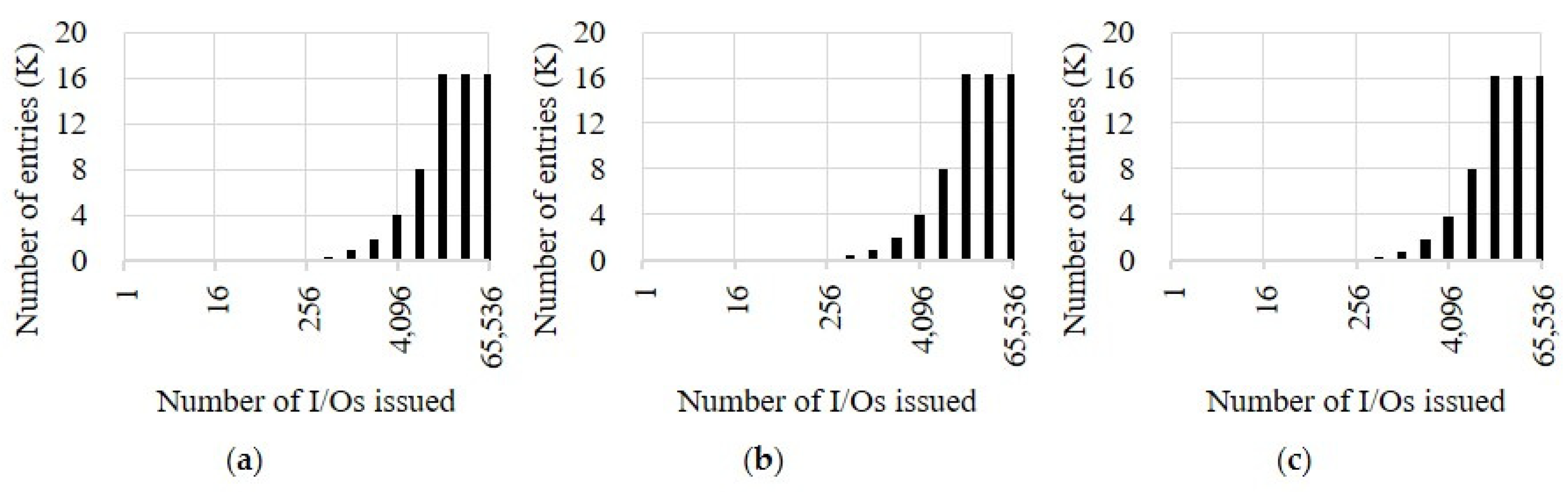
In this way, we measured the number of I/O requests enqueued in the submission queue in the environment summarized in
Table 1. These experiments were performed for the three SSDs described in
Table 2, and one of the widely used storage benchmark tools, fio, was employed for I/O workload generation [
24]. We used libaio as an I/O engine for fio and set the depth that is the number of simultaneous I/O requests made to the SSD from one to 65,536 [
25]. We also set the submission queue size of each SSD to 16,384, which is the maximum size supported. In each experiment, we used the O_DIRECT flag to remove the effects of the buffer and cache layer inside the host operating system [
26]. We also ran fio on only one of several CPU cores to avoid interfering with other processes. The configuration for this experiment is summarized in
Table 3a. Note that we repeated all experiments 10 times to make the results reliable.
Figure 1 shows the average number of I/O requests enqueued in the submission queue after running fio for about 1 min. This number dramatically increases when the number of I/O requests issued by fio is equal to or greater than 256 for SSD-A and SSD-B and equal to or greater 512 for SSD-C. This finding indicates that the SSDs are no longer able to process I/O requests immediately, so they have started waiting in the submission queue. The submission queue of each SSD also becomes almost filled when the number of I/O requests issued is greater than or equal to 16,384. In this situation, the pending I/O requests in the submission queue cannot be rearranged and controlled, so a significant delay can be expected if an I/O request that needs to be handled urgently enters.
Next, a simple experiment was conducted to measure the delay of the I/O request. We first ran fio by setting the number of I/O requests from zero to 20,000 to send a sufficient I/O load to the submission queues. Then, we ran the microbenchmark tool described in
Table 3b that issued a single read request of 512 B, the minimum request size, and measured the time to process the I/O request. We set the process priority of the microbenchmark tool as the highest to mimic a process that is more urgent than other processes.
Figure 2 shows the latency of an I/O request issued by a microbenchmark when each SSD is very busy because of fio execution. Naturally, the latency linearly increases as the I/O load on the SSD increases in each case. When the number of I/O requests issued is 16,384, which is the maximum submission queue size of the SSDs, the latencies become almost constant. Most importantly, there were numerous pending I/O requests in the submission queue in each case, which eventually delayed the execution of the microbenchmark tool with high process priority. Hence, we experimentally confirmed that urgent I/O requests made by high priority processes can be delayed when SSDs are busy due to processing other I/O requests.
4. HMB-Based Fast Track for Urgent I/O Requests
This section presents a new I/O handling method called HMB I/O, which processes urgent I/O requests immediately by using the HMB as a fast track for these requests [
27]. As the HMB is a shared region that can be accessed by both the host and SSD, data requested for read or write operations can be transferred between these components via the HMB instead of the legacy I/O stack.
Figure 3 briefly shows the I/O processing procedure in our scheme. Normal I/O requests pass through the software and hardware queues in the multiqueue block I/O layer and I/O submission queue of the NVMe device driver as in the original procedure. As described in
Section 3, if numerous I/O requests are pending in any queue, the new I/O requests should wait until the previous I/O requests have been dequeued.
When an I/O request is urgent and should be processed immediately, our scheme first bypasses the software and hardware queues. Then, it writes some information related to the I/O requests into the HMB and sends an HMB I/O command, which is a newly added NVMe command in our scheme. As the HMB I/O command should not wait in the submission queues with numerous pending I/O commands, a dedicated queue is necessary in our scheme. A simple solution is to create a new submission queue and then use it as the dedicated queue for the HMB I/O commands. However, even if the highest priority is given to the dedicated submission queue, the latency cannot be avoided completely because submission queues are dispatched in a WRR manner to the SSD devices.
As an alternative, in our approach, the HMB I/O commands are sent into the administration submission queue, which only contains device management I/O commands such as activating the HMB and creating a submission queue. As the administration submission queue is usually empty and is always preferentially dispatched, unlike the other submission queues, the HMB I/O commands can be quickly delivered to the SSD device. If the SSD device receives the HMB I/O commands, it processes them by referring to information within the HMB and finally writes the response of the completed I/O request into the HMB if necessary.
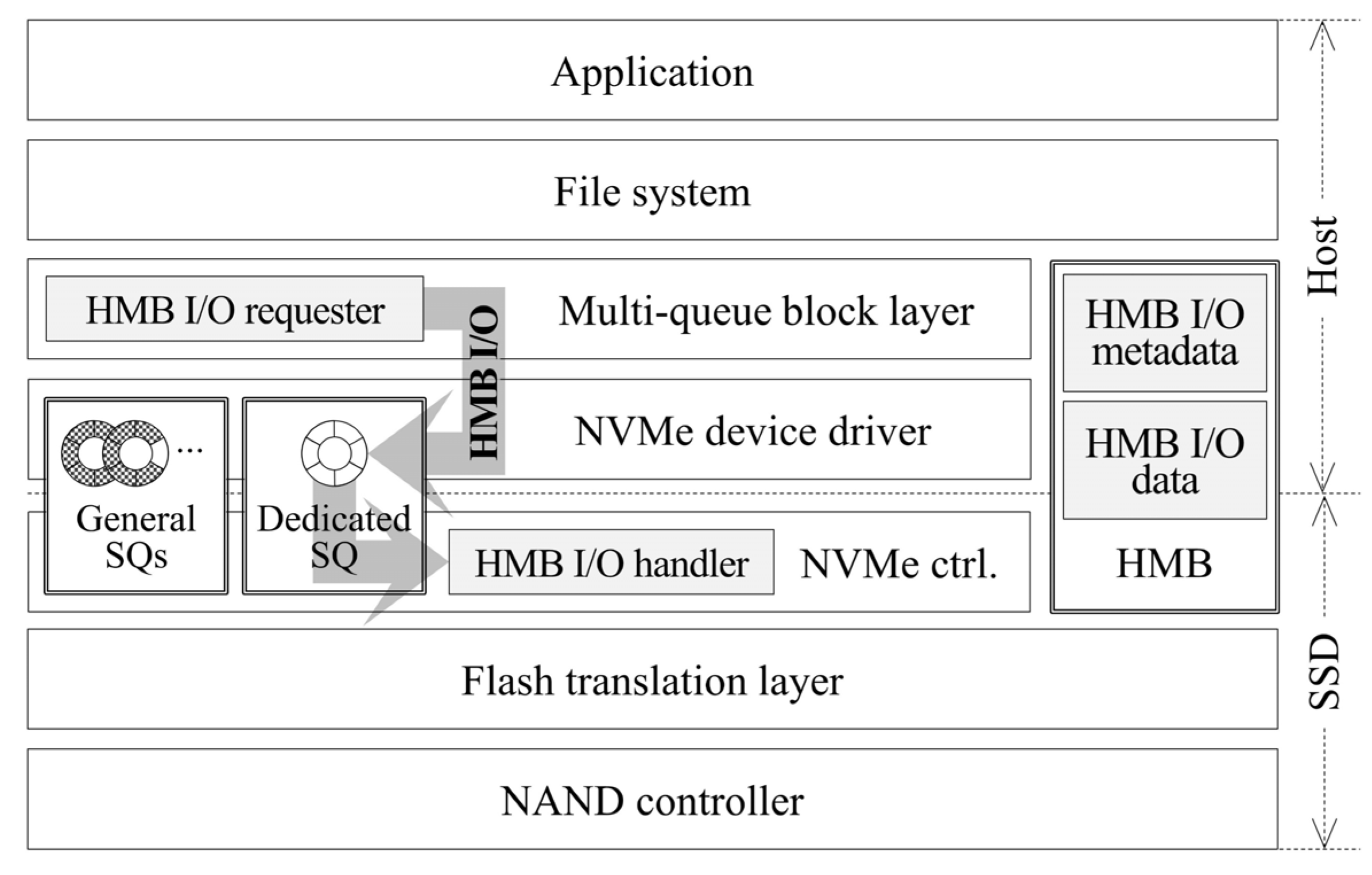
To support HMB I/O, we designed two modules—an HMB I/O requester within the host and an HMB I/O handler within the SSD (
Figure 4). In the block I/O layer, the HMB I/O requester first picks out urgent I/O requests. If an I/O request is urgent, the HMB I/O requester writes information related to the I/O request in the HMB I/O metadata area located in the HMB and issues an HMB I/O command to the SSD. The HMB I/O handler receives the HMB I/O command and starts to process the I/O request in the SSD. It retrieves information related to the I/O request from the HMB I/O metadata area and copies data from NAND to the HMB I/O data area located in the HMB or from the HMB I/O data area to NAND in accordance with the I/O type, read or write. Finally, after the SSD completes the HMB I/O command, the HMB I/O requester receives the completion and the I/O request handling is finished.
The detailed operations of HMB I/O according to I/O type are described in
Figure 5. In the case of a read request, the HMB I/O requester is invoked by
submit_bio(), which starts to process the I/O request at the beginning of the block I/O layer and determines whether or not it is urgent. There are various methods of determining urgency, but one of the simplest is to bring the priority of the process issued the I/O request into the block I/O layer and then use it. As the SSD controller manages the I/O requests in the page units, whereas the host uses the
bio structure represented by sectors, the HMB I/O requester first translates the sector addresses into the logical page addresses. This translation is originally performed in the device driver, but in our work, it was conducted in advance to send the I/O requests directly to the SSDs via the HMB.
After translation, the converted data are written to the HMB I/O metadata area. As can be seen in
Figure 6, the
HMBIOMetadata area has a starting logical page number
lpn, number of pages
nlp, and request type
type. Both this space and the HMB I/O data area, which saves data to be written to or read from the NAND flash, are allocated when the SSD receives the
Set Feature command. This command is issued by the host when the host requests that the SSD activate the HMB. To share the spaces with the host, after allocating them, the SSD writes their location information to the
HMB control block. The host can access the spaces by using data in the
HMB control block:
Segment, which is the index of the physically contiguous block of the HMB and
offset, which is the internal offset in the segment. Then, the HMB I/O requester sends the HMB I/O command to the SSD, and the HMB I/O handler receives it. By using the HMB I/O metadata, data are copied from the NAND flash to the HMB I/O data area and the completion message is enqueued to the dedicated queue. After the host receives the completion message, the host copies data from the HMB I/O data area into its own memory pages, where the location is described in the
bio, and completes the request by
bio_endio().
The process in the write request case differs from that in the read request case in two respects. One is that the HMB I/O requester copies the data from the host memory pages to the HMB I/O data area before issuing an HMB I/O command. The other is that the HMB I/O handler copies data from the HMB I/O data area to the NAND flash after reading the request information from the HMB I/O metadata area.
5. Performance Evaluation
We implemented the proposed HMB I/O scheme in the QEMU-based SSD emulator by referring to prior works [
8,
28]. Our implementation includes HMB-related functions such as activating the HMB, dividing the HMB space for multiple purposes, and sharing the HMB with the host. We also added the HMB I/O handler and requester to the emulated SSD and Linux kernel, respectively.
We conducted various experiments to verify the effectiveness of HMB I/O for providing QoS to urgent I/Os when an SSD has a bursty I/O load.
Table 4 describes the experimental environments. The submission queue size of the emulated NVMe SSD was set to 16,384, and fio was used to generate heavy I/O workloads by issuing random read requests. In our experiment, the average number of I/O requests in each submission queue was about 14,890 when only fio was executed. To generate the urgent I/O requests that could be handled by HMB I/O, we used I/O workloads collected on a Nexus 5 Android smartphone [
29]. The workloads consisted of I/O records that were collected at the block I/O layer and device driver of the smartphone when some applications or system functions such as sending and receiving calls were working (
Table 5). To replay them in the block I/O layer, all I/O requests bypassed the caches and buffers of the host operating system and were directly delivered to the block I/O layer. Before executing the workloads in
Table 5, we first executed fio for some duration to fill the submission queues with I/O requests sufficiently.
Figure 7 shows the average latency of urgent I/O requests in four cases—when urgent I/O requests are processed via the original block I/O layer while fio is not executed (
Idle (
original)), when urgent I/O requests are processed by HMB I/O while fio is not executed (
Idle (
HMB I/O)), when urgent I/O requests are processed by original block I/O layer while fio is executed (
Busy (
original)), and when urgent I/O requests are processed by HMB I/O while fio is executed (
Busy (
HMB I/O)). When the SSD is busy with a heavy workload, the average latencies of urgent I/O requests reach 996.8 ms. However, by processing urgent I/O requests with HMB I/O, the average latency can be improved by 31.6–459.7 times. Above all, the latencies of urgent I/O requests are significantly stable when they are processed with HMB I/O. When fio is executed simultaneously, the latencies of urgent I/O requests are from 0.11 to 2.48 ms if they are processed with the HMB I/O, but they are from 22.31 to 96.98 ms if they are processed via the original block I/O layer.
In the same experiment used to obtain the data in
Figure 7, we analyzed the results in terms of tail latencies, which are often more important than average latencies.
Figure 8 depicts the relative performance improvement when using HMB I/O compared to the latency when fio and microbenchmark are executed simultaneously without using the HMB I/O. As shown, by servicing the urgent workloads with HMB I/O, the tail latencies were reduced to 14%–39%. In addition, there are no significant differences from the idle situation in which only the microbenchmark was executed, about 1.4 times on average.
Figure 9 shows the individual I/O latencies of the workloads when fio was executed together. Only three sets of results are shown here (those for the Movie, Amazon, and Twitter workloads) because they have high, middle, and low performance improvements in terms of average latency, respectively. As expected, the I/O latencies are very long when differentiated service is not provided, at 600–1200 ms in many cases. This level cannot be ignored in terms of user satisfaction. On the other hand, the latencies are very short when HMB I/O is used to process the workloads urgently, again demonstrating the effectiveness of our scheme.
We also analyzed the I/O latency as a function of the amount of I/O on the SSD, namely, the number of I/O requests issued by fio. To this end, we set the number of I/Os issued from eight to 16,384 and used the Amazon workload to measure the I/O latencies because the performance improvement of this workload was the middle among the workloads we tested. As can be seen in
Figure 10, when HMB I/O is not used, the average latency gradually increases as the I/O load increases. If the Amazon workload is processed by HMB I/O, this situation is significantly improved, and the average latency is constantly about 15 ms regardless of the number of I/Os issued by fio.
Since our scheme gives high priority to I/O requests that should be processed urgently even if there are other pending I/O requests in the submission queues, the processing of relatively less urgent I/O requests is inevitably delayed.
Figure 11 shows the average fio latency as a function of the number of I/O issued. As the I/O load on the SSD increases, the fio latency also increases regardless of the usage of HMB I/O. In particular, when HMB I/O is employed, the I/O requests from the fio in the submission queue should wait longer due to the processing of urgent I/O requests via HMB I/O, so the fio latency increases by 49% on average. Although the microbenchmark is given a higher process priority, the process priority has no effect here because it is not considered in the original multiqueue block I/O layer.
When the SSD is very busy due to numerous I/O requests, our HMB I/O can be efficiently utilized to improve application launch times. Launching an application requires many I/O requests to read files such as executable files, configurations, and shared libraries. We measured the launch times of several widely used applications by employing the start time and the time at which the initial screen display is finished (
Table 6). As in the previous experiments, three applications were given higher process priority, and all I/O requests issued by these applications were processed by HMB I/O.
Figure 12 shows the launch time of each application as a function of the I/O load on the SSD. If the number of I/O requests issued by fio is equal to or less than 16, the effectiveness of HMB I/O is not obvious. However, when the number of I/O requests issued is greater than 16, the application launch time increases rapidly without HMB I/O, whereas with HMB I/O, the launch time is almost constant. This finding indicates that HMB I/O is an effective means of providing a guaranteed launch time for application, which is very important for improving user satisfaction.
6. Conclusions
This paper presented an I/O scheme that provides guaranteed performance even when an SSD is overburdened due to numerous I/O requests. This approach utilizes an HMB that enables the SSD to access the host DRAM as a fast track for I/O requests requiring urgent processing. To avoid delayed processing of urgent I/O requests when there are numerous pending I/O requests in the submission queues, they are sent to the SSDs by bypassing the original block I/O layer. Various experiments showed that this HMB I/O scheme provides stable I/O performance in every case in terms of average and tail latency. In particular, our scheme could guarantee application launch times, which is crucial for end users.
Since the HMB space can be used for the cooperation of the host and SSD, we believe that it has much potential to improve the I/O performances when the NVMe SSD is used as a storage. Like our work bypasses the multiqueue block I/O layer by using the HMB, other parts of the existing I/O kernel stack can be also optimized via the HMB. Especially, as DRAM within modern SSDs is not always enough to execute the FTL, the host’s DRAM can be used instead. In addition, as the host has better computation ability as well as more workload information than SSDs, the HMB space can be utilized efficiently for write buffer or mapping the table cache. In the future, we will study continuously many usage cases to use the HMB for improving the I/O performance in the NVMe SSDs.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}