Hierarchical Transformer Network for Utterance-Level Emotion Recognition


Abstract
:1. Introduction
- We propose a hierarchical transformer framework to better learn both the individual utterance embeddings and the contextual information of utterances.
- We use a pretrained language model, BERT, to obtain better dialog embedding, which is equivalent to introducing external data into the model and solving the problem of data shortage to some extent.
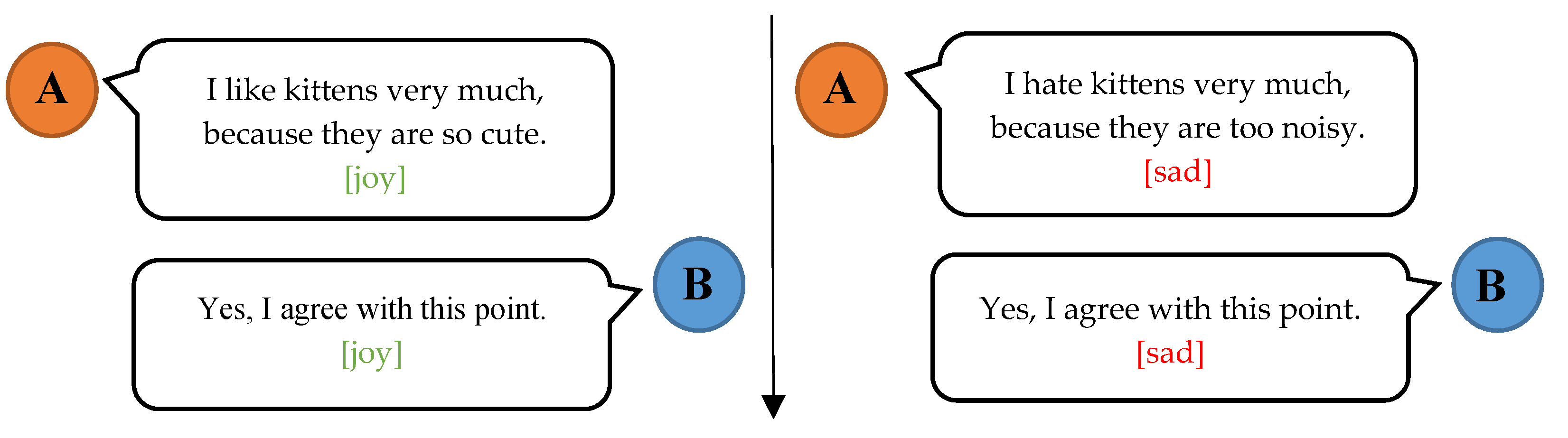
- For the first time, we use speaker embedding in the model for the ULER task, which allows our model to capture the interaction between speakers and better understand emotional dynamics in dialog systems.
- Our model outperforms state-of-the-art models on three benchmark datasets, Friends, EmotionPush, and EmoryNLP.
2. Related Work
3. Approach
3.1. Task Definition
3.2. HiTransformer: Hierarchical Transformer
3.2.1. Individual Utterance Embedding
3.2.2. Contextual Utterance Embedding
3.3. HiTransformer-s: Hierarchical Transformer with Speaker Embeddings
3.4. Model Training
4. Experimental Settings
4.1. Dataset
4.2. Evaluation Metrics
4.3. Compared Methods
- [7]: A model with a 1-D CNN to extract the utterance embeddings and a bidirectional LSTM to model the relationship of utterances;
- bcGRU [7]: A variant of with a BiGRU to capture the utterance-level context;
- [7]: is a context-dependent encoder (CoDE) model with a bidirectional GRU that extracts the utterance embeddings and a bidirectional GRU that models the relationship of utterances;
- [7]: A variant of that pretrains a context-dependent encoder (CoDE) for ULER by learning from unlabeled conversation data;
- HiGRU [4]: A hierarchical gated recurrent unit (HiGRU) framework with a lower-level GRU to model the word-level inputs and an upper-level GRU to capture the contexts of utterance-level embeddings;
- HiGRU-f [4]: A variant of HiGRU with individual feature fusion;
- HiGRU-sf [4]: A variant of HiGRU with self-attention and feature fusion;
- SCNN [18]: A sequence-based convolutional neural network that utilizes the emotion sequence from the previous utterances for detecting the emotion of the current utterance.
- IDEA [8]: Two different BERT models were developed. For Friends, pretraining was done using a sliding window of two utterances to provide dialogue context. For EmotionPush, pretraining was performed on Twitter data, as it is similar in nature to chat-based dialogues. In both cases, special attention was given to the class imbalance issue by applying “weighted balanced warming” to the loss function.
4.4. Parameters
5. Result Analysis
5.1. Comparison with Baselines
5.2. HiTransformer vs. HiTransformer-s
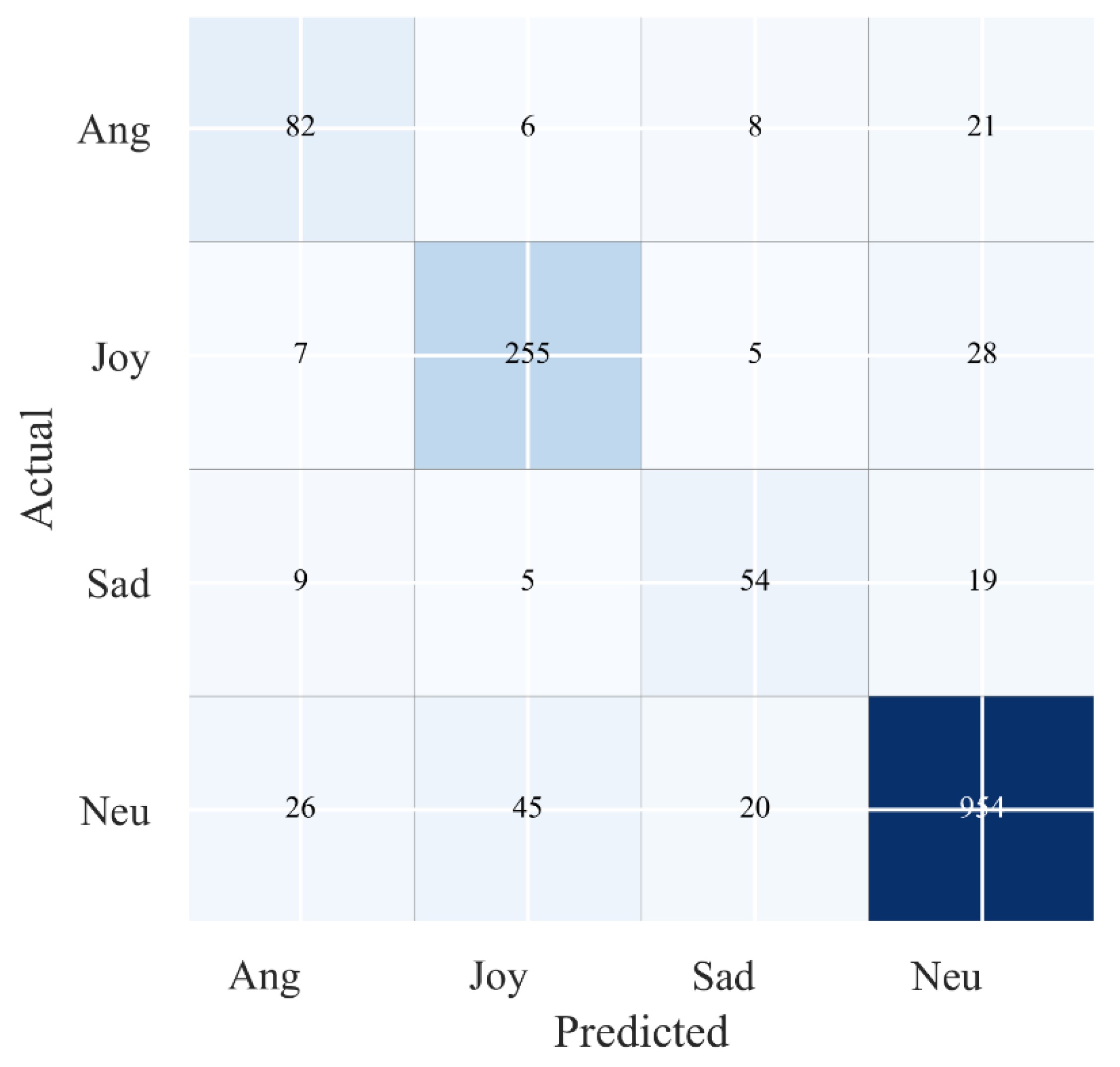
5.3. Error Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 873–883. [Google Scholar]
- Olson, D. From utterance to text: The bias of language in speech and writing. Harv. Educ. Rev. 1977, 47, 257–281. [Google Scholar] [CrossRef]
- Hazarika, D.; Poria, S.; Zadeh, A.; Cambria, E.; Morency, L.; Zimmermann, R. Conversational memory network for emotion recognition in dyadic dialogue videos. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018; pp. 2122–2132. [Google Scholar]
- Jiao, W.; Yang, H.; King, I.; Lyu, M.R. HiGRU: Hierarchical Gated Recurrent Units for Utterance-level Emotion Recognition. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 397–406. [Google Scholar]
- Bradbury, J.; Merity, S.; Xiong, C.; Socher, R. Quasi-recurrent neural networks. arXiv 2016, arXiv:1611.01576. [Google Scholar]
- Zhong, P.; Wang, D.; Miao, C. Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations. In Proceedings of the International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 165–176. [Google Scholar]
- Jiao, W.; Michae, R.L.; Irwin, K. PT-CoDE: Pre-trained Context-Dependent Encoder for Utterance-level Emotion Recognition. arXiv 2019, arXiv:1910.08916. [Google Scholar]
- Huang, Y.; Lee, S.; Ma, M.; Chen, Y.; Yu, Y.; Chen, Y. EmotionX-IDEA: Emotion BERT—An Affectional Model for Conversation. arXiv 2019, arXiv:1908.06264. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Navarretta, C.; Choukri, K.; Declerck, T.; Goggi, S.; Grobelnik, M.; Maegaard, B. Mirroring facial expressions and emotions in dyadic conversations. In Proceedings of the Language Resources and Evaluation Conference, Portoroz, Slovenia, 23–28 May 2016; pp. 469–474. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2013, 3, 1137–1155. [Google Scholar]
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-supervised recursive autoencoders for predicting sentiment distributions. In Proceedings of the Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 151–161. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Abdul-Mageed, M.; Ungar, L.H. Emonet: Fine-grained emotion detection with gated recurrent neural networks. In Proceedings of the Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 718–728. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A.F. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar]
- Luo, L.; Yang, H.; Chin, F.Y.L. Emotionx-dlc: Self-attentive BiLSTM for detecting sequential emotions in dialogues. In Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, Melbourne, Australia, 20 July 2018; pp. 32–36. [Google Scholar]
- Zahiri, S.M.; Choi, J.D. Emotion detection on TV show transcripts with sequence-based convolutional neural networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 44–52. [Google Scholar]
- Zhou, X.; Li, L.; Dong, D.; Liu, Y.; Chen, Y.; Zhao, W.X.; Yu, D.; Wu, H. Multi-turn response selection for chatbots with deep attention matching network. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1118–1127. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Cohen, W.W.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openaiassets/research-covers/languageunsupervised/languageunderstandingpaper.pdf (accessed on 23 June 2020).
- Dehghani, M.; Gouws, S.; Vinyals, O.; Uszkoreit, J.; Kaiser, Ł. Universal transformers. arXiv 2018, arXiv:1807.03819. [Google Scholar]
- Liu, P.; Chang, S.; Huang, X.; Tang, J.; Cheung, J.C.K. Contextualized non-local neural networks for squence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6762–6769. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, A.L. Deep contextualized word representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1 June 2018; pp. 2227–2237. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing bert for aspect-based sentiment analysis via constructing auxiliary sentence. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 380–385. [Google Scholar]
- Nils, R.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3973–3983. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Hsu, C.C.; Ku, L.W. Socialnlp 2018 emotionx challenge overview: Recognizing emotions in dialogues. In Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, Melbourne, Australia, 20 July 2018; pp. 27–31. [Google Scholar]
- Khosla, S. Emotionx-ar: CNN-DCNN autoencoder based emotion classifier. In Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, Melbourne, Australia, 20 July 2018; pp. 37–44. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Dialog (#Utterance) | Emotion | ||||||
|---|---|---|---|---|---|---|---|---|
| Train | Val | Test | Ang | Hap/Joy | Sad | Neu | Others | |
| Friends | 720 (10,561) | 80 (1178) | 200 (2764) | 759 | 1710 | 498 | 6530 | 5006 |
| EmotionPush | 720 (10,733) | 80 (1202) | 200 (2807) | 140 | 2100 | 514 | 9855 | 2133 |
| Dataset | #Dialog (#Utterance) | Emotion | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Val | Test | Neu | Joy | Peaceful | Powerful | Scared | Mad | Sad | |
| EmoryNLP | 713 (9934) | 99 (1344) | 85 (1328) | 3776 | 2755 | 1191 | 1063 | 1645 | 1332 | 844 |
| Model | Friends | EmotionPush | EmoryNLP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mac-F1 | WA | UWA | Mac-F1 | WA | UWA | Mac-F1 | WA | UWA | |
| SA-BiLSTM | - | 79.8 | 59.6 | - | 87.7 | 55.0 | - | - | - |
| CNN-DCNN | - | 67.0 | 62.5 | - | 75.7 | 62.5 | - | - | - |
| 63.1 | 79.9 | 63.3 | 60.3 | 84.8 | 57.9 | 25.5 | 33.5 | 27.6 | |
| bcGRU | 62.4 | 77.6 | 66.1 | 60.5 | 84.6 | 56.9 | 26.1 | 33.1 | 27.4 |
| 62.4 | 78.0 | 65.3 | 60.3 | 84.2 | 58.5 | 26.7 | 34.7 | 28.8 | |
| 65.9 | 81.3 | 66.8 | 62.6 | 84.7 | 60.4 | 29.1 | 36.1 | 30.3 | |
| HiGRU | - | 74.4 | 67.2 | - | 73.8 | 66.3 | - | - | - |
| HiGRU-f | - | 71.3 | 68.4 | - | 73.0 | 66.9 | - | - | - |
| HiGRU-sf | - | 74.0 | 68.9 | - | 73.0 | 68.1 | - | - | - |
| IDEA | 73.1 | 81.6 | 77.9 | 69.5 | 88.2 | 84.9 | - | - | - |
| SCNN | - | - | - | - | - | - | 26.9 | 37.9 | - |
| HiTransformer | 66.66 | 82.11 | 63.71 | 63.90 | 86.87 | 61.55 | 31.36 | 37.25 | 29.24 |
| HiTransformer-s | 67.88 | 82.18 | 68.78 | 65.43 | 86.92 | 63.03 | 33.04 | 37.98 | 32.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Wu, C.; Wang, Z.; Zheng, K. Hierarchical Transformer Network for Utterance-Level Emotion Recognition. Appl. Sci. 2020, 10, 4447. https://doi.org/10.3390/app10134447
Li Q, Wu C, Wang Z, Zheng K. Hierarchical Transformer Network for Utterance-Level Emotion Recognition. Applied Sciences. 2020; 10(13):4447. https://doi.org/10.3390/app10134447
Chicago/Turabian StyleLi, Qingbiao, Chunhua Wu, Zhe Wang, and Kangfeng Zheng. 2020. "Hierarchical Transformer Network for Utterance-Level Emotion Recognition" Applied Sciences 10, no. 13: 4447. https://doi.org/10.3390/app10134447