Robust Deep Speaker Recognition: Learning Latent Representation with Joint Angular Margin Loss




Abstract
:1. Introduction
- A family of models is proposed that utilizes angular-margin-based losses to improve the original SincNet architecture.
- Experimentally significant performance improvements are demonstrated in comparison to the performance of competitive baselines over a number of speaker-recognition datasets.
- Interdataset evaluation was performed, which demonstrated that one of the proposed models, ALL-SincNet, consistently outperformed the baselines and prior models.
- Cross-domain evaluation was performed on Bengali speaker recognition, which is considered a more diverse domain task, and it showed that ALL-SincNet could generalize reasonably well compared to the other baselines.
2. Related Work
2.1. Speaker Recognition
2.2. Loss
3. Loss Function
3.1. Softmax Loss
3.2. A-Softmax Loss
3.3. AM-Softmax Loss
3.4. CosFace Loss
4. Method
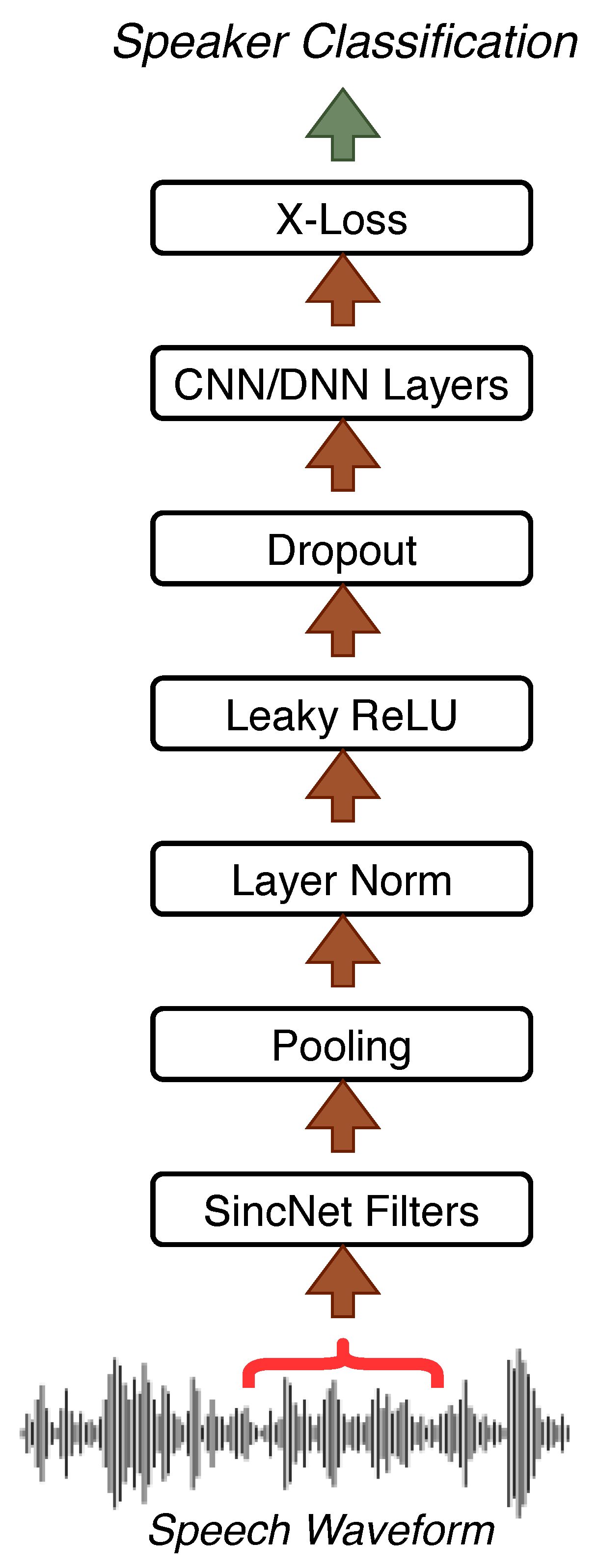
4.1. SincNet
4.2. Proposed Architecture
4.2.1. ArcFace Loss
4.2.2. Ensemble Loss
4.2.3. Combination of Margin-Based Toss
5. Experiments
5.1. Datasets
5.1.1. TIMIT
5.1.2. LibriSpeech
5.1.3. Large Bengali ASR Dataset
5.2. Baselines
5.3. Training and Testing Procedure
5.4. Metrics
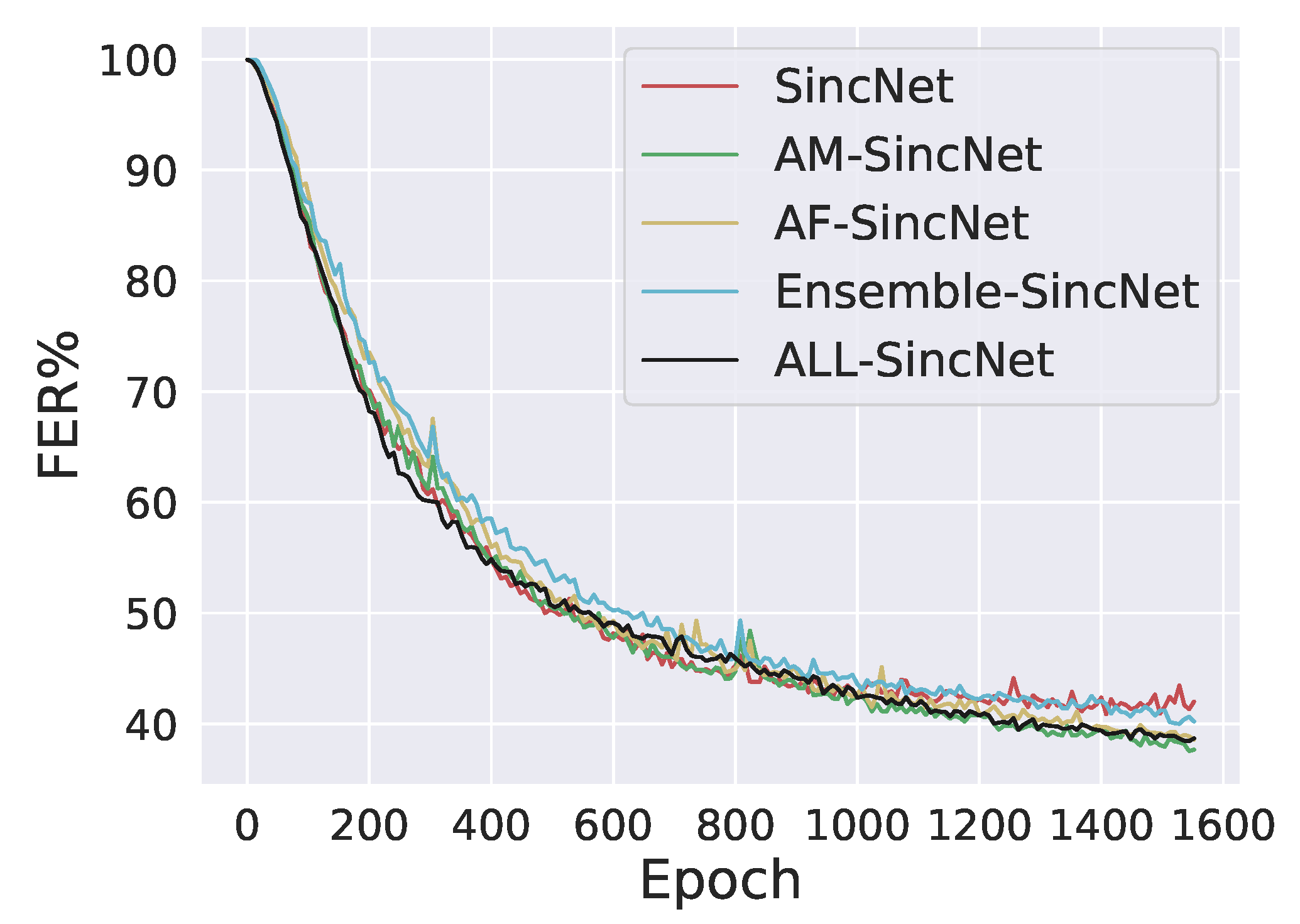
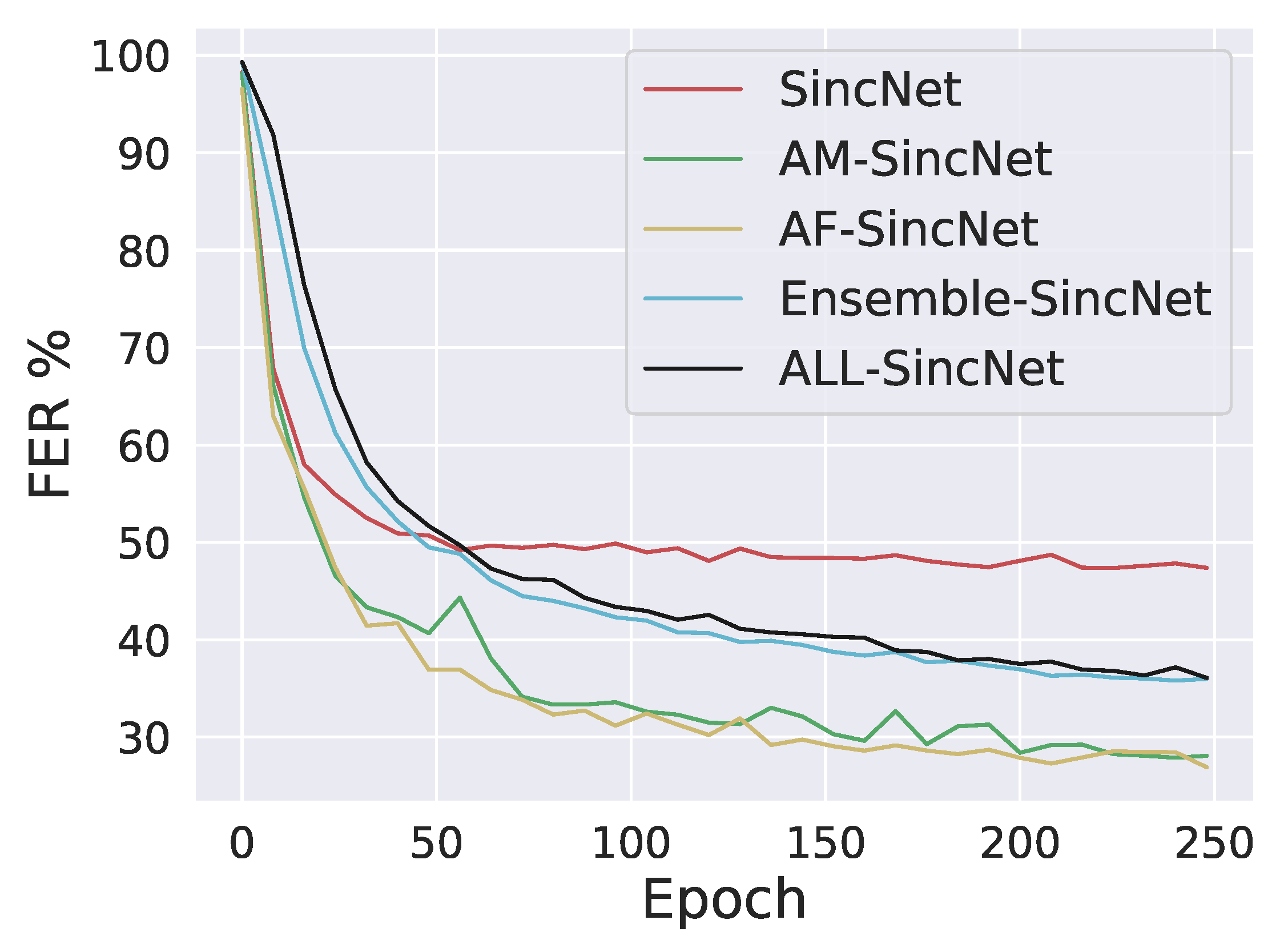
6. Results
6.1. Intradataset Evaluation
6.2. Interdataset Evaluation
- A single speaker’s single speech was registered in our system.
- Cosine similarity was performed using Equation (12) with rest of the test set and identified with the highest similar score.
6.2.1. Trained on TIMIT and Tested on LibriSpeech
6.2.2. Trained on LibriSpeech and Tested on TIMIT
6.2.3. Interdataset Test on Bengali ASR Dataset (Interlanguage Test)
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-End Factor Analysis for Speaker Verification. Trans. Audio Speech Lang. Proc. 2011, 19, 788–798. [Google Scholar] [CrossRef]
- Prince, S.J.D.; Elder, J.H. Probabilistic Linear Discriminant Analysis for Inferences About Identity. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- Matějka, P.; Glembek, O.; Castaldo, F.; Alam, M.J.; Plchot, O.; Kenny, P.; Burget, L.; Černocky, J. Full-covariance UBM and heavy-tailed PLDA in i-vector speaker verification. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4828–4831. [Google Scholar]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4052–4056. [Google Scholar]
- Richardson, F.; Reynolds, D.A.; Dehak, N. A Unified Deep Neural Network for Speaker and Language Recognition. CoRR 2015, abs/1504.00923. Available online: http://xxx.lanl.gov/abs/1504.00923 (accessed on 20 April 2020).
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep Neural Network Embeddings for Text-Independent Speaker Verification. Proc. Interspeech 2017, 999–1003. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 20 March 2020).
- Yu, D.; Deng, L. Automatic Speech Recognition: A Deep Learning Approach; Springer Publishing Company: New York City, NY, USA, 2014. [Google Scholar]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Ravanelli, M. Deep learning for distant speech recognition. arXiv 2017, arXiv:1712.06086. [Google Scholar]
- Ravanelli, M.; Brakel, P.; Omologo, M.; Bengio, Y. A network of deep neural networks for distant speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: New York City, NY, USA, 2017; pp. 4880–4884. [Google Scholar]
- Kenny, P.; Stafylakis, T.; Ouellet, P.; Gupta, V.; Alam, M.J. Deep Neural Networks for extracting Baum-Welch statistics for Speaker Recognition. In Proceedings of the Odyssey 2014, Joensuu, Finland, 16–19 June 2014; pp. 293–298. [Google Scholar]
- Yaman, S.; Pelecanos, J.; Sarikaya, R. Bottleneck Features for Speaker Recognition. In Proceedings of the Odyssey 2012—The Speaker and Language Recognition Workshop, Singapore, 25–28 June 2012; Volume 12. [Google Scholar]
- Salehghaffari, H. Speaker verification using convolutional neural networks. arXiv 2018, arXiv:1803.05427. [Google Scholar]
- Lukic, Y.; Vogt, C.; Dürr, O.; Stadelmann, T. Speaker identification and clustering using convolutional neural networks. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; IEEE: New York City, NY, USA, 2018; pp. 1021–1028. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, NY, USA, 15–21 June 2019; pp. 4690–4699. [Google Scholar]
- Nunes, J.A.C.; Macêdo, D.; Zanchettin, C. Additive margin sincnet for speaker recognition. In Proceedings of the 2019 IEEE International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–5. [Google Scholar]
- Hansen, J.H.L.; Hasan, T. Speaker Recognition by Machines and Humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Dişken, G.; Tüfekçi, Z.; Saribulut, L.; Çevik, U. A Review on Feature Extraction for Speaker Recognition under Degraded Conditions. IETE Tech. Rev. 2017, 34, 321–332. [Google Scholar] [CrossRef]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. arXiv 2018, arXiv:abs/1806.05622. [Google Scholar]
- Bhattacharya, G.; Alam, M.J.; Kenny, P. Deep Speaker Embeddings for Short-Duration Speaker Verification. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Palaz, D.; Magimai-Doss, M.; Collobert, R. Analysis of CNN-Based Speech Recognition System Using Raw Speech as Input; Idiap Research Institute: Martigny, Switzerland, 2015. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Mohamed, A.; Ramabhadran, B. Learning filter banks within a deep neural network framework. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–13 December 2013; pp. 297–302. [Google Scholar]
- Yu, H.; Tan, Z.; Zhang, Y.; Ma, Z.; Guo, J. DNN Filter Bank Cepstral Coefficients for Spoofing Detection. IEEE Access 2017, 5, 4779–4787. [Google Scholar] [CrossRef]
- Seki, H.; Yamamoto, K.; Nakagawa, S. A deep neural network integrated with filterbank learning for speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5480–5484. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Cai, W.; Chen, J.; Li, M. Analysis of Length Normalization in End-to-End Speaker Verification System. arXiv 2018, arXiv:1806.03209. [Google Scholar]
- Shon, S.; Tang, H.; Glass, J.R. Frame-Level Speaker Embeddings for Text-Independent Speaker Recognition and Analysis of End-to-End Model. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1007–1013. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive Statistics Pooling for Deep Speaker Embedding. arXiv 2018, arXiv:abs/1803.10963. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Muckenhirn, H.; Magimai-Doss, M.; Marcel, S. Towards Directly Modeling Raw Speech Signal for Speaker Verification Using CNNS. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4884–4888. [Google Scholar]
- Dinkel, H.; Chen, N.; Qian, Y.; Yu, K. End-to-end spoofing detection with raw waveform CLDNNS. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4860–4864. [Google Scholar]
- Yu, Y.; Fan, L.; Li, W. Ensemble Additive Margin Softmax for Speaker Verification. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6046–6050. [Google Scholar]
- Cai, W.; Chen, J.; Li, M. Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System. arXiv 2018, arXiv:1804.05160. [Google Scholar]
- Wang, X.; Zhang, S.; Lei, Z.; Liu, S.; Guo, X.; Li, S.Z. Ensemble Soft-Margin Softmax Loss for Image Classification. arXiv 2018, arXiv:1805.03922. [Google Scholar]
- Gretton, A.; Fukumizu, K.; Teo, C.-H.; Song, L.; Schölkopf, B.; Smola, A. A kernel statistical test of independence. In Proceedings of the Advances in Neural Information Processing Systems 20—2007 Conference, Vancouver, BC, Canada, 3–6 December 2007; Curran Associates Inc.: New York City, NY, USA, 2009; pp. 1–8. [Google Scholar]
- Garofolo, J.S.; Lamel, L.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. DARPA TIMIT: Acoustic-phonetic continuous speech corpus CD-ROM, NIST speech disc 1-1.1. STIN 1993, 93, 27403. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Li, J.; Zhang, X.; Jia, C.; Xu, J.; Zhang, L.; Wang, Y.; Ma, S.; Gao, W. Universal Adversarial Perturbations Generative Network For Speaker Recognition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Tawara, N.; Ogawa, A.; Iwata, T.; Delcroix, M.; Ogawa, T. Frame-Level Phoneme-Invariant Speaker Embedding for Text-Independent Speaker Recognition on Extremely Short Utterances. In Proceedings of the ICASSP 2020—IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; pp. 6799–6803. [Google Scholar]
- Kjartansson, O.; Sarin, S.; Pipatsrisawat, K.; Jansche, M.; Ha, L. Crowd-Sourced Speech Corpora for Javanese, Sundanese, Sinhala, Nepali, and Bangladeshi Bengali. In Proceedings of the 6th International Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU), Gurugram, India, 29–31 August 2018; pp. 52–55. [Google Scholar]
- Kjartansson, O.; Sarin, S.; Pipatsrisawat, K.; Jansche, M.; Ha, L. Large Bengali ASR Training Data Set. 2018. Available online: https://www.openslr.org/53/ (accessed on 15 January 2020).
- Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:abs/1607.06450. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:abs/1502.03167. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York City, NY, USA, 2019; pp. 8024–8035. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Configuration |
|---|---|
| SincNet (baseline) | SincNet + softmax loss [16] |
| AM-SincNet (baseline) | SincNet + AM-Softmax loss [21] |
| AF-SincNet | SincNet + ArcFace loss (Section 4.2.1) |
| Ensemble-SincNet | SincNet + ensemble loss (Section 4.2.2) |
| ALL-SincNet | SincNet + combination of margin-based loss (Section 4.2.3) |
| Configuration | TIMIT ↓ | LibriSpeech ↓ |
|---|---|---|
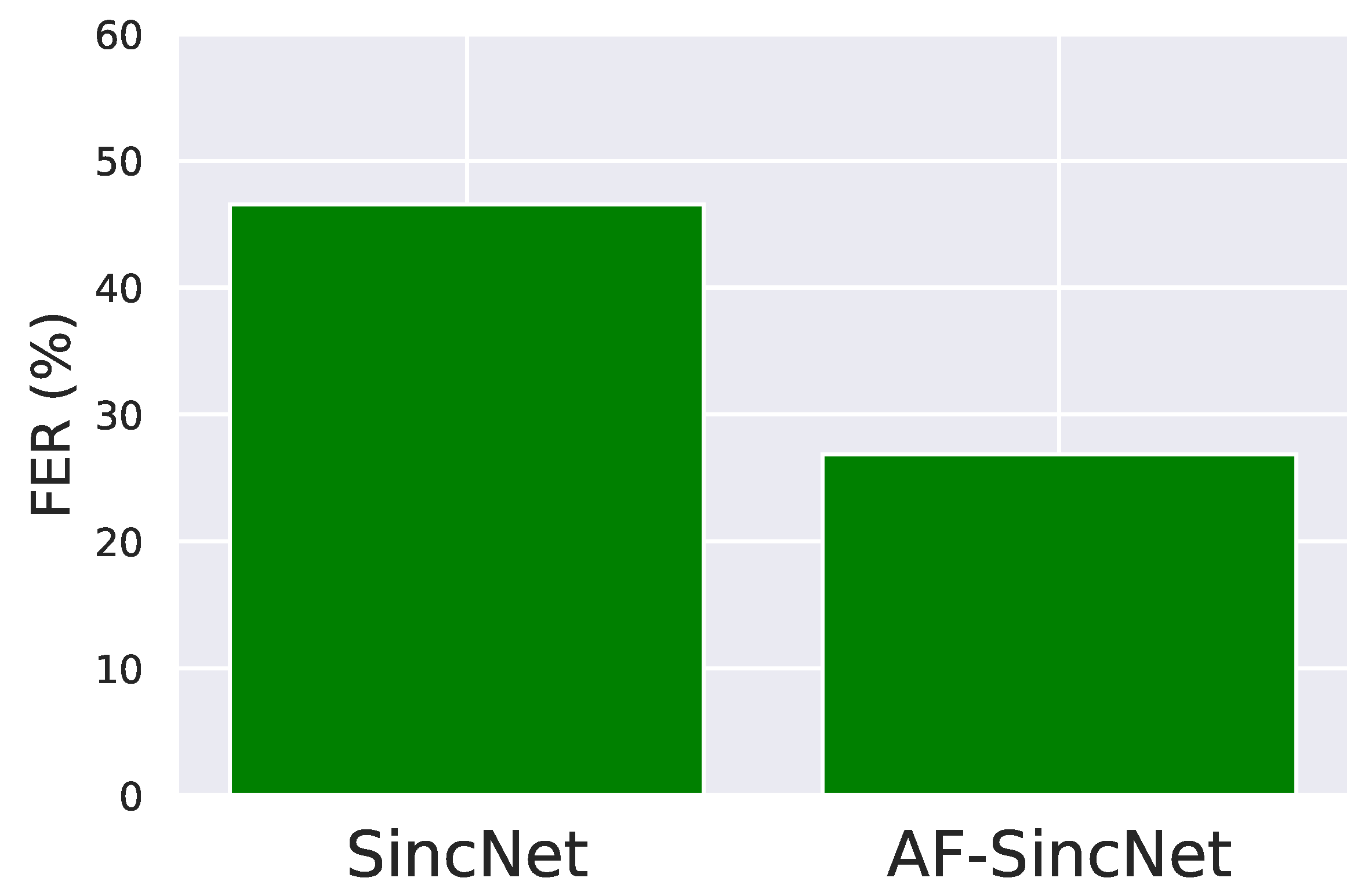
| SincNet [16] | 47.38 | 45.23 |
| AM-SincNet [21] | 28.09 | 44.73 |
| AF-SincNet | 26.90 | 44.65 |
| Ensemble-SincNet | 35.98 | 45.97 |
| ALL-SincNet | 36.08 | 45.92 |
| Configuration | CER on TIMIT ↓ | CER on LibriSpeech ↓ |
|---|---|---|
| SincNet [16] | 1.08 | 3.2 |
| AM-SincNet [21] | 0.36 | 6.1 |
| AF-SincNet | 0.28 | 5.7 |
| Ensemble-SincNet | 0.79 | 7.2 |
| ALL-SincNet | 0.72 | 6.4 |
| TIMIT Trained LibriSpeech Test | LibriSpeech Trained TIMIT Test | ||
|---|---|---|---|
| Configuration | CER (%) | Configuration | CER (%) |
| SincNet [16] | 10.09% | SincNet | 10.94% |
| AM-SincNet [21] | 9.39% | AM-SincNet | 13.10% |
| AF-SincNet | 9.14% | AF-SincNet | 10.83% |
| Ensemble-SincNet | 8.10% | Ensemble-SincNet | 12.87% |
| ALL-SincNet | 7.15% | ALL-SincNet | 10.72% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chowdhury, L.; Zunair, H.; Mohammed, N. Robust Deep Speaker Recognition: Learning Latent Representation with Joint Angular Margin Loss. Appl. Sci. 2020, 10, 7522. https://doi.org/10.3390/app10217522
Chowdhury L, Zunair H, Mohammed N. Robust Deep Speaker Recognition: Learning Latent Representation with Joint Angular Margin Loss. Applied Sciences. 2020; 10(21):7522. https://doi.org/10.3390/app10217522
Chicago/Turabian StyleChowdhury, Labib, Hasib Zunair, and Nabeel Mohammed. 2020. "Robust Deep Speaker Recognition: Learning Latent Representation with Joint Angular Margin Loss" Applied Sciences 10, no. 21: 7522. https://doi.org/10.3390/app10217522