MASS: Microphone Array Speech Simulator in Room Acoustic Environment for Multi-Channel Speech Coding and Enhancement


Abstract
:Featured Application
Abstract
1. Introduction
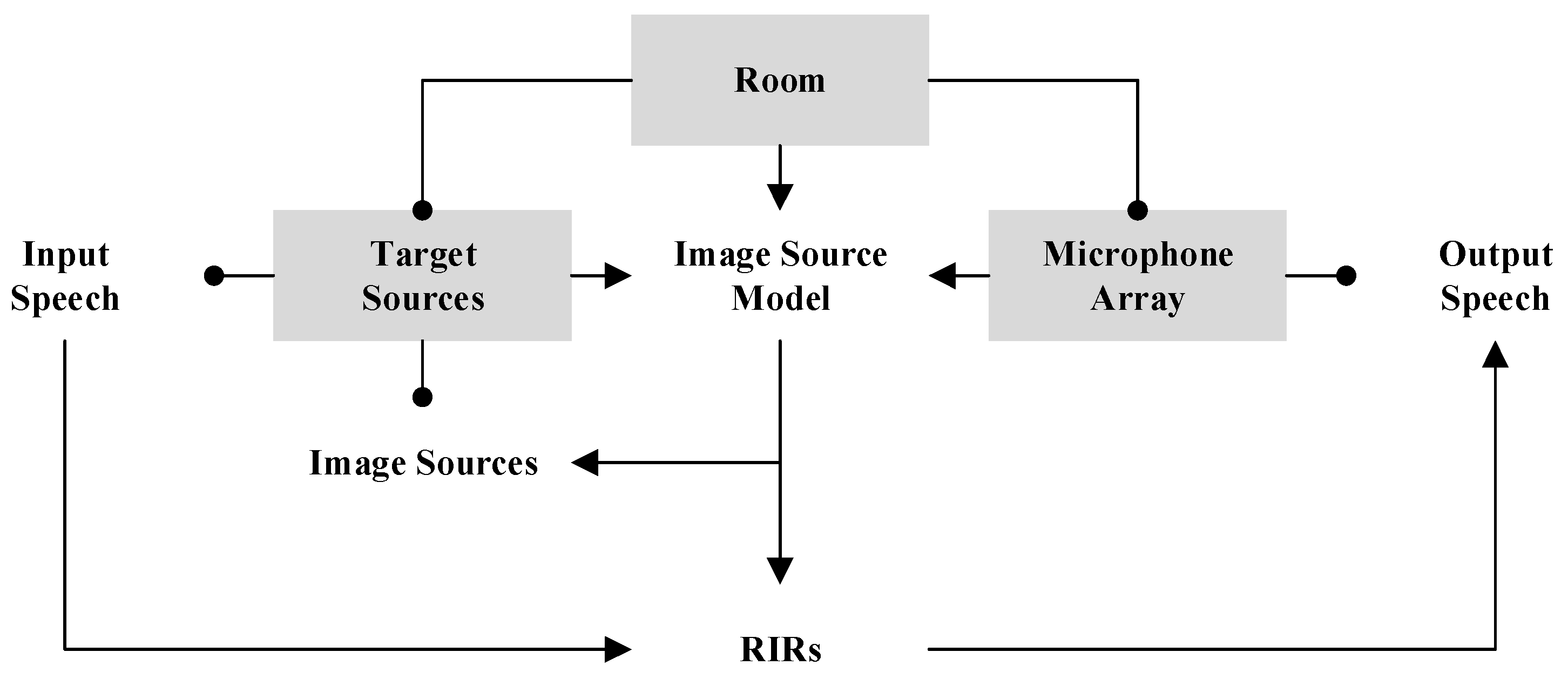
2. Microphone Array Speech Simulator
3. Simulation and Analysis of Microphone Array Speech
3.1. Simulation of Microphone Array Speech in Room Acoustic Environment
3.2. Analysis of the Simulated Microphone Array Speech
3.3. Comparison with Other Speech Simulation Methods
4. Applications in Multi-Channel Speech Coding and Enhancement
4.1. Simulation of Microphone Array Speech Signals
4.2. Application in Multi-Channel Speech Coding
4.3. Application in Multi-Channel Speech Enhancement
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Benesty, J.; Chen, J.; Huang, Y. Microphone Array Signal Processing; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Odeon Room Acoustics Software. Available online: http://www.odeon.dk (accessed on 21 February 2020).
- Enhanced Acoustics Simulator for Engineers (EASE). Available online: http://www.auralisation.de (accessed on 21 February 2020).
- Schimmel, S.M.; Muller, M.F.; Dillier, N. A fast and accurate “shoebox” room acoustics simulator. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 241–244. [Google Scholar]
- Wabnitz, A.; Epain, N.; Jin, C.T.; van Schaik, A. Room acoustics simulation for multichannel microphone arrays. In Proceedings of the 2010 International Symposium on Room Acoustics, Melbourne, Australia, 29–31 August 2010; pp. 1–6. [Google Scholar]
- Nielsen, J.K.; Jensen, J.R.; Jensen, S.H.; Christensen, M.G. The single- and multichannel audio recordings database (SMARD). In Proceedings of the 2014 14th International Workshop on Acoustic Signal. Enhancement (IWAENC), Juan-les-Pins, France, 8–11 September 2014; pp. 40–44. [Google Scholar]
- Scheibler, R.; Bezzam, E.; Dokmanic, I. Pyroomacoustics: A Python Package for Audio Room Simulation and Array Processing Algorithms. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 351–355. [Google Scholar]
- Thieman, J.; Ito, N.; Vincent, E. The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings. J. Acoust. Soc. Am. 2013, 133, 3591. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, X.; Yan, N.; Wang, L.; Zhu, Y.; Chen, H. A multi-channel/multi-speaker articulatory database in Mandarin for speech visualization. In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, Singapore, 12–14 September 2014; pp. 299–303. [Google Scholar]
- Hadad, E.; Heese, F.; Vary, P.; Gannot, S. Multichannel audio database in various acoustic environments. In Proceedings of the 2014 14th International Workshop on Acoustic Signal Enhancement (IWAENC), Juan-les-Pins, France, 8–11 September 2014; pp. 313–317. [Google Scholar]
- Suh, Y.; Kim, Y.; Lim, H.; Goo, J.; Jung, Y.; Choi, Y.; Kim, H.; Choi, D.-L.; Lee, Y. Development of distant multi-channel speech and noise databases for speech recognition by in-door conversational robots. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Korea, 1–3 November 2017; pp. 1–4. [Google Scholar]
- Tang, Z.; Chen, L.; Wu, B.; Yu, D.; Manocha, D. Improving reverberant Speech Training Using Diffuse Acoustic Simulation. Available online: https://arxiv.org/abs/1907.03988v4 (accessed on 10 February 2020).
- Drude, L.; Heitkaemper, J.; Boeddeker, C.; Haeb-Umbach, R. SMS-WSJ: Database, Performance Measures, and Baseline Recipe for Multi-Channel Source Separation and Recognition. Available online: https://arxiv.org/abs/1910.13934 (accessed on 30 October 2019).
- Chen, Z.; Yoshioka, Y.; Lu, L.; Zhou, T.; Meng, Z.; Luo, Y.; Wu, J.; Li, J. Continuous Speech Separation: Dataset and Analysis. Available online: https://arxiv.org/abs/2001.11482 (accessed on 30 January 2020).
- Sabine, W.C.; Egan, M.D. Collected Papers on Acoustics. J. Acoust. Soc. Am. 1994, 95, 3679–3680. [Google Scholar] [CrossRef] [Green Version]
- Habets, E.A.P.; Cohen, I.; Gannot, S. Generating nonstationary multisensor signals under a spatial coherence constraint. J. Acoust. Soc. Am. 2008, 124, 2911–2917. [Google Scholar] [CrossRef] [PubMed]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT Acoustic-Phonetic Continous Speech Corpus CD-ROM. NIST Speech disc 1-1.1; NASA STI/Recon Technical Report N 93, 27403; NASA: Washington, DC, USA, 1993.
- Gannot, S.; Vincent, E.; Markovich-Golan, S.; Ozerov, A. A Consolidated Perspective on Multimicrophone Speech Enhancement and Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 692–730. [Google Scholar] [CrossRef] [Green Version]
- Chakrabarty, S.; Wang, D.; Habets, E.A.P. Time-Frequency Masking Based Online Speech Enhancement with Multi-Channel Data Using Convolutional Neural Networks. In Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 476–480. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- 3GPP TS 26.445. Codec for Enhanced Voice Services (EVS); Detailed Algorithmic Description. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=1467 (accessed on 14 June 2019).
- 3GPP TS 26.071. Mandatory Speech CODEC Speech Processing Functions; AMR Speech Codec; General Description. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=1386 (accessed on 22 June 2018).
- 3GPP TS 26.171. Speech Codec Speech Processing Functions; Adaptive Multi-Rate -Wideband (AMR-WB) Speech Codec; General Description. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=1420 (accessed on 22 June 2018).
- Dietz, M.; Multrus, M.; Eksler, V.; Malenovsky, V.; Norvell, E.; Pobloth, H.; Miao, L.; Wang, Z.; Laaksonen, L.; Vasilache, A.; et al. Overview of the EVS codec architecture. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 5698–5702. [Google Scholar]
- Chen, J.; Benesty, J.; Huang, Y. Robust time delay estimation exploiting redundancy among multiple microphones. IEEE Trans. Speech Audio Process. 2003, 11, 549–557. [Google Scholar] [CrossRef]
- Hansen, J.H.L.; Pellom, B.L. An Effective Quality Evaluation Protocol For Speech Enhancement Algorithms. In Proceedings of the 5th International Conference on Spoken Language Processing, Sydney, Australia, 30 November–4 December 1998; pp. 2819–2822. [Google Scholar]
- Abramson, A.; Cohen, I. Simultaneous Detection and Estimation Approach for Speech Enhancement. IEEE Trans. Speech Audio Process. 2007, 15, 2348–2359. [Google Scholar] [CrossRef]
- Nakatani, T.; Yoshioka, T.; Kinoshita, K.; Miyoshi, M.; Juang, B.-H. Speech Dereverberation Based on Variance-Normalized Delayed Linear Prediction. IEEE Trans. Speech Audio Process. 2010, 18, 1717–1731. [Google Scholar] [CrossRef]
- Higuchi, T.; Ito, N.; Yoshioka, T.; Nakatani, T. Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5210–5214. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs | Outputs |
|---|---|
| room size source location microphone array location signal-to-noise ratio (SNR) absorption factor clean speech (for target speech source) noise signal (for diffuse noise) | microphone array clean speech microphone array clean speech with reverberation microphone array noisy speech microphone array noisy speech with reverberation microphone array noise signals |
| Theoretical TDOA | Simulated TDOA |
|---|---|
| 1.3113 samples | about 1.3 samples |
| SNR [dB] | RT60 [ms] | CNN_SMARD | CNN_MCS | CNN_MASS | |||
|---|---|---|---|---|---|---|---|
| ΔP | ΔS | ΔP | ΔS | ΔP | ΔS | ||
| -5 | 700 | 0.4289 | 0.2951 | 0.4345 | 0.3021 | 0.4502 | 0.3101 |
| 500 | 0.6621 | 0.2706 | 0.6598 | 0.2989 | 0.6789 | 0.3012 | |
| 300 | 0.7731 | 0.3151 | 0.7902 | 0.3201 | 0.8067 | 0.3395 | |
| 0 | 700 | 0.5645 | 0.1892 | 0.5762 | 0.1803 | 0.5801 | 0.1992 |
| 500 | 0.6587 | 0.2041 | 0.6412 | 0.2154 | 0.6621 | 0.2201 | |
| 300 | 0.6598 | 0.2263 | 0.6701 | 0.2312 | 0.6689 | 0.2298 | |
| 5 | 700 | 0.3678 | 0.1499 | 0.3562 | 0.1428 | 0.3609 | 0.1501 |
| 500 | 0.4726 | 0.1275 | 0.4893 | 0.1364 | 0.5011 | 0.1468 | |
| 300 | 0.4987 | 0.1345 | 0.5098 | 0.1452 | 0.5126 | 0.1402 | |
| 10 | 700 | 0.3251 | 0.0924 | 0.3178 | 0.0951 | 0.3365 | 0.0899 |
| 500 | 0.4482 | 0.0898 | 0.4557 | 0.0942 | 0.4406 | 0.1021 | |
| 300 | 0.5041 | 0.1092 | 0.5189 | 0.1125 | 0.5208 | 0.1198 | |
| Application | Multi-Channel Speech Coding | Multi-Channel Speech Enhancement |
|---|---|---|
| Input | Clean speech | Noisy speech Clean speech with reverberation Noisy speech with reverberation |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, R.; Bao, C.; Cui, Z. MASS: Microphone Array Speech Simulator in Room Acoustic Environment for Multi-Channel Speech Coding and Enhancement. Appl. Sci. 2020, 10, 1484. https://doi.org/10.3390/app10041484
Cheng R, Bao C, Cui Z. MASS: Microphone Array Speech Simulator in Room Acoustic Environment for Multi-Channel Speech Coding and Enhancement. Applied Sciences. 2020; 10(4):1484. https://doi.org/10.3390/app10041484
Chicago/Turabian StyleCheng, Rui, Changchun Bao, and Zihao Cui. 2020. "MASS: Microphone Array Speech Simulator in Room Acoustic Environment for Multi-Channel Speech Coding and Enhancement" Applied Sciences 10, no. 4: 1484. https://doi.org/10.3390/app10041484