6D Pose Estimation of Objects: Recent Technologies and Challenges




Abstract
:1. Introduction
1.1. Overview
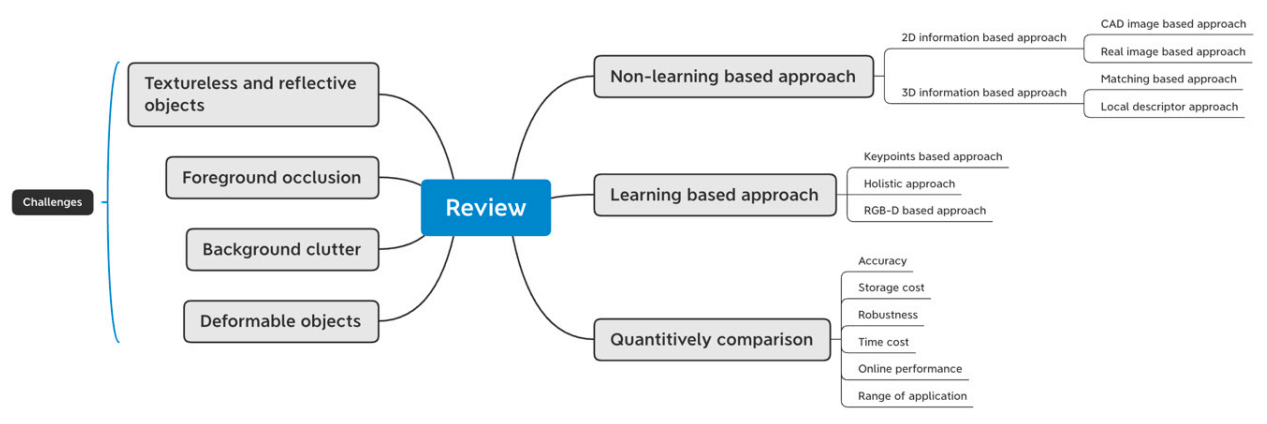
1.2. Classification
1.3. Challenge
1.4. Structure Layout
2. Learning-Based Approaches
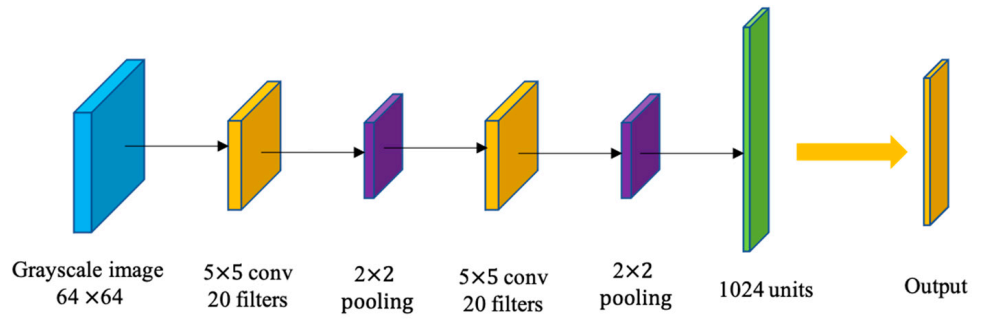
2.1. Keypoint-Based Approaches
2.2. Holistic Approaches
2.3. RGB-D-Based Appraoches
2.4. Conclusions
3. Non-Learning-Based Approaches
3.1. 2D-Information-Based Approaches
3.1.1. CAD Image-Based Approaches
3.1.2. Real Image-Based Approaches
3.1.3. Conclusions
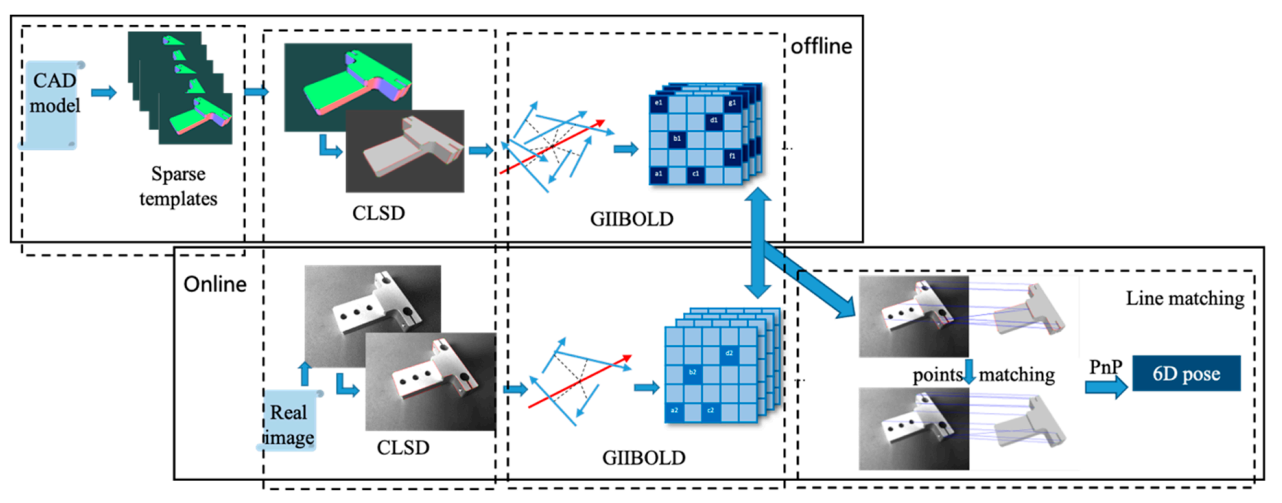
3.2. 3D-Information-Based Approaches
3.2.1. Matching-Based Approaches
3.2.2. Local Descriptor Approaches
3.2.3. Conclusions
4. Comparison
5. Challenges
5.1. Textureless and Reflective Objects
5.2. Foreground Occlusion
5.3. Background Clutter
5.4. Deformable Objects
5.5. Conclusions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Drummond, T.; Cipolla, R. Real-time visual tracking of complex structures. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 932–946. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Zhao, Y.; Qu, S.; Zhang, Y.; Weng, F. Real Time and Robust 6D Pose Estimation of RGBD Data for Robotic Bin Picking. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5283–5288. [Google Scholar]
- Yan, W.; Xu, Z.; Zhou, X.; Su, Q.; Li, S.; Wu, H. Fast Object Pose Estimation Using Adaptive Threshold for Bin-Picking. IEEE Access 2020, 8, 63055–63064. [Google Scholar] [CrossRef]
- Xu, J.; Pu, S.; Zeng, G.; Zha, H. 3D pose estimation for bin-picking task using convex hull. In Proceedings of the 2012 IEEE International Conference on Mechatronics and Automation, Chengdu, China, 5–8 August 2012; pp. 1381–1385. [Google Scholar]
- Buchholz, D. Bin-Picking: New Approaches for a Classical Problem; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Yang, J.; Zeng, G.; Wang, W.; Zuo, Y.; Yang, B.; Zhang, Y. Vehicle Pose Estimation Based on Edge Distance Using Lidar Point Clouds (Poster). In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–6. [Google Scholar]
- Gu, R.; Wang, G.; Hwang, J. Efficient Multi-person Hierarchical 3D Pose Estimation for Autonomous Driving. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 163–168. [Google Scholar]
- Kothari, N.; Gupta, M.; Vachhani, L.; Arya, H. Pose estimation for an autonomous vehicle using monocular vision. In Proceedings of the 2017 Indian Control Conference (ICC), Guwahati, India, 4–6 January 2017; pp. 424–431. [Google Scholar]
- Zhang, S.; Song, C.; Radkowski, R. Setforge-Synthetic RGB-D Training Data Generation to Support CNN-Based Pose Estimation for Augmented Reality. In Proceedings of the 2019 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Beijing, China, 10–18 October 2019; pp. 237–242. [Google Scholar]
- Lu, Y.; Kourian, S.; Salvaggio, C.; Xu, C.; Lu, G. Single Image 3D Vehicle Pose Estimation for Augmented Reality. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019; pp. 1–5. [Google Scholar]
- Hachiuma, R.; Saito, H. Recognition and pose estimation of primitive shapes from depth images for spatial augmented reality. In Proceedings of the 2016 IEEE 2nd Workshop on Everyday Virtual Reality (WEVR), Greenville, SC, USA, 20–20 March 2016; pp. 32–35. [Google Scholar]
- Li, X.; Ling, H. Hybrid Camera Pose Estimation with Online Partitioning for SLAM. IEEE Robot. Autom. Lett. 2020, 5, 1453–1460. [Google Scholar] [CrossRef]
- Ruan, X.; Wang, F.; Huang, J. Relative Pose Estimation of Visual SLAM Based on Convolutional Neural Networks. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8827–8832. [Google Scholar]
- Xiao, Z.; Wang, X.; Wang, J.; Wu, Z. Monocular ORB SLAM based on initialization by marker pose estimation. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macau, China, 18–20 July 2017; pp. 678–682. [Google Scholar]
- Malyavej, V.; Torteeka, P.; Wongkharn, S.; Wiangtong, T. Pose estimation of unmanned ground vehicle based on dead-reckoning/GPS sensor fusion by unscented Kalman filter. In Proceedings of the 2009 6th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Pattaya, Thailand, 6–9 May 2009; pp. 395–398. [Google Scholar]
- Zhaoyang, N.; Jianyun, Z.; Zhidong, Z. Angle Estimation for Bi-static MIMO Radar Based on Tri-iterative Algorithm. In Proceedings of the 2010 First International Conference on Pervasive Computing, Signal Processing and Applications, Harbin, China, 17–19 September 2010; pp. 1264–1267. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Crivellaro, A.; Rad, M.; Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. A Novel Representation of Parts for Accurate 3D Object Detection and Tracking in Monocular Images. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4391–4399. [Google Scholar]
- Zabulis, X.; Lourakis, M.; Koutlemanis, P. 3D Object Pose Refinement in Range Images. In International conference on Computer Vision Systems; Springer: Cham, Switzerland, 2015; pp. 263–274. [Google Scholar]
- Zabulis, X.; Lourakis, M.I.; Koutlemanis, P. Correspondence-free pose estimation for 3D objects from noisy depth data. Vis. Comput. 2018, 34, 193–211. [Google Scholar] [CrossRef]
- Hoang, D.; Stoyanov, T.; Lilienthal, A.J. Object-RPE: Dense 3D Reconstruction and Pose Estimation with Convolutional Neural Networks for Warehouse Robots. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–6. [Google Scholar]
- Hoang, D.-C.; Stoyanov, T.; Lilienthal, A. High-Quality Instance-Aware Semantic 3D Map Using RGB-D Camera. arXiv 2019, arXiv:1903.10782. [Google Scholar]
- Wen, Y.; Pan, H.; Yang, L.; Wang, W. Edge Enhanced Implicit Orientation Learning With Geometric Prior for 6D Pose Estimation. IEEE Robot. Autom. Lett. 2020, 5, 4931–4938. [Google Scholar] [CrossRef]
- Pitteri, G.; Ramamonjisoa, M.; Ilic, S.; Lepetit, V. On Object Symmetries and 6D Pose Estimation from Images. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 614–622. [Google Scholar]
- Manhardt, F.; Arroyo, D.M.; Rupprecht, C.; Busam, B.; Birdal, T.; Navab, N.; Tombari, F. Explaining the Ambiguity of Object Detection and 6D Pose From Visual Data. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6840–6849. [Google Scholar]
- Zhang, W.; Chenkun, Q.I. Pose Estimation by Key Points Registration in Point Cloud. In Proceedings of the 2019 3rd International Symposium on Autonomous Systems (ISAS), Shanghai, China, 29–31 May 2019; pp. 65–68. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 292–301. [Google Scholar]
- Li, Z.; Wang, G.; Ji, X. CDPN: Coordinates-Based Disentangled Pose Network for Real-Time RGB-Based 6-DoF Object Pose Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7677–7686. [Google Scholar]
- Oberweger, M.; Rad, M.; Lepetit, V. Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3848–3856. [Google Scholar]
- Hu, Y.; Hugonot, J.; Fua, P.; Salzmann, M. Segmentation-Driven 6D Object Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3380–3389. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Bao, H.; Zhou, X. PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Jeon, M.H.; Kim, A. PrimA6D: Rotational Primitive Reconstruction for Enhanced and Robust 6D Pose Estimation. IEEE Robot. Autom. Lett. 2020, 5, 4955–4962. [Google Scholar] [CrossRef]
- Hu, Y.; Fua, P.; Wang, W.; Salzmann, M. Single-Stage 6D Object Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2927–2936. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. Educ. Inf. 2015, 31, 2938–2946. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-based 3D detection and 6D pose estimation great again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Do, T.-T.; Cai, M.; Pham, T.; Reid, I. Deep-6DPose: Recovering 6D Object Pose from a Single RGB Image. arXiv 2018, arXiv:1802.10367. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3338–3347. [Google Scholar]
- Chen, W.; Jia, X.; Chang, H.J.; Duan, J.; Leonardis, A. G2L-Net: Global to Local Network for Real-Time 6D Pose Estimation With Embedding Vector Features. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4232–4241. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. PVN3D: A Deep Point-Wise 3D Keypoints Voting Network for 6DoF Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11629–11638. [Google Scholar]
- Labbé, Y.; Carpentier, J.; Aubry, M.; Sivic, J. CosyPose: Consistent Multi-view Multi-object 6D Pose Estimation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 574–591. [Google Scholar]
- Correll, N.; Bekris, K.E.; Berenson, D.; Brock, O.; Causo, A.; Hauser, K.; Okada, K.; Rodriguez, A.; Romano, J.M.; Wurman, P.R. Analysis and Observations From the First Amazon Picking Challenge. IEEE Trans. Autom. Sci. Eng. 2018, 15, 172–188. [Google Scholar] [CrossRef]
- Jonschkowski, R.; Eppner, C.; Höfer, S.; Martín-Martín, R.; Brock, O. Probabilistic multi-class segmentation for the Amazon Picking Challenge. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 1–7. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, Z.; Zhang, H.; Wei, Q. Vision-Based Pose Estimation for Textureless Space Objects by Contour Points Matching. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2342–2355. [Google Scholar] [CrossRef]
- Miyake, E.; Takubo, T.; Ueno, A. 3D Pose Estimation for the Object with Knowing Color Symbol by Using Correspondence Grouping Algorithm. In Proceedings of the 2020 IEEE/SICE International Symposium on System Integration (SII), Honolulu, HI, USA, 12–15 January 2020; pp. 960–965. [Google Scholar]
- Ulrich, M.; Wiedemann, C.; Steger, C. Combining Scale-Space and Similarity-Based Aspect Graphs for Fast 3D Object Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1902–1914. [Google Scholar] [CrossRef]
- Steger, C. Occlusion, clutter, and illumination invariant object recognition. Int. Arch. Photogramm. Remote Sens. 2003, 34, 345–350. [Google Scholar]
- Konishi, Y.; Hanzawa, Y.; Kawade, M.; Hashimoto, M. Fast 6D Pose Estimation from a Monocular Image Using Hierarchical Pose Trees. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 398–413. [Google Scholar]
- Muñoz, E.; Konishi, Y.; Murino, V.; Bue, A.D. Fast 6D pose estimation for texture-less objects from a single RGB image. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5623–5630. [Google Scholar]
- Khosla, A.; Torralba, A.; Lim, J. FPM: Fine Pose Parts-Based Model with 3D CAD Models. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef] [Green Version]
- Pei, L.; Liu, K.; Zou, D.; Li, T.; Wu, Q.; Zhu, Y.; Li, Y.; He, Z.; Chen, Y.; Sartori, D. IVPR: An Instant Visual Place Recognition Approach Based on Structural Lines in Manhattan World. IEEE Trans. Instrum. Meas. 2020, 69, 4173–4187. [Google Scholar] [CrossRef]
- Peng, J.; Xu, W.; Liang, B.; Wu, A. Virtual Stereovision Pose Measurement of Noncooperative Space Targets for a Dual-Arm Space Robot. IEEE Trans. Instrum. Meas. 2020, 69, 76–88. [Google Scholar] [CrossRef]
- Chaumette, F.; Hutchinson, S. Visual servo control. II. Advanced approaches [Tutorial]. IEEE Robot. Autom. Mag. 2007, 14, 109–118. [Google Scholar] [CrossRef]
- Comport, A.I.; Marchand, E.; Pressigout, M.; Chaumette, F. Real-time markerless tracking for augmented reality: The virtual visual servoing framework. IEEE Trans. Vis. Comput. Graph. 2006, 12, 615–628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kratochvil, B.E.; Dong, L.; Nelson, B.J. Real-time rigid-body visual tracking in a scanning electron microscope. In Proceedings of the 2007 7th IEEE Conference on Nanotechnology (IEEE NANO), Hong Kong, China, 2–5 August 2007; pp. 442–447. [Google Scholar] [CrossRef] [Green Version]
- Yesin, K.B. A CAD model based tracking for visually guided three-dimensional microassembly. Robotica 2005, 23, 409–418. [Google Scholar] [CrossRef]
- Muñoz, E.; Konishi, Y.; Beltran, C.; Murino, V.; Bue, A.D. Fast 6D pose from a single RGB image using Cascaded Forests Templates. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4062–4069. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 881, pp. 886–893. [Google Scholar]
- Guo, J.; Wu, P.; Wang, W. A precision pose measurement technique based on multi-cooperative logo. J. Phys. Conf. Ser. 2020, 1607, 012047. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Wang, H.; Yi, L.; Guibas, L.J.; Abbott, A.L.; Song, S. Category-Level Articulated Object Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3703–3712. [Google Scholar]
- Wang, K.; Xie, J.; Zhang, G.; Liu, L.; Yang, J. Sequential 3D Human Pose and Shape Estimation From Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7273–7282. [Google Scholar]
- Zhang, Z.; Hu, L.; Deng, X.; Xia, S. Weakly Supervised Adversarial Learning for 3D Human Pose Estimation from Point Clouds. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1851–1859. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, C.; Rosenberger, M.; Notni, G. 6D Object Pose Estimation Algorithm Using Preprocessing of Segmentation and Keypoint Extraction. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Konishi, Y.; Hattori, K.; Hashimoto, M. Real-Time 6D Object Pose Estimation on CPU. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 3451–3458. [Google Scholar]
- Park, K.; Patten, T.; Prankl, J.; Vincze, M. Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7207–7213. [Google Scholar]
- Tamadazte, B.; Marchand, E.; Dembélé, S.; Le Fort-Piat, N. CAD Model-based Tracking and 3D Visual-based Control for MEMS Microassembly. Int. J. Robot. Res. 2010, 29, 1416–1434. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Guo, Z.; Chai, Z.; Liu, C.; Xiong, Z. A Fast Global Method Combined with Local Features for 6D Object Pose Estimation. In Proceedings of the 2019 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hong Kong, China, 8–12 July 2019; pp. 1–6. [Google Scholar]
- Akizuki, S.; Aoki, Y. Pose alignment for different objects using affordance cues. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–3. [Google Scholar]
- Yu, H.; Fu, Q.; Yang, Z.; Tan, L.; Sun, W.; Sun, M. Robust Robot Pose Estimation for Challenging Scenes With an RGB-D Camera. IEEE Sens. J. 2019, 19, 2217–2229. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary robust independent elementary features. In Proceedings of the Proceedings of the 11th European Conference on Computer Vision: Part IV, Heraklion, Crete, Greece, 22 December 2011; pp. 778–792. [Google Scholar]
- Nospes, D.; Safronov, K.; Gillet, S.; Brillowski, K.; Zimmermann, U.E. Recognition and 6D Pose Estimation of Large-scale Objects using 3D Semi-Global Descriptors. In Proceedings of the 2019 16th International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019. [Google Scholar]
- Zhang, H.; Cao, Q. Texture-less object detection and 6D pose estimation in RGB-D images. Robot. Auton. Syst. 2017, 95, 64–79. [Google Scholar] [CrossRef]
- Pan, W.; Zhu, F.; Hao, Y.; Zhang, L. Fast and precise 6D pose estimation of textureless objects using the point cloud and gray image. Appl. Opt. 2018, 57, 8154–8165. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Jiang, Z.; Zhao, X.; Zhang, S.; Wu, C. Sparse Template-Based 6-D Pose Estimation of Metal Parts Using a Monocular Camera. IEEE Trans. Ind. Electron. 2020, 67, 390–401. [Google Scholar] [CrossRef]
- Zhang, H.; Cao, Q. Detect in RGB, Optimize in Edge: Accurate 6D Pose Estimation for Texture-less Industrial Parts. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3486–3492. [Google Scholar]
- Pan, W.; Zhu, F.; Hao, Y.; Zhang, L. 6D Pose Estimation Based on Multiple Appearance Features from Single Color Image. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017; pp. 406–411. [Google Scholar]
- Dong, Z.; Liu, S.; Zhou, T.; Cheng, H.; Zeng, L.; Yu, X.; Liu, H. PPR-Net:Point-wise Pose Regression Network for Instance Segmentation and 6D Pose Estimation in Bin-picking Scenarios. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1773–1780. [Google Scholar]
- Chen, W.; Duan, J.; Basevi, H.; Chang, H.J.; Leonardis, A. PointPoseNet: Point Pose Network for Robust 6D Object Pose Estimation. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2813–2822. [Google Scholar]
- Cao, Q.; Zhang, H. Combined Holistic and Local Patches for Recovering 6D Object Pose. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2219–2227. [Google Scholar]
- Li, W.; Sun, J.; Luo, Y.; Wang, P. 6D Object Pose Estimation using Few-Shot Instance Segmentation and 3D Matching. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 1071–1077. [Google Scholar]
- Chen, X.; Chen, Y.; You, B.; Xie, J.; Najjaran, H. Detecting 6D Poses of Target Objects From Cluttered Scenes by Learning to Align the Point Cloud Patches with the CAD Models. IEEE Access 2020, 8, 210640–210650. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.; Allen, P.K. Recognition of deformable object category and pose. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5558–5564. [Google Scholar]
- Li, Y.; Wang, Y.; Yue, Y.; Xu, D.; Case, M.; Chang, S.; Grinspun, E.; Allen, P.K. Model-Driven Feedforward Prediction for Manipulation of Deformable Objects. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1621–1638. [Google Scholar] [CrossRef]
- Caporali, A.; Palli, G. Pointcloud-based Identification of Optimal Grasping Poses for Cloth-like Deformable Objects. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; pp. 581–586. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Storage Cost | Robustness | Time Cost | Online Performance | Range of Application | ||
|---|---|---|---|---|---|---|---|
| Learning-based approaches | Keypoint-based approaches | B | B | B | C | C | B |
| Holistic approaches | C | B | B | B | B | B | |
| RGB-D-based approaches | A | C | A | C | C | C | |
| Non-learning-based approaches | 2D-information-based approaches | B | A | C | A | A | A |
| 3D-information-based approaches | A | B | B | B | B | C | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Feng, W.; Zhao, X.; Lv, Y. 6D Pose Estimation of Objects: Recent Technologies and Challenges. Appl. Sci. 2021, 11, 228. https://doi.org/10.3390/app11010228
He Z, Feng W, Zhao X, Lv Y. 6D Pose Estimation of Objects: Recent Technologies and Challenges. Applied Sciences. 2021; 11(1):228. https://doi.org/10.3390/app11010228
Chicago/Turabian StyleHe, Zaixing, Wuxi Feng, Xinyue Zhao, and Yongfeng Lv. 2021. "6D Pose Estimation of Objects: Recent Technologies and Challenges" Applied Sciences 11, no. 1: 228. https://doi.org/10.3390/app11010228
APA StyleHe, Z., Feng, W., Zhao, X., & Lv, Y. (2021). 6D Pose Estimation of Objects: Recent Technologies and Challenges. Applied Sciences, 11(1), 228. https://doi.org/10.3390/app11010228