
Named Entity Correction in Neural Machine Translation Using the Attention Alignment Map



Abstract
:Featured Application
Abstract
1. Introduction
2. Machine Translation
2.1. Neural Machine Translation
2.2. Conventional Named Entity Recognition
3. Proposed Method
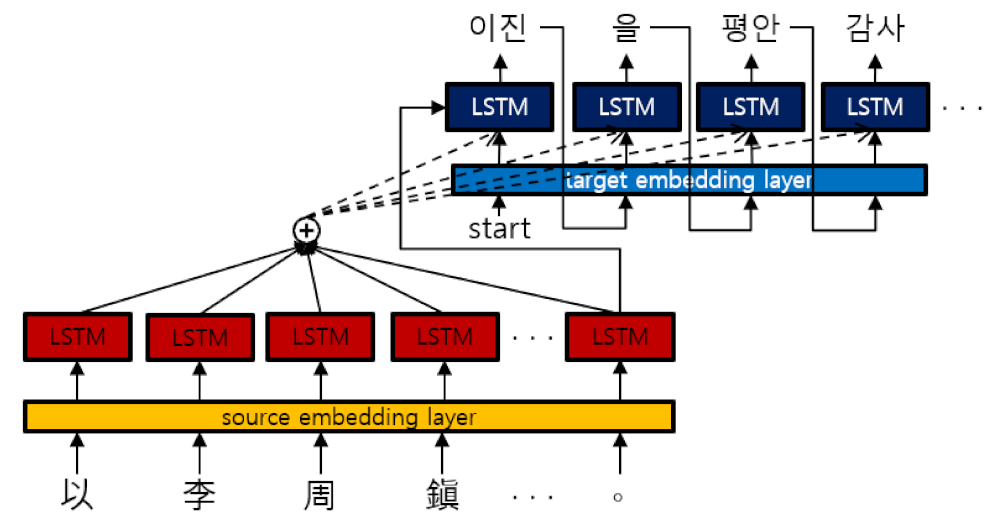
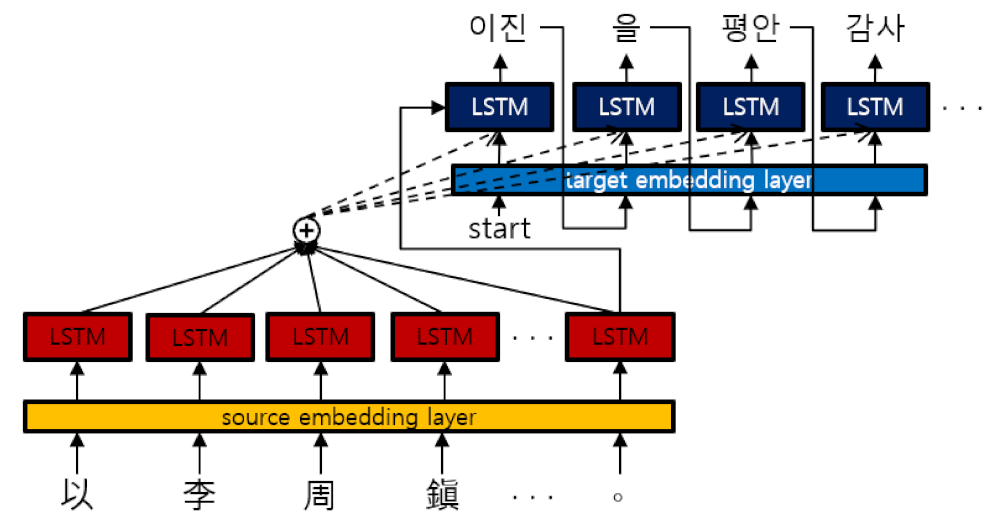
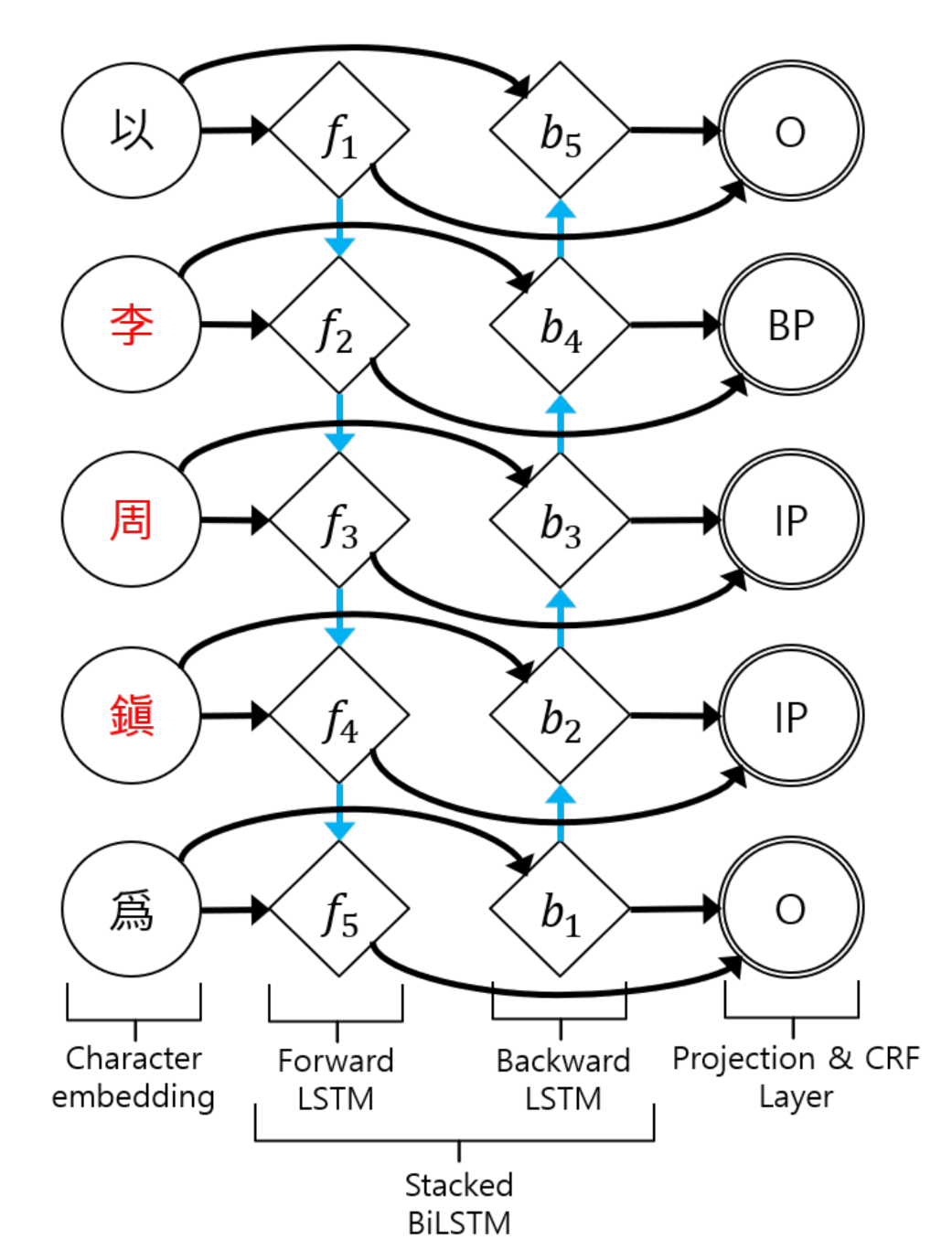
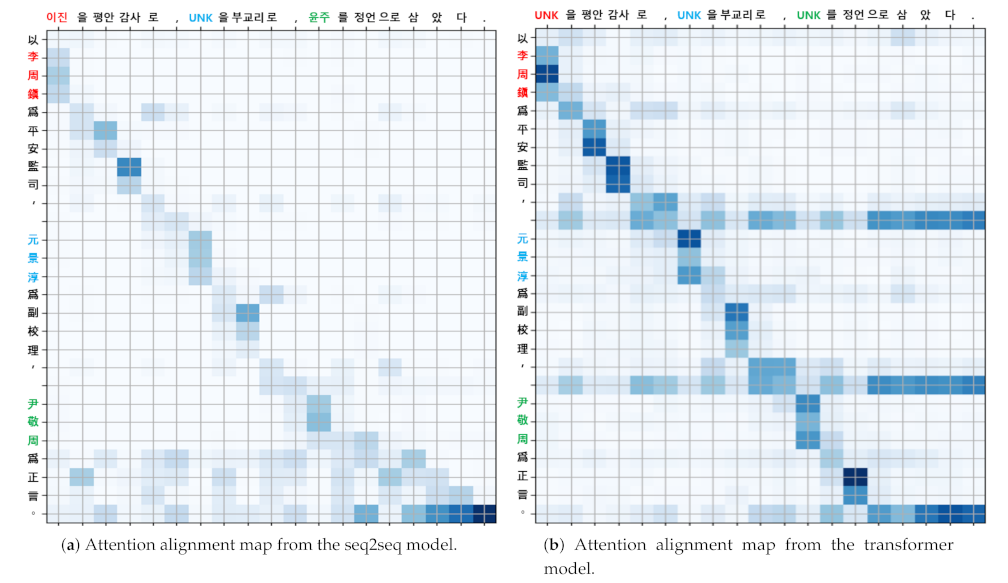
3.1. AAM in Sequence-to-Sequence Models
3.2. Transformer
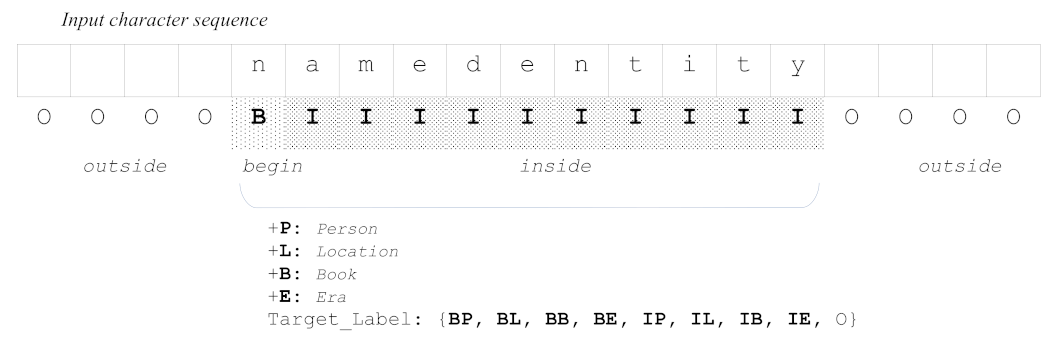
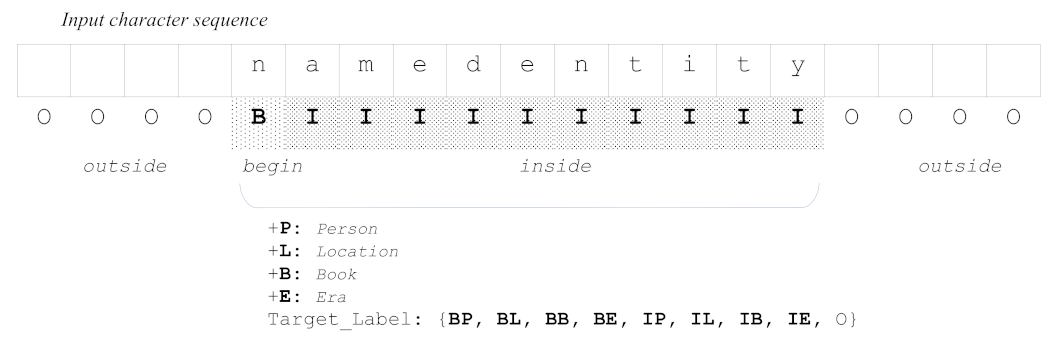
3.3. NER Model
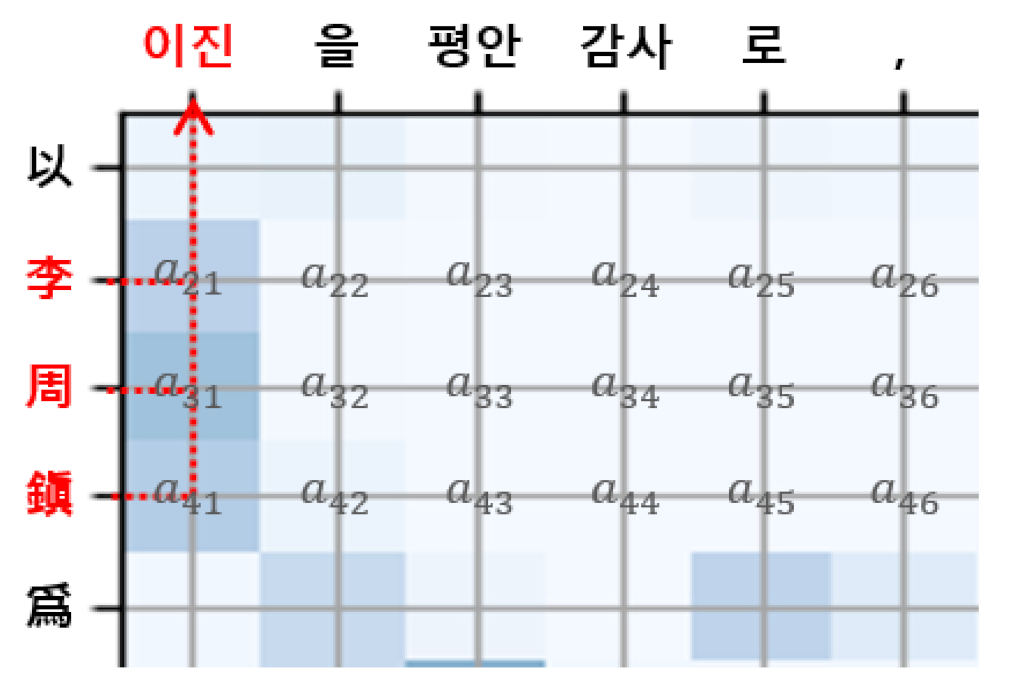
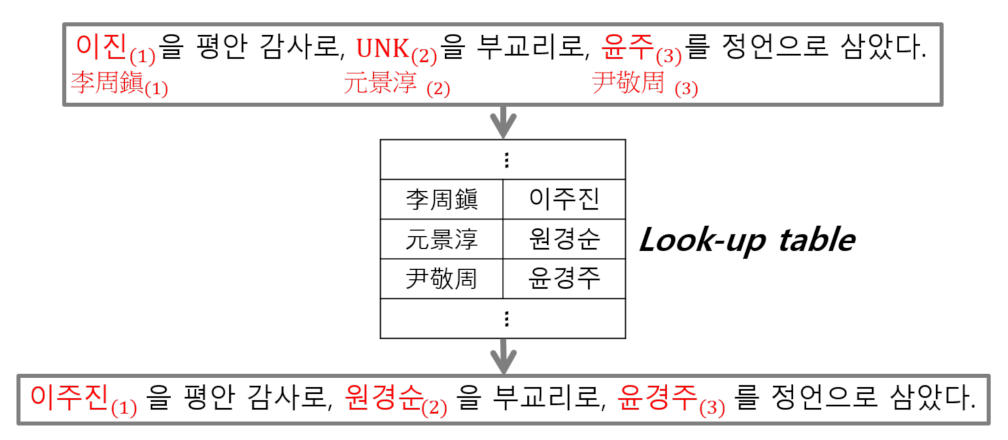
3.4. Named Entity Correction with AAM
4. Experiments
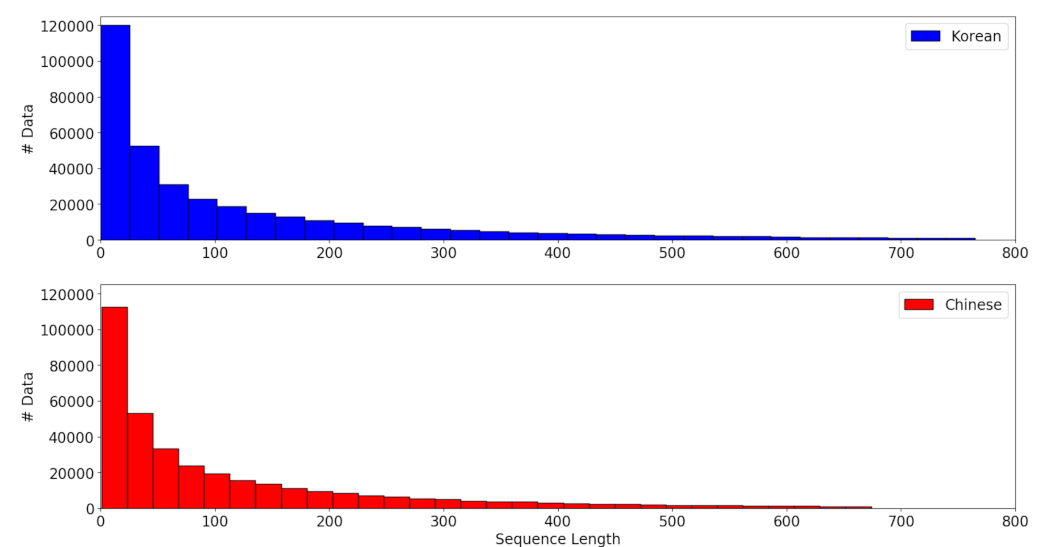
4.1. Dataset: The Annals of the Joseon Dynasty
4.2. Models
4.3. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NMT | Neural machine translation |
| NER | Named entity recognition |
| OOV | Out of vocabulary |
| RNN | Recurrent neural network |
| LSTM | Long short-term memory |
| BLSTM | Bi-directional long short-term memory |
| GRU | Gated recurrent unit |
| AAM | Attention alignment map |
References
- Koehn, P.; Och, F.J.; Marcu, D. Statistical Phrase-based Translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology—Volume 1; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 48–54. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chiang, D. A Hierarchical Phrase-based Model for Statistical Machine Translation. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 263–270. [Google Scholar] [CrossRef]
- Chen, K.; Zhao, T.; Yang, M.; Liu, L.; Tamura, A.; Wang, R.; Utiyama, M.; Sumita, E. A Neural Approach to Source Dependence Based Context Model for Statistical Machine Translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 266–280. [Google Scholar] [CrossRef]
- Wang, X.; Tu, Z.; Zhang, M. Incorporating Statistical Machine Translation Word Knowledge Into Neural Machine Translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2255–2266. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent Continuous Translation Models. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Seattle, WA, USA, 2013; pp. 1700–1709. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Li, S.; Zhao, J.; Shi, G.; Tan, Y.; Xu, H.; Chen, G.; Lan, H.; Lin, Z. Chinese Grammatical Error Correction Based on Convolutional Sequence to Sequence Model. IEEE Access 2019, 7, 72905–72913. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, F.; Zhang, Y.; Liu, C.; Bengio, Y. Drawing and Recognizing Chinese Characters with Recurrent Neural Network. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 849–862. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Luong, M.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Xu, Y.; Liu, W.; Chen, G.; Ren, B.; Zhang, S.; Gao, S.; Guo, J. Enhancing Machine Reading Comprehension With Position Information. IEEE Access 2019, 7, 141602–141611. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Seljan, S.; Dunđer, I.; Pavlovski, M. Human Quality Evaluation of Machine-Translated Poetry. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 18 May 2020. [Google Scholar] [CrossRef]
- Dunđer, I.; Seljan, S.; Pavlovski, M. Automatic machine translation of poetry and a low-resource language pair. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020. [Google Scholar] [CrossRef]
- Dunđer, I. Machine Translation System for the Industry Domain and Croatian Language. J. Inf. Organ. Sci. 2020, 44, 33–50. [Google Scholar] [CrossRef]
- Brkić, M.; Seljan, S.; Vičić, T. Automatic and Human Evaluation on English-Croatian Legislative Test Set. Lect. Notes Comput. Sci. LNCS 2013, 7817, 311–317. [Google Scholar] [CrossRef]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer Learning for Low-Resource Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1568–1575. [Google Scholar] [CrossRef]
- Yang, Z.; Cheng, Y.; Liu, Y.; Sun, M. Reducing Word Omission Errors in Neural Machine Translation: A Contrastive Learning Approach. In Proceedings of the 57th Annual Meeting on Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 6191–6196. [Google Scholar] [CrossRef]
- Tan, Z.; Wang, S.; Yang, Z.; Chen, G.; Huang, X.; Sun, M.; Liu, Y. Neural machine translation: A review of methods, resources, and tools. AI Open 2020, 1, 5–21. [Google Scholar] [CrossRef]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On Using Very Large Target Vocabulary for Neural Machine Translation. arXiv 2014, arXiv:1412.2007. [Google Scholar]
- Luong, M.; Manning, C.D. Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models. arXiv 2016, arXiv:1604.00788. [Google Scholar]
- Luong, T.; Sutskever, I.; Le, Q.; Vinyals, O.; Zaremba, W. Addressing the Rare Word Problem in Neural Machine Translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 11–19. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting on Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Haddad, H.; Fadaei, H.; Faili, H. Handling OOV Words in NMT Using Unsupervised Bilingual Embedding. In Proceedings of the 2018 9th International Symposium on Telecommunications (IST), Tehran, Iran, 17–19 December 2018; pp. 569–574. [Google Scholar] [CrossRef]
- Ling, W.; Trancoso, I.; Dyer, C.; Black, A.W. Character-based Neural Machine Translation. arXiv 2015, arXiv:1511.04586. [Google Scholar]
- Costa-jussà, M.R.; Fonollosa, J.A.R. Character-based Neural Machine Translation. arXiv 2016, arXiv:1603.00810. [Google Scholar]
- Lee, J.; Cho, K.; Hofmann, T. Fully Character-Level Neural Machine Translation without Explicit Segmentation. Trans. Assoc. Comput. Linguist. 2017, 5, 365–378. [Google Scholar] [CrossRef] [Green Version]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T. Statistical Language Models Based on Neural Networks. Ph.D. Thesis, Brno University of Technology, Brno-střed, Czech Republic, 2012. [Google Scholar]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th International Conference on Machine Learning; ACM: New York, NY, USA, 2008; pp. 160–167. [Google Scholar] [CrossRef]
- Socher, R.; Lin, C.C.Y.; Ng, A.Y.; Manning, C.D. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. In Proceedings of the 28th International Conference on International Conference on Machine Learning; Omnipress: Washington, WA, USA, 2011; pp. 129–136. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain Adaptation for Large-scale Sentiment Classification: A Deep Learning Approach. In Proceedings of the 28th International Conference on International Conference on Machine Learning; Omnipress: Washington, WA, USA, 2011; pp. 513–520. [Google Scholar]
- Nut Limsopatham, N.C. Bidirectional LSTM for Named Entity Recognition in Twitter Messages. In Proceedings of the 2nd Workshop on Noisy User-Generated Text, Osaka, Japan, 11 December 2016; pp. 145–152. [Google Scholar] [CrossRef]
- Aguilar, G.; Maharjan, S.; López Monroy, A.P.; Solorio, T. A Multi-task Approach for Named Entity Recognition in Social Media Data. In Proceedings of the 3rd Workshop on Noisy User-Generated Text; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 148–153. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Schuster, M.; Paliwal, K. Bidirectional Recurrent Neural Networks. Trans. Sig. Proc. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification; ACL: Berlin, Germany, 2016. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar]
- Liao, Y.; Xiong, P.; Min, W.; Min, W.; Lu, J. Dynamic Sign Language Recognition Based on Video Sequence with BLSTM-3D Residual Networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 21–26 July 2016. [Google Scholar]
- Lei Ba, J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–289. [Google Scholar]
- Park, E.L.; Cho, S. KoNLPy: Korean natural language processing in Python. In Proceedings of the 26th Annual Conference on Human and Cognitive Language Technology, Chuncheon, Korea, 10 October 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A Theoretically Grounded Application of Dropout in Recurrent Neural Networks. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 1019–1027. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Derczynski, L.; Nichols, E.; van Erp, M.; Limsopatham, N. Results of the WNUT2017 Shared Task on Novel and Emerging Entity Recognition. In Proceedings of the 3rd Workshop on Noisy User-Generated Text; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 140–147. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | 以李周鎭爲平安監司, 元景淳爲副校理, 尹敬周爲正言 |
| Truth | 이주진을 평안 감사로, 원경순을 부교리로, 윤경주를 정언으로 삼았다. |
| English Translation | Lee Joo Jin is assigned as the Pyeongan inspector, |
| Won Kyung Soon as the vice dictator, Yun Gyeong Joo as the dictator. | |
| NMT output | 이진을 평안 감사로, UNK을 부교리로, 윤주를 정언으로 삼았다. |
| Input | 分遣暗行御史李允明, 金夢臣, 李宇謙等, 廉察諸道 |
| Truth | 암행어사 이윤명 · 김몽신 · 이우겸 등을 |
| 나누어 파견하여 여러 도를 검찰하게 하였다. | |
| English Translation | The secret royal inspectors Lee Yun Myeong, Kim Mong Shin, |
| and Lee Woo Gyeom were dispatched to investigate various provinces. | |
| NMT output | 암행어사 UNK·UNK·UNK 등을 |
| 나누어 보내어 두루 제도를 살피게 하였다. | |
| Input | 江原道 楊口縣民家九十九戶, 一時燒燼道臣以聞, 上命行恤典 |
| Truth | 강원도 양구현의 민가 99호가 한꺼번에 불타 없어졌는데, |
| 도신이 계문하니, 임금이 휼전을 시행하라고 명하였다. | |
| English Translation | 99 civil houses in Yanggu Gangwon province were burnt down all at once, |
| Do Shin requested the king to distribute food tickets to civilians. | |
| NMT output | 강원도 UNK민가 99호가 한꺼번에 불에타버렸다. |
| 도주가 아뢰니, 상이 휼전을 행하라고 명하였다. | |
| Input | 上詣永禧殿展謁, 仍詣儲慶宮, 毓祥宮, 延祜宮, 宣禧宮展拜 |
| Truth | 임금이 영희전에 나아가 전알하고, 이어서 |
| 저경궁·육상궁·연호궁·선희궁에 나아가 전배하였다. | |
| English Translation | The king went to Yeonghuijeon and perform a rites, and then to Jeogyeonggung, |
| Sokseonggung, Yeonhogung, and Seonhuigung and performed rites. | |
| NMT output | 임금이 영모전에 나아가서 전알하고, |
| 이어서 경복궁·UNK·UNK·경희전에 나아가 참배하였다. | |
| Input | 行召對, 講≪名臣奏議≫ |
| Truth | 소대를 행하고 ≪명신주의≫를 강론하였다. |
| English Translation | Conducted a So Dae and lectured on ≪Myungshinism≫. |
| NMT output | 소대를 행하고 ≪UNK≫를 강하였다. |
| Input | 江原道 楊口縣民家九十九戶, 一時燒燼 |
| Output | BL IL IL BL IL IL O O O O O O O O O O O O |
| Input | 道臣以聞, 上命行恤典 |
| Output | BP IP O O O O O O O O O |
| Input | 以李周鎭爲平安監司, 元景淳爲副校理, 尹敬周爲正言 |
| Output | 이진을 평안 감사로, UNK을 부교리로, 윤주를 정언으로 삼았다. |
| English | Lee Joo Jin is assigned as the Pyeongan inspector, Won Kyung Soon as the vice dictator, Yun Gyeong Joo as the dictator. |
| Input | 以李周鎭爲平安監司, 元景淳爲副校理, 尹敬周爲正言 |
| Output | 以李周鎭爲平安監司, 元景淳爲副校理, 尹敬周爲正言 |
| Input | 以李周鎭(1)爲平安監司, 元景淳(2)爲副校理, 尹敬周(3)爲正言 |
| Output | 이진(1)을 평안 감사로, UNK(2)을 부교리로, 윤주(3)를 정언으로 삼았다. |
| # total characters | 66M | ||
| # characters within the named entities | 5M | ||
| # types of named entities | 140K | ||
| Ratio of the named entity types | |||
| Person | Location | Book | Era |
| 73.3% | 24.0% | 2.4% | 0.3% |
| Model | Description | Vocab | Params | Original | Modified | |
|---|---|---|---|---|---|---|
| Seq2seq | (500, 512, 3, 1024, 2) | 40K | 58M | 35.75 | 39.29 | +3.54 |
| Seq2seq | (500, 512, 3, 1024, 2) | 42K | 59M | 35.83 | 39.53 | +3.70 |
| Seq2seq | (500, 512, 3, 1024, 2) | 50K | 63M | 35.66 | 39.13 | +3.47 |
| Seq2seq | (500, 512, 3, 1024, 2) | 87K | 81M | 35.29 | 37.89 | +2.60 |
| Seq2seq-Reduced | (300, 256, 3, 512, 2) | 42K | 22M | 33.95 | 37.26 | +3.31 |
| Seq2seq-Reduced | (300, 256, 3, 512, 2) | 87K | 54M | 33.73 | 36.59 | +2.86 |
| Transformer-Big | (512, 6, 8, 2048) | 42K | 65M | 33.90 | 37.07 | +3.17 |
| Transformer-Big | (512, 6, 8, 2048) | 87K | 88M | 32.66 | 35.62 | +2.96 |
| Transformer | (256, 3, 4, 1024) | 42K | 16M | 34.68 | 37.79 | +3.11 |
| Transformer | (256, 3, 4, 1024) | 87K | 27M | 34.95 | 37.98 | +3.03 |
| Transformer-Reduced | (128, 2, 2, 256) | 42K | 6M | 30.61 | 33.52 | +2.91 |
| Model | Entity Form | Surface Form |
|---|---|---|
| Dictionary search | 4.4% | 35.0% |
| 1-layer LSTM Stack | 91.1% | 88.0% |
| 2-layers LSTM Stack | 91.9% | 88.5% |
| 3-layers LSTM Stack | 91.8% | 88.2% |
| Truth | 이주진을 평안 감사로, 원경순을 부교리로, 윤경주를 정언으로 삼았다. |
| English Translation | Lee Joo Jin is assigned as the Pyeongan inspector, Won Kyung Soon as the vice dictator, Yun Gyeong Joo as the dictator. |
| Baseline | 이진을 평안 감사로, UNK을 부교리로, 윤주를 정언으로 삼았다. |
| Proposed | 이주진을 평안 감사로, 원경순을 부교리로, 윤경주를 정언으로 삼았다. |
| Truth | 암행어사 이윤명 · 김몽신 · 이우겸 등을 나누어 파견하여 여러 도를 검찰하게 하였다. |
| English Translation | The secret royal inspectors Lee Yun Myeong, Kim Mong Shin, and Lee Woo Gyeom were dispatched to investigate various provinces. |
| Baseline | 암행어사 UNK·UNK·UNK 등을 나누어 보내어 두루 제도를 살피게 하였다. |
| Proposed | 암행어사 이윤명 · 김몽신 · 이우겸 등을 나누어 보내어 두루 제도를 살피게 하였다. |
| Truth | 강원도 양구현의 민가 99호가 한꺼번에 불타 없어졌는데, 도신이 계문하니, 임금이 휼전을 시행하라고 명하였다. |
| English Translation | 99 civil houses in Yanggu Gangwon province were burnt down all at once, Do Shin requested the king to distribute food tickets to civilians. |
| Baseline | 강원도 UNK민가 99호가 한꺼번에 불에타버렸다. 도주가 아뢰니, 상이 휼전을 행하라고 명하였다. |
| Proposed | 강원도 양구현민가 99호가 한꺼번에 불에타버렸다. 도신가 아뢰니, 상이 휼전을 행하라고 명하였다. |
| Truth | 임금이 영희전에 나아가 전알하고, 이어서 저경궁·육상궁·연호궁·선희궁에 나아가 전배하였다. |
| English Translation | The king went to Yeonghuijeon and perform a rites, and then to Jeogyeonggung, Sokseonggung, Yeonhogung, and Seonhuigung and performed rites. |
| Baseline | 임금이 영모전에 나아가서 전알하고, 이어서 경복궁·UNK·UNK·경희전에 나아가 참배하였다. |
| Proposed | 임금이 영희전에 나아가서 전알하고, 이어서 저경궁·육상궁·연호궁·선희궁에 나아가 참배하였다. |
| Truth | 소대를 행하고 ≪명신주의≫를 강론하였다. |
| English Translation | Conducted a So Dae and lectured on ≪Myungshinism≫. |
| Baseline | 소대를 행하고 ≪UNK≫를 강하였다. |
| Proposed | 소대를 행하고 ≪명신주의≫를 강하였다. |
| Source | 上御居廬廳, 召對, 命儒臣, 讀≪必經≫ |
| Truth | 임금이 거려청에 나아가 소대하였다. 임금이 유신들에게 명하여 ≪심경≫을 읽게하였다. |
| English Translation | The king went to Georyeocheong and conducted a So Dae. The king ordered the subjects to read ≪Shim Gyung≫. |
| Baseline | 상이 UNK에 나아가 소대하였다. 유신에게 명하여 ≪UNK≫을 읽게하였다. |
| Proposed | 상이 UNK에 나아가 소대하였다. 유신에게 명하여 ≪UNK≫을 읽게하였다. |
| NER output | [≪必經≫, Book] |
| Source | 進講于熙政堂 |
| Truth | 희정당에서 진강하였다. |
| English Translation | He lectured at Huijeongdang. |
| Baseline | UNK에서 진강하였다. |
| Proposed | UNK에서 진강희정당였다. |
| NER output | [熙政堂, Location] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Lee , J.; Lee , M.; Jang, G.-J. Named Entity Correction in Neural Machine Translation Using the Attention Alignment Map. Appl. Sci. 2021, 11, 7026. https://doi.org/10.3390/app11157026
Lee J, Lee J, Lee M, Jang G-J. Named Entity Correction in Neural Machine Translation Using the Attention Alignment Map. Applied Sciences. 2021; 11(15):7026. https://doi.org/10.3390/app11157026
Chicago/Turabian StyleLee, Jangwon, Jungi Lee , Minho Lee , and Gil-Jin Jang. 2021. "Named Entity Correction in Neural Machine Translation Using the Attention Alignment Map" Applied Sciences 11, no. 15: 7026. https://doi.org/10.3390/app11157026
APA StyleLee, J., Lee , J., Lee , M., & Jang, G.-J. (2021). Named Entity Correction in Neural Machine Translation Using the Attention Alignment Map. Applied Sciences, 11(15), 7026. https://doi.org/10.3390/app11157026