
Hybrid Machine Learning Model for Body Fat Percentage Prediction Based on Support Vector Regression and Emotional Artificial Neural Networks




Abstract
:1. Introduction
- Collection of primary data for BFP prediction with a higher number of observations for anthropometric attributes for both genders.
- Employment of the WHR for the first time in a machine learning prediction model for BFP.
- Creating a hybrid model for accurate prediction of the BFP.
- Feature selection and the most influential factor determination using SVR and left-out sensitivity analysis.
- Prediction of BFP using the selected features and EANN.
- Comparison of the results with benchmark machine learning models.
2. Materials and Methods
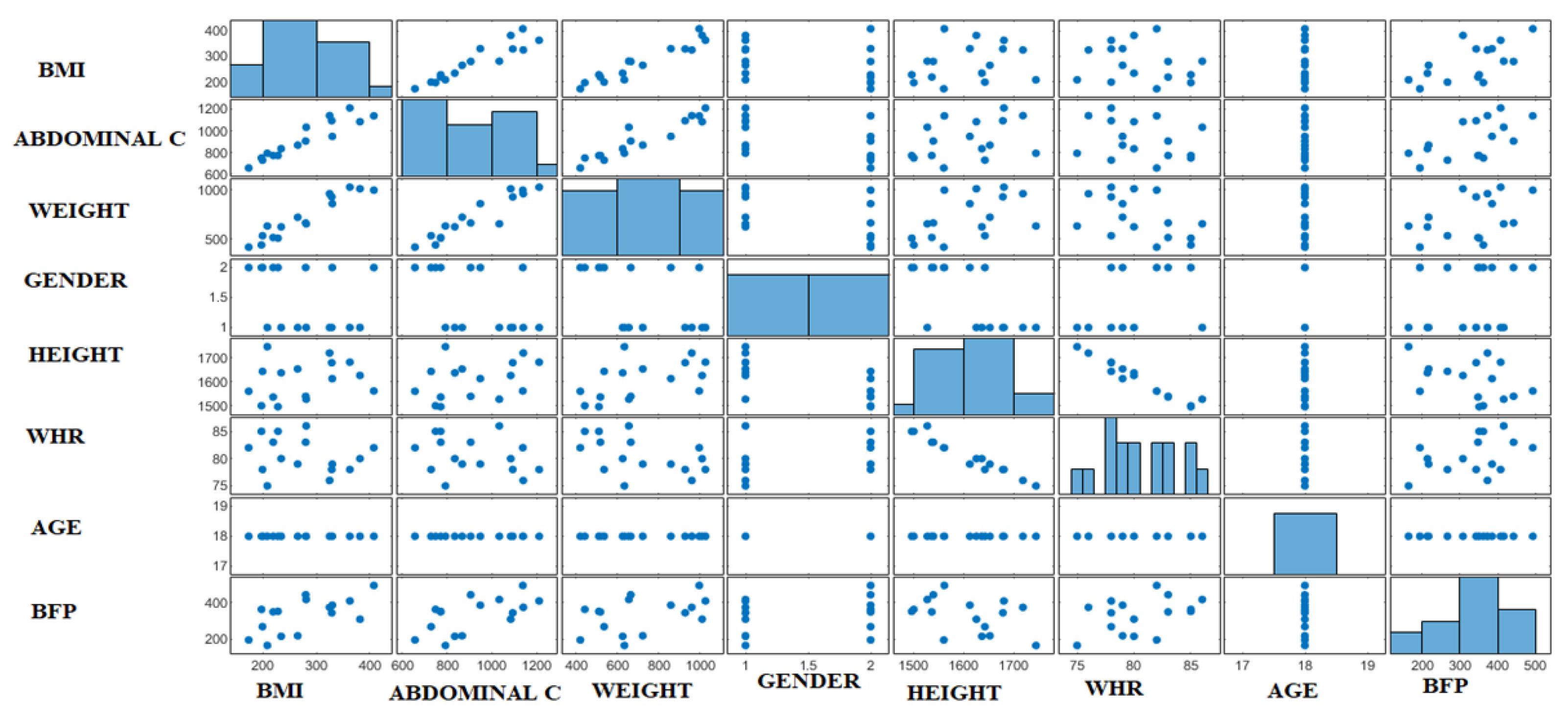
2.1. Datasets
2.2. Machine Learning Models
2.2.1. Artificial Neural Networks
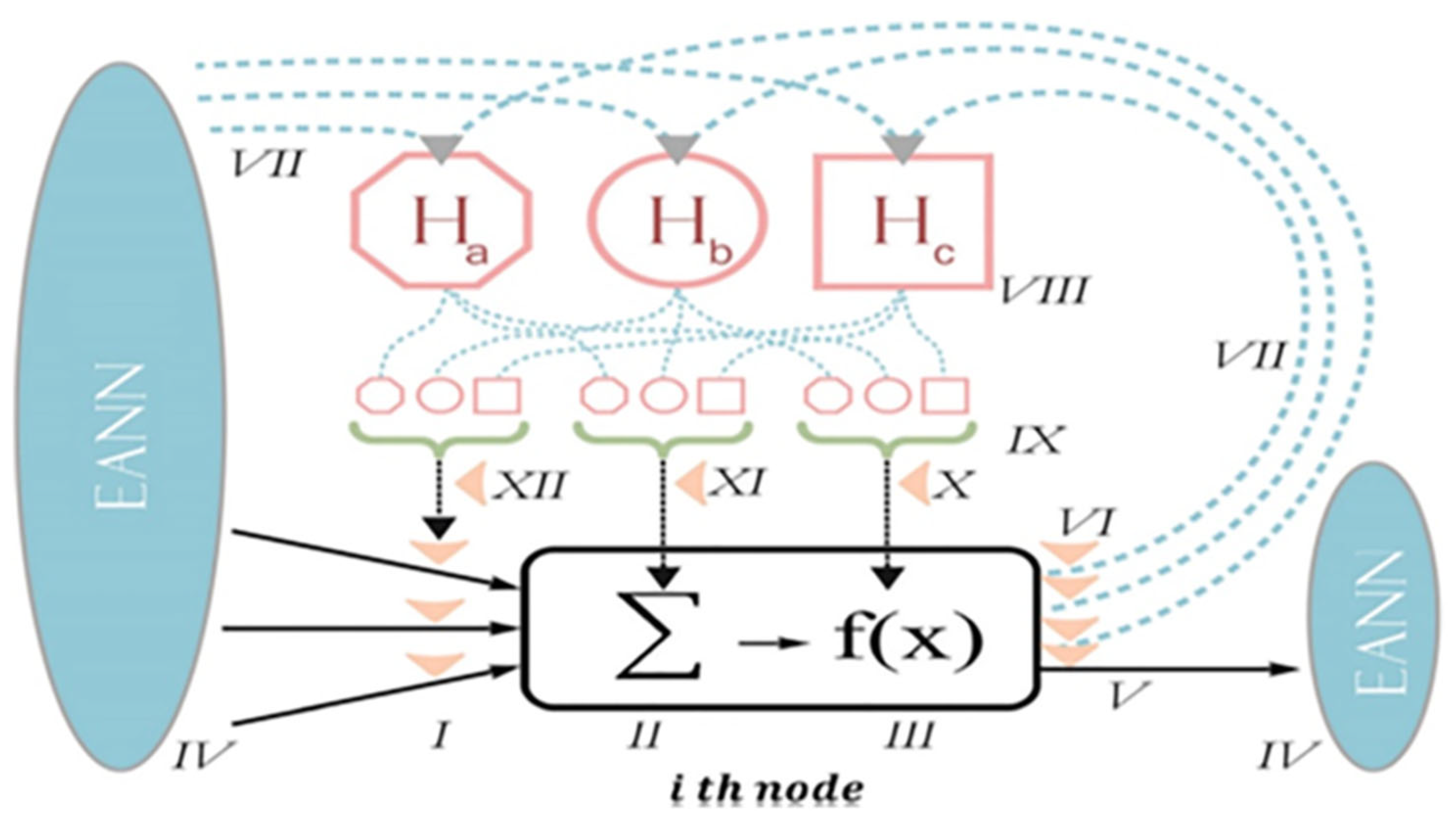
2.2.2. Emotional Artificial Neural Networks
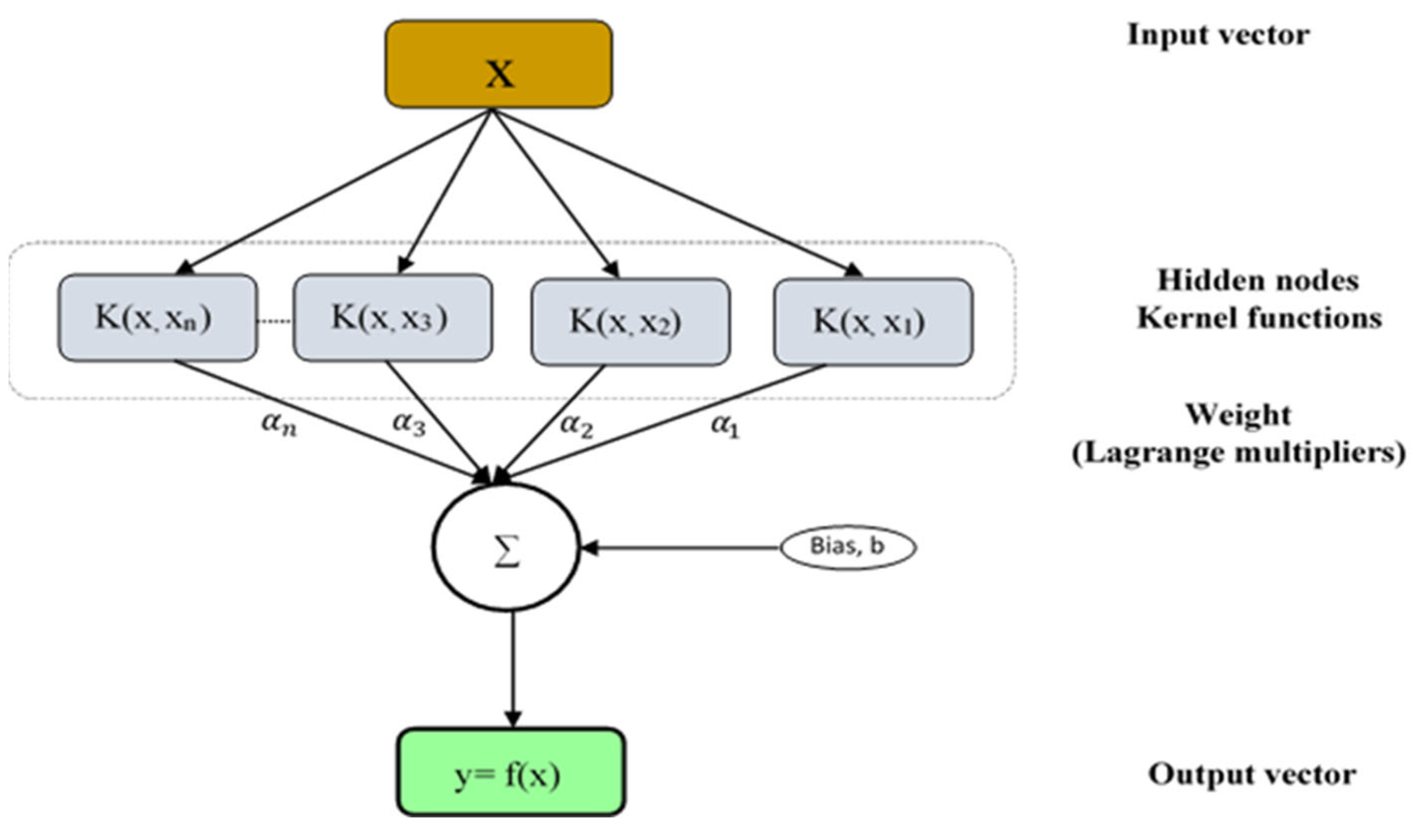
2.2.3. Support Vector Regression
2.3. Data Preparation, Validation, and Performance Evaluation
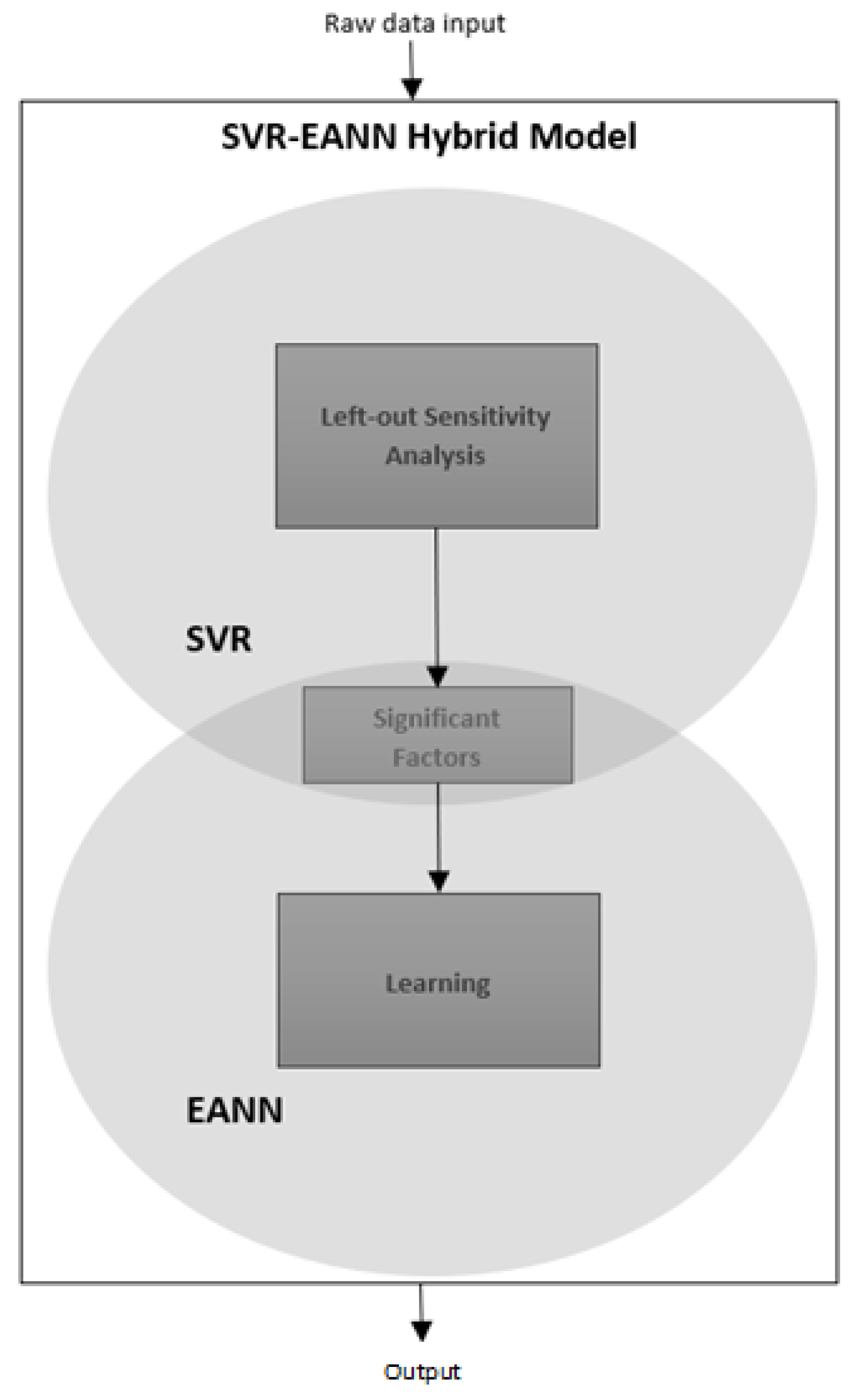
3. Proposed Hybrid Model
4. Results and Discussions
4.1. Determination of Significant Factors
4.2. Regression Results and Comparisons
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kupusinac, A.; Stokić, E.; Doroslovački, R. Predicting body fat percentage based on gender, age and BMI by using artificial neural networks. Comput. Methods Programs Biomed. 2014, 113, 610–619. [Google Scholar] [CrossRef]
- Fan, J.-G.; Kim, S.-U.; Wong, V.W.-S. New trends on obesity and NAFLD in Asia. J. Hepatol. 2017, 67, 862–873. [Google Scholar] [CrossRef] [Green Version]
- Flegal, K.M.; Shepherd, J.A.; Looker, A.C.; Graubard, B.I.; Borrud, L.G.; Ogden, C.L.; Harris, T.B.; Everhart, J.E.; Schenker, N. Comparisons of percentage body fat, body mass index, waist circumference, and waist-stature ratio in adults. Am. J. Clin. Nutr. 2009, 89, 500–508. [Google Scholar] [CrossRef]
- Swainson, M.G.; Batterham, A.M.; Tsakirides, C.; Rutherford, Z.H.; Hind, K. Prediction of whole-body fat percentage and visceral adipose tissue mass from five anthropometric variables. PLoS ONE 2017, 12, e0177175. [Google Scholar] [CrossRef]
- DeGregory, K.; Kuiper, P.; DeSilvio, T.; Pleuss, J.; Miller, R.; Roginski, J.; Fisher, C.; Harness, D.; Viswanath, S.; Heymsfield, S. A review of machine learning in obesity. Obes. Rev. 2018, 19, 668–685. [Google Scholar] [CrossRef]
- Chen, W.; Hou, X.-H.; Zhang, M.-L.; Bao, Y.-Q.; Zou, Y.-H.; Zhong, W.-H.; Xiang, K.-S.; Jia, W.-P. Comparison of body mass index with body fat percentage in the evaluation of obesity in Chinese. Biomed. Environ. Sci. 2010, 23, 173–179. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Tuncal, K. Prediction of cancer incidence rates for the European continent using machine learning models. Health Inform. J. 2021, 27. [Google Scholar] [CrossRef]
- Ferenci, T.; Kovacs, L. Predicting body fat percentage from anthropometric and laboratory measurements using artificial neural networks. Appl. Soft Comput. 2018, 67, 834–839. [Google Scholar] [CrossRef]
- Chiong, R.; Fan, Z.; Hu, Z.; Chiong, F. Using an improved relative error support vector machine for body fat prediction. Comput. Methods Programs Biomed. 2021, 198, 105749. [Google Scholar] [CrossRef]
- Johnson, R.W. Fitting percentage of body fat to simple body measurements. J. Stat. Educ. 1996, 4. [Google Scholar] [CrossRef]
- Shao, Y.E. Body fat percentage prediction using intelligent hybrid approaches. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [Green Version]
- Uçar, M.K.; Ucar, Z.; Köksal, F.; Daldal, N. Estimation of body fat percentage using hybrid machine learning algorithms. Measurement 2021, 167, 108173. [Google Scholar] [CrossRef]
- Liu, M.; Chen, L.; Du, X.; Jin, L. Activated Gradients for Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef]
- Khashman, A. A modified backpropagation learning algorithm with added emotional coefficients. IEEE Trans. Neural Netw. 2008, 19, 1896–1909. [Google Scholar] [CrossRef]
- Rahman, M.A.; Milasi, R.M.; Lucas, C.; Araabi, B.N.; Radwan, T.S. Implementation of emotional controller for interior permanent-magnet synchronous motor drive. IEEE Trans. Ind. Appl. 2008, 44, 1466–1476. [Google Scholar] [CrossRef]
- Nourani, V. An emotional ANN (EANN) approach to modeling rainfall-runoff process. J. Hydrol. 2017, 544, 267–277. [Google Scholar] [CrossRef]
- Gholami, A.; Bonakdari, H.; Samui, P.; Mohammadian, M.; Gharabaghi, B. Predicting stable alluvial channel profiles using emotional artificial neural networks. Appl. Soft Comput. 2019, 78, 420–437. [Google Scholar] [CrossRef]
- Sharghi, E.; Nourani, V.; Najafi, H.; Gokcekus, H. Conjunction of a newly proposed emotional ANN (EANN) and wavelet transform for suspended sediment load modeling. Water Supply 2019, 19, 1726–1734. [Google Scholar] [CrossRef]
- Biswas, R.; Samui, P.; Rai, B. Determination of compressive strength using relevance vector machine and emotional neural network. Asian J. Civ. Eng. 2019, 20, 1109–1118. [Google Scholar] [CrossRef]
- De Koning, L.; Merchant, A.T.; Pogue, J.; Anand, S.S. Waist circumference and waist-to-hip ratio as predictors of cardiovascular events: Meta-regression analysis of prospective studies. Eur. Heart J. 2007, 28, 850–856. [Google Scholar] [CrossRef]
- Usman, A.; Işik, S.; Abba, S. A novel multi-model data-driven ensemble technique for the prediction of retention factor in HPLC method development. Chromatographia 2020, 83, 933–945. [Google Scholar] [CrossRef]
- Cavus, N.; Mohammed, Y.B.; Yakubu, M.N. Determinants of Learning Management Systems during COVID-19 Pandemic for Sustainable Education. Sustainability 2021, 13, 5189. [Google Scholar] [CrossRef]
- Khashman, A. Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert Syst. Appl. 2010, 37, 6233–6239. [Google Scholar] [CrossRef]
- Ozsahin, I.; Sekeroglu, B.; Mok, G.S. The use of back propagation neural networks and 18F-Florbetapir PET for early detection of Alzheimer’s disease using Alzheimer’s Disease Neuroimaging Initiative database. PLoS ONE 2019, 14, e0226577. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Nigam, S.; Kumar, N. Vehicular traffic noise modeling using artificial neural network approach. Transp. Res. Part C Emerg. Technol. 2014, 40, 111–122. [Google Scholar] [CrossRef]
- Nourani, V.; Alami, M.T.; Vousoughi, F.D. Wavelet-entropy data pre-processing approach for ANN-based groundwater level modeling. J. Hydrol. 2015, 524, 255–269. [Google Scholar] [CrossRef]
- Nourani, V.; Gökçekuş, H.; Umar, I.K.; Najafi, H. An emotional artificial neural network for prediction of vehicular traffic noise. Sci. Total. Environ. 2020, 707, 136134. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Haykin, S., Ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Cavus, N.; Mohammed, Y.B.; Yakubu, M.N. An Artificial Intelligence-Based Model for Prediction of Parameters Affecting Sustainable Growth of Mobile Banking Apps. Sustainability 2021, 13, 6206. [Google Scholar] [CrossRef]
- Wang, W.-c.; Xu, D.-m.; Chau, K.-w.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinform. 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Oytun, M.; Tinazci, C.; Sekeroglu, B.; Acikada, C.; Yavuz, H.U. Performance prediction and evaluation in female handball players using machine learning models. IEEE Access 2020, 8, 116321–116335. [Google Scholar] [CrossRef]
- Nourani, V.; Gökçekuş, H.; Umar, I.K. Artificial intelligence based ensemble model for prediction of vehicular traffic noise. Environ. Res. 2020, 180, 108852. [Google Scholar] [CrossRef]
- Rabehi, A.; Guermoui, M.; Lalmi, D. Hybrid models for global solar radiation prediction: A case study. Int. J. Ambient. Energy 2020, 41, 31–40. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei, Taiwan, 2003. Available online: http://www.csie.ntu.edu.tw/~cjlin/papers.html (accessed on 14 October 2021).
- Nourani, V.; Elkiran, G.; Abdullahi, J.; Tahsin, A. Multi-region modeling of daily global solar radiation with artificial intelligence ensemble. Nat. Resour. Res. 2019, 28, 1217–1238. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Y.; Yu, Z.; Tian, F. Feature selection of power system transient stability assessment based on random forest and recursive feature elimination. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 1264–1268. [Google Scholar] [CrossRef]
- Stanton, J.M. Galton, Pearson, and the peas: A brief history of linear regression for statistics instructors. J. Stat. Educ. 2001, 9. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1189–1232. [Google Scholar] [CrossRef]
- Stevens, J.; Truesdale, K.P.; Cai, J.; Ou, F.-S.; Reynolds, K.R.; Heymsfield, S.B. Nationally representative equations that include resistance and reactance for the prediction of percent body fat in Americans. Int. J. Obes. 2017, 41, 1669–1675. [Google Scholar] [CrossRef] [Green Version]
- Leahy, S.; O’Neill, C.; Sohun, R.; Toomey, C.; Jakeman, P. Generalised equations for the prediction of percentage body fat by anthropometry in adult men and women aged 18–81 years. Br. J. Nutr. 2013, 109, 678–685. [Google Scholar] [CrossRef] [Green Version]
- Deurenberg, P.; Deurenberg-Yap, M.; Wang, J.; Lin, F.P.; Schmidt, G. Prediction of percentage body fat from anthropometry and bioelectrical impedance in Singaporean and Beijing Chinese. Asia Pac. J. Clin. Nutr. 2000, 9, 93–98. [Google Scholar] [CrossRef]
- Fthenakis, Z.G.; Balaska, D.; Zafiropulos, V. Uncovering the FUTREX-6100XL prediction equation for the percentage body fat. J. Med. Eng. Technol. 2012, 36, 351–357. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | BMI (kg/m2) | Abdominal C (cm) | Weight (kg) | Gender | Height (cm) | WHR (cm) | Age | BFP |
|---|---|---|---|---|---|---|---|---|
| Mean | 26.218 | 86.6345 | 67.05 | 1.81 | 160.301 | 0.825 | 23.05 | 33.42 |
| Standard Deviation | 10.33 | 18.031 | 21.761 | 0.40 | 9.4638 | 0.0554 | 3.43 | 11.83 |
| Minimum | 12.9 | 60.7 | 15.40 | 1.00 | 63.00 | 0.66 | 18.00 | 3.00 |
| Maximum | 237.3 | 182.7 | 183.70 | 2.00 | 199.8 | 2.1 | 29.00 | 87.7 |
| BMI | Abdominal C | Weight | Gender | Height | WHR | Age | BFP | |
|---|---|---|---|---|---|---|---|---|
| BMI | 1 | |||||||
| abdominal C | 0.9531 | 1 | ||||||
| weight | 0.9279 | 0.9589 | 1 | |||||
| gender | 0.0118 | −0.155 | −0.2183 | 1 | ||||
| height | −0.0036 | 0.1203 | 0.3288 | −0.6017 | 1 | |||
| WHR | 0.0047 | −0.0698 | −0.2683 | 0.4822 | −0.9358 | 1 | ||
| age | 0.2479 | 0.2042 | 0.2216 | 0.0289 | −0.0059 | 0.0490 | 1 | |
| BFP | 0.8086 | 0.7583 | 0.6277 | 0.4411 | −0.3979 | 0.3643 | 0.2097 | 1 |
| Removed Parameter | RMSE |
|---|---|
| BMI | 0.0564 |
| Abdominal C | 0.1509 |
| Weight | 0.0341 |
| Gender | 0.1223 |
| Height | 0.0708 |
| WHR | 0.0589 |
| Age | 0.0157 |
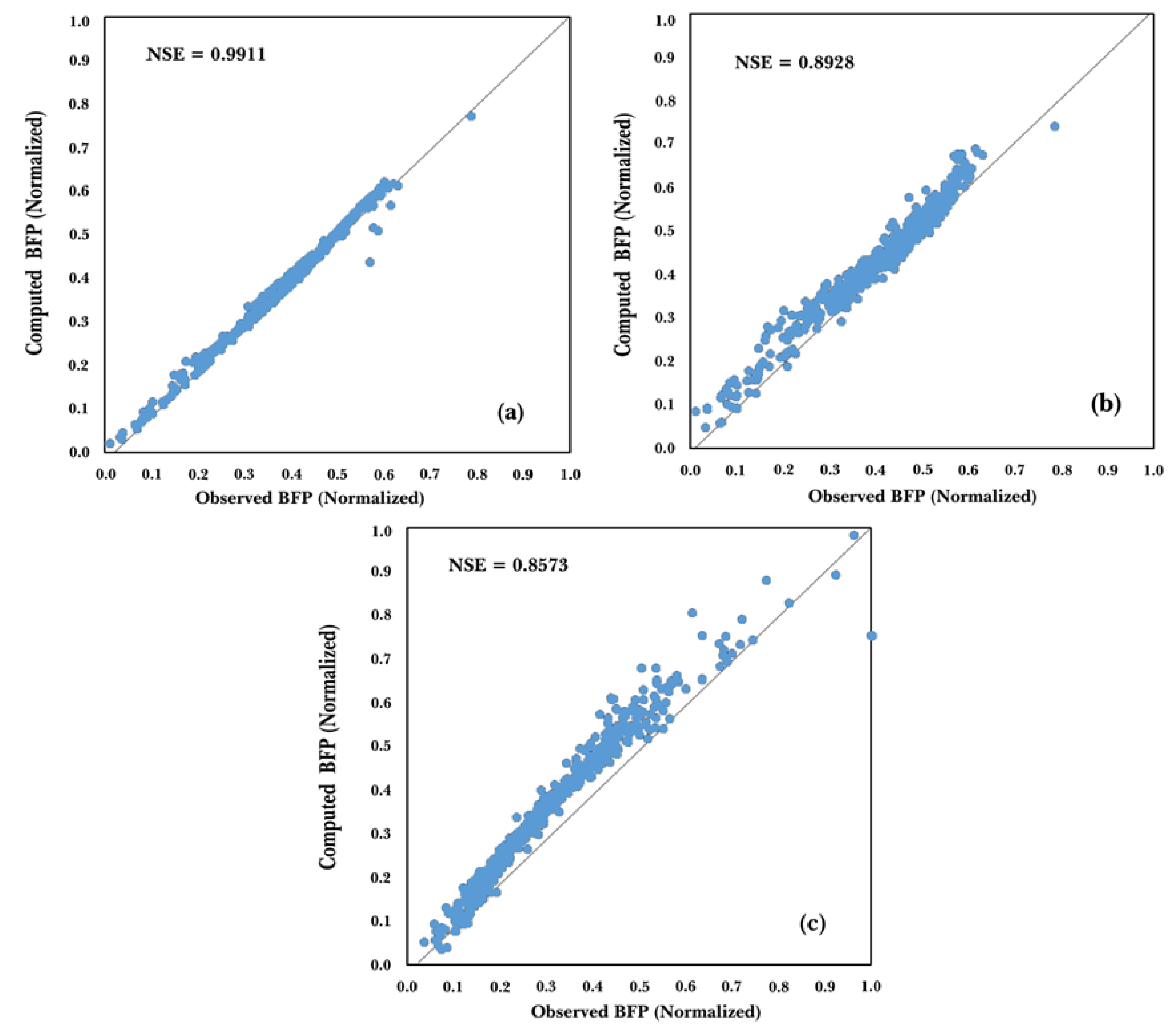
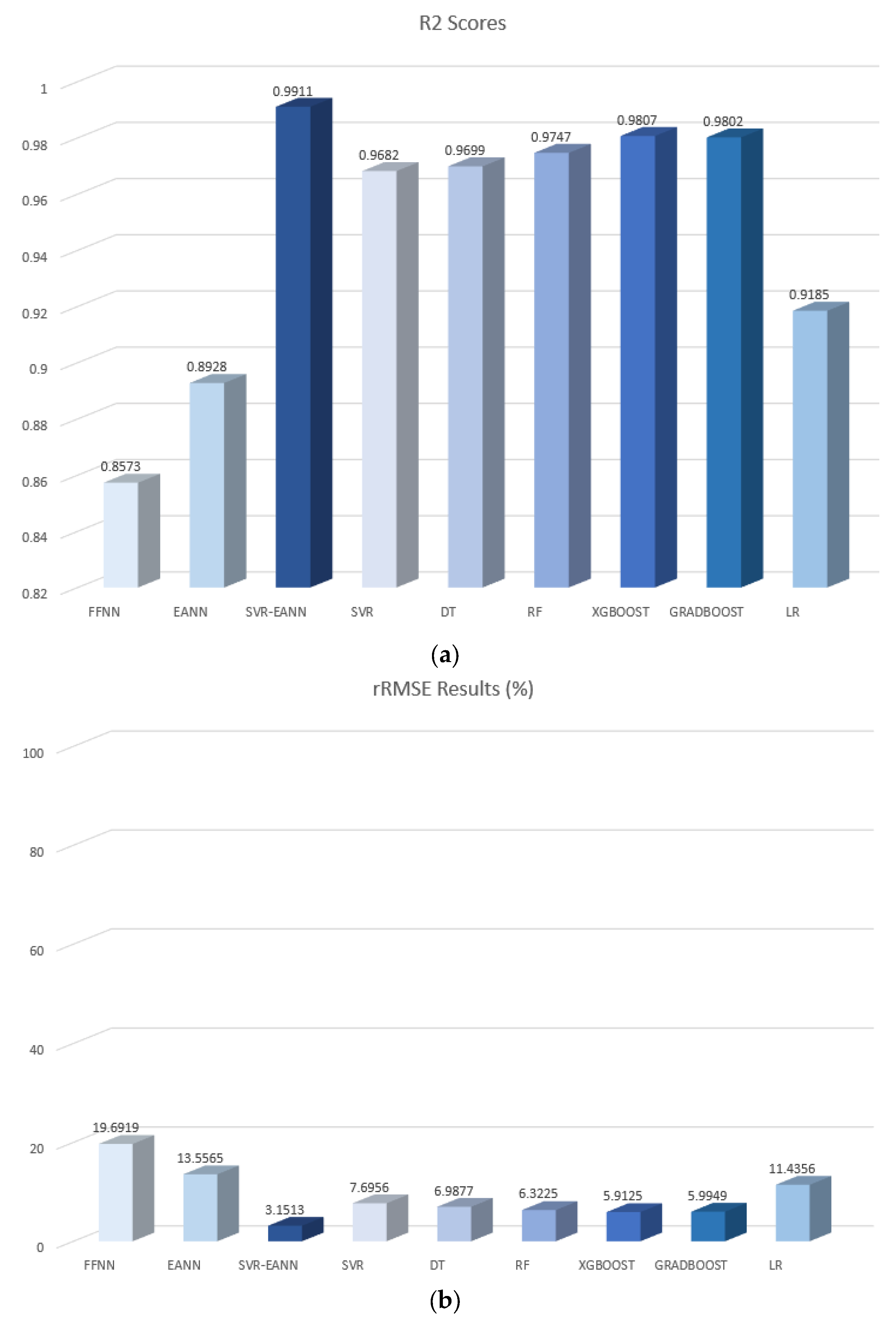
| Models | R2 | RMSE | RRMSE (%) |
|---|---|---|---|
| FFNN | 0.8573 | 0.0622 | 19.6919 |
| EANN | 0.8928 | 0.0464 | 13.5565 |
| SVR-EANN | 0.9911 | 0.0125 | 3.1513 |
| SVR | 0.9682 | 0.0245 | 7.6956 |
| DT | 0.9699 | 0.0216 | 6.9877 |
| RF | 0.9747 | 0.0198 | 6.3225 |
| XGBOOST | 0.9807 | 0.0178 | 5.9125 |
| GRADBOOST | 0.9802 | 0.0182 | 5.9949 |
| LR | 0.9185 | 0.0396 | 11.4356 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, S.A.; Cavus, N.; Sekeroglu, B. Hybrid Machine Learning Model for Body Fat Percentage Prediction Based on Support Vector Regression and Emotional Artificial Neural Networks. Appl. Sci. 2021, 11, 9797. https://doi.org/10.3390/app11219797
Hussain SA, Cavus N, Sekeroglu B. Hybrid Machine Learning Model for Body Fat Percentage Prediction Based on Support Vector Regression and Emotional Artificial Neural Networks. Applied Sciences. 2021; 11(21):9797. https://doi.org/10.3390/app11219797
Chicago/Turabian StyleHussain, Solaf A., Nadire Cavus, and Boran Sekeroglu. 2021. "Hybrid Machine Learning Model for Body Fat Percentage Prediction Based on Support Vector Regression and Emotional Artificial Neural Networks" Applied Sciences 11, no. 21: 9797. https://doi.org/10.3390/app11219797
APA StyleHussain, S. A., Cavus, N., & Sekeroglu, B. (2021). Hybrid Machine Learning Model for Body Fat Percentage Prediction Based on Support Vector Regression and Emotional Artificial Neural Networks. Applied Sciences, 11(21), 9797. https://doi.org/10.3390/app11219797