2.1. Microgrid and Energy Management System
The decentralised electricity generation model has many advantages over the conventional centralised systems that consist of remote generation units. In a centralised generation model, power flows in one direction, from a small number of large generators to many consumers over a long distance. Therefore, the centralised model requires large power plants to meet the demand and significant transmission lines to connect households and businesses with their power source, resulting in colossal air pollutant emissions, wastage of generation, and land use. The fact that it requires a high integration level also means that its system is extremely vulnerable to disturbances in the supply chain. Therefore, its attractiveness is reducing, and the penetration of small-scale decentralised systems or microgrids is emerging and increasingly invested.
The microgrid is essentially a local energy grid with control capability and autonomous operation, which can be disconnected from the primary grid when required [
3]. In opposition to centralised systems, power in a microgrid flows in both directions. As it is built locally using renewable sources, it is more efficient, more reliable, lower cost, and cleaner than the centralised model. The three main types of a microgrid are remote, grid-connected, and networked microgrids. In this study, a grid-connected microgrid focuses on the most suitable system for commercial and residential buildings. A grid-connected microgrid can operate in either grid-connected mode or stand-alone mode based on the requirement. In grid-connected mode, the microgrid imports or exports the power from and to the grid depending on generation and load conditions and market policies based on contractual obligations. On the other hand, in islanding mode, the microgrid disconnects from the utility when an abnormal condition occurs in the grid, and the microgrid has to satisfy the load with the required level of power quality by utilising the local storage and renewable resources [
4]. Therefore, the energy management strategies used are different, and a coordinated control approach for microgrid energy management is required to minimise the errors between the forecasting and real-time data in the schedule, and dispatch layers of the system [
5].
The setup of monitoring and optimising energy consumption to regulate the energy flow is commonly known as an energy management system (EMS). A microgrid usually requires an energy management system to assign active and reactive power references, ensuring cooperation between the controllable units to achieve stable and economic operation [
5]. The latest research shows that the objective of energy management of a microgrid is to minimise the microgrid’s operating costs such as fuel costs, operating maintenance costs, and purchase cost of electricity from the conventional power grids [
5]. One of the key features that allow a microgrid energy management system to achieve its objective is to have a robust and accurate forecasting technique of load demand/generation profile capability. In a residential setting, energy management works on optimising energy consumption, equipment efficiency, detecting faults in a deteriorating system, implementing ways to reduce energy wastage, and recovering energy wastage for other purposes. The EMS inferences provide data visualisation to household owners to better understand their usage patterns and recommendations on smart energy usage to drive better behaviour in their daily use. As an effect, maintenance cost is reduced because equipment usage is optimised [
6]. Not only capturing and presenting historical data, but an EMS can also help forecast a household or a building’s energy consumption by using an intelligent machine learning algorithm. It also allows the developers to accurately identify the sizing of power resources required to meet a built or a new unit’s demand. However, one of the main drawbacks of using high-end machine learning algorithms is the lack of valid data set for effective training. That is why our study focuses not only on developing an optimised machine learning algorithm but also on establishing a novel synthetic load generator to evaluate our proposed model.
For the synthetic load generator to be built, an investigation into standard controllable loads, uncontrollable loads, and critical loads with their usage pattern in a typical household was carried out. Any device or appliance’s power consumption can be controlled by adjusting their duration on and off time [
7]. Controllable loads can be differentiated from uncontrollable loads based on their ability to be turned off without sacrificing the user’s comfort [
8]. For example, air conditioners and refrigerators can be turned off for a certain period to save power without significantly affecting household comfort. However, microwave ovens or toasters, examples of uncontrollable load, should not be turned off because this directly impacts the occupant’s comfort. The critical loads are loads that will result in a significant loss or damage when power off [
9]. Examples of essential loads are a smoke alarm, a water pump, and critical load panels in an energy storage system [
10]. Following these definitions, in a distributed power system, popular controllable loads, such as refrigerators, HVAC systems, entertainment devices, and fans are considered in the mathematical model formulated in this study. The most commonly used loads in residential settings are supposed to generate an extensive data set of load profiles with artificially induced non-linearity. A list of loads being considered is explained in the methodology section below.
Another fact about microgrids is that majority of them are built-in integration with renewable energy sources such as wind turbines, solar photovoltaic (PV), and fuel cells due to the global transition to green technologies. In addition to the eco-friendly advantages of such systems, the renewable resources add more non-linearity into the system due to their stochastic nature, resulting in an advanced/robust energy management algorithm. In 2009, for the EU, nearly 55% of the new installed capacity based on renewable sources corresponded to the wind and PV intermittent generation (39% and 16%, respectively) [
11]. According to the Australian Department of Industry, Science, Energy, and Resources, in 2019, 21% of Australia’s total electricity generation was based on the renewable energy resources, which consisted of 7% of wind, 7% of solar, and 5% of hydro, making the share of renewables the highest recorded since the 1970s [
12]. On this note, the study of load forecasting methodology is critical because it will enable an accurate sizing/scheduling of renewable sources for a microgrid system, preventing resource wastage or shortage and many other system failures.
2.2. Machine Learning
The complexity of residential load forecasting lies in the significant volatility and stochastic nature of the load profiles. Many researchers worldwide are working towards addressing this complexity by developing an accurate forecasting technique that addresses this uncertainty. The statistical learning approaches are based on the predefined relationship between variables and require a smaller data set but whereas the more accurate and advanced machine learning algorithms require a big data set. In recent years, the rise of big data with machine learning makes it a potential solution to address load forecasting in a residential energy management system. Traditional methods tend to avoid such uncertainty by load aggregation to offset uncertainties, customer classification to cluster uncertainties, and spectral analysis to filter out uncertainties [
13]. Therefore, many studies are carried out to evolve the current machine learning techniques to learn the uncertainty at the building level directly due to the many influencing factors.
According to Lars Hulstaert, a data scientist at Johnson and Johnson, most machine learning systems require the ability to explain to stakeholders why specific predictions are made [
14]. The accuracy and interpretability trade-off is typically considered when choosing a suitable machine learning model. Generally, there are two types of machine learning models, namely, black-box and white-box. Black-box models such as neural networks and gradient boosting models yield highly accurate predictions. However, their computational operation is difficult to understand. On the other hand, white-box models such as linear regression and decision trees, despite being much easier to interpret, produce less predictive capacity. In this research, an initial comprehensive multi-criteria analysis of the most common machine learning techniques in models such as linear regression, gradient boosting, decision tree, and neural network was performed to determine the best potential method optimised for load forecasting application.
Machine learning approaches are generally used to address supervised and unsupervised learning problems. Since the proposed methodology aims to predict energy consumption, supervised learning is a more suitable option as its primary function is to model the value of the target variable based on the predictor variables. Machine learning and artificial intelligence techniques are used in a wide variety of applications, such as load forecasting [
15], determining product quality [
16], and fault quality [
17]. Linear regression, decision trees, and neural networks are all examples of supervised learning. Despite the similarities, their computation principles are different. Regression analysis is a methodology that allows finding a functional relationship among dependent variables and independent variables [
18]. For complex systems, such as the energy consumption in buildings, the regression analysis is considered as an iterative process, in which the outputs are used to diagnose, validate, criticise, and possibly modify the inputs [
18]. In the decision tree approaches, an empirical tree represents a segmentation of the created data by applying a series of simple rules. Through the repetitive process of splitting, predictions are made, and the logic is usually comprehensible [
19].
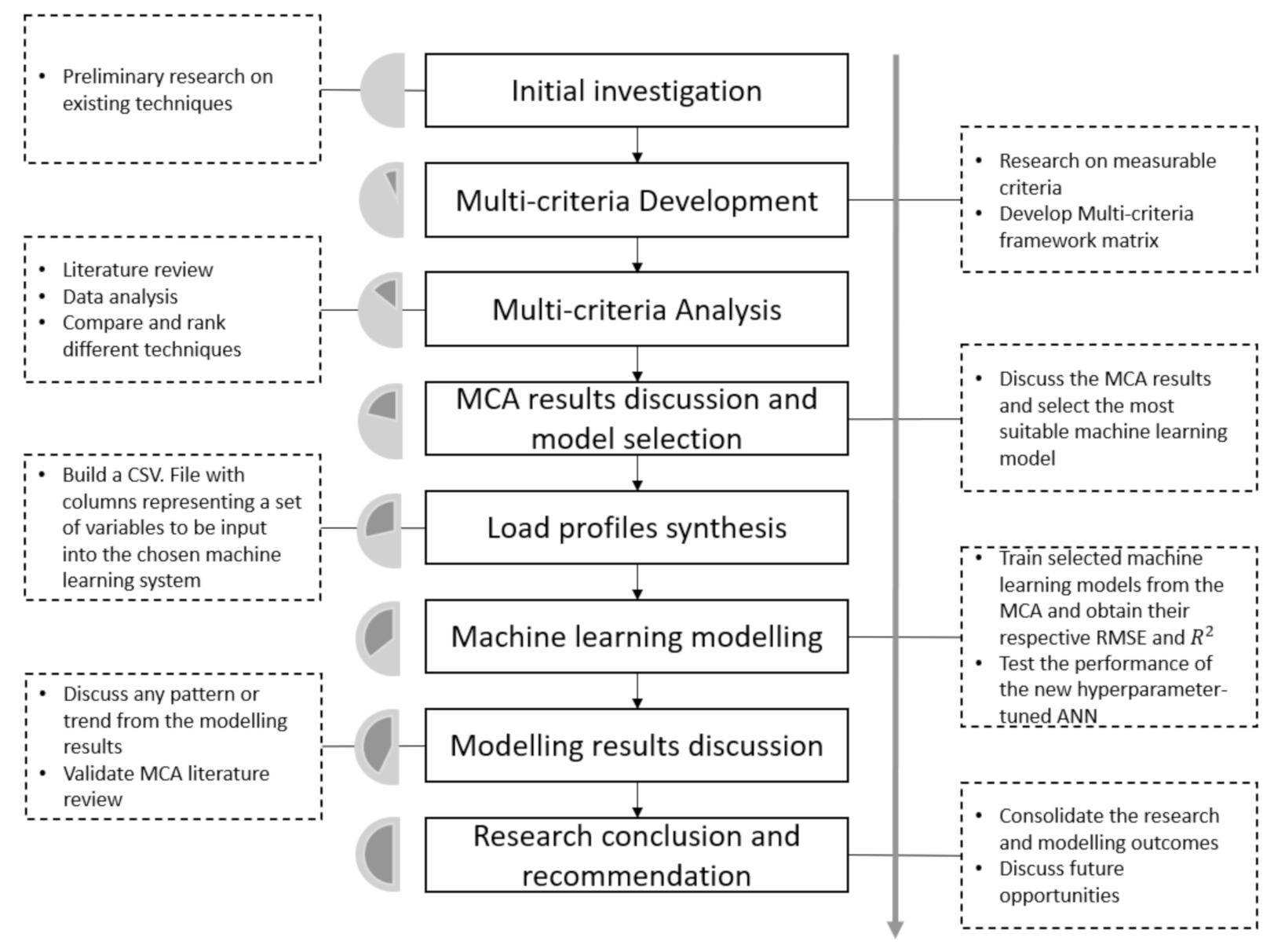
On the contrary, the neural network is a class of algorithms loosely modelled on connections between neurons in the human biological brain, which is designed to imitate the natural nervous system information process and decision making [
20]. There are many choices of neural network optimising architecture that significantly influences the performance of the model. This study proposes a novel deep neural network model by optimising the hyper-parameters to enhance neural networks’ performances. A comprehensive literature review in the form of multi-criteria analysis (MCA) was carried out. The next section of the paper will critically highlight how the MCA analysis is performed and evaluated.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}