1. Introduction
Due to their advantages of simple structure, sustainability, and flexible control methods, skid-steering vehicles have been widely used in civil and military applications, including agricultural vehicles [
1], combat vehicles [
2,
3], robots [
4,
5], and so on. As shown in
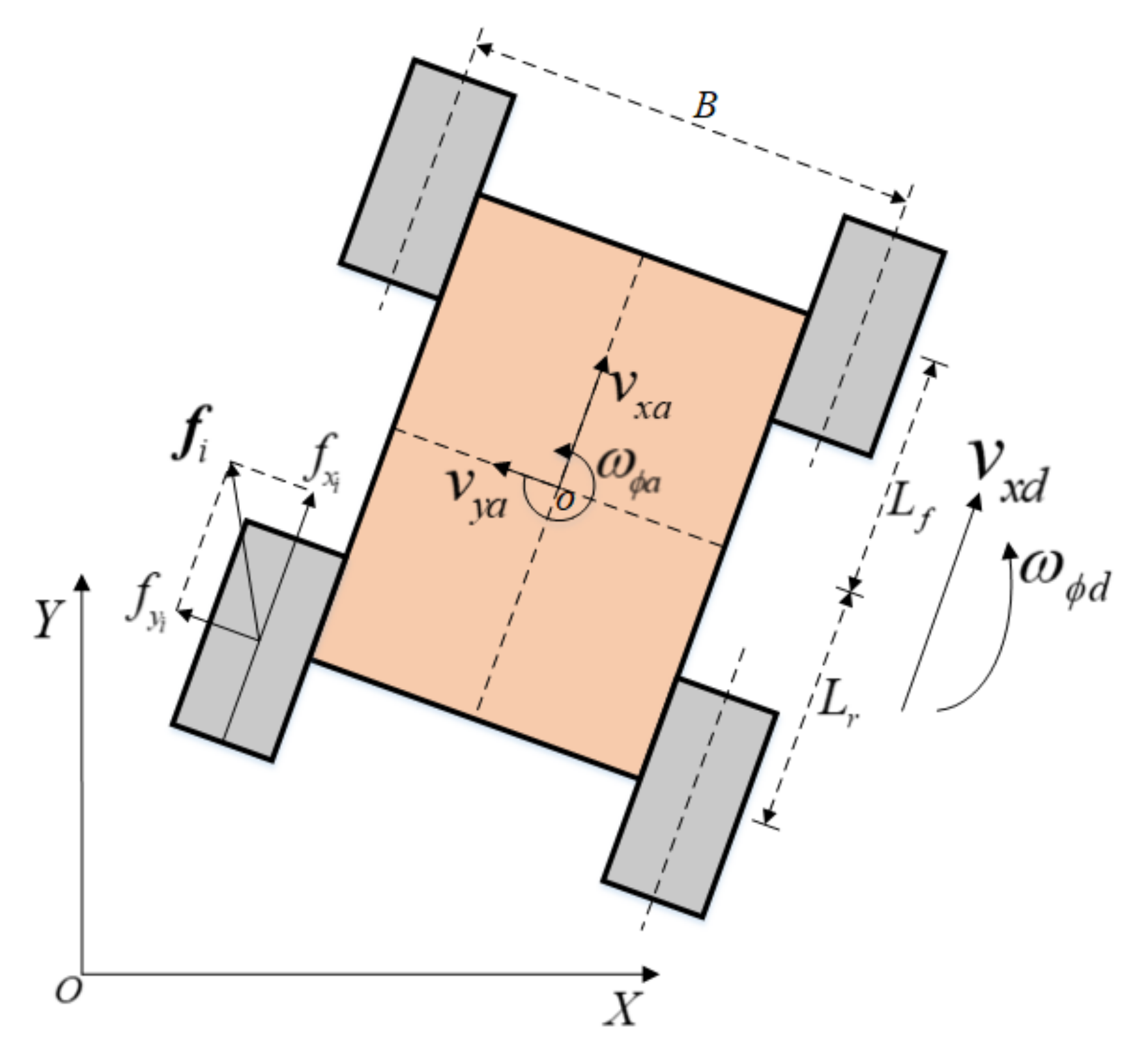
Figure 1, skid-steering vehicles are typically equipped with four independent driving wheels, forming an overdrive system with more control output than control input. Unlike car-like vehicles [
6,
7,
8], skid-steering vehicles do not possess a dedicated steering system; therefore, a reasonable torque distribution is key to skid-steering vehicle control. With the development of optimal problem solvers, through reinforcement learning (RL) techniques in complex systems, new insights have been provided for coordinated torque distribution in skid-steering vehicles. Therefore, the development of torque distribution strategies based on RL has become a promising research direction for future skid-steering vehicles.
The conventional control methods for skid-steering vehicles, mainly, include kinematics and dynamics methods [
9]. In kinematics methods, the desired control value is transformed into a reference speed for each wheel, based on the vehicle kinematics, following which each driving wheel generates driving torque, to track its own reference speed for vehicle control [
10,
11,
12]. Kinematics methods are subject to significant slippage and skidding, when precisely following the wheel reference speed, which seriously impacts the control performance of the vehicle. In [
13], the authors proposed a speed-adaptive control algorithm for six-wheeled differential steering vehicles. To enhance the vehicle handing and lateral stability performance, reference wheel speeds are, individually, generated for each wheel, based on their respective slipping and skidding status. In [
14], a hierarchical controller was designed for a skid-steering vehicle, based on the need of dynamic control. In the controller, a reference wheel speed generator was designed to calculate the wheel speed, and a wheel speed follower is used to reach the target wheel speed. In [
15], in order to mitigate the effects of wheel slip on accurate control, the authors proposed a new kinematics model for skid-steering vehicles, which has the ability to predict and compensate for the slippages in the forward kinematics.
To improve maneuverability and stability, recent studies have proposed dynamics methods for the control of skid-steering vehicles. Dynamics methods can address the problem of torque distribution for skid-steering vehicles, through optimization theory [
16,
17,
18]. In [
19], the authors proposed a hierarchical torque distribution strategy for a skid-steering electric unmanned ground vehicle (EUGV), in order to control the longitudinal speed and yaw rate. The objective function, consisting of the longitudinal tire workload rates and weight factors of the tires, was established by considering inequality constraints, including actuator, road adhesion, and tire friction circle constraints. In [
20], a hierarchical control framework for a six-wheel independent drive (6WID) vehicle was proposed, and optimization theory was employed to distribute the driving torques. The control strategy was used to realize the real-time torque distribution, having the ability to maintain wheel failure tolerance and limit wheel slip.
To date, RL algorithms have been successfully implemented in robots [
21] and unmanned aerial vehicles (UAVs) [
22,
23] as well as energy [
24], transportation [
25], and other complex systems [
26,
27]. The DDPG algorithm has been successfully used to deal with decision-making problems involving continuous action spaces in various vehicle control applications [
28], such as trajectory planning [
29], automatic lane changing [
30], and optimal torque distribution [
31,
32,
33]. To overcome the shortcomings of the original DDPG in the training process, many learning tricks have been proposed to make the training more efficient and the convergence more stable. In [
34], the authors proposed a DDPG-based controller that allows UAVs to fly robustly in uncertain environments. Three learning tricks—delayed learning, adversarial attack, and mixed exploration—were introduced, to overcome the fragility and volatility of the original DDPG, which greatly improved the convergence speed, convergence effect, and stability. In [
35], a control approach based on Twin Delayed DDPG (TD3) was proposed, to handle the model-free attitude control problem of On-Orbit Servicing Spacecraft (OOSS), under the guidance of a mixed reward system. The Proportional–Integral–Derivative (PID) guide TD3 algorithm effectively increased the training speed and learning stability of the TD3 algorithm, through the use of prior knowledge. In [
36], an improved energy management framework that embeds expert knowledge into the DDPG was proposed for hybrid electric vehicles (HEVs). By incorporating the battery characteristics and the optimal brake specific fuel consumption of HEVs, the proposed framework not only accelerated the learning process, but also obtained better fuel economy. In [
37], the authors proposed a knowledge-assisted DDPG for the control of a cooperative wind farm, by combining knowledge-assisted methods with the DDPG algorithm. Three analytical models were utilized to speed up the learning process and train robustly.
To summarize the above work, kinematic methods are incapable of overcoming unexpected wheel slip, while dynamics methods can, theoretically, effectively control wheel slip within a limited range. However, the implementation of dynamics methods requires complicated functions, in order to estimate the vehicle model and the wheel–ground interactions, which are difficult to apply in practice [
38]. The RL algorithm iteratively explores the optimal control strategy of the system in the training process, and the associated neural networks can approximate the dynamics model and wheel–ground interactions. Therefore, an RL-based torque distribution strategy for skid-steering vehicles is incorporated into our work.
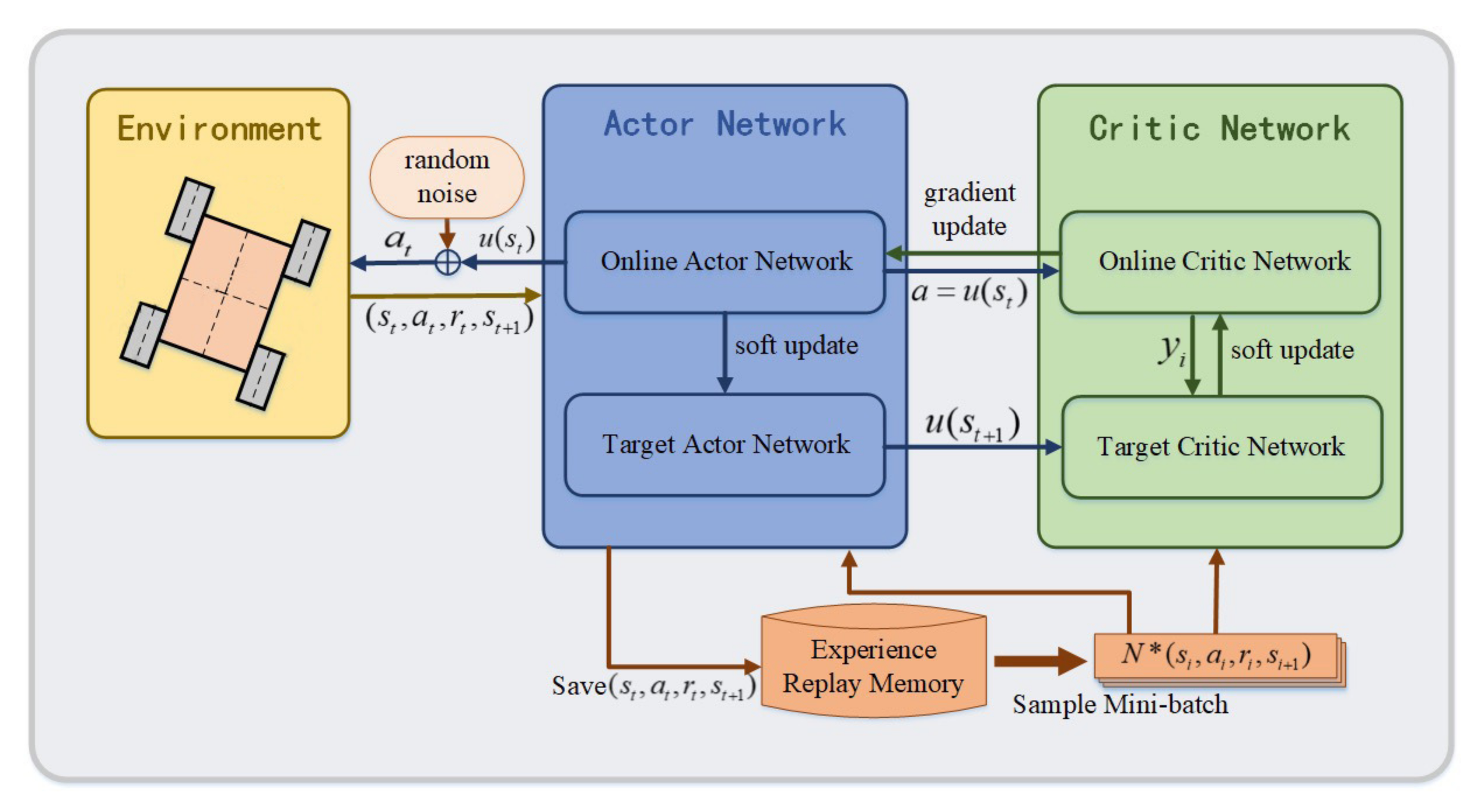
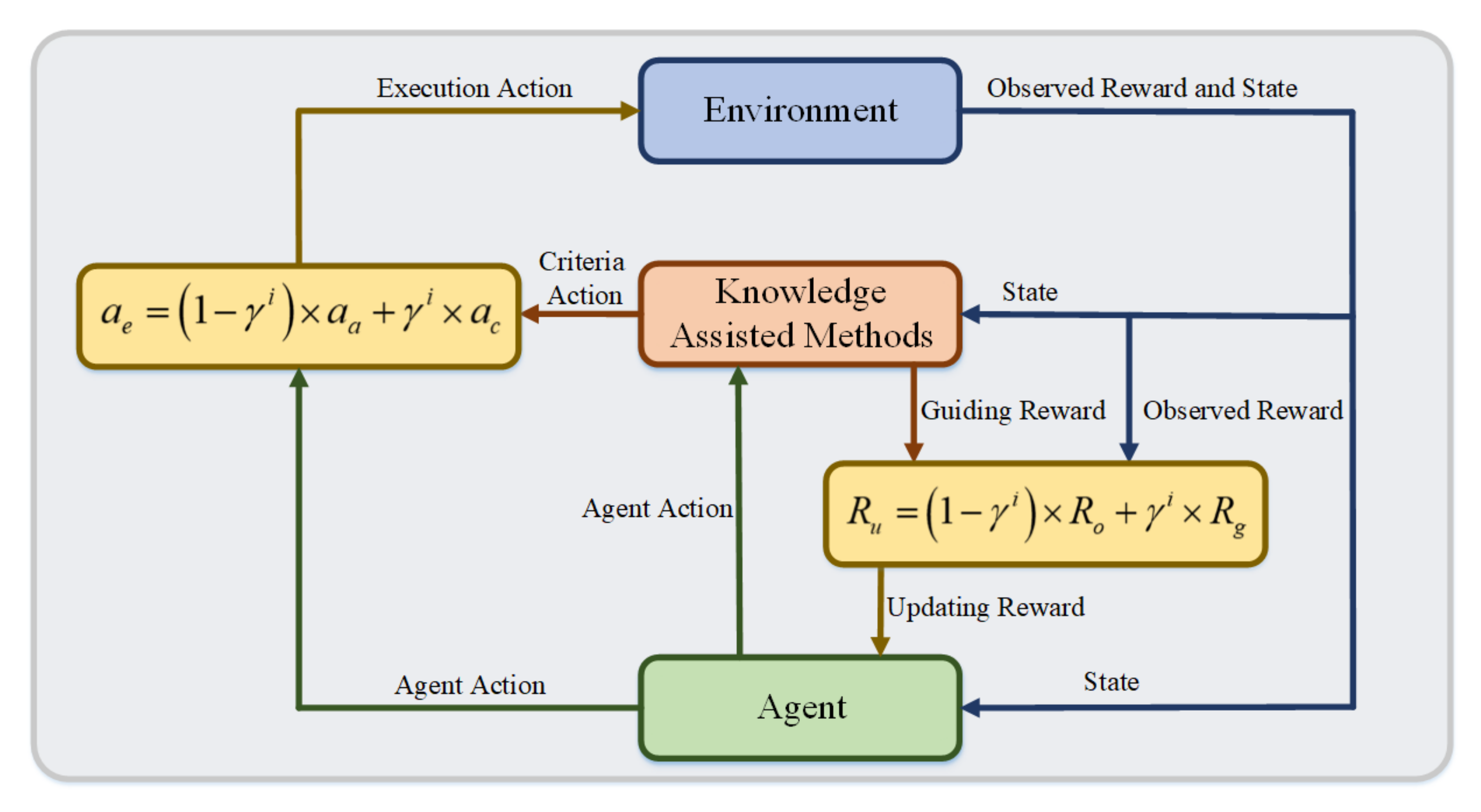
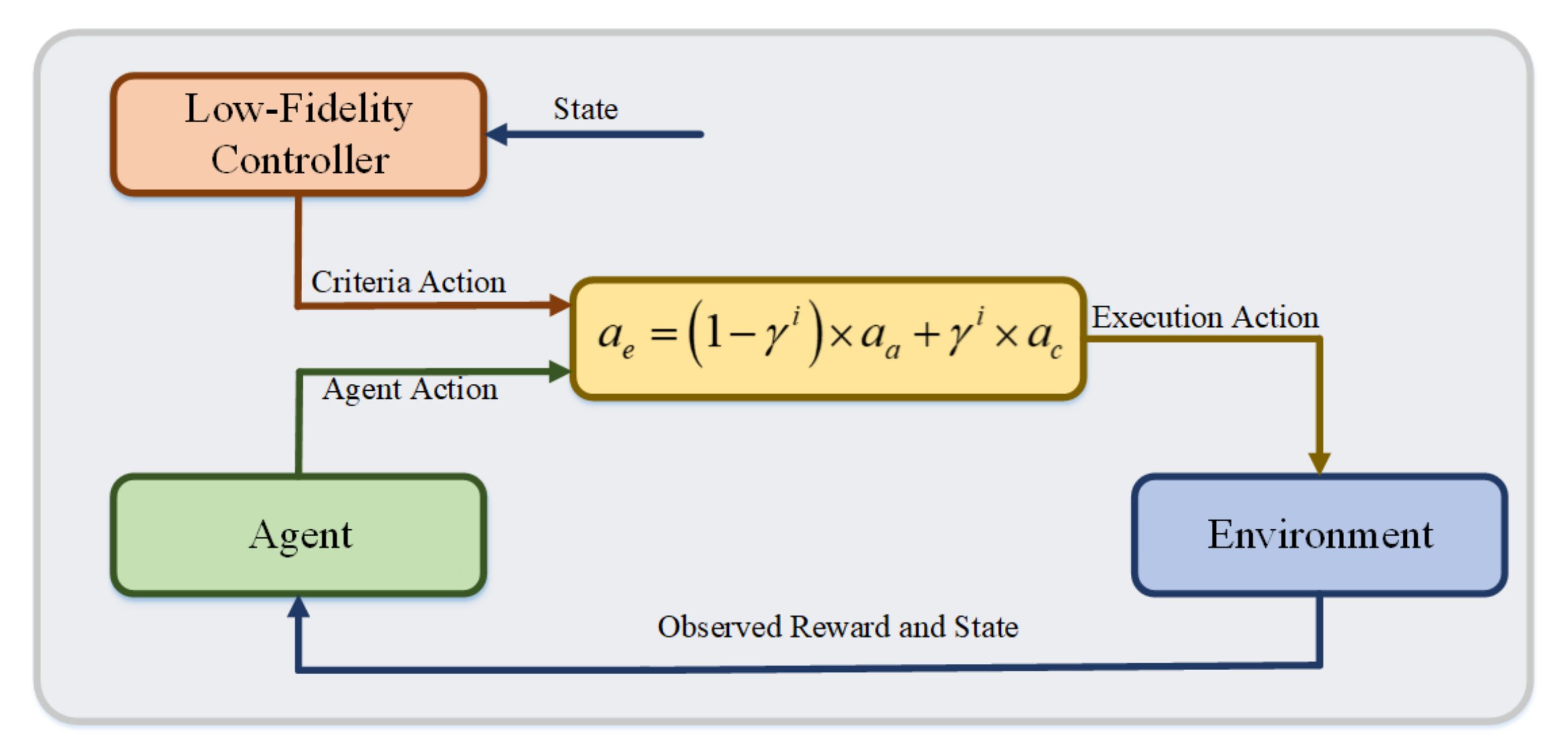
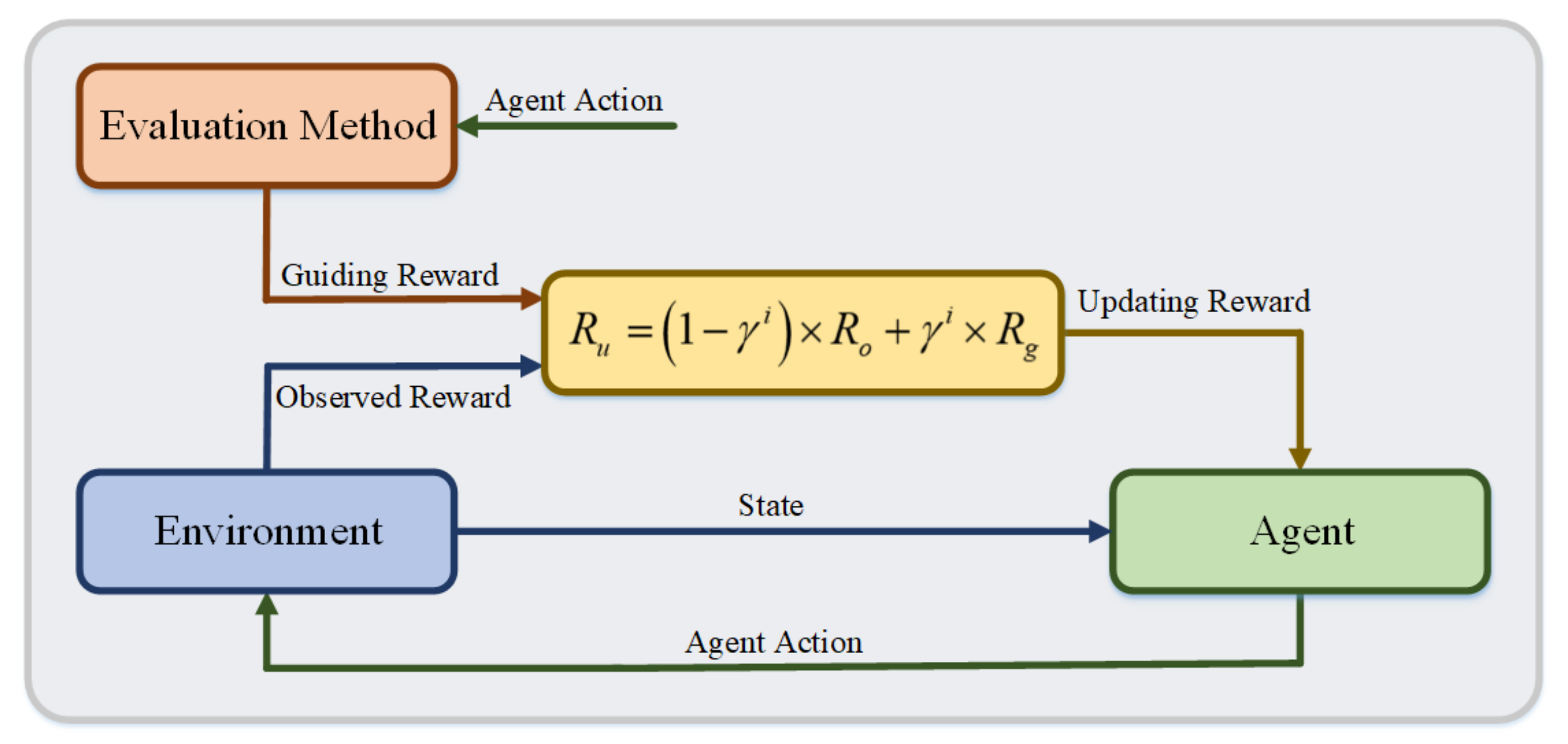
In this study, we propose a KA-DDPG-based driving torque distribution method for skid-steering vehicles, in order to minimize the tracking error, with respect to the desired value. We, first, analyze a dynamics model of skid-steering vehicles for torque distribution. Then, the agent of the KA-DDPG algorithm is designed for vehicle control. Based on the torque distribution strategy of KA-DDPG, we can achieve longitudinal speed and yaw rate tracking control for skid-steering vehicles. The main contributions of this study can be summarized as follows: (1) a KA-DDPG-based torque distribution strategy is proposed for skid-steering vehicles, in order to minimize the errors of the longitudinal speed and yaw rate, thus realizing the tracking control of the desired value; (2) considering the learning efficiency of the KA-DDPG algorithm, the knowledge-assisted RL framework is proposed by combining two knowledge-assisted learning methods with the DDPG algorithm; and (3) a dynamics model for skid-steering vehicles is constructed, in order to evaluate the performance of the proposed method.
The remainder of this paper is organized as follows.
Section 2 consists of two parts: one addressing the dynamics model of skid-steering vehicles, and another focused on the DDPG algorithm.
Section 3 presents our KA-DDPG-based torque distribution method for skid-steering vehicles. The settings of the simulation environment are detailed in
Section 4. In
Section 5, the performance of the KA-DDPG-based torque distribution strategy and the contributions of the assisted learning methods in KA-DDPG are illustrated.
Section 6 concludes this work and discusses possible future work.
4. Simulation Environment Settings
In the simulations, we considered the dynamics model of skid-steering vehicles with four independent driving wheels, which includes vehicle body dynamics, wheel dynamics, and the wheel–ground interaction model. It is important to note that we consider the vehicle as running on flat ground with friction coefficient
.
Table 1 provides the detailed vehicle dynamics settings used in the simulations.
The KA-DDPG algorithm was implemented on the PyCharm IDE with Python 3.7, and ran on an Intel Core i5 computer. Based on the definition of the agent, the actor network and its target network were constructed, using two
fully connected neural networks, and the critic network and its target network were constructed using two
fully connected neural networks. The structures of the neural networks are shown in
Figure 7, and the detailed parameters of the KA-DDPG algorithm are listed in
Table 2.
Based on the simulation environment design described above, training was carried out for a total of 5000 episodes, and the designed agent learned the torque distribution strategy. During training, the vehicle state was randomly initialized in each episode. Due to the two newly introduced knowledge-assisted learning methods, the training of the KA-DDPG converged quickly and stably. After completing the learning, only the parameters of the actor network were retained, which then received the current state of the vehicle in real-time and generated the optimal distributing action, in order to realize control of the vehicle.
5. Results and Discussion
Simulations were first conducted to demonstrate the control performance of the KA-DDPG-based torque distribution method. The vehicle behaviors are discussed under different scenarios, including a straight scenario and a cornering scenario. Furthermore, we verified the contributions of the knowledge-assisted learning methods in the learning process of the KA-DDPG algorithm, through three different cases.
5.1. Effectiveness of KA-DDPG
In order to verify the control performance of the KA-DDPG-based torque distribution method for skid-steering vehicles, the simulations were designed with two different scenarios: a straight scenario and a corning scenario. The low-fidelity controller defined in
Section 3.2.2 was considered as the baseline for comparative experiments, which is a controller based on physical knowledge. We introduced an evaluation method that is, commonly, used to quantitatively evaluate longitudinal speed and yaw rate tracking performance. This evaluation method uses the integral of the quadratic function of the tracking error of the longitudinal speed and yaw rate, to evaluate the tracking performance. The integrals
and
are, respectively, expressed as follows [
41]:
In the straight scenario, the desired yaw rate was always kept at 0 rad/s, in order to identify the drift of the skid-steering vehicle. The desired longitudinal speed changed during the simulation, which was set to
m/s at the beginning of the simulation, to
m/s and
m/s at 200 s and 400 s, respectively, and, then, kept at
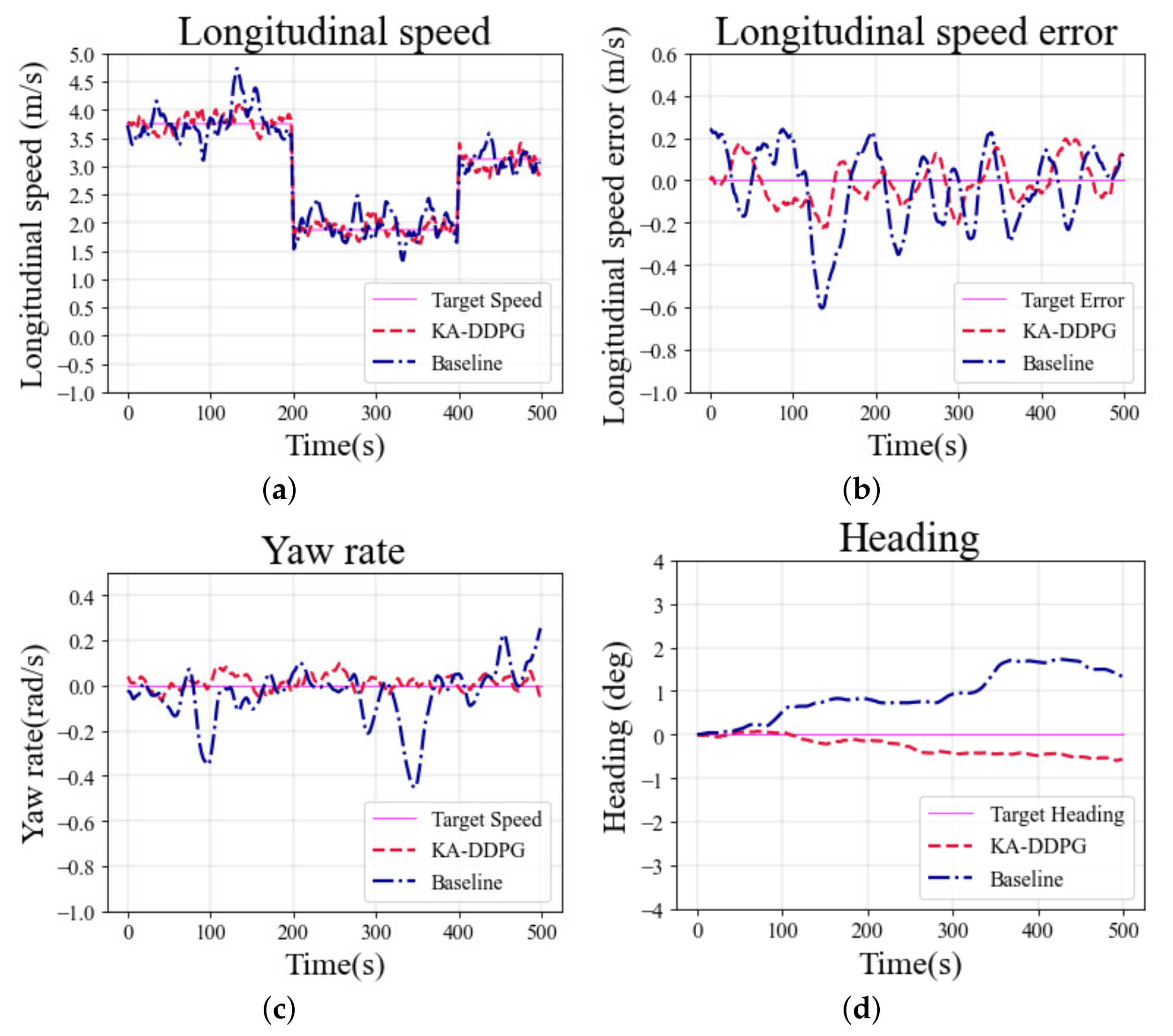
m/s until the end. The simulation results for the straight scenario are shown in
Figure 8.
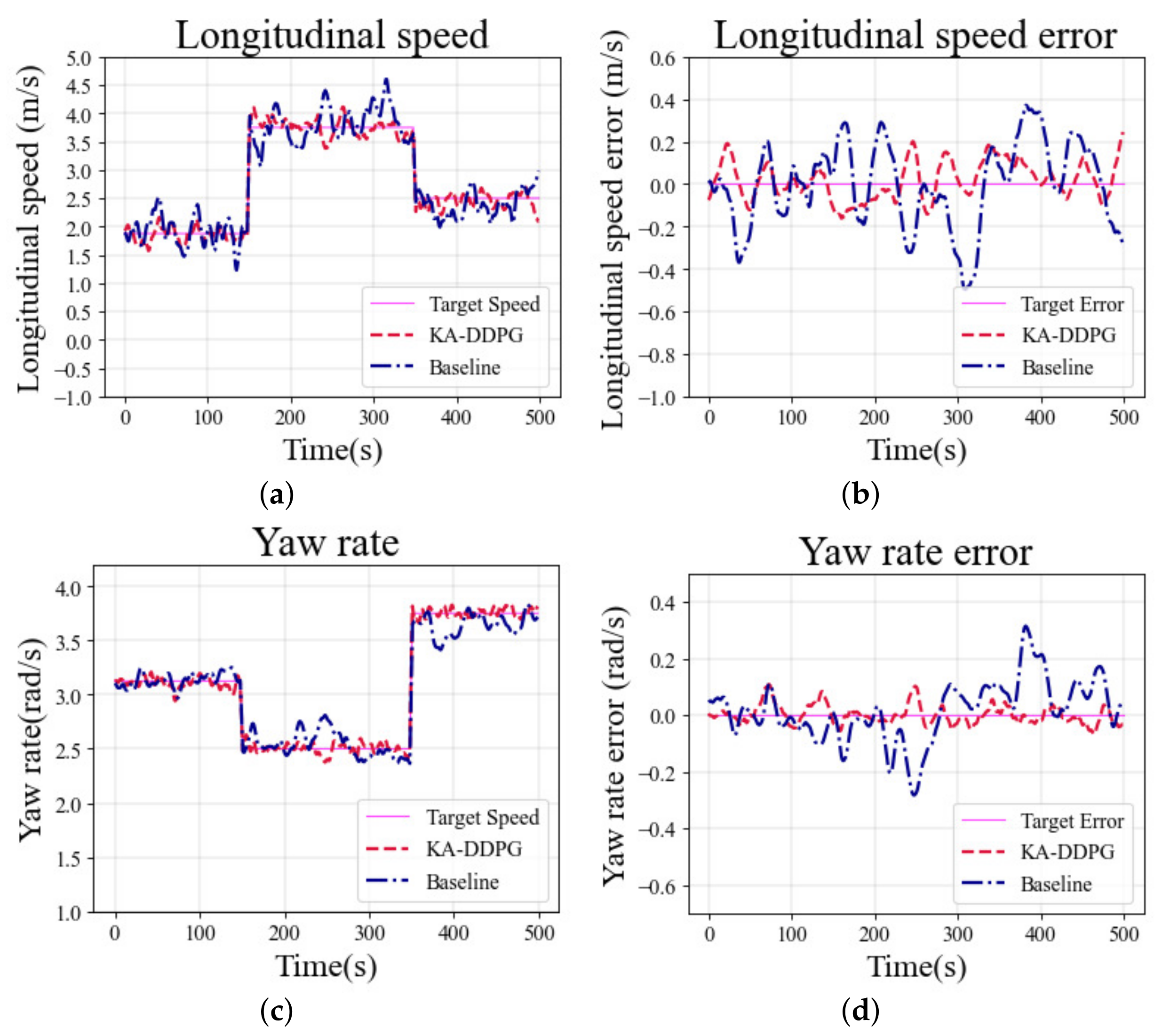
Figure 8a shows a comparison of longitudinal speed tracking, for the different torque distribution methods in the straight scenario. To more clearly demonstrate the tracking performance for longitudinal speed,
Figure 8b shows the corresponding tracking error. The tracking error of the baseline method fluctuated greatly, and the longitudinal speed tracking performance was significantly worse than that of KA-DDPG. The tracking error of the baseline frequently exceeded
m/s, while the maximum error of KA-DDPG was always stably kept within
m/s.
Figure 8c shows a comparison of the yaw rate tracking performance in the straight scenario. It can be emphasized that the target yaw rate is a constant value in the straight scenario, which is always 0 rad/s. The tracking results show that KA-DDPG kept the tracking error of the yaw rate within
rad/s, while the maximum tracking error of the baseline exceeded
rad/s. As shown in
Figure 8d, the heading of the baseline was larger than that of KA-DDPG, indicating that the vehicle controlled by the baseline suffered from greater drift. These simulation results demonstrate that the tracking performance of the KA-DDPG algorithm, for the longitudinal speed and yaw rate in the straight scenario, was better than that of the baseline.
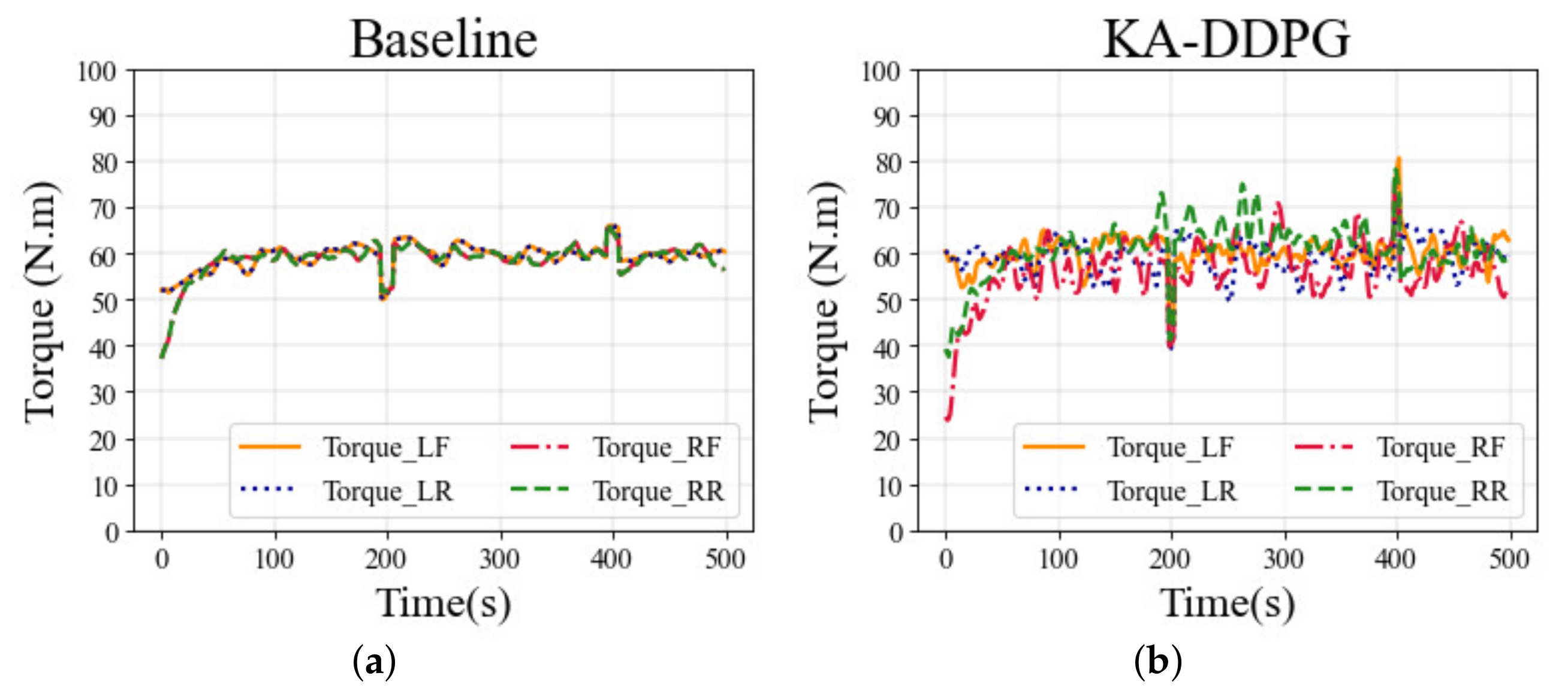
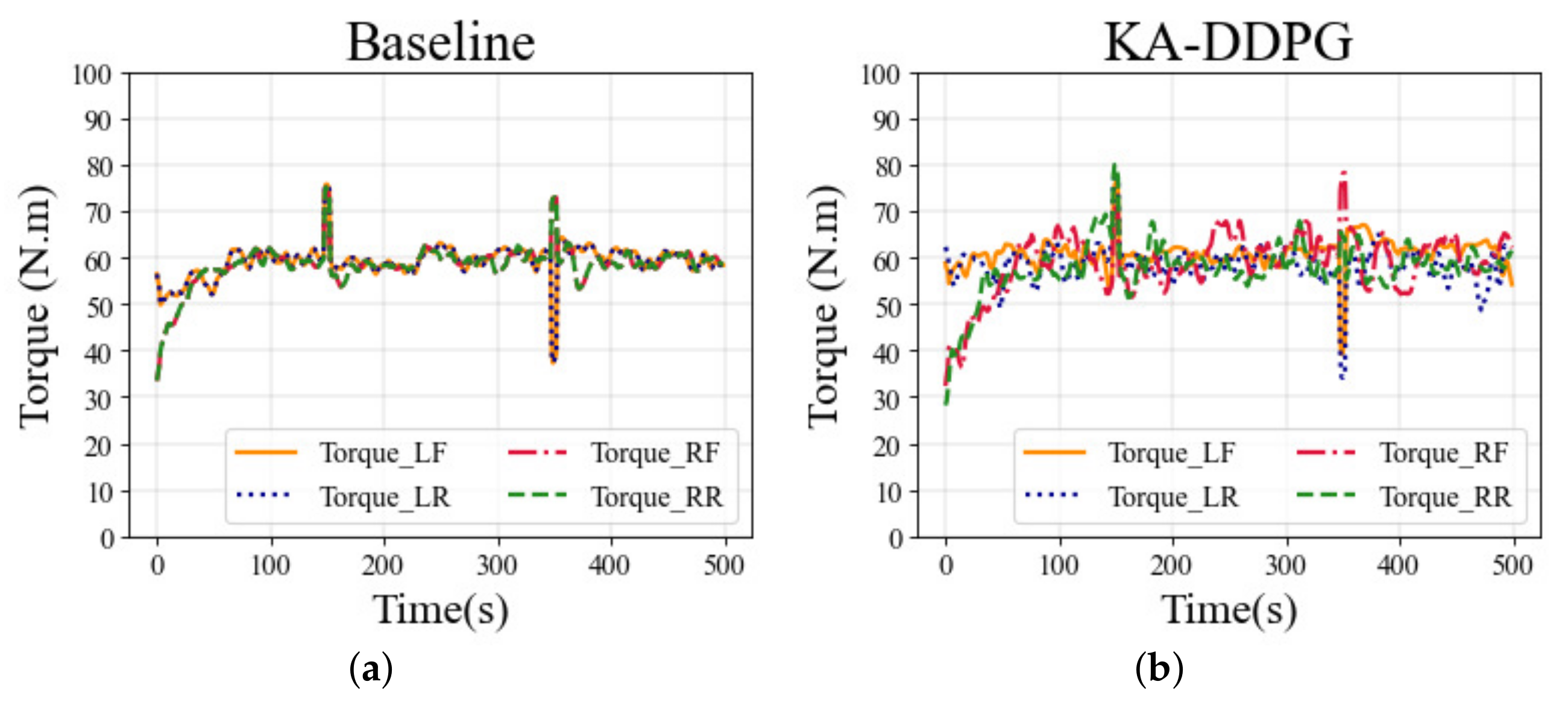
Figure 9 shows the torque distribution curves for each wheel in the straight scenario, and the torque distributions of the two different methods had similar trends. However, the driving torques of the KA-DDPG algorithm reflect the vehicle’s situation more quickly than the baseline, which explains why the KA-DDPG algorithm presented better tracking performance than the baseline.
To verify the cornering ability of the KA-DDPG-based torque distribution method, the simulations were conducted in a cornering scenario. Compared to the simulations in the straight scenario, the tracking performance of the proposed torque distribution method was more rigorously verified in the cornering scenario. The longitudinal speed of the vehicle was set to
m/s at the beginning of the simulation,
m/s at 150 s,
m/s at 350 s, and, then, held at
m/s until the end. The yaw rate was no longer a constant value, which was set to
rad/s at the beginning of the simulation,
rad/s at 150 s,
rad/s at 350 s, and, then, held at
rad/s until the end of the simulation. The tracking performances of the different methods in the cornering scenario are shown in
Figure 10.
Figure 10a shows the longitudinal speed tracking results in the cornering scenario, and it can be seen, intuitively, that the longitudinal speed tracking performance did not deteriorate significantly, compared with the straight scenario.
Figure 10b shows the tracking errors of the longitudinal speed in the cornering scenario. The maximum error of the baseline exceeded
m/s, while the maximum error of the KA-DDPG method was kept within
m/s. The yaw rate tracking performance of different methods is shown in
Figure 10c, while
Figure 10d shows the tracking errors of the yaw rate in the cornering scenario. The KA-DDPG method kept the yaw rate error within
rad/s, which was significantly smaller than that of the baseline. In the cornering scenario, the tracking performance of the KA-DDPG method was still better than that of the baseline, which is the same as the conclusion in the straight scenario, indicating that the tracking performance did not deteriorate in a more complex scenario.
Figure 11 shows the torque distribution curves, for each wheel in the cornering scenario. The torque distributions of the different methods in the cornering scenario showed the same trend as in the straight scenario, and the driving torques of the KA-DDPG method changed more quickly than those of the baseline method.
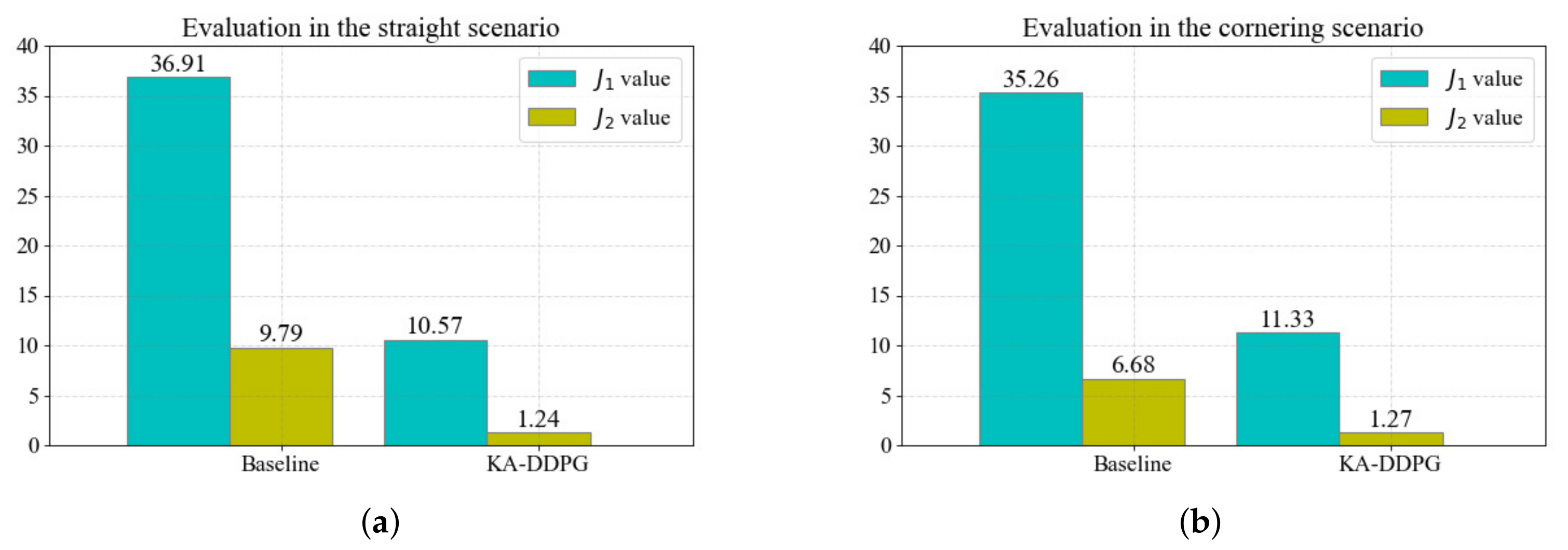
To quantitatively illustrate the tracking performance more specifically, Equation (
23) was introduced, to evaluate the tracking performance of the longitudinal speed and yaw rate. The quantitative evaluation results for the simulations in the straight scenario and the cornering scenario discussed above are displayed in
Figure 12.
Figure 12a shows the quantitative evaluation in the straight scenario. In 500 s of straight driving,
in the KA-DDPG method was reduced by
, compared to the baseline. Similarly,
of the KA-DDPG method was reduced by
, compared to the baseline. The quantitative evaluation demonstrated that the KA-DDPG method has better tracking performance for the longitudinal speed and yaw rate than the baseline in the straight scenario, consistent with the results of the above analysis. The quantitative evaluation in the cornering scenario is shown in
Figure 12b. Compared with the evaluation results of the baseline, in the simulation under the cornering scenario,
of the KA-DDPG method was reduced by
, and
was reduced by
, when compared to the baseline. These quantitative evaluations in different scenarios demonstrate that the KA-DDPG method has better desired value tracking performance than the baseline.
Based on the analysis of the simulation results, the tracking performance of skid-steering vehicles, based on the KA-DDPG method, was investigated. Compared with the baseline, the KA-DDPG-based torque distribution method showed better tracking performance in different scenarios. Although the baseline is a low-fidelity controller, it was sufficient to illustrate that the KA-DDPG method can be successfully applied to the torque distribution problem of skid-steering vehicles.
5.2. Contributions of Knowledge-Assisted Learning Methods
To verify the contributions of the knowledge-assisted learning methods in the learning process of KA-DDPG, we trained the KA-DDPG algorithm, with three cases. The configurations of these cases were as follows: (1) the KA-DDPG, including the criteria action and guiding reward methods (i.e., the algorithm proposed in this work); (2) the KA-DDPG, only including the guiding reward method; and (3) the KA-DDPG, only including the criteria action method. As the skid-steering vehicle studied in this paper is an overdrive system, applying the original DDPG may cause the agent to search in a wrong direction, leading to a sub-optimal solution. Therefore, we do not consider the torque distribution method, based on the original DDPG, in this section. In each case, the KA-DDPG was trained for 5000 episodes. During training, the vehicle state was randomly initialized in each episode. To verify the stability of the convergence, the training in each case was repeated five times.
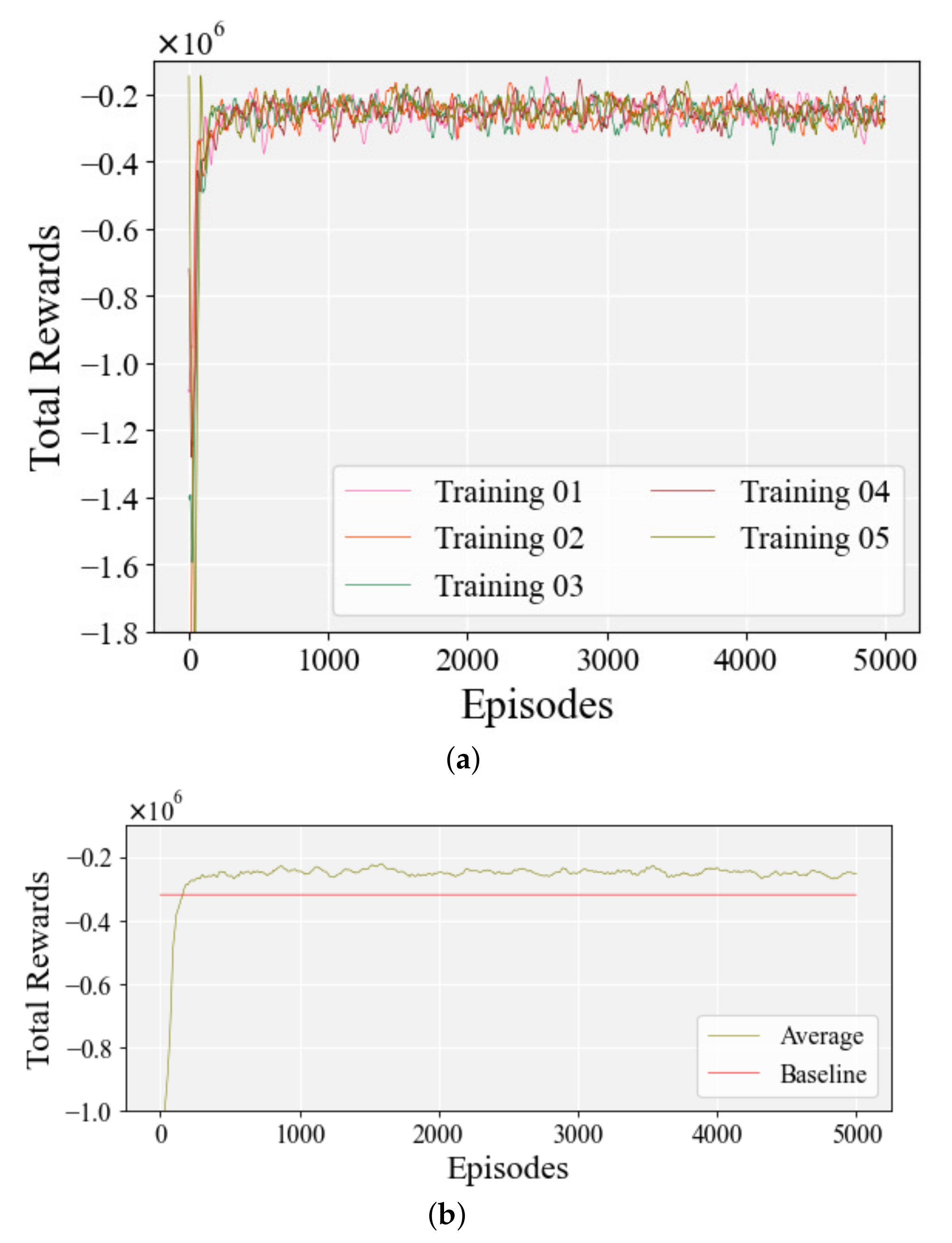
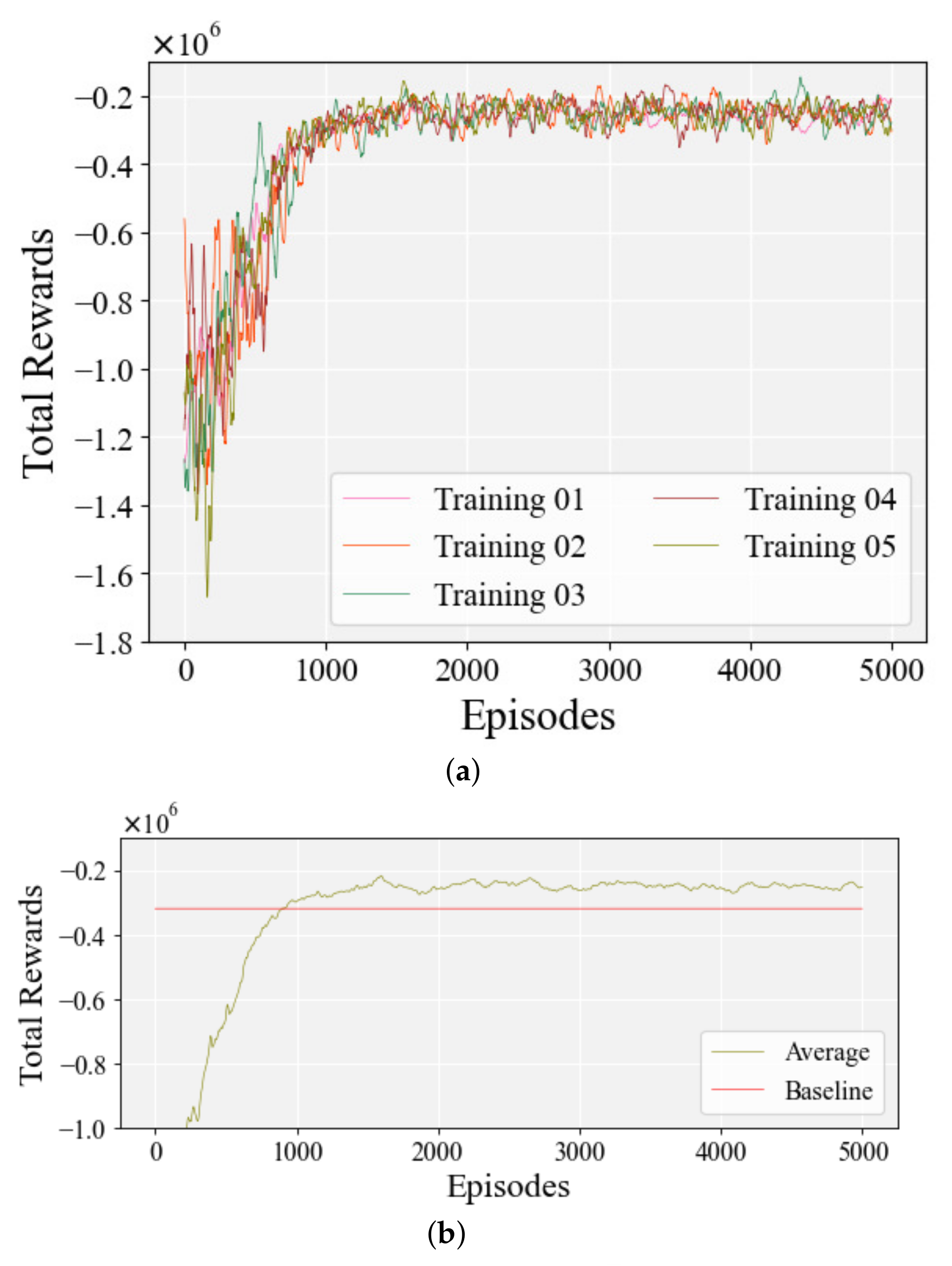
Figure 13 shows the total rewards during the learning process of the first case, which is the case of KA-DDPG with both of the assisted learning methods. As shown in
Figure 13a, the rewards converged quickly and smoothly in each learning process. Such learning processes indicate that the agent can still stably learn a reasonable torque distribution strategy, to ensure the control performance. With the assistance of knowledge-assisted learning methods, the agent no longer randomly generates actions with low rewards during the learning process, and has the ability to rapidly increase the cumulative rewards, which not only accelerated the convergence of the learning process, but also ensured that the convergence was smooth. As shown in
Figure 13b, on average, the KA-DDPG-based torque distribution method outperformed the baseline in cumulative rewards after training for 200 episodes, which means that KA-DDPG not only learns control policies from the low-fidelity controller, but also explores and learns policies for better control performance. At about 300 episodes, each learning process converged smoothly.
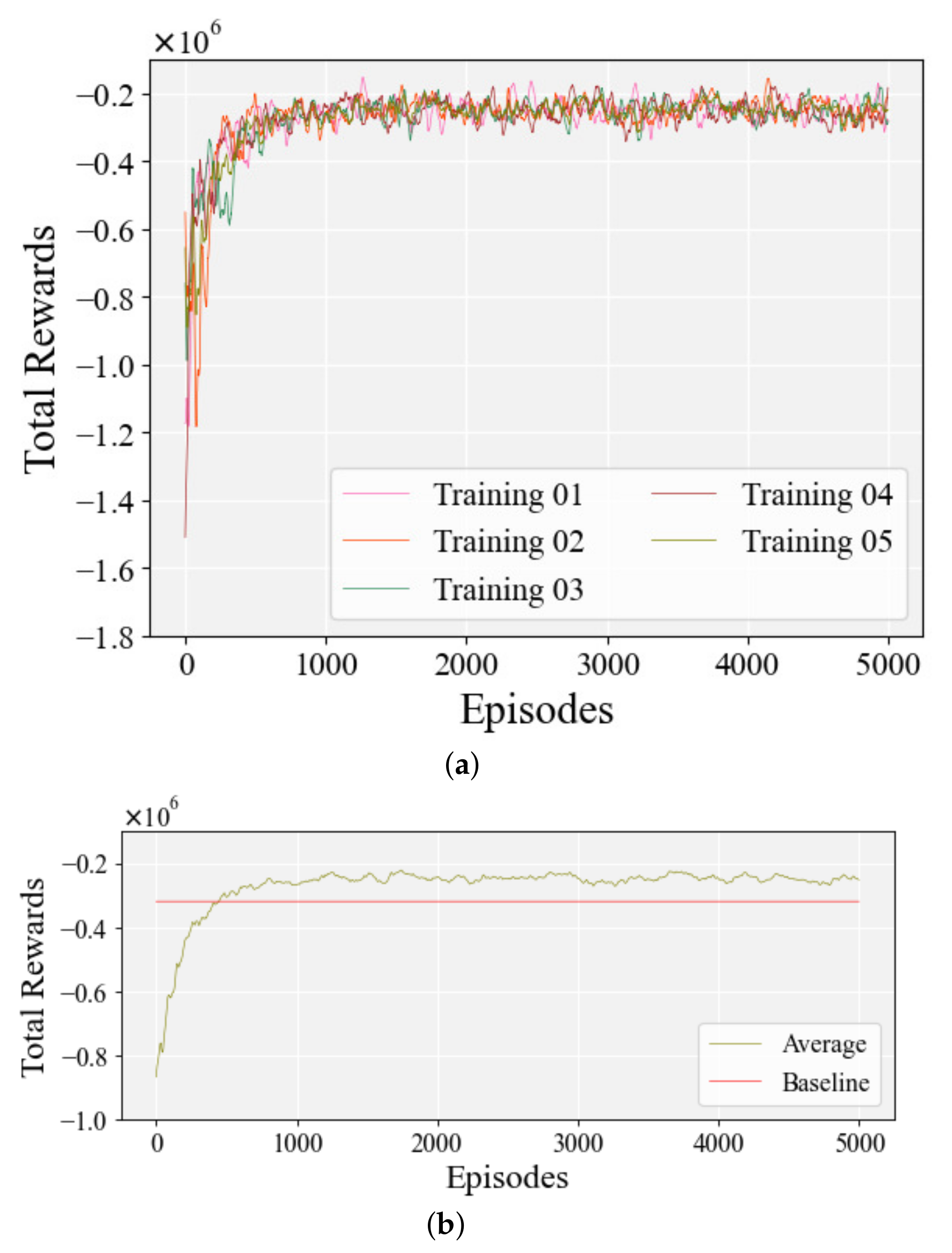
Then, we trained the KA-DDPG, including only the guiding reward method and without the criteria action method, in order to illustrate the contribution of the criteria action method.
Figure 14 shows the learning process of the KA-DDPG, without the assistance of the criteria action method. Without the assistance of criteria actions, execution actions were searched randomly at the beginning of the learning process, making the rewards more volatile. As the number of episodes increased, the volatility of the total rewards decreased, and the learning process converged stably.
Figure 14a shows the total rewards in each learning process, and
Figure 14b shows the average of the total rewards. Without the assistance of the criteria action method, the KA-DDPG needed about 800 episodes to perform better than the baseline, while the first case (including both assisted learning methods) only took about 200 episodes to achieve the same result. Similarly, the convergence of KA-DDPG, without the criteria action method, was, also, slower than the first case, taking about 1200 episodes to converge. Such results illustrate that the learning cost of KA-DDPG is greatly increased without the assistance of the criteria action method. The above simulation results demonstrate that the criteria action method reduces the learning cost, by helping the agent to reduce the randomly selected actions in the learning process.
Finally, we trained the KA-DDPG, including only the criteria action method, in order to illustrate the contribution of the guiding reward method.
Figure 15 shows the learning process of the KA-DDPG algorithm, without sharpening the reward through use of the guiding reward method. Compared to the first case, KA-DDPG, without the guiding reward method, had a larger reward at the beginning of the learning process, but it grew more slowly and showed more volatility. The simulation results demonstrated that the guiding reward method in KA-DDPG led the learning process to converge faster, by sharpening the reward function.
Figure 15a shows the total rewards of KA-DDPG, without the guiding reward method in each learning process, while
Figure 15b shows the average of the total rewards. Without the assistance of the guiding reward method, KA-DDPG needed about 500 episodes to outperform the baseline, while only about 200 episodes were needed to achieve the same control performance, when using both assisted learning methods. Similarly, KA-DDPG, without the guiding reward method, needed about 800 episodes to converge, which was also slower. These simulation results demonstrate that the guiding reward method, also, has the ability to reduce the learning cost. However, unlike the criteria action method, which reduces the learning cost by reducing randomly selected actions, the guiding reward method achieves this purpose by sharpening the reward function.
To summarize, the simulation results presented above demonstrate that both of the assisted learning methods proposed in this paper can reduce the learning cost of the KA-DDPG algorithm. The guiding reward method accelerates the learning process, by sharpening the updating reward with the assistance of the evaluation method, whereas the criteria action method achieves this through providing the learning direction by criteria actions, thus reducing the randomly searched actions.
5.3. Discussion
To verify the KA-DDPG based torque distribution strategy, we conducted the desired value tracking performance evaluation in two different scenarios, by comparing with the controller used for assisted learning. The contribution of the assisted learning methods was, also, verified by comparing the learning process of different cases of the KA-DDPG algorithm.
For the desired value tracking performance evaluation, quantitative evaluations in different scenarios show that the KA-DDPG method had smaller desired value tracking errors than the baseline. In other words, the KA-DDPG method had a better desired value tracking performance. The great improvements in the tracking performance come from the fact that the KA-DDPG algorithm not only learned from the knowledge-assisted learning methods but also explored the better distribution strategy, through the exploration ability of RL.
For the contribution of knowledge-assisted learning methods evaluation, we trained the KA-DDPG algorithm, with different configurations on three cases, namely the KA-DDPG algorithm with two assisted learning methods and the KA-DDPG algorithm with only one of the assisted learning methods. The result is the KA-DDPG with two assisted learning methods converged with less learning time than the other cases. The great improvements in the learning process come from the knowledge-assisted learning methods. The guiding reward method accelerates the learning process, by sharpening the updating reward with the assistance of the evaluation method, whereas the criteria action method achieves this by providing the learning direction through criteria actions, reducing the randomly searched actions.
From all the simulation results, we conclude that the KA-DDPG algorithm, which combines the knowledge-assisted learning methods with the DDPG algorithm, can be successfully applied to the torque distribution of skid steering vehicles. This work lays a foundation for the use of RL technologies to directly distribute the torque of skid-steering vehicles, in future practical applications. The knowledge-assisted RL framework proposed in this work provides a powerful weapon for applying RL technologies in overdrive systems, such as skid-steering vehicles. However, the verification part of this paper was carried out in a simulation environment, so challenges do still exist to transfer the proposed method to a real application. For future research, we will consider reducing the reality gap in a real application.
6. Conclusions
In this study, a KA-DDPG-based torque distribution strategy for skid-steering vehicles was proposed, in order to minimize the tracking error of the desired value, which included the longitudinal speed and yaw rate, making the considered problem a dual-channel control problem. The KA-DDPG algorithm combines the DDPG algorithm with knowledge-assisted learning methods, constructing a knowledge-assisted learning framework that combines analytical methods with an RL algorithm. Two knowledge-assisted methods were introduced into the KA-DDPG algorithm: a criteria action method and a guiding reward method.
In order to validate the proposed strategy, simulations were first conducted in different scenarios, including a straight scenario and a cornering scenario. The tracking performance simulation results demonstrated that the proposed torque distribution strategy had an excellent control performance in different scenarios. In addition, simulations were conducted to verify the contributions of the assisted learning methods in the learning process of KA-DDPG. The simulation results illustrated that both of the proposed assisted learning methods helped to accelerate the agent’s learning process. The criteria action method provides the learning direction for the agent and speeds up the learning speed, by reducing the random search actions, while the guiding reward method achieves the same result by sharpening the reward function.
This work opens an exciting path for the use of RL algorithms in the problem of torque distribution in skid-steering vehicles. However, there are still some areas that require more in-depth study. The verification section of this research was carried out in a simulation environment, without any experiments being in a real environment. Wheel slip limits, which are important for skid-steering vehicle control, were not considered in this work. The lateral movement of the vehicle, which is unavoidable in actual applications, was, also, not considered in this work. At present, we are exploring these unsolved problems to extend this work.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}