1. Introduction
There is an unprecedented increase in the growth of mobile data traffic contributed by the advent of inexpensive smart electronic gadgets that are overburdening the scarce spectrum resources below 6 GHz [
1]. This tremendous burst of users’ data requests imposes network overhead to provide data to the users during peak-traffic hours. To handle high data demands, it is imperative to develop new communication techniques such as internet of things (IoT), data caching, and cloud computing [
2].
A hierarchical heterogeneous network comprised of macro and small cells is envisioned for 4G by 3GPP to ameliorate network density [
3]. Under the coverage of macro cells, multiple low-power and small coverage Small Base Stations (SBSs) are deployed and connected to the core network through a wired backhaul link [
4]. Conventionally, users fetch their required contents from the core network via serving SBSs, which not only incurs congestion at the serving SBS but also overburdens the backhaul link. It is an interesting fact that users’ data demands have a redundancy trend towards social networking, popular videos, and online gaming [
5]. However, networks are equipped with limited operational capacity, therefore they are unable to handle explosive data demands, resulting in data traffic congestion [
6]. Modern data traffic manifests reuse of asynchronous contents [
7], because a large amount of data traffic incurs a backhaul bottleneck problem, which degrades the Quality of Experience (QoE). To relieve the traffic burden over the backhaul link, caching appears to be a promising approach that can directly serve contents to the users [
8].
Caching at the network edge is recognized as an efficient way to mitigate bottleneck issues that arise due to SBSs’ densification [
9]. The data placement at the SBS level has the potential to serve users with immediate effects, which can significantly reduce the network delay [
10]. Therefore, the data placement at the SBS level has attracted tremendous attention from the research community. SBSs are located close to users, which can allow better data access by the users. Therefore, caching popular contents at the SBS level can fulfill users’ demands with minimum delay [
11]. There are three benefits of SBS level caching. First, popular contents are placed close to the users, which reduces latency. Second, redundant data transmission over backhaul and network congestion is reduced. Third, most of the users’ data requests are fulfilled through cache resources rather than the core network, which alleviates the backhaul link traffic congestion. These aforementioned advantages motivate data service providers to adopt new advanced technologies to improve QoE. Due to the capacity constraint on the cache resources, it is imperative to utilize scarce cache resources in an intelligent manner [
12]. For efficient data caching, the network must rely on accurate information in data requests for determining what and where to cache contents [
13]. Furthermore, the performance of a caching scheme is affected by the fluctuation in data traffic load over time, which leads to waste of bandwidth [
14]. To counter demand fluctuation issues, data placement during off-peak hours is a promising approach when it comes to meeting future users’ data demands for smoothing data traffic load. This appears to be an efficient way to optimize bandwidth utilization. Hence, it is imperative to shift the backhaul data traffic burden from peak to off-peak hours and perform data placement close to the users based on the predicted data popularity profile.
There are two categories of data caching schemes, i.e., static and dynamic caching schemes. In static caching schemes, cached contents remain the same [
15]. Moreover, all the static caching schemes perform data caching based on the data popularity profile and the inter-file correlation is not exploited to improve the network performance [
16]. However, dynamic caching schemes such as Least Frequently Used (LFU) and Least Recently Used (LRU) schemes update their cached contents with respect to time and new arriving contents to meet diverse users’ data demands [
17]. Also, stochastic network information can be exploited to optimize data placement. For instance, the diversity of data caching can be optimized by modeling the cache-enabled SBSs through homogeneous Poisson Point Process (PPP) [
18]. In addition, users’ mobility also poses significant challenges due to dynamic network connectivity and varying channel conditions; therefore, it is crucial to take users’ mobility patterns into account [
19]. Machine learning based caching schemes can be a potential approach to optimize 5G cellular network performance by learning and tracking users’ mobility patterns and spatio-temporal data popularity profiles [
20].
Motivated by the above mentioned prospects of data caching in a wireless network, in this paper we design an intelligent data caching approach to offload more data traffic through cache resources to minimize network delay. We implement data caching while considering users’ mobility and diverse data demands that introduce significant challenges. In addition, the RL approach is devised to optimize data caching without requiring any prior information. Moreover, we validated our proposed caching scheme performance under various network parameters such as varying cache capacity, data popularity profiling, etc. The prominent contributions of our work are summarized as follows:
We design a data caching approach in a 5G network comprised of a hierarchical heterogeneous network to minimize network delay. Moreover, we consider practical assumptions such as inter-cell interference and users’ mobility, which make our problem more arduous.
We model the data caching problem at the SBS level by considering evolving users’ data demands patterns. The data demands and cache states are taken as system states. Both the transmission of cached contents and replacement of old contents with new and more popular contents constitute the system action.
We propose a Q-learning based data caching scheme following a dynamic data popularity profile while taking cache capacity constraints and users’ mobility into account. It is notable that we formulate a tractable MDP in a mobility scenario, which is a highly challenging task.
Extensive simulations are conducted to demonstrate the performance of the propose caching scheme in minimizing network delay. The performance of our proposed Q-learning based caching scheme is compared with the four baseline caching schemes. These include learning based branch and bound (LB&B) [
21], least frequently used content caching (LFUCC) [
22], highly popular content caching (HPCC) [
23], and random content caching (RCC) [
24] schemes under different network parameters such as varying number of users, cache capacities, data popularity skewness, and data library sizes.
The rest of the paper is organized as follows.
Section 2 discusses the related works on data caching.
Section 3 provides detail of the system model. In
Section 4, we present problem formulation. In
Section 5, we discuss the Q-learning-based proposed data caching scheme. In
Section 6, we provide simulation results to demonstrate the performance gains of our proposed caching scheme. Finally,
Section 7 concludes the paper. Furthermore, the key notations are listed in
Table 1.
2. Related Works
There is an unprecedented growth in data traffic on online social apps and platforms that strained the limited backhaul resources of wireless networks. Therefore, Nimrah et al. [
25] proposed a proactive data caching mechanism to support interest-based user grouping for data sharing, while taking into account the complete information from the social graph for one-to-one interaction between users. The data caching entities are selected based on users’ profiles and revenue status. Then, the users’ group membership is approximated by utilizing users’ data demands logs without any prior information from the overlaid users’ social graph. The obtained results demonstrated a 30% to 34% performance gain in data access via cache resources. In [
26], the authors proposed a concept of data caching at aerial base stations and defined delay tolerant and delay sensitive users which have different data transmission rate requirements. The authors proposed an iterative algorithm that applies a decomposition method. The obtained results showed a significant improvement in utilization of backhaul resources.
Nowadays, many researchers are exploiting the potential of machine learning to optimize data caching in wireless networks. Shuja et al. [
27] provided a comprehensive survey about several machine learning approaches used in next generation edge networks. Doan et al. [
28] proposed a caching mechanism to predict data popularity profiles and estimation of popularity of new contents based on features extraction of existing contents and similarity with newly arrived contents. The authors extracted spatio-temporal features of existing and newly arrived contents with a convolution neural network (CNN) with several stage pooling. Then, a clustering algorithm based on Jaccard and cosine distance is devised to extract contents features to handle the dimensional. Afterwards, contents are classified into various categories by employing support vector machine (SVM). The obtained results showed significant performance gain.
However, in a realistic network, users are mobile, and the network condition keeps evolving. Hence, a mechanism is necessary that does not require prior information to train the system and can learn through interaction with the environment. Therefore, researchers consider implementation of RL to optimize data caching in wireless networks. One such effort is made by Xiang et al. [
29], where the RL approach is devised for content caching and wireless network slicing. The authors used a Zipf distribution to model users’ data demands, and the wireless network channel is designed as a finite state Markov channel. In [
30], the authors proposed data caching at the base station level. RL is devised to optimize cache allocation without any previous information in an online fashion. The proposed approach learns through direct perturbation of the environment and observing variation in the network performance.
3. System Model
A cache-enabled wireless network is depicted in
Figure 1, where cache-enabled SBSs are denoted by
. The cache capacity of each SBS is equal to
C. The users existing in the network are denoted by
. The distribution of SBSs and users follow Poisson Point Process (PPP) with intensity
and
, respectively. The users connected with serving SBS
s are represented by a binary element
, where
if user
u is connected to SBS
s, otherwise
. We consider that the network contains a data library of
F contents represented by the set
, where each content is of equal size
. Then, we used a Zipf distribution to capture the spatial heterogeneity of the data popularity profile [
31] as follows:
where
denotes the contents popularity distribution skewness that controls spatial heterogeneity of contents popularity. It is imperative to design an optimal caching strategy
X to improve data access via cache resources. We define a decision variable
to determine whether content
f is cached by serving SBS
s or not. If
, then content
f is cached by SBS
s, otherwise it is equal to 0. Thus, when a user
u requests content
f from serving SBS
s, then SBS
s decides transmission of content
f based on the caching strategy
X.
3.1. Mobility
In a wireless network, users exhibit mobility that causes complexity for data caching. Therefore, it is imperative to examine the influence of users’ mobility on data access through the cached resources. When users roam around, their connection to serving SBS is unstable, and requires an effective data caching mechanism to provide users’ their desired contents efficiently. Therefore, mobility patterns of users’ are observed by dividing the communication time between a user and serving SBS into
T time slots, which is expressed by
. A user is considered static in the first time slot and moved to another position in the second time slot. In this manner, the communication time period between user
u and serving SBS
s is represented as follows:
where
represents contact duration between serving SBS
s and user
u, and
represents the user
u under the coverage of SBS
s.
and
denote the location of SBS
s and user
u, respectively.
follows an exponential distribution with parameter
to determine a contact pattern between SBS
s and user
u.
3.2. Transmission Model
When a user
u demands a content
f from its serving SBS
s, the desired content is transmitted with a data transmission rate [
32] that is evaluated as
where
W is the bandwidth to user
u and
represents the received signal to interference and noise ratio. Here
is evaluated as follows:
where
represents the transmission power of SBS
s,
represents the distance between serving SBS
s and user
u.
represents the path loss exponent, and
represents the inter-cell interference. However, by utilizing interference mitigation mechanisms such as spectrum reuse, power control, and alignment of interference, the inter-cell interference is considered as a constant noise.
4. Problem Formulation
Let
represent the average content
f access delay for user
u from its serving SBS
s for caching strategy
X. At least
time slots are required for successful transmission of content
f. Thus, the minimum number of time slots for successful data transmission from the serving SBS
s to the user
u is determined as
where
represents time duration of a complete time slot. Thus, for user
u, average delay of receiving content
f is determined as
The delay experienced by user
u in obtaining content
f from serving SBS
s is evaluated as
When content
f is not cached by serving SBS
s, then first content
f is fetched from the core network through a backhaul link before transferring content
f towards the demanding user.
where
represents extra delay of data transmission from core network to serving SBS
s. According to [
33],
is much larger than
and the impact of
X on
is negligible. Therefore, the average delay
is fixed and can be determined by the average time of content
f downloading from core network to the serving SBS
s of user
u.
In this work, our objective is network delay minimization while taking into account evolving users’ data preferences. Here, we formulate our objective function as
where constraint (
10) sets a cache capacity constraint on the SBS. Our problem is NP-hard. Hence, it is challenging to find an optimal caching solution. Therefore, we utilize a machine learning approach known as reinforcement learning (RL) to optimize data caching in wireless networks while taking into account limited cache capacity and users’ diverse data demands.
5. Q-Leaning Based Data Caching
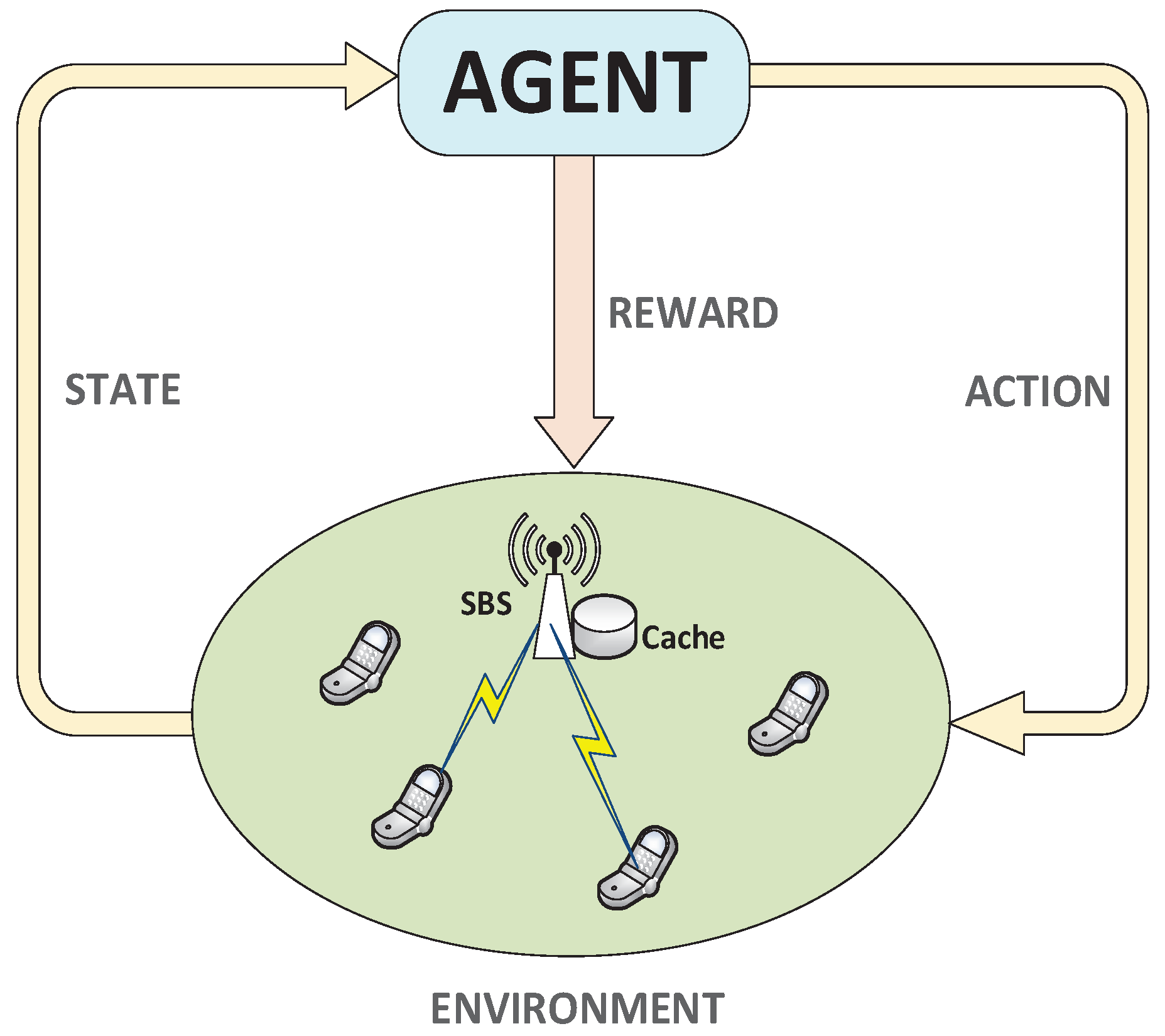
An illustration of RL-based data caching is provided in
Figure 2. The efficiency of the data caching mechanism is measured by determining the delay experienced by the users accessing the data from the serving SBS. Therefore, we devise Q-learning based data caching at the SBS level. Q-learning constituted by state, action, and reward.
State: State () is the set of cache states of serving SBS s, , where represents the contents placement of SBS s that is represented as .
Action: Action () is the set of actions to optimize caching at SBS s. We define action set as to perform an adjustment of cached contents in the SBS s.
Reward: is the reward provided to the SBS in return for performing an action a during state m, which is an expected reduction in data access delay from the cache resource.
The process of caching in SBS s at time t is described as
The current cache set of SBS s is sensed at time t, i.e., .
Based on the current cache state , an action is selected by SBS s.
The system transfers to a new state in result of action . Moreover, in result of this transition a reward is obtained.
The reward is provided to the SBS s and the whole process is repeated.
Our objective is to enhance rewards to reduce data access delay via cached resources. To increase rewards, it is necessary to perform optimal actions. A state-value function
V is defined to determine data caching efficiency in the following manner:
where
represents the discount factor to determine the effect of future rewards on the current action decisions.
We utilize Q-learning to determine the optimal caching policy
for SBS
s, which corresponds to
V without prior system information. Since the cache decision is taken in an independent manner, optimal
for SBS
s is determined as follows:
Moreover,
is estimated by defining Q-value for every state-action pair. An optimal Q-value for SBS
s is defined in the following manner:
where
represents the current state of SBS
s,
represents the state transfer in result of performing an action
at state
, and
represents the probability of system transition from state
to
.
is evaluated by calculating the difference between gain of caching fresh content and loss of removing old content as follows:
where
represents increase in data access via cache resources in result of caching new content. However, loss of replacing old content is evaluated as
where
represents decrease in data access via cached resources as a result of removing previous content. Then, the reward function is determined as
Then, the relationship between value function
and Q-value is as follows:
If for every state-action pair an optimal Q-value is known, then an optimal policy is determined as
is determined by the Q-learning algorithm in a recursive manner by utilizing the update rule for SBS [
34].
where
represents learning rate,
is the state transition from state
as a result of an action
at time
t, where
.
The details of pseudo code of the proposed Q-learning based caching algorithm is provided in Algorithm 1. First, state-action pairs are initialized for the Q-learning caching mechanism. Then, actions
are selected by iterative evaluation of state-action pairs to maximize the Q-function. As a result of the selection of better actions, the system rewards are enhanced according to Equation (
18). Thus, SBS
s can cache contents that can potentially improve long term reward. In steps 9 and 10, the reward is achieved and system transition to a new state occurs. Finally, the Q-table is updated based on the rewards achieved. The proposed scheme evaluation has a complexity
. Moreover, Q-values are updated in each iteration; therefore, the proposed scheme update has a complexity
.
| Algorithm 1 Q-Learning based Data Caching at SBS level. |
- 1:
Initialize Q-value for every state-action pair. - 2:
fordo - 3:
Choose a random probability p. - 4:
if - 5:
, - 6:
otherwise, - 7:
randomly select an action . - 8:
Execute action in the system. - 9:
Obtain reward . - 10:
transits to the next state and enter the next interval. - 11:
update,
- 12:
end for
|
6. Performance Evaluation
A realistic mobility trajectory collected in Korea Advanced Institute of Science & Technology (KAIST), Korea is devised to model mobility patterns of users. The mobility patterns of users are observed through Garmin GPS 60CSx receivers. We exploit the
greedy policy to maintain a balance between exploration and exploitation of action in order to maximize reward. The
can be adjusted from (0, 1) [
35]. The value of
is set to explore the actions to maximize the reward. Moreover,
and
is set. All the simulations are performed with Matlab R2017a. All simulation parameters are mentioned in
Table 2.
The performance of our proposed RL-based caching mechanism is validated against state-of-the-art caching schemes:
Learning based Branch & Bound (LB&B): LB&B enables learning from patterns of users’ data demands based on their data viewing preferences.
Least Frequently Used Contents Caching (LFUCC): The frequency of users’ data requests is followed by a diverse data popularity profile. Therefore, LFUCC devised data demands frequency and content popularity to improve data access via cache resources.
Highly Popular Contents Caching (HPCC): HPCC enables caching highly demanded contents by the users to conserve limited cache resources.
Randomized Contents Caching (RCC): RCC exploits caching randomly to reduce the complexity without reducing data service quality.
In
Figure 3, an impact of data library size is observed on data access delay via cache resources. The obtained results depict a low delay for small numbers of contents because there are data requests for only these contents. These small number of contents can be accommodated in the limited cache resources to minimize data access delay. However, when number of contents is large, then users have more choices of contents that cause diversity of data demands. This creates a challenge in optimizing data caching to improve data access via cache resources. In the case of failure of data access via cache resources, contents will be fetched from the core network with a large delay. Our proposed cache scheme achieves low delay of data access by exploiting Q-learning and users’ mobility patterns. When there are 300 contents, our proposed scheme achieves 4%, 8%, 9.8%, and 13.5% lower delay than LB&B, LFUCC, HPCC, and RCC, respectively. Hence, performance gain of the proposed caching scheme is high by employing intelligent cache decisions based on available cache resources and users’ data demands.
In
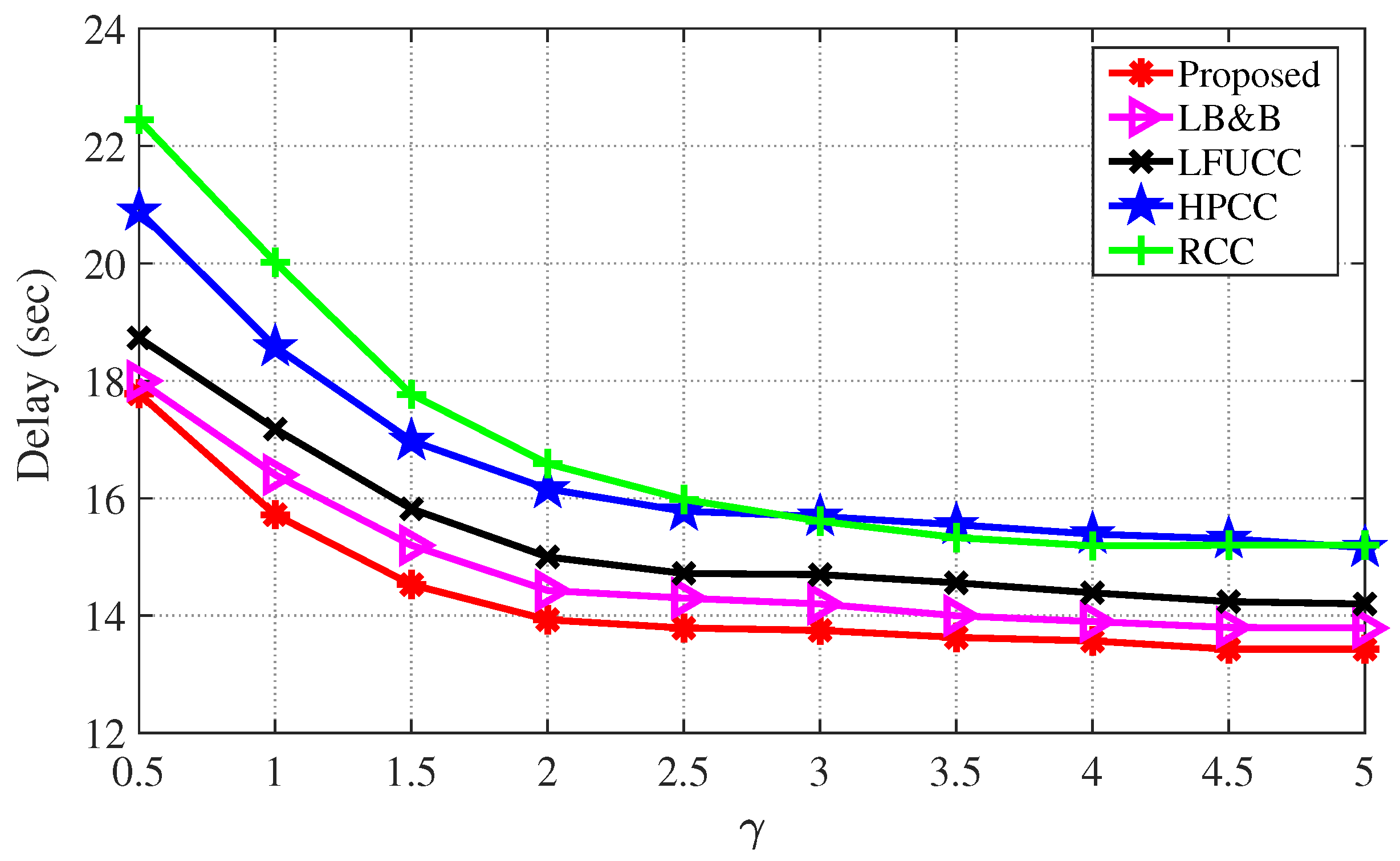
Figure 4, the influence of the data popularity profile is observed on the cache decision of our proposed caching mechanism. Popularity skewness is utilized for the aforementioned reason. From the obtained results it is obvious that when popularity skewness value is high, then data access delay is low. This low delay is due to the fact that fewer contents are responsible for constituting data traffic that can be placed in the cached resources. This improves the potential of data access via cache resources. From the obtained results it is evident that our proposed caching mechanism outperforms all the baseline schemes. The delay is greatly reduced when popularity skewness is varied from 0.5 to 5. However, after popularity skewness equal to 2.5, the delay response is stable because contents generating data requests are already cached. Hence, popularity skewness has a significant role in driving users’ data viewing patterns and our proposed caching mechanism efficiently caches contents and improves content access via cache resources.
Figure 5 shows performance gain of our proposed caching mechanism under the influence of increasing number users. The efficiency of the proposed caching mechanism is clear in this result because increasing number of users implies more diverse data demands. However, all contents cannot be cached due to the cache constraint; therefore, optimal cache decisions are necessary. For instance, when there are 30 users, our proposed caching mechanism achieves 3.5%, 5.5%, 7.2%, and 12% lower delay than LB&B, LFUCC, HPCC, and RCC, respectively. This shows that our proposed caching mechanism can intelligently decide which contents should be cached based on evolving user data requests and positions.
In
Figure 6, we analyzed the impact of the cache capacity on the data access delay. It is obvious, when cache capacity is large, then more contents can be cached. This enables more data access through the cache resources. When cache capacity is 60, our proposed caching mechanism achieves 2.6%, 3.3%, 7%, and 8.2% lower delay than LB&B, LFUCC, HPCC, and RCC, respectively. From the obtained results, it is clear that our scheme efficiently utilized cache resources, even in the case of low cache capacity, to accurately predict users’ data demands and perform caching accordingly.
In
Figure 7, an impact of
on traffic offloading via cache resource is analyzed. From obtained results, it is evident that more contents are accessed through cache resources with an increasing
. It is due to the fact that with increasing value of
, fewer contents are responsible for most of the data traffic, which are cached. Hence, more traffic is offloaded through cache resources. For
, our proposed mechanism performs 18%, 47.5%, 90%, and 96% more data offloading through cache resources than LB&B, LFUCC, HPCC, and RCC respectively. Hence, our proposed mechanism has optimized data placement and efficiently utilized limited cache resources.
In
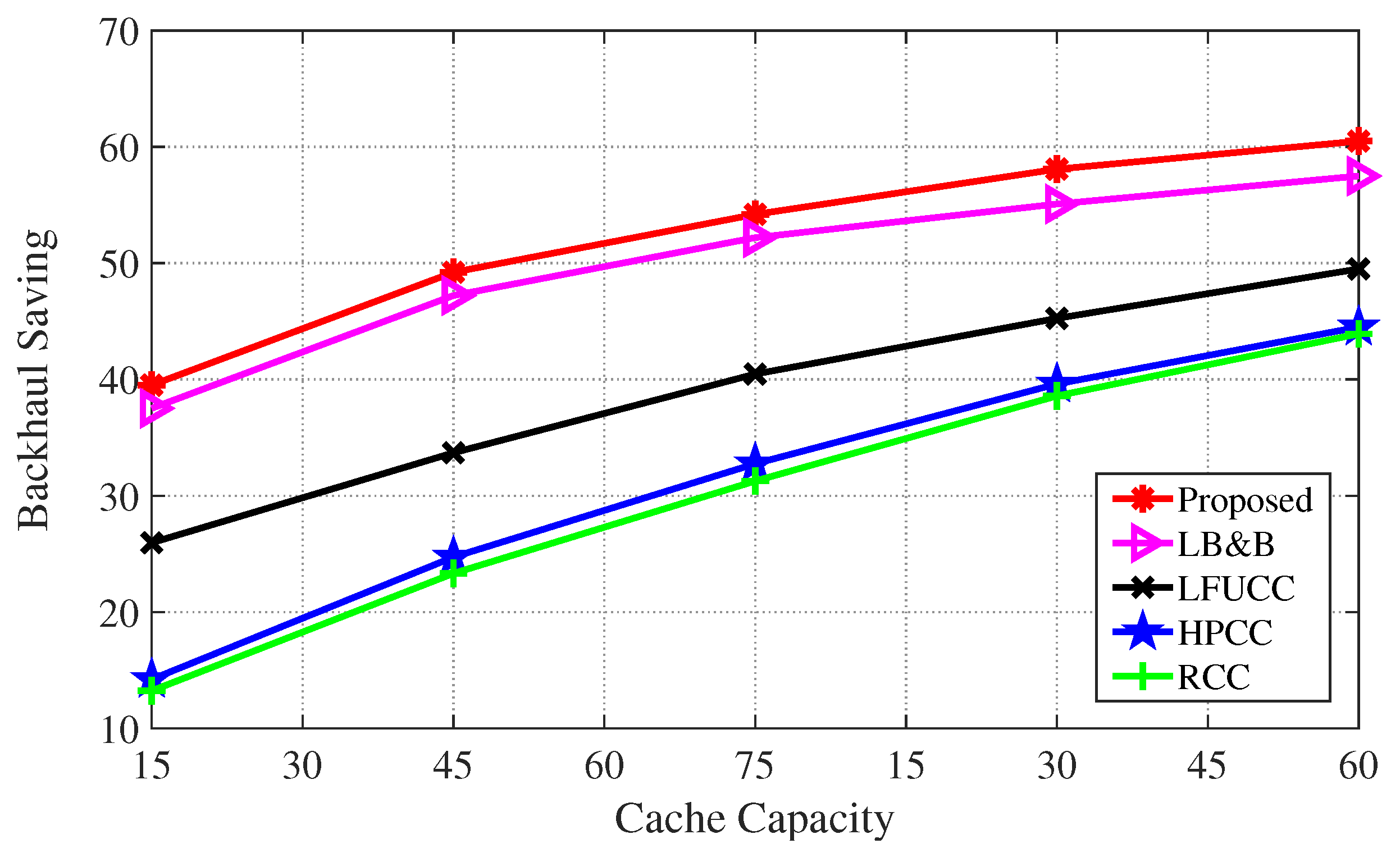
Figure 8, an improvement in backhaul saving in result of increasing cache capacity is analyzed. It is clear from the obtained results that when cache capacity is large more data requests are fulfilled via cache resource and backhaul resources are conserved. For instance, when cache capacity is 45, our proposed mechanism achieves 6%, 35%, 64%, and 74% high backhaul saving than LB&B, LFUCC, HPCC, and RCC, respectively. These obtained results demonstrate our proposed mechanism can accurately place contents in the cache resource by observing users’ data demands.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}