1. Introduction
Eye-tracking techniques have been gradually applied in different fields, such as remote task of the servo platform motion, which is helpful to achieve accurate manipulation and highly human-machine interaction [
1,
2]. Some methods have been implemented to accurately estimate the line-of-sight and output gaze points [
3,
4,
5]. When people wear on Head-mounted eye-tracking device, gazes the scene displayed on the Head-mounted display to complete remote tasks. This process contains persons’ interaction object and gaze region, and the output gaze points contain different meanings [
6,
7]. For visual characteristics, people’s gaze attention is uncertain, so that the gaze points have uncertain meanings [
8,
9,
10,
11], they use gaze points within a set range and time threshold or with other interaction modes. It is challenging to use eye-tracking gaze points to accurately manipulate the servo platform. Therefore, this paper research the classification of gaze points method from the visual characteristics factor [
12,
13,
14], in order to understand the meaning of gaze point to manipulate the servo platform.
Vella [
10] uses a Clustering method to describe gaze points feature and to recognize user. Kim [
11] adopts Support vector machines (SVM) method to recognize the gaze direction. Boisvert [
12] proposes a framework to apply Random Forest Algorithm (RF) for highlighting features that distinguish behavioral differences observed across visual task and understanding gaze behavior. Fuchs [
13] uses Gaussian Hidden Markov Models (GHMM) to analysis gaze and estimate the current proximal intention. Coutrot [
14] relies on Hidden Markov models (HMM) to classify scan-path fixations and infer an observer-related characteristic. Qiu [
15] proposes Conditional Random Field model (CRF) to classify eye fixation data and Lafferty [
16] uses this model CRF to classify sequence data. The same Benfold [
17] uses CRF method according head motion, walking direction, and appearance to estimate coarse gaze direction. Above all, these research have used different classification and recognition methods to the eye gaze information, but these need more related information to input, and for our application is not clear.
Huang [
18] fuses the visual saliency and task-dependent in eye-tracking gaze to learn eye attention transfer and predict gaze information. Related studies [
19,
20,
21,
22,
23] on gaze point prediction take into account the integration of visual saliency and human gaze attention transfer, that is, the underlying visual characteristics of eye gaze visual characteristics and human brain consciousness attention. The similar research on Named entity recognition studies [
24,
25,
26,
27] need to encode input features and output recognition sequences, these are applicated in weapon, product quality and language areas.
According to above work, this paper research only has gaze point and gaze image as the input, will need encoding the inputting feature, then understanding the gaze point meaning to classify and recognize using based on CRF model. The clustering method [
10] only needs to consider the distance relationship between data by looking for distance iteration of data. The SVM method [
11] classifies the data types by looking for a hyperplane of data. Therefore, the proposed method is also compared with these two methods. The RF method [
12] build many estimators including all feature to classify. The gaze points observed by the correlated HMM model method [
14] are independent of each other, and the labeling at the current moment is only related to the labeling at the previous moment. However, the gaze point recognition often requires more features, and the labeling of the current moment should be related to the previous moment and the next moment. The GHMM method [
13] to consider the distribution of features. The CRF model method [
16] can customize the feature function, which express not only the dependence between observations, but also the complex dependence between the current observation and multiple states before and after. This can efficiently overcome the problems faced by HMM model. However, its disadvantage is that the sequence features require to be manually extracted. So, this paper based on CRF, with little input considered visual characteristics, and do some ways to solve our problem. That is different from other research.
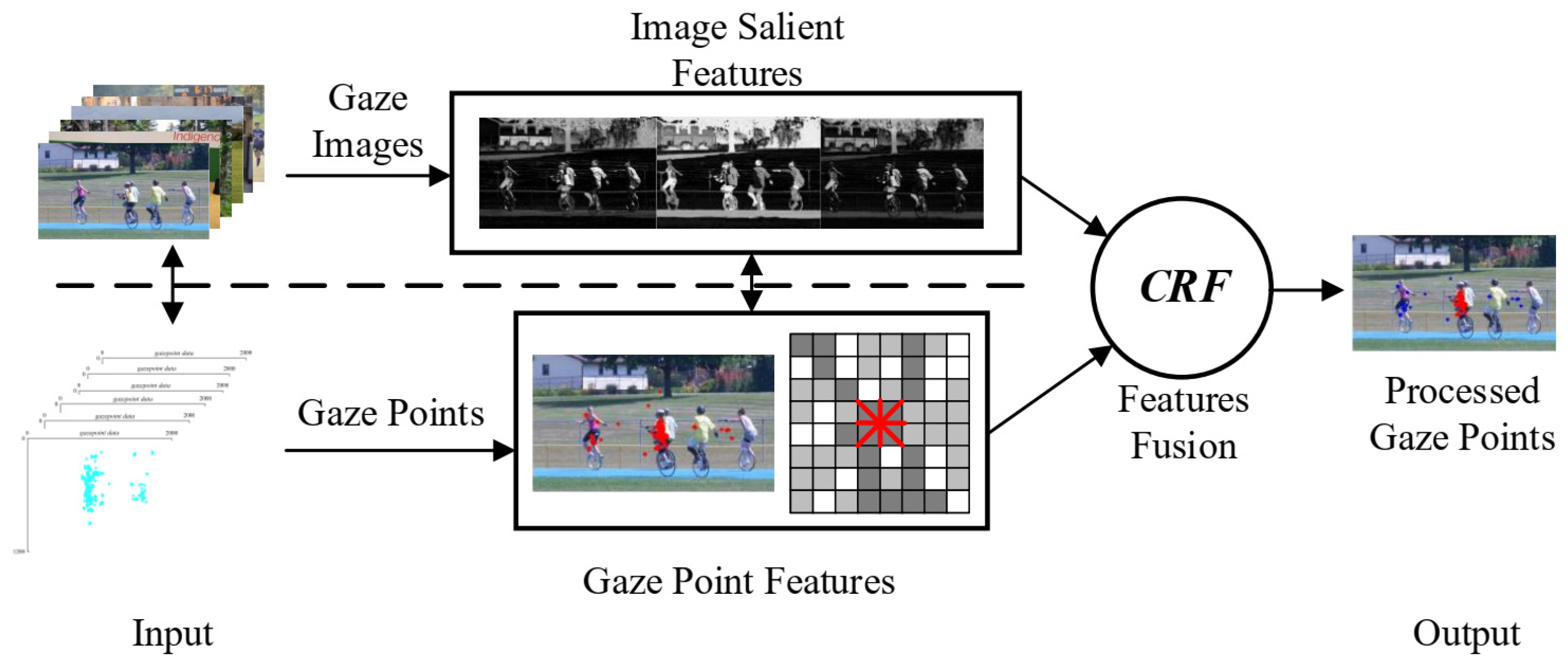
This paper proposes a gaze points classification method based on CRF and visual characteristics to extract the meaning of gaze points for a more accurate manipulation of servo platform, while the servo platform visually aim the target. Considering the saliency of images and task-related attention in human eye gaze tasks, the visual features of gaze images and gaze points are described, the LSTM model [
18] is introduced to merge the two described feature relationships, and the CRF model is used to mark and classify the eye-tracking gaze points. The proposed method aims at classifying the gaze points from the perspective of visual characteristics and improving the accuracy of eye-tracking interaction. In the application of eye-tracking, the potential of eye-tracking interaction is fully utilized, and the isolated eye gaze point is removed.
The main contributions of this paper are summarized as follows.
- (1)
A novel hybrid classification model is proposed, introducing visual characteristics about gaze scene image and gaze point;
- (2)
The method achieves automatic and efficient analytical processing of gaze points in eye-tracking interaction.
This remainder of this paper is organized as follows.
Section 2, describes the gaze point classification method of conditional random field based on visual characteristics.
Section 3, presents the experimental process and data.
Section 4, shows the experimental results and the comparison with other related methods. Finally, the conclusions and future work are drawn in
Section 5.
4. Experimental Results and Analysis
4.1. Classification Results of Gaze Points
Figure 10 shows the gaze point classification process. The experimental results are analyzed from two aspects: subjective result analysis where the result of gaze point classification is analyzed from gaze point visualization, and objective analysis of the results, where the proposed method is compared with the relevant data classification method.
Compared with related classification method, the clustering method [
10], the SVM method [
11], the RF method [
12], the GHMM method [
13], the HMM method [
14] and the CRF method [
16] to further analyze proposed method results.
4.2. Subjective Result Analysis
Figure 11 presents the result of gaze points classification. The first row shows a visualization of the original gaze points. The second row shows the visualization result of gaze point classification by the proposed method.
Statistical calculation and analysis are performed on the method of visual gaze points (
Figure 11). The results of
Ra and
Co of gaze concentration, as well as the subjective ratio of the sample gaze point classification results are shown in
Figure 12. It can be seen that the distribution of gaze points in different gaze images is different, and the concentration degree of gaze is also different.
It can be seen from
Figure 11 that there are many targets in the No. 1, No. 2, No. 3 gaze image, while the main target is clear, and the attention is relatively concentrated in the fixation process. In an example of image background watching a single task the main target is only one. When watching a gaze image in the process of test, there are 51 images of this type in the 100 images. Therefore, we analysis the concentrated attention is shown in
Table 3, the result of scene image gazing with large target significantly, and average
Ra and
Co values after classification are analyzed by various methods, the gaze images and gaze points data are from our collect data. The proposed method
Co = 16.44 is the lowest,
Ra = 69.67% is higher than other five methods. In addition, the gaze points classification results reflect the well gaze attention.
In
Figure 11, No. 4, No. 5, No. 6 gaze images in the target are more than in other images. In general, the visual characteristics of prominent performance are observed. The attention during the gaze is more scattered, and gaze exists for each target. The No. 4 image background single gaze task has a main target for the third person. The No. 5 image in the background is complex, but the relatively visual distribution of clear gaze task has main target for the second person. The No. 6 image in the background complex target is not prominent, and the main target of the gaze task is the first person. There are 49 images of such type in 100 images, and a statistical analysis of the gaze attentional concentration is shown in
Table 4 with related methods, the gaze images and gaze points data are from our collect data. The proposed method
Ra = 49.67% is the highest,
Co = 21.39 is lower than other five methods. In addition, the gaze points classification results reflect the well gaze attention.
In general, the subjective result show that gazing images with different visual characteristics can have different effects on human attention and gaze results. The proposed method considers the human visual characteristics during gaze, which is more reasonable, and the classification of gaze points for targets is more relative with the physiological characteristics of people. Simultaneously, the results also showed that in such analysis of gaze point, the relative gaze point of concentration is high, and is relatively better for the gaze point interaction accuracy and stability.
4.3. Objective Result Analysis
Table 5 shows the comparison of gaze point classification results by different related algorithms in the example images of
Figure 11. The proposed method outperforms the relevant algorithms in terms of precision, recall, and comprehensive performance.
It can be seen from
Table 5 that the overall performance of the proposed method is well and stable. The results of the image No. 1 in
Figure 11 of the gaze points are classified using the clustering method in [
10]. Although the various evaluation values are higher, because the fact that classification of the data is iteratively calculated in terms of the distance situation between the data, this method is simply considered from the distribution distance, and the results after visualization are clear (
Figure 13), containing many gaze points that do not belong to the target range. The result of the image No. 3 in
Figure 11 shows that too many gaze points of the target are classified (
Figure 14), which instead makes the various evaluation values low. Similarly, the classification SVM method in [
11] also has a relatively good classification result for gaze points. Although the data characteristics are considered, the factor relationship between human visual characteristics is not considered. The proposed method is based on the ideological basis of research [
14,
16,
24] for integrated research, which not only considers the feature establishment of gaze points, but also the relationship between features. It also integrates the influence of human visual characteristics into learning, and the overall result is higher than the objective evaluation value of the five methods.
Similarly, the results of the test data are statistically analyzed and the gaze points classification results of 100 gaze images are evaluated.
Figure 15 presents the average comparison of test experimental results.
It can be seen from
Figure 15 that the final evaluation results of the proposed method,
Precision = 86.81%, Recall = 86.79%, We = 86.79%, they are still better than those of relevant methods. In general, the proposed method has slightly improved the comparison indexes compared with similar data classification methods, and the comparison of comprehensive performance is also slightly advantageous. However, the improved performance is not very prominent, and the percentage of improvement is not large. According to the presented analysis, on the one hand, the method still lacks the comprehensiveness of feature description in the description of gaze points and fails to better describe the feature relations between gaze points, and therefore the final classification result is not significantly superior to that of relevant methods. However, in the process of analysis from the starting of feature establishment, the method tries to establish gaze point features based on visual characteristic from different areas, and the same learning and training classification results are also better. On the other hand, this study tackles the case where the data distribution of the original gaze points is relatively concentrated, and the proportion of unintentional saccade is small. No matter what kind of gaze point classification is used, the distribution of the gaze points is more concentrated than that of the gaze consciousness, which is easy to classify.
4.4. Real Scene Image Gaze Points Classification and Application
Through the previously mention research on the classification of gaze points, the eye-tracking technology is used to control the servo platform and perform the visual aiming of the servo platform. Specifically, the experimenters wear on the eye-tracking device, and gaze at the targets on the display (the image transmitted by the scene camera on the servo platform) are verified. In addition, the original gaze point and the gaze point after classification are compared. Part 1 shows the gaze at real images experiment. Part 2 further shows the real-time servo platform visual aiming.
Part 1: experimenters gaze at the “person” (as for target) in the school and select six scenes to illustrate.
Figure 16 presents the comparison of gaze points during the real images gazing.
In
Figure 16, (1) the target of gaze is not specified, and the gaze points are widely distributed; (2) and (3) the gaze target is the person on the right; (4) the gaze target is designated as the second person; (5) the gaze target is the person on the right side of the step; (6) the gaze target is the person on the steps. In each image, the first row presents the gaze image, the second row presents the original gaze points, and the third row presents the classified gaze points. It can be clearly seen that the proposed method classifies the gaze points associated with the target “person”.
Table 6 presents the comparison of real images gaze test evaluation results. The proposed method can classify real scene images gaze points, the
Co is the lowest, the
Ra is better than other methods result, and the
Precision,
Recall and
We all is better than others result. These further show our method have a well classification result based on visual characteristics, and in gazing process gaze target long time that with different attention distribution. So, when we manipulate servo platform accuracy aiming visual, need understanding the meaning of gaze point to use.
Part 2: experimenter gaze the center of target, as shown in
Figure 17.
Figure 17a is gaze target. During the gazing process, interference to the target
Figure 17b and the target
Figure 17c will appear from different positions to the target. The position of the “+” in the center of the servo platform scene camera during the gaze test is recorded. When the blue “+” and green “+” overlap in the target center of the stable area, the servo platform visual aiming is achieved.
Figure 18 shows the state of gaze point and servo platform scene camera following and visual aiming during gazing.
Figure 18a is the gaze target,
Figure 18b is the appearance of the first interference target,
Figure 18c is the appearance of the second interference target.
Figure 19 shows the distribution of gaze points in the experimental visual aiming process.
Figure 19a is the distribution of gaze points of the original output, and
Figure 19b is the distribution of gaze points after classification.
Figure 20 present the gaze process 24 different time visual aiming state.
The experimental results show that the proposed method can efficiently classify the gaze points of the target and make the servo platform camera more accurately follow and aim achieving the servo platform visual aiming.
In summary, the proposed gaze points classification method based on visual characteristics is experimentally tested by gazing at different 100 images, 6 real scene images and target. It can be seen that the distribution of gaze points in different gaze images reflects the different attention and gaze concentration of human eyes. For the gaze at a single background and a prominent target, the distribution of gaze points is highly concentrated. For the image having a complex background and no prominent target, the distribution of gaze points is scattered and widely distributed. The subjective and objective results obtained by the proposed method demonstrate that it achieves a high degree of gaze attention. In 100 gaze images average Precision = 86.81%, Recall = 86.79%, We = 86.79%, In 6 real scene the best Ra = 91.34%, Co = 16.98, Precision = 98.15%, Recall = 98.17%, We = 98.16%. These are also better and stable than those obtained by other methods. However, the evaluation values are not particularly improved. This is the presented study of visual characteristics and human physiological characteristics has not taken into consideration the different influencing factors, and there is no applicability for the establishment of various relationships. These still need to be further explored in future studies. Simultaneously, the experiment results of this study show the applicability of eye-tracking of gaze points classification, in order to achieve servo platform visual aiming.
5. Conclusions
This paper studied the gaze points classification based on visual characteristics, aiming at the head-mounted eye-tracking device to gaze control servo platform, and achieve servo platform visual aiming. The gaze points can be automatically analyzed and classified, so as to achieve accurate visual aiming of servo platform. Through feature encoding of gaze image and gaze points, an establish the learning relationship between features. The CRF model is further input to output the predicted gaze points classification. The experimental results show that the proposed method performs feature analysis of gaze points from different angles. Compared with the relevant algorithms, it can be clearly seen from the subjective results that the proposed method can efficiently classify target gaze points. In addition, the objective comparison with relevant algorithms shows that the proposed method has improved the accuracy, recall rate and weight value. Furthermore, it can be applied to more accuracy achieve visual aiming of servo platform.
In future work, we aim at further studying the human-oriented, autonomous and efficient eye-tracking modes, in order to be able to understand the meaning of gaze points. In addition, the application of gaze point, should do more online experiment research. This can improve the effective use of gaze points, and accurately perform the human-computer interaction application of eye-tracking.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}