
Dynamic Fire Risk Classification Prediction of Stadiums: Multi-Dimensional Machine Learning Analysis Based on Intelligent Perception

Abstract
:1. Introduction
- We propose a risk prediction model of a gradient boosting decision tree combined with the K-fold cross-validation strategy, which can effectively predict the fire risk level of stadiums based on dozens of factors. We show that with basic information about stadiums (fire acceptance status, fire host failure rate, stadium size, etc.), we can predict in advance the likelihood of a stadium fire in the future.
- We show that by using the GB-RFE method to screen and optimize the indicators, the optimized fire risk feature can replace all the features to represent the fire risk of the stadium, and its model performance also achieves the same or similar effect.
- With reference to standard regulations and related literature, we design threshold intervals from both static and dynamic aspects to quantify and classify fire risk assessment indicators.
2. Dataset
3. Methodology
3.1. Data Preprocessing
3.1.1. Data Cleaning
3.1.2. Data Conversion
3.2. Recursive Feature Elimination
3.3. Feature Correlation Analysis Based on Pearson
3.4. Performance Measure
3.4.1. Classification Metrics
- (1)
- Accuracy: The ratio of the correct number of samples classified by the classifier to the total number of samples.
- (2)
- Precision: The ratio of the total number of positive samples correctly classified by the classifier to the total number of samples identified as positive samples by the classifier.
- (3)
- Recall or Sensitivity: The ratio of the total number of correct positive samples classified by the classifier to the total number of real positive samples.
- (4)
- F1-score: as the harmonic mean of recall and precision, it is better than independent precision or recall indicators, which is an important indicator for evaluating classification models [20]. Precision and recall have their own shortcomings. If the threshold is high, the precision is high, but there will be a lot of data loss; if the threshold is low, the recall will be high, but the prediction will be very inaccurate. Therefore, the F1-score is used to evaluate the classifier more comprehensively and can balance the effects of precision and recall.
3.4.2. Cross-Validation
- K-fold cross-validation
- 2.
- Stratified K-Fold cross-validation
3.5. Classification Modeling Using Data Mining Algorithms
- Using full features (47 features), combined with two cross-checks and six machine learning algorithms to build 12 risk prediction models.
- Selecting a significant feature subset (17 features) of recursive feature elimination, and using two cross-validation methods and six machine learning algorithms to establish 12 risk prediction models.
4. Experimental Results
4.1. Selected Features
- Fire acceptance: FRBMaterials, Evacuation signs, Rescue field;
- Fire Safety Personnel Management: NO_CertificatesPersonnel, Fire drills;
- Fire Facility Equipment Management: Fire host, rFHF, nrWaterPressure, PPCSSmoke, CCSmoke, lFP, UBMCompany, ULMTime;
- Hazard management: rIPC, rHD;
- Unit fire data maintenance: BgLayout, FSupervisor.
4.2. Feature Correlation Analysis
4.3. Cross-Validation
4.3.1. K-Fold
4.3.2. Stratified K-Fold
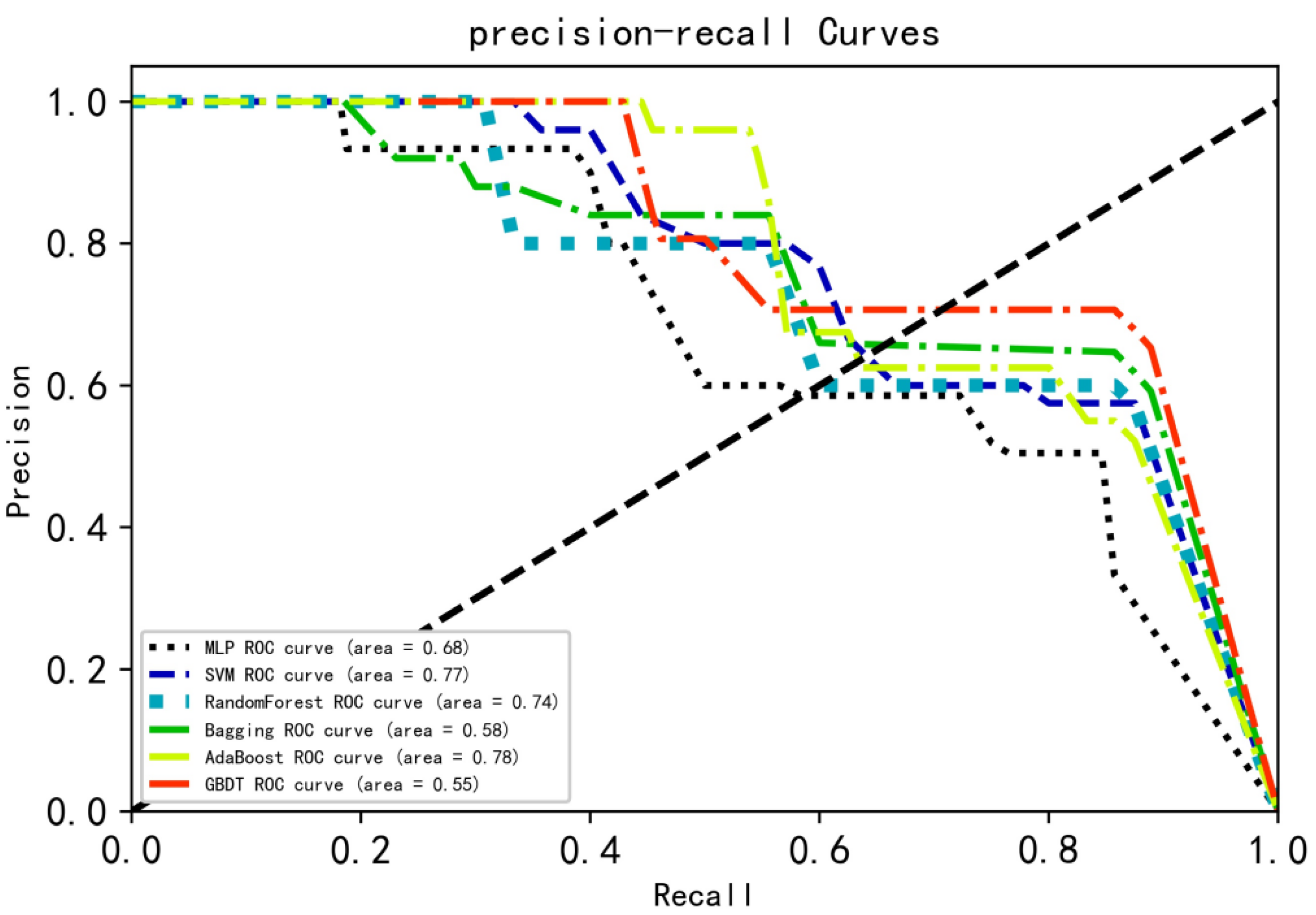
4.4. Performance of Classification Models
5. Discussion and Future Work
5.1. Comparison of Performance Metrics between Predictive models Using Significant Features and Full Features
5.2. Optimal Risk Prediction Model
5.2.1. Performance of Risk Prediction Models
5.2.2. Comparison with Other Study
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Name | Description | Data Type and Value |
|---|---|---|
| Building Intrinsic Safety: | ||
| Fire acceptance | Whether to pass the fire acceptance | Nominal–Pass/Fail |
| FRBMaterials | Flammability rating of building materials | Nominal–Pass/Fail |
| FEL | Fire emergency lighting | Nominal–Pass/Fail |
| Evacuation signs | Evacuation signs | Nominal–Pass/Fail |
| Fire lanes | Fire lanes | Nominal–Pass/Fail |
| Rescue field | Rescue field | Nominal–Pass/Fail |
| Rescue entrance | Rescue entrance | Nominal–Pass/Fail |
| BgStructure | Building structure | Nominal-Outdoor, open, partially open, enclosed |
| VeSize | Venue size | Nominal-Seats < 3000, 3000 ≤ Seats < 5000, 5000 ≤ Seats < 10,000, 10,000 ≤ Seats < 50,000, Seats ≥ 50,000 |
| Fire Safety Personnel Management: | ||
| NO_FSPR | Number of fire station personnel recorded | Nominal-Numbers ≥ 6, Numbers = 5, Numbers = 4, Numbers = 3, Numbers ≤ 2 |
| FCRStaff | Staff in the fire control room | Numerical-% |
| FSTra | Fire safety training | Nominal-days ≤ 180, 180 < days ≤ 365, days > 365 |
| NO_CertificatesPersonnel | Number of certificates of fire control room personnel | Nominal-Numbers ≥ 2, Numbers = 1, Numbers = 0 |
| Fire drills | Fire drills | Nominal-days ≤ 180, 180 < days ≤ 365, days > 365 |
| Fire Facility Equipment Management: | ||
| Fire host | Fire host status | Nominal-Normal, no data, offline duration (≤24 h), offline duration (>24 h) |
| FSPDetection | Fire host power detection | Nominal-Both are normal/ a normal/Neither is normal |
| rFHF | Fire host Failure ratio | Numerical-% |
| rFHS | Fire host shielding ratio | Numerical-% |
| rFAI | Fire alarm integrity ratio | Numerical-% |
| CCSprinkler | Sprinkler control cabinet status | Nominal-Automatic/ manual/offline/disconnected |
| nrWaterPressure | The normal rate of water pressure at the end of the sprinkler system | Numerical-% |
| WPFH | Worst point fire hydrant water pressure | Numerical-MPa |
| CCFireHydrantPump | Fire hydrant pump control cabinet status | Nominal-Automatic/ manual/offline/disconnected |
| rFDOI | Fire door operating integrity ratio | Numerical-% |
| rFSR | Fire shutter running integrity ratio | Numerical-% |
| PPCSSmoke | Smoke prevention power connection status | Nominal-connected/disconnected |
| CCSmoke | Smoke control cabinet status | Nominal-Automatic/ manual/offline/disconnected |
| lFWT | Fire water tank level | Numerical-mm |
| lFP | Fire pool level | Numerical-mm |
| UBMCompany | Unit-bound maintenance company | Nominal-Yes/No |
| ULMTime | Unit’s Latest Maintenance Time | Nominal-days ≤ 365, days > 365 |
| Hazard management: | ||
| rIPC | Inspection point completion ratio | Numerical-% |
| rHD | Hidden danger ratio | Numerical-% |
| Hidden dangers_Rec | Rectification of hidden dangers | Numerical |
| Hidden dangers_ h Level | The highest level of hidden dangers | Nominal-Level I, Level II, Level III |
| Unit fire data maintenance: | ||
| RegulatoryUnitsTyp | Types of Regulatory Units | Nominal-Yes/No |
| FCRL | Fire control room location | Nominal-Yes/No |
| UPC | Unit property category | Nominal-Yes/No |
| BgLayout | Building layout | Nominal-Yes/No |
| NO_EvacuationSairs | Number of evacuation stairs | Numerical |
| NO_SafeExits | Number of safe exits | Numerical |
| FFAEEPlans | Fire fighting and emergency evacuation plans | Nominal-Yes/No |
| FS_Sys | Fire safety system | Nominal-Yes/No |
| FS_Res | Fire safety responsible person | Nominal-Yes/No |
| FS_Man | Fire safety manager | Nominal-Yes/No |
| FS_Lia | Fire safety liaison | Nominal-Yes/No |
| FSupervisor | Fire supervisor | Nominal-Yes/No |
References
- Zheng, W. Fire Safety Assessment of China’s Twelfth National Games Stadiums. Procedia Eng. 2014, 71, 95–100. [Google Scholar] [CrossRef]
- Hamed, T.; Dara, R.; Kremer, S.C. Network intrusion detection system based on recursive feature addition and bigram technique. Comput. Secur. 2018, 73, 137–155. [Google Scholar] [CrossRef]
- Latah, M.; Toker, L. Towards an efficient anomaly-based intrusion detection for software-defined networks. IET Netw. 2018, 7, 453–459. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Zhang, T.; Liu, W. A fire risk assessment method based on the combination of quantified safety checklist and structure entropy weight for shopping malls. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2021, 235, 610–626. [Google Scholar] [CrossRef]
- Choi, J.-H.; Lee, S.-W.; Hong, W.-H. A development of fire risk map and risk assessment model for urban residential areas by raking fire causes. J. Archit. Inst. Korea Plan. Des. 2013, 29, 271–278. [Google Scholar]
- Liu, F.; Zhao, S.; Weng, M.; Liu, Y. Fire risk assessment for large-scale commercial buildings based on structure entropy weight method. Saf. Sci. 2017, 94, 26–40. [Google Scholar] [CrossRef]
- Wang, S.-H.; Wang, W.-C.; Wang, K.-C.; Shih, S.-Y. Applying building information modeling to support fire safety management. Autom. Constr. 2015, 59, 158–167. [Google Scholar] [CrossRef]
- Cheng, X.-Q.; Jin, X.L.; Wang, Y.; Guo, J.; Zhang, T.; Li, G. Survey on big data system and analytic technology. J. Softw. 2014, 25, 1889–1908. [Google Scholar]
- Lo, S.M.; Liu, M.; Zhang, P.H.; Yuen, K.K.R. An Artificial Neural-network Based Predictive Model for Pre-evacuation Human Response in Domestic Building Fire. Fire Technol. 2008, 45, 431–449. [Google Scholar] [CrossRef]
- Madaio, M.; Chen, S.-T.; Haimson, O.L.; Zhang, W.; Cheng, X.; Hinds-Aldrich, M.; Chau, D.H.; Dilkina, B. Firebird: Predicting fire risk and prioritizing fire inspections in Atlanta. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New Orleans, LA, USA, 13–17 August 2016; pp. 185–194. [Google Scholar]
- Kim, D.H. A study on the development of a fire site risk prediction model based on initial information using big data analysis. J. Soc. Disaster Inf. 2021, 17, 245–253. [Google Scholar]
- Liu, Z.-G.; Li, X.-Y.; Jomaas, G. Identifying Community Fire Hazards from Citizen Communication by Applying Transfer Learning and Machine Learning Techniques. Fire Technol. 2020, 57, 2809–2838. [Google Scholar] [CrossRef]
- Surya, L. Risk Analysis Model That Uses Machine Learning to Predict the Likelihood of a Fire Occurring at A Given Property. Int. J. Creat. Res. Thoughts (IJCRT) ISSN 2017, 5, 2320–2882. [Google Scholar]
- Anderson-Bell, J.; Schillaci, C.; Lipani, A. Predicting non-residential building fire risk using geospatial information and convolutional neural networks. Remote Sens. Appl. Soc. Environ. 2021, 21, 100470. [Google Scholar] [CrossRef]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Xie, H.; Weerasekara, N.N.; Issa, R.R.A. Improved System for Modeling and Simulating Stadium Evacuation Plans. J. Comput. Civ. Eng. 2017, 31, 04016065. [Google Scholar] [CrossRef]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Khosravi, M.; Vaferi, B.; Amar, M.N.; Ghriga, M.A.; Mohammed, A.H. Application of machine learning methods for estimating and comparing the sulfur dioxide absorption capacity of a variety of deep eutectic solvents. J. Clean. Prod. 2022, 363, 132465. [Google Scholar] [CrossRef]
- Zhu, H.; You, X.; Liu, S. Multiple Ant Colony Optimization Based on Pearson Correlation Coefficient. IEEE Access 2019, 7, 61628–61638. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009; Volume 5, pp. 532–538. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Poh, C.Q.; Ubeynarayana, C.U.; Goh, Y.M. Safety leading indicators for construction sites: A machine learning approach. Autom. Constr. 2018, 93, 375–386. [Google Scholar] [CrossRef]
- Guan, F.; Shi, J.; Ma, X.; Cui, W.; Wu, J. A method of false alarm recognition based on k-nearest neighbor. In Proceedings of the 2017 International Conference on Dependable Systems and Their Applications (DSA), Beijing, China, 31 October–2 November 2017. [Google Scholar]
- Gholizadeh, P.; Esmaeili, B.; Memarian, B. Evaluating the Performance of Machine Learning Algorithms on Construction Accidents: An Application of ROC Curves. In Construction Research Congress 2018; ASCE: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Dang, T.T.; Cheng, Y.; Mann, J.; Hawick, K.; Li, Q. Fire risk prediction using multi-source data: A case study in humberside area. In Proceedings of the 2019 25th International Conference on Automation and Computing (ICAC), Lancaster, UK, 5–7 September 2019; pp. 1–6. [Google Scholar]
- Zhu, R.; Hu, X.; Hou, J.; Li, X. Application of machine learning techniques for predicting the consequences of construction accidents in China. Process Saf. Environ. Prot. 2020, 145, 293–302. [Google Scholar] [CrossRef]
- Pirklbauer, K.; Findling, R.D. Storm Operation Prediction: Modeling the Occurrence of Storm Operations for Fire Stations. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events, Kassel, Germany, 22–26 March 2021; pp. 123–128. [Google Scholar]
- Wang, Q.; Zhang, J.; Guo, B.; Hao, Z.; Zhou, Y.; Sun, J.; Yu, Z.; Zheng, Y. CityGuard: Citywide fire risk forecasting using a machine learning approach. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–21. [Google Scholar] [CrossRef]
- Zhang, Y.; Geng, P.; Sivaparthipan, C.; Muthu, B.A. Big data and artificial intelligence based early risk warning system of fire hazard for smart cities. Sustain. Energy Technol. Assess. 2021, 45, 100986. [Google Scholar] [CrossRef]
- Chang, J.; Yoon, J.; Lee, G. Machine Learning Techniques in Structural Fire Risk Prediction. Int. J. Softw. Eng. Its Appl. 2020, 14, 17–26. [Google Scholar] [CrossRef]












| Risk Score | Risk Rank | Attribute Requirements |
|---|---|---|
| [90–100] | Level I (Not at risk) | Low priority |
| [80–90) | Level II (Low risk) | Regular inspection |
| [70–80) | Level III (Medium risk) | Frequent regular inspection and fire safety management. |
| [60–70) | Level IV (High risk) | The probability of fire accidents is extremely high, some casualties and particularly heavy property losses, take immediate measures. |
| <60 | Level V (Extremely high risk) | The probability of a fire accident is extremely high, with a large number of casualties and particularly heavy property losses, take immediate measures. |
| First-Level Metrics | Second-Level Metrics | Third-Level Metrics | Level I [90–100] | Level II [80–90) | Level III [70–80) | Level IV [60–70) | Level V (<60) |
|---|---|---|---|---|---|---|---|
| Building Inherent Safety | Building fire performance | Venue size/seats | <3000 | [3000,5000) | [5000,10,000) | [10,000,50,000) | ≥50,000 |
| Building structure | Outdoor | Open | Partially Open | Enclosed | — | ||
| Fire acceptance | Whether it has passed the fire inspection | Pass | — | — | Fail | — |
| First-Level Metrics | Second-Level Metrics | Third-Level Metrics | Level I [90–100] | Level II [80–90) | Level III [70–80) | Level IV [60–70) | Level V (<60) |
|---|---|---|---|---|---|---|---|
| Facility Equipment Management | Fire host | Fire host status | Normal | — | No data | Offline time ≤ 24 h | Offline time > 24 h |
| Fire host power detection | Both the main and standby fire power supply signals are detected | — | One of the main and backup fire-fighting power supply signals is detected | — | The main and backup fire-fighting power signals are not detected | ||
| Failure ratio | 0% | (0%,5%] | (5%,10%] | (10%,20%] | >20% | ||
| Shielding ratio | 0% | (0%,5%] | (5%,10%] | (10%,20%] | >20% |
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive(P) | True Positive(TP) | False Negative(FN) |
| Actual Negative(N) | False Positive(FP) | True Negative(TN) |
| Cluster 1 (%) | Cluster 2 (%) | Cluster 3 (%) | Cluster 4 (%) | Cluster 5 (%) | Average (%) | |
|---|---|---|---|---|---|---|
| MLP | 81.42 | 81.42 | 82.85 | 87.85 | 84.44 | 83.59 |
| SVM | 85.71 | 85.71 | 91.42 | 82.85 | 88.14 | 86.76 |
| RF | 84.28 | 94.28 | 95.71 | 97.14 | 89.62 | 92.20 |
| Bagging | 91.42 | 94.28 | 95.71 | 92.85 | 86.66 | 92.18 |
| AdaBoost | 90.00 | 94.28 | 94.28 | 91.42 | 89.62 | 91.92 |
| Gradient Boosting | 92.85 | 94.28 | 97.14 | 95.71 | 86.66 | 93.32 |
| Cluster 1 (%) | Cluster 2 (%) | Cluster 3 (%) | Cluster 4 (%) | Cluster 5 (%) | Average (%) | |
|---|---|---|---|---|---|---|
| MLP | 79.28 | 86.42 | 88.57 | 90.00 | 93.33 | 87.52 |
| SVM | 90.00 | 88.57 | 91.42 | 92.85 | 88.14 | 90.19 |
| RF | 91.42 | 91.42 | 88.57 | 95.71 | 92.59 | 91.94 |
| Bagging | 90.00 | 87.14 | 88.57 | 94.28 | 92.59 | 90.51 |
| AdaBoost | 90.00 | 84.28 | 90.00 | 91.42 | 92.59 | 89.65 |
| Gradient Boosting | 91.42 | 87.14 | 88.57 | 94.28 | 92.59 | 90.80 |
| Performance Metrics | Machine Learning Algorithms | K-Fold Cross-Validation | Stratified K-Fold Cross-Validation | ||
|---|---|---|---|---|---|
| Full Features (47 Features) | RFE-Top20 (17 Features) | Full Features (47 Features) | RFE-Top20 (17 Features) | ||
| (a) Accuracy | MLP | 87.1 | 83.5 | 86.0 | 87.4 |
| SVM | 86.7 | 86.7 | 90.1 | 90.1 | |
| RF | 91.6 | 92.1 | 91.3 | 91.9 | |
| Bagging | 92.4 | 92.1 | 91.8 | 90.4 | |
| AdaBoost | 91.8 | 91.8 | 90.2 | 89.6 | |
| Gradient Boosting | 93.2 | 93.2 | 91.6 | 90.7 | |
| (b) Precision | MLP | 68.5 | 54.4 | 68.8 | 71.9 |
| SVM | 71.0 | 71.0 | 75.4 | 75.4 | |
| RF | 77.5 | 81.5 | 80.2 | 81.5 | |
| Bagging | 82.5 | 79.8 | 81.0 | 79.0 | |
| AdaBoost | 81.9 | 81.9 | 77.6 | 74.7 | |
| Gradient Boosting | 84.2 | 84.2 | 80.7 | 78.8 | |
| (c) Recall | MLP | 58.8 | 48.0 | 63.1 | 67.7 |
| SVM | 70.8 | 70.8 | 73.4 | 73.4 | |
| RF | 80.0 | 80.8 | 79.5 | 80.9 | |
| Bagging | 82.9 | 81.4 | 80.0 | 77.5 | |
| AdaBoost | 80.5 | 80.5 | 77.3 | 73.3 | |
| Gradient Boosting | 84.3 | 84.3 | 80.4 | 78.6 | |
| (d) F1- score | MLP | 61.3 | 48.0 | 64.1 | 68.4 |
| SVM | 65.2 | 67.7 | 72.1 | 72.1 | |
| RF | 76.4 | 77.8 | 77.8 | 79.6 | |
| Bagging | 80.1 | 78.0 | 79.0 | 76.5 | |
| AdaBoost | 78.6 | 78.4 | 77.3 | 71.9 | |
| Gradient Boosting | 81.9 | 81.9 | 78.7 | 77.0 | |
| (e) Auroc | MLP | 91.4 | 88.8 | 90.1 | 92.1 |
| SVM | 94.8 | 94.8 | 95.4 | 95.3 | |
| RF | 95.9 | 95.8 | 96.1 | 95.9 | |
| Bagging | 95.7 | 94.9 | 94.1 | 94.5 | |
| AdaBoost | 93.4 | 93.5 | 91.9 | 91.7 | |
| Gradient Boosting | 96.2 | 95.9 | 95.1 | 95.1 | |
| (f) Auprc | MLP | 76.6 | 68.9 | 75.1 | 77.7 |
| SVM | 84.8 | 84.9 | 88.2 | 87.9 | |
| RF | 86.2 | 86.2 | 87.7 | 86.0 | |
| Bagging | 86.8 | 87.1 | 84.6 | 85.7 | |
| AdaBoost | 84.0 | 84.2 | 78.2 | 78.2 | |
| Gradient Boosting | 89.8 | 88.8 | 84.4 | 84.4 | |
| Performance Metrics | Stadium Fire Risk Dataset | |
|---|---|---|
| Model | Value (%) | |
| (a) Accuracy | Gradient Boosting + REF-Top20 + K-fold | 93.2 |
| Gradient Boosting + Full features + K-fold | 93.2 | |
| Bagging + Full features + K-fold | 92.4 | |
| RF + Full features + K-fold | 92.1 | |
| Bagging + REF-Top20 + K-fold | 92.1 | |
| (b) Precision | Gradient Boosting + REF-Top20 + K-fold | 84.2 |
| Gradient Boosting + Full features + K-fold | 84.2 | |
| Bagging + Full features + K-fold | 82.5 | |
| Adaboost + REF-Top20 + K-fold | 81.9 | |
| Adaboost + Full features + K-fold | 81.9 | |
| (c) Recall | Gradient Boosting + REF-Top20 + K-fold | 84.3 |
| Gradient Boosting + Full features + K-fold | 84.3 | |
| Bagging + Full features + K-fold | 82.9 | |
| Bagging + REF-Top20 + K-fold | 81.4 | |
| RF + REF-Top20 + Stratified K-fold | 80.9 | |
| (d) F1-score | Gradient Boosting + REF-Top20 + K-fold | 81.9 |
| Gradient Boosting + Full features + K-fold | 81.9 | |
| Bagging + Full features + K-fold | 80.1 | |
| RF + REF-Top20 + Stratified K-fold | 79.6 | |
| Bagging + Full features + Stratified K-fold | 79.0 | |
| (e) Auroc | Gradient Boosting + Full features + K-fold | 96.2 |
| RF + Full features + Stratified K-fold | 96.1 | |
| RF + Full features + K-fold | 95.9 | |
| Gradient Boosting + REF-Top20 + K-fold | 95.9 | |
| RF + REF-Top20 + Stratified K-fold | 95.9 | |
| (f) Auprc | Gradient Boosting + Full features + K-fold | 89.8 |
| Gradient Boosting + REF-Top20 + K-fold | 88.8 | |
| SVM + Full features + Stratified K-fold | 88.2 | |
| SVM + REF-Top20 + Stratified K-fold | 87.9 | |
| RF + Full features + Stratified K-fold | 87.7 | |
| Dataset | ML + Feature Combination + Cross-Validation | Frequency |
|---|---|---|
| Stadium Fire Risk Data | Gradient Boosting + REF-Top20 + K-fold | 6 |
| Gradient Boosting + Full features + K-fold | 6 | |
| RF + REF-Top20 + Stratified K-fold | ||
| Bagging + Full features + Stratified K-fold | ||
| Bagging + Full features + K-fold | 4 |
| Souce | ML Algorithm Used | Accuracy | Recall | F1-Score | Auroc | Auprc |
|---|---|---|---|---|---|---|
| Kim et al. [11] | Deep Neural Network | 75.1% | — | — | — | — |
| Liu et al. [12] | TrAdaBoost (a typical transfer learning method) | 89.0% | 88.0% | — | 89.0% | — |
| Poh et al. [23] | SVM | 78.0% | — | — | — | — |
| Guan et al. [24] | K-nearest Neighbor | 92.4% | — | — | — | — |
| Gholizadeh et al. [25] | AdaBoost (CART) | 71.0% | — | 69.0% | — | — |
| Dang et al. [26] | XGBoost (Test with balanced data) | 91.0% | — | — | — | — |
| Zhu et al. [27] | Logistic Regression | — | 80.3% | 78.3% | — | — |
| Pirklbauer et al. [28] | Random Forest | — | — | — | 91.0% | — |
| Wang et al. [29] | Neural Networks | — | 55.8% | 40.0% | 76.3% | — |
| Zhang et al. [30] | Random Forest | 91.2% | — | — | — | — |
| Chang et al. [31] | Neural Networks | 89.1% | 59.3% | 70.1% | — | — |
| Proposed model | Gradient boosting with RFE-Top20 features using K-fold Cross-Validation | 93.2% | 84.3% | 81.9% | 95.9% | 88.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Fan, X.; Zhao, Z.; Jiang, X. Dynamic Fire Risk Classification Prediction of Stadiums: Multi-Dimensional Machine Learning Analysis Based on Intelligent Perception. Appl. Sci. 2022, 12, 6607. https://doi.org/10.3390/app12136607
Lu Y, Fan X, Zhao Z, Jiang X. Dynamic Fire Risk Classification Prediction of Stadiums: Multi-Dimensional Machine Learning Analysis Based on Intelligent Perception. Applied Sciences. 2022; 12(13):6607. https://doi.org/10.3390/app12136607
Chicago/Turabian StyleLu, Ying, Xiaopeng Fan, Zhipan Zhao, and Xuepeng Jiang. 2022. "Dynamic Fire Risk Classification Prediction of Stadiums: Multi-Dimensional Machine Learning Analysis Based on Intelligent Perception" Applied Sciences 12, no. 13: 6607. https://doi.org/10.3390/app12136607