With the growing use of financial services in smartphones, robust security is required to protect mobile devices from unauthorized access. Nowadays, one-time or static authentication mechanisms such as PIN-, pattern-based authentication, and biometrics, e.g., TouchID, and FaceID, are widely deployed on smartphones. However, they authenticate users only once at the initial log-in and are vulnerable to shoulder-surfing or presentation attacks [
1].
Unlike physical biometrics, which utilizes human physical attributes such as face and fingerprint, behavioral biometrics exploits user behavioral patterns such as screen-touch gestures and gait patterns. Physical biometrics are generally more unique and stable than behavioral ones; however, they require users’ cooperation to capture their biometric traits, such as touching a sensor with a finger or turning a face to a camera. In contrast, behavioral biometrics can capture users’ biometric data tacitly with built-in sensors of mobile devices such as the touch screen, accelerometer, and gyroscope. Therefore, behavioral biometrics can actualize implicit continuous authentication, further enhancing the security of mobile devices without deteriorating the user experience.
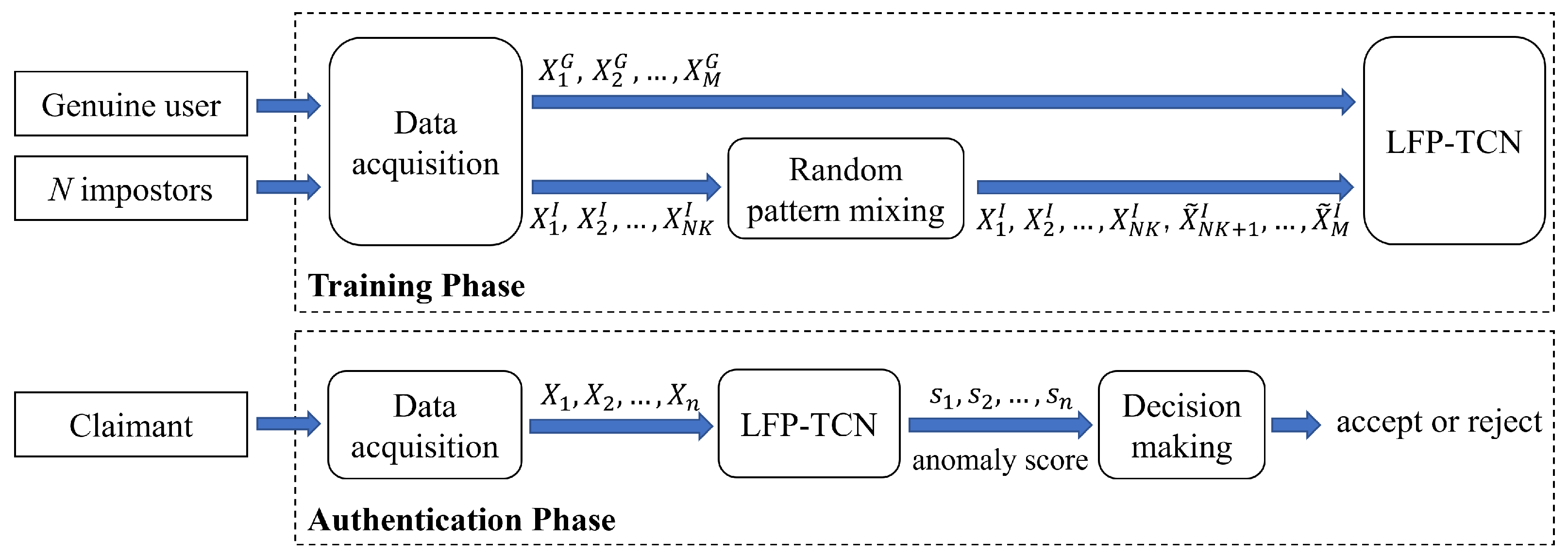
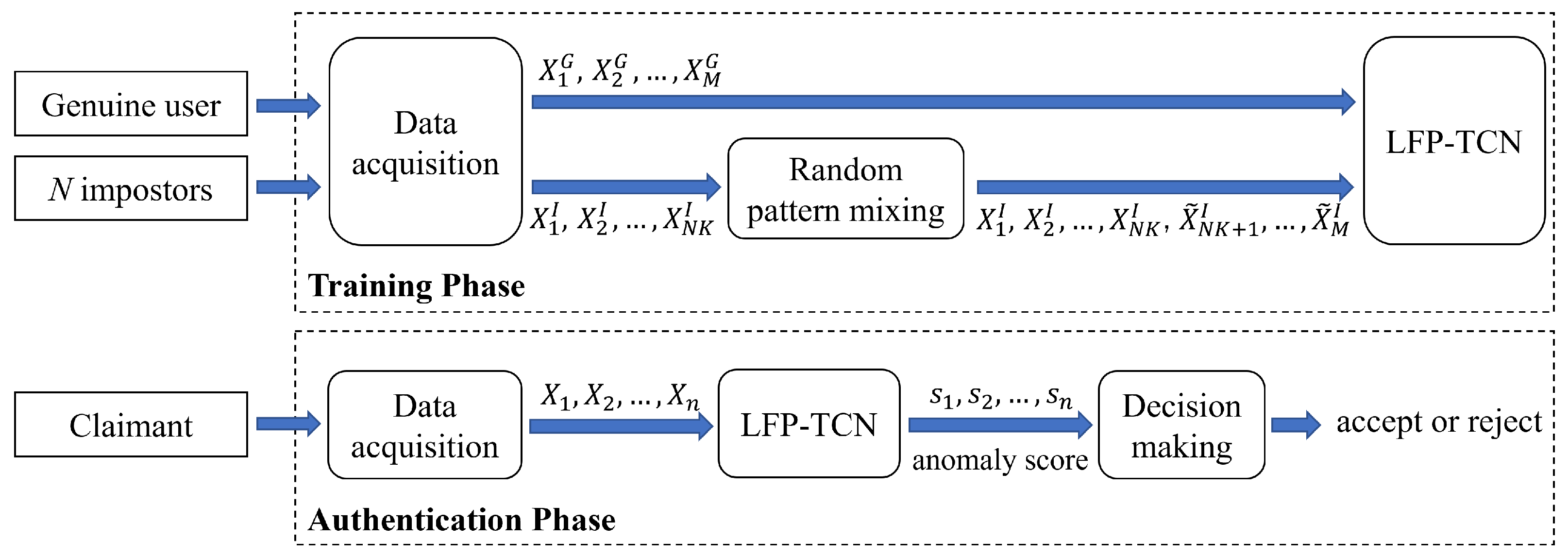
For deployment, mobile continuous authentication systems first capture sensor data of a genuine user (and impostors if available), which is used to construct the user’s profile. Then, claimants are monitored during re-authentication time and judged as “accept” or “reject”.
Motivation and Contribution
Since mobile devices are personal and hardly shared, mobile-based biometric authentication can be deemed an anomaly detection problem, in which models differentiate a single genuine user and all other impostors (anomalies). Prior works have different assumptions about the availability of impostor data with respect to unsupervised, semi-supervised, and fully-supervised learning. The approach relying on unsupervised or semi-supervised anomaly detection assumes that impostor data cannot be obtained in advance, solely depending on unlabeled or genuine data for the training [
2,
3,
4,
5,
6,
7]. However, this approach is poor at detecting impostors because they do not leverage prior knowledge of impostors.
On the other hand, the fully-supervised approach assumes that genuine and all impostor profiles (seen impostors) are available for learning [
3,
8,
9,
10,
16,
17]. An apparent issue of this approach is that models are not designed to work in an open-set setting—a practical scenario for biometrics, where it is unfeasible to have all impostor profiles available for training due to time and monetary costs. During authentication, the model may not infer correct decisions when encountering a never-seen impostor (unseen impostor).
Considering the issues of previous approaches, we posit the mobile-based authentication as a few-shot anomaly detection (FSAD) problem [
18]. FSAD is a subfield of weakly supervised learning in that only an incomplete set of anomaly classes is known at the training. In addition to the unavailability of complete knowledge of anomalies, FSAD is allowed to use only a few anomalous data. Recent works have addressed FSAD considering the availability of small-scale labeled anomaly data in real-world scenarios [
19,
20,
21,
22].
Compared to the fully supervised approach, FSAD is practical in mobile-based authentication. First, our model is sample-efficient because it uses only a few seen impostor (anomaly class) data for training. Secondly, our model aims to work in an open-set setting, where models encounter unseen impostors. By leveraging partial knowledge of seen impostors, our model excels at detecting unseen impostors more than unsupervised and semi-supervised models.
This work is the first attempt to address mobile-based biometrics authentication from the FSAD vein. Specifically, we define the challenges as follows:
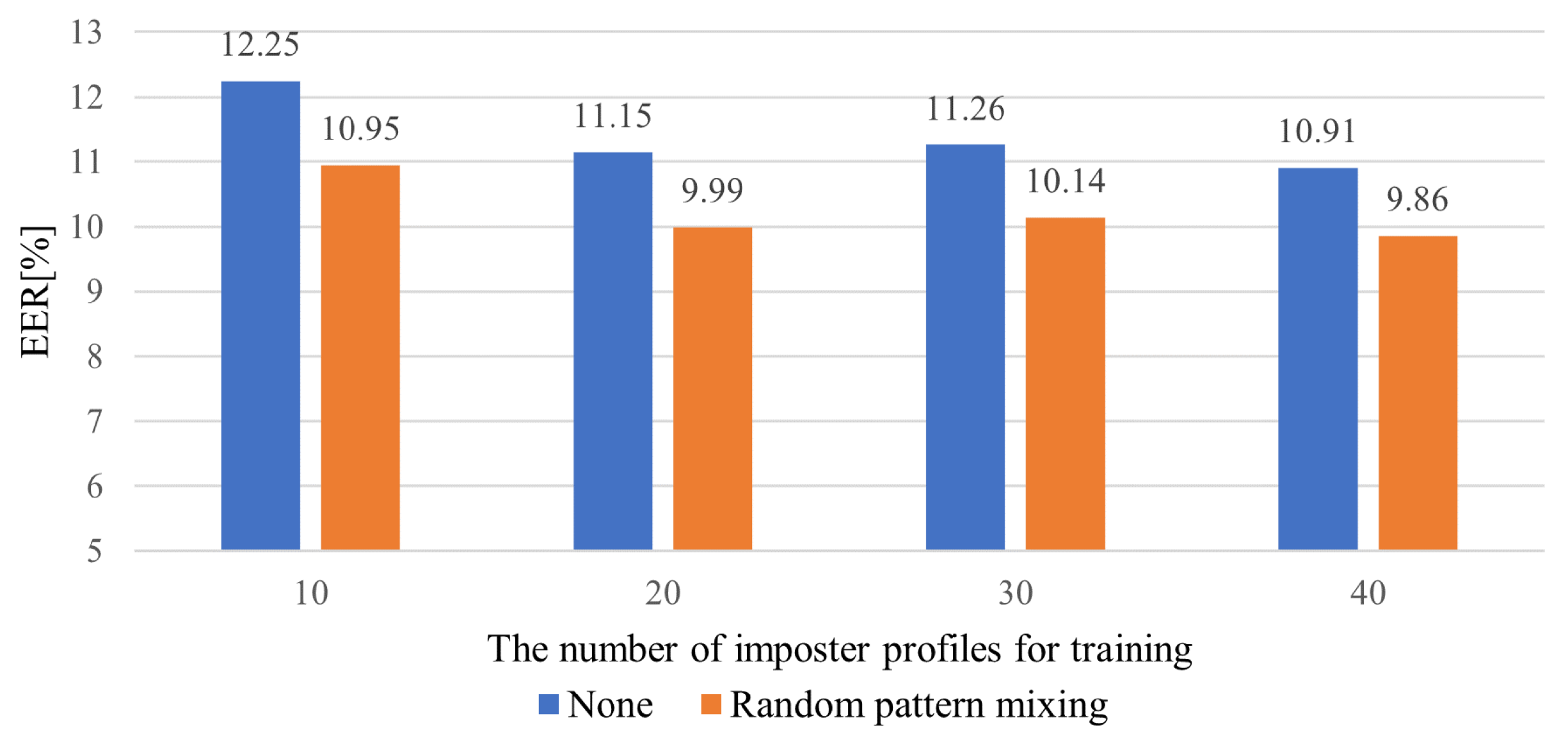
Limited impostor profiles for training:
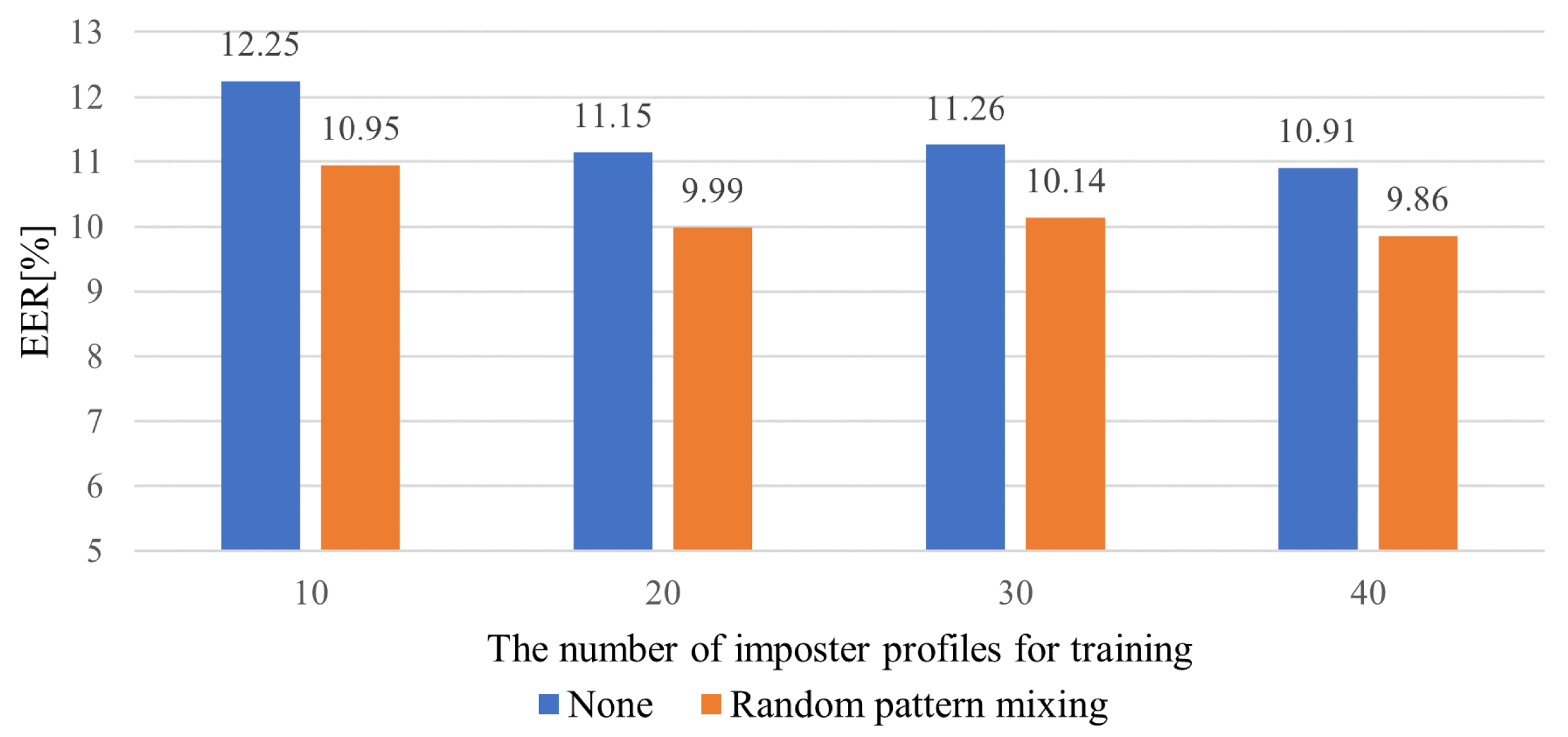
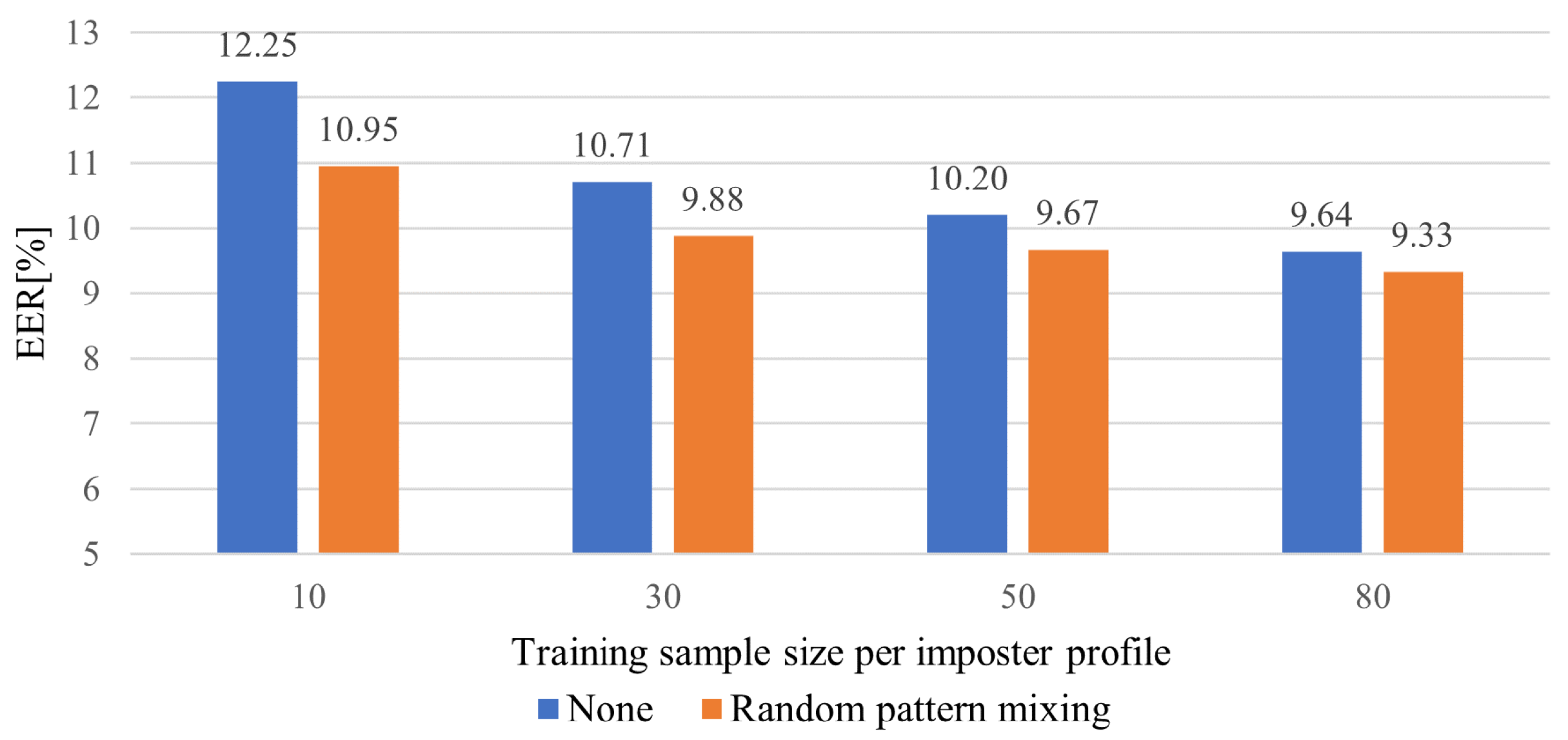
The core challenge of FSAD is the limited availability of seen impostor profiles. However, the models need to be able to detect arbitrary unseen impostors during inference.
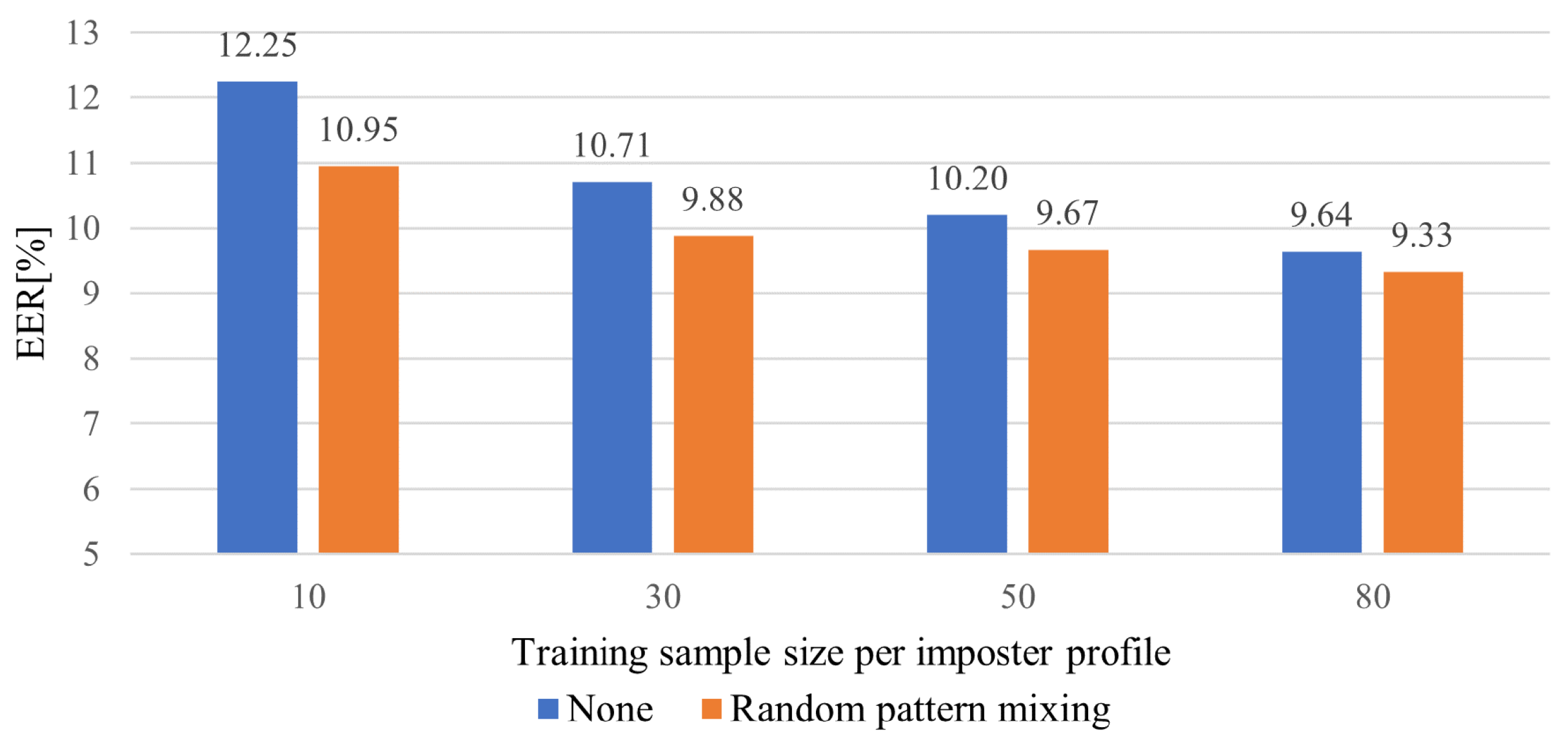
Class imbalance between genuine and impostor data:
Since FSAD uses extensive genuine and small impostor data, models inherently suffer from the class-imbalance problem. This can emphasize the genuine class and under-fit the impostor classes, preventing learning the impostor patterns adequately.
Large intra-class variance of user behavior data:
Due to the significant intra-class variance of raw touch sensor data, most touch-gesture authentication solutions have adopted hand-crafted features and conventional machine learning models such as support-vector machine, random forest, etc., which are more noise-robust than learned features [
11,
12,
13,
14,
23,
24,
25,
26,
27,
28]. However, hand-crafted features lack refined feature information, making it hard to characterize delicate impostor patterns.
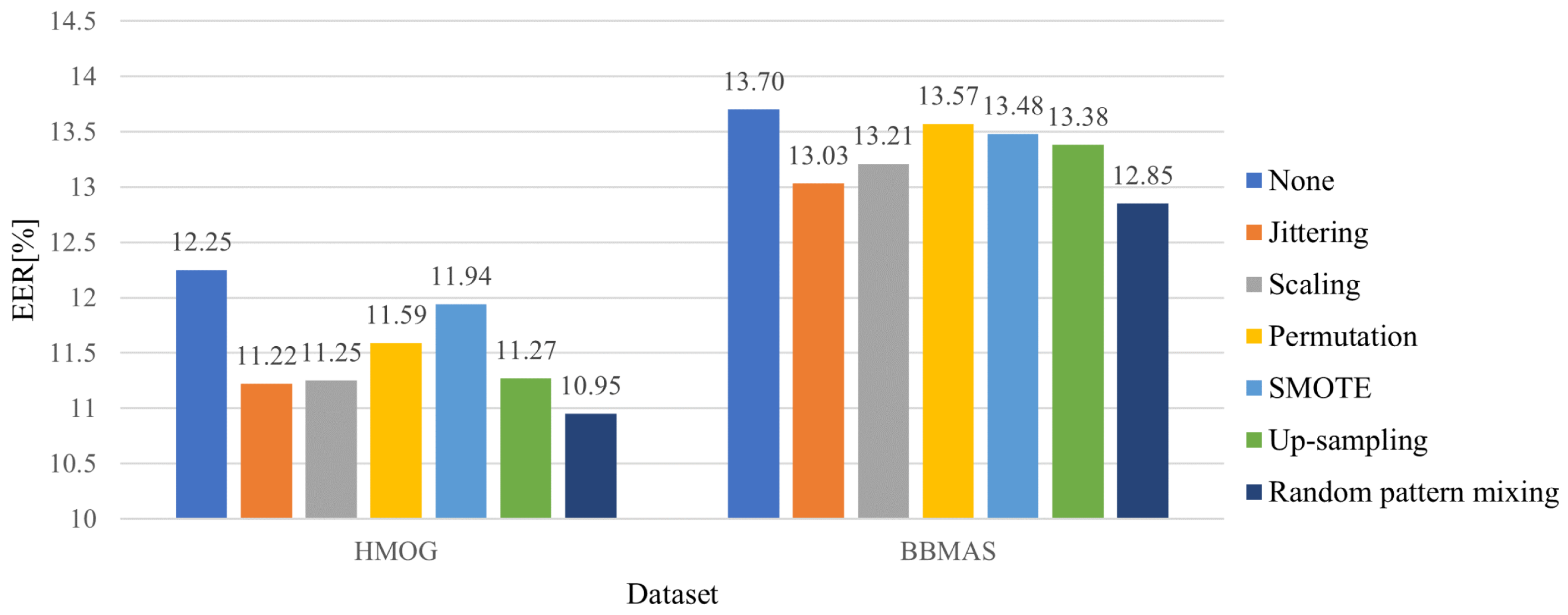
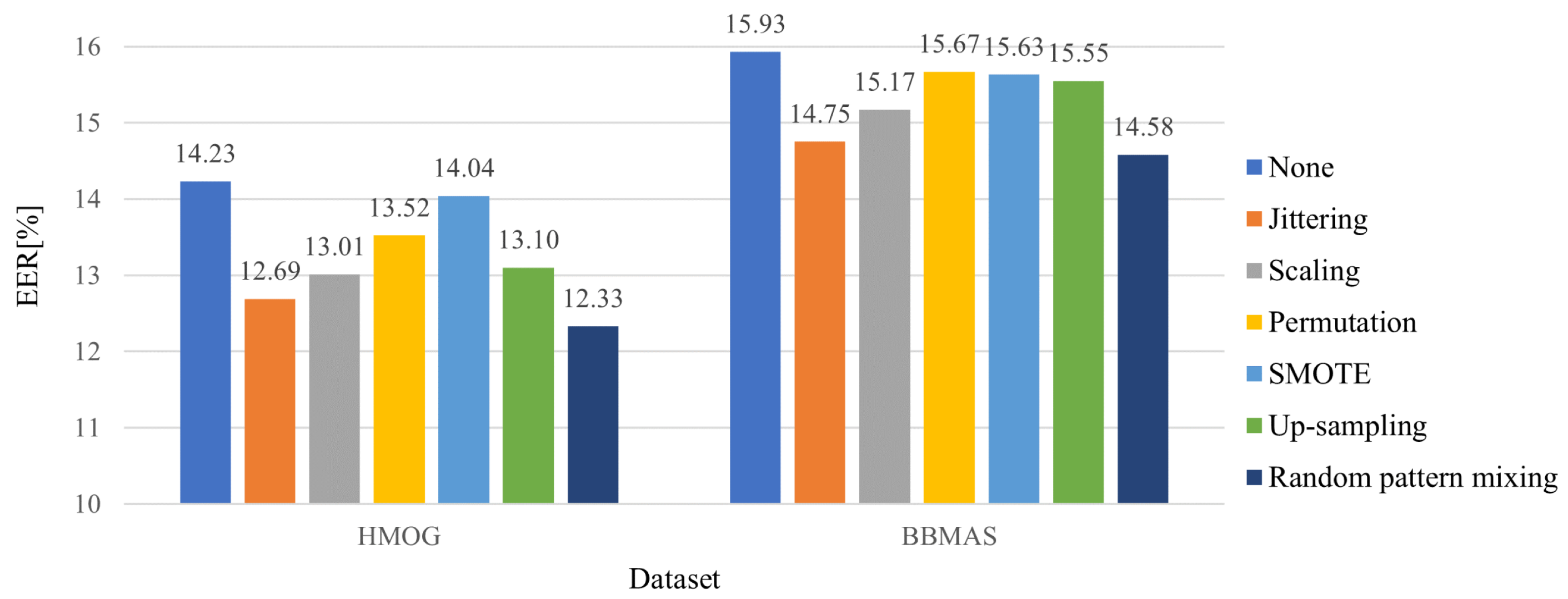
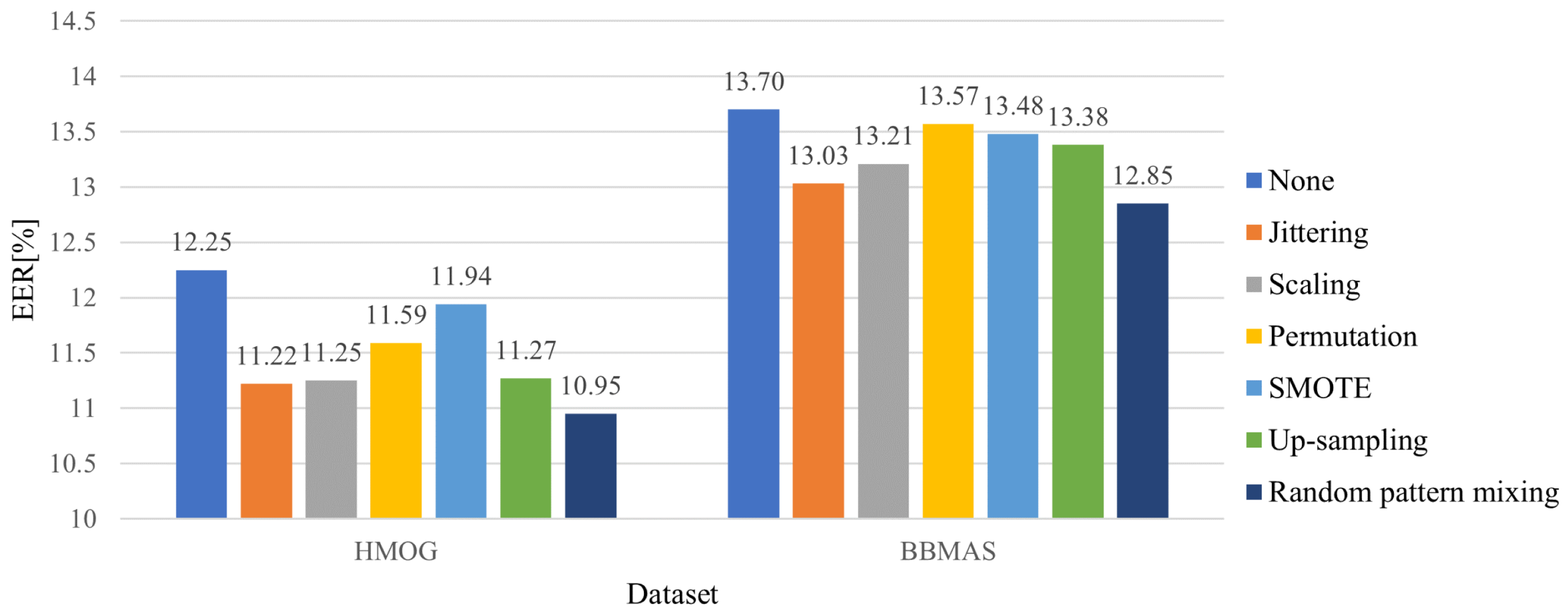
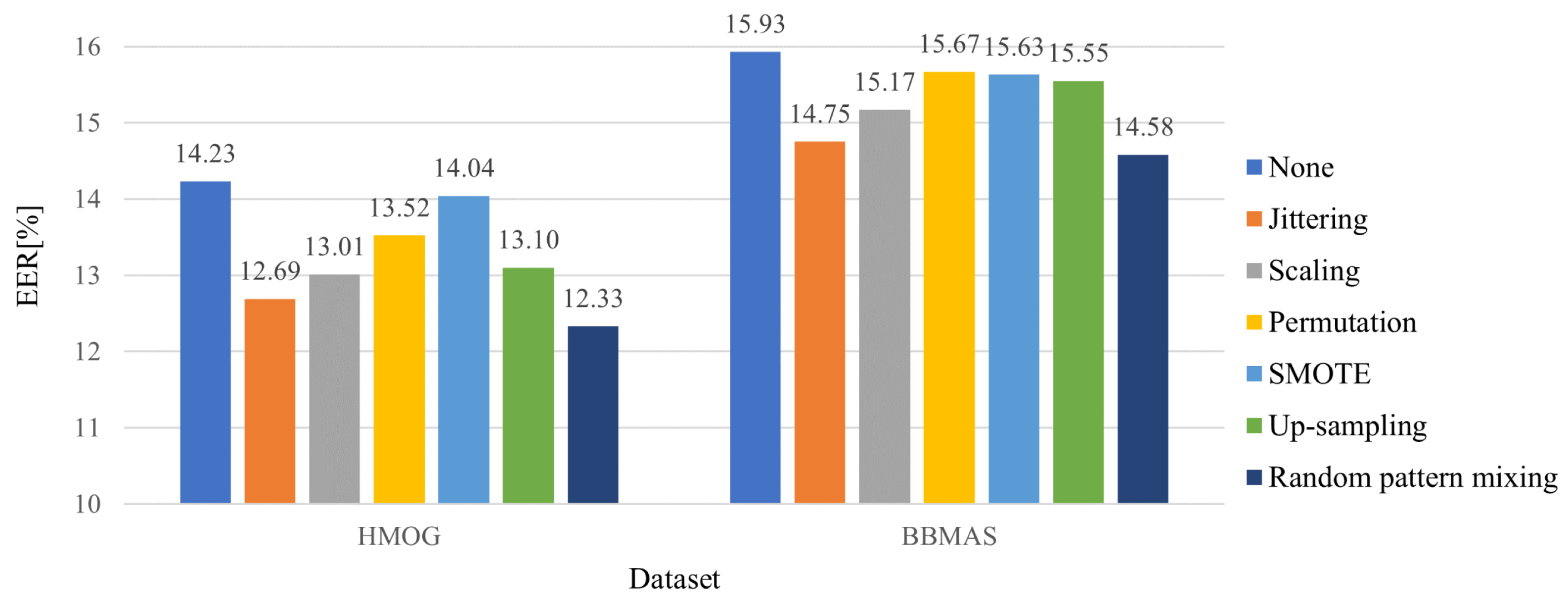
To address the first two challenges, we propose random pattern mixing—a data augmentation method tailored for sequential touch sensor data. While data augmentation has been extensively studied for visual data [
29], it is under-explored for anomaly detection [
18] and sequential data [
17]. A few primitive augmentation methods for sequential data, such as jittering and scaling [
3,
16,
17], are intended to generate data of a minority class (seen impostors in our case) by adding small noises or changing their magnitudes slightly, for example. Despite the fact that smooth decision boundaries between a genuine user and seen impostors yield better generalization, they do not help detect unseen impostors because unseen impostors may have completely different patterns from seen impostors. To improve the robustness against unseen impostors, the proposed random pattern mixing aims to enlarge the feature space of impostor data, producing various synthetic patterns not present in seen impostors.
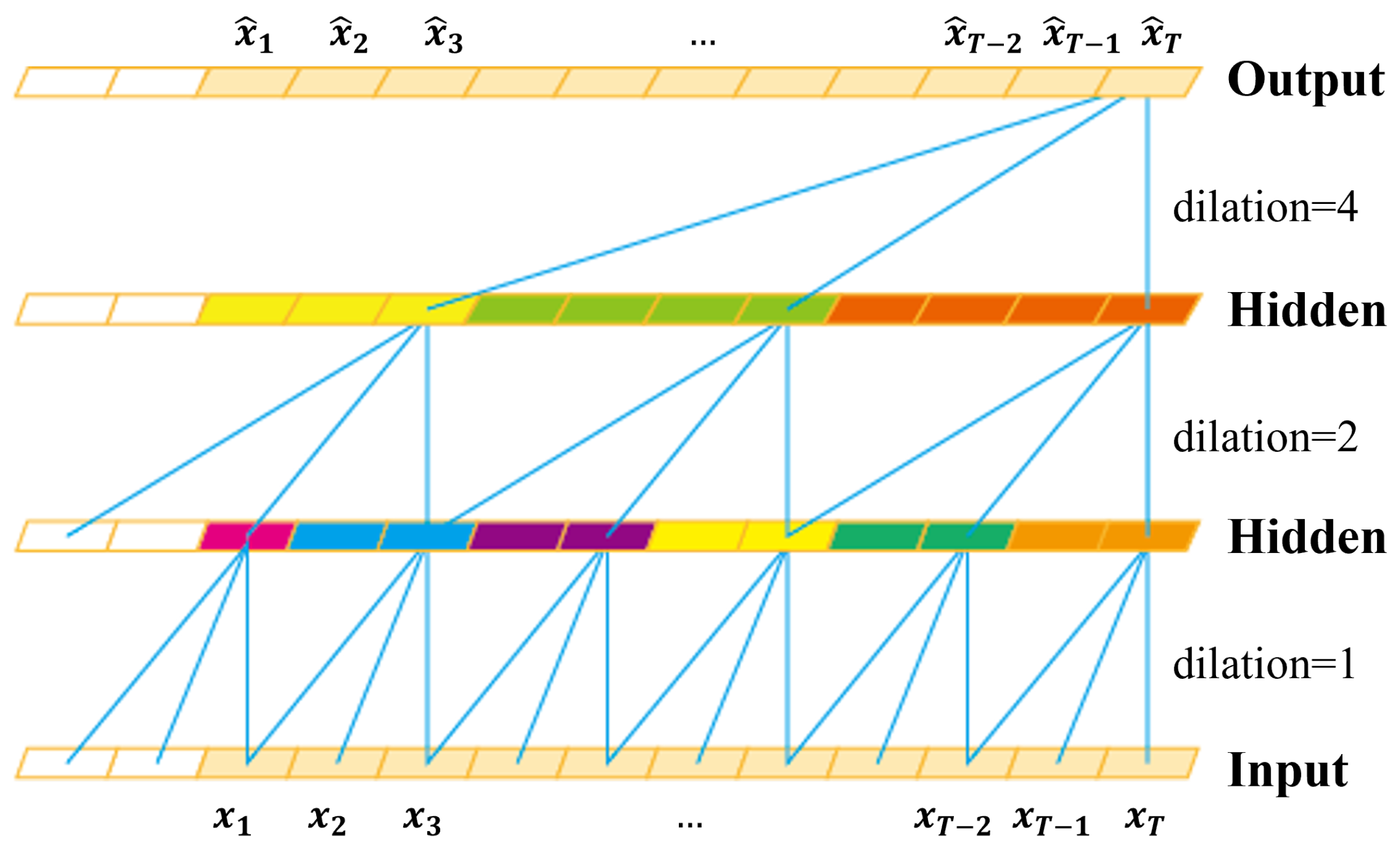
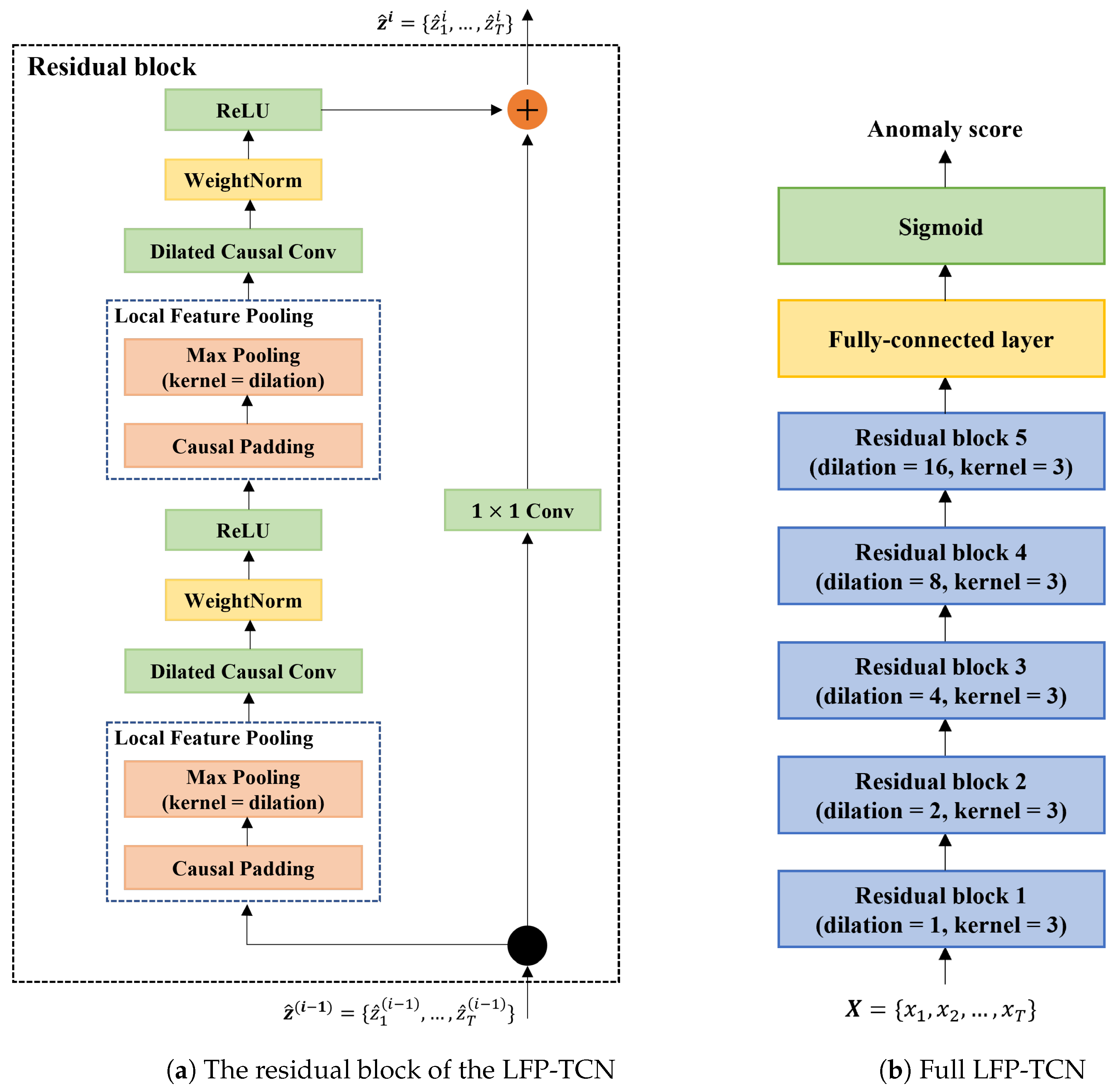
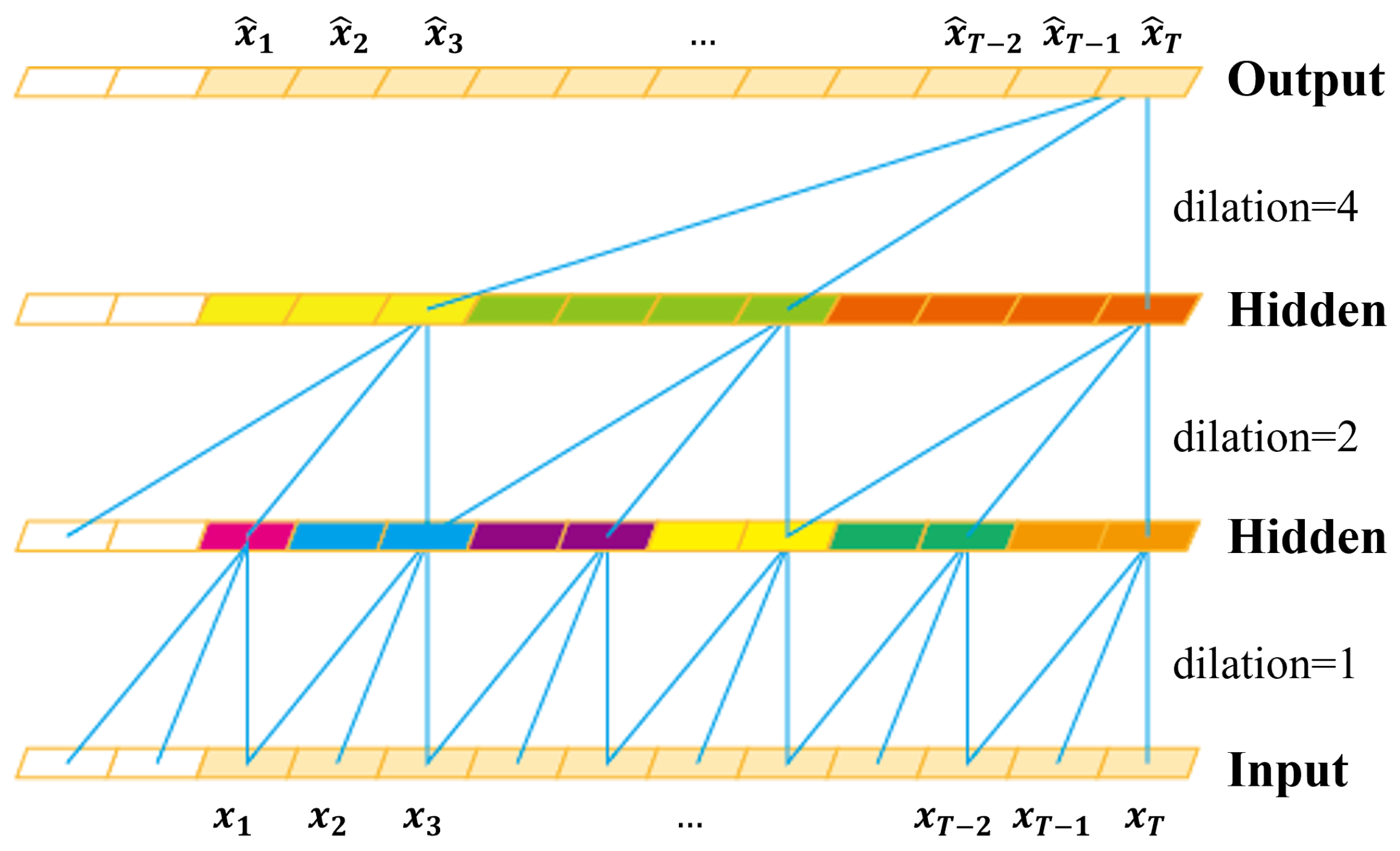
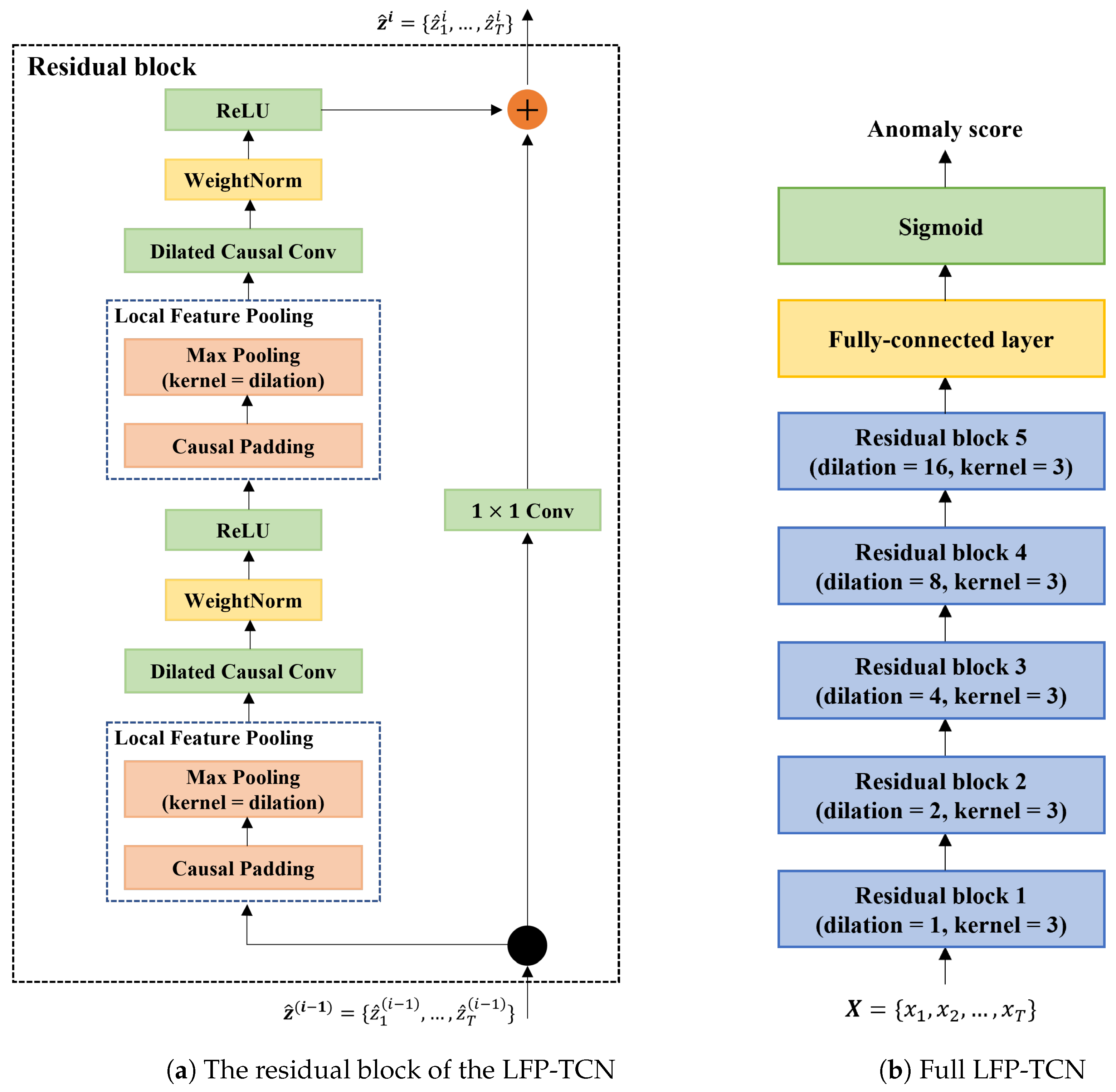
To respond to the third challenge, we devise a novel local feature pooling (LFP)-enabled temporal convolution network (TCN) for raw sequential touch sensor data modeling. The TCN [
30] is a variant of the convolution neural network (CNN) modified for sequential data modeling. Kim et al. exploited the TCN for touch-gesture authentication, showing its superior performance over the LSTM baseline [
31]. Indeed, the TCN can learn global information with its large receptive field and yields noise-robust global representations of touch screen data.
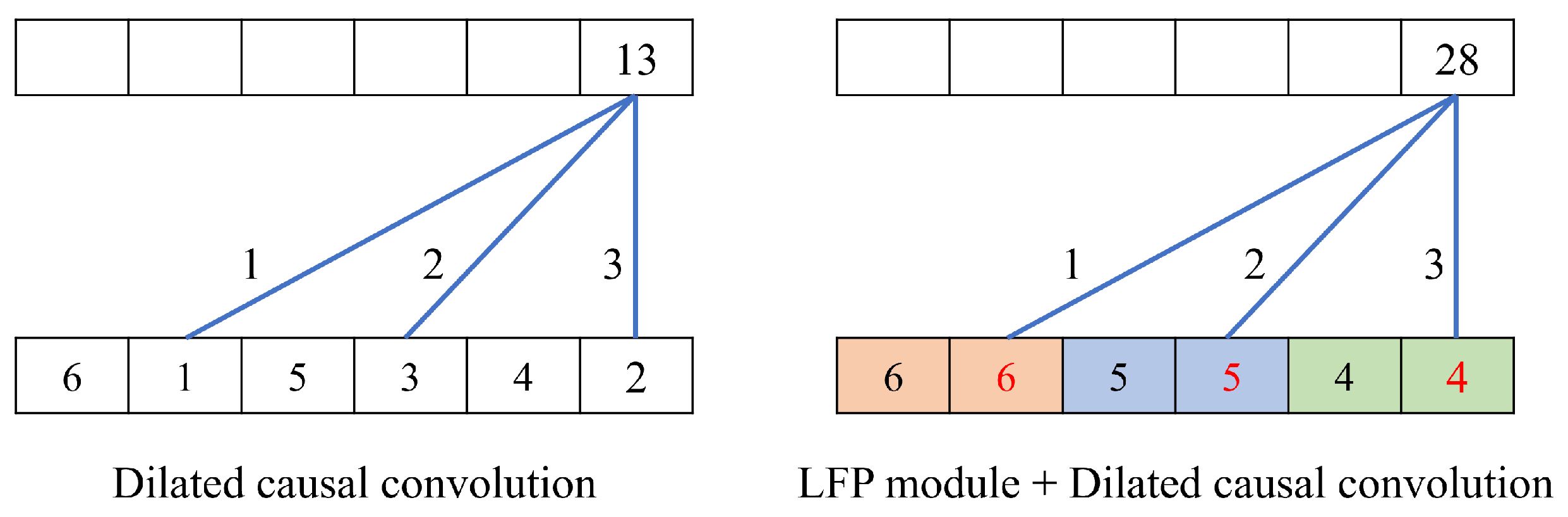
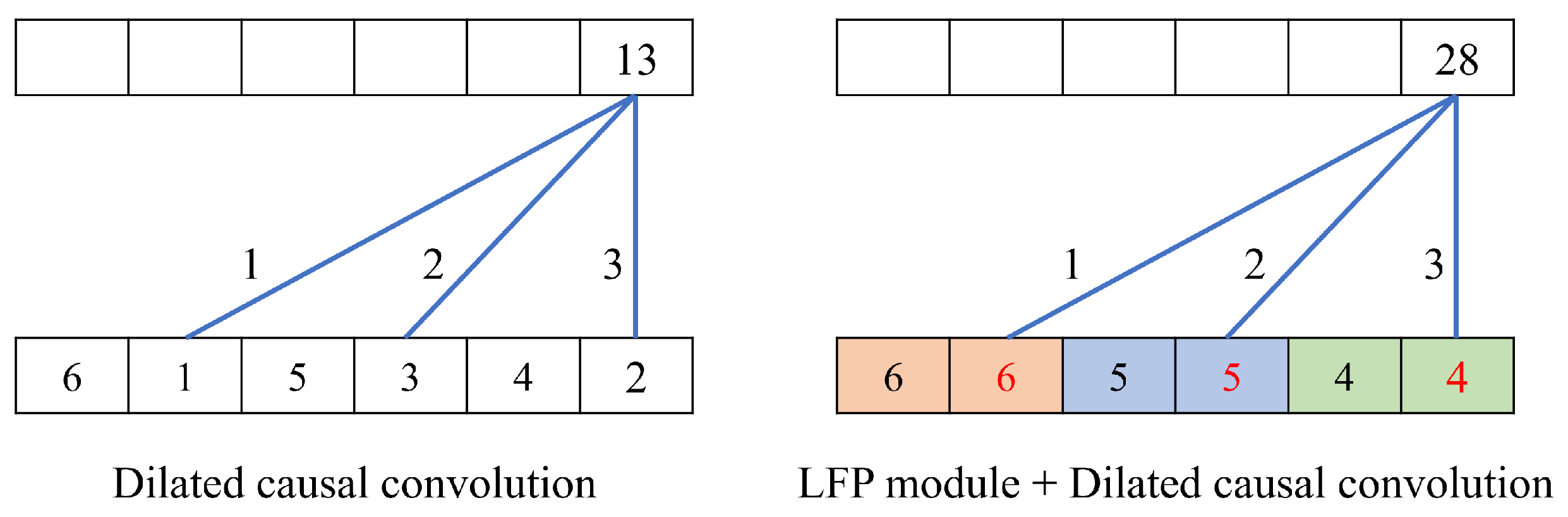
In this paper, we enhance the TCN with the LFP module, which enables aggregating local feature information to learn fine-grained representations of impostors. Specifically, the LFP module prevents local information loss due to the sparsity of the kernel in the dilated convolution. Moreover, the LFP module is parameter-free; thus, it is suitable for applications on memory-constrained mobile devices such as smartphones.
Finally, we demonstrate continuous authentication based on the decision and score-level fusion. Although many researchers have worked on continuous authentication, prior works have applied the sensor-level fusion, which enlarges window size according to re-authentication time [
2,
3,
5,
10]. However, this approach exaggerates the long-term dependency problem for the recurrent neural networks (RNNs) or increases the model complexity of the CNNs. Therefore, we explore alternatives using the decision and score-level fusion, which maintain the window size and prevent the problems above.
In summary, our contributions are as follows.
We formulate continuous mobile-based biometric authentication as a few-shot anomaly detection problem, aiming to enhance the discrimination robustness of the genuine user and seen and unseen impostors.
We present a sequential data augmentation method, random pattern mixing, which expands the feature space of impostor data, providing synthetic impostor patterns not present in seen impostors.
We propose the LFP-TCN, which aggregates global and local feature information, characterizing fine-grained impostor patterns from noisy sensor data.
We demonstrate the continuous authentication based on the decision and score-level fusion, which can effectively improve the authentication performance for longer re-authentication time.
The rest of this paper is organized as follows.
Section 2 reviews related works.
Section 3 introduces our authentication method.
Section 4 explains the experimental settings.
Section 5 presents the experimental results and analysis. Finally, we end with the conclusion in
Section 6.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}