1. Introduction
People are essential resources in the construction industry, so their safety should be a top priority. Accidents occasionally occur during the construction of large projects, making construction sites one of the most dangerous places to work. Accidents can result in injuries from cars, trucks, or objects falling from a height. Such injuries can result in the death of an individual (worker), which can cause damage to the worker’s family and the builder. Therefore, appropriate protective measures should be taken to address this risk. According to the U.S. Bureau of Labor Statistics (BLS) 2013 Workplace Injury Dataset, approximately 100 fatal and 7300 non-fatal head injuries were caused by falling objects on the job each year in the United States between 2003 and 2012. Many of these injuries could have been prevented if workers had regularly worn safety helmets. Wearing a helmet is an effective protective measure to minimize the risk of traumatic brain injury when the vertical fall of an object collides with a person’s head. Helmets effectively reduced the impact of heavy objects (concrete blocks) falling from a height of 1.83 m by 75% to 90%, compared to people who did not wear helmets [
1]. Therefore, introducing automated monitoring technology and regular site monitoring is essential to reduce the risk of accidents.
In recent years, many researchers have devoted their efforts to detecting workers in the field. Different researchers have tried many traditional techniques to detect the location and activity of workers. Most studies have used traditional vision-based computer vision and machine learning techniques, and the histogram of oriented gradients (HoG), background subtraction, and color segmentation, to detect the helmets of workers [
2,
3,
4,
5,
6]. Most of these methods are computationally expensive, and the accuracy is low.
With the development of deep learning, using convolutional neural networks (CNN) to locate and monitor workers has become very popular. Compared to traditional detection, CNN has improved dramatically in terms of accuracy. Many advanced algorithms such as SSD [
7], YOLO [
8], Faster-RCNN [
9], and Efficient-Net [
10] can detect features very accurately, and these methods can easily detect objects in real-time video streams. CNN and deep learning methods have several advantages over traditional methods. First, they can detect static and moving objects beyond traditional detection methods that rely on object movement. Secondly, they can detect workers in different poses, while traditional methods sometimes cannot detect objects when the workers’ poses change. However, most of the existing helmet detection algorithms are not end-to-end; these methods first detect workers and then determine the presence of helmets within the prediction frame. Such detection has some logical problems. For example, the helmet will be certified as a positive sample even if it is not worn as long as it appears in the prediction frame, which is the opposite of our monitoring needs.
On the other hand, existing object detection networks are generally complex, and the number of parameters is generally high. Such problems can lead to higher computational costs and make it challenging to meet the needs of real-time detection. This paper focuses on how to accurately and quickly detect workers’ helmets.
In this paper, the research objective is to identify whether all the people on a construction site are wearing helmets. At the same time, the mainstream object detection methods are computationally expensive and have low accuracy. To solve this problem, we designed an end-to-end one-stage convolutional neural network that achieves high accuracy while significantly reducing computational cost and can meet the real-time performance required for real-world detection.
The main contributions of this paper are as follows:
The proposed object detection network for helmet-wearing utilizes GhostNet, a lightweight network, as the backbone feature extraction network. It uses its cheap operation to make the model lighter overall while ensuring efficient automatic feature extraction.
In the feature processing stage, we designed multiscale segmentation and feature fusion network (MSFFN) to improve the algorithm’s robustness in detecting objects at different scales. In contrast, the design of the feature fusion network can enrich the diversity of helmet features, which is beneficial to the accuracy of helmet detection when the distance changes, viewpoint changes, and occlusion phenomena occur.
Our proposed lightweight residual convolutional attention network version 2 (LRCA-Netv2) is an improvement of the spatial attention module LRCA-Net proposed in our previous work. The main idea of the improvement is that by fusing the combined features along with the horizontal and vertical directions and then weighting the attention separately, such an operation can establish dependencies between the more distant features using precise location information. It has a good performance improvement over the previous module.
The mAP and FPS of the proposed lightweight helmet-wearing detection network evaluated on the combined dataset reach 93.5% and 42, respectively, improving our model in execution speed and accuracy compared to other methods.
2. Related Work
Traditionally, helmet detection is a tedious task. Before helmet testing, the person is usually tested. Du et al. (2011) [
11] detected helmets using a Haar-like feature algorithm. The Haar-like feature first detects possible face regions. Then, above the face region, it detects the helmet using color detection. The AdaBoost learning (classifier) method was adopted during the face and non-face classification, which helps to remove outliers.
Similarly, Silva et al. (2013) [
12] proposed a “Hybrid descriptor for features Extraction”, a traditional machine learning approach employed to detect helmets of motorcycle riders. His algorithm was based on a local binary pattern (LBP), a histogram of oriented gradients, and a circular Hough transform descriptor aided with a hybrid descriptor. SVM and random-forest classifiers were used for vehicle classification.
Later, workers were detected in live video streaming by an algorithm presented by Zhu et al. (2016) [
13]. Their vision-based method facilitates monitoring construction site workers to detect the wearing of a helmet, per safety regulations requirements. Histogram of gradient (HoG) features, combined with pair-wise matching, was used to detect the workers with helmets. This method relies on background subtraction to speed up the detection of human bodies. The proposed method allows a helmet of any color to be easily detected. Similar to the previous work, Shrestha et al. (2015) [
14] developed a tool that automatically detects the workers who are not wearing helmets in real-time video. The procedure uses a Haar-like feature detection algorithm that detects the worker’s face. Once the human face is detected, this information is sent to the helmet detection algorithm, which uses the edge detection algorithm (semi-circular appearance of helmet) combined with color detection, and detects the helmet on a worker’s head.
Another vision-based method by Park et al. (2015) [
15] came to light from research. The authors used the traditional machine learning approach with an available dataset of true and false matches of helmet images. The method contains background subtraction followed by SVM, dilation, erosion, and rectangle fitting. The authors extended the HoG technique to detect helmets directly in their work. It can easily detect the helmet with different colors. The helmet is detected in the upper part of the rectangle, which encloses the human. For training data, the helmets were annotated manually. Almost the same technique was adopted by Rubaiyat et al. (2016) [
2] with a different dataset of images, though they only used HoG and circular Hough transform with SVM to train the data in their approach.
Mneymneh et al. (2017) [
16] used SURF features combined with cascaded filters (HoG, Haar-like, and LBP) to detect workers with hard hats. The SURF detector also performed very well. Li et al. (2017) [
3] used the ViBe-Background modeling algorithm combined with HoG and SVM to detect helmeted workers in substations. The ViBe-Background algorithm extracts workers from complex backgrounds, and HoG + SVM detects whether workers are wearing helmets. The method achieves an accuracy of 89% when using test data.
In all, traditional methods have performed very well in the past, but all methods have some inevitable problems. Most of the methods shared the same issues while detecting helmets. In the methods above, most methods used HoG, color segmentation, and SVM. These methods mostly fail to detect illumination changes, occlusions, color variations, non-circular objects, and busy backgrounds. The advantage of traditional methods is that they do not require a lot of data to train. However, the execution speed and accuracy are not high.
To address the limitations of traditional methods, then there is a need to develop more robust helmet detection. Developing suitable CNN algorithms based on data from construction sites is a feasible solution to this problem.
In such attempts, Jiang et al. (2016) [
17] tried an artificial neural network (ANN) combined with statistical features (GLCM) to detect the helmets from low-resolution image data. The algorithm comprised a local binary pattern (LBP) and gray-level co-occurrence matrix (GLCM) aided with a back-propagation artificial neural network. GLCM is an image descriptor that characterizes the image. It was observed that ANNs could be trained by experience when applied to new unknown input data. Following the footsteps of ANN models, CNN modeling came into existence. CNN was a groundbreaking aspect of deep learning, gaining popularity in recent years. The CNN was improved, and many new sub-CNNs were developed to enhance the efficiency.
Fang et al. (2018) [
18] used the Faster R-CNN method to detect non-helmet-wearing workers. Faster R-CNN has a moderate processing time, but it has a higher precision when compared with old methods. Faster R-CNN is a two-stage algorithm, so when the Faster R-CNN is compared to competitive algorithms, the speed is lower than those methods. Therefore, a compromise should be made for speed and accuracy as Faster R-CNN is slow but highly accurate. On the subject of speed, YOLO, a new algorithm, was developed to overcome the speed issues of Faster R-CNN. Bo et al. (2019) [
19] administered YOLOv3 with Dark-Net-53 (backbone) feature detection algorithm for detecting unsafe actions conducted by workers on-site. The YOLO algorithm can easily be adapted to real-time surveillance systems to detect the helmet quickly. According to the data from this study, the accuracy was 96.6%. The good idea behind YOLO is that it is a one-stage algorithm. It can solve the regression directly but fail to generate a bounding box around RoI.
Similarly, Wu et al. (2019) [
20] used improved YOLO v3 with a Dense-Net backbone to identify whether or not workers wear a safety harness while working. Upon implementation, the YOLO-Dense-Net backbone can also detect occluded objects well. YOLO has many versions and can be modified into new algorithms. The version used in the above research was a modified YOLO v3, which was 2.44% better than the original YOLO v3.
The Single Shot MultiBox Detector (SSD) algorithm is worth mentioning when discussing one-stage algorithms. SSD’s success is its ability to withstand different sizes and multi-scale feature maps. Additionally, the architecture is simple and efficient. Due to SSD’s simplicity and frequent use, Long et al. (2019) [
21] adopted this algorithm to build a safety head protection detection model. The attractive part of SSD is that it uses less GPU and performs better than previously mentioned methods. In addition, the proposed method can achieve a real-time speed of up to 21 fps.
A comparative study was conducted by Nath et al. (2020) [
22]. The author built and compared three models using YOLO v3 architecture to check the speed and efficiency of all proposed models. The first model initially detects the worker and helmet, and then the information is passed to a machine learning classifier. The second model simultaneously detects workers with helmets in a single CNN framework. The third model uses cropped images, and then the CNN classifier classifies the images (as a helmet or non-helmet user). It was found that the second approach achieved the best results with 72% accuracy and could process 11 fps data. The third approach was second-best performing and gained an accuracy of 68%. However, the first model was the fastest and could process 13 fps with 63% accuracy.
With the update of the YOLO series, Hayat and Morgado-Dias (2022) [
23] proposed an automatic safety helmet detection system based on YOLOv5x with good detection capability for smaller objects and in terms of objects in low-light images.
Recently, Wang et al. (2020) [
24] fabricated a model based on lightweight CNN to detect helmets in real-time. A depth-wise separable MobileNet model was used for detection. In depth-wise convolution, a single filter to each input channel is applied, and then the pointwise 1 × 1 convolution is used to combine the outputs of the depth-wise convolution. The proposed MobileNet (adopted as the backbone) was used for fast multi-scale feature map generation. This means the network can detect small objects and can deal with occlusions. The average precision of the proposed method was up to 89.4%, with the running speed being 62 FPS.
In contrast, representative works such as [
25] proposed a sampling fusion network, SCRDet, which fuses multi-layer features with adequate anchor sampling to improve small object detection due to the difficulty of detecting objects of small size, any orientation, and dense distribution. Based on this, [
26] proposed SCRDet++ to highlight the features of small objects and reduce the interference of the background by designing an instance-level feature map denoising module in the feature map and improving the handling of rotation detection by incorporating the IoU constant factor into SmoothL1 loss. This work provides an excellent idea for dense small-size object detection.
In this paper, we propose a new one-stage lightweight automatic helmet wear detection algorithm to address the limitations of previous studies. The method’s superiority is demonstrated in the publicly available dataset, contributing to industrial application development and lightweight research on neural networks.
3. Methodologies
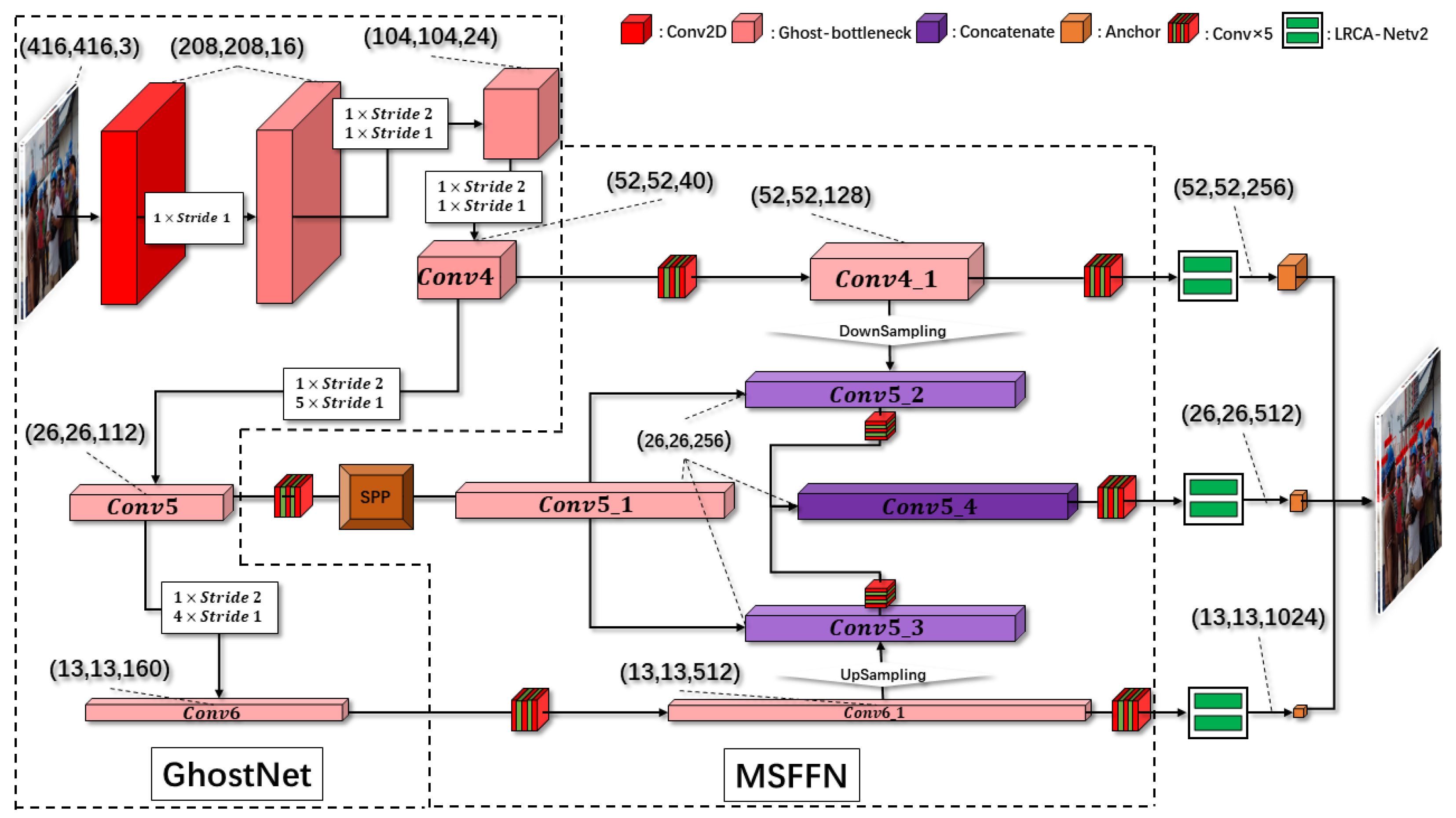
Figure 1 shows the network framework of the proposed helmet-wearing detection algorithm, which consists of three main components: a backbone feature extraction network, a multi-scale segmentation and feature fusion network, and an improved lightweight residual convolutional attention network, namely LRCA-Netv2.
GhostNet is the backbone feature extraction network to meet the network’s overall lightweight. The multi-scale segmentation and feature fusion network (MSFFN) improves the algorithm’s robustness in detecting objects at different scales. At the same time, feature fusion is also designed to facilitate the detection of helmets. In addition, the spatial attention module in LRCA-Net is improved. The original 7 × 7 convolution method, which cannot synthesize global information, is abandoned in the spatial dimension. The integrated features along the horizontal and vertical directions are fused and then weighted separately for attention, which is more effective in focusing on global features. The precise location information is used to make dependencies between more distant features. Experimental results show that such a design scheme can significantly improve helmet detection accuracy while greatly reducing computational costs.
3.1. Design of Backbone Network
Due to the application device’s limited memory and computational resources, the efficiency and lightweight nature of detection algorithms designed for the problem of wearing helmets are crucial. The research focuses on making the network less computationally intensive while ensuring accuracy. The overall computation of neural networks mainly depends on the number of parameters in the backbone network, so choosing a lightweight backbone network is essential. GhostNet [
27] (Han et al., 2020) obtains one of the similar feature maps by inexpensively manipulating the transform of another, such that one of the similar feature maps can be considered as a phantom of the other one. The phantom feature maps can be generated by cheap operations based on the Ghost module so that the same number of feature maps can be generated with fewer parameters than a standard convolutional layer, so fewer arithmetic resources are required. We chose GhostNet as the backbone network because it can improve the execution speed of models in existing designed neural network structures. The design of the backbone network was based on GhostNet with two modules in a series of steps, sizes 1 and 2, as shown in
Figure 2.
When Stride equals 1, no height and width compression is applied to the input feature layer, and the residual structure is used to optimize the network. When Stride is equal to 2, layer-by-layer convolution is added in the middle of the residual structure to compress the height and width of the input feature layer, respectively. The backbone network designed in this way reduces the number of parameters in the network and continuously obtains the deepened feature layers. Based on the feature maps obtained by one standard convolution, the feature maps can be compressed and deepened by one Stride 2 and multiple Stride 1s. We took the last three convolutional layers, namely Conv4, Conv5, and Conv6, with the shapes (52, 52, 40), (26, 26, 112), and (13, 13, 160), respectively. These three feature layers have multi-scale sensing information and contain three sizes that can be applied to different object features near and far. These three feature layers were fed into our proposed multi-scale feature fusion network (MSFFN) for the helmet detection task.
3.2. Multi-Scale and Feature Fusion Network
By analyzing the samples in the helmet dataset in 13 × 13, 26 × 26, and 52 × 52 multi-scale segmentation, the object as a whole can be captured as features, whether based on 3 × 3 or 5× 5 convolutional kernels.
Since the majority of convolutional kernels in the whole network have a size of 3 × 3, it is evident that the helmet wearer’s object size is a better match for the segmentation size of 26 × 26, as shown in
Figure 3, so when designing the feature fusion network, more attention should be paid to the size of the feature layers of 26 × 26.
In the feature fusion process, the Conv5 module of shape (26, 26, 112) is the first input to the spatial pyramid pooling (SPP), as in
Figure 4. SPP is performed by first halving the input channels by the Conv×5 module and then performing maximum pooling with kernel sizes of 26, 13, and 5, respectively, where the padding is adaptive to different kernel sizes. The results of the three maximum pooling operations are concatenated with the unpooled data, and the number of combined channels is restored to the same as the input. The Conv4_1 of shape (52, 52, 128), Conv5_1 of shape (26, 26, 256) and Conv6_1 of shape (13, 13, 512) are obtained, respectively. Next, Conv4_1 and Conv6_1 are downsampled and upsampled, respectively, and then combined with Conv5_1 to generate Conv5_2 and Conv5_3, respectively. Conv5_2 and Conv5_3 are also fused to obtain the new feature layer Conv5_4.
We designed the SPP module, as shown in
Figure 4, which aims to achieve the fusion of local and global features of the feature map. Because the size of the largest pooling kernel is the same as the size of the input feature map at this time, such a structure can enrich the expressiveness of the feature map and facilitate the case of large differences in object sizes in the images to be detected. Subsequent ablation experiments prove that the detection accuracy can be effectively improved after adding the SPP module. Combined with the design of MSFFN, multi-scale feature layers can be used to deepen the feature network and further enrich the diversity of shapes. Finally, the attention module is added to the three obtained feature layers of different scales, Conv4_1, Conv5_4, and Conv6_1.
3.3. Improved Lightweight Residual Convolutional Attention Network
In our previous work, we replaced the fully connected layer in the channel attention module of CBAM with 1D convolution. We added the residual structure to obtain the improved network LRCA-Net [
28] (Liang et al., 2022) so that the modified module can effectively capture the information of cross-channel interaction and reduce the overall number of parameters of the module to achieve overall efficiency.
However, we find that there is still room for improvement by analyzing the spatial attention module part of LRCA-Net (whose structure is shown in
Figure 5). The operation process is shown in Equation (1), i.e., maximum pooling and average pooling are used, respectively. Then, the two obtained features are connected and aggregated into a feature with the shape of H × W × 2. Then, it is directly convolved by a standard convolution layer of size 7 × 7, and then the spatial-refined feature
F″ by sigmoid:
where
As denotes the spatial attention module,
F′ denotes the channel-refined feature,
F″ denotes the spatial-refined feature
F″, σ denotes the sigmoid function, and
k7×7 represents the convolution kernel size of 7 × 7.
It can be seen that the drawback of this spatial attention module is very obvious. The direct 7 × 7 standard convolution for the feature map cannot obtain the feature map with integrated global information. As shown in
Figure 6, there is a lack of perceptual relationship between the two 7 × 7 convolutions for feature maps of size
n ×
n.
To solve this problem, we improved the spatial attention module, as shown in
Figure 7. First, we averaged the pooling based on the
X and
Y axes, respectively, for the input feature map
F′ with shape H × W × C as in Equations (2) and (3):
where
W is the width of the feature map,
H is the height of the feature map, and
is the feature map value within the feature map at (
i,
j).
The aggregated features obtained along the two directions are
X(
F′) with the shape
H × 1 ×
C and
Y(
F′) with the shape 1 ×
W ×
C, respectively, and the two features are concatenated and subjected to a 1 × 1 convolution operation to obtain the integrated feature
f as in Equation (4). This perception capability can provide the correlation between features in the same space and accurately retain their location information, which helps to locate the object more accurately:
where [,] represents the concatenate operation,
ReLU is the normalization and activation function, and
f is the integrated feature.
After passing
f through the 1 × 1 convolution split by the sigmoid function, respectively, two sets of attention, such as
As(
H) with the shape
H × 1 ×
C and
As(
W) with the shape 1 ×
W ×
C are obtained as Equations (5) and (6):
The obtained attention weights are combined with the input features to obtain the spatial refined feature
F″ as in Equation (7):
Therefore, using the new spatial attention module to replace the previous method, the improved attention mechanism LRCA-Netv2 overall structure can be obtained, as shown in
Figure 8.
Using a combination of features along with horizontal and vertical directions, the idea proposed in this paper focuses on the spatial dimension and weights the attention separately to focus on the global features more effectively. Previously, spatial attention was based solely on convolution and used precise location information to create dependencies among more distant features.
5. Conclusions
To reduce the risk of head trauma to workers during construction work at high-risk workplaces such as construction sites, it is critical to develop an algorithm that can automatically and robustly detect helmet wear.
In this paper, we designed a novel one-stage lightweight end-to-end convolutional neural network aimed at identifying whether people on a construction site are wearing helmets or not. This algorithm achieves high accuracy while significantly reducing computational costs and can meet the real-time performance required for real-world detection. The designed neural network first utilizes GhostNet, a lightweight network, as the backbone feature extraction network. It uses its inexpensive operation to make the model lighter overall while ensuring efficient automatic feature extraction. Secondly, we designed a multi-scale segmentation and feature fusion network (MSFFN) in the feature-processing stage to improve the algorithm’s robustness in detecting objects at different scales.
In contrast, the design of the feature fusion network can enrich the diversity of helmet features, which is beneficial to improving the accuracy of helmet detection when distance changes, viewpoint changes, and occlusion phenomena occur. For the attention module, we propose LRCA-Netv2, an improved version of LRCA-Net, and it has a good performance improvement over the previous one. Finally, the mAP and FPS of the proposed lightweight helmet-wearing detection network evaluated on the dataset reached 93.5% and 42, respectively. Our model has excellent performance compared to other methods. This work provides new ideas for improving existing helmet wear detection algorithms and model lightweight efforts. Future developments will involve expanding the variety of construction site detection objects, especially for small objects, and focusing on such working directions as improving the loss function, combining modules with adaptability, and combining helmet detection with tracking techniques for monitoring other objects.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}