1. Introduction
In the Nineteenth Century, the quality of people’s travel was greatly improved with the birth of the first automobile. The components of semi-active suspension systems, which mainly include shock absorbers, elastic elements, and dampers, play a key role in improving the smoothness, handling stability, and passenger comfort of a car.
An onboard sensor is used to extract the road information for the semi-active suspension system, through the adjustment of the damping coefficient to improve the smoothness and stability of the vehicle. At present, the control strategy of semi-active suspension has been extensively studied. A controller was proposed by [
1] to characterize the inverse dynamics of magnetorheological dampers using a polynomial model. Rao et al. [
2] proposed an improved sky-hook control (SHC) strategy to optimize the parameters by equating the control force of the feedback system with that obtained by a linear quadratic regulator (LQR). The paper [
3] proved the conditions for the feedback controller in the ideal state using linear matrix inequalities (LMIs) and Liapunov functions that depend on the time lag distance. Based on variational optimal control theory, an open-loop variational feedback controller for semi-active control of a suspension system was proposed in [
4]. A fuzzy controller and an adaptive fuzzy controller were developed in [
5] to achieve road holding and passenger comfort on most road profiles. The article [
6] developed an adaptive fuzzy sliding mode control method based on a bionic reference model, which takes into account the variation of the vehicle mass and is able to provide both finite-time convergence and energy-efficient performance. The article [
7] developed a new dynamic model named the QSHM model based on quasi-static (QS) models and hysteretic multiplier (HM) factors. On the basis of the implementation of a new method of experiment-based modeling of magnetorheological hydrodynamics, several hysteresis multiplier factors were introduced. The article [
8] developed a self-powered magnetic rheological (MR) damper to effectively control the vibration of a front-loaded washing machine. The damper consisted of a shear MR damping part and a generator with a permanent magnet and induction coil. The paper [
9] proposed a new adaptive control method to deal with dead zones and time delay problems in actuators of vibration control systems. In addition, fuzzy neural networks were used to approximate unmodeled dynamics, and sliding mode controllers were designed to enhance the robustness of the system to uncertainty and robustness. Based on the Bolza–Meyer criterion, a new optimal control law related to sliding mode control was developed in [
10]. The controller has gain adjustability, where the gain value can be greater than one. Most of the aforementioned methods are based on establishing an accurate mathematical model and proving the effectiveness of the proposed control strategy through a rigorous theory, which is computationally intensive and more difficult to implement in practice.
Since its introduction in 1954, reinforcement learning has been developed over the years with reformative advances in both theory and applications. In terms of theory, the deep Q-network (DQN) algorithm was proposed in [
11], which solved the problem of the difficult convergence of training under off-policy by end-to-end training mode. The deep deterministic policy gradient (DDPG) algorithm was proposed in [
12], which is based on the DQN, using a replay buffer and target network for updating, while using a neural network for function approximation. The paper [
13] proposed the trust region policy optimization (TRPO) algorithm, which was improved for policy optimization and solves the problem of selecting the update step size during the policy update, which enables the policy update of the agent to be monotonically enhanced, but it also has the problem of high computational complexity. Compared with control strategies based on mathematical models, reinforcement learning can generate a large amount of data by interacting with the environment and find the best strategy from the sampled data, so it has been successfully applied in several application scenarios. In 2017, Alpha Go defeated Ke Jie by using reinforcement learning algorithms, which is the world’s top-ranked Go player, and since then, reinforcement learning has been known to the public [
14] from the Wuzhen Go Summit. The paper [
15] proposed a deep reinforcement learning framework in the MOBA game Honor of Kings, enabling the AI agent Tencent Solo to beat top human professional players in 1v1 games. In recent years, the PPO algorithm [
16] based on the actor–critic algorithm uses an importance sample to transform the on-policy into the off-policy, which is conducive to fully reusing the sampled data, avoiding data waste and speeding up the learning rate, and the CLIP function is used to control the step size of the gradient update of the policy, so that the control strategy is monotonically improved without violent shaking. The PPO algorithm has been applied in several application scenarios. In paper [
17], the PPO algorithm was applied to image caption generation; a single model was trained by fine-tuning the pre-trained X-Transformer, and good experimental results were obtained. The paper [
18] utilized the proximal policy optimization (PPO) algorithm to construct a second-order intact agent for navigating through an obstacle field such that the angle-based formation was allowed to shrink while maintaining the shape, and the geometric centroid of the formation was constantly oriented toward the target. The PPO algorithm is suitable as a control strategy for semi-active suspensions because of its ability to continuously interact with the environment to achieve policy improvement and optimize monotonic enhancement through importance sampling, as well as due to its computational simplicity.
At present, the application of reinforcement learning in vehicle suspension control has attracted much attention and achieved a series of results in order to reduce the dependence on accurate mathematical models for the design of control strategies for suspension systems and to overcome the influence of its own uncertain parameters and the external environment on the control performance. The article [
19] explored the application of batch reinforcement learning (BRL) to the problem of designing semi-active suspensions for optimal comfort. In the article [
20], the performance of a nonlinear quarter-car active suspension system was investigated using a stochastic real-valued reinforcement learning control strategy. The article [
21] developed a secure reinforcement learning framework that combines model-free learning with model-based safety supervision applied to active suspension systems. A model-free reinforcement learning algorithm was proposed based on a deterministic policy gradient and neural network approximation in [
22], which learned the state feedback controller from the sampled data of the suspension system. Liu Ming et al. [
23] used the deep deterministic policy gradient algorithm (DDPG) as the control strategy of a semi-active suspension system, which adaptively updates the learned reward value based on the control strategy based on the learned reward values and achieved good control results. The above results fully demonstrate that the use of reinforcement learning algorithms as the control strategy for a semi-active suspension system does not require a strict theoretical definition and accurate mathematical modeling, which can greatly reduce the amount of computation and simplify the complexity of the algorithm. It cannot be ignored that the performance of the vehicle suspension is related to vehicle driving comfort and driving safety, and the performance indicators should be different when facing different road conditions. However, existing successful designs do not sufficiently consider the integration of road information with vehicle driving status to guide the design of relevant strategies.
Motivated by integrating the road condition changes with the reward function, a PPO-based semi-active control strategy is proposed to improve the ride comfort and driving safety. The main contributions are listed as follows:
(1) The PPO algorithm was used as the control strategy of the semi-active suspension, and the body acceleration, suspension deflection, and dynamic tire load were selected as the state space to set the reward function of the PPO algorithm to optimize the performance of the semi-active suspension system;
(2) Combining the road variation with the reward function made it possible to improve the suspension performance by dynamically adjusting the weight matrix of the reward function for different levels of roads;
(3) The proposed control strategy was proven to be effective in improving the performance of the suspension by conducting simulations under different vehicle speeds, vehicle models, and road conditions.
The rest of the paper is organized as follows: In
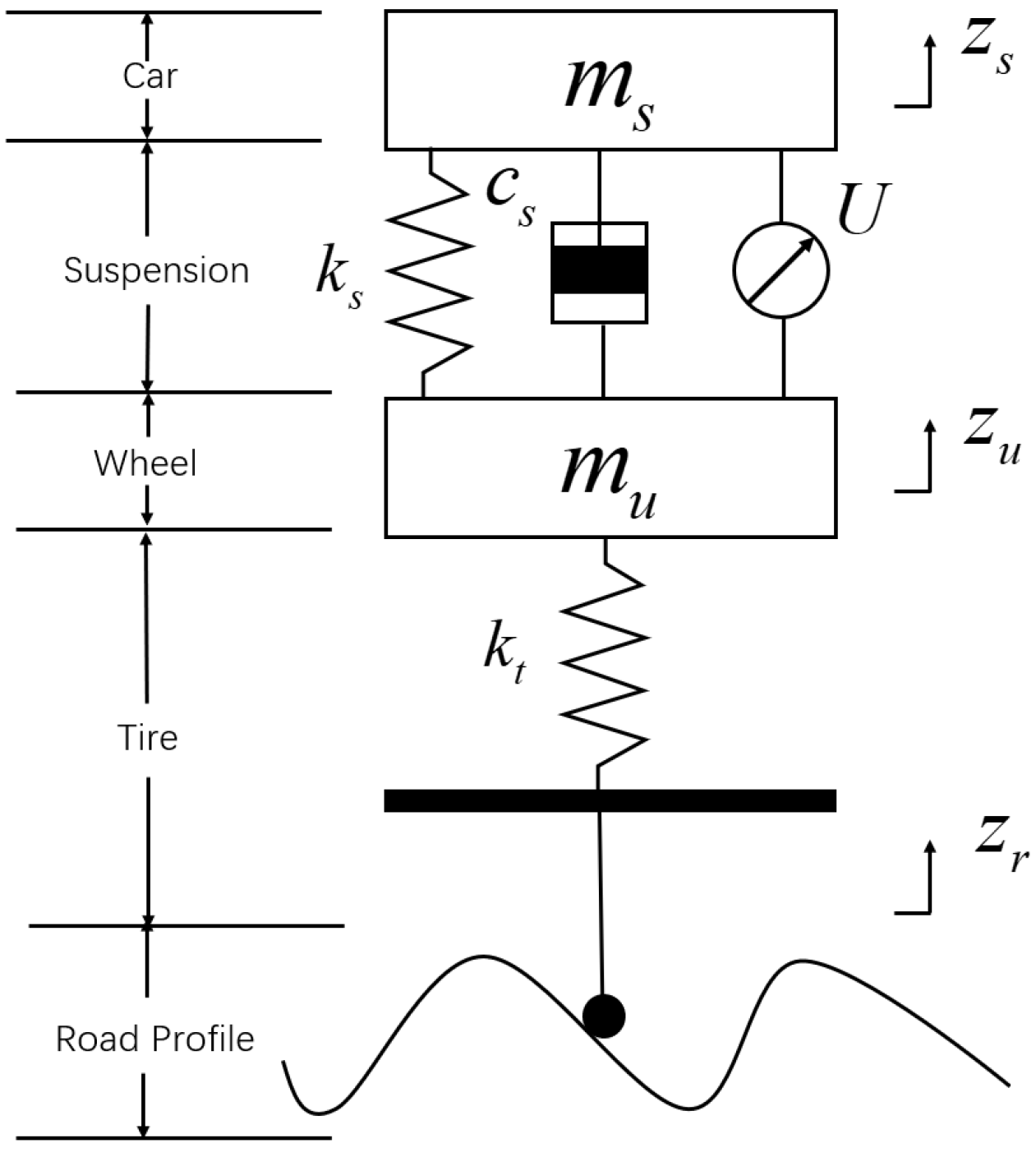
Section 2, we give a systematic modeling of road disturbances and a two-degree-of-freedom (DOF) quarter semi-active suspension system model. Details of the implementation of a semi-active suspension system based on the proximal policy optimization (PPO) algorithm are given in the
Section 3. The simulation experiments and results are given in
Section 4. Finally,
Section 5 gives a conclusion and future work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}