3.1. Activities in Spoken Academic Lecture
In this section, we introduce a classification of teaching activities identifiable from academic spoken discourse in university classes. Specifically, our interest is to come up with a set of academic labels which characterize teaching STEM subjects and which are useful for students to be able to access the contents of the syllabus as well as to easily find any organizational issue related to the course.
Our proposal is inspired by the typical structure of a lecture presented by Malavska in [
22] and the academic labels used by Diosdado et al. in [
39]. Our set of labels is organized according to whether the label identification is more dependent on the audio signal or on the automated transcription.
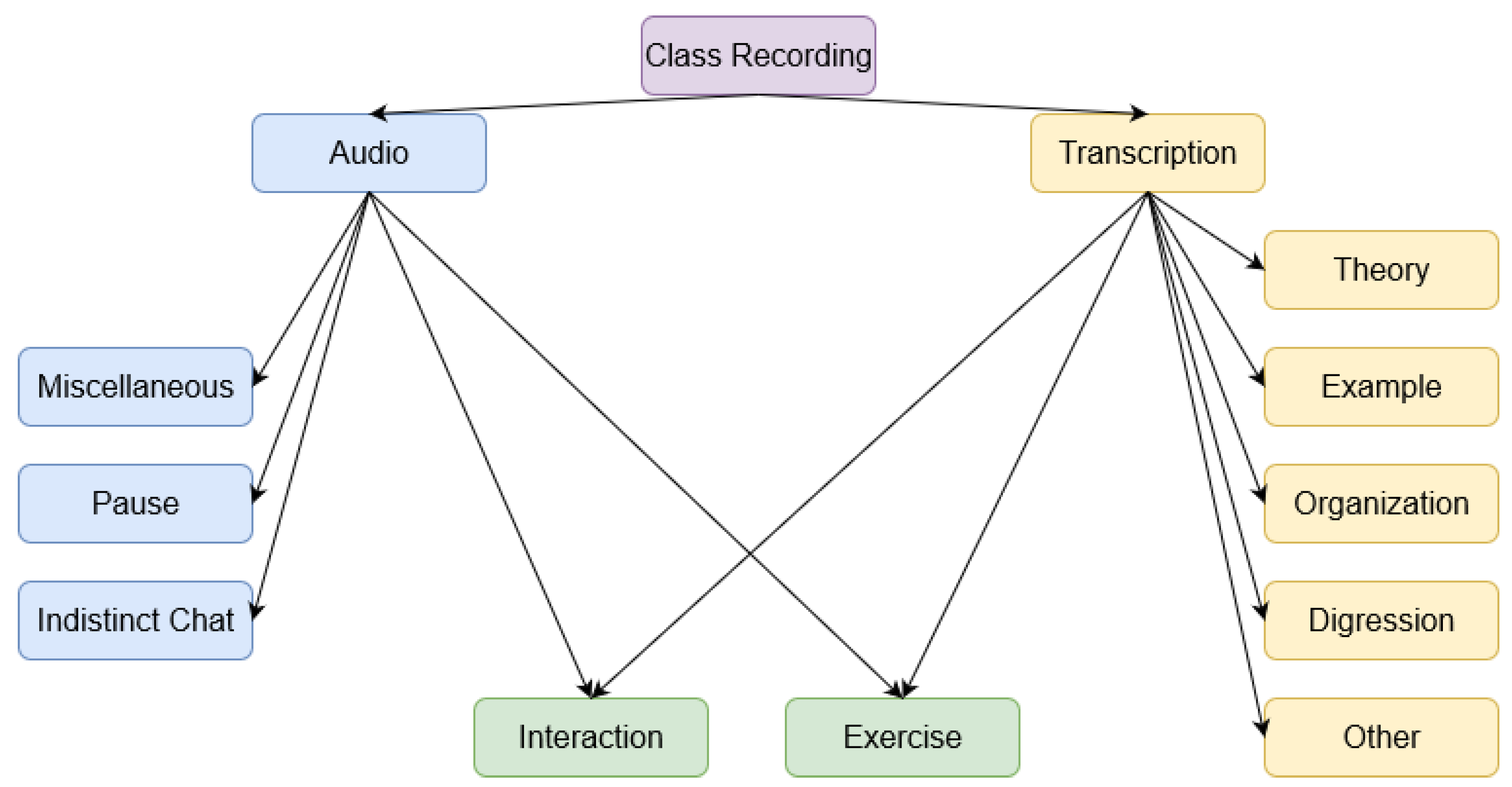
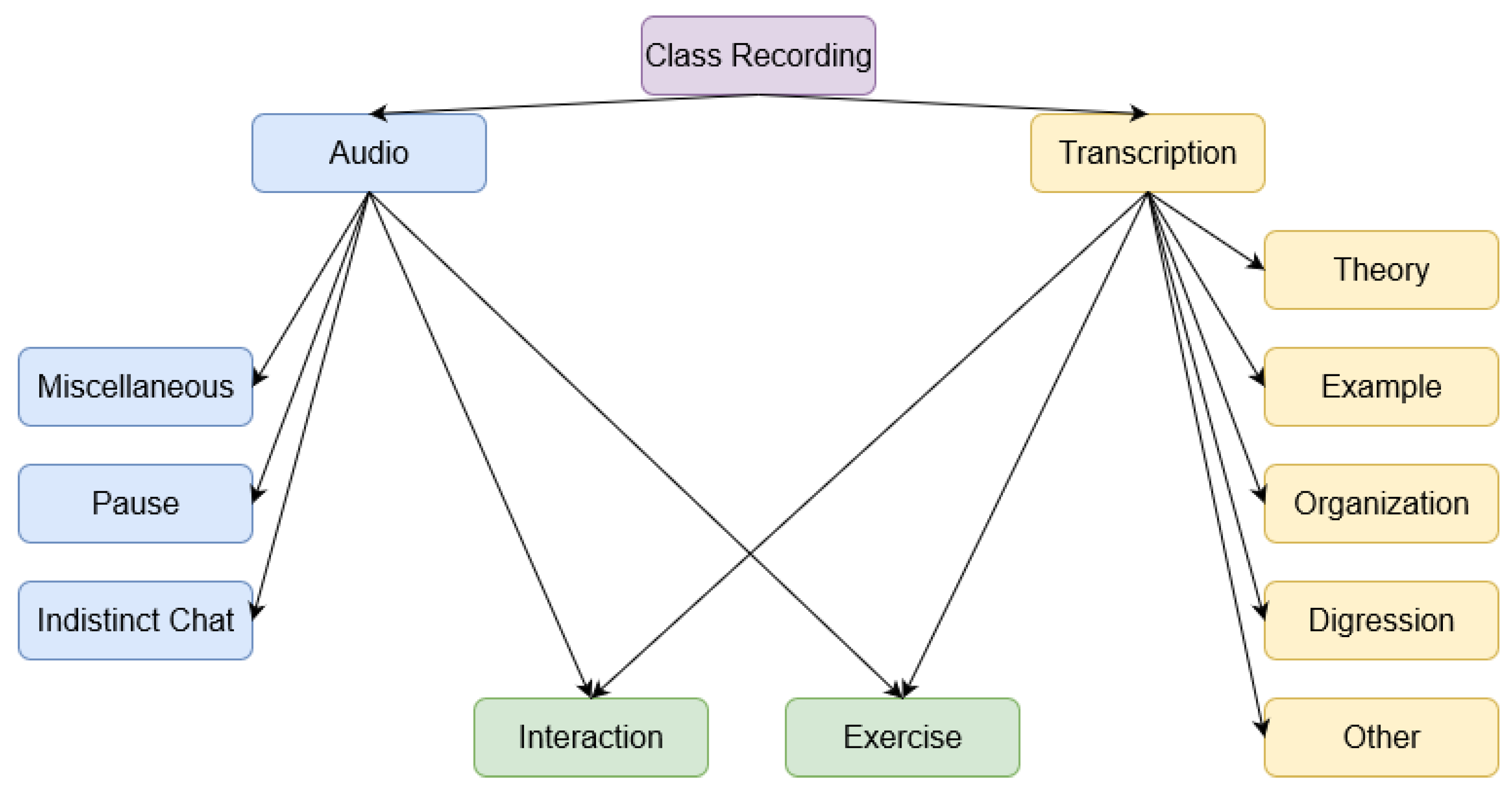
Figure 1 shows the hierarchy of labels. The labels under the ’Audio’ category are used to filter out sounds from the audio file which do not feature voices or when the recorded voices are murmurs, which are meaningless for our task. This includes sections of the audio file resulting from a muted microphone or microphone feedback (Miscellaneous), background noise (Indistinct Chat) or periods of silence between segments of speech (Pause).
The right branch of the tree in
Figure 1 comprises the activities that come up during a regular expository class around the syllabus of a subject. The activities classified only under the category ’Transcription’ denote the nature and communicative purpose of the teacher’s speech. Under this category we gather the activities that typically involve an extended speech of the teacher with no interactions from the students: exposition of the theory (Theory) and illustration of theoretical concepts through concrete examples (Example), information about organizational issues, grading policy, assignments, scheduling, housekeeping, etc. (Organization), a shift of the lecturer speech to a more personal discourse or course-related asides (Digression), or a speech around non-course-related matters (Other).
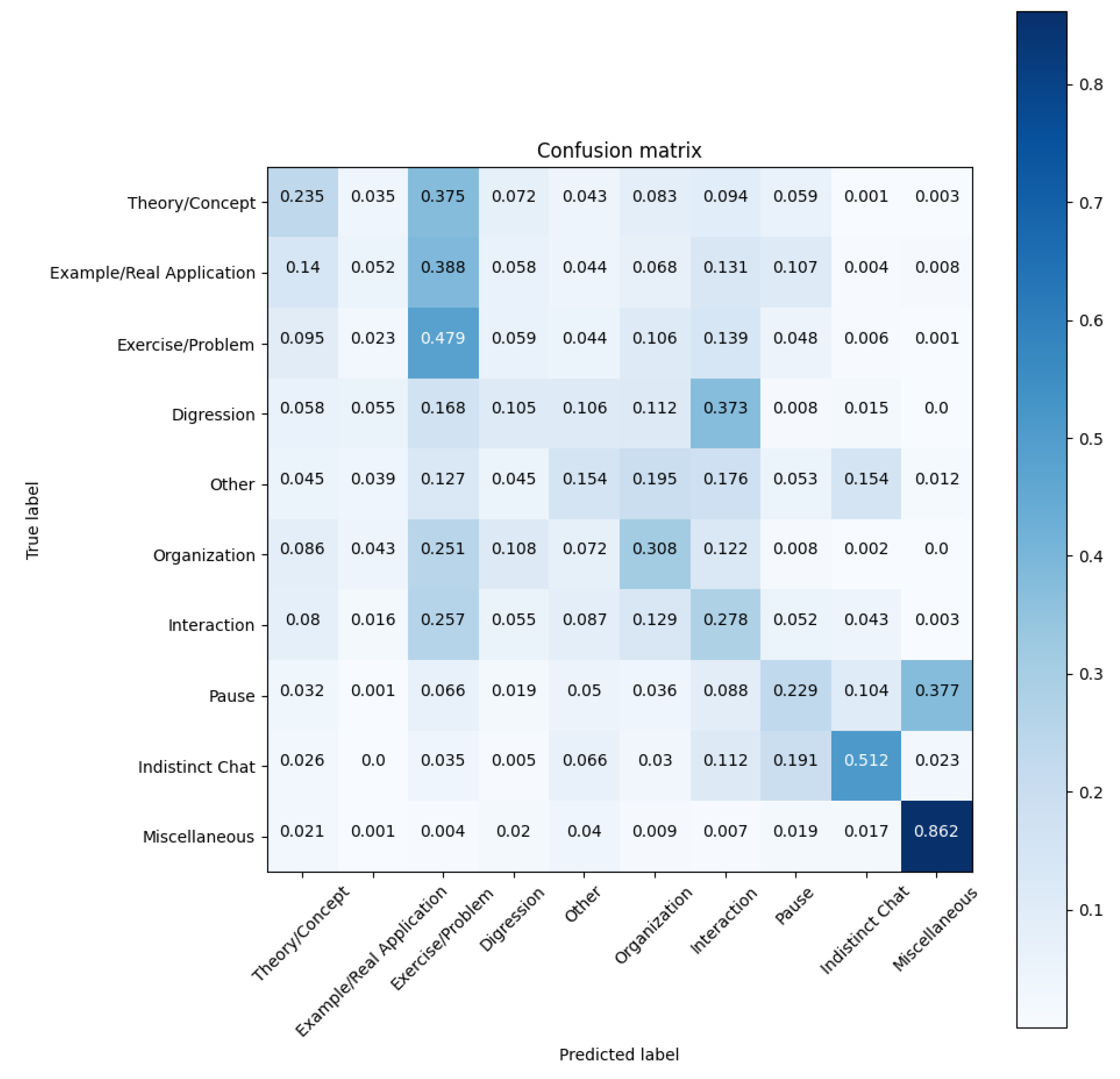
We identified a third group of activities which were not distinguishable by analyzing separately the audio file and the transcription. Typically, these activities involved an exchange of communication between the teacher and students. We placed under this mixed category the label “Interaction”, which represents teacher–student conversations that come up during the class, and the label “Exercise”, which accounts for a common activity in scientific/technical courses (in nontechnical contexts this label could be replaced by “Practical Activity”). Our experience from the visualization of multiples class recordings is that student engagement is far more frequent during problem and exercise solving than during theory exposition. This is the reason why “Exercise” is an activity classified under both Audio and Transcription categories.
3.2. Audio and Transcriptions Files
Our goal was to recognize the teaching activity that a lecturer was doing at any given time during a class. To this end, we needed to segment the class recording (audio and transcriptions) and classify each segment in its corresponding activity. A segment represented a linguistic meaningful unit such as a word, a sentence, a paragraph or any information unit depending on the task of the text analysis.
We worked with recordings from university lectures delivered in Spanish which were obtained from a repository at our university (UPV). The classes were recorded using a camera that focused on the scaffold and the blackboard, and a lapel microphone worn by the lecturer. With this setup, we obtained a video and audio recording of the lecturer. The lapel microphone captured the lecturer’s voice with good quality. However, due to the characteristics of this kind of microphone, it was not possible to obtain a reliable capture of the students’ voices.
Regarding the automatic transcription of lecture notes, we used the MLLP transcription and translation platform for automated and assisted multilingual media subtitling that provides support for the transcription of video, audio and content of the courses (
https://ttp.mllp.upv.es/index.php?page=faq) (accessed: 20 January 2022) [
40,
41] .
The final dataset consisted of 34 audio files and automated transcriptions, each corresponding to a delivered class, which amounted to a total of 3773 min. We selected recordings from five male professors and five female professors to ensure gender variety, and chose a wide range of subjects, such as mathematics, oceanographic physics, digital signal processing, etc., to ensure subject diversity. A breakdown of the dataset by subject and gender can be found in
Table 1. We manually labeled the automated transcriptions following the label hierarchy shown in
Figure 1.
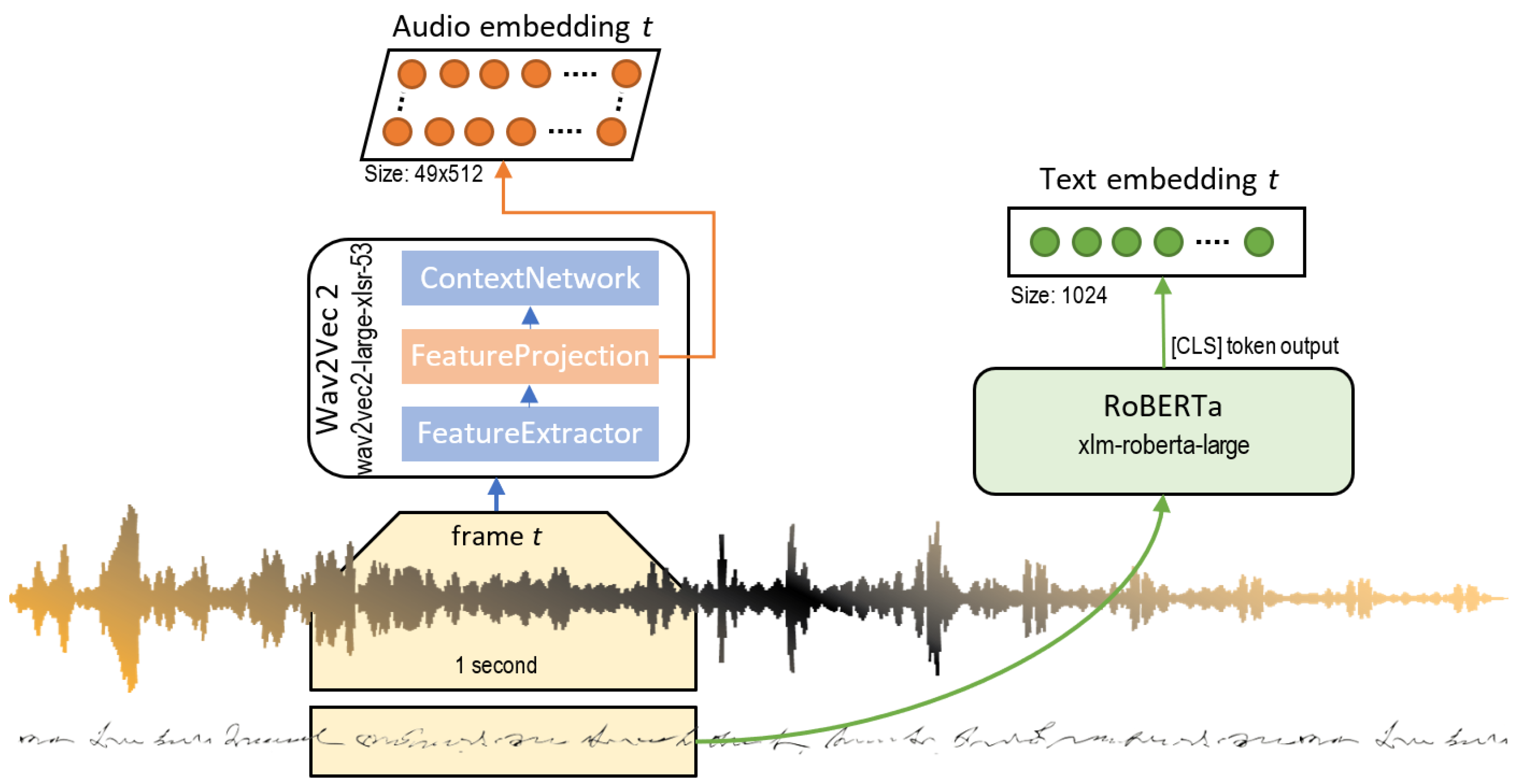
We put the primary focus on the contents of the lecture, i.e., on the automated transcription. Our aim was to exploit powerful pretrained language models so that we could differentiate teaching activities based on a specific vocabulary, the use of dates and the verbal form employed by the teacher. The reason why we used an online transcription and translation platform of a research group from our own university UPV was because this system performed better in the academic speech setting, specifically because it transcribed scientific and technical expressions as well as mathematical formulae more accurately than other transcription systems we tried, such as, for instance, the transcription tools of YouTube or Microsoft Teams.
Even so, the automated transcriptions featured unwanted characteristics such as lack of punctuation, the absence of capital letters and minor errors. All these issues made our task more complex because of the noise introduced in the transcription and the absence of markers that split the transcribed text in smaller units such as, for instance, sentences. Some transcription files, however, were manually revised and thus have punctuation symbols, capital letters, etc. Whenever it was possible, we used the manually revised transcription due to their higher quality.
Regarding the audio signals of the recordings, they provided key features of the lecturer’s speech, such as the tone, the cadence or the pauses between utterances. In the following, we show the raw audio waveforms and the corresponding transcription of some of the teaching activities identified in the class recordings. The waveforms were obtained with the Audacity tool [
42], a free open-source audio editor and recorder. We examined the raw waveforms of various academic activities and analyzed their differences.
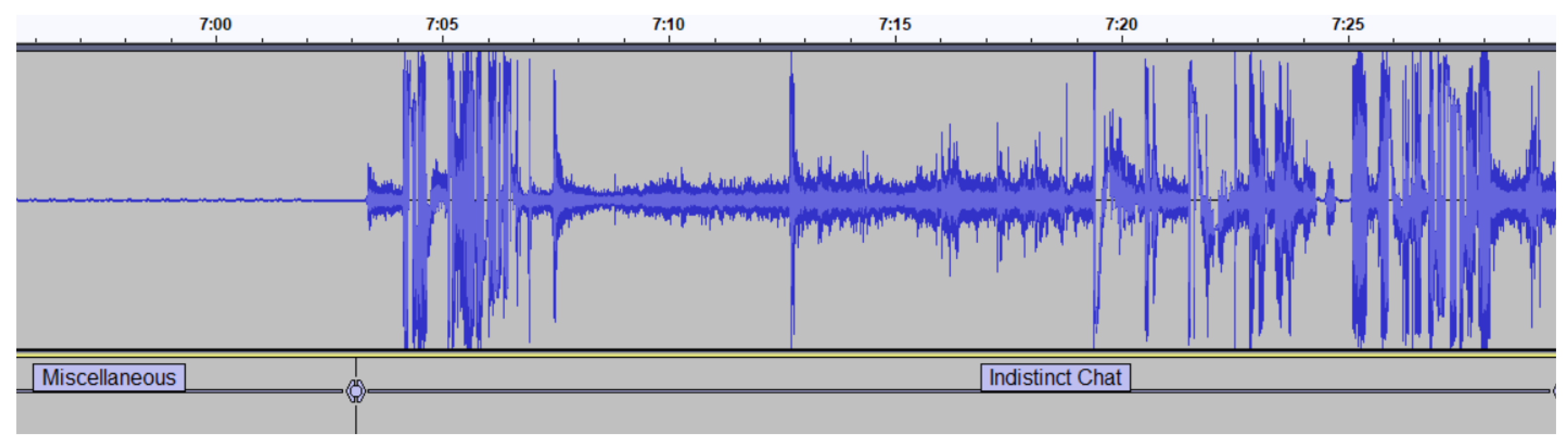
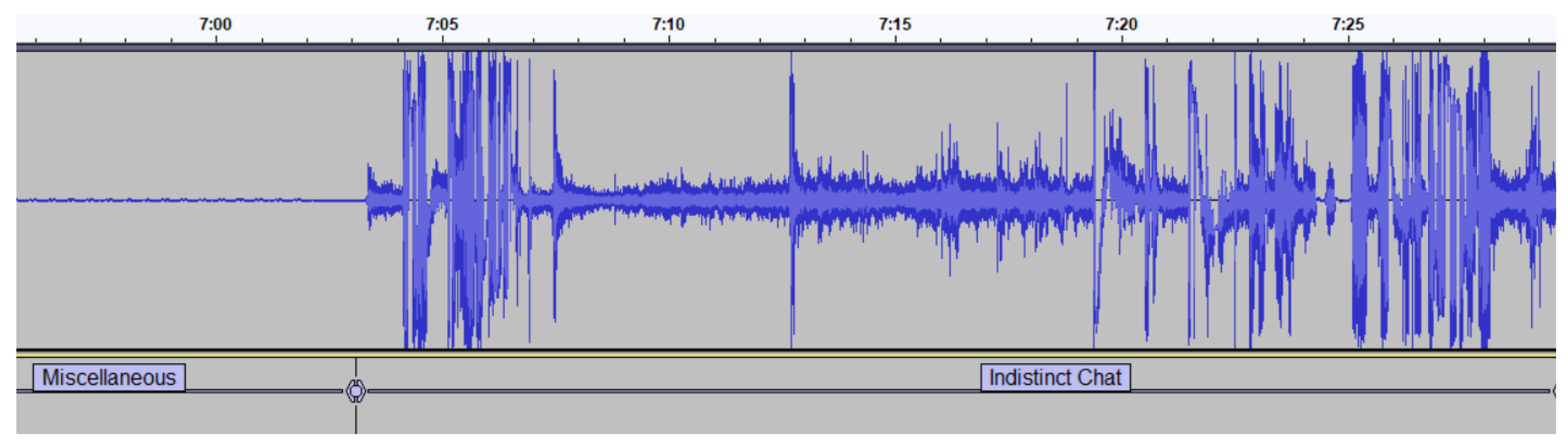
Miscellaneous/Pause/Indistinct Chat: As we can see in
Figure 2, a Miscellaneous audio segment is identified by the lack of audio signal at the beginning of the recording. Since recordings are scheduled in advance, the scheduled starting time is usually some minutes before the lecture actually begins, and the end of the class may also be a few minutes before the scheduled ending time. Consequently, the recordings contain several minutes where the microphone is off, leaving the recording with muted segments that we defined as Miscellaneous. We defined as a Pause a segment of audio where the lecturer does not speak for more than 2 s. However, during this period of silence, students chat among themselves and, sometimes, they speak loud enough to be captured by the lapel microphone worn by the lecturer. We defined this occurrence as Indistinct Chat. As can be observed in
Figure 2, Indistinct Chat is clearly distinguishable from segments where the lecturer speaks, as it happens in
Figure 3, in which the teacher makes a digression commenting on some question of a test (see transcription in
Table 2), and in
Figure 4, in which the words of the teacher are concerned with the organization of the class, particularly, the teacher is announcing a five-minute break (see transcription in
Table 3). One can notice the distinction between Indistinct Chat and Digression or Organization by comparing the difference in the amplitude of the corresponding waveforms.
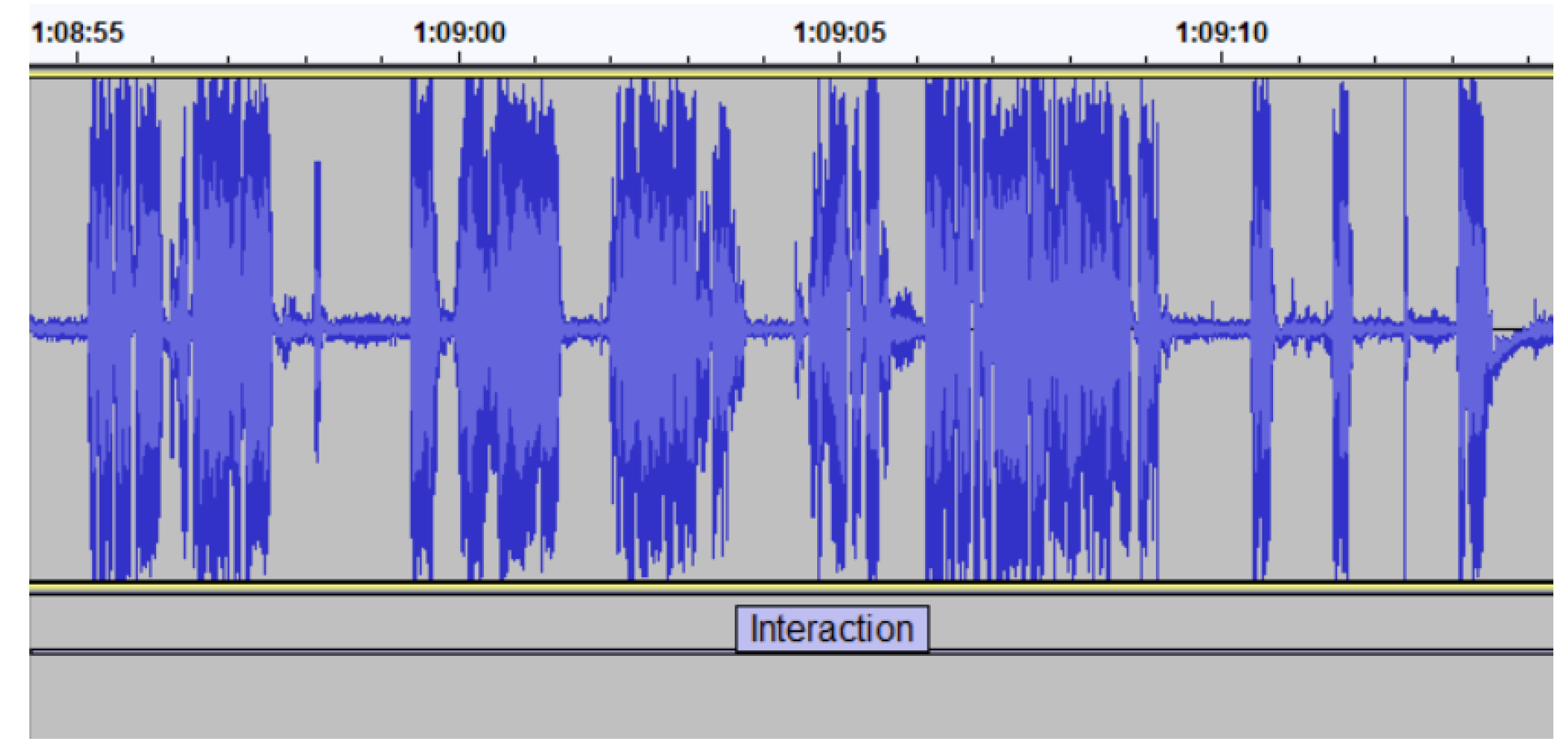
Interaction: In
Figure 5, and its corresponding transcription in
Table 4, we can observe that this audio sample interleaves segments of short silences with segments of the teacher’s speech, usually indicating that the lecturer is conversing with a student.
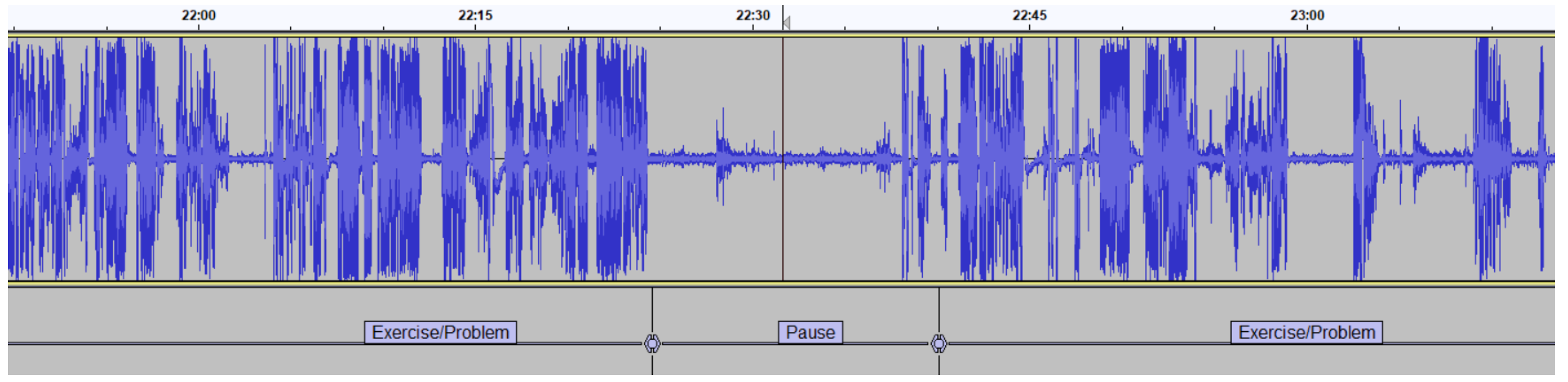
Exercise:
Figure 6 and its corresponding transcription in
Table 5 shows an audio sample that also interleaves periods of silence with teacher’s speech, like in Interaction, but in this case the duration of the segments of speech and silence are generally longer than in Interaction. The silences in
Figure 6 mainly happen when the teacher is writing on the blackboard and stops sporadically in order to check if students are able to follow the explanation. Looking at the content of
Table 5, we can conclude that the lecturer is solving an Exercise due to the use of variables and formulae and the fact that an equation for a specific electric circuit is being solved.
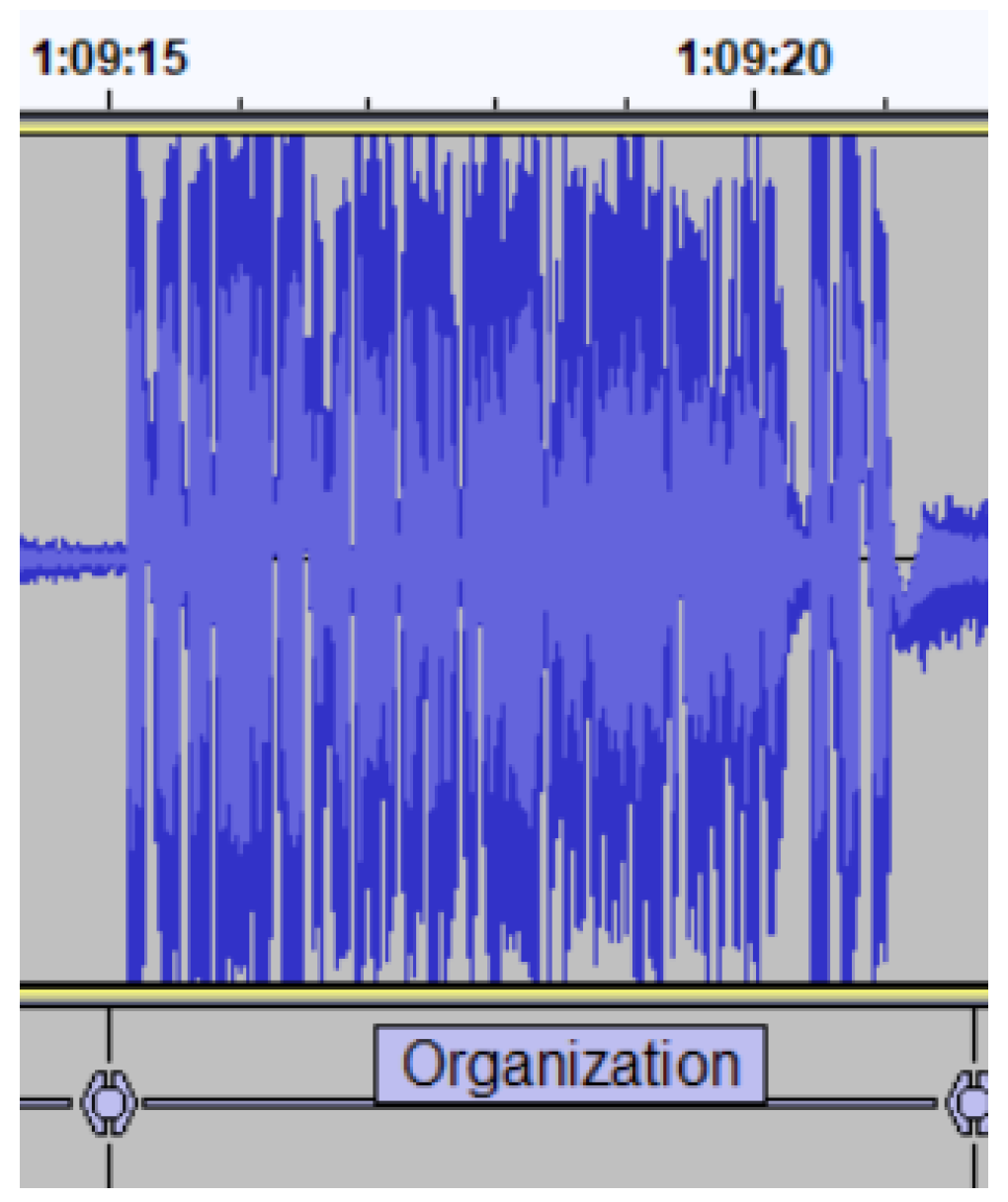
Theory/Example/Organization/Digression/Other: We grouped all these labels together because clearly and distinguishable audio features that discriminated among the teaching activities did not exist, as all of them were consistent with the audio signal of a monologue of the lecturer’s speech. This is reflected in
Figure 3 (Digression),
Figure 4 (Organization),
Figure 7 (Theory), and their corresponding transcriptions in
Table 2,
Table 3 and
Table 6. We needed to distinguish them based on the content of the speech. In
Table 6, we can see that the lecturer is explaining a concept belonging to the syllabus of the course, specifically, the main characteristics of the Zener diode (a special type of diode designed to reliably allow current to flow backwards), and clarifies certain figures on the notes that usually confuse the students.
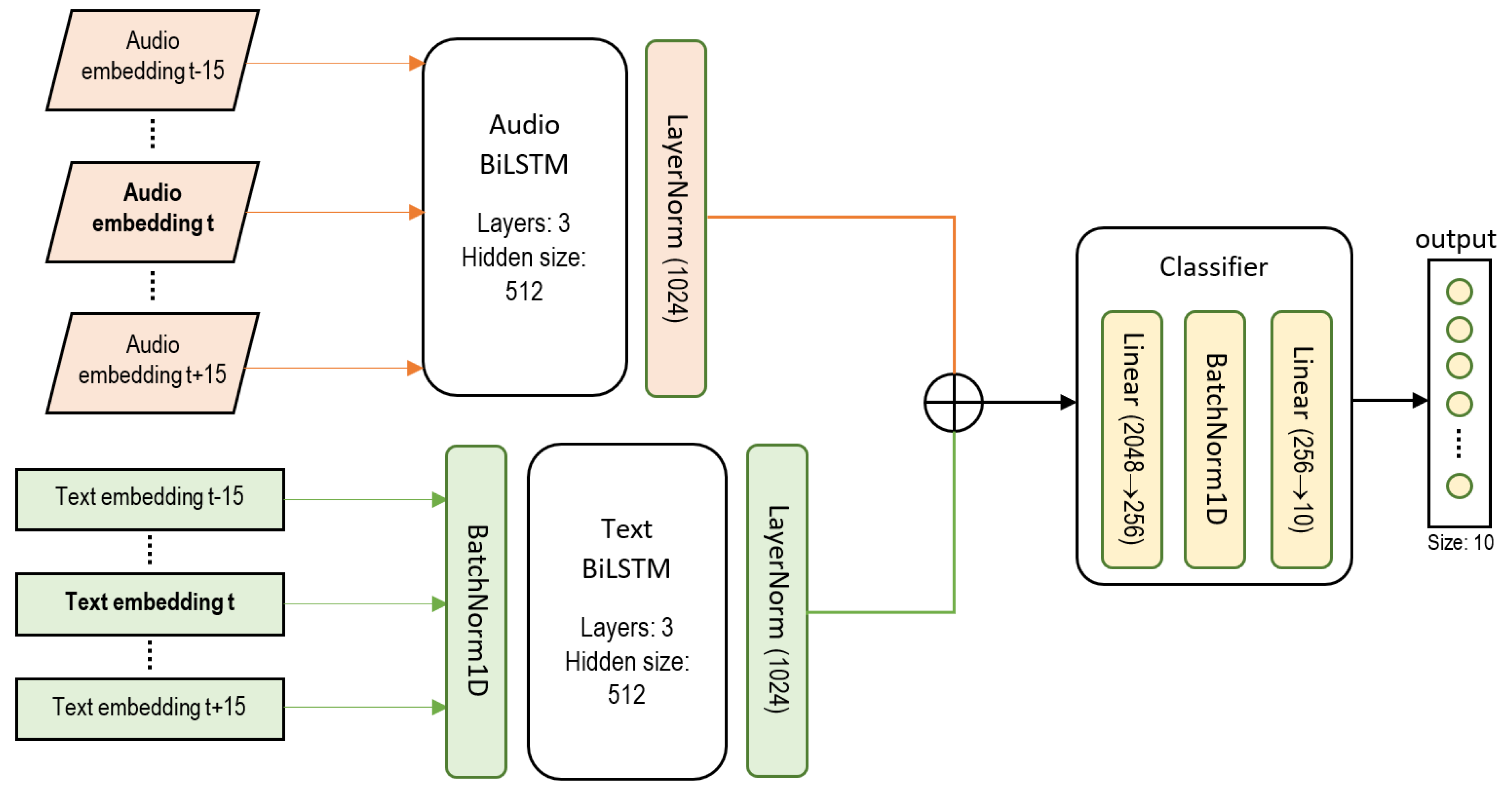
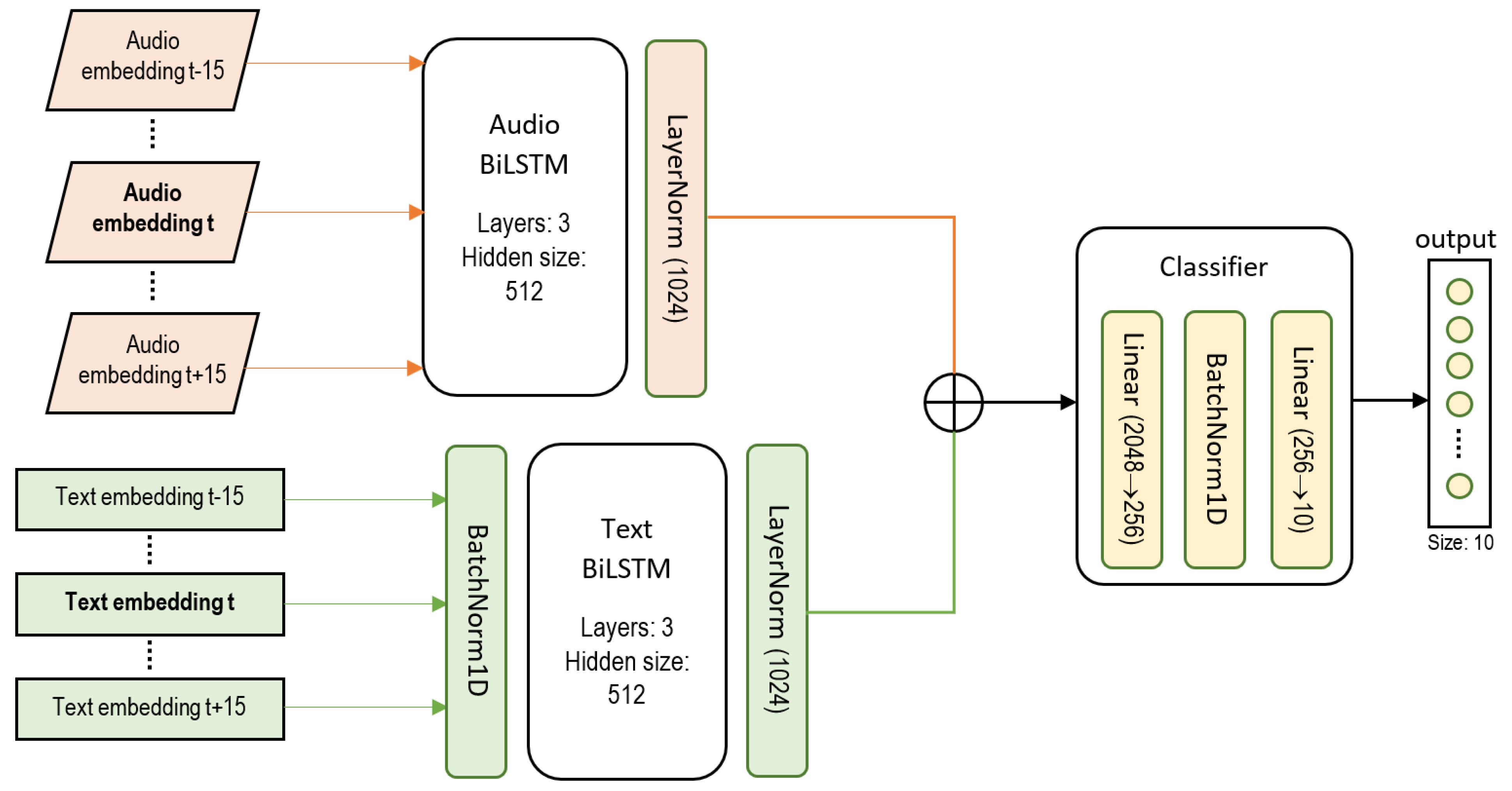
From the above exposition, we can observe the distinctive audio signals of those activities that involve some kind of students engagement such as Interaction or Exercise. We were thus able to extract useful information from the audio recordings related to the speed of utterance, pitch of voice and pausing and phrasing that helped distinguish this type of activities from those that were categorized as a monologue-style of the lecturer. For those activities that represent an extended speech of the teacher, we were able to extract distinguishable features from the transcribed notes. Hence, we expected that exploiting together audio features and text features would ease the task of segmenting and classifying academic activities from class recordings.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}