
Monocular Depth Estimation Using Res-UNet with an Attention Model


Abstract
:1. Introduction
- Most of the depth maps suffer from inaccurate boundaries and edges which leads the model to a high level of errors and losses during training.
- Sometimes, models create depth maps which have scale invariance problems.
- In semi-supervised and unsupervised learning, the model learns from a stereovision system which requires extensive calibration and post-processing.
- Certain models are very complex and require a considerable amount of memory and training time to develop depth maps.
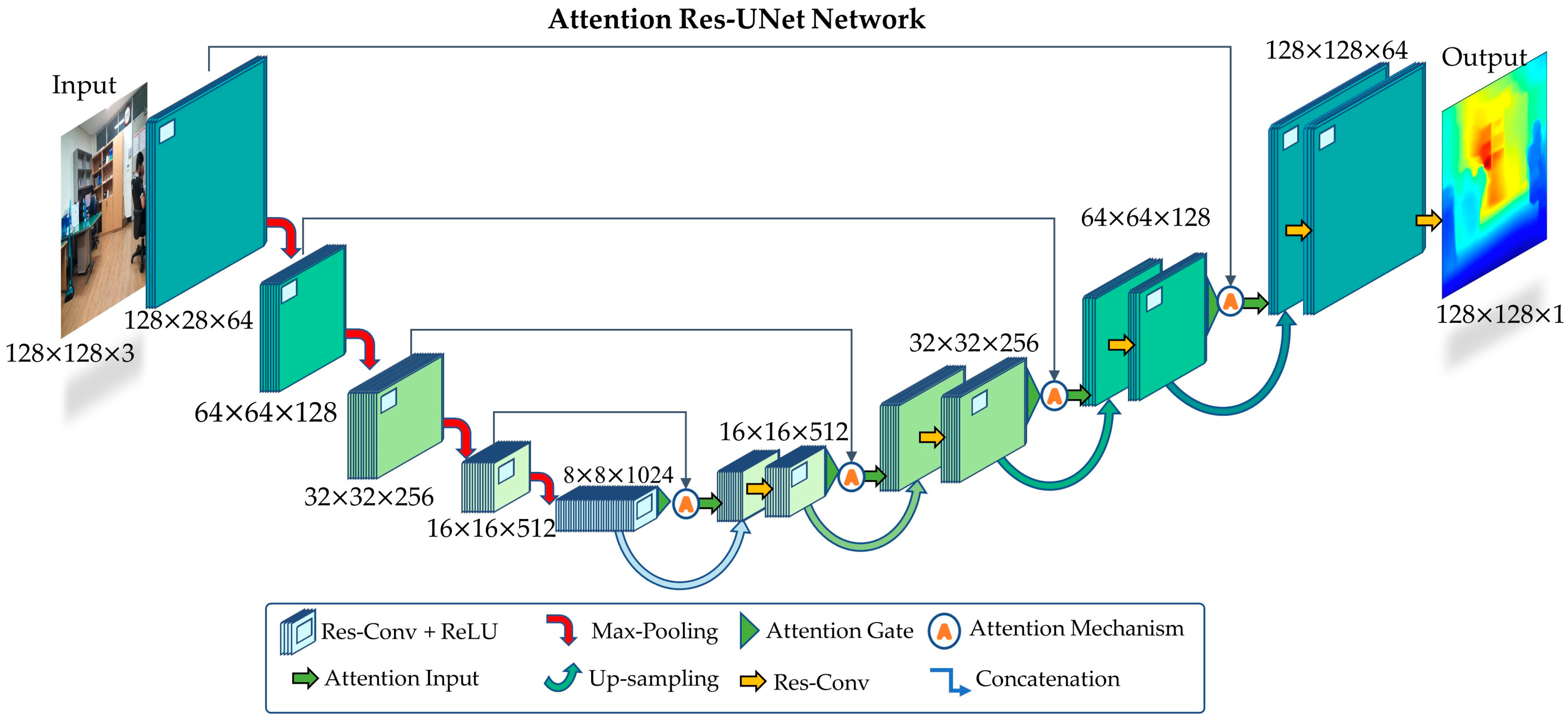
- We present a simple UNet architecture with Res-Net encoder–decoder blocks which can efficiently extract depth features from an input image.
- We added a spatial attention mechanism in our Res-UNet architecture which enhance the feature response and create clear boundaries and edges.
- We show that incorporating an attention mechanism did not increase the parameters in the model; rather, it helped the model to learn a greater number features in a shorter time with fewer iterations. The attention in the model suppresses the features response at the irrelevant locations while enhancing the response at relevant locations such as the edges or boundaries of depth maps.
- In summary, we created depth maps with a simple straight forward network which could be easily trained to any depth sensing or segmentation task.
- In conclusion, we discuss the findings, including the characterization of key parameters which influence performance, and outline avenues for future research in depth-mapping methodologies.
2. Related Work and Motivation
2.1. Traditional Methods
2.2. Depth Estimation Using Deep Learning
2.2.1. Supervised Learning
2.2.2. Semi-Supervised and Unsupervised Learning
3. Proposed Method
3.1. Overview
3.2. Proposed Model
3.2.1. Residual Network Block
3.2.2. Attention Block
- (a)
- Hard attention (Stochastic): Model training is more challenging in hard attention because of iterative region proposal and cropping [46]. These models are frequently non-differentiable and require reinforcement learning for parameter updates. Hard attention has been highly adopted in trainable transformers in recent times, as these models use iterative region proposal and cropping during feature learning.
- (b)
- Soft attention (Deterministic): Soft attention is probabilistic and uses normal backpropagation. These attention mechanisms do not require Monte Carlo or repeated random sampling. Soft attention is used to highlight the only relevant activation during training. It reduces the computational recourses wasted on irrelevant activations and provides a better generalization of the network. Additive soft attention has recently been used in image categorization and sentence-to-sentence translation [42,47].
3.2.3. Attention Model in Depth Maps Estimation
3.2.4. Overall Architecture
3.2.5. Model Training
3.2.6. Loss Function
4. Results and Discussion
4.1. Datasets
4.1.1. NYU-Depth v2
4.1.2. DIODE Dataset
4.2. Evaluation Results
4.2.1. Quantitative Evaluation
- 1.
- Average relative error
- 2.
- Root mean square error
- 3.
- Average error
- 4.
- Threshold accuracy
4.2.2. Qualitative Results
4.3. Implementation Details
4.3.1. Learning Curve for the DIODE Dataset
4.3.2. Learning Curve for the NYU-Depth v2 Dataset
4.4. Discussion
4.4.1. Depth-Estimation Algorithm
4.4.2. Evaluation Analysis
4.5. Ablation Study
4.5.1. Hyperparameters and Training
4.5.2. Loss Function
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; ISBN 978-0-521-54051-3. [Google Scholar]
- Leonard, J.J.; Durrant-Whyte, H.F. Mobile Robot Localization by Tracking Geometric Beacons. IEEE Trans. Robot. Autom. 1991, 7, 376–382. [Google Scholar] [CrossRef]
- Leonard, J.J.; Durrant-Whyte, H.F.; Pj, O. Directed Sonar Sensing for Mobile Robot Navigation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7576, pp. 746–760. ISBN 978-3-642-33714-7. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image Using a Multi-Scale Deep Network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. arXiv 2015, arXiv:1411.4734. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed]
- Jan, A.; Khan, S.; Seo, S. Deep Learning-Based Depth Map Estimation: A Review. Korean J. Remote Sens. 2023, 39, 1–21. [Google Scholar]
- Alhashim, I.; Wonka, P. High Quality Monocular Depth Estimation via Transfer Learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VIII 14 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. arXiv 2017, arXiv:1609.03677. [Google Scholar]
- Vasiljevic, I.; Kolkin, N.; Zhang, S.; Luo, R.; Wang, H.; Dai, F.Z.; Daniele, A.F.; Mostajabi, M.; Basart, S.; Walter, M.R.; et al. DIODE: A Dense Indoor and Outdoor DEpth Dataset. arXiv 2019, arXiv:1908.00463. [Google Scholar]
- Wheatstone, C. XVIII. Contributions to the Physiology of Vision—Part the First. On Some Remarkable, and Hitherto Unobserved, Phenomena of Binocular Vision. Phil. Trans. R. Soc. 1838, 128, 371–394. [Google Scholar] [CrossRef]
- Peddie, W. Helmholtz’s Treatise on Physiological Optics. Nature 1925, 116, 88–89. [Google Scholar] [CrossRef]
- Hoiem, D.; Efros, A.A.; Hebert, M. Automatic Photo Pop-up: ACM SIGGRAPH 2005. ACM Trans. Comput. Syst. 2005, 24, 577–584. [Google Scholar] [CrossRef]
- Karsch, K.; Liu, C.; Kang, S.B. Depth Transfer: Depth Extraction from Video Using Non-Parametric Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2144–2158. [Google Scholar] [CrossRef]
- Ladický, L.; Shi, J.; Pollefeys, M. Pulling Things out of Perspective. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 89–96. [Google Scholar]
- Saxena, A.; Chung, S.; Ng, A. Learning Depth from Single Monocular Images. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; MIT Press: Cambridge, MA, USA, 2005; Volume 18. [Google Scholar]
- Yang, J.; Alvarez, J.M.; Liu, M. Non-Parametric Depth Distribution Modelling Based Depth Inference for Multi-View Stereo. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 8616–8624. [Google Scholar]
- Guido, R.C.; Pedroso, F.; Contreras, R.C.; Rodrigues, L.C.; Guariglia, E.; Neto, J.S. Introducing the Discrete Path Transform (DPT) and Its Applications in Signal Analysis, Artefact Removal, and Spoken Word Recognition. Digit. Signal Process. 2021, 117, 103158. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Seo, S. SNR Analysis for Quantitative Comparison of Line Detection Methods. Appl. Sci. 2021, 11, 10088. [Google Scholar] [CrossRef]
- Yang, L.; Su, H.; Zhong, C.; Meng, Z.; Luo, H.; Li, X.; Tang, Y.Y.; Lu, Y. Hyperspectral Image Classification Using Wavelet Transform-Based Smooth Ordering. Int. J. Wavelets Multiresolut Inf. Process. 2019, 17, 1950050. [Google Scholar] [CrossRef]
- Zheng, X.; Tang, Y.Y.; Zhou, J. A Framework of Adaptive Multiscale Wavelet Decomposition for Signals on Undirected Graphs. IEEE Trans. Signal Process. 2019, 67, 1696–1711. [Google Scholar] [CrossRef]
- Guariglia, E.; Silvestrov, S. Fractional-Wavelet Analysis of Positive Definite Distributions and Wavelets on D’(C). In Engineering Mathematics II: Algebraic, Stochastic and Analysis Structures for Networks, Data Classification and Optimization; Silvestrov, S., Rančić, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 337–353. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper Depth Prediction with Fully Convolutional Residual Networks. arXiv 2016, arXiv:1606.00373. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zwald, L.; Lambert-Lacroix, S. The BerHu Penalty and the Grouped Effect. arXiv 2012, arXiv:1207.6868. [Google Scholar]
- Wang, P.; Cohen, S.; Price, B.; Yuille, A. Towards Unified Depth and Semantic Prediction from a Single Image. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Boston, MA, USA, 2015; pp. 2800–2809. [Google Scholar]
- Roy, A.; Todorovic, S. Monocular Depth Estimation Using Neural Regression Forest. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 5506–5514. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep Ordinal Regression Network for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting Single Image Depth Estimation: Toward Higher Resolution Maps with Accurate Object Boundaries. arXiv 2018, arXiv:1803.08673. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Kumari, S.; Jha, R.R.; Bhavsar, A.; Nigam, A. AUTODEPTH: Single Image Depth Map Estimation via Residual CNN Encoder-Decoder and Stacked Hourglass. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 340–344. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. arXiv 2017, arXiv:1704.07813. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos. arXiv 2018, arXiv:1811.06152. [Google Scholar] [CrossRef]
- Chen, Z.; Badrinarayanan, V.; Drozdov, G.; Rabinovich, A. Estimating Depth from RGB and Sparse Sensing. arXiv 2018, arXiv:1804.02771. [Google Scholar] [CrossRef]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. arXiv 2018, arXiv:1802.05522. [Google Scholar]
- Goldman, M.; Hassner, T.; Avidan, S. Learn Stereo, Infer Mono: Siamese Networks for Self-Supervised, Monocular, Depth Estimation. arXiv 2019, arXiv:1905.00401. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. Available online: https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf (accessed on 10 May 2023).
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Song, J.; Kim, S.; Yoon, S. AligNART: Non-Autoregressive Neural Machine Translation by Jointly Learning to Estimate Alignment and Translate. arXiv 2021, arXiv:2109.06481. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. 2017. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization 2015. Available online: https://arxiv.org/abs/1512.04150 (accessed on 10 May 2023).
- Mnih, V.; Heess, N.; Graves, A. Kavukcuoglu, Koray Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Huang, P.-H.; Matzen, K.; Kopf, J.; Ahuja, N.; Huang, J.-B. DeepMVS: Learning Multi-View Stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2821–2830. [Google Scholar]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. DeMoN: Depth and Motion Network for Learning Monocular Stereo. arXiv 2017, arXiv:1612.02401. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer No. | Input Layer | Stride and Filters | Output |
|---|---|---|---|
| Encoder | |||
| Input | 128 × 128 × 3 | (1, 1, 64) | 128 × 128 × 64 |
| L1 | 128 × 128 × 64 | (2, 2, 128) down-sampling | 64 × 64 × 128 |
| L2 | 64 × 64 × 128 | (2, 2, 256) down-sampling | 32 × 32 × 256 |
| L3 | 32 × 32 × 256 | (2, 2, 512) down-sampling | 16 × 16 × 512 |
| L4 | 16 × 16 × 512 | (2, 2, 1024) down-sampling | 8 × 8 × 1024 |
| L5 | Bottleneck (8 ×8 × 1024) | ||
| Decoder | |||
| att #1 | Attention (L5, L4) (16× 16 × 512) | 16 × 16 × 512 | |
| up #1 | L5_up-sampling | (2, 2, 512) | 16 × 16 × 512 |
| L6 | concatenation (att #1, up #1) + Res-Conv | 16 × 16 × 512 | |
| att #2 | Attention (L6, L3) (32 × 32 × 256) | 32 × 32 × 256 | |
| up #2 | L6_up-sampling | (2, 2, 256) | 32 × 32 × 256 |
| L7 | concatenation (att #2, up #2) + Res-Conv | 32 × 32 × 256 | |
| att #3 | Attention (L7, L2) (64 × 64 × 128) | 64 × 64 × 128 | |
| up #3 | L7_up-sampling | (2, 2, 128) | 64 × 64 × 128 |
| L8 | concatenation (att #3, up #3) + Res-Conv | 64 × 64 × 128 | |
| att #4 | Attention (L8, L1) (128 × 128 × 64) | 128 × 128 × 64 | |
| up #4 | L8_ re-sampling | (2, 2, 64) | 128 × 128 × 64 |
| L9 | concatenation (att #4, up #4) + Res-Conv | 128 × 128 × 64 | |
| Output | L9_re-sampling | (1, 1, 1) | 128 × 128 × 1 |
| Dataset | Type | Image Size |
|---|---|---|
| NYU-depth v2 | Indoor and outdoor scenes | 640 × 480 |
| KITTI | Road environment | 1280 × 384 |
| Cityscapes | Urban streets | 1024 × 2048 |
| DIODE | Indoor and outdoor scenes | 1024 × 768 |
| Make3D | Outdoor scenes | 1704 × 2272 |
| Middlebury | Static indoor scenes | 3000 × 2000 |
| Methods | High Is Better ↑ | Low Is Better ↓ | ||||
|---|---|---|---|---|---|---|
| ↑ | Rel↓ | RMS↓ | Log10↓ | |||
| Eigen et al. [5] | 0.769 | 0.950 | 0.988 | 0.158 | 0.641 | - |
| Laina et al. [27] | 0.811 | 0.953 | 0.988 | 0.127 | 0.573 | 0.055 |
| Fu et al. [32] | 0.828 | 0.965 | 0.992 | 0.115 | 0.509 | 0.051 |
| Alhashim and Wonka [9] | 0.846 | 0.974 | 0.994 | 0.123 | 0.465 | 0.053 |
| Ours (scaled) | 0.917 | 0.987 | 0.993 | 0.117 | 0.398 | 0.047 |
| Components | Title 3 | |
|---|---|---|
| Hardware | CPU GPU SSD | Intel(R) Core (TM) i5-11400F 8 GB GeForce RTX 3050 500 GB Samsung SSD |
| RAM | 16 GB | |
| Software | OS Programming Platform Library | Windows 11 Pro, 64 bits Python 3.8 TensorFlow 2+ |
| Loss Functions | Training Loss | Output |
|---|---|---|
| 0.0094 | Model was trained to minimum loss | |
| 0.0251 | Model was trained to acceptable loss | |
| 0.0291 | Model was trained to acceptable loss | |
| 0.0261 | Model failed at 4th epoch | |
| 0.0557 | Model failed at 6th epoch | |
| 0.0207 | Model failed at 2nd epoch | |
| 0.096 | Model failed at 1st epoch |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jan, A.; Seo, S. Monocular Depth Estimation Using Res-UNet with an Attention Model. Appl. Sci. 2023, 13, 6319. https://doi.org/10.3390/app13106319
Jan A, Seo S. Monocular Depth Estimation Using Res-UNet with an Attention Model. Applied Sciences. 2023; 13(10):6319. https://doi.org/10.3390/app13106319
Chicago/Turabian StyleJan, Abdullah, and Suyoung Seo. 2023. "Monocular Depth Estimation Using Res-UNet with an Attention Model" Applied Sciences 13, no. 10: 6319. https://doi.org/10.3390/app13106319