
Towards Digital Twins of 3D Reconstructed Apparel Models with an End-to-End Mobile Visualization




Abstract
:1. Introduction
2. Related Work
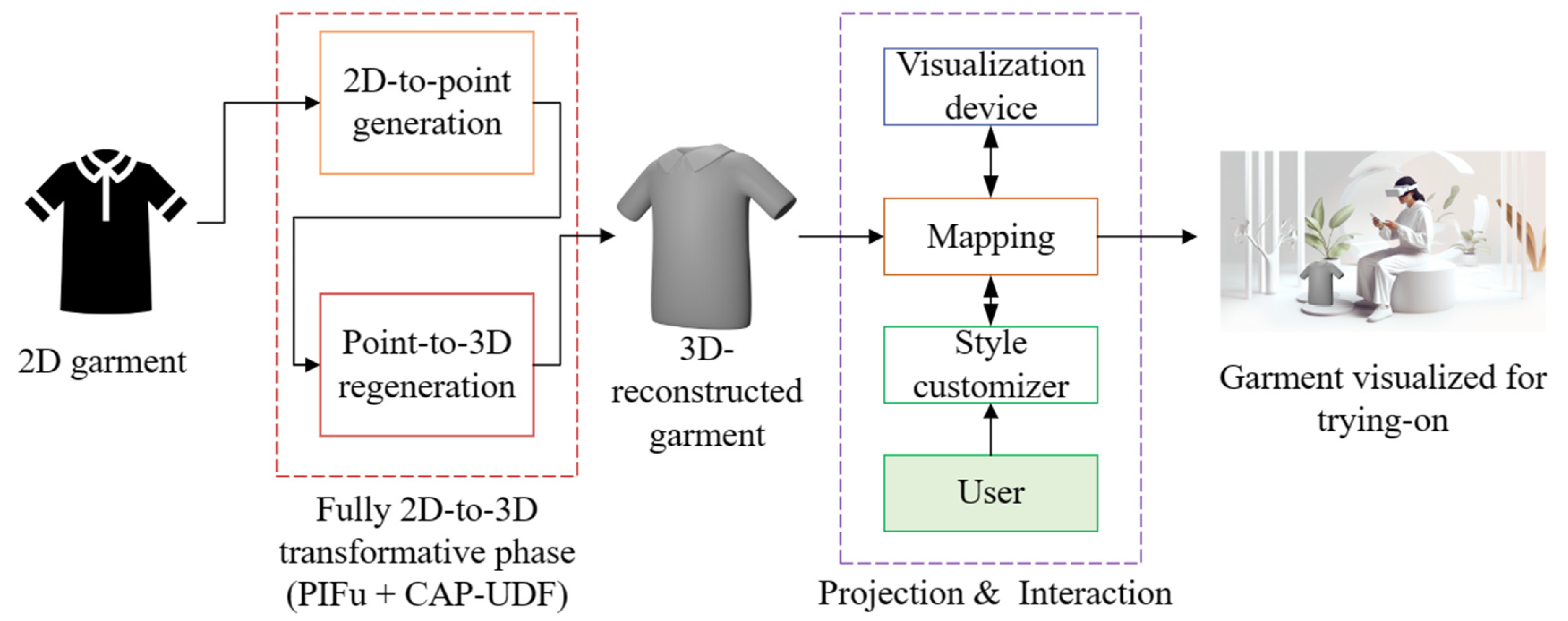
- We proposed an end-to-end 2D-to-3D framework including 2D-to-3D point cloud via PIFu processing and regenerating 3D-point cloud-to-3D fully regenerated instances via the CAP–UDF model, in which these two steps are integrated as one mainstream task;
- Comparisons from multiple perspectives were conducted using one benchmark dataset and one actual implementation for a garment task;
- Garment visualization has been further demonstrated in a virtual world after mapping from the regenerating task.
3. Methodology
- A.
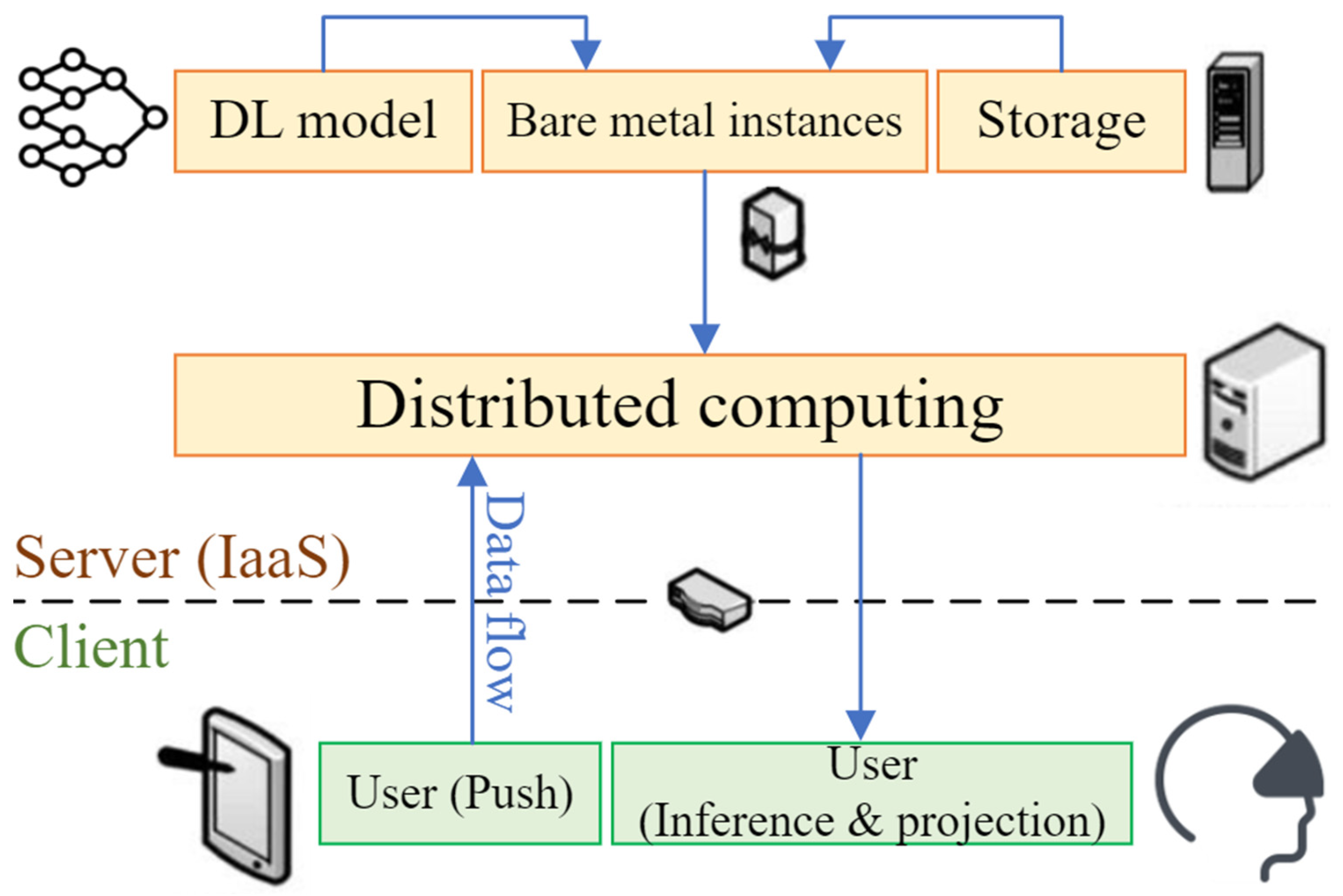
- Fundamental: Deep-Learning in regard to 3D Deep Reconstruction and Cloud Computing Infrastructure
- B.
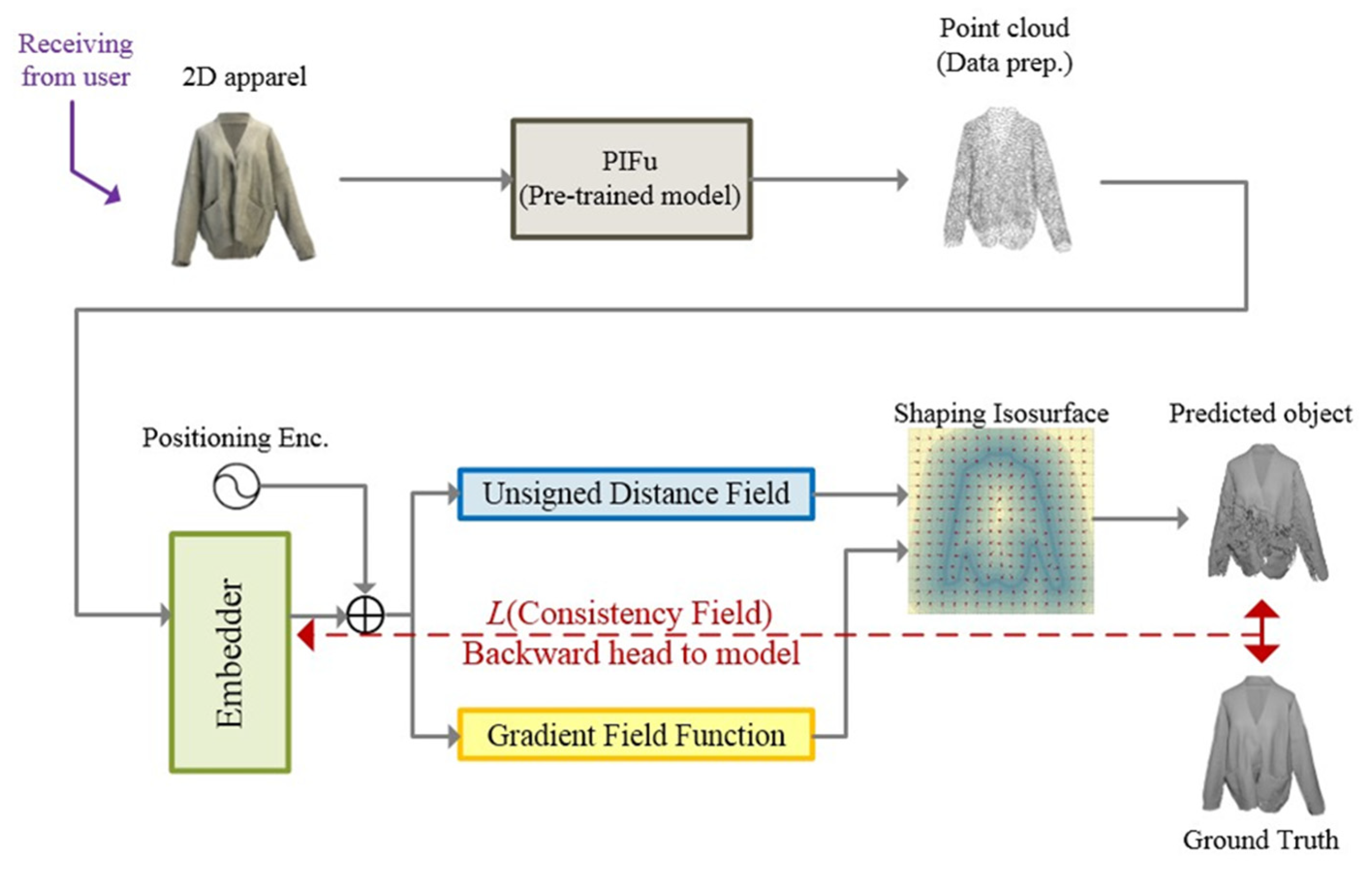
- Reconstruction phase: 2D-to-point cloud Pixel-Aligned Implicit Function (PIFu) and point cloud-to-3D Unsigned Distance Function-based Consistency-Aware Progression (CAP-UDF).
- C.
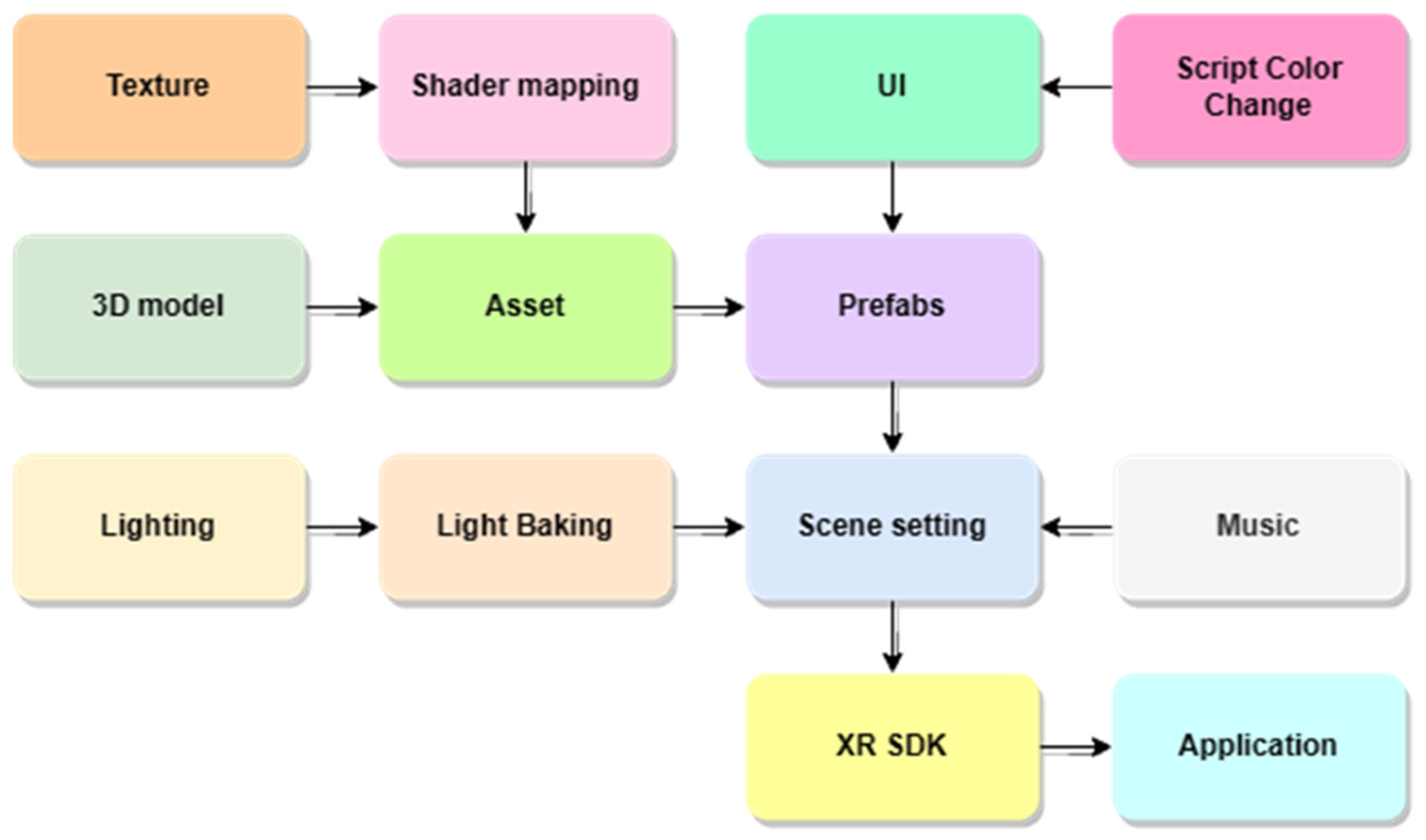
- Visualization Phase: Physical-to-Virtual Transformative Topology (P2V)
- D.
- Designed End-to-End Framework
| Algorithm 1: An end-to-end visualization for virtual trying-on. |
| Notation I: input or pre-processed data Ntrain: Num_trainings to generate 3D entities M: mobile device Φ: 3D-reconstruction model B: virtual reality equipment U(Phy/Vir); UP/UV: physical/virtual world via user interaction perspective S: server #---User side— #1 to transmit data from mobile device to server side S ← UP ⸰ M(I) #---Server side— #2 to generate 2D instances so as to be 3D-reconstruction entities OnEvent Reconstruction Phase do def pifu_pretrained: point_cloud_gen = PIFu_model(pretrained=True) def cap_udf_training: for n in training_loop: | Compute UDFs-based cloud rearrangement f ← ∇f | Compute Consistency-aware surface reconstruction L | Backward Total L objective function to model Φ End for Execute IPC = point_cloud_gen (I) While Iteration1 < Ntrain-raw3D: Iteration1++ Update ΦTr ← cap_udf_training(Φ(IPC_train)) End while Reconstruct I3D = ΦTr(IPC_test) Return Reconstructed 3D Objects I3D End OnEvent #---User side— #3 to transmit reconstructed instance and render over virtual world with user interaction UP ← S(I3D) OnEvent Projection Phase do import I3D if I3D. is_available() then Execute mapping entities into virtual space I3D-VR = P2V(I3D); Perform I3D-VR projecting over B virtual reality device with U interaction UV ⸰ B(I3D-VR); end if End OnEvent |
| Ensure Garment(s) for virtual try-on via VR devices |
4. Results
- A.
- Datasets
- B.
- System Configuration and Implementation
- C.
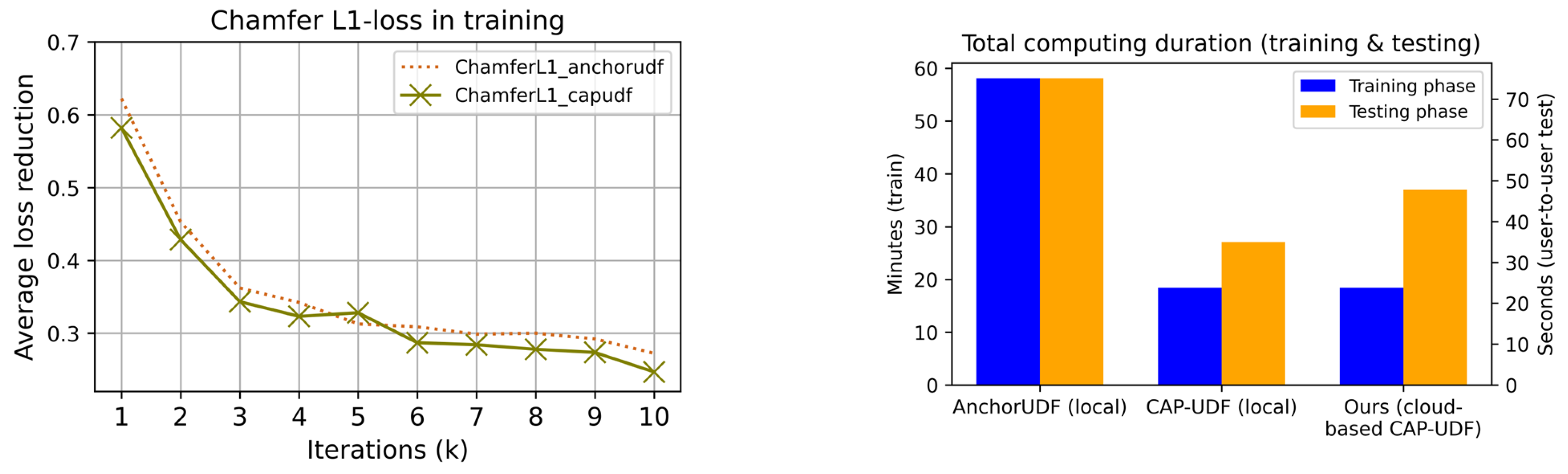
- Experimental Results
- D.
- Analysis
- E.
- Instance-Reconstructed Mapping and Projection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 85–113. [Google Scholar] [CrossRef]
- Van Der Horn, E.; Mahadevan, S. Digital Twin: Generalization, characterization and implementation. Decis. Support Syst. 2021, 145, 113524. [Google Scholar] [CrossRef]
- Hamzaoui, M.A.; Julien, N. Social Cyber-Physical System\s and Digital Twins Networks: A perspective about the future digital twin ecosystems. IFAC-PapersOnLine 2022, 55, 31–36. [Google Scholar] [CrossRef]
- Liu, M.; Fang, S.; Dong, H.; Xu, C. Review of digital twin about concepts, technologies, and industrial applications. J. Manuf. Syst. 2021, 58, 346–361. [Google Scholar] [CrossRef]
- Collins, J.; Goel, S.; Deng, K.; Luthra, A.; Xu, L.; Gundogdu, E.; Zhang, X.; Vicente, T.F.Y.; Dideriksen, T.; Arora, H.; et al. Abo: Dataset and benchmarks for real-world 3d object understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21126–21136. [Google Scholar]
- Jurado, J.M.; Padrón, E.J.; Jiménez, J.R.; Ortega, L. An out-of-core method for GPU image mapping on large 3D scenarios of the real world. Future Gener. Comput. Syst. 2022, 134, 66–77. [Google Scholar] [CrossRef]
- Špelic, I. The current status on 3D scanning and CAD/CAM applications in textile research. Int. J. Cloth. Sci. Technol. 2020, 32, 891–907. [Google Scholar] [CrossRef]
- Helle, R.H.; Lemu, H.G. A case study on use of 3D scanning for reverse engineering and quality control. Mater. Today Proc. 2021, 45, 5255–5262. [Google Scholar] [CrossRef]
- Son, K.; Lee, K.B. Effect of tooth types on the accuracy of dental 3d scanners: An in vitro study. Materials 2020, 13, 1744. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Chibane, J.; Pons-Moll, G. Neural unsigned distance fields for implicit function learning. Adv. Neural. Inf. Process Syst. 2020, 33, 21638–21652. [Google Scholar] [CrossRef]
- Venkatesh, R.; Karmali, T.; Sharma, S.; Ghosh, A.; Babu, R.V.; Jeni, L.A.; Singh, M. Deep implicit surface point prediction networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12653–12662. [Google Scholar]
- Zhao, F.; Wang, W.; Liao, S.; Shao, L. Learning anchored unsigned distance functions with gradient direction alignment for single-view garment reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12674–12683. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Phanichraksaphong, V.; Tsai, W.H. Automatic Assessment of Piano Performances Using Timbre and Pitch Features. Electronics 2023, 12, 1791. [Google Scholar] [CrossRef]
- Liu, J.; Ji, P.; Bansal, N.; Cai, C.; Yan, Q.; Huang, X.; Xu, Y. Planemvs: 3d plane reconstruction from multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8665–8675. [Google Scholar]
- Cernica, D.; Benedek, I.; Polexa, S.; Tolescu, C.; Benedek, T. 3D Printing—A Cutting Edge Technology for Treating Post-Infarction Patients. Life 2021, 11, 910. [Google Scholar] [CrossRef]
- Barricelli, B.R.; Casiraghi, E.; Gliozzo, J.; Petrini, A.; Valtolina, S. Human digital twin for fitness management. IEEE Access 2020, 8, 26637–26664. [Google Scholar] [CrossRef]
- Shengli, W. Is human digital twin possible? Comput. Methods Programs Biomed. 2021, 1, 100014. [Google Scholar] [CrossRef]
- Li, X.; Cao, J.; Liu, Z.; Luo, X. Sustainable business model based on digital twin platform network: The inspiration from Haier’s case study in China. Sustainability 2021, 12, 936. [Google Scholar] [CrossRef] [Green Version]
- Al-Ali, A.R.; Gupta, R.; Zaman Batool, T.; Landolsi, T.; Aloul, F.; Al Nabulsi, A. Digital twin conceptual model within the context of internet of things. Future Internet 2020, 12, 163. [Google Scholar] [CrossRef]
- Štroner, M.; Křemen, T.; Urban, R. Progressive Dilution of Point Clouds Considering the Local Relief for Creation and Storage of Digital Twins of Cultural Heritage. Appl. Sci. 2022, 12, 11540. [Google Scholar] [CrossRef]
- Niccolucci, F.; Felicetti, A.; Hermon, S. Populating the Data Space for Cultural Heritage with Heritage Digital Twins. Data 2022, 7, 105. [Google Scholar] [CrossRef]
- Lv, Z.; Shang, W.L.; Guizani, M. Impact of Digital Twins and Metaverse on Cities: History, Current Situation, and Application Perspectives. Appl. Sci. 2022, 12, 12820. [Google Scholar] [CrossRef]
- Ashraf, S. A proactive role of IoT devices in building smart cities. Internet Things Cyber-Phys. Syst. 2021, 1, 8–13. [Google Scholar] [CrossRef]
- Hsu, C.H.; Chen, X.; Lin, W.; Jiang, C.; Zhang, Y.; Hao, Z.; Chung, Y.C. Effective multiple cancer disease diagnosis frameworks for improved healthcare using machine learning. Measurement 2021, 175, 109145. [Google Scholar] [CrossRef]
- Jamil, D.; Palaniappan, S.; Lokman, A.; Naseem, M.; Zia, S. Diagnosis of Gastric Cancer Using Machine Learning Techniques in Healthcare Sector: A Survey. Informatica 2022, 45, 7. [Google Scholar] [CrossRef]
- Meraghni, S.; Benaggoune, K.; Al Masry, Z.; Terrissa, L.S.; Devalland, C.; Zerhouni, N. Towards digital twins driven breast cancer detection. In Intelligent Computing: Proceedings of the 2021 Computing Conference, 1st ed.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Lv, Z.; Qiao, L.; Li, Y.; Yuan, Y.; Wang, F.Y. Blocknet: Beyond reliable spatial digital twins to parallel metaverse. Patterns 2022, 3, 100468. [Google Scholar] [CrossRef]
- Song, M.; Shi, Q.; Hu, Q.; You, Z.; Chen, L. On the Architecture and Key Technology for Digital Twin Oriented to Equipment Battle Damage Test Assessment. Electronics 2020, 12, 128. [Google Scholar] [CrossRef]
- Tang, Y.M.; Au, K.M.; Lau, H.C.; Ho, G.T.; Wu, C.H. Evaluating the effectiveness of learning design with mixed reality (MR) in higher education. Virtual Real. 2020, 24, 797–807. [Google Scholar] [CrossRef]
- Livesu, M.; Ellero, S.; Martínez, J.; Lefebvre, S.; Attene, M. From 3D models to 3D prints: An overview of the processing pipeline. Comput. Graph. Forum 2017, 36, 537–564. [Google Scholar] [CrossRef] [Green Version]
- Fritsch, D.; Klein, M. 3D and 4D modeling for AR and VR app developments. In Proceedings of the 23rd International Conference on Virtual System & Multimedia (VSMM), Dublin, Ireland, 31 October–4 November 2017; pp. 1–8. [Google Scholar]
- Garcia-Dorado, I.; Aliaga, D.G.; Bhalachandran, S.; Schmid, P.; Niyogi, D. Fast weather simulation for inverse procedural design of 3d urban models. ACM Trans. Graph. (TOG) 2017, 36, 1–19. [Google Scholar] [CrossRef]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. (TOG) 2013, 32, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Chabra, R.; Lenssen, J.E.; Ilg, E.; Schmidt, T.; Straub, J.; Lovegrove, S.; Newcombe, R. Deep local shapes: Learning local sdf priors for detailed 3d reconstruction. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 608–625. [Google Scholar]
- Ding, C.; Zhao, M.; Lin, J.; Jiao, J.; Liang, K. Sparsity-based algorithm for condition assessment of rotating machinery using internal encoder data. IEEE Trans. Ind. Electron. 2019, 67, 7982–7993. [Google Scholar] [CrossRef]
- Li, T.; Wen, X.; Liu, Y.S.; Su, H.; Han, Z. Learning deep implicit functions for 3D shapes with dynamic code clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 12840–12850. [Google Scholar]
- Guillard, B.; Stella, F.; Fua, P. Meshudf: Fast and differentiable meshing of unsigned distance field networks. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 576–592. [Google Scholar]
- Atzmon, M.; Lipman, Y. Sal: Sign agnostic learning of shapes from raw data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2565–2574. [Google Scholar]
- Atzmon, M.; Lipman, Y. Sald: Sign agnostic learning with derivatives. arXiv 2020, arXiv:2006.05400. [Google Scholar]
- Gropp, A.; Yariv, L.; Haim, N.; Atzmon, M.; Lipman, Y. Implicit geometric regularization for learning shapes. arXiv 2020, arXiv:2002.10099. [Google Scholar]
- Ma, B.; Han, Z.; Liu, Y.S.; Zwicker, M. Neural-pull: Learning signed distance functions from point clouds by learning to pull space onto surfaces. arXiv 2020, arXiv:2011.13495. [Google Scholar]
- Tang, Y.M.; Ho, H.L. 3D modeling and computer graphics in virtual reality. In Mixed Reality and Three-Dimensional Computer Graphics; IntechOpen: London, UK, 2020. [Google Scholar] [CrossRef] [Green Version]
- Van Holland, L.; Stotko, P.; Krumpen, S.; Klein, R.; Weinmann, M. Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments. arXiv 2020, arXiv:2211.14310. [Google Scholar]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2304–2314. [Google Scholar]
- Yang, X.; Lin, G.; Chen, Z.; Zhou, L. Neural Vector Fields: Implicit Representation by Explicit Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16727–16738. [Google Scholar]
- Hong, F.; Chen, Z.; Lan, Y.; Pan, L.; Liu, Z. Eva3d: Compositional 3d human generation from 2d image collections. arXiv 2022, arXiv:2210.04888. [Google Scholar]
- Dong, Z.; Xu, K.; Duan, Z.; Bao, H.; Xu, W.; Lau, R. Geometry-aware Two-scale PIFu Representation for Human Reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 31130–31144. [Google Scholar]
- Linse, C.; Alshazly, H.; Martinetz, T. A walk in the black-box: 3D visualization of large neural networks in virtual reality. Neural Comput. Appl. 2022, 34, 21237–21252. [Google Scholar] [CrossRef]
- Klingenberg, S.; Fischer, R.; Zettler, I.; Makransky, G. Facilitating learning in immersive virtual reality: Segmentation, summarizing, both or none? J. Comput. Assist. Learn. 2023, 39, 218–230. [Google Scholar] [CrossRef]
- Ghasemi, Y.; Jeong, H.; Choi, S.H.; Park, K.B.; Lee, J.Y. Deep learning-based object detection in augmented reality: A systematic review. Comput. Ind. 2022, 139, 103661. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Liu, X.; Zheng, Y. A digital-twin-assisted fault diagnosis using deep transfer learning. IEEE Access 2019, 7, 19990–19999. [Google Scholar] [CrossRef]
- Wei, Y.; Wei, Z.; Rao, Y.; Li, J.; Zhou, J.; Lu, J. Lidar distillation: Bridging the beam-induced domain gap for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; Springer Nature: Cham, Switzerland, 2022; pp. 179–195. [Google Scholar]
- Regenwetter, L.; Nobari, A.H.; Ahmed, F. Deep generative models in engineering design: A review. J. Mech. Des. 2022, 144, 071704. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | 2D Captured-to-Point Cloud | Point Cloud-to-3D Reconstructed Object | 3D Visualization over Virtual/Actual World |
|---|---|---|---|
| PIFu | ✓ | - | - |
| Anchor-UDF, CAP–UDF | - | ✓ | - |
| 3D-VR (Y.-M. Tang and H.L. Ho, 2020) [43] 3D-AR (L. Van et al., 2020) [44] | - | - | ✓ |
| Proposed Method | ✓ | ✓ | ✓ |
| Dataset | The Number of Instances | Object Styles (Class) | Data Types |
|---|---|---|---|
| ShapeNet Cars | 1 | 1 | 3D Point clouds |
| DeepFashion3D | ~2078 | 10 | 2D garments and 3D point clouds |
| Studies | Chamfer L1 | Chamfer L2 | F-Score-0.005 | F-Score-0.01 |
|---|---|---|---|---|
| Raw input | 0.681 | 0.165 | 0.835 | 0.981 |
| Anchor-UDF | 0.444 | 0.099 | 0.932 | 0.997 |
| CAP–UDF | 0.389 | 0.089 | 0.947 | 0.998 |
| Studies | Chamfer L1 | Chamfer L2 |
|---|---|---|
| Pixel2Mesh | 5.124 | 1.235 |
| PIFu | 1.450 | 0.434 |
| Anchor-UDF | 0.655 | 0.151 |
| CAP–UDF | 0.586 | 0.129 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doungtap, S.; Petchhan, J.; Phanichraksaphong, V.; Wang, J.-H. Towards Digital Twins of 3D Reconstructed Apparel Models with an End-to-End Mobile Visualization. Appl. Sci. 2023, 13, 8571. https://doi.org/10.3390/app13158571
Doungtap S, Petchhan J, Phanichraksaphong V, Wang J-H. Towards Digital Twins of 3D Reconstructed Apparel Models with an End-to-End Mobile Visualization. Applied Sciences. 2023; 13(15):8571. https://doi.org/10.3390/app13158571
Chicago/Turabian StyleDoungtap, Surasachai, Jirayu Petchhan, Varinya Phanichraksaphong, and Jenq-Haur Wang. 2023. "Towards Digital Twins of 3D Reconstructed Apparel Models with an End-to-End Mobile Visualization" Applied Sciences 13, no. 15: 8571. https://doi.org/10.3390/app13158571
APA StyleDoungtap, S., Petchhan, J., Phanichraksaphong, V., & Wang, J.-H. (2023). Towards Digital Twins of 3D Reconstructed Apparel Models with an End-to-End Mobile Visualization. Applied Sciences, 13(15), 8571. https://doi.org/10.3390/app13158571