
Multi-Scale Residual Depthwise Separable Convolution for Metro Passenger Flow Prediction

Abstract
:1. Introduction
- (1)
- We employ the RDSC module to capture spatiotemporal dependencies between stations from various temporal patterns (real-time, daily, and weekly), which is a residual network structure with a channel attention mechanism.
- (2)
- We model inter-station interactions through a network structure correlation graph and passenger flow similarity graph and utilize the MDSC module to enhance multi-scale spatial correlations on these graphs.
- (3)
- Experimental results based on real data of metro passenger inflow and outflow prove that our approach outperforms other baseline models in terms of prediction performance.
2. Methodology
2.1. Overall Framework
2.2. Construction of Relationship Graphs between Metro Stations
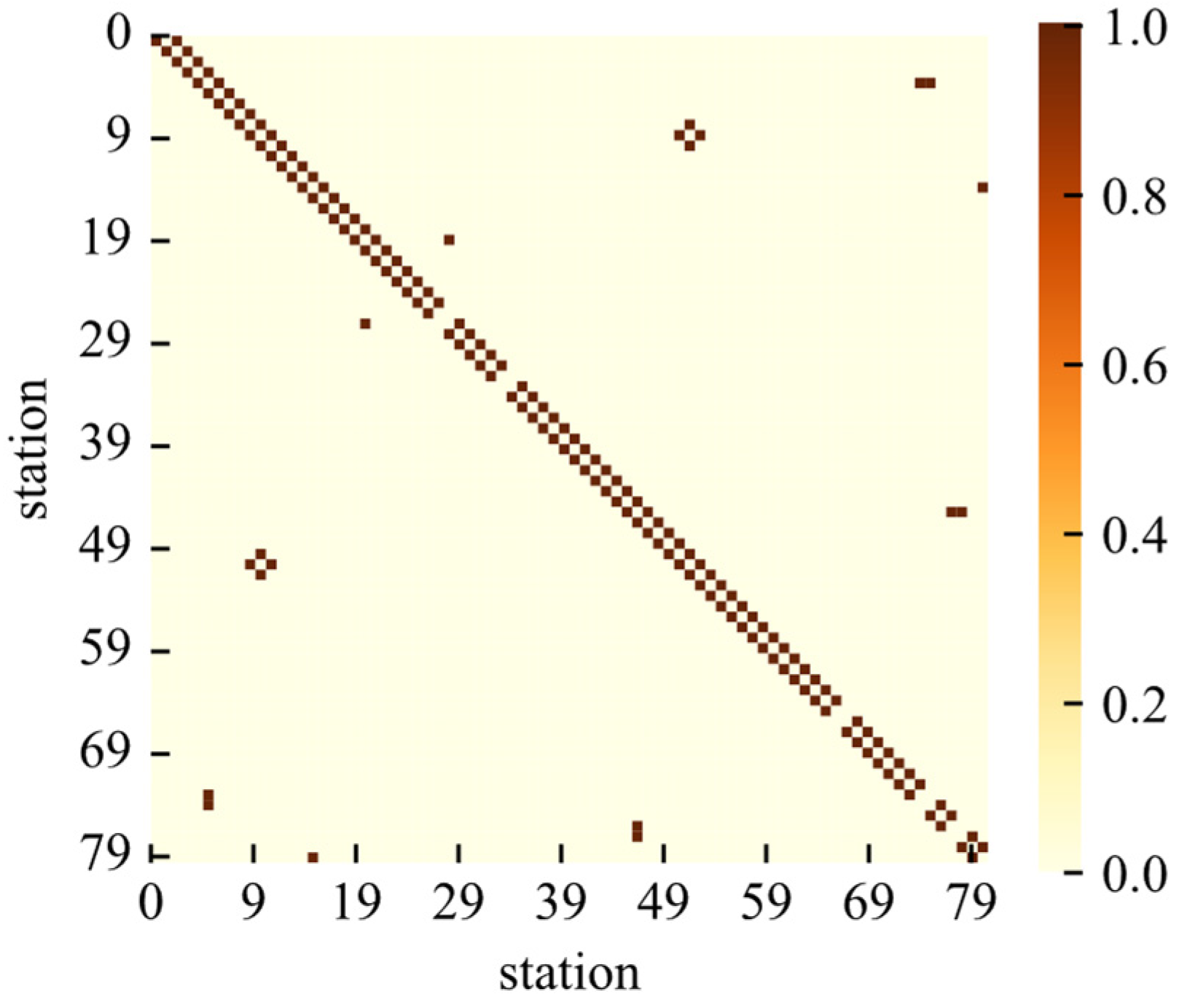
2.2.1. Network Structure Correlation Graph
2.2.2. Passenger Flow Similarity Graph
2.3. Residual Depthwise Separable Convolution Module
2.4. Multi-Scale Depthwise Separable Convolution Module
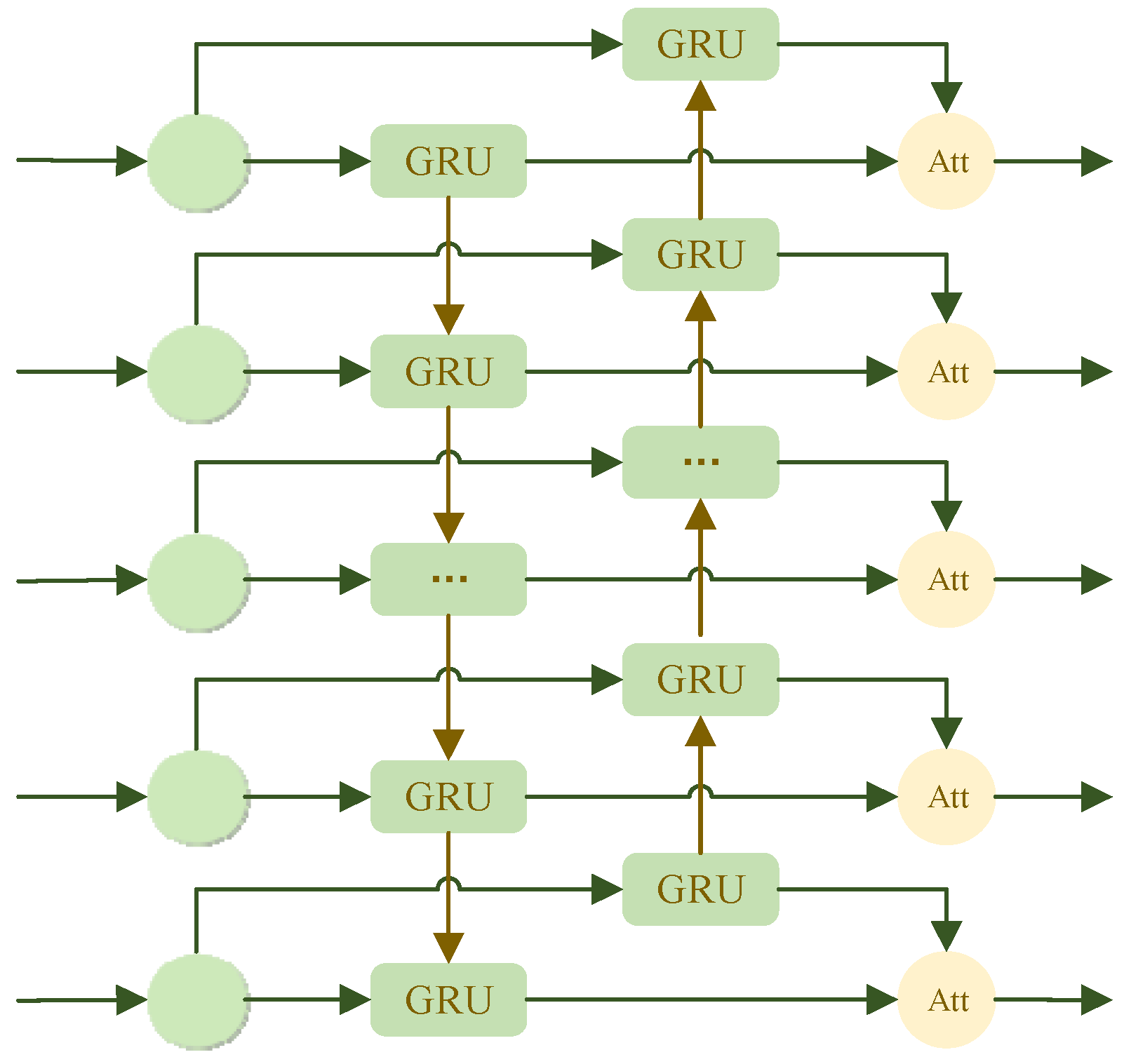
2.5. AttBiGRU
3. Experiments
3.1. Data Description
3.2. Evaluation Metrics
3.3. Baseline Models
3.4. Results and Discussion
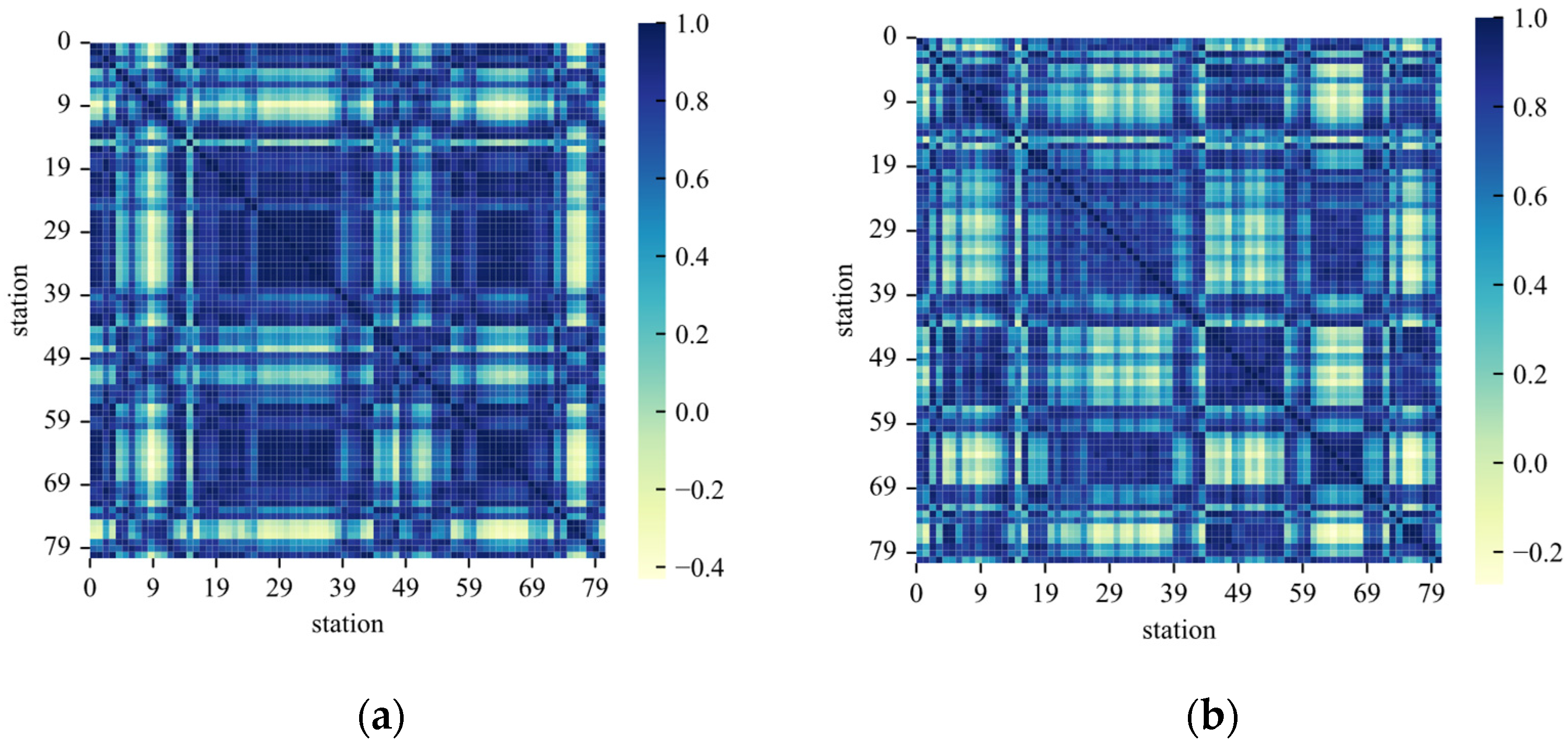
3.4.1. Analysis of Relationship Graphs between Metro Stations
3.4.2. Effectiveness of Graph Construction
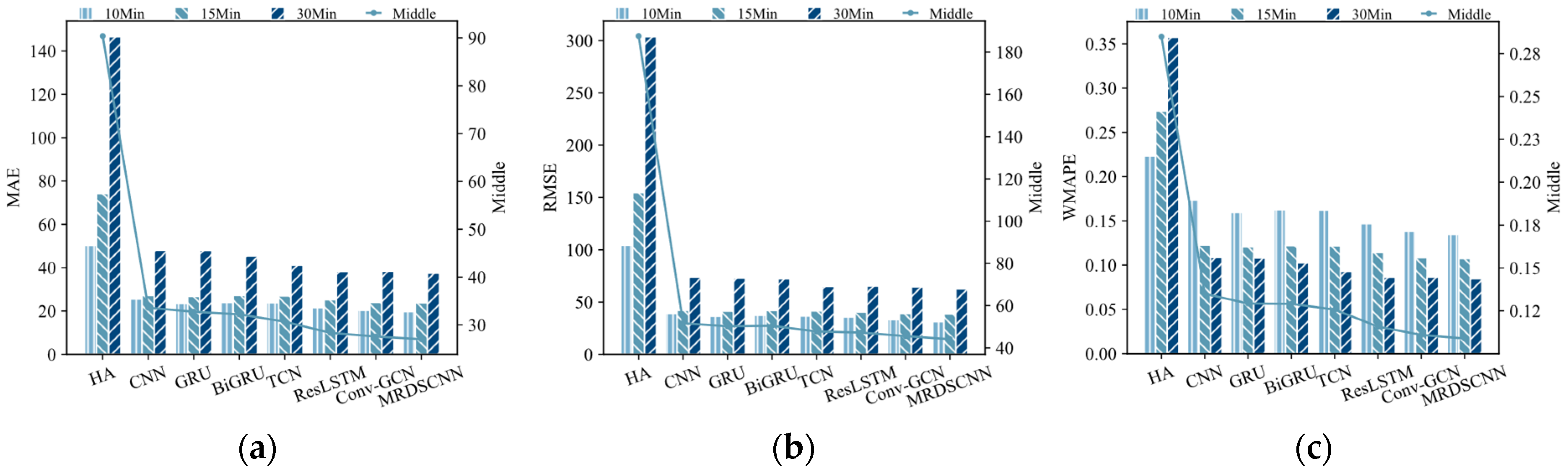
3.4.3. Comparative Analysis of Different Models
3.4.4. Prediction Performance of Typical Stations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cavone, G.; Montaruli, V.; Van Den Boom, T.; Dotoli, M. Demand-Oriented Rescheduling of Railway Traffic in Case of Delays. In Proceedings of the 2020 7th International Conference on Control, Decision and Information Technologies (CoDIT), Prague, Czech Republic, 29 June–2 July 2020; pp. 1040–1045. [Google Scholar]
- Luo, J.; Tong, Y.; Cavone, G.; Dotoli, M. A Service-Oriented Metro Traffic Regulation Method for Improving Operation Performance. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3533–3538. [Google Scholar]
- Cavone, G.; Blenkers, L.; Van Den Boom, T.; Dotoli, M.; Seatzu, C.; De Schutter, B. Railway disruption: A bi-level rescheduling algorithm. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 54–59. [Google Scholar]
- Ghasempour, T.; Nicholson, G.L.; Kirkwood, D.; Fujiyama, T.; Heydecker, B. Distributed approximate dynamic control for traffic management of busy railway networks. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3788–3798. [Google Scholar] [CrossRef]
- Liu, J.; Chen, L.; Roberts, C.; Gemma, N.; Bo, A. Algorithm and peer-to-peer negotiation strategies for train dispatching problems in railway bottleneck sections. IET Intell. Transp. Syst. 2019, 13, 1717–1725. [Google Scholar] [CrossRef]
- Hou, Z.; Dong, H.; Gao, S.; Nicholson, G.; Chen, L.; Roberts, C. Energy-saving metro train timetable rescheduling model considering ATO profiles and dynamic passenger flow. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2774–2785. [Google Scholar] [CrossRef]
- Smith, B.L.; Demetsky, M.J. Traffic flow forecasting: Comparison of modeling approaches. J. Transp. Eng. 1997, 123, 261–266. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, Z.; Zeng, B.; Deng, J.; Li, C. A multi-pattern deep fusion model for short-term bus passenger flow forecasting. Appl. Soft Comput. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, M.-C. Forecasting the short-term metro passenger flow with empirical mode decomposition and neural networks. Transp. Res. Part C Emerg. Technol. 2012, 21, 148–162. [Google Scholar] [CrossRef]
- Tang, T.; Liu, R.; Choudhury, C. Incorporating weather conditions and travel history in estimating the alighting bus stops from smart card data. Sustain. Cities Soc. 2020, 53, 101927. [Google Scholar] [CrossRef]
- Lin, L.; Gao, Y.; Cao, B.; Wang, Z.; Jia, C.; Guo, L. Passenger Flow Scale Prediction of Urban Rail Transit Stations Based on Multilayer Perceptron (MLP). Complexity 2023, 2023, 1430449. [Google Scholar] [CrossRef]
- Peng, H.; Wang, H.; Du, B.; Bhuiyan, M.Z.A.; Ma, H.; Liu, J.; Wang, L.; Yang, Z.; Du, L.; Wang, S.; et al. Spatial temporal incidence dynamic graph neural networks for traffic flow forecasting. Inf. Sci. 2020, 521, 277–290. [Google Scholar] [CrossRef]
- Hou, Z.; Du, Z.; Yang, G.; Yang, Z. Short-Term Passenger Flow Prediction of Urban Rail Transit Based on a Combined Deep Learning Model. Appl. Sci. 2022, 12, 7597. [Google Scholar] [CrossRef]
- Zhai, X.; Shen, Y. Short-Term Bus Passenger Flow Prediction Based on Graph Diffusion Convolutional Recurrent Neural Network. Appl. Sci. 2023, 13, 4910. [Google Scholar] [CrossRef]
- Wu, J.; Li, X.; He, D.; Li, Q.; Xiang, W. Learning spatial-temporal dynamics and interactivity for short-term passenger flow prediction in urban rail transit. Appl. Intell. 2023, 53, 19785–19806. [Google Scholar] [CrossRef]
- Sha, S.; Li, J.; Zhang, K.; Yang, Z.; Wei, Z.; Li, X.; Zhu, X. RNN-Based Subway Passenger Flow Rolling Prediction. IEEE Access 2020, 8, 15232–15240. [Google Scholar] [CrossRef]
- Niu, K.; Cheng, C.; Chang, J.; Zhang, H.; Zhou, T. Real-Time Taxi-Passenger Prediction With L-CNN. IEEE Trans. Veh. Technol. 2019, 68, 4122–4129. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Zhang, X.; Wang, C.; Chen, J.; Chen, D. A deep neural network model with GCN and 3D convolutional network for short-term metro passenger flow forecasting. IET Intell. Transp. Syst. 2023, 17, 1599–1607. [Google Scholar] [CrossRef]
- Chen, P.; Fu, X.; Wang, X. A Graph Convolutional Stacked Bidirectional Unidirectional-LSTM Neural Network for Metro Ridership Prediction. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6950–6962. [Google Scholar] [CrossRef]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef]
- Liu, L.; Chen, J.; Wu, H.; Zhen, J.; Li, G.; Lin, L. Physical-Virtual Collaboration Modeling for Intra- and Inter-Station Metro Ridership Prediction. IEEE Trans. Intell. Transport. Syst. 2022, 23, 3377–3391. [Google Scholar] [CrossRef]
- Dong, N.; Li, T.; Liu, T.; Tu, R.; Lin, F.; Liu, H.; Bo, Y. A method for short-term passenger flow prediction in urban rail transit based on deep learning. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Liu, L.; Wu, M.; Chen, R.-C.; Zhu, S.; Wang, Y. A Hybrid Deep Learning Model for Multi-Station Classification and Passenger Flow Prediction. Appl. Sci. 2023, 13, 2899. [Google Scholar] [CrossRef]
- Ke, J.; Qin, X.; Yang, H.; Zheng, Z.; Zhu, Z.; Ye, J. Predicting origin-destination ride-sourcing demand with a spatio-temporal encoder-decoder residual multi-graph convolutional network. Transp. Res. Part C Emerg. Technol. 2021, 122, 102858. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, F.; Guo, Y.; Li, X. Multi-graph convolutional network for short-term passenger flow forecasting in urban rail transit. IET Intell. Transp. Syst. 2020, 14, 1210–1217. [Google Scholar] [CrossRef]
- Li, H. Time works well: Dynamic time warping based on time weighting for time series data mining. Inf. Sci. 2021, 547, 592–608. [Google Scholar] [CrossRef]
- Ni, Q.; Zhang, M. STGMN: A gated multi-graph convolutional network framework for traffic flow prediction. Appl. Intell. 2022, 52, 15026–15039. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X.; Li, T. Predicting citywide crowd flows using deep spatio-temporal residual networks. Artif. Intell. 2018, 259, 147–166. [Google Scholar] [CrossRef]
- Chen, D.; Yan, X.; Liu, X.; Li, S.; Wang, L.; Tian, X. A multiscale grid-based stacked bidirectional GRU neural network model for predicting traffic speeds of urban expressways. IEEE Access 2021, 9, 1321–1337. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zhang, J.; Chen, F.; Cui, Z.; Guo, Y.; Zhu, Y. Deep Learning Architecture for Short-Term Passenger Flow Forecasting in Urban Rail Transit. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7004–7014. [Google Scholar] [CrossRef]
- Yin, D.; Jiang, R.; Deng, J.; Li, Y.; Xie, Y.; Wang, Z.; Zhou, Y.; Song, X.; Shang, J. MTMGNN: Multi-time multi-graph neural network for metro passenger flow prediction. GeoInformatica 2023, 27, 77–105. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, C.; Tsung, F. Transformer Based Spatial-Temporal Fusion Network for Metro Passenger Flow Forecasting. In Proceedings of the 2021 17th IEEE International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1515–1520. [Google Scholar]
- Yang, J.; Liu, T.; Li, C.; Tong, W.; Zhu, Y.; Ai, W. MGSTCN: A multi-graph spatio-temporal convolutional network for metro passenger flow prediction. In Proceedings of the 2021 7th International Conference on Big Data Computing and Communications (BigCom), Deqing, China, 13–15 August 2021; pp. 164–171. [Google Scholar]
- Lu, Y.; Ding, H.; Ji, S.; Sze, N.N.; He, Z. Dual attentive graph neural network for metro passenger flow prediction. Neural Comput. Appl. 2021, 33, 13417–13431. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Description |
|---|---|
| Smith et al. [7] | The HA model forecasted Lisbon Airport’s passenger numbers to determine the demand in a new airport using non-causal methods. |
| Bai et al. [8] | This paper proposed a mutil-pattern deep fusion approach which used the AP algorithm for clustering analysis and fused the output of the multi-pattern DBNs to obtain the final prediction results. |
| Wei et al. [9] | The EMD-BPN model decomposed the short-term passenger flow series data into a number of intrinsic mode function (IMF) components as inputs to the BPN and then applied BPN to passenger flow prediction. |
| Tang et al. [10] | The paper incorporated weather variables, personal travel history, and network features into the GBDT algorithm. |
| Lin et al. [11] | The multilayer perceptron (MLP)-based passenger flow prediction model was developed to predict the passenger flow at key stations. |
| Peng et al. [12] | Dynamic-GRCNN model integrated the relationship of passengers and GCN and LSTM units to learn complex traffic spatial–temporal features. |
| Hou et al. [13] | The TCN-LSTM model solved the difficulty of accurate prediction due to the large fluctuation and randomness of short-term passenger flow in rail transit. |
| Zhai et al. [14] | Graph-based DCRNN integrated graph features into the RNN to capture the spatiotemporal dependencies in the bus network. The diffusion convolution recurrent neural network (DCRNN) architecture was adopted to forecast the future number of passengers on each bus line. |
| Wu et al. [15] | The MFGCN model included the GCN with a spatial-attention mechanism and the LSTM with a temporal-attention mechanism to extract higher-order spatial–temporal interaction characteristics. |
| Sha et al. [16] | The GRU model can selectively retain and update important information about past time steps due to its gating mechanism of information flow within the network. |
| Niu et al. [17] | Authors applied convolutional operations to extract spatial and temporal features from the passenger flow time series. By stacking multiple convolutional layers, the CNN can capture complex and hierarchical representations of the input sequence. |
| Kipf et al. [18] | The GCN presented a scalable approach for semi-supervised learning on graph-structured data that is based on an efficient variant of convolutional neural networks which operate directly on graphs. |
| Zhang et al. [19] | The ARConv-GCN model combined GCN and the attention residual 3DCNN for more accurate short-term passenger flow prediction in rail transit. |
| Chen et al. [20] | This paper proposed a parallel-structured deep learning model that consists of a GCN and a stacked BiLSTM for predicting passenger inflow. |
| Zhao et al. [21] | Authors introduced GCN to capture the geographical connectivity relationships between sites on the basis of GRU. |
| Liu et al. [22] | The PVCGN is a Seq2Seq model including a graph convolution gated recurrent unit (GC-GRU) for spatial–temporal representation learning and a fully connected gated recurrent unit (FC-GRU) for capturing the global evolution tendency. |
| Dong et al. [23] | This paper incorporated the convolution operation between LSTM cells and predicted passenger flow for three different types of stations: terminal station, transfer station, and regular station. |
| Liu et al. [24] | This paper proposed a novel two-step strategy (Transformer-K-Means)-(ResNet-GCN-AttLSTM), which includes classification block based on the K-Means, and prediction block, which includes ResNet, GCN, and AttLSTM. |
| Ke et al. [25] | The ST-ED-RMGC model was proposed, which is an encoder–decoder framework used to study the OD-based ride-sourcing demand prediction problem. |
| Zhang et al. [26] | The Conv-GCN model is a fusion of multi-graph GCN and 3D CNN, allowing it to effectively capture high-level spatiotemporal features among different patterns of passenger flow. |
| Cavone et al. [1] | The predicted passenger flow results can serve as a key solution to alleviate the operational pressure brought about by increasing demand. |
| Luo et al. [2] | Passenger flow prediction can provide reference for optimizing traffic operations in disturbed environments and ensuring a secure and comfortable travel experience for passengers. |
| Cavone et al. [3] | Passenger flow prediction can also be used to respond to emergency situations or traffic interruptions. |
| Ghasempour et al. [4] | Passenger flow prediction results can help to rearrange subway schedules and reduce delays. |
| Liu et al. [5] | Accurate passenger flow prediction can contribute to limiting train delays, especially in a bottleneck area of railway traffic management. |
| Hou et al. [6] | The results of passenger flow prediction are helpful for train scheduling in bottleneck sections and reducing train energy consumption. |
| Station | 5:30–5:40 | 5:40–5:50 | 5:50–6:00 | … | 23:10–23:20 | 23:10–23:20 | 23:20–23:30 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 4 | 3 | … | 1 | 0 | 0 |
| 1 | 0 | 5 | 5 | … | 2 | 1 | 1 |
| 2 | 0 | 9 | 11 | … | 6 | 4 | 1 |
| … | … | … | … | … | … | … | … |
| 79 | 0 | 0 | 4 | … | 5 | 7 | 1 |
| Parameters | Passenger Inflow Prediction | Passenger Outflow Prediction | AttBiGRU |
|---|---|---|---|
| Kernel Size | 3 × 3 | 3 × 3 | - |
| Dilation rate | 3 | 3 | - |
| Residual Module1 | 32 filters | 32 filters | - |
| Residual Module2 | 64 filters | 64 filters | - |
| Batch Size | 64 | 64 | 64 |
| Activation Function | ReLu | ReLu | Linear |
| Number of Layers | - | - | 1 |
| Number of Neurons | - | - | 128 |
| Number of Neurons in FC1 | 80 | 80 | - |
| Number of Neurons in FC2 | 80 | 80 | - |
| Number of GCN Layers | 1 | 1 | - |
| Model | 10 Min | 15 Min | 30 Min | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | |
| MRDSCNN-No G | 19.23 | 29.71 | 13.07% | 23.92 | 38.60 | 10.80% | 40.55 | 67.14 | 9.26% |
| MRDSCNN-Gc | 17.41 | 28.58 | 11.86% | 22.25 | 36.76 | 10.09% | 39.72 | 65.14 | 9.08% |
| MRDSCNN-Gs | 17.35 | 28.39 | 11.81% | 22.24 | 36.75 | 10.08% | 39.69 | 65.99 | 9.06% |
| MRDSCNN | 16.91 | 27.74 | 11.53% | 21.84 | 35.99 | 9.89% | 37.83 | 61.75 | 8.65% |
| Model | 10 Min | 15 Min | 30 Min | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | |
| MRDSCNN-No G | 20.52 | 33.72 | 13.97% | 24.55 | 40.20 | 11.06% | 40.26 | 68.10 | 9.07% |
| MRDSCNN-Gc | 20.32 | 33.56 | 13.85% | 24.00 | 39.12 | 10.85% | 38.93 | 64.64 | 8.75% |
| MRDSCNN-Gs | 20.28 | 33.19 | 13.78% | 23.83 | 38.65 | 10.75% | 37.68 | 63.70 | 8.48% |
| MRDSCNN | 19.75 | 31.27 | 13.48% | 23.83 | 38.59 | 10.73% | 37.46 | 62.49 | 8.45% |
| Model | 10 Min | 15 Min | 30 Min | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | |
| HA [7] | 31.57 | 56.50 | 21.53% | 58.59 | 104.87 | 26.55% | 178.53 | 311.32 | 38.96% |
| CNN [17] | 22.40 | 33.46 | 15.23% | 26.54 | 42.20 | 12.03% | 47.00 | 71.44 | 10.74% |
| GRU [16] | 20.64 | 31.94 | 14.04% | 26.39 | 41.15 | 11.94% | 44.33 | 69.85 | 10.14% |
| BiGRU [30] | 21.72 | 33.30 | 14.74% | 28.28 | 43.29 | 12.80% | 45.28 | 71.31 | 10.35% |
| TCN [31] | 21.29 | 32.25 | 14.50% | 26.41 | 40.76 | 11.97% | 43.52 | 66.53 | 9.95% |
| ResLSTM [32] | 20.10 | 32.08 | 13.68% | 24.13 | 39.17 | 10.96% | 40.70 | 65.89 | 9.31% |
| Conv-GCN [26] | 18.11 | 29.75 | 12.24% | 23.41 | 39.22 | 10.68% | 40.20 | 64.75 | 9.34% |
| MRDSCNN | 16.91 | 27.74 | 11.53% | 21.84 | 35.99 | 9.89% | 37.83 | 61.75 | 8.65% |
| STGCN [33] | 16.74 | 30.36 | 11.30% | 25.11 | 45.54 | 16.95% | 50.22 | 91.08 | 33.90% |
| DCRNN [33] | 18.00 | 32.24 | 12.14% | 27.00 | 48.36 | 18.21% | 54.00 | 96.72 | 36.42% |
| GBDT [22] | 20.59 | 34.33 | - | 30.88 | 51.50 | - | 36.48 | 61.94 | - |
| TSTFN [34] | - | - | - | 23.56 | 39.70 | - | 47.12 | 79.40 | - |
| Model | 10 Min | 15 Min | 30 Min | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | MAE | RMSE | WMAPE | |
| HA [7] | 50.34 | 104.47 | 22.32% | 74.24 | 154.63 | 27.41% | 146.55 | 303.63 | 35.73% |
| CNN [17] | 25.50 | 39.03 | 17.35% | 27.18 | 42.06 | 12.28% | 48.09 | 73.95 | 10.85% |
| GRU [16] | 23.48 | 36.49 | 15.94% | 26.76 | 41.40 | 12.06% | 48.02 | 72.86 | 10.79% |
| BiGRU [30] | 23.96 | 37.35 | 16.27% | 27.21 | 41.95 | 12.22% | 45.48 | 72.15 | 10.24% |
| TCN [31] | 23.85 | 36.68 | 16.22% | 26.98 | 41.54 | 12.19% | 41.20 | 65.10 | 9.30% |
| ResLSTM [32] | 21.57 | 35.78 | 14.69% | 25.17 | 40.55 | 11.41% | 38.30 | 65.44 | 8.64% |
| Conv-GCN [26] | 20.31 | 33.12 | 13.82% | 24.01 | 39.02 | 10.82% | 38.41 | 64.62 | 8.65% |
| MRDSCNN | 19.75 | 31.27 | 13.48% | 23.83 | 38.59 | 10.73% | 37.46 | 62.49 | 8.45% |
| STGCN [33] | 20.25 | 34.72 | 13.68% | 30.38 | 52.08 | 20.52% | 60.76 | 104.16 | 41.04% |
| DCRNN [33] | 21.77 | 37.84 | 14.69% | 32.66 | 56.76 | 22.04% | 65.32 | 113.52 | 44.07% |
| MGSTCN [35] | - | - | - | 24.10 | 36.50 | - | 48.20 | 73.00 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Liu, L.; Li, M. Multi-Scale Residual Depthwise Separable Convolution for Metro Passenger Flow Prediction. Appl. Sci. 2023, 13, 11272. https://doi.org/10.3390/app132011272
Li T, Liu L, Li M. Multi-Scale Residual Depthwise Separable Convolution for Metro Passenger Flow Prediction. Applied Sciences. 2023; 13(20):11272. https://doi.org/10.3390/app132011272
Chicago/Turabian StyleLi, Taoying, Lu Liu, and Meng Li. 2023. "Multi-Scale Residual Depthwise Separable Convolution for Metro Passenger Flow Prediction" Applied Sciences 13, no. 20: 11272. https://doi.org/10.3390/app132011272
APA StyleLi, T., Liu, L., & Li, M. (2023). Multi-Scale Residual Depthwise Separable Convolution for Metro Passenger Flow Prediction. Applied Sciences, 13(20), 11272. https://doi.org/10.3390/app132011272