

Secure and Efficient Deduplication for Cloud Storage with Dynamic Ownership Management

Abstract
:1. Introduction
- Social media: Social media platforms generate a wide range of data daily, including posts, photos, and videos. And, they captures client activities and interests for the purpose of delivering personalized content and targeted advertising.
- Search the Internet: Search engines such as Google (90.82%), Yahoo (3.17%), and Bing (2.83%) analyze clients’ search terms and click behavior to improve search results, providing personalized information and advertisements [1].
- Internet of Things: Internet of Things (IoT) devices gather diverse environmental data such as temperature, humidity, and location in smart cities and homes. The collected data are used to improve the client convenience and energy efficiency.
- The protocol lacks data deduplication functionality, resulting in an inefficient usage of cloud storage space.
- The protocol requires trust in the CS as it exposes the client’s plaintext to the CS.
- The protocol does not consider specifically updating ownership information concerning stored data in cloud storage.
1.1. Contributions
- Efficient alleviation of client’s computational costs. Our study focuses on scenarios where clients upload data directly to cloud storage services, necessitating the encryption of data for secure storage. Our proposed deduplication protocol is based on the secure data sharing in cloud (SeDaSC) protocol [5], which aims to enhance the computational efficiency for clients utilizing cloud services. Similar to the SeDaSC protocol, ours also integrates a third party called a cryptographic server (CS). The CS encrypts data and the CS executes the data deduplication process. And, our proposed protocol demonstrates efficiency in terms of client-side computational cost compared to existing server-side deduplication protocols.
- Strong assurance of data privacy. In the SeDaSC protocol [5], as clients transmit plaintext to the CS, there is a requirement for trust in the CS, leading to potential privacy infringements. Our protocol prevents the exposure of data to the CS by having clients blind encrypt the data before transmitting them to the CS. The CS then performs CE on the blind encrypted data, enabling deduplication on the encrypted data in cloud storage. Essentially, our protocol ensures privacy for both the CS and cloud storage.
- Reduced third-party dependency. Given that the CS in the SeDaSC protocol has access to data in plaintext, the security of the protocol relies heavily on placing strong trust in the CS. To reduce dependency on the CS, Areed et al. proposed a method where the client employs convergent encryption even when a CS is in place [7]. However, this approach negates the advantage of the CS in reducing the client’s computational overhead. In our protocol, the CS still performs convergent encryption, but the client has the capability to reduce its level of trust in the CS by providing data that are blindly encrypted.
- Secure data management in cases of dynamic ownership changes. Existing deduplication protocols using a CS [5,7] do not specifically consider changes in ownership of data (stored in cloud storage) that may occur due to clients modifying or deleting data. Ref. [5] states that, upon revocation of ownership, clients cannot access the data stored in cloud storage. However, the method mentioned assumes that, without proper authentication of being the rightful owner, the client cannot decrypt the data as they possess only encryption key fragments. Hence, the mentioned process differs in dynamically managing ownership to acquire security elements. Clients’ ownership changes are common scenarios in cloud services and data deduplication. Our protocol allows for secure deduplication even in situations where ownership changes occur frequently. By providing dynamic ownership updates, our protocol enhances security, ensuring both forward and backward secrecy.
1.2. Organization
2. Related Work
2.1. Server-Side Deduplication
2.2. Client-Side Deduplication
3. Preliminaries and Background
3.1. Encryption for Secure Deduplication
3.1.1. Convergent Encryption
- KeyGen. Given a cryptographic hash function h and plaintext m as input, a convergent key is output.
- Encrypt. Given convergent key K and plaintext m as input, it produces encrypted data C.
- Decrypt. Given convergent key K and ciphertext C as input, it produces decrypted data m.
3.1.2. Message-Locked Encryption
- KeyGen. Given a cryptographic hash function h and plaintext m as input, an encryption key for MLE is output.
- Encrypt. Given an encryption key K and plaintext m as input, it produces encrypted data C.
- Decrypt. Given an encryption key K and ciphertext C as input, it produces decrypted data m.
- TagGen. Given a cryptographic hash function H and ciphertext C as input, it produces an integrity verification tag T, which corresponds to ciphertext C.
3.2. Proofs of Ownership
- KeyGen. Given a cryptographic hash function h and plaintext m as input, an encryption key is produced.
- Encrypt. Given an encryption key K and plaintext m as input, it produces encrypted data C.
- TagGen. Given a cryptographic hash function h, ciphertext C, and the Merkle tree leaf size parameters b as input, it produces a Merkle tree and integrity verification tag .
- Decrypt. Given an encryption key K and ciphertext C as input, it produces decrypted data m.
3.3. Secure Data Sharing in Cloud (SeDaSC) Protocol
- Upload. The client uploads plaintext data. The CS generates an encryption key for the uploaded data. Using the encryption key, the CS encrypts the plaintext and stores the data’s information and client’s information in an access control list (). The CS then splits the generated encryption key into two parts, securely storing one part and transmitting the other part to the client. To further enhance security, the CS overwrites and deletes the initial encryption key. The encrypted data are finally stored in the cloud. The purpose of storing client information in the is to verify the legitimate ownership of data when a download request is made. Splitting the encryption key into two parts prevents any single entity from decrypting the data independently. If it is an initial upload, a key generation process is performed.
- KeyGen. Given security parameters and a 256-bit cryptographic hash function h as input, a symmetric key is produced.
- Encrypt. Taking plaintext m, symmetric key algorithms , and symmetric key K as input, it produces encrypted data .
- KeyGen for Client i. Given symmetric key K as input, it generates the key of CS, , and the key of client i, .
- Download. The client requests decryption of data stored in the cloud, sending the encrypted data to the CS. The CS uses the information stored in the , along with the symmetric key provided by the client, to recover the encryption key. Since each client has a different pair, the impersonation of other clients is prevented. If the client sends the correct symmetric key to the CS, it can receive the decrypted data. Alternatively, the client can request the CS to perform both download and decryption. In this case, the client sends the group ID and symmetric key to the CS, which retrieves and decrypts the data from the cloud before transmitting them to the client.
- Decrypt. Given encrypted data C, CS’s key , client i’s key , access control list , and symmetric key algorithms as input, it recovers the encryption key and decrypts the data to produce plaintext .
4. System Model
4.1. Entity
- Client: A client is a person who has ownership by uploading data to cloud storage. Since the data were deduplicated and stored, only the initial client’s data are stored in the storage. The client refers to both the initial and subsequent uploaders that have ownership.
- Cryptographic server (CS): The CS acts as an intermediary between the client and cloud storage. The CS configures the access control list () with the hash value received from the client. The manages data information stored in the cloud storage and client information that owns it. The CS controls the client’s data access rights based on the . If data need to be stored in cloud storage, CS encrypts the data and sends them to cloud storage.
- Cloud storage: Cloud storage stores data from clients. Cloud storage generates a group key for the data in which the storage request is made to manage the dynamic ownership update. The key is generated independently of a key shared in the previous owner group. The data in which the storage request occurs are re-encrypted with the generated key and stored in the storage. It is assumed that cloud storage is unreliable.
4.2. Security Requirements
- Data privacy: Data privacy means that the actual content of the data should be protected from unauthorized access, ensuring that sensitive information within the data remains confidential. The original data remain inaccessible to cloud storage, the CS, and unauthorized clients.
- Data integrity: Data integrity involves ensuring that the data stored in the system remain unaltered and reliable. Both the cloud storage and the CS must have mechanisms in place to verify the purity and correctness of the data before storing them or transferring ownership.
- Forward security: Forward security is a concept where clients whose ownership has expired must be prevented from accessing data stored on the cloud storage. This ensures that, even after losing ownership rights, clients cannot access data that they previously owned. It aims to prevent unauthorized access, protect the integrity of data, maintain a clear separation of ownership, and ensure that clients cannot access data outside their current ownership scope.
- Backward security: Backward security is a concept where clients who have uploaded data to the cloud storage should not be able to access data that were stored before they gained ownership. In other words, even after acquiring ownership rights to certain data, clients should not have access to the historical data records from previous owners.
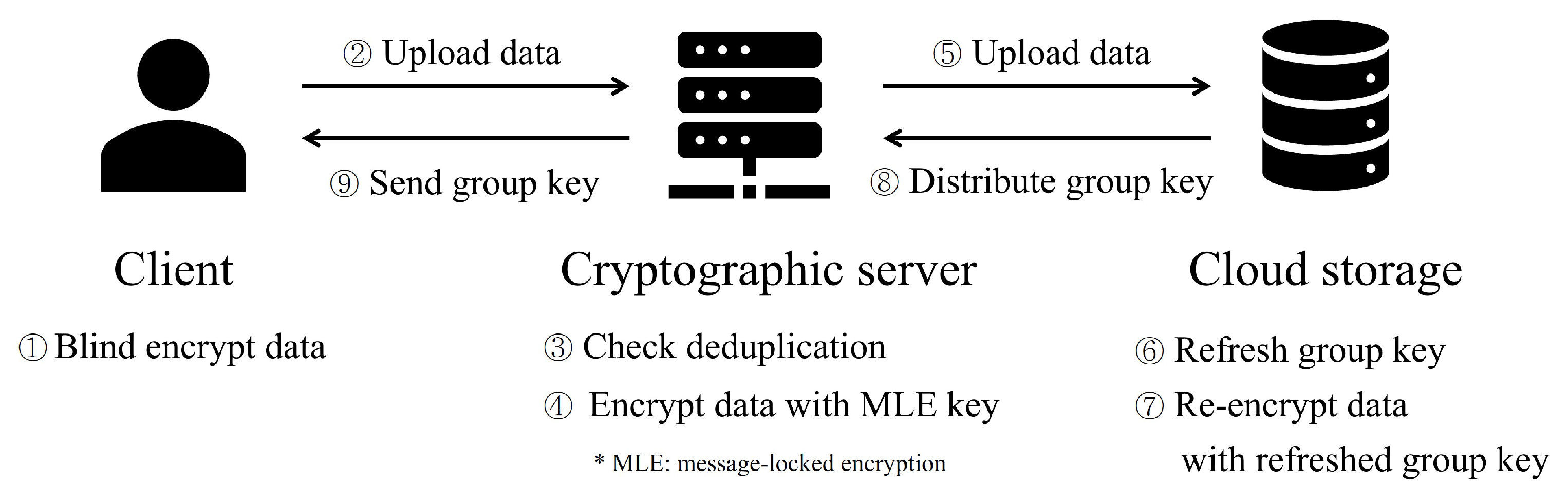
5. The Proposed Secure Deduplication Protocol
5.1. Initial Data Upload
- Step 1.
- Upload pre-work. Client i must blind encrypt and send data to CS.
- The client i calculates the hash value of the message m.
- The client calculates and a hash value . M is a blind encrypted value sent to the CS. Not only is it generated faster than the encryption operation, but also the characteristics of the plaintext are not revealed to the CS.
- The client randomly selects . This will be used to prove the client themselves.
- The client stores , , and . The is used to recover m from M when data downloading. The is used to identify the desired data when requesting an ownership update or data download. The is used to identify the client.
- The client sends an upload request, M, and to the CS.
- Step 2.
- Deduplicate data. The CS determines whether the received data are duplicated and processes the data according to the case.
- The CS calculates the hash value of the received M.
- The CS checks whether and exist in the . The initial upload means no data in the cloud storage. In this case, no information exists in the .
- The CS stores and in . Also, since there are no data in the cloud storage, CS must encrypt M and send it to the cloud storage.
- The CS encrypts M with the hash value . Encrypting data with a hash value is called MLE. Hash values are always the same for the same data. Thus, MLE can generate the same ciphertext for the same data.
- The CS sends a store request, , and to the cloud storage.
- Step 3.
- Re-encrypt data. Cloud storage generates a group key and re-encrypts the data.
- The cloud storage generates a group key, denoted as , by encrypting the results of XOR operations on and session I with the cloud storage’s .
- The cloud storage performs an XOR operation on the ciphertext C and the group key . The C is received from the CS. The result of the XOR operation is a re-encrypted ciphertext for session I.
Whenever an ownership update occurs, the cloud storage refreshes a group key and a re-encrypted ciphertext for the session N.- The cloud storage stores , , and in a ciphertext list of cloud storage ().
- The cloud storage generates an to distribute the refreshed group key. Since there are no owners in the previous session, the generates only .
- The cloud storage sends the generated to the CS and requests it to be sent to the data owner.
- Step 4.
- Send refreshed group key. The CS sends the group key to the legitimate client. The CS must send the group key to the client based on and stored in the . And, the client keeps the group key.
- The CS generates the by XOR operation on the client’s random value in and the received from the cloud storage. The is the random value of the client i stored as owning in the .
5.2. Subsequent Data Upload
- Step 1.
- Upload pre-work.
- The client j calculates the hash value of the message m.
- The client calculates and a hash value to be sent to the CS.
- The client randomly selects to be used to prove oneself.
- The client j stores , , and .
- The client j sends an upload request, M, and to the CS.
- Step 2.
- Deduplicate data.
- The CS calculates the hash value of the received M.
- The CS checks whether and exist in the . For subsequent uploads, they are divided into two cases.
- The first case is that client j uploaded the same data before, but the client does not remember it and re-uploads the data. In this case, and will exist in the of the CS. If so, the CS notifies the client j that the data are already saved.
- The second case is that information about exists in the CS’s but the client j is not registered as the owner. In this case, an update of the ownership group shall be made. The CS stores the client j’s random value in the . And, the CS send a group key update request to the cloud storage.
5.3. Data Download
- Step 1.
- Request download. The client sends a download request to the CS.
- Client i sends a download request with , , and to the CS to download the data.
indicates that the data client wants to download. serves as proof of the client i’s identity, and signifies the client’s involvement in session N. The use of a small quotation mark on the values sent by the client visually indicates whether they match the values stored in the CS and the cloud storage. - Step 2.
- Check ownership. The client sends a download request to the CS.
- The CS checks whether and are stored in the . If both and exist, the CS will normally perform the download process. However, without or , CS will send an error message to the client. This is because the client cannot prove ownership to the CS, or the data do not exist in the cloud storage.
- The CS sends a download request, , and to the cloud storage. is for identifying data stored in the of the cloud storage, and is a group key for session N used to decrypt the re-encrypted data.
- Step 3.
- Cloud storage’s decryption. The cloud storage decrypts the re-encrypted data and sends them to the CS.
- The cloud storage checks whether is stored in the . If exists, the cloud storage calculates ciphertext by performing an XOR operation on the group key and re-encrypted data . The is received from the CS, and the is stored in the of the cloud storage.
- The cloud storage sends to the CS.
- Step 4.
- CS’s decryption. The CS decrypts the ciphertext and sends to the client.
- The CS decrypts the ciphertext as to obtain , and the CS computes the hash value of the message .
- The CS checks whether and calculated are the same. The is a value stored in the CS’s . If the two values are the same, it means that they have been decoded normally and will be transmitted to the client. In other cases, it means that an error occurred during the decoding process, and the client will be notified of this error.
- The CS sends to the client i.
- Step 5.
- Client’s decryption. The client recovers plaintext m from M.
- The client recovers the plaintext by performing an XOR operation on and . The hash value is stored in the client, and the is received from the CS.
If there is no error message received from the CS, m and will be the same data.
5.4. Ownership Update
- Step 1.
- Upload pre-work. The same as Step 1 of the subsequent upload in Section 5.2.
- Step 2.
- Deduplicate data.
- The CS calculates the hash value of the received M.
- The CS checks whether and exist in the .
If information about exists in the of the CS, but client j is not registered as the owning client, an ownership update should be made.- The CS stores the random value of client j in the .
- The CS sends a data re-encrypting request with to the cloud storage. The hash value, denoted as , plays a crucial role in identifying the specific data requested for updating in the cloud storage.
- Step 3.
- Re-encrypt data.
- The cloud storage generates a group key, denoted as , by encrypting the results of XOR operations on and session J with the cloud storage’s . In this context, the encryption with the cloud storage’s secret key is achieved through symmetric key encryption. The hash value is received from the CS.
- The cloud storage generates re-encrypted data, denoted as , by conducting an XOR operation on , , and . Accordingly, the re-encrypted data take the form of .
The previous group key, denoted as , serves to decrypt the ciphertext C within . Essentially, the cloud storage stores only for efficient storage space utilization. Whenever an ownership update occurs, the cloud storage recovers the original ciphertext C using the group key from stored in the . In addition, the cloud creates re-encryption data, , through an XOR operation on ciphertext C and . Importantly, a new group key is generated independently of any prior session. This independence arises because when the cloud storage generates a session value, it remains disconnected from previous sessions, ensuring that each session operates independently.- The cloud storage stores and created in the above two processes.
- The cloud storage generates to distribute the refreshed group key to clients.
- −
- ;
- −
- .
In subsequent uploads, both the existing data owners from the previous session and new owners are involved. Thus, the cloud storage creates two type of refreshed group keys: the for newly added owners and for existing owners. For newly added owners, includes only , because the new owners are not aware of the previous session N. For existing owners, consists of and . And, the prior group key of serves to verify the ownership of previous owners.- The cloud storage sends the generated and to the CS to requests it to be sent to the data owner.
- Step 4.
- Send refreshed group key.
- The CS sends the refreshed group key to the client based on the and stored in the . Suppose that the clients with are j (additional uploader) and i (existing owner).
- −
- For additional uploader j:
- The CS generates by performing an XOR operation on the random value of client j and the .
- The CS sends to client j.
- The client j recovers from the value received.
- *
- .
- −
- For existing owner i:
- The CS generates by performing an XOR operation on the random value of client i and the .
- The CS sends to client i.
- The client i recovers from the value received.
- *
- .
- Both clients store the group key for session J.
5.5. Ownership Delete
- Step 1.
- Request ownership revocation. A client sends an ownership release request to the CS.
- The client i submits an ownership revocation request to the CS, which includes , , and . The hash value specifies which data are owned. The random value informs the client of who it is. The group key means that the client belongs to session N in progress. The small quotation mark on the values sent by the client visually indicates whether they match the values stored in the CS and the cloud storage.
- Step 2.
- Check ownership. The CS checks the client’s ownership,
- The CS checks whether and are stored in the .
If both and are provided, the CS proceeds with the ownership deletion process. However, if either or is missing, the CS sends an error message to the client. In cases where the client is the last owner of stored in , the CS additionally sends a group-key delete request to the cloud storage, ensuring proper data management and security. If the client is the last owner of the stored in the , the CS will also send a group key delete request to the cloud storage.- The CS sends a download request to the cloud storage, which includes , . The hash value is crucial for identifying information stored in the of the cloud storage. The group key serves the purpose of decrypting the re-encrypted data in the cloud storage.
- Step 3.
- Check group key. The cloud storage checks the client’s group key.
- The cloud storage performs a check to determine whether the stored group key matches the received from the CS. If these values match, the cloud storage sends a group key authentication success message to the CS. Otherwise, the cloud storage sends an error message to the CS.
- Step 4.
- Revoke ownership. The CS revokes the client’s ownership in .
- If the message received from the cloud storage is successful, the CS removes the from the , then forwards the results to the client. Conversely, in case of a failure message, an error message is sent to the client.
- Step 5.
- Re-encrypt data. The cloud storage recreates re-encrypted data. After the completion of client i’s ownership revocation, two distinct scenarios emerge.
- First, if remaining owners exist, the group key for the other owners is updated.
- The cloud storage generates a group key, denoted as , by encrypting the results of XOR operations on and session with the cloud storage’s .
- The cloud storage generates a distribution key , designed for the remaining owners. The created in this process is referred to as .
- The cloud storage sends to the CS to request it to be sent to the data owner.
- Second, if there are no remaining owners, all information stored in the cloud storage and the CS at is deleted.
- The cloud storage deletes all data to optimize storage efficiency.
- The cloud storage notifies the CS that all information regarding has been erased.
- Step 6.
- Send refreshed group key. The CS sends the group key to the client based on the . Suppose that a client with is client j, who is an existing owner.
- If the CS receives from the cloud:
- The CS performs an XOR operation on client j’s random value and , and the operation result is for client j.
- The CS sends to client j.
- The client j recovers from , and the client stores .
- If the CS receives a notification from the cloud storage that all information has been deleted:
- The CS deletes all information related to stored in the .
6. Discussion
6.1. Security Analysis
- Data privacy. In our protocol, the CS can access M, but M has blind encryption applied to plaintext m. Hash functions used in blind encryption have structural safety that cannot recover input values from hash values due to preimage resistance. Therefore, the CS cannot recover m from M. The proposed protocol can ensure safety and solve key exchange problems with a relatively simple hash operation.The data delivered to cloud storage in the proposed protocol are a value encrypted with the message-locked encryption (MLE) key by the CS. Since these data are encrypted with the same key, if they are a request for the same plaintext, they will have the same ciphertext. Therefore, cloud storage may perform deduplication on the same encrypted data.
- Data integrity. In our protocol, when a client uploads data, the CS verifies if the received hash value matches the one that it computes directly. The cloud storage also checks if the hash value received from the CS matches the one it calculates independently. In essence, during the upload process, data integrity is inherently confirmed, preventing the storage of corrupted data.
- Forward secrecy. In our protocol, when a client deletes their ownership, they are no longer included in the ownership group for that session, and they cannot access the original data. The ownership group is updated immediately when a client’s ownership changes, and the refreshed group key is also modified. Therefore, following a request for ownership deletion, whether data have been deleted or retained, the client cannot access data stored in the cloud storage.
- Backward secrecy. In our protocol, a client can only access data stored in the cloud if they have uploaded the data and acquired ownership. Even if a client owns the data, they do not automatically become a part of the ownership group for that session. In the proposed protocol, when a client uploads data, the ownership group is immediately updated, and the refreshed group key is changed. Therefore, even if a client uploads data, they cannot gain access to information about data previously stored by the ownership group.
6.2. Performance Analysis
- Client computational complexity:
- Upload. Among the existing server-side deduplication protocols, [4,7] stand out in terms of minimal client computational requirements for data uploads, as depicted in Table 3. These protocols involve a single H and a single SE during both initial and subsequent uploads. In contrast, our protocol necessitates two operations of H and two operations of ⨁. SE algorithms are typically resource-intensive and computationally complex, used for encrypting data. On the other hand, operations like transforming an input into a fixed-size hash value using H and relatively simpler bit-wise operations like ⨁ are generally performed faster and more efficiently. However, actual performance may vary based on factors such as the algorithm used, implementation methods, and hardware configurations, among others.
Table 3 reveals that our approach excels in minimizing computational complexity when uploading and downloading data, offering an efficient solution for clients. - Server computational complexity, on the other hand, pertains to the computational resources required by the cloud storage server when re-encrypting data and distributing group keys during ownership changes. The inclusion of dynamic ownership update features in [6,15] and our approach is a distinct advantage. These features guarantee data confidentiality during ownership transitions and prevent departing clients from accessing data still stored in the cloud storage.
6.3. Analytical Synthesis
- Mitigation of CS dependency: The CS, which encrypts data on behalf of clients, allows clients to significantly reduce their computational workload. However, due to the CS’s capability to access data in plaintext, it must be completely trusted. Our proposal employs blind encryption on plaintext to prevent unauthorized access to plaintext by the CS. As a result, our protocol offers a secure solution, particularly in environments where trust in CS security is low.
- Dynamic ownership update: When applying data deduplication in cloud storage environments, situations arise where ownership information changes. Two common scenarios involve either the original data owner modifying or deleting their data, resulting in the revocation of ownership, or a new client uploading data that match existing data, granting them ownership rights. Such ownership changes can occur frequently in cloud storage services and must be appropriately managed to ensure the security of the service. To solve this issue, our protocol involves the cloud storage storing data in an encrypted format using a secret key. When a change in ownership occurs, the data are re-encrypted with a new key. This newly generated key is then distributed to clients by the CS. This approach enables the prevention of revoked clients from accessing data and ensures that newly added clients cannot access previously uploaded data.
- Client computational efficiency: SeDaSC optimizes client computational efficiency by assigning encryption operations to the CS. However, to generate the same ciphertext for identical data, sending plaintext to the CS is necessary, demanding trust in the CS. To address this, we implemented blind encryption on plaintext, preventing CS access to plaintext. In our proposal, blind encryption requires one hash function and one XOR operation. Table 3 highlights our protocol’s superior computational efficiency on the client side. While our proposal involves more computations than SeDaSC, it still demonstrates greater efficiency than previously proposed server-side deduplication protocols.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Search Engine Market Share Worldwide. Available online: https://gs.statcounter.com/search-engine-market-share#monthly-202201-202212-bar (accessed on 15 October 2023).
- Ng, W.K.; Wen, Y.; Zhu, H. Private data deduplication protocols in cloud storage. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; pp. 441–446. [Google Scholar]
- Dutch, M. Understanding data deduplication ratios. In Proceedings of the SNIA Data Management Forum, Orlando, FL, USA, 7 April 2008; Volume 7. [Google Scholar]
- Douceur, J.R.; Adya, A.; Bolosky, W.J.; Simon, P.; Theimer, M. Reclaiming space from duplicate files in a serverless distributed file system. In Proceedings of the 22nd International Conference on Distributed Computing Systems, Vienna, Austria, 2–5 July 2002; pp. 617–624. [Google Scholar]
- Ali, M.; Dhamotharan, R.; Khan, E.; Khan, S.U.; Vasilakos, A.V.; Li, K.; Zomaya, A.Y. SeDaSC: Secure data sharing in clouds. IEEE Syst. J. 2015, 11, 395–404. [Google Scholar] [CrossRef]
- Hur, J.; Koo, D.; Shin, Y.; Kang, K. Secure data deduplication with dynamic ownership management in cloud storage. IEEE Trans. Knowl. Data Eng. 2016, 28, 3113–3125. [Google Scholar] [CrossRef]
- Areed, M.F.; Rashed, M.M.; Fayez, N.; Abdelhay, E.H. Modified SeDaSc system for efficient data sharing in the cloud. Concurr. Comput. Pract. Exp. 2021, 33, e6377. [Google Scholar] [CrossRef]
- Keelveedhi, S.; Bellare, M.; Ristenpart, T. DupLESS: Server-Aided encryption for deduplicated storage. In Proceedings of the 22nd USENIX Security Symposium (USENIX Security 13), Washington, DC, USA, 14–16 August 2013; pp. 179–194. [Google Scholar]
- Bellare, M.; Keelveedhi, S.; Ristenpart, T. Message-locked encryption and secure deduplication. In Advances in Cryptology—EUROCRYPT 2013, Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Athens, Greece, 26–30 May 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 296–312. [Google Scholar]
- Puzio, P.; Molva, R.; Önen, M.; Loureiro, S. ClouDedup: Secure deduplication with encrypted data for cloud storage. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science, Bristol, UK, 2–5 December 2013; Volume 1, pp. 363–370. [Google Scholar]
- Scanlon, M. Battling the digital forensic backlog through data deduplication. In Proceedings of the 2016 Sixth International Conference on Innovative Computing Technology (INTECH), Dublin, Ireland, 24–26 August 2016; pp. 10–14. [Google Scholar]
- Kim, D.; Song, S.; Choi, B.Y.; Kim, D.; Song, S.; Choi, B.Y. HEDS: Hybrid Email Deduplication System. In Data Deduplication for Data Optimization for Storage and Network Systems; Springer: Cham, Switzerland, 2017; pp. 79–96. [Google Scholar]
- Shin, Y.; Koo, D.; Yun, J.; Hur, J. Decentralized server-aided encryption for secure deduplication in cloud storage. IEEE Trans. Serv. Comput. 2017, 13, 1021–1033. [Google Scholar] [CrossRef]
- Yuan, H.; Chen, X.; Wang, J.; Yuan, J.; Yan, H.; Susilo, W. Blockchain-based public auditing and secure deduplication with fair arbitration. Inf. Sci. 2020, 541, 409–425. [Google Scholar] [CrossRef]
- Ma, X.; Yang, W.; Zhu, Y.; Bai, Z. A Secure and Efficient Data Deduplication Scheme with Dynamic Ownership Management in Cloud Computing. In Proceedings of the 2022 IEEE International Performance, Computing, and Communications Conference (IPCCC), Austin, TX, USA, 11–13 November 2022; pp. 194–201. [Google Scholar]
- Storer, M.W.; Greenan, K.; Long, D.D.; Miller, E.L. Secure data deduplication. In Proceedings of the 4th ACM International Workshop on Storage Security and Survivability, Alexandria, VA, USA, 31 October 2008; pp. 1–10. [Google Scholar]
- Halevi, S.; Harnik, D.; Pinkas, B.; Shulman-Peleg, A. Proofs of ownership in remote storage systems. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 491–500. [Google Scholar]
- Di Pietro, R.; Sorniotti, A. Boosting efficiency and security in proof of ownership for deduplication. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security, Seoul, Republic of Korea, 2–4 May 2012; pp. 81–82. [Google Scholar]
- Blasco, J.; Di Pietro, R.; Orfila, A.; Sorniotti, A. A tunable proof of ownership scheme for deduplication using bloom filters. In Proceedings of the 2014 IEEE Conference on Communications and Network Security, San Francisco, CA, USA, 29–31 October 2014; pp. 481–489. [Google Scholar]
- Li, S.; Xu, C.; Zhang, Y. CSED: Client-side encrypted deduplication scheme based on proofs of ownership for cloud storage. J. Inf. Secur. Appl. 2019, 46, 250–258. [Google Scholar] [CrossRef]
- Guo, C.; Jiang, X.; Choo, K.K.R.; Jie, Y. R-Dedup: Secure client-side deduplication for encrypted data without involving a third-party entity. J. Netw. Comput. Appl. 2020, 162, 102664. [Google Scholar] [CrossRef]
- Al-Amer, A.; Ouda, O. Secure and Efficient Proof of Ownership Scheme for Client-Side Deduplication in Cloud Environments. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 916–923. [Google Scholar] [CrossRef]
- Ha, G.; Jia, C.; Chen, Y.; Chen, H.; Li, M. A secure client-side deduplication scheme based on updatable server-aided encryption. IEEE Trans. Cloud Comput. 2023, 11, 3672–3684. [Google Scholar] [CrossRef]
- Lee, K.; Lee, D.H.; Park, J.H. Efficient Revocable Identity-Based Encryption via Subset Difference Methods. Des. Codes Cryptogr. 2017, 85, 39–76. [Google Scholar] [CrossRef]

{kind=link}
| Notation | Description |
|---|---|
| m | The plaintext |
| The cryptographic hash function | |
| M | The blind-encrypted data |
| C | The ciphertext |
| The random value of client i | |
| The access control list of CS | |
| The ciphertext list of cloud storage | |
| The symmetric encrypt function | |
| The secret key of cloud storage | |
| The client identification name | |
| session | The session identification in progress |
| The group key for session N | |
| The re-encrypted data for session N | |
| The distribution group key | |
| The distribution group key for client n |
| Data Privacy | Data Integrity | Forward Secrecy | Backward Secrecy | |
|---|---|---|---|---|
| [4] | O | X | X | X |
| [9] | O | O | X | X |
| [5] | X | X | 0 | 0 |
| [7] | O | X | X | X |
| [6] | O | O | O | O |
| Ours | O | O | O | O |
| Client Computational Complexity | Server-Aided | Server Computational Complexity | |||
|---|---|---|---|---|---|
| Initial Upload | Subsequent Upload | Download | Dynamic Ownership Update | ||
| [4] | 1H + 1SE | 1H + 1SE | 1SD | X | X |
| [8] | 2H + 2SE + 2M + 3E | 2H + 2SE + 2M + 3E | 2SD | O | X |
| [10] | 2H + 4B∗SE + B∗DS | 2H + 4B∗SE + B∗DS | 2B∗SE + B∗SD | X | X |
| [11] | - | - | - | O | X |
| [6] | 2H + 1SE + 1⨁ | 2H + 1SE + 1⨁ | 2H + 2SD + 1⨁ | X | 1H + 3SE + 1⨁ |
| [12] | - | - | - | X | X |
| [13] | 1H + 5M + + 1DDH | 1H + 5M + + 1DDH | 1H + 1KDF + 3M | O | X |
| [14] | 3H + 1SE + 1M + 1E + 1DS | 3H + 1SE + 1M + 1E + 1DS | 1H + 1SD | O | X |
| [7] | 1H + 1SE | 1H + 1SE | 1SD | O | X |
| [15] | 1H + 1DS + 1PRE-Dn + 1PRE-En + 1SE | 1H + 1DS + 1PRE-Dn + 1PRE-En | - | X | 1PRE-ReEn |
| Ours | 2H + 2⨁ | 2H + 2⨁ | 1⨁ | O | 1SE + 4⨁ |
| SeDaSC Protocol | Our Protocol | ||||
|---|---|---|---|---|---|
| Computational Overhead | Communication Overhead | Computational Overhead | Communication Overhead | ||
| Upload | Client | 0 | 2H + 2⨁ | ||
| CS | RBG + 1H + 1⨁ + 1SE | + | RBG + 1SE | ||
| Cloud storage | 0 | 0 | RBG + 1SE + 4⨁ | 2 | |
| Download | Client | 0 | 0 | ||
| CS | 1SD | 1SD | + | ||
| Cloud storage | 0 | 1SD | |||
| Ownership update | Client | - | - | 1⨁ | 0 |
| CS | - | - | |||
| Cloud storage | - | - | RBG + 1SE + 4⨁ | 2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, M.; Seo, M. Secure and Efficient Deduplication for Cloud Storage with Dynamic Ownership Management. Appl. Sci. 2023, 13, 13270. https://doi.org/10.3390/app132413270
Lee M, Seo M. Secure and Efficient Deduplication for Cloud Storage with Dynamic Ownership Management. Applied Sciences. 2023; 13(24):13270. https://doi.org/10.3390/app132413270
Chicago/Turabian StyleLee, Mira, and Minhye Seo. 2023. "Secure and Efficient Deduplication for Cloud Storage with Dynamic Ownership Management" Applied Sciences 13, no. 24: 13270. https://doi.org/10.3390/app132413270