
A Wrapped Approach Using Unlabeled Data for Diabetic Retinopathy Diagnosis

 ,
, 
Abstract
:1. Introduction
2. The Proposed DR Detection System
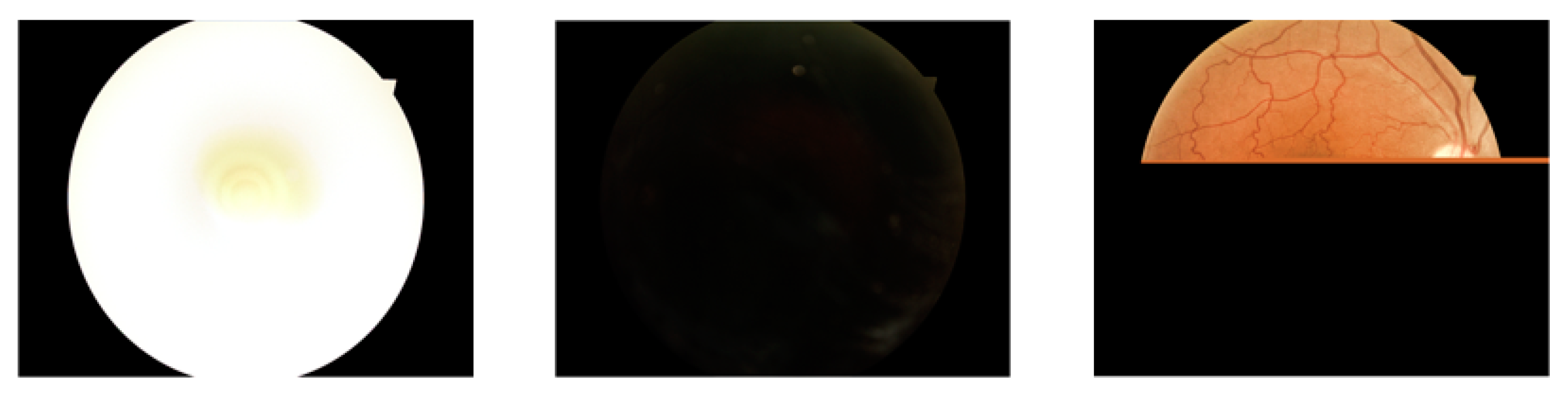
2.1. Data Pre-Processing
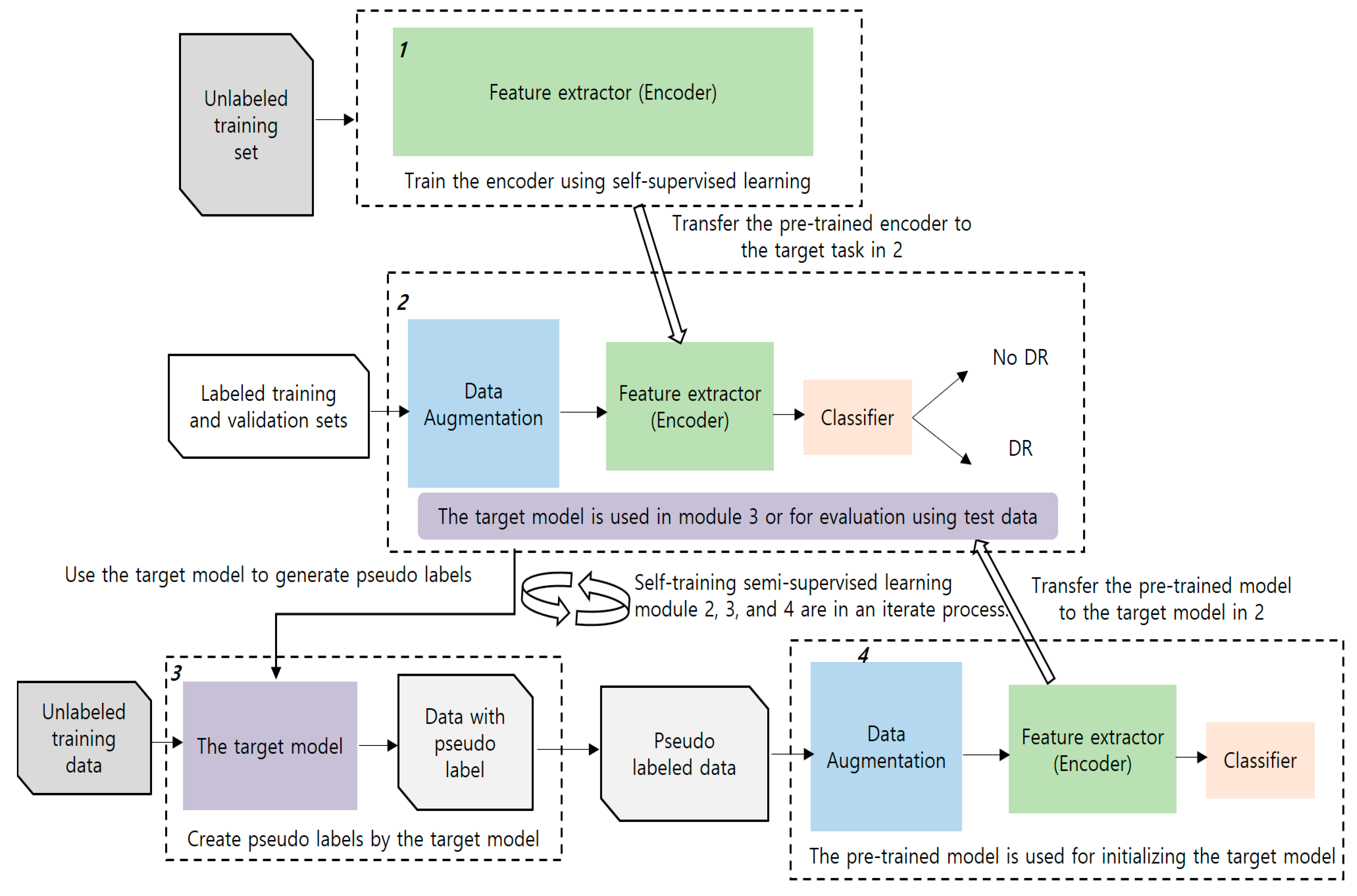
2.2. The Proposed Method
2.2.1. Pre-Training Using Self-Supervised Learning
2.2.2. Pre-Training Using Semi-Supervised Learning
2.2.3. A Combination of Self-Supervised and Semi-Supervised Learning
2.2.4. Additional Process for Imbalanced Learning
3. Experiments
3.1. Datasets
3.2. Experimental Setup
3.3. Experimental Results at Baseline
3.4. Experimental Results for the Proposed Method
3.5. Performance Testing on Other Datasets and Comparison with Previous Results
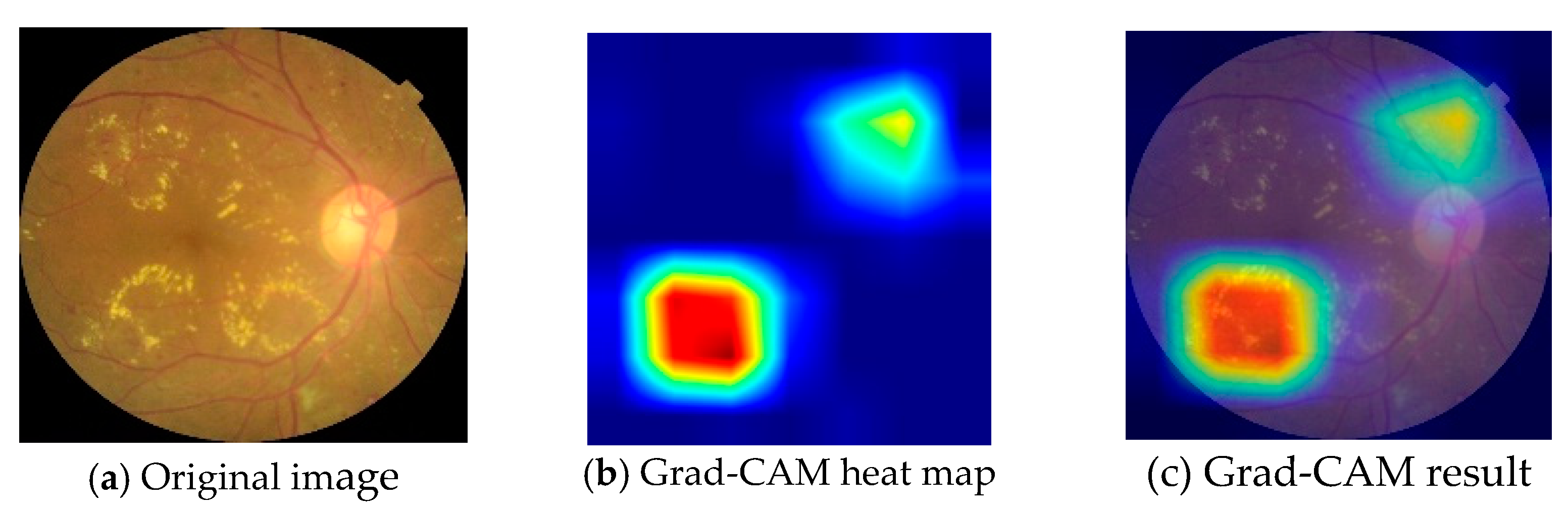
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Memon, W.R.; Lal, B.; Sahto, A.A. Diabetic retinopathy. Prof. Med. J. 2017, 24, 234–238. [Google Scholar] [CrossRef]
- Liu, Y.-P.; Li, Z.; Xu, C.; Li, J.; Liang, R. Referable diabetic retinopathy identification from eye fundus images with weighted path for convolutional neural network. Artif. Intell. Med. 2019, 99, 101694. [Google Scholar] [CrossRef] [PubMed]
- Lakshminarayanan, V.; Kheradfallah, H.; Sarkar, A.; Balaji, J.J. Automated Detection and Diagnosis of Diabetic Retinopathy: A Comprehensive Survey. J. Imaging 2021, 7, 165. [Google Scholar] [CrossRef] [PubMed]
- Tsiknakis, N.; Theodoropoulos, D.; Manikis, G.; Ktistakis, E.; Boutsora, O.; Berto, A.; Scarpa, F.; Scarpa, A.; Fotiadis, D.I.; Marias, K. Deep learning for diabetic retinopathy detection and classification based on fundus images: A review. Comput. Biol. Med. 2021, 135, 104599. [Google Scholar] [CrossRef]
- Mookiah, M.R.K.; Acharya, U.R.; Chua, C.K.; Lim, C.M.; Ng, E.; Laude, A. Computer-aided diagnosis of diabetic retinopathy: A review. Comput. Biol. Med. 2013, 43, 2136–2155. [Google Scholar] [CrossRef]
- Mateen, M.; Wen, J.; Hassan, M.; Nasrullah, N.; Sun, S.; Hayat, S. Automatic Detection of Diabetic Retinopathy: A Review on Datasets, Methods and Evaluation Metrics. IEEE Access 2020, 8, 48784–48811. [Google Scholar] [CrossRef]
- Mansour, R.F. Deep-learning-based automatic computer-aided diagnosis system for diabetic retinopathy. Biomed. Eng. Lett. 2017, 8, 41–57. [Google Scholar] [CrossRef]
- Zhang, W.; Zhong, J.; Yang, S.; Gao, Z.; Hu, J.; Chen, Y.; Yi, Z. Automated identification and grading system of diabetic retinopathy using deep neural networks. Knowl.-Based Syst. 2019, 175, 12–25. [Google Scholar] [CrossRef]
- Li, F.; Liu, Z.; Chen, H.; Jiang, M.; Zhang, X.; Wu, Z. Automatic Detection of Diabetic Retinopathy in Retinal Fundus Photographs Based on Deep Learning Algorithm. Transl. Vis. Sci. Technol. 2019, 8, 4. [Google Scholar] [CrossRef]
- Tymchenko, B.; Marchenko, P.; Spodarets, D. Deep Learning Approach to Diabetic Retinopathy Detection. arXiv 2020, arXiv:2003.02261v1. [Google Scholar]
- Alyoubi, W.; Abulkhair, M.; Shalash, W. Diabetic Retinopathy Fundus Image Classification and Lesions Localization System Using Deep Learning. Sensors 2021, 21, 3704. [Google Scholar] [CrossRef] [PubMed]
- Hagos, M.T.; Kant, S. Transfer learning based detection of diabetic retinopathy from small dataset. arXiv 2019, arXiv:1905.07203v2. [Google Scholar]
- He, A.; Li, T.; Li, N.; Wang, K.; Fu, H. CABNet: Category Attention Block for Imbalanced Diabetic Retinopathy Grading. IEEE Trans. Med. Imaging 2020, 40, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Cortés, S.T.; Pava MD, L.; Perdómo, O.; González, F.A. Hybrid deep learning Gaussian process for diabetic retinopathy diagnosis and uncertainty quantification. arXiv 2020, arXiv:2007.14994v1. [Google Scholar]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional neural networks for diabetic retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef]
- Islam, S.M.S.L.; Hasan, M.M.H.; Abdullah, S. Deep learning based early detection and grading of diabetic retinopathy using retinal fundus images. arXiv 2018, arXiv:1812.10595v1. [Google Scholar]
- Zhang, D.; Bu, W.; Wu, X. Diabetic retinopathy classification using deeply supervised ResNet. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A Deep Learning Ensemble Approach for Diabetic Retinopathy Detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Antal, B.; Hajdu, A. An ensemble-based system for automatic screening of diabetic retinopathy. Knowl.-Based Syst. 2014, 60, 20–27. [Google Scholar] [CrossRef]
- Zeng, X.; Chen, H.; Luo, Y.; Ye, W. Automated Diabetic Retinopathy Detection Based on Binocular Siamese-Like Convolutional Neural Network. IEEE Access 2019, 7, 30744–30753. [Google Scholar] [CrossRef]
- Li, X.; Jia, M.; Islam, T.; Yu, L.; Xing, L. Self-Supervised Feature Learning via Exploiting Multi-Modal Data for Retinal Disease Diagnosis. IEEE Trans. Med. Imaging 2020, 39, 4023–4033. [Google Scholar] [CrossRef]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- Kobat, S.G.; Baygin, N.; Yusufoglu, E.; Baygin, M.; Barua, P.D.; Dogan, S.; Yaman, O.; Celiker, U.; Yildirim, H.; Tan, R.-S.; et al. Automated Diabetic Retinopathy Detection Using Horizontal and Vertical Patch Division-Based Pre-Trained DenseNET with Digital Fundus Images. Diagnostics 2022, 12, 1975. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Li, H.; Dillman, J.R.; Altaye, M.; Wang, H.; Parikh, N.A.; He, L. A self-training deep neural network for early prediction of cognitive deficits in very preterm infants using brain functional connectome data. Pediatr. Radiol. 2022, 52, 2227–2240. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; He, X.; Qi, G.; Li, Y.; Cong, B.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. arXiv 2015, arXiv:1409.0575v3. [Google Scholar] [CrossRef]
- Zhu, X.; Vondrick, C.; Fowlkes, C.C.; Ramanan, D. Do We Need More Training Data? Int. J. Comput. Vis. 2015, 119, 76–92. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.-I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Jackson, B.R. The Dangers of False-Positive and False-Negative Test Results: False-Positive Results as a Function of Pretest Probability. Clin. Lab. Med. 2008, 28, 305–319. [Google Scholar] [CrossRef] [PubMed]
- Seeger, M. A taxonomy for semi-supervised learning methods. In Semi-Supervised Learning; Chapelle, O., Schölkopf, B., Zien, A., Eds.; The MIT Press: Cambridge, MA, USA; London, UK, 2006; pp. 15–31. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-Supervised Learning. arXiv 2021, arXiv:2103.00550v2. [Google Scholar] [CrossRef]
- Cuadros, J.; Bresnick, G. EyePACS: An Adaptable Telemedicine System for Diabetic Retinopathy Screening. J. Diabetes Sci. Technol. 2009, 3, 509–516. [Google Scholar] [CrossRef] [PubMed]
- OIA-DDR Data for Diabetic Retinopathy Classification. Available online: https://github.com/nkicsl/DDR-dataset (accessed on 17 March 2022).
- Decencière, E.; Zhang, X.; Cazuguel, G.; Lay, B.; Cochener, B.; Trone, C.; Gain, P.; Ordóñez-Varela, J.-R.; Massin, P.; Erginay, A.; et al. Feedback on a publicly distributed image database: The Messidor database. Image Anal. Ster. 2014, 33, 231. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, June 26–1 July 2016. [Google Scholar]
- Sun, Z.; Fan, C.; Sun, X.; Meng, Y.; Wu, F.; Li, J. Neural semi-supervised learning for text classification under large-scale pre-training. arXiv 2020, arXiv:2011.08626v2. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 16 June 2022. [Google Scholar]
- Yang, Y.; Xu, Z. Rethinking the value of labels for improving class-imbalanced learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19290–19301. [Google Scholar]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2021, 7, 100198. [Google Scholar] [CrossRef]
- Zhou, B.; Cui, Q.; Wei, X.-S.; Chen, Z.-M. BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 16 June 2020. [Google Scholar]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. arXiv 2019, arXiv:1910.09217. [Google Scholar]
- American Academy of Ophthalmology. International Clinical Diabetic Retinopathy Disease Severity Scale Detailed Table; International Council of Ophthalmology: Brussels, Belgium, 2002. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2019, arXiv:1610.02391. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Imbalanced Training Set | Balanced Training Set | Validation Set | Test Set | ||
|---|---|---|---|---|---|---|
| Number | Percentage (%) | Number | Percentage (%) | Number | Number | |
| 0 | 19,725 | 80.42 | 4802 | 50.0 | 1029 | 1029 |
| 1 | 4802 | 19.58 | 4802 | 50.0 | 1029 | 1029 |
| Class | DDR Test Set | Messidor-2 Test Set |
|---|---|---|
| Number | Number | |
| 0 | 1690 | 1291 |
| 1 | 1690 | 457 |
| Dataset | Imbalanced Training Set | Balanced Training Set | ||||
|---|---|---|---|---|---|---|
| Metrics | ACC (%) | TPR (%) | TNR (%) | ACC (%) | TPR (%) | TNR (%) |
| Training from scratch | 50.0 | 0.0 | 100.0 | 68.03 | 65.89 | 70.17 |
| Transfer learning | 81.78 | 68.42 | 95.14 | 80.27 | 75.02 | 85.52 |
| Data augmentation | 82.12 | 68.03 | 96.12 | 81.53 | 74.05 | 89.02 |
| Dataset | Imbalanced Training Set | Balanced Training Set | |||||
|---|---|---|---|---|---|---|---|
| Metrics | ACC (%) | TPR (%) | TNR (%) | ACC (%) | TPR (%) | TNR (%) | |
| Baseline | T(D) | 82.12 | 68.03 | 96.21 | 81.53 | 74.05 | 89.02 |
| The proposed method | T(U)F(D) | 84.50 | 74.32 | 95.51 | 84.60 | 82.90 | 86.72 |
| T(U)F(D)F(cls) | 85.81 | 81.84 | 90.29 | - | - | - | |
| T(D)L(U)→D′ T(D′)F(D) | 84.99 | 78.52 | 90.38 | 86.40 | 82.80 | 90.90 | |
| T(D)L(U)→D′ T(D′)F(D)F(cls) | 85.62 | 80.95 | 90.28 | - | - | - | |
| T(U)F(D)L(U)→D′ T(D′)F(D) | - | - | - | 86.25 | 82.60 | 89.89 | |
| T(U)F(D)L(U)→D′ T(D′)F(D)F(cls) | 86.10 | 85.13 | 87.07 | - | - | - | |
| Dataset | Imbalanced Training Set | Balanced Training Set | ||||
|---|---|---|---|---|---|---|
| Metrics | ACC (%) | TPR (%) | TNR (%) | ACC (%) | TPR (%) | TNR (%) |
| T(U)F(D)(F(cls) for imb set) | 86.15 | 83.43 | 88.88 | 88.31 | 83.20 | 93.43 |
| T(D)L(U)→D′ T(D′)F(D)(F(cls) for imb set) | 89.2 | 88.64 | 89.73 | 88.76 | 84.97 | 92.54 |
| T(U)F(D)L(U)→D′ T(D′)F(D)(F(cls) for imb set) | 89.50 | 87.81 | 91.18 | 89.62 | 86.39 | 92.84 |
| Dataset | Imbalanced Training Set | Balanced Training Set | ||||
|---|---|---|---|---|---|---|
| Metrics | ACC (%) | TPR (%) | TNR (%) | ACC (%) | TPR (%) | TNR (%) |
| T(U)F(D)(F(cls) for imb set) | 87.30 | 85.78 | 87.84 | 85.81 | 84.90 | 86.13 |
| T(D)L(U)→D′ T(D′)F(D)(F(cls) for imb set) | 90.56 | 89.28 | 91.01 | 87.87 | 85.78 | 88.61 |
| T(U)F(D)L(U)→D′ T(D′)F(D)(F(cls) for imb set) | 90.68 | 86.0 | 92.33 | 88.90 | 85.78 | 90.01 |
| Dataset | EyePaCS | DDR | Messidor-2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Metrics | ACC (%) | TPR (%) | TNR (%) | ACC (%) | TPR (%) | TNR (%) | AUC (%) | TPR (%) | TNR (%) |
| Customized CNN model in [15] | 75.0 | 30.0 | 95.0 | - | - | - | - | - | - |
| CABNet in [13] | 86.18 | - | - | 78.98 | - | - | - | - | - |
| DLGP-DR in [14] | - | - | - | - | - | - | 87.87 | 72.37 | 86.25 |
| The proposed method | 86.40 | 82.80 | 90.90 | 89.62 | 86.39 | 92.84 | 90.15 | 89.28 | 91.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Kim, Y.; Chung, Y.-C.; Yoon, S.; Rhee, S.-Y.; Kim, Y.S. A Wrapped Approach Using Unlabeled Data for Diabetic Retinopathy Diagnosis. Appl. Sci. 2023, 13, 1901. https://doi.org/10.3390/app13031901
Zhang X, Kim Y, Chung Y-C, Yoon S, Rhee S-Y, Kim YS. A Wrapped Approach Using Unlabeled Data for Diabetic Retinopathy Diagnosis. Applied Sciences. 2023; 13(3):1901. https://doi.org/10.3390/app13031901
Chicago/Turabian StyleZhang, Xuefeng, Youngsung Kim, Young-Chul Chung, Sangcheol Yoon, Sang-Yong Rhee, and Yong Soo Kim. 2023. "A Wrapped Approach Using Unlabeled Data for Diabetic Retinopathy Diagnosis" Applied Sciences 13, no. 3: 1901. https://doi.org/10.3390/app13031901
APA StyleZhang, X., Kim, Y., Chung, Y.-C., Yoon, S., Rhee, S.-Y., & Kim, Y. S. (2023). A Wrapped Approach Using Unlabeled Data for Diabetic Retinopathy Diagnosis. Applied Sciences, 13(3), 1901. https://doi.org/10.3390/app13031901