

Estimation of Obesity Levels with a Trained Neural Network Approach optimized by the Bayesian Technique

 ,
,  , , ,
, , ,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Relevant Dataset
2.2. Experimental Analysis
2.2.1. Data Generated: Training, Testing, and Validation Procedure
2.2.2. Neural Network (NN) and Hyperparameters Optimization
2.2.3. Feature Scoring and Selection
2.2.4. Model Evaluation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kivrak, M. Deep Learning-Based Prediction of Obesity Levels According to Eating Habits and Physical Condition. J. Cogn. Syst. 2021, 6, 24–27. [Google Scholar] [CrossRef]
- Hernández Álvarez, G.M. Prevalencia de Sobrepeso y Obesidad, y Factores de Riesgo, en Niños de 7-12 Años, en una Escuela Pública de Cartagena Septiembre-Octubre de 2010. 2011. Available online: https://repositorio.unal.edu.co/handle/unal/7739 (accessed on 17 January 2023).
- Obesity and Overweight. Available online: https://www.who.int/news-room/fact-sheets/detail/obesity-and-overweight (accessed on 1 January 2023).
- Cecchini, M.; Vuik, S. The Heavy Burden of Obesity; OCED: Paris, France, 2019. [Google Scholar]
- Colditz, G.A. Economic costs of obesity and inactivity. Med. Sci. Sport. Exerc. 1999, 31, S663–S667. [Google Scholar] [CrossRef] [PubMed]
- Gil-Rojas, Y.; Garzón, A.; Hernández, F.; Pacheco, B.; González, D.; Campos, J.; Mosos, J.D.; Barahona, J.; Polania, M.J.; Restrepo, P. Burden of disease attributable to obesity and overweight in Colombia. Value Health Reg. Issues 2019, 20, 66–72. [Google Scholar] [CrossRef] [PubMed]
- Oshinubi, K.; Rachdi, M.; Demongeot, J. Analysis of reproduction number R0 of COVID-19 using current health expenditure as gross domestic product percentage (CHE/GDP) across countries. Healthcare 2021, 9, 1247. [Google Scholar] [CrossRef] [PubMed]
- Van Baal, P.H.M.; Polder, J.J.; de Wit, G.A.; Hoogenveen, R.T.; Feenstra, T.L.; Boshuizen, H.C.; Engelfriet, P.M.; Brouwer, W.B.F. Lifetime medical costs of obesity: Prevention no cure for increasing health expenditure. PLoS Med. 2008, 5, e29. [Google Scholar] [CrossRef] [Green Version]
- Gülü, M.; Yapici, H.; Mainer-Pardos, E.; Alves, A.R.; Nobari, H. Investigation of obesity, eating behaviors and physical activity levels living in rural and urban areas during the covid-19 pandemic era: A study of Turkish adolescent. BMC Pediatr. 2022, 22, 405. [Google Scholar] [CrossRef]
- Reidpath, D.D.; Burns, C.; Garrard, J.; Mahoney, M.; Townsend, M. An ecological study of the relationship between social and environmental determinants of obesity. Health Place 2002, 8, 141–145. [Google Scholar] [CrossRef]
- Cohen, D.A.; Finch, B.K.; Bower, A.; Sastry, N. Collective efficacy and obesity: The potential influence of social factors on health. Soc. Sci. Med. 2006, 62, 769–778. [Google Scholar] [CrossRef]
- Lamerz, A.; Kuepper-Nybelen, J.; Wehle, C.; Bruning, N.; Trost-Brinkhues, G.; Brenner, H.; Hebebrand, J.; Herpertz-Dahlmann, B. Social class, parental education, and obesity prevalence in a study of six-year-old children in Germany. Int. J. Obes. 2005, 29, 373–380. [Google Scholar] [CrossRef] [Green Version]
- Ng, M.; Fleming, T.; Robinson, M.; Thomson, B.; Graetz, N.; Margono, C.; Mullany, E.C.; Biryukov, S.; Abbafati, C.; Abera, S.F. Global, regional, and national prevalence of overweight and obesity in children and adults during 1980–2013: A systematic analysis for the Global Burden of Disease Study 2013. Lancet 2014, 384, 766–781. [Google Scholar] [CrossRef] [Green Version]
- Ford, E.S.; Mokdad, A.H. Epidemiology of obesity in the Western Hemisphere. J. Clin. Endocrinol. Metab. 2008, 93, S1–S8. [Google Scholar] [CrossRef] [Green Version]
- Fontaine, K.R.; Redden, D.T.; Wang, C.; Westfall, A.O.; Allison, D.B. Years of life lost due to obesity. JAMA 2003, 289, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Berrington de Gonzalez, A.; Hartge, P.; Cerhan, J.R.; Flint, A.J.; Hannan, L.; MacInnis, R.J.; Moore, S.C.; Tobias, G.S.; Anton-Culver, H.; Freeman, L.B.; et al. Body-mass index and mortality among 1.46 million white adults. N. Engl. J. Med. 2010, 363, 2211–2219. [Google Scholar] [CrossRef] [Green Version]
- Whitlock, G.; Lewington, S.; Sherliker, P.; Clarke, R.; Emberson, J.; Halsey, J.; Qizilbash, N.; Collins, R.; Peto, R. Body-mass index and cause-specific mortality in 900 000 adults: Collaborative analyses of 57 prospective studies. Lancet 2009, 373, 1083–1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pischon, T.; Boeing, H.; Hoffmann, K.; Bergmann, M.; Schulze, M.B.; Overvad, K.; van der Schouw, Y.T.; Spencer, E.; Moons, K.G.; Tjønneland, A.; et al. General and abdominal adiposity and risk of death in Europe. N. Engl. J. Med. 2008, 359, 2105–2120. [Google Scholar] [CrossRef] [Green Version]
- Jaacks, L.M.; Vandevijvere, S.; Pan, A.; McGowan, C.J.; Wallace, C.; Imamura, F.; Mozaffarian, D.; Swinburn, B.; Ezzati, M. The obesity transition: Stages of the global epidemic. Lancet Diabetes Endocrinol. 2019, 7, 231–240. [Google Scholar] [CrossRef]
- Lavie, C.J.; McAuley, P.A.; Church, T.S.; Milani, R.V.; Blair, S.N. Obesity and cardiovascular diseases: Implications regarding fitness, fatness, and severity in the obesity paradox. J. Am. Coll. Cardiol. 2014, 63, 1345–1354. [Google Scholar] [CrossRef] [Green Version]
- Koh-Banerjee, P.; Franz, M.; Sampson, L.; Liu, S.; Jacobs Jr, D.R.; Spiegelman, D.; Willett, W.; Rimm, E. Changes in whole-grain, bran, and cereal fiber consumption in relation to 8-y weight gain among men. Am. J. Clin. Nutr. 2004, 80, 1237–1245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ford, E.S. The epidemiology of obesity and asthma. J. Allergy Clin. Immunol. 2005, 115, 897–909. [Google Scholar] [CrossRef]
- Bakhshi, E.; Koohpayehzadeh, J.; Seifi, B.; Rafei, A.; Biglarian, A.; Asgari, F.; Etemad, K.; BIDHENDI, Y.R. Obesity and related factors in Iran: The STEPS Survey, 2011. Iran. Red Crescent Med. J. 2015, 17, e22479. [Google Scholar] [CrossRef] [Green Version]
- Sarlio-Lähteenkorva, S.; Silventoinen, K.; Lahelma, E. Relative weight and income at different levels of socioeconomic status. Am. J. Public Health 2004, 94, 468–472. [Google Scholar] [CrossRef] [PubMed]
- Bonauto, D.K.; Lu, D.; Fan, Z.J. Peer reviewed: Obesity prevalence by occupation in Washington State, behavioral risk factor surveillance system. Prev. Chronic Dis. 2014, 11, E04. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- John, U.; Hanke, M.; Rumpf, H.; Thyrian, J. Smoking status, cigarettes per day, and their relationship to overweight and obesity among former and current smokers in a national adult general population sample. Int. J. Obes. 2005, 29, 1289–1294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Besson, H.; Ekelund, U.; Luan, J.; May, A.; Sharp, S.; Travier, N.; Agudo, A.; Slimani, N.; Rinaldi, S.; Jenab, M. A cross-sectional analysis of physical activity and obesity indicators in European participants of the EPIC-PANACEA study. Int. J. Obes. 2009, 33, 497–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kahan, S. Overweight and obesity management strategies. Am. J. Manag. Care 2016, 22, s186–s196. [Google Scholar]
- Popkin, B.M.; Adair, L.S.; Ng, S.W. Global nutrition transition and the pandemic of obesity in developing countries. Nutr. Rev. 2012, 70, 3–21. [Google Scholar] [CrossRef] [Green Version]
- Spiegelman, B.M.; Flier, J.S. Obesity and the regulation of energy balance. Cell 2001, 104, 531–543. [Google Scholar] [CrossRef] [Green Version]
- Mondal, P.K.; Foysal, K.H.; Norman, B.A.; Gittner, L.S. Predicting Childhood Obesity Based on Single and Multiple Well-Child Visit Data Using Machine Learning Classifiers. Sensors 2023, 23, 759. [Google Scholar] [CrossRef]
- Dhal, P.; Azad, C. A comprehensive survey on feature selection in the various fields of machine learning. Appl. Intell. 2022, 52, 4543–4581. [Google Scholar] [CrossRef]
- Palechor, F.M.; de la Hoz Manotas, A. Dataset for estimation of obesity levels based on eating habits and physical condition in individuals from Colombia, Peru and Mexico. Data Brief 2019, 25, 104344. [Google Scholar] [CrossRef]
- Keras: The Python Deep Learning API. 2022. Available online: https://keras.io/ (accessed on 13 December 2022).
- Heidari, A.A.; Faris, H.; Aljarah, I.; Mirjalili, S. An efficient hybrid multilayer perceptron neural network with grasshopper optimization. Soft Comput. 2019, 23, 7941–7958. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Jones, D.R. A taxonomy of global optimization methods based on response surfaces. J. Glob. Optim. 2001, 21, 345–383. [Google Scholar] [CrossRef]
- Head, T.; Kumar, M.; Nahrstaedt, H.; Louppe, G.; Shcherbatyi, I. Scikit-Optimize: Sequential Model-Based Optimization in Python—Scikit-Optimize 0.8.1 Documentation. 2022. Available online: https://scikit-optimize.github.io/stable/user_guide.html (accessed on 13 December 2022).
- Celik, C.; Bilge, H.S. Feature Selection With Weighted Conditional Mutual Information. J. Gazi Univ. Fac. Eng. Archit. 2015, 30, 585–596. [Google Scholar]
- Takahashi, K.; Yamamoto, K.; Kuchiba, A.; Koyama, T. Confidence interval for micro-averaged F1 and macro-averaged F1 scores. Appl. Intell. 2022, 52, 4961–4972. [Google Scholar] [CrossRef]
- Assel, M.; Sjoberg, D.D.; Vickers, A.J. The Brier score does not evaluate the clinical utility of diagnostic tests or prediction models. Diagn. Progn. Res. 2017, 1, 19. [Google Scholar] [CrossRef] [Green Version]
- sklearn.feature_selection.SelectKBest. Scikit-Learn. 2022. Available online: https://scikit-learn/stable/modules/generated/sklearn.feature_selection.SelectKBest.html (accessed on 13 December 2022).
- Stangroom, J. Z Score Calculator for 2 Population Proportions. Soc. Sci. Stat 2016. Available online: https://www.socscistatistics.com/tests/ztest/ (accessed on 23 December 2022).
- De-La-Hoz-Correa, E.; Mendoza Palechor, F.; De-La-Hoz-Manotas, A.; Morales Ortega, R.; Sánchez Hernández, A.B. Obesity Level Estimation Software Based on Decision Trees. J. Comput. Sci. 2019, 15, 67–77. [Google Scholar] [CrossRef] [Green Version]
- Pang, X.; Forrest, C.B.; Lê-Scherban, F.; Masino, A.J. Prediction of early childhood obesity with machine learning and electronic health record data. Int. J. Med. Inform. 2021, 150, 104454. [Google Scholar] [CrossRef]
- Cheng, X.; Lin, S.-Y.; Liu, J.; Liu, S.; Zhang, J.; Nie, P.; Fuemmeler, B.F.; Wang, Y.; Xue, H. Does physical activity predict obesity—A machine learning and statistical method-based analysis. Int. J. Environ. Res. Public Health 2021, 18, 3966. [Google Scholar] [CrossRef]
- Adams, S.A.; Der Ananian, C.A.; DuBose, K.D.; Kirtland, K.A.; Ainsworth, B.E. Physical activity levels among overweight and obese adults in South Carolina. South. Med. J. 2003, 96, 539–544. [Google Scholar] [CrossRef]
- Carbone, S.; Del Buono, M.G.; Ozemek, C.; Lavie, C.J. Obesity, risk of diabetes and role of physical activity, exercise training and cardiorespiratory fitness. Prog. Cardiovasc. Dis. 2019, 62, 327–333. [Google Scholar] [CrossRef]
- Janssen, I.; Katzmarzyk, P.T.; Boyce, W.F.; Vereecken, C.; Mulvihill, C.; Roberts, C.; Currie, C.; Pickett, W. Comparison of overweight and obesity prevalence in school-aged youth from 34 countries and their relationships with physical activity and dietary patterns. Obes. Rev. 2005, 6, 123–132. [Google Scholar] [CrossRef]
- Klesges, R.C.; Eck, L.H.; Hanson, C.L.; Haddock, C.K.; Klesges, L.M. Effects of obesity, social interactions, and physical environment on physical activity in preschoolers. Health Psychol. 1990, 9, 435. [Google Scholar] [CrossRef]
- Kamal Nor, N.; Ghozali, A.H.; Ismail, J. Prevalence of Overweight and Obesity Among Children and Adolescents With Autism Spectrum Disorder and Associated Risk Factors. Front. Pediatr. 2019, 7, 38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whitaker, R.C. Obesity prevention in pediatric primary care: Four behaviors to target. Arch. Pediatr. Adolesc. Med. 2003, 157, 725–727. [Google Scholar] [CrossRef] [PubMed]
- Al-Domi, H.A.; Faqih, A.; Jaradat, Z.; Al-Dalaeen, A.; Jaradat, S.; Amarneh, B. Physical activity, sedentary behaviors and dietary patterns as risk factors of obesity among Jordanian schoolchildren. Diabetes Metab. Syndr. Clin. Res. Rev. 2019, 13, 189–194. [Google Scholar] [CrossRef] [PubMed]
- Al-Dalaeen, A.; Al-Domi, H. Factors Associated with Obesity among School Children in Amman, Jordan. Malays. J. Nutr. 2017, 23, 211–218. [Google Scholar]
- Ayabe, M.; Kumahara, H.; Morimura, K.; Sakane, N.; Ishii, K.; Tanaka, H. Accumulation of short bouts of non-exercise daily physical activity is associated with lower visceral fat in Japanese female adults. Int. J. Sport. Med. 2013, 34, 62–67. [Google Scholar] [CrossRef]
- Cameron, N.; Godino, J.; Nichols, J.F.; Wing, D.; Hill, L.; Patrick, K. Associations between physical activity and BMI, body fatness, and visceral adiposity in overweight or obese Latino and non-Latino adults. Int. J. Obes. 2017, 41, 873–877. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.X.; Brown, B.B.; Hanson, H.; Kowaleski-Jones, L.; Smith, K.R.; Zick, C.D. Moderate to vigorous physical activity and weight outcomes: Does every minute count? Am. J. Health Promot. 2013, 28, 41–49. [Google Scholar] [CrossRef] [Green Version]
- Jefferis, B.J.; Parsons, T.J.; Sartini, C.; Ash, S.; Lennon, L.T.; Wannamethee, S.G.; Lee, I.M.; Whincup, P.H. Does duration of physical activity bouts matter for adiposity and metabolic syndrome? A cross-sectional study of older British men. Int. J. Behav. Nutr. Phys. Act. 2016, 13, 36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ebisu, T. Splitting the distance of endurance running: On cardiovascular endurance and blood lipids. Jpn J. Phys. Educ. 1985, 30, 37–43. [Google Scholar]
- Siddarth, D. Risk factors for obesity in children and adults. J. Investig. Med. 2013, 61, 1039–1042. [Google Scholar] [CrossRef] [PubMed]
- Hurst, Y.; Fukuda, H. Effects of changes in eating speed on obesity in patients with diabetes: A secondary analysis of longitudinal health check-up data. BMJ Open 2018, 8, e019589. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Symbol | Feature | Possible Value/Category | Descriptive Statistics |
|---|---|---|---|
| Gender | Gender | Female | 227 (45.58) |
| Male | 271 (54.42) | ||
| Age | Age | Numeric value | 23.15 ± 6.72 |
| Height | Height | Numeric value in meters | 1.69 ± 0.1 |
| Weight | Weight | Numeric value in kilograms | 69.57 ± 17.01 |
| History | Family history of overweight | Yes | 198 (39.76) |
| No | 300 (60.24) | ||
| FAVC | Eat high-caloric food frequently | Yes | 150 (30.12) |
| No | 348 (69.88) | ||
| FCVC | Vegetables consumption frequency | Never | 32 (6.43) |
| Sometimes | 272 (54.62) | ||
| Always | 194 (38.96) | ||
| NCP | Number of main meals daily | Between 1 and 2 | 108 (21.69) |
| Three | 344 (69.08) | ||
| More than three | 46 (9.24) | ||
| CAEC | Consumption of food between meals | No | 53 (10.64) |
| Sometimes | 136 (27.31) | ||
| Frequently | 289 (58.03) | ||
| Always | 20 (4.02) | ||
| Smoke | Smoking | Yes | 466 (93.57) |
| No | 32 (6.43) | ||
| CH2O | Liquid intake daily | Less than a liter | 135 (27.11) |
| Between 1 and 2 L | 266 (53.41) | ||
| More than 2 L | 97 (19.48) | ||
| SCC | Calorie consumption monitoring | Yes | 443 (88.96) |
| No | 55 (11.04) | ||
| FAF | Physical activity | I do not have | 162 (32.53) |
| 1 or 2 days | 158 (31.73) | ||
| 2 or 4 days | 113 (22.69) | ||
| 4 or 5 days | 65 (13.05) | ||
| TUE | Time using technological devices | 0–2 h | 243 (48.80) |
| 3–5 h | 181 (36.35) | ||
| More than 5 h | 74 (14.86) | ||
| CALC | Alcohol consumption | No | 1 (0.20) |
| Sometimes | 45 (9.04) | ||
| Frequently | 273 (54.82) | ||
| Always | 179 (35.94) | ||
| MTRANS | Type of transportation used | Automobile | 99 (19.88) |
| Motorbike | 7 (1.41) | ||
| Bike | 11 (2.21) | ||
| Public transportation | 326 (65.46) | ||
| Walking | 55 (11.04) | ||
| Obesity | Obesity level category | Underweight | 34 (6.83) |
| Normal weight | 287 (57.63) | ||
| Overweight Level I | 47 (9.44) | ||
| Overweight Level II | 11 (2.21) | ||
| Obesity Type I | 3 (0.60) | ||
| Obesity Type II | 58 (11.65) | ||
| Obesity Type III | 58 (11.65) |
| Dataset | Underweight | Normal Weight | Overweight Level I | Overweight Level II | Obesity Type I | Obesity Type II | Obesity Type III |
|---|---|---|---|---|---|---|---|
| training | 28 | 212 | 43 | 9 | 2 | 42 | 38 |
| testing | 6 | 75 | 4 | 2 | 1 | 16 | 20 |
| validation training | 22 | 168 | 35 | 7 | 1 | 36 | 30 |
| validation testing | 6 | 44 | 8 | 2 | 1 | 6 | 8 |
| Hyperparameters | Lowest | Highest | Optimum |
|---|---|---|---|
| n_unit_dense | 20 | 5000 | 30 |
| LR | 10−10 | 10−1 | 0.013 |
| epoch | 20 | 1500 | 1051 |
| batch | 1 | 32 | 16 |
| Trial | Accuracy | F1-Score “Underweight” | F1-Score “Normal Weight” | F1-Score “Overweight Level I” | F1-Score “Overweight Level II” | F1-Score “Obesity Type I” | F1-Score “Obesity Type II” | F1-Score “Obesity Type III” |
|---|---|---|---|---|---|---|---|---|
| 1 | 92.74% | 88.89% | 95.36% | 96.29% | 100.0% | 100.0% | 78.57% | 90.90% |
| 2 | 93.55% | 88.89% | 96.00% | 100.0% | 100.0% | 0% | 80.00% | 90.00% |
| 3 | 92.74% | 88.89% | 94.74% | 100.0% | 100.0% | 100.0% | 74.07% | 95.24% |
| 4 | 96.77% | 94.12% | 97.99% | 100.0% | 100.0% | 100.0% | 90.32% | 95.24% |
| 5 | 95.97% | 94.12% | 97.33% | 100.0% | 100.0% | 100.0% | 87.50% | 94.74% |
| 6 | 92.74% | 88.89% | 95.36% | 96.29% | 100.0% | 100.0% | 78.57% | 90.90% |
| 7 | 94.35% | 94.12% | 96.69% | 100.0% | 100.0% | 100.0% | 80.00% | 90.00% |
| 8 | 91.13% | 88.89% | 93.51% | 100.0% | 100.0% | 100.0% | 66.67% | 94.74% |
| 9 | 87.90% | 84.21% | 93.33% | 88.00% | 100.0% | 0% | 66.67% | 80.00% |
| 10 | 92.74% | 80.00% | 95.89% | 96.30% | 100.0% | 100.0% | 87.50% | 85.71% |
| mean | 93.06% | 89.10% | 95.62% | 97.68% | 100% | 80% | 78.98% | 90.74% |
| SD | 2.34 | 4.27 | 1.43 | 3.62 | 0 | 40 | 7.76 | 4.62 |
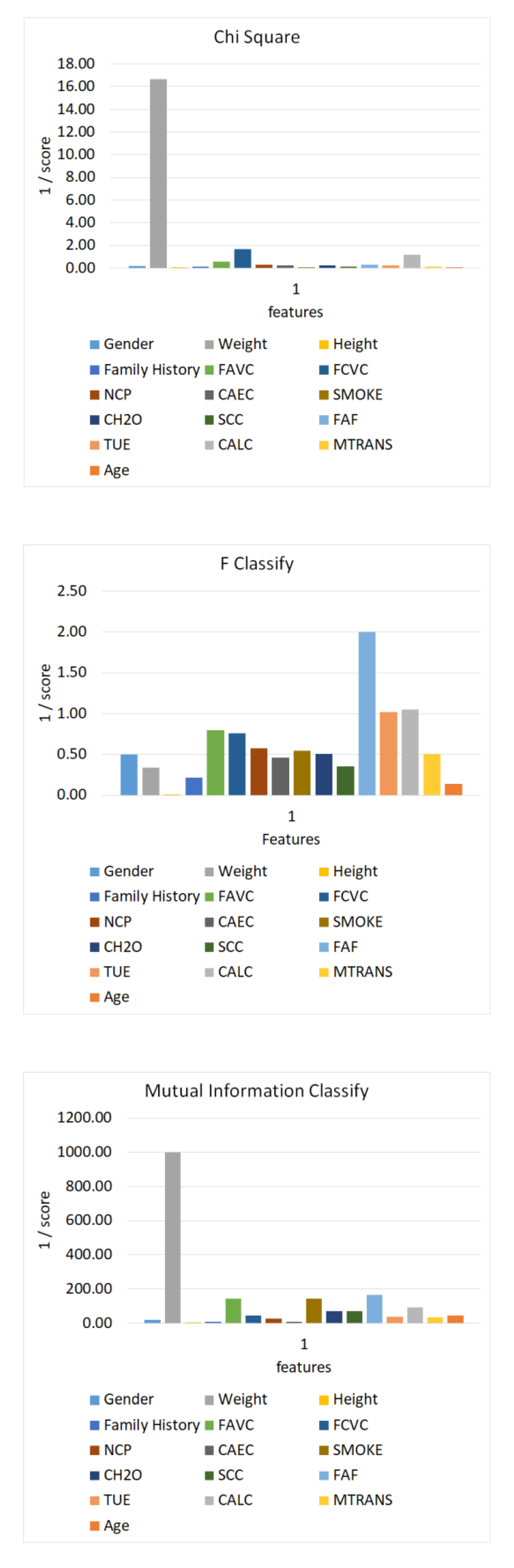
| Feature Name | Chi-Square | F-Classify | Mutual Information Classification |
|---|---|---|---|
| Gender | 6.01 | 2.00 | 0.048 |
| Age | 59.91 | 7.13 | 0.023 |
| Height | 0.06 | 2.99 | 0.001 |
| Weight | 745.97 | 113.3 | 0.529 |
| History | 7.94 | 4.64 | 0.132 |
| FAVC | 1.68 | 1.25 | 0.007 |
| FCVC | 0.60 | 1.32 | 0.022 |
| NCP | 3.68 | 1.75 | 0.039 |
| CAEC | 4.73 | 2.18 | 0.099 |
| Smoke | 18.01 | 1.85 | 0.007 |
| CH2O | 4.47 | 1.97 | 0.014 |
| SCC | 8.34 | 2.86 | 0.014 |
| FAF | 3.25 | 0.50 | 0.006 |
| TUE | 4.15 | 0.98 | 0.026 |
| CALC | 0.86 | 0.95 | 0.011 |
| MTRANS | 8.65 | 1.98 | 0.028 |
| Hyperparameters | Chi-Square | F-Classify | Mutual Information Classification |
|---|---|---|---|
| n_unit_dense | 32 | 65 | 120 |
| lr | 0.085 | 0.0086 | 0.024 |
| epoch | 758 | 1200 | 967 |
| batch | 16 | 8 | 8 |
| Feature Selection Method | Accuracy | F1-Score | SD Accuracy | SD F1-Score | Sensitivity | Specificity | Brier Score |
|---|---|---|---|---|---|---|---|
| Original Model | 93.06% | 92.79% | 2.34 | 3.29 | 93.08% | 93.60% | 0.094 |
| Chi-Square | 89.04% | 89.36% | 1.57 | 1.63 | 89.03% | 90.60% | 0.147 |
| F-Classify | 90.32% | 89.74% | 1.78 | 1.72 | 90.27% | 89.84% | 0.122 |
| Mutual Information Classification | 86.52% | 86.56% | 2.44 | 2.35 | 86.55% | 87.40% | 0.194 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yagin, F.H.; Gülü, M.; Gormez, Y.; Castañeda-Babarro, A.; Colak, C.; Greco, G.; Fischetti, F.; Cataldi, S. Estimation of Obesity Levels with a Trained Neural Network Approach optimized by the Bayesian Technique. Appl. Sci. 2023, 13, 3875. https://doi.org/10.3390/app13063875
Yagin FH, Gülü M, Gormez Y, Castañeda-Babarro A, Colak C, Greco G, Fischetti F, Cataldi S. Estimation of Obesity Levels with a Trained Neural Network Approach optimized by the Bayesian Technique. Applied Sciences. 2023; 13(6):3875. https://doi.org/10.3390/app13063875
Chicago/Turabian StyleYagin, Fatma Hilal, Mehmet Gülü, Yasin Gormez, Arkaitz Castañeda-Babarro, Cemil Colak, Gianpiero Greco, Francesco Fischetti, and Stefania Cataldi. 2023. "Estimation of Obesity Levels with a Trained Neural Network Approach optimized by the Bayesian Technique" Applied Sciences 13, no. 6: 3875. https://doi.org/10.3390/app13063875
APA StyleYagin, F. H., Gülü, M., Gormez, Y., Castañeda-Babarro, A., Colak, C., Greco, G., Fischetti, F., & Cataldi, S. (2023). Estimation of Obesity Levels with a Trained Neural Network Approach optimized by the Bayesian Technique. Applied Sciences, 13(6), 3875. https://doi.org/10.3390/app13063875