
Deep-Learning-Based Sound Classification Model for Concrete Pouring Work Monitoring at a Construction Site



Abstract
:1. Introduction
2. Literature Review
2.1. Accident Detection Studies Based on Acoustic Analysis
2.2. Studies on AI in the Construction Field
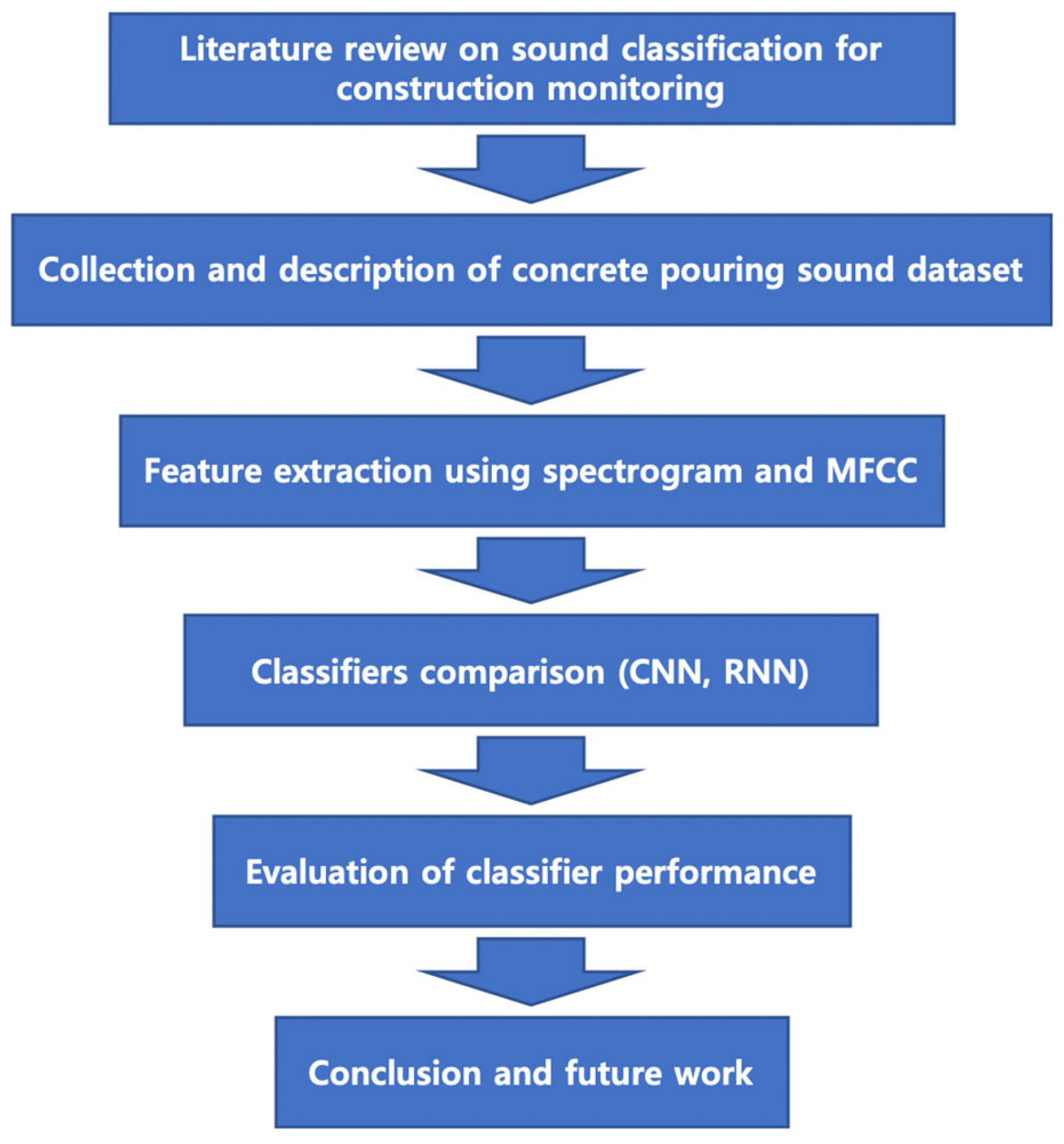
3. Research Scope and Method
4. Methods and Models for Sound Classification in Concrete Pouring Work Monitoring
4.1. Dataset
4.2. Feature Extraction
4.3. Classfiers (CNN and RNN)
5. Results and Utilization Plan
Utilization Plan
6. Conclusions
- Develop a web-server-based sound source determination and location prediction system to enable real-time monitoring of construction sites and provide immediate notifications when abnormal signs are detected.
- Maximize the utilization of the proposed classification model by developing wireless devices that leverage edge computing technology, thus ensuring efficient and seamless data processing and communication.
- Integrate various IoT device sensors with sound data to develop an algorithm that can accurately detect a wide range of site statuses, paving the way for a more comprehensive and smart safety monitoring system.
- Expand the classification model to encompass other construction activities and industries, allowing for broader applications and a more profound impact on safety monitoring across various sectors.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haduong, A.; Kim, J.J.; Balali, V.; Assistant, G. Statistical Results on Incidents for Formwork Safety in Concrete Structures. In Proceedings of the Construction Research Congress 2018, New Orleans, LA, USA, 2–4 April 2018. [Google Scholar]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer Vision Techniques for Construction Safety and Health Monitoring. Adv. Eng. Inform. 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Lee, Y.J.; Park, M.W.; Brilakis, I. Entity Matching across Stereo Cameras for Tracking Construction Workers. In Proceedings of the ISARC 2016—33rd International Symposium on Automation and Robotics in Construction, Auburn, AL, USA, 18–21 July 2016; International Association for Automation and Robotics in Construction (I.A.A.R.C): Auburn, AL, USA; pp. 669–677. [Google Scholar]
- Shin, T.H.; Chin, S.; Yoon, S.W.; Kwon, S.W. A Service-Oriented Integrated Information Framework for RFID/WSN-Based Intelligent Construction Supply Chain Management. Autom. Constr. 2011, 20, 706–715. [Google Scholar] [CrossRef]
- Cho, C.; Lee, Y.-C.; Zhang, T.; Student, P.D. Sound Recognition Techniques for Multi-Layered Construction Activities and Events. In Proceedings of the Computing in Civil Engineering 2017, Seattle, WA, USA, 25–27 June 2017. [Google Scholar]
- Park, M.W.; Brilakis, I. Construction Worker Detection in Video Frames for Initializing Vision Trackers. Autom. Constr. 2012, 28, 15–25. [Google Scholar] [CrossRef]
- Fricker, S.; Vogel, T. Site Installation and Testing of a Continuous Acoustic Monitoring. Constr. Build. Mater. 2007, 21, 501–510. [Google Scholar] [CrossRef]
- Lee, Y.-C.; Scarpiniti, M.; Uncini, A. Advanced Sound Classifiers and Performance Analyses for Accurate Audio-Based Construction Project Monitoring. J. Comput. Civ. Eng. 2020, 34, 04020030. [Google Scholar] [CrossRef]
- Ogden, R.; Hawkins, S.; House, J.; Huckvale, M.; Local, J.; Carter, P.; Dankovičová, J.; Heid, S. ProSynth: An Integrated Prosodic Approach to Device-Independent, Natural-Sounding Speech Synthesis. Comput. Speech Lang. 2000, 14, 177–210. [Google Scholar] [CrossRef]
- Boyanov, B.; Hadjitodorov, S. Acoustic Analysis of Pathological Voices: A Voice Analysis System for the Screening and Laryngeal Diseases. IEEE Eng. Med. Biol. Mag. 1997, 16, 74–82. [Google Scholar] [CrossRef]
- Kavitha, S.; Sanjana, N.; Yogajeeva, K.; Sathyavathi, S. Speech Emotion Recognition Using Different Activation Function. In Proceedings of the 2021 International Conference on Advancements in Electrical, Electronics, Communication, Computing and Automation, ICAECA 2021, Coimbatore, India, 8–9 October 2021. [Google Scholar] [CrossRef]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio Surveillance of Roads: A System for Detecting Anomalous Sounds. IEEE Trans. Intell. Transp. Syst. 2016, 17, 279–288. [Google Scholar] [CrossRef]
- Ferrari, S.; Piccinini, R.; Silva, M.; Exadaktylos, V.; Berckmans, D.; Guarino, M. Cough Sound Description in Relation to Respiratory Diseases in Dairy Calves. Prev. Vet. Med. 2010, 96, 276–280. [Google Scholar] [CrossRef]
- Morrison, G.S. Forensic Voice Comparison and the Paradigm Shift. Sci. Justice 2009, 49, 298–308. [Google Scholar] [CrossRef]
- Mitsuyoshi, S.; Nakamura, M.; Omiya, Y.; Shinohara, S.; Hagiwara, N.; Tokuno, S. Mental Status Assessment of Disaster Relief Personnel by Vocal Affect Display Based on Voice Emotion Recognition. Disaster Mil. Med. 2017, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Kochlan, M.; Hodon, M.; Cechovic, L.; Kapitulik, J.; Jurecka, M. WSN for Traffic Monitoring Using Raspberry Pi Board. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems, FedCSIS 2014, Warsaw, Poland, 7–10 September 2014; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2014; pp. 1023–1026. [Google Scholar]
- Rios-Cabrera, R.; Tuytelaars, T.; van Gool, L. Efficient Multi-Camera Vehicle Detection, Tracking, and Identification in a Tunnel Surveillance Application. Comput. Vis. Image Underst. 2012, 116, 742–753. [Google Scholar] [CrossRef]
- Lee, K.B.; Shin, H.S. An Application of a Deep Learning Algorithm for Automatic Detection of Unexpected Accidents under Bad CCTV Monitoring Conditions in Tunnels. In Proceedings of the 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications, Deep-ML 2019, Istanbul, Turkey, 26–28 August 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2019; pp. 7–11. [Google Scholar]
- Giri, P.; Ng, K.; Phillips, W. Wireless Sensor Network System for Landslide Monitoring and Warning. IEEE Trans. Instrum. Meas. 2019, 68, 1210–1220. [Google Scholar] [CrossRef]
- Cheng, C.F.; Rashidi, A.; Davenport, M.A.; Anderson, D. Audio Signal Processing for Activity Recognition of Construction Heavy Equipment. In Proceedings of the ISARC 2016—33rd International Symposium on Automation and Robotics in Construction, Auburn, AL, USA, 18–21 July 2016; International Association for Automation and Robotics in Construction (I.A.A.R.C): Auburn, AL, USA; pp. 642–650. [Google Scholar]
- Lee, H.-S.; Asce, M.; Lee, K.-P.; Park, M.; Baek, Y.; Lee, S.; Asce, A.M. RFID-Based Real-Time Locating System for Construction Safety Management. J. Comput. Civ. Eng. 2012, 26, 366–377. [Google Scholar] [CrossRef]
- Jin, H.; Zhang, L.; Liang, W.; Ding, Q. Integrated Leakage Detection and Localization Model for Gas Pipelines Based on the Acoustic Wave Method. J. Loss Prev. Process. Ind. 2014, 27, 74–88. [Google Scholar] [CrossRef]
- Liu, J.; Luo, H.; Liu, H. Deep Learning-Based Data Analytics for Safety in Construction. Autom. Constr. 2022, 140, 104302. [Google Scholar] [CrossRef]
- Rafiei, M.H.; Adeli, H. Novel Machine-Learning Model for Estimating Construction Costs Considering Economic Variables and Indexes. J. Constr. Eng. Manag. 2018, 144, 04018106. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep Learning Applications and Challenges in Big Data Analytics. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Jang, Y.; Jeong, I.; Cho, Y.K. Identifying Impact of Variables in Deep Learning Models on Bankruptcy Prediction of Construction Contractors. Eng. Constr. Archit. Manag. 2021, 28, 3282–3298. [Google Scholar] [CrossRef]
- Quaranta, G.; De Domenico, D.; Monti, G. Machine-Learning-Aided Improvement of Mechanics-Based Code-Conforming Shear Capacity Equation for RC Elements with Stirrups. Eng. Struct. 2022, 267, 114665. [Google Scholar] [CrossRef]
- Li, Z.; Yoon, J.; Zhang, R.; Rajabipour, F.; Srubar, W.V.; Dabo, I.; Radlińska, A. Machine Learning in Concrete Science: Applications, Challenges, and Best Practices. NPJ Comput. Mater. 2022, 8, 1–17. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M.R.; Rajagopalan, B. Attribute-Based Safety Risk Assessment. I: Analysis at the Fundamental Level. J. Constr. Eng. Manag. 2015, 141, 04015021. [Google Scholar] [CrossRef]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Application of Machine Learning to Construction Injury Prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.Y.; Hoang, N.D.; Roy, A.F.V.; Wu, Y.W. A Novel Time-Depended Evolutionary Fuzzy SVM Inference Model for Estimating Construction Project at Completion. Eng. Appl. Artif. Intell. 2012, 25, 744–752. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Peng, H.S.; Wu, Y.W.; Chen, T.L. Estimate at Completion for Construction Projects Using Evolutionary Support Vector Machine Inference Model. Autom. Constr. 2010, 19, 619–629. [Google Scholar] [CrossRef]
- Lam, K.C.; Yu, C.Y. A Multiple Kernel Learning-Based Decision Support Model for Contractor Pre-Qualification. Autom. Constr. 2011, 20, 531–536. [Google Scholar] [CrossRef]
- Li, L.; Wang, J.; Leung, H.; Jiang, C. Assessment of Catastrophic Risk Using Bayesian Network Constructed from Domain Knowledge and Spatial Data. Risk Anal. 2010, 30, 1157–1175. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, J.; Li, Q.; Fang, N.; Wang, P.; Ding, L.; Li, S. A Hybrid Model for Prediction in Asphalt Pavement Performance Based on Support Vector Machine and Grey Relation Analysis. J. Adv. Transp. 2020, 2020, 7534970. [Google Scholar] [CrossRef]
- Naganathan, H.; Chong, W.O.; Chen, X. Building Energy Modeling (BEM) Using Clustering Algorithms and Semi-Supervised Machine Learning Approaches. Autom. Constr. 2016, 72, 187–194. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs Neurons: Comparison between Random Forest and ANN for High-Resolution Prediction of Building Energy Consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Hitimana, E.; Bajpai, G.; Musabe, R.; Sibomana, L.; Kayalvizhi, J. Implementation of Iot Framework with Data Analysis Using Deep Learning Methods for Occupancy Prediction in a Building. Future Internet 2021, 13, 67. [Google Scholar] [CrossRef]
- Yang, J.; Arif, O.; Vela, P.A.; Teizer, J.; Shi, Z. Tracking Multiple Workers on Construction Sites Using Video Cameras. Adv. Eng. Inform. 2010, 24, 428–434. [Google Scholar] [CrossRef]
- Chun, P.J.; Izumi, S.; Yamane, T. Automatic Detection Method of Cracks from Concrete Surface Imagery Using Two-Step Light Gradient Boosting Machine. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 61–72. [Google Scholar] [CrossRef]
- Rachmawati, T.S.N.; Kim, S. Unmanned Aerial Vehicles (UAV) Integration with Digital Technologies toward Construction 4.0: A Systematic Literature Review. Sustainability 2022, 14, 5708. [Google Scholar] [CrossRef]
- Johnson, D.S.; Lorenz, W.; Taenzer, M.; Mimilakis, S.; Grollmisch, S.; Abeßer, J.; Lukashevich, H. DESED-FL and URBAN-FL: Federated Learning Datasets for Sound Event Detection. In Proceedings of the European Signal Processing Conference, EUSIPCO, Dublin, Ireland, 23–27 August 2021; pp. 556–560. [Google Scholar]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice Recognition Algorithms Using Mel Frequency Cepstral Coefficient (MFCC) and Dynamic Time Warping (DTW) Techniques. arXiv 2010, arXiv:1003.4083. [Google Scholar]
- Singh, P.P.; Rani, P. An Approach to Extract Feature Using MFCC. IOSR J. Eng. 2014, 4, 21–25. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Pascanu, R.; Gulcehre, C.; Cho, K.; Bengio, Y. How to Construct Deep Recurrent Neural Networks. arXiv 2013, arXiv:1312.6026. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sound Type | Precision | Recall |
|---|---|---|
| Concrete pouring | 96% | 97% |
| Formwork impact sound | 96% | 90% |
| Car horn | 95% | 96% |
| Siren | 96% | 96% |
| Jackhammer | 94% | 92% |
| Hammer | 93% | 96% |
| Drilling | 91% | 95% |
| Excavator | 95% | 93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, I.; Kim, Y.; Chin, S. Deep-Learning-Based Sound Classification Model for Concrete Pouring Work Monitoring at a Construction Site. Appl. Sci. 2023, 13, 4789. https://doi.org/10.3390/app13084789
Kim I, Kim Y, Chin S. Deep-Learning-Based Sound Classification Model for Concrete Pouring Work Monitoring at a Construction Site. Applied Sciences. 2023; 13(8):4789. https://doi.org/10.3390/app13084789
Chicago/Turabian StyleKim, Inchie, Yije Kim, and Sangyoon Chin. 2023. "Deep-Learning-Based Sound Classification Model for Concrete Pouring Work Monitoring at a Construction Site" Applied Sciences 13, no. 8: 4789. https://doi.org/10.3390/app13084789
APA StyleKim, I., Kim, Y., & Chin, S. (2023). Deep-Learning-Based Sound Classification Model for Concrete Pouring Work Monitoring at a Construction Site. Applied Sciences, 13(8), 4789. https://doi.org/10.3390/app13084789