
Object-Tracking Algorithm Combining Motion Direction and Time Series
Abstract
:1. Introduction
- 1.
- We add an additional constraint from the angle quantity to enhance the understanding of motion direction for the network. The additional directional guidance loss guides the network learned motion direction information, which effectively improves the tracking performance.
- 2.
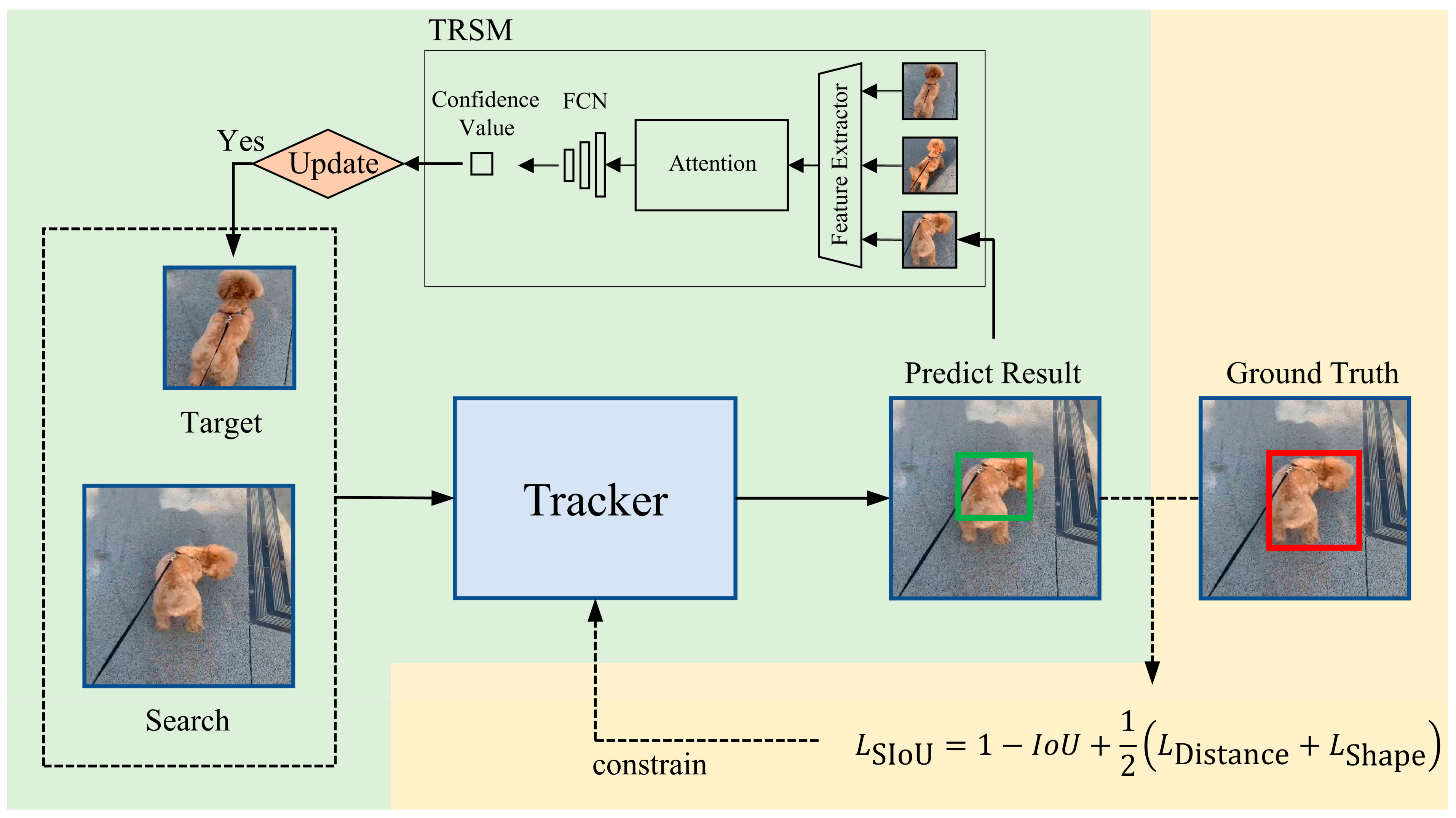
- A tracking result scoring module (TRSM) is proposed to determine the reliability of tracking results. The scoring results are used to assist in the selection of high-quality templates and promote the updating of templates.
- 3.
- The proposed algorithm is evaluated on four benchmark datasets, including TrackingNet, GOT-10K, LaSOT, and VOT2020. Both quantitative experiments and qualitative analysis validate the effectiveness of the proposed method in this work.
2. Related Works
3. Methods
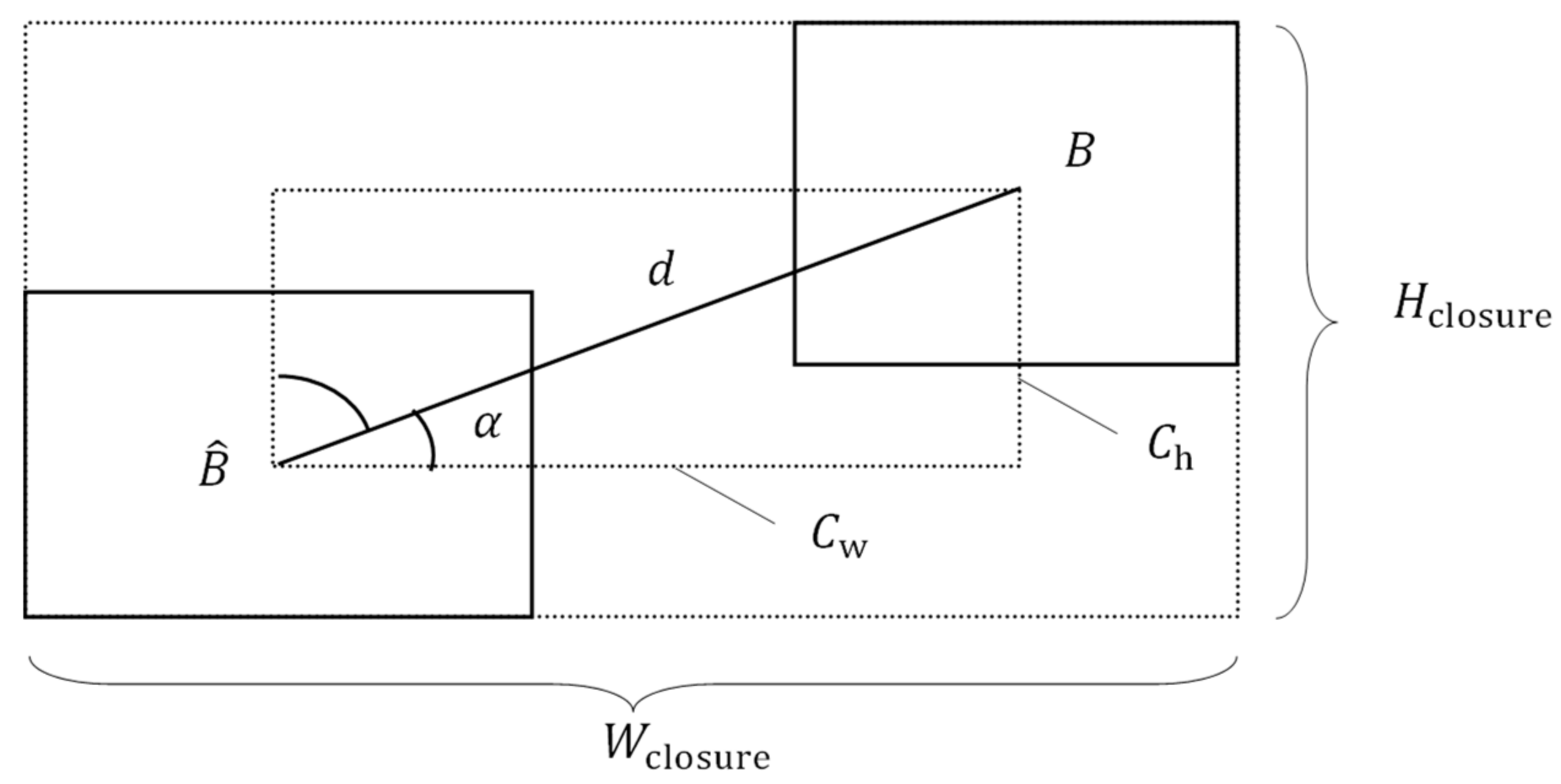
3.1. Loss Function with Directional Guidance
3.2. Tracking Result Scoring Module
4. Experimental Results and Analysis
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
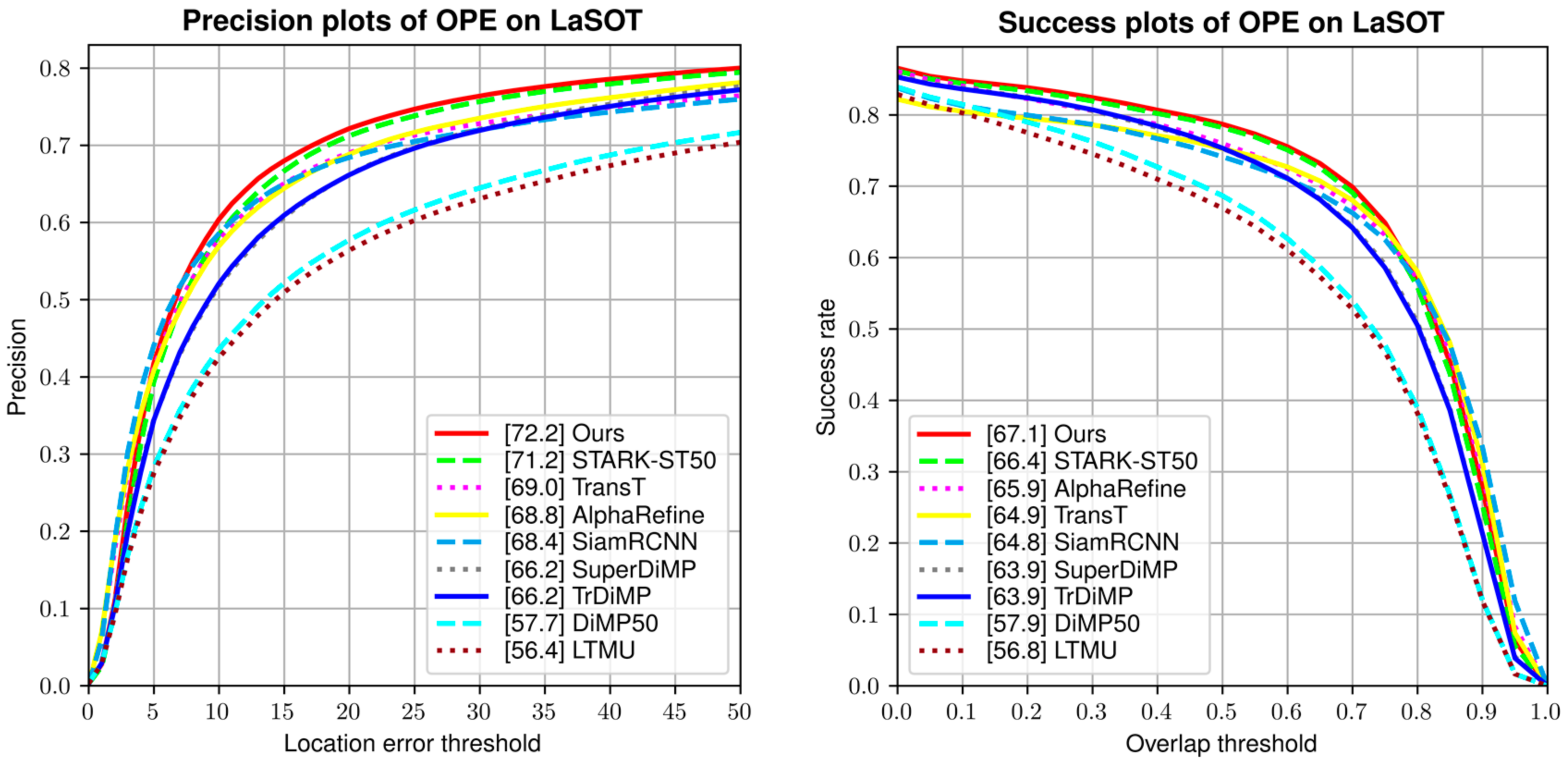
4.4. Comparison of Results
4.5. Speed, FLOPs, and Params
4.6. Ablation Study
4.7. Qualitative Results Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kiani Galoogahi, H.; Fagg, A.; Huang, C.; Ramanan, D.; Lucey, S. Need for speed: A benchmark for higher frame rate object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 24–27 October 2017; pp. 1125–1134. [Google Scholar]
- Bonatti, R.; Ho, C.; Wang, W.; Choudhury, S.; Scherer, S. Towards a robust aerial cinematography platform: Localizing and tracking moving targets in unstructured environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 229–236. [Google Scholar]
- Karaduman, M.; Cınar, A.; Eren, H. UAV traffic patrolling via road detection and tracking in anonymous aerial video frames. J. Intell. Robot. Syst. 2019, 95, 675–690. [Google Scholar] [CrossRef]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep learning for visual tracking: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 3943–3968. [Google Scholar] [CrossRef]
- Soleimanitaleb, Z.; Keyvanrad, M.A.; Jafari, A. Object tracking methods: A review. In Proceedings of the 2019 9th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 24–25 October 2019; pp. 282–288. [Google Scholar]
- Zhou, J.; Yao, Y.; Yang, R. Deep Learning for Single-object Tracking: A Survey. In Proceedings of the 2022 IEEE 2nd International Conference on Software Engineering and Artificial Intelligence (SEAI), Xiamen, China, 10–12 June 2022; pp. 12–19. [Google Scholar]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. Mixformer: End-to-end tracking with iterative mixed attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13608–13618. [Google Scholar]
- Wei, Y.; Hua, Y.; Xiang, W. Research on Specific Long-term Single Object Tracking Algorithms in the Context of Traffic. Procedia Comput. Sci. 2022, 214, 304–311. [Google Scholar] [CrossRef]
- Wang, J.; Yang, H.; Xu, N.; Wu, C.; Wu, D.O. Long-term target tracking combined with re-detection. EURASIP J. Adv. Signal Process. 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Wang, N.; Yeung, D.-Y. Learning a deep compact image representation for visual tracking. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 809–817. [Google Scholar]
- Nam, H.; Baek, M.; Han, B. Modeling and propagating cnns in a tree structure for visual tracking. arXiv 2016, arXiv:1608.07242. [Google Scholar]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Stct: Sequentially training convolutional networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1373–1381. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. Eur. Conf. Comput. Vis. 2016, 9914, 850–865. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. AAAI Conf. Artif. Intell. 2020, 34, 12549–12556. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.; Leibe, B. Siam r-cnn: Visual tracking by re-detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6578–6588. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar]
- Fu, Z.; Liu, Q.; Fu, Z.; Wang, Y. Stmtrack: Template-free visual tracking with space-time memory networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13774–13783. [Google Scholar]
- Yu, B.; Tang, M.; Zheng, L.; Zhu, G.; Wang, J.; Feng, H.; Feng, X.; Lu, H. High-performance discriminative tracking with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 9856–9865. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10448–10457. [Google Scholar]
- Han, B.; Sim, J.; Adam, H. Branchout: Regularization for online ensemble tracking with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3356–3365. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Gupta, D.K.; Arya, D.; Gavves, E. Rotation equivariant siamese networks for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12362–12371. [Google Scholar]
- Bian, T.; Hua, Y.; Song, T.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Vtt: Long-term visual tracking with transformers. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9585–9592. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Kämäräinen, J.-K.; Danelljan, M.; Zajc, L.Č.; Lukežič, A.; Drbohlav, O. The eighth visual object tracking VOT2020 challenge results. Eur. Conf. Comput. Vis. 2020, 12539, 547–601. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. Eur. Conf. Comput. Vis. 2014, 8693, 740–755. [Google Scholar]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-performance long-term tracking with meta-updater. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6298–6307. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6182–6191. [Google Scholar]
- Danelljan, M.; Bhat, G. PyTracking: Visual Tracking Library Based on PyTorch. Available online: https://github.com/visionml/pytracking (accessed on 31 March 2021).
- Yan, B.; Zhang, X.; Wang, D.; Lu, H.; Yang, X. Alpha-refine: Boosting tracking performance by precise bounding box estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5289–5298. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Zhang, Q.; Wang, Z.; Liang, H. SiamRDT: An object tracking algorithm based on a reliable dynamic template. Symmetry 2022, 14, 762. [Google Scholar] [CrossRef]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7183–7192. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar]
- Deng, A.; Liu, J.; Chen, Q.; Wang, X.; Zuo, Y. Visual Tracking with FPN Based on Transformer and Response Map Enhancement. Appl. Sci. 2022, 12, 6551. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. Eur. Conf. Comput. Vis. 2020, 12366, 771–787. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhat, G.; Johnander, J.; Danelljan, M.; Khan, F.S.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 483–498. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Published | AUC (%) | P (%) |
|---|---|---|---|
| LTMU [38] | 2020 | 56.8 | 56.4 |
| DiMP50 [39] | 2019 | 57.9 | 57.7 |
| TrDiMP [22] | 2021 | 63.9 | 66.2 |
| SuperDiMP [40] | 2019 | 63.9 | 66.2 |
| SiamRCNN [19] | 2020 | 64.8 | 68.4 |
| TransT [21] | 2021 | 64.9 | 69.0 |
| AlphaRefine [41] | 2021 | 65.9 | 68.8 |
| STARK-ST50 [25] | 2021 | 66.4 | 71.2 |
| Ours | - | 67.1 | 72.2 |
| Tracker | Published | AUC (%) | |
|---|---|---|---|
| SiamRPN++ [42] | 2019 | 73.3 | 80.0 |
| DiMP50 [39] | 2019 | 74.0 | 80.1 |
| SiamRDT [43] | 2022 | 74.6 | - |
| SiamFC++ [15] | 2020 | 75.4 | 80.0 |
| PrDiMP50 [44] | 2020 | 75.8 | 81.6 |
| AlphaRefine [41] | 2021 | 80.5 | 85.6 |
| SiamRCNN [19] | 2020 | 81.2 | 85.4 |
| TransT [21] | 2021 | 81.4 | 86.7 |
| STARK-ST50 [25] | 2021 | 81.3 | 86.1 |
| Ours | - | 81.9 | 87.2 |
| Tracker | Published | AO (%) | SR0.5 (%) | SR0.75 (%) |
|---|---|---|---|---|
| ATOM [45] | 2019 | 55.6 | 63.4 | 40.2 |
| TR-Siam [46] | 2022 | 58.2 | 68.3 | 45.7 |
| SiamFC++ [15] | 2020 | 59.5 | 69.5 | 47.9 |
| DiMP50 [39] | 2019 | 61.1 | 71.7 | 49.2 |
| Ocean [47] | 2020 | 61.1 | 72.1 | 47.3 |
| SiamRDT [43] | 2022 | 61.3 | 72.5 | 49.2 |
| PrDiMP50 [44] | 2020 | 63.4 | 73.8 | 54.3 |
| SiamRCNN [19] | 2020 | 64.9 | 72.8 | 59.7 |
| TransT [21] | 2021 | 67.1 | 76.8 | 60.9 |
| STARK-ST50 [25] | 2021 | 68.0 | 77.7 | 62.3 |
| Ours | - | 69.7 | 79.4 | 63.9 |
| Tracker | Published | EAO | Accuracy | Robustness |
|---|---|---|---|---|
| KCF [48] | 2014 | 0.154 | 0.407 | 0.432 |
| SiamFC [14] | 2016 | 0.179 | 0.418 | 0.502 |
| ATOM [45] | 2019 | 0.271 | 0.462 | 0.734 |
| DiMP50 [39] | 2019 | 0.274 | 0.457 | 0.74 |
| UPDT [49] | 2018 | 0.278 | 0.465 | 0.755 |
| SuperDiMP [40] | 2019 | 0.305 | 0.477 | 0.786 |
| STARK-ST50 [25] | 2021 | 0.308 | 0.478 | 0.799 |
| Ours | - | 0.313 | 0.486 | 0.798 |
| Trackers | Speed (fps) | Params (M) | FLOPs (G) |
|---|---|---|---|
| Our | 25 | 29.8 | 12.9 |
| STARK-ST50 | 27 | 28.2 | 12.8 |
| STARK-ST50 | DIOU | CIOU | SIOU | TRSM | TrackingNet | LaSOT | |||
|---|---|---|---|---|---|---|---|---|---|
| AUC (%) | P (%) | AUC (%) | |||||||
| 1 | √ | 86.1 | 81.3 | 71.2 | 66.4 | ||||
| 2 | √ | √ | 86.4 | 81.4 | 71.3 | 66.4 | |||
| 3 | √ | √ | 86.4 | 81.4 | 71.4 | 66.5 | |||
| 4 | √ | √ | 86.9 | 81.6 | 71.8 | 66.8 | |||
| 5 | √ | √ | 86.6 | 81.5 | 71.6 | 66.7 | |||
| 6 | √ | √ | √ | 87.2 | 81.9 | 72.2 | 67.1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, J.; Wu, C.; Yang, S. Object-Tracking Algorithm Combining Motion Direction and Time Series. Appl. Sci. 2023, 13, 4835. https://doi.org/10.3390/app13084835
Su J, Wu C, Yang S. Object-Tracking Algorithm Combining Motion Direction and Time Series. Applied Sciences. 2023; 13(8):4835. https://doi.org/10.3390/app13084835
Chicago/Turabian StyleSu, Jianjun, Chenmou Wu, and Shuqun Yang. 2023. "Object-Tracking Algorithm Combining Motion Direction and Time Series" Applied Sciences 13, no. 8: 4835. https://doi.org/10.3390/app13084835