1. Introduction
Language stands as one of humanity’s most remarkable accomplishments and has been a driving force in the evolution of human society. Today, it is an indispensable component of both our professional and social lives. Dialogue, as a term [
1], refers to interactive communication between two or more individuals or groups in the context of human language. It is a two-way intentional communication that can take on spoken or written forms. Language assumes a prominent role, especially in the context of cybersecurity and social engineering, as malicious users employ it to deceive and manipulate unsuspecting individuals. Among various social engineering attacks, chat-based social engineering is recognized as a critical factor in the success of cyber-attacks, particularly in small and medium-sized enterprise (SME) environments. This type of attack is attracting increasing attention due to its potential impact and ease of exploitation. According to Verizon’s 2022 [
2] report, the human element is a significant factor in driving 82% of cybersecurity breaches.
During a CSE attack, malicious users utilize linguistic manipulation to deceive their targets by exploiting human personality traits and technical misconfigurations. From a strategic standpoint, it is more effective [
3] to isolate individual CSE attack enablers and investigate detection methods for each enabler separately. In a chat-based dialogue, such as one between an SME employee and a potential customer, interlocutors communicate through written sentences. The ability to identify one or more characteristics that can reveal the malicious intent of an interlocutor can sufficiently safeguard the SME employee against potential CSE attacks. Dialogue act (DA) is a term used to describe the function or intention of a specific utterance in a conversation, and it has already been identified [
3] as one of the critical enablers of successful CSE attacks. As such, detecting dangerous DAs that may lead to a successful CSE attack is of paramount importance.
The widespread use of dialogue systems (such as Alexa and Siri) has led to a surge in research in this field. It is advantageous for us to transfer knowledge and terminology from this field to chat-based social engineering recognition tasks. The formalism used to describe these systems can facilitate the modeling of human-to-human conversations, especially CSE attacks, as both types of dialogues share common structural characteristics. Dialogue systems rely on dialogue-state tracking (DST) to monitor the state of the conversation. Similarly, in human-to-human dialogues and CSE attacks, the state of the dialogue can be tracked through the DST process, which in our case, is the state of the CSE attack. CSE attacks involve deception and manipulation in order to acquire sensitive information, such as an attacker posing as a trusted individual (e.g., a bank representative) to trick the victim into disclosing personal information. By using DST to track the dialogue state and identify when the attacker is attempting to extract sensitive information or deceive the victim, we can detect and prevent CSE attacks.
Leveraging the progress made in dialogue systems, we develop a system that performs CSE attack state tracking. The main component in the system’s architecture is a BERT-based model that is trained and fine-tuned to detect the intent of an interlocutor utilizing a multi-schema ontology and related dialogue acts. The main contributions of our work are as follows:
A set of dialogue acts in the CSE attack context, called SG-CSE DAs.
A corpus, called SG-CSE Corpus, annotated with SG-CSE-DAs appropriate for CSE attack state tracking model training.
A multi-schema ontology for CSE attacks, called SG-CSE Ontology.
A BERT-based model, called SG-CSE BERT, that follows the schema-guided paradigm for CSE attack state tracking fine-tuned with SG-CSE Corpus.
2. Related Work
In DST, the main tasks are the prediction of intention, requested slots, and slot values, and although there is no similar research applying DST tasks for the purpose of recognizing CSE attacks, we present related works that deal with DST tasks in single-domain or multiple domains.
Rastogi et al. [
4], introduce the Schema-Guided Dialogue dataset to face the challenges of building large-scale virtual assistants. They also present a schema-guided paradigm for task-oriented dialogue for predicting intents and slots using natural language descriptions. The Schema-Guided Dialogue corpus extends the task-oriented dialogue corpora by providing a large-scale dataset (16k+ utterances across 16 domains). Along with the novel schema-guided dialogue paradigm, a model is released that facilitates the dialogue-state tracking able to generalize to new unseen domains and services. This work, with its simplistic and clear approach, inspired our research.
Xu and Hu in [
5] suggest an approach that can track unknown slot values when Natural Language Understanding (NLU) is missing, which leads to improvements in state-of-the-art results. Their technique combined with feature dropout extracts unknown slot values with great efficiency. The described enterprise-to-enterprise architecture effectively predicts unknown slot values and errors, leading to state-of-the-art results on the DSTC2 benchmark. The addition of a jointly trained classification component that is combined with the pointer network forms an efficient hybrid architecture. This work presents a different perspective as to what can be important for unknown slot prediction and how we can approach a solution.
Chao and Lane, in [
6], build on BERT to learn context-aware dialogue-state tracking for scaling up to diverse domains with an unknown ontology. They propose a new end-to-end approach for scalable context-based dialogue-state tracking that uses BERT in sentence-level and pair-level representations. The proposed BERT-DST is an end-to-end dialogue-state tracking approach that directly utilizes the BERT language model for slot value identification, unlike prior methods, which require candidate generation and tagging from n-gram enumeration or slot taggers. The most important module is the BERT dialogue context encoding module, which produces contextualized representations to extract slot values from the contextual patterns. The empirical evaluation of SimM and Sim-R datasets showed that the proposed BERT-DST model was more efficient in utilizing the slot value dropout technique and encoder parameter sharing. The authors’ approach to extracting slot values with an unknown domain ontology is important. Furthermore, the BERT architecture is inspiring and helped us design our model.
Deriu et al. [
7], summarize the state of evaluation techniques of dialogue systems. They use a classification of dialogue systems that leads to an equally effective classification of evaluation methods. Thus, they easily comment on each evaluation method focusing on those that lead to a reduction in the involvement of human labor. In their survey paper, they compare and contrast different evaluation measures across the various classes of dialogue systems (task-oriented, conversational, and question-answering dialogue systems)—a useful review that presents the modern state of dialogue systems’ evaluation techniques and helps to foresee the trends.
Xiong et al. [
8], propose an approach to process multi-turn dialogues based on the combination of BERT encoding and hierarchical RNN. The authors propose a domain-independent way to represent semantic relations among words in natural language using neural context vectors. The proposed MSDU model is able to recognize intents, dialogue acts, and slots utilizing the historical information of a multi-turn dialogue. The test results using multi-turn dialogue datasets Sim-R and Sim-M showed that the MSDU model was effective and brought about a 5% improvement in FrameAcc compared with models such as MemNet and SDEN.
Zhao et al. [
9], propose a schema description-driven dialog system, D3ST, which uses natural language descriptions instead of names for dialog system variables (slots and intents). They present a schema description-driven dialogue system that produces a better understanding of task descriptions and schemas, leading to better performance. Measured on the MultiWOZ, SGD, and SGD-X datasets, they demonstrate that the approach can lead to better results in all areas: quality of understanding, learning data efficiency, and robustness. Their approach differentiates between schema names and schema descriptions and recommends using natural language descriptions. This work nicely presents the flexibility that we can get using different schemas.
Ma et al. [
10], propose an end-to-end machine reading comprehension for non-categorical slots and a Wide & Deep model for a categorical slot DST system, achieving state-of-the-art performance on a challenging zero-shot task. Their system, which is an end-to-end machine reading comprehension (MRC) model for the task Schema-Guided Dialogue-State Tracking, employs two novel techniques to build a model that can accurately generate slots in a user turn, with state-of-the-art performance in the DSTC 8 Track 4 dataset. This work introduces RoBERTa as a classification model for intent recognition and slot recognition.
Kim et al. [
11], propose a novel paradigm to improve dialogue-state tracking that focuses on the decoder analyzing changes to memory rather than on determining the state from scratch. They use an explicitly available memory for dialogue-state tracking to improve state operations prediction and accuracy. The proposed Selectively Overwriting Memory (SOM) is a general method to improve dialogue-state tracking (DST). Initial experiments showed improved performance on open vocabulary tasks. This work presents an approach where the initial problem definition is changed to fit the proposed solution.
Kumar et al. [
12], propose an architecture for robust, dialogue-state tracking using deep learning, demonstrating improved performance over the state-of-the-art. They introduce a novel model architecture for dialogue-state tracking using attention mechanisms to predict across different granularities to better handle long-range cross-domain dependencies. The proposed model employs attention mechanisms to encode information from both the recent dialogue history and from the semantic level of slots. The proposed approach is a cross-attention-based model that performs coreference resolution and slot filling in a human-robot dialogue to address complex multi-domain dialogues.
In [
13], Lin et al. propose a slot-description-enhanced generative approach for zero-shot cross-domain dialogue-state tracking. They efficiently learn slot-to-value mapping and jointly learn generalizable zero-shot descriptions. They demonstrate improved performance on multimodal question answering and multi-agent dialogues. The generative framework introduced for zero-shot cross-domain dialogue-state tracking significantly improves the existing state-of-the-art for DST. Their approach helps the design and evaluation of dialogue systems for tasks that require entities to communicate about unseen domains or multiple domains.
Lin et al. [
14], propose TransferQA, which transfers cross-task dialogue knowledge from general question answering to dialogue-state tracking. The TransferQA is a generative QA model that learns a transferable, domain-agnostic QA encoder for handling question-answering tasks. TransferQA is a general framework that transfers knowledge from existing machine learning models, particularly the more challenging zero-shot scenarios. Negative question sampling and context truncation techniques were introduced to construct unanswerable questions,
Li et al. [
15], propose a simple syntax-aware natural language generation as a general way to perform slot inference for dialogue-state tracking, achieving a new state of the art on MultiWOZ 2.1. They present a language-independent approach for tracking slot values in task-oriented dialogues, making it possible to add a domain to an existing system (as used in the Alice personal assistant). They offer a generative, end-to-end architecture for dialogue-state tracking that only needs domain-specific substantive examples. They propose contextual language models, not built from ontologies, for determining the domains in which a multi-domain task-oriented dialogue is occurring.
3. Background
3.1. Dialogue Systems
According to Dan Jurafsky [
16], human-to-human dialogues possess several properties. A crucial structural attribute is a turn, which is a singular contribution made by one speaker in the dialogue. A full dialogue comprises a sequence of turns. For instance, in
Table 1, two interlocutors identified as V(ictim) and A(ttacker) exchange utterances in a small six-turn dialogue excerpted from the CSE corpus [
17]. One or more utterances from the same speaker can be grouped into a single turn. Typically, an utterance from speaker V is followed by a response from speaker A, constituting an exchange. A dialogue consists of multiple exchanges.
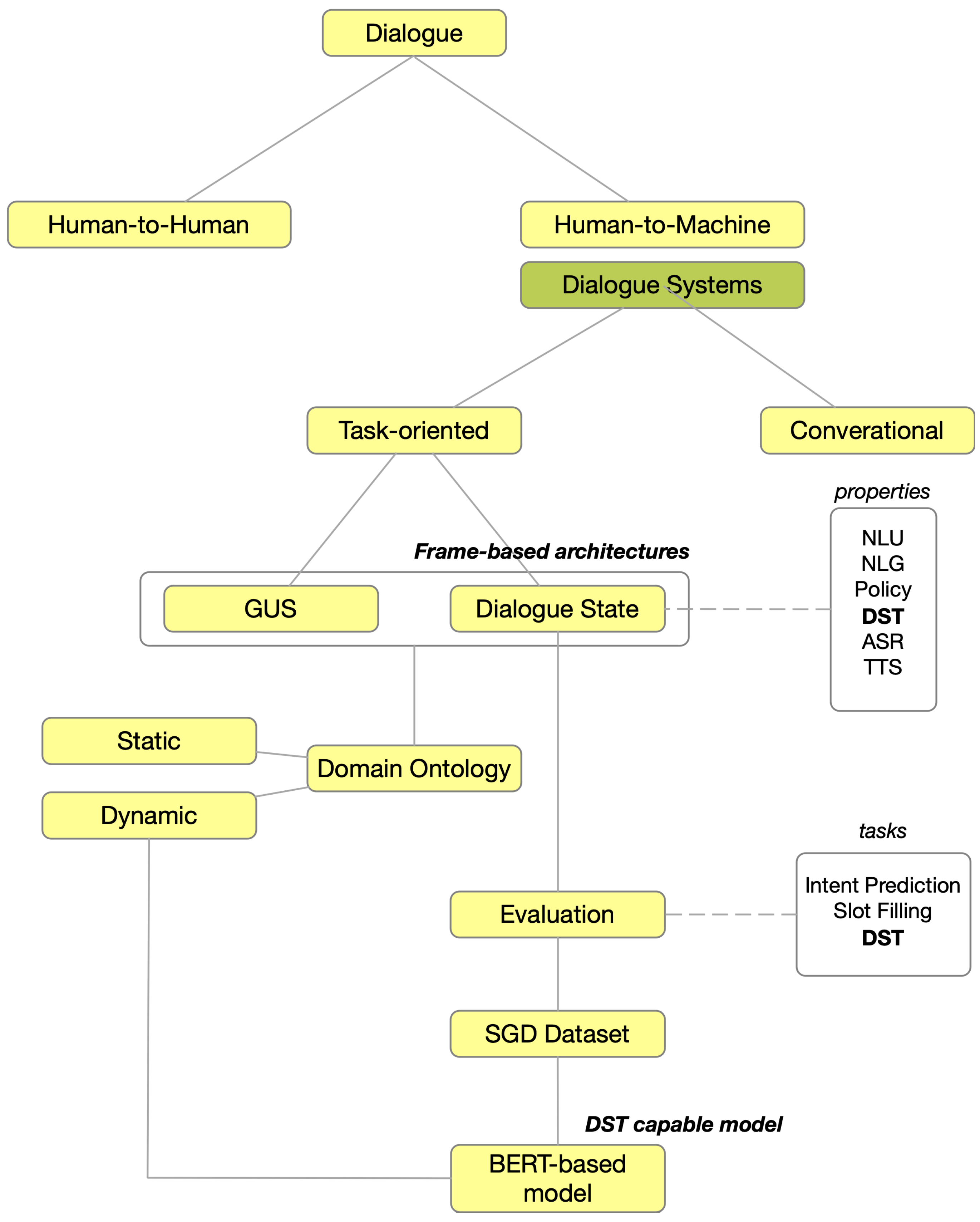
Nowadays, a dialogue can be conducted between humans or between a machine and a human, and the latter is named a dialogue system. Dialogue systems communicate with humans in natural language, both spoken and written, and can be classified as:
Task-based systems can be further classified, based on their architecture, into systems that use:
The primary objective of dialogue systems when interacting with a human is to elicit three key pieces of information from the user’s utterance: domain classification, user intention, and requested information. Domain classification pertains to the conversation’s context and can be determined through the use of a domain ontology. To ensure proper interpretation and response to user input, a formal representation of the knowledge that a conversational system must comprehend must exist. This knowledge comprises concepts and entities mentioned in the conversation, the relationships between them, and the potential dialogue states, which are encapsulated in the domain ontology. Dialogue systems rely on ontologies to link the user’s input to the corresponding concepts and entities, as well as to monitor the current dialogue state. By tracking the state of the conversation and the user’s objectives, the system can generate more precise and pertinent responses. The domain ontology can be defined by means of a static schema, where the dialogue system operates within a single domain, or a dynamic schema, where the dialogue system is capable of operating within multiple domains. In this context, the schema represents a framework or structure that defines the arrangement of data. Typically, a dialogue system consists of the following units:
Natural Language Understanding (NLU) unit, which uses machine learning to interpret the user’s utterance.
Dialogue-State Tracking (DST) unit, which maintains the entire history of the dialogue.
Dialogue Policy unit, which defines a set of rules to drive the interactions between the user and the system.
Natural Language Generation (NLG), which generates responses in natural language.
Text-to-Speech unit, which transforms text to speech.
Automated Speech Recognition unit, which transforms speech into text.
3.2. Dialogue Acts
The Speech Act theory, introduced by Austin [
19] and Searle [
20,
21] in the 1960s, has become a widely used concept in linguistics and literature studies. Today, the modern notion of speech act [
22] has found applications in diverse fields such as ethics, epistemology, and clinical psychology [
23]. Dialogue Acts (DAs) are a type of Speech Act that represents the communicative intention behind a speaker’s utterance in a dialogue. Hence, identifying the dialogue acts of each speaker in a conversation is an essential initial step in automatically determining intention.
The Switchboard-1 corpus [
24], which consists of telephone speech conversations, was one of the first corpora related to dialogue and dialogue acts. It contains approximately 2400 two-way telephone conversations involving 543 speakers. The Switchboard Dialogue Act Corpus (SwDA) [
25,
26] extended the Switchboard-1 corpus with tags from the SWBD-DAMSL tagset [
27]. The SWBD-DAMSL tagset was created by augmenting the Discourse Annotation and Markup System of Labelling (DAMSL) tagset. Through clustering, 220 tags were reduced to 42 tags to improve the language model for the Switchboard corpus. The resulting tags include dialogue acts such as statement-non-opinion, acknowledge, statement-opinion, and agree/accept, among others. The size of the reduced set has been a matter of debate, with some studies [
28,
29,
30] using a 42-label set while others have used the most commonly used four-class classification.
Constatives: committing the interlocutor to something’s being the case.
Directives: attempts by the interlocutor to get the addressee to do something.
Commissives: committing the interlocutor to some future course of action.
Acknowledgments: express the interlocutor’s attitude regarding the addressee with respect to some social action.
Thus, we can think of DAs as a tagset that can be used to classify utterances based on a combination of pragmatic, semantic, and syntactic criteria.
3.3. Schema-Guided Paradigm
Rastogi et al. [
4] proposed a novel approach named schema-guided dialogue to facilitate dialogue-state tracking by using natural language descriptions to define a dynamic set of service schemata. A schema-guided ontology is an ontology that characterizes the domain and is confined by a specific schema or set of schemas. In this context, a schema specifies the organization of the data and the associations between the concepts and entities that are expected to be present in the dialogue. A frame is a data structure that represents the current state of the dialogue at a specific time point. It is comprised of key-value pairs, where the keys represent the entities and concepts that are relevant to the conversation, and the values represent the corresponding values of these concepts. Typically, a frame corresponds to a specific schema or set of schemas, and it can be updated as the dialogue progresses. For instance, in a restaurant booking system, a frame may contain information such as the date and time of the reservation, the number of diners, and the desired cuisine type. In the schema-guided paradigm, frames are predetermined, and the system anticipates the user’s input to conform to one of the predefined frames. Although this approach can improve the robustness and accuracy of the dialogue system by providing a structured and domain-specific representation of knowledge, it also limits the flexibility of the system to handle novel and unforeseen input. A frame is typically comprised of the following components:
Intents: represent the goal of the interlocutor; they define the task or action that the dialogue system is trying to accomplish.
Slots: represent the information that is being requested or provided; they describe the properties of the entities or concepts that are relevant to the task.
Slot values: represent the value of the slots; they are the actual information that has been extracted or provided during the conversation.
Dialogue history: represents the conversation so far; it includes all the previous turns of dialogue in the current conversation.
Constraints: represent the additional information that is useful for the task; they are used to guide the dialogue towards a successful outcome.
3.4. Dialogue-State Tracking (DST)
Dialogue-state tracking [
31] is the process of maintaining an accurate representation of the current state of a conversation. This involves identifying the user’s intentions and goals, as well as the entities and concepts that are mentioned in the conversation, in order to provide relevant and precise responses. To tackle the challenge of representing the dialogue state, Young et al. [
32] proposed a method that leveraged dialogue acts. They employed a partially observable Markov decision process (POMDP) to build systems that could handle uncertainty, such as dialogue systems. To achieve a practical and feasible implementation of a POMDP-based dialogue system, the state can be factorized into discrete components that can be effectively represented by probability distributions over each factor [
33]. These factorized distributions make it more feasible to represent the most common slot-filling applications of POMDP-based systems, where the complete dialogue state is reduced to the state of a small number of slots that require filling.
In 2020, Rastogi et al. [
4] proposed the schema-guided paradigm to tackle dialogue-state tracking, which involved predicting a dynamic set of intents and slots by using their natural language descriptions as input. They also introduced a schema-guided dataset to evaluate the dialogue-state tracking tasks of dialogue systems, including domain prediction, intent prediction, and slot filling. Additionally, they developed a DST model capable of zero-shot generalization. The schema-guided design utilizes modern language models, such as BERT, to create a unified dialogue model for all APIs and services by inputting a service’s schema, which enables the model to predict the dynamic set of intents and slots within the schema. This approach has gained significant attention, and annual competitions, such as the Dialogue Systems Technology Challenge (DSTC), track the progress in this field [
34].
To achieve slot filling, a sequence model can be trained using different types of dialogue acts as classification labels for each individual domain. Additionally, pretrained language models, such as GPT [
35], ELMo [
36], BERT [
37], and XLNet [
38], have shown significant promise in recent years with regards to natural language processing. These models have outperformed prior algorithms in terms of generalization and zero-shot learning. Consequently, they offer an effective approach to performing zero-shot learning for language understanding. Furthermore, by leveraging pretrained language models in the schema-guided paradigm, dialogue systems can generalize to unseen service schema elements and improve their accuracy and robustness.
The primary objectives of dialogue-state tracking (DST) encompass predicting the active user intention, requested slots, and values of slots in a given conversation turn. Within the context of DST, the user intention closely relates to the service supplied by the dialogue system. The intention refers to the user input’s purpose or goal, while the service represents the functionality offered by the dialogue system to achieve the user’s intent. The user’s intention is typically deduced from the input and ongoing conversation state and can be expressed as a label or a set of labels that indicate the user’s objective. A service denotes the task or action the dialogue system intends to perform and can be defined by a group of intentions and slots. The slots indicate the requested or supplied information. For example, an intention might involve “booking a flight,” while the slots could consist of “destination,” “departure date,” “return date,” and other related information. Services may vary over time, making it critical to have a flexible and adaptable ontology that can be modified as required.
DST’s capacity to handle either a closed set of slots (static ontology) or an open set of slots (dynamic ontology) is a crucial attribute. In the former, the model is capable of predicting only those predefined slot values and cannot assimilate new slot values from example data. The model generally comprises three modules: an input layer that translates each input token into an embedding vector, an encoder layer that encodes the input to a hidden state, and an output layer that predicts the slot value based on the hidden state. In the former, where the set of possible slot values is predefined, the output layer may be approached in two ways: (i) a feed-forward layer that generates all possible values associated with a specific slot; or (ii) an output layer that contrasts both the input representation and slot values and provides scores for each slot value. The scores can be normalized by applying non-linear activation functions, such as SoftMax or sigmoid, to convert them into probability distributions or individual probabilities.
In DST, the zero-shot setting enables a model to handle new intents or slots that it has not seen before without requiring additional training data. This allows the model to generalize to new contexts or situations based on the knowledge gained during training. Unlike traditional supervised learning approaches, where a DST model is trained on a specific dataset with a specific set of intents and slots, a zero-shot DST model can handle new intents and slots without prior exposure. Techniques such as transfer learning, pre-training, or meta-learning can be used to achieve this goal and learn a more general and robust model. For instance, a zero-shot DST model can utilize pre-trained language models or embeddings, which have already learned significant knowledge about language from a large corpus of text data. The model can then be fine-tuned on a smaller dataset specific to the DST task at hand.
4. The Proposed SG-CSE Attack State Tracker
4.1. Description
We propose the SG-CSE Attack State Tracker (SG-CSEAST), a system that estimates the dialogue state during a CSE attack state by predicting the intention and slot-value pairs at turn
of the dialogue. The SG-CSEAST consists of the following four units depicted in
Figure 1.
NLU: converts the utterances into a meaningful representation.
SG-CSE BERT: takes into account the dialogue history, and outputs the estimated state of the CSE attack.
CSE Policy: decides which mitigation action to take.
Mitigation Action: applies the selected mitigation action.
In this work, we implement the SG-CSE BERT unit, which detects information leakage and deception attempts. The information concerns SME, Information Technology (IT), and personal details, while in our context, we define deception as the attempt of a malicious user to persuade a user to use an IT resource. We follow the schema-guided paradigm utilizing Das and dialogue history. The steps toward SG-CSE BERT implementation are the following (
Figure 2):
The schema-guided paradigm makes use of a domain’s ontology to create the required schema that describes each service existing in the domain. In our research, the domain is the CSE attacks, and we predict the service, user intention, and requested slot-value pairs. For example, for an utterance like: “What is the CEO’s first name?” the SG-CSE BERT model should be able to build a representation like the one presented in
Table 2.
A CSE attack is unleashed through the exchange of utterances in turns of a dialogue. Time is counted in turns, and thus at any turn
, the CSE attack is at the state
and this state comprises the summary of all CSE attack history until time
. State
encodes the attacker’s goal in the form of (slot, value) pairs. The different slot and value pairs are produced by the CSE ontology [
17] and the proposed DAs that represent the in-context entities, intents, and their interconnection. The values for each slot are provided by the attacker during the CSE attack and represent her goal, e.g., during a CSE attack, at turn
the state
could be
In such a state, the attacker’s goal has been encoded for slots
during the dialogue.
Figure 3 depicts the dialogue system concepts and evolution that are related to our research and the concepts transferred from the dialogue systems field to the CSE attack domain for the purpose of CSE attack recognition via CSE attack-state tracking. As
Figure 3 depicts, a dialogue can be realized between humans or between humans and machines. The latter is called dialogue systems and can be task-oriented or conversational. The architecture of dialogue systems can be described using frames, and among their properties, dialogue-state tracking is a property that represents the state of the dialogue at any given moment. The schema is created based on the SG-CSE domain ontology, and we can perform prediction tasks using state-of-the-art language models such as BERT.
The SG-CSE BERT unit, as proposed, adheres to the schema-guided approach for zero-shot CSE attack state tracking by employing a fine-tuned BERT model. By taking various CSE attack schemas as input, the model can make predictions for a dynamic set of intents and slots. These schemas contain the description of supported intents and slots in natural language, which are then used to obtain a semantic representation of these schema elements. The use of a large pre-trained model such as BERT enables the SG-CSE BERT unit to generalize to previously unseen intents and slot-value pairs, resulting in satisfactory performance outcomes on the SG-CSE Corpus. The SG-CSE BERT unit is made up of two different components. A pre-trained BERT base cased model from Hugging Face Transformers to obtain embedded representations for schema elements, as well as to encode user utterances. The model is capable of returning both the encoding of the entire user utterance using the ‘CLS’ token, as well as the embedded representation of each individual token in the utterance, including intents, slots, and categorical slot values. This is achieved by utilizing the natural language descriptions provided in the schema files in the dataset. These embedded representations are pre-computed and are not fine-tuned during the optimization of model parameters in the state update module. The second component is a decoder that serves to return logits for predicted elements by conditioning on the encoded utterance. In essence, this component utilizes the encoded user utterance to make predictions regarding the user’s intent and the relevant slot values. Together, these various components comprise the SG-CSE BERT unit.
4.2. The SG-CSE Dialogue Acts
Given the inherent differences between CSE attack dialogues and standard dialogues, a carefully designed set of dialogue-act labels is necessary to meet the requirements of CSE attack recognition. These dialogue acts should be able to capture the intentions of the attacker while remaining easily understandable. To create a set of appropriate dialogue acts, the utterances of both interlocutors in the CSE corpus [
17] were analyzed, classified, and combined into pairs. Building on Young’s paradigm outlined in [
32], we propose a set of fourteen dialogue acts. Each SG-CSE DA is represented by an intent slot and has a data type and a set of values that it can take. The full list of the dialogue acts is presented in the following table (
Table 3). The percentage of each dialogue act frequency is also given in the last column for the total number of utterances in the SG-CSE Corpus.
The following
Table 4 contains examples of dialogue acts mapped to real word utterances from the SG-CSE Corpus.
4.3. The SG-CSE Corpus
The SG-CSE Corpus is a task-oriented dialogue corpus specifically designed for CSE attacks and is derived from the CSE corpus. Its main purpose is to serve as a training set for intent prediction, slot-value prediction, and dialogue-state tracking in the context of CSE attacks. The evaluation set of the SG-Corpus contains previously unseen services from the CSE domain, which allows us to evaluate the SG-CSE BERT model’s ability to generalize in zero-shot settings. The corpus comprises various types of CSE attacks, including real-life cases and fictional scenarios. The hybrid approach used to create the SG-CSE Corpus combines characteristics of both balanced and opportunistic corpora [
39,
40], and it is based on the schema-guided paradigm. The SG-CSE Corpus contains 90 dialogues and is presented in
Table 5.
The original CSE corpus was preprocessed, and all dialogues were converted into pairs of utterances and annotated. In order to enhance the corpus, we utilized paraphrasing techniques and replaced significant verbs and nouns to generate additional dialogues. More specifically, to address the potential limitations of a small corpus, we created a list of 100 critical nouns and 100 critical verbs categorized under one of three sensitive data categories, and for each noun and verb, we generated ten new sentences where the noun was substituted with a similar word. In this regard, we utilized the Word Embeddings technique, which utilizes dense vector representations to capture the meaning of words. The embeddings are learned by moving points in the vector space based on the surrounding words of the target word. To discover synonyms, we employed a pre-trained word2vec model based on the distributional hypothesis, which posits that linguistic items with similar contextual distributions have similar meanings. By grouping words with similar contextual distributions, we created a segregation of different domain words based on their vector values. This resulted in a vector space where each unique word in the dialogues was assigned a corresponding vector, representing a vector representation of the words in the collected dialogues. The critical verbs and nouns were replaced and combined to create new phrases. The following figure (
Figure 4) depicts the distribution of the number of turns in the dialogues involved.
Figure 5 presents the distribution of types of dialogue acts existing in the SG-CSE Corpus:
The annotation task has significantly enhanced the value and quality [
41] of the SG-CSE Corpus, allowing it to be utilized for task-oriented dialogue tasks, such as DST. Additionally, natural language descriptions of the various schema elements (i.e., services, slots, and intents) are included in the corpus. To test the zero-shot generalization ability, the evaluation set includes at least five services that are not present in the training set. The SG-CSE Corpus is composed of CSE attack dialogues between two interlocutors, where each dialogue pertains to a specific CSE attack service in the form of a sequence of turns. Each turn is annotated with the active intent, dialogue state, and slot spans for the different slot values mentioned in the turn. The schema includes information such as the service name, the supported tasks (intents), and the attributes of the entities used by the service (slots).
4.4. The SG-CSE Ontology
The CSE ontology [
17] is an ontology that connects social engineering concepts with cybersecurity concepts and focuses on sensitive data that could be leaked from an SME employee during a chat-based dialogue. It is an asset-oriented ontology that was derived from the corresponding concept map [
17] depicted in
Figure 6. The sensitive data may pertain to SME, IT, or personal details.
The CSE ontology groups similar concepts in context to facilitate the hierarchical categorization of assets and is designed to be efficient for text classification tasks by limiting the depth to no more than three levels. It was created through a custom information extraction system that leveraged various text documents such as corporate IT policies, IT professionals’ CVs, and ICT manuals. An excerpt of the CSE ontology created in Protégé is illustrated in
Figure 7 below, along with the arc types.
The SG-CSE ontology comprises a collection of schemas that describe the CSE attack domain based on the CSE ontology and the proposed set of fourteen SG-CSE DAs [
42]. The use of a schema-based ontology enables a structured and domain-specific representation of knowledge, enhancing the robustness and accuracy of the detection task. This is achieved through the provision of predefined frames, encompassing predetermined entities and concepts, which the system can expect to encounter as input.
Table 6 presents the 18 slots existing in SG-CSE in tabular form with accompanying example values.
The services present in the training set are the following four:
where the slots related to each service are combinations of the aforementioned slots in
Table 6.
Figure 8 depicts an excerpt of the example schema for the CSE_SME_Info_Extraction service. The dots between the boxes denote that more slots and intents exist.
4.5. The SG-CSE BERT Model
This section introduces the SG-CSE BERT model, which operates in a schema-guided setting and can condition the CSE attack service schema using the descriptions of intents and slots. To enable the model to represent unseen intents and slots, a BERT-based model pre-trained on large corpora is employed. As a result, the proposed SG-CSE is a model for zero-shot schema-guided dialogue-state tracking in CSE attack dialogues. The SG-CSE BERT model encodes all schema intents, slots, and categorical slot values into embedded representations. Since social engineering attacks can take many forms, schemas may differ in their number of intents and slots. Therefore, predictions are made over a dynamic set of intents and slots by conditioning them on the corresponding schema embedding.
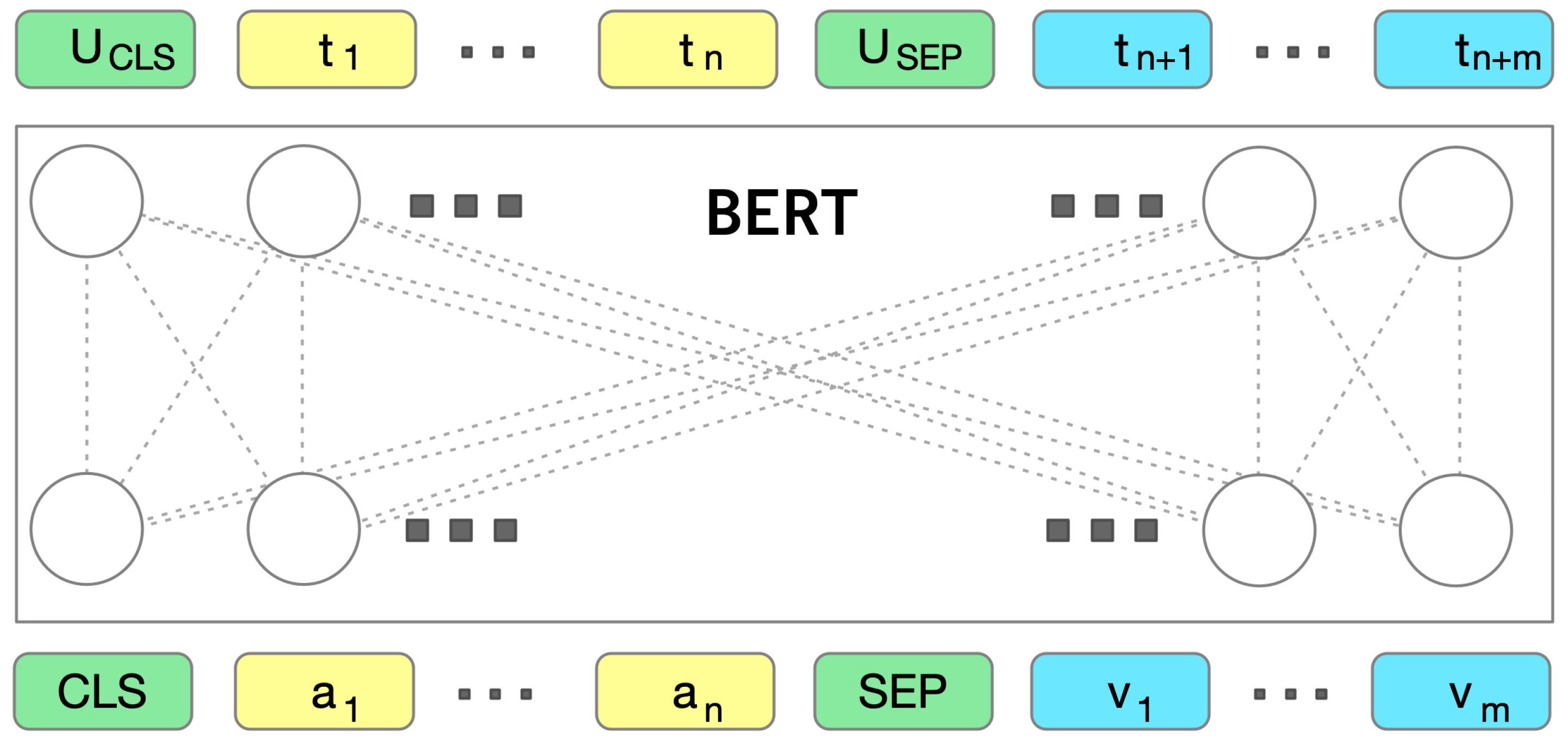
The sequence pairs used for the embeddings of intent, slot, and slot value are presented in
Table 7, and they are fed as input to the pre-trained BERT model (
Figure 9) where
and
are the two sequence tokens that are fed as a pair to SG-CSE BERT encoder. The
is the embedded representation of the schema and
are the token-level representations.
Schema Embeddings: Let be the intents and slots of CSE attack service and where and where their embeddings. The embeddings of the non-categorical slots are denoted by where and the embeddings for all possible values that the categorical slot can take are denoted by where and . C is the number of categorical slots and .
Utterance Embedding: A pair of two consecutive utterances between the two interlocutors is encoded and represented to embeddings as and the token level representations where and M the total number of tokens in the pair of utterances.
The model utilizes the schema and utterance embeddings and a set of projections [
4] to proceed to predictions for active intent, requested slot, and user goal. More specifically, the
active intent, which is the intent requested by the attacker that we are trying to recognize, takes the value ‘NONE’ if the model currently processes no intent. Otherwise, if
is the trainable parameter in
then the intent is given by:
SoftMax function is used to normalize the logits are normalized and produce a distribution over the set of intents plus the “NONE” intent. The intent with the highest probability is predicted as active.
The
requested slots, which means the slots whose values are requested by the user in the current utterance, are given by:
The sigmoid function I is used to normalize the logits and get a score in the range of [0, 1]. During inference, all slots with a score > 0.6 are predicted as requested.
The
user goal is defined as the user constraints specified over the dialogue context till the current user utterance, and it is predicted in two stages. In the first stage, a distribution of size 3 denoting the slot status taking values
none,
harmless, and
current is obtained using:
If the status is predicted as
none, its value is assumed unchanged. If the predicted status is
harmless, then the slot gets the value
harmless. Otherwise, the slot value is predicted using the following:
The SoftMax algorithm is used to map the categorical values of a variable into a distribution over the entire range of possible values. For each non-categorical slot, logits are obtained using the following:
Each of these two distributions above represents the starting and end points for the actual span of text that references the specific slot. The indices maximizing will be the boundary between spans, and the value associated with that span is assigned to that slot.
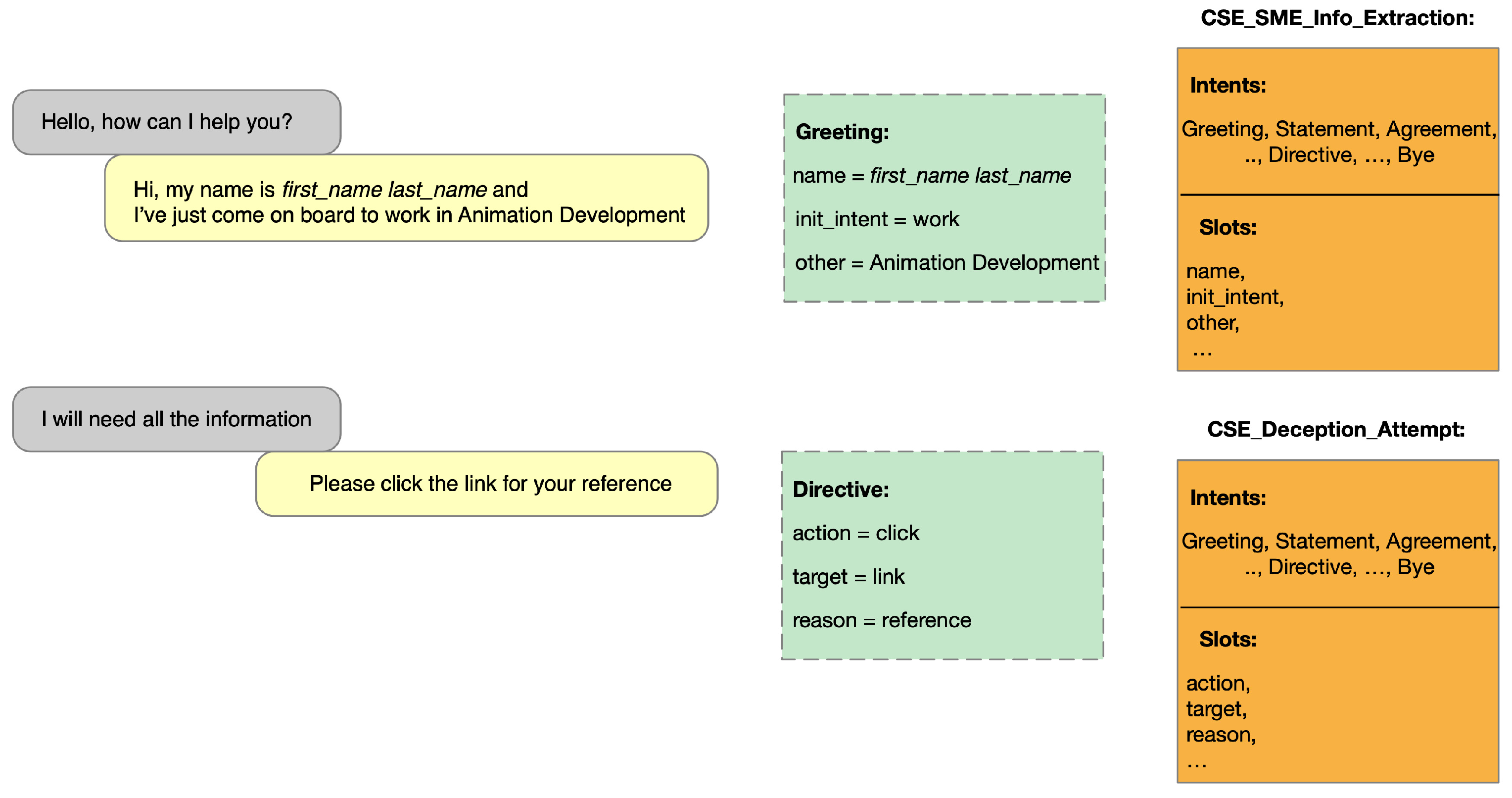
In
Figure 10 above, we see the predicted CSE attack dialogue state using two turns from two different utterance pairs. In the green boxes, the active intent and slot assignments are shown, and in the orange box, we can see the related schema of the CSE attack service. The CSE attack state representation is conditioned on the CSE attack schema, which is provided as input along with the victim and attacker utterances.
5. Results
We consider the following metrics for evaluation of the CSE attack state tracking:
Active Intent Accuracy: The fraction of user turns for which the active intent has been correctly predicted.
Requested Slot F1: The macro-averaged F1 score for requested slots overall eligible turns. Turns with no requested slots in ground truth and predictions are skipped.
Average Goal Accuracy: For each turn, we predict a single value for each slot present in the dialogue state. This is the average accuracy of predicting the value of a slot correctly.
Joint Goal Accuracy: This is the average accuracy of correctly predicting all slot assignments for a given service in a turn. Additionally, Harmonic means between seen and unseen classes.
We implemented the SG-CSE BERT model using the Hugging Face library and the BERT uncased model with 12 layers, 768 hidden dimensions, and 12 self-attention heads. To train the model, we used a batch size of 32 and a dropout rate of 0.2 for all classification heads. We also employed a linear warmup strategy with a duration of 10% of the training steps, in addition to the AdamW optimizer with a learning rate of 2 × 10−5.
In
Figure 11, the performance of the SG-CSE BERT model is depicted. SG-CSE BERT shows efficiency in Active Intent Accuracy and Requested Slots F1 and less efficiency in Average Goal Accuracy and Joint Goal Accuracy.
The following
Table 8 presents the performance results.
6. Discussion
Early dialogue-state tracking (DST) datasets were developed to be specific to a particular domain due to the difficulty in building models that can effectively track dialogue states for multiple domains. However, with the recent release of multi-domain datasets and the incorporation of machine learning-based methods, it has become possible to build models that can track states for multiple domains using a single set of training data. To evaluate the ability of models to generalize in zero-shot settings, we created the SG-CSE Corpus and included evaluation sets containing unseen services. To address the issue of limited dialogue resources, data augmentation can be explored as an option. Augmenting the training dataset by adding more diverse examples can improve performance. Source-based augmentation generates sentences by changing a single variable value in a sample utterance, while target-based augmentation takes portions of sentences from different places in the training data and recombines them.
SG-CSE BERT is a model that is built around BERT, a pre-trained transformer-based model that has been trained on a large corpus of text data. BERT has demonstrated strong generalization ability across a wide range of natural language processing tasks and domains. When fine-tuned on a specific task and domain, BERT is able to learn specific patterns and features of the task and domain, which allows it to achieve good performance. However, if BERT is not fine-tuned, it may be able to detect new unseen intents, but it would not have enough information to generate the corresponding slot values. Moreover, it may not be able to detect new unseen services or new unseen domains. Large-scale neural language models trained on massive corpora of text data have achieved state-of-the-art results on a variety of traditional NLP tasks. However, although the standard pre-trained BERT is capable of generalizing, task-specific fine-tuning is essential for achieving good performance. This is confirmed by recent research, which has shown that pre-training alone may not be sufficient to achieve high accuracy in NLP tasks. For example, the performance of a pre-trained model on a downstream task may be significantly improved by fine-tuning it on a smaller in-domain dataset.
The SG-CSE Corpus is designed to test and evaluate the ability of dialogue systems to generalize in zero-shot settings. The evaluation set of the corpus contains unseen services, which is important to test the generalization ability of the model. Our evaluation set does not expose the set of all possible values for certain slots. It is impractical to have such a list for slots like IP addresses or time because they have infinitely many possible values or for slots like names or telephone numbers for which new values are periodically added. Such slots are specifically identified as non-categorical slots. In our evaluation sets, we ensured the presence of a significant number of values that were not previously seen in the training set to evaluate the performance of models on unseen values. Some slots, like hardware, software, etc., are classified as categorical, and a list of all possible values for them is provided in the schema.
SG-CSE BERT is designed to handle dialogue-state tracking for a larger number of related services within the same domain. Its schema-guided paradigm provides a structured and domain-specific representation of knowledge, which increases the model’s robustness and accuracy. This, in turn, allows the system to better understand and interpret user input and track the dialogue state more accurately. The schema and frames work together to create this representation, with the schema constraining the possible states of the dialogue and the frames tracking the current state. The proposed system has shown satisfactory performance, and the experimental results demonstrate its effectiveness. Its simplistic approach also leads to more computational efficiency, which makes it a good candidate for use as a separate component in a holistic CSE attack recognition system, as proposed in previous works [
3,
43,
44]. Additionally, SG-CSE BERT is computationally efficient and scalable to handle large schemata and dialogues. It should be noted that the performance of SG-CSE BERT is dependent on the quality and completeness of the training data. Moreover, incorporating additional sources of information, such as user context and sentiment, can enhance the system’s performance in real-world scenarios. Overall, SG-CSE BERT provides a promising solution for zero-shot schema-guided dialogue-state tracking in the domain of CSE attack recognition.
A static ontology, which is a predefined and unchanging set of intents and slots, can be used for zero-shot detection in DST. However, there are some limitations to its effectiveness [
45]. While a comprehensive ontology can cover a wide range of possible situations and contexts, it may not be able to encompass all possible scenarios. As a result, a model trained on such an ontology may struggle to generalize to new and unseen intents and slots. Moreover, since the ontology remains static and is not updated during the training process, it may not be able to adapt to changes in the domain over time or new types of attacks. In contrast, a dynamic ontology can be updated during the training process to adapt to new situations and contexts. This can be achieved by using unsupervised methods to extract the ontology from the data or by incorporating active learning methods that allow the system to query human experts when encountering unseen intents and slots. By using a dynamic ontology, the system can learn to recognize new intents and slots over time, improving its ability to generalize to new and unseen scenarios. Zero-shot detection in DST remains an active area of research, with new methods and approaches being developed to improve the performance of DST models in detecting unseen intents and slots. By incorporating dynamic ontologies and other techniques, future DST models may be better equipped to recognize and respond to previously unseen user input.
7. Conclusions
The aim of this study was to investigate schema-guided dialogue-state tracking in the context of CSE attacks. We created a set of fourteen dialogue acts and developed the SG-CSE Corpus using the CSE ontology and corpus. We followed the schema-guided paradigm to introduce the SG-CSE BERT, a simplistic model for zero-shot CSE attack state tracking. The performance results were promising and demonstrated the effectiveness of the approach. To provide context for the study, we discussed dialogue systems and their characteristics, which helped us define our approach. Then, we examined how concepts and terminology from task-based dialogue systems and dialogue-state tracking can be transferred to the CSE attack domain.
We focused on creating the SG-CSE DAs and SG-CSE Corpus, mapping slots and intents, and proposing the SG-CSE BERT model. The model achieved satisfactory performance results using a small model and input encoding. Although various model enhancements were attempted, no significant improvement was observed. The study suggests that data augmentation and the addition of hand-crafted features could improve the performance of the CSE attack state tracking, but further experimentation is necessary to explore these methods. The proposed model offers an advantage in the few-shot experiments, where only limited labeled data is available. Such an approach can help to create a more comprehensive and accurate understanding of CSE attacks and their underlying mechanisms, as well as to develop more effective detection and prevention strategies. For example, experts in natural language processing can help to improve the performance of dialogue-state tracking models, while experts in psychology and sociology can provide insights into the social engineering tactics used in CSE attacks and the psychological factors that make users susceptible to these attacks. Cyber-security experts can provide a deeper understanding of the technical aspects of CSE attacks and help to develop more robust and effective defense mechanisms.
In addition, it is important to emphasize the need for ethical considerations in the development of CSE attack detection systems. As these systems involve the processing of sensitive and personal information, it is crucial to ensure that they are designed and used in a way that respects privacy and protects against potential biases and discrimination. This requires a careful and transparent design process, as well as ongoing monitoring and evaluation of the system’s performance and impact. Overall, a multi-disciplinary and ethical approach is essential for the development of effective and responsible CSE attack detection systems.
Future works will focus on the SG-CSE corpus augmentation techniques to present new CSE attack services. Furthermore, the proposed SG-CSE BERT will be incorporated into an ensemble system that will detect CSE attacks, where it will act as an individual component responsible for practicing dialogue-state tracking.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}