
Key News Event Detection and Event Context Using Graphic Convolution, Clustering, and Summarizing Methods

Abstract
:1. Introduction
2. Related Work
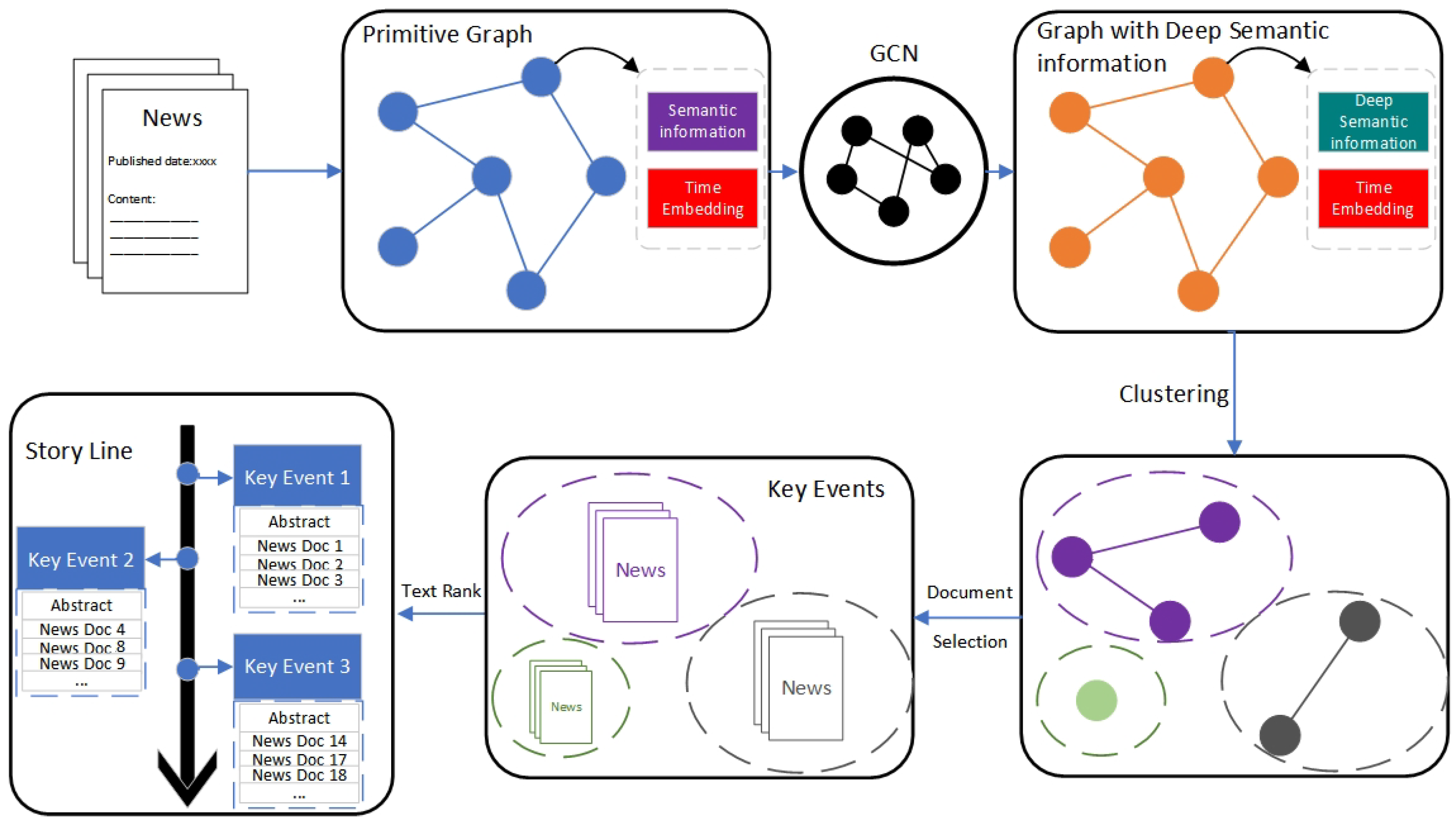
3. Methodology
3.1. Graph Construction Based on High-Quality Phrases
3.1.1. Semantic Embedding of High-Quality Phrases
3.1.2. Time Embedding of High-Quality Phrases
3.1.3. Graph Construction of High-Quality Phrases
3.2. Graph Optimization
3.2.1. GCN-Based Graph Node Optimization
3.2.2. Optimizing Graph Edges
3.3. Key Event Detection
3.4. Generation of Key Events Context
3.4.1. Abstract Generation
3.4.2. Identifying Event Context
| Algorithm 1 Extract Time Estimation |
| Input: Key Event K Output: Time Estimation T |
| 1. t_start ← MAX_TIME |
| 2. t_end ← MIN_TIME |
| 3. for d ← K do |
| 4. publish_time ← d.publish_time |
| 5. if publish_time < t_start do |
| 6. t_start ← publish_time |
| 7. end if |
| 8. if publish_time > t_end do |
| 9. t_end ← publish_time |
| 10. end if |
| 11. end for |
| 12. T ←(t_start, t_end) |
| 13. return T |
4. Experiments
4.1. Experiment Setup
4.2. Metrics
4.3. Experimental Results and Analysis
- Miranda et al. [26] can classify emerging documents into existing document clusters by training an SVM classifier.
- newsLens [27] clusters documents by processing several overlapped time windows.
- Staykovski et al. [28], which is a modification of newsLens.
- S-BERT [29] uses Sentence Transformers to obtain a vector representation of documents, which is then clustered by processing a time window.
- EvMine [7] clusters documents using graphs constructed from detected bursts of temporal peak phrases within a certain time range.
4.4. Ablation Study
4.5. Identifying the Event Context
4.6. Parameter Study
4.7. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hussain, T.; Muhammad, K.; Ullah, A.; Cao, Z.; Baik, S.W.; de Albuquerque, V.H.C. Cloud-assisted multiview video summarization using CNN and bidirectional LSTM. IEEE Trans. Ind. Inform. 2019, 16, 77–86. [Google Scholar] [CrossRef]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Goyal, P.; Kaushik, P.; Gupta, P.; Vashisth, D.; Agarwal, S.; Goyal, N. Multilevel Event Detection, Storyline Generation, and Summarization for Tweet Streams. IEEE Trans. Comput. Soc. Syst. 2020, 7, 8–23. [Google Scholar] [CrossRef]
- Salwen, Z.C.; Michael, B.; Garrison, B.; Driscoll, P.D. (Eds.) Communication Research Trends. In Online News and the Public; Routledge: London, UK, 2006; Volume 25, pp. 37–39. [Google Scholar]
- Yang, S.; Sun, Q.; Zhou, H.; Gong, Z.; Zhou, Y.; Huang, J. A topic detection method based on Key Graph and community partition. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; ACM: New York, NY, USA, 2018; pp. 30–34. [Google Scholar]
- Ge, T.; Pei, W.; Ji, H.; Li, S.; Chang, B.; Sui, Z. Bring you to the past: Automatic Generation of Topically Relevant Event Chronicles. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 575–585. [Google Scholar]
- Zhang, Y.; Guo, F.; Shen, J.; Han, J. Unsupervised Key Event Detection from Massive Text Corpora. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD’22), Washington, DC, USA, 14–18 August 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 2535–2544. [Google Scholar] [CrossRef]
- Xie, J.; Sun, H.; Zhou, J.; Qu, W.; Dai, X. Event Detection as Graph Parsing. In Findings of the Association for Computational Linguistics: ACL-IJCNLP, Online; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 1630–1640. [Google Scholar] [CrossRef]
- He, L.; Meng, Q.; Zhang, Q.; Duan, J.; Wang, H. Event Detection Using a Self-Constructed Dependency and Graph Convolution Network. Appl. Sci. 2023, 13, 3919. [Google Scholar] [CrossRef]
- Saravanakumar, K.K.; Ballesteros, M.; Chandrasekaran, M.K.; McKeown, K. Event-Driven News Stream Clustering using Entity-Aware Contextual Embeddings. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 2330–2340. [Google Scholar] [CrossRef]
- Sia, S.; Dalmia, A.; Mielke, S.J. Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too! In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 1728–1736. [Google Scholar] [CrossRef]
- Santos, J.; Mendes, A.; Miranda, S. Simplifying Multilingual News Clustering Through Projection From a Shared Space. arXiv 2022, arXiv:2204.13418. [Google Scholar] [CrossRef]
- Gaglio, S.; Re, G.L.; Moranam, M. A framework for real-time Twitter data analysis. Comput. Commun. 2016, 73, 236–242. [Google Scholar] [CrossRef]
- Brochier, R.; Guille, A.; Velcin, J. Inductive document network embedding with topic word attention. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Proceedings, Part I 42. Springer: New York, NY, USA, 2020; pp. 326–340. [Google Scholar]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10, 10008. [Google Scholar] [CrossRef]
- Guille, A.; Favre, C. Event detection, tracking, and visualization in Twitter: A mention-anomaly-based approach. Soc. Netw. Anal. Min. 2015, 5, 18–32. [Google Scholar] [CrossRef]
- Chen, Z.; Mukherjee, A.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. Discovering Coherent Topics Using General Knowledge. In Proceedings of the 22st ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013; pp. 209–218. [Google Scholar]
- Guzman, J.; Poblete, B. Online relevant anomaly detection in the Twitter stream an eficient bursty keyword delection mode. In Proceedings of the ACM SIGKDD Workshop on Outlier Detection and Description, Chicago, IL, USA, 11 August 2013; ACM: New York, NY, USA, 2013; pp. 31–39. [Google Scholar]
- Gu, X.; Wang, Z.; Bi, Z.; Meng, Y.; Liu, L.; Han, J.; Shang, J. Ucphrase: Unsupervised context-aware quality phrase tagging. arXiv 2021, arXiv:2105.14078. [Google Scholar] [CrossRef]
- Palangi, H.; Deng, L.; Shen, Y.; Gao, J.; He, X.; Chen, J.; Song, X.; Ward, R. Deep sentence embedding using long short termmemory networks: Analysis and application to information retrieval. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 696–707. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Q.; Song, L. Sentence-State LSTM for Text Representation. arXiv 2018, arXiv:1805.02474. [Google Scholar]
- Thomas, K.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Rada, M.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 15 January 2004; pp. 404–411. [Google Scholar]
- Miranda, S.; Znotins, A.; Cohen, S.B.; Barzdins, G. Multilingual Clustering of Streaming News. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4535–4544. [Google Scholar]
- Laban, P.; Hearst, M.A. newsLens: Building and visualizing long-ranging news stories. In Proceedings of the Events and Stories in the News Workshop, Vancouver, BC, Canada, 4 August 2017; pp. 1–9. [Google Scholar]
- Staykovski, T.; Barrón-Cedeño, A.; Da San Martino, G.; Nakov, P. Dense vs. Sparse Representations for News Stream Clustering. In Text2Story@ ECIR 2019; ACM: New York, NY, USA, 2019; pp. 47–52. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prec | Rec | Fmeas | |
|---|---|---|---|
| Miranda et al. [26] | 0.444 | 0.706 | 0.615 |
| newsLens [27] | 0.426 | 0.824 | 0.561 |
| Staykovski et al. [28] | 0.414 | 0.706 | 0.522 |
| S-BERT [29] | 0.508 | 0.836 | 0.631 |
| EvMine [7] | 0.829 | 0.682 | 0.748 |
| GCS | 0.986 | 0.706 | 0.824 |
| Prec | Rec | Fmeas | |
|---|---|---|---|
| EvMine [7] | 0.829 | 0.682 | 0.748 |
| GCS-NoGCN | 0.910 | 0.647 | 0.758 |
| Prec | Rec | Fmeas | |
|---|---|---|---|
| GCS-NoGCN | 0.910 | 0.647 | 0.748 |
| GCS | 0.986 | 0.706 | 0.824 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhang, Y.; Li, Y.; Chaomurilige. Key News Event Detection and Event Context Using Graphic Convolution, Clustering, and Summarizing Methods. Appl. Sci. 2023, 13, 5510. https://doi.org/10.3390/app13095510
Liu Z, Zhang Y, Li Y, Chaomurilige. Key News Event Detection and Event Context Using Graphic Convolution, Clustering, and Summarizing Methods. Applied Sciences. 2023; 13(9):5510. https://doi.org/10.3390/app13095510
Chicago/Turabian StyleLiu, Zheng, Yu Zhang, Yimeng Li, and Chaomurilige. 2023. "Key News Event Detection and Event Context Using Graphic Convolution, Clustering, and Summarizing Methods" Applied Sciences 13, no. 9: 5510. https://doi.org/10.3390/app13095510
APA StyleLiu, Z., Zhang, Y., Li, Y., & Chaomurilige. (2023). Key News Event Detection and Event Context Using Graphic Convolution, Clustering, and Summarizing Methods. Applied Sciences, 13(9), 5510. https://doi.org/10.3390/app13095510