
A Fine-Tuning Based Approach for Daily Activity Recognition between Smart Homes


Abstract
:1. Introduction
- (1)
- We found a network structure suitable for identifying sensor data streams in smart homes.
- (2)
- We performed a small data-based network model training on a public dataset [8] and obtained highly informative parameter metrics.
2. Related Work
2.1. Methods of Daily Activity Recognition Based on Heterogeneous Smart Home Environments
2.2. The Development Process of Fine-Tuning
2.3. Methods of Daily Activity Recognition Based on LSTM
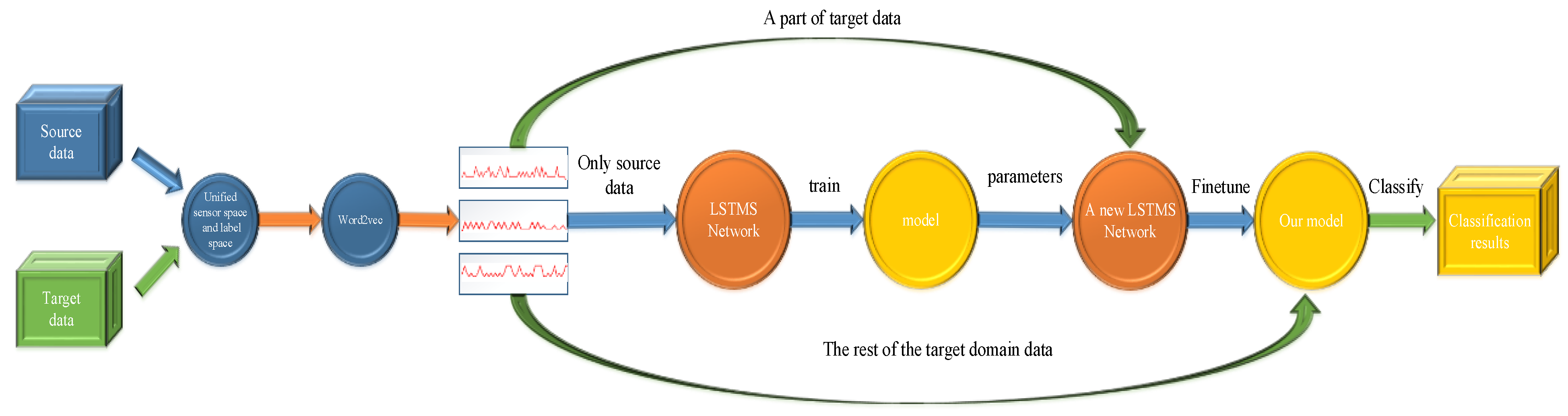
3. The Proposed Approach
3.1. Unify Sensor Space and Activity Space
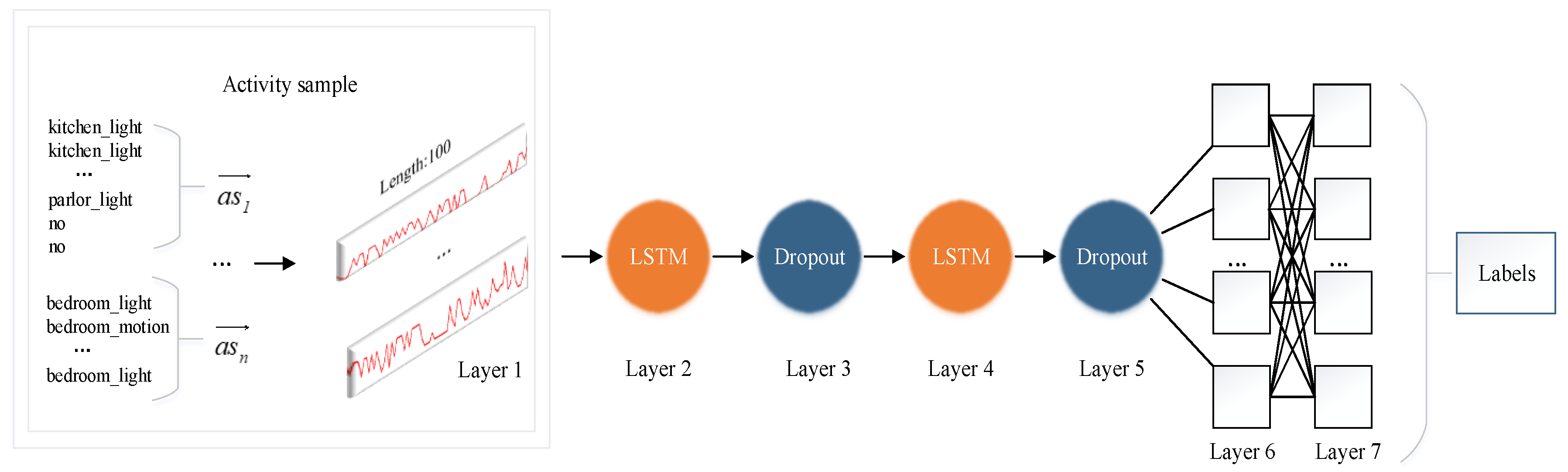
3.2. Network Structure
3.3. Fine-Tuning
4. Results and Evaluation
4.1. Smart Homes Datasets
4.2. Metrics
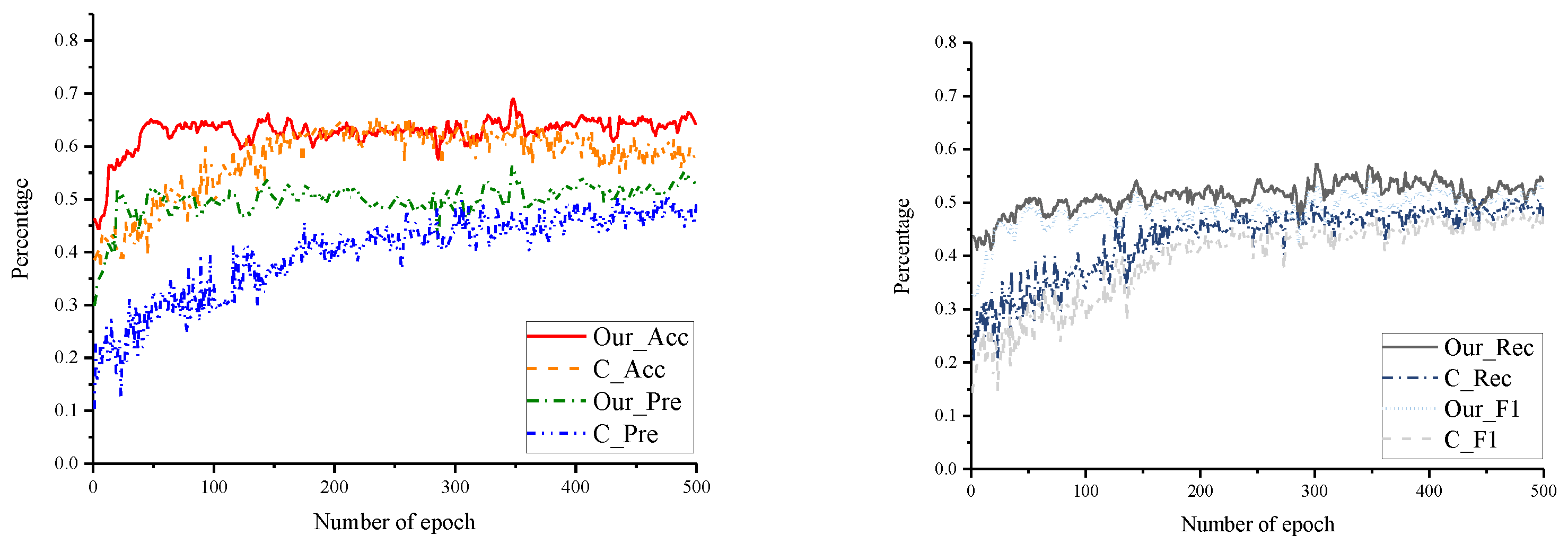
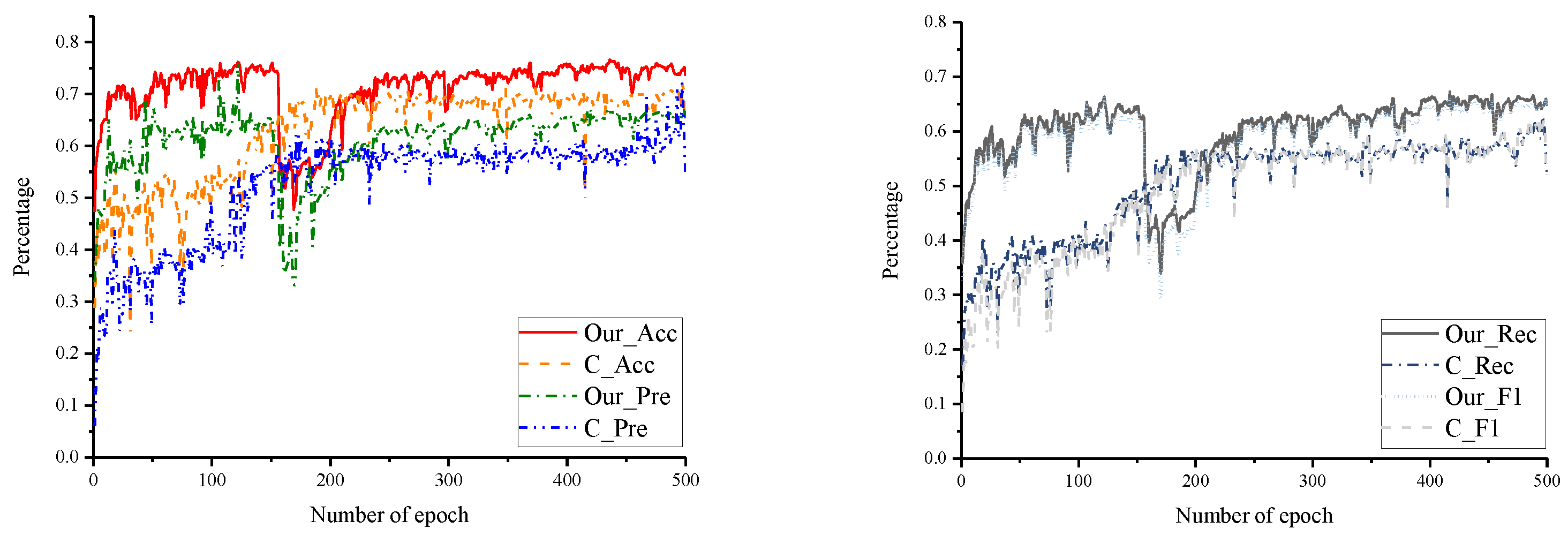
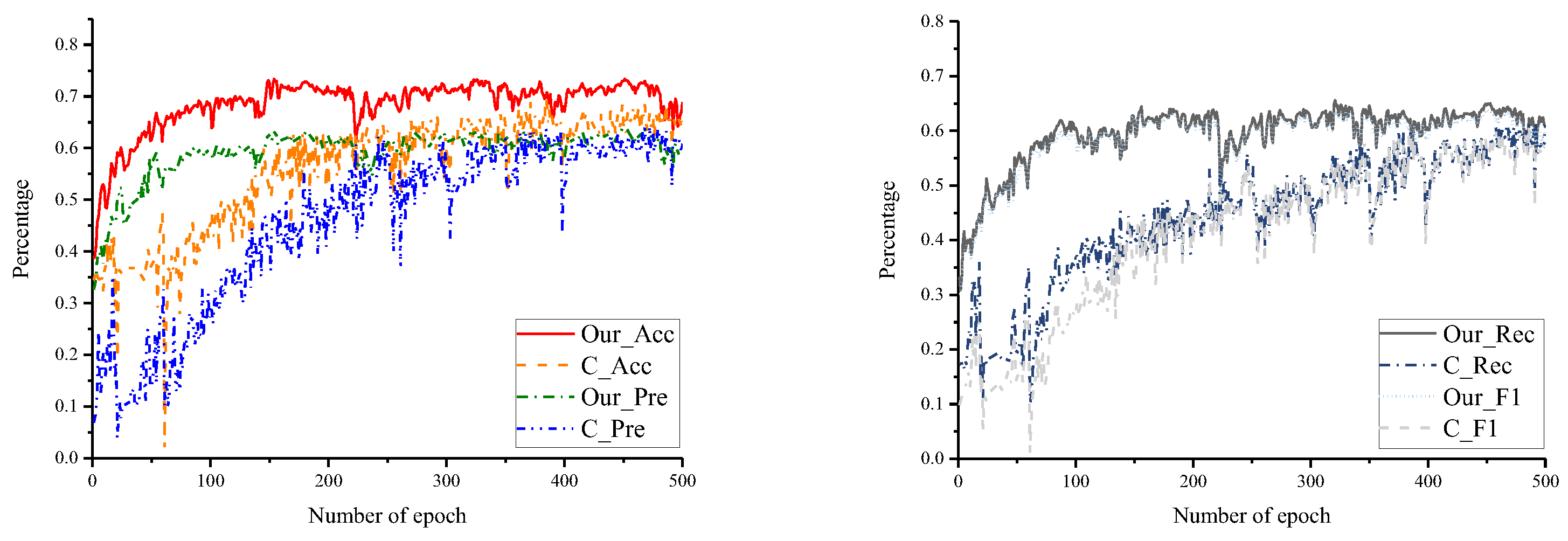
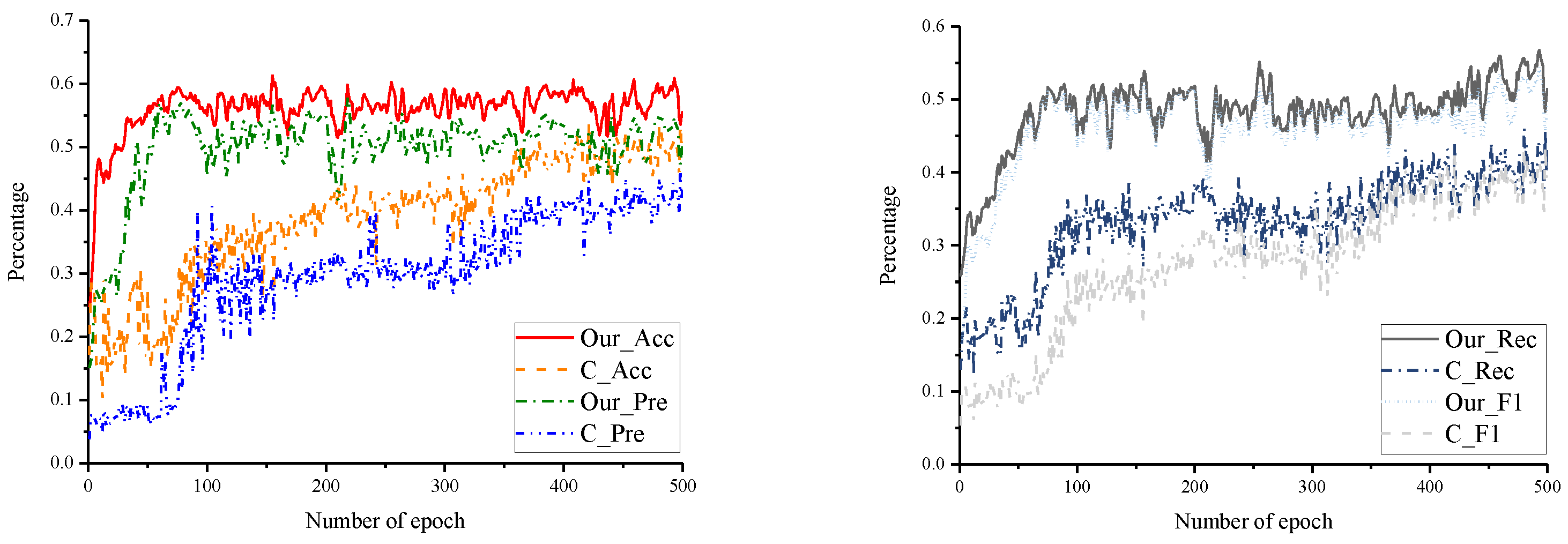
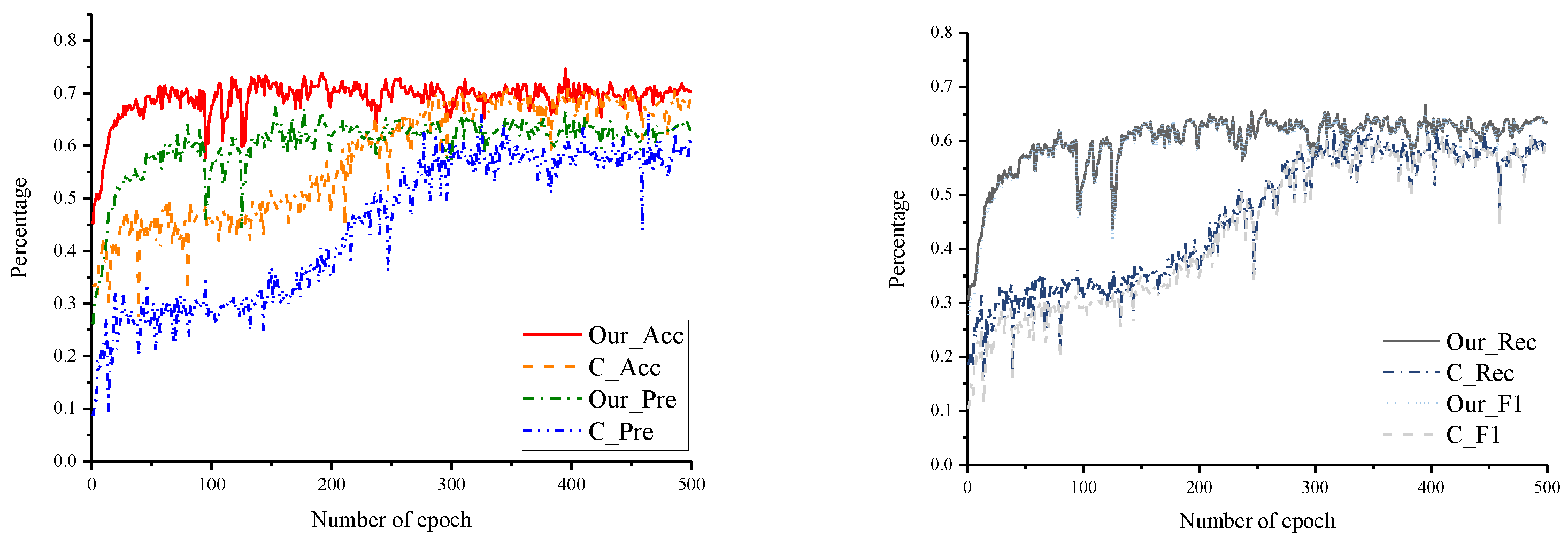
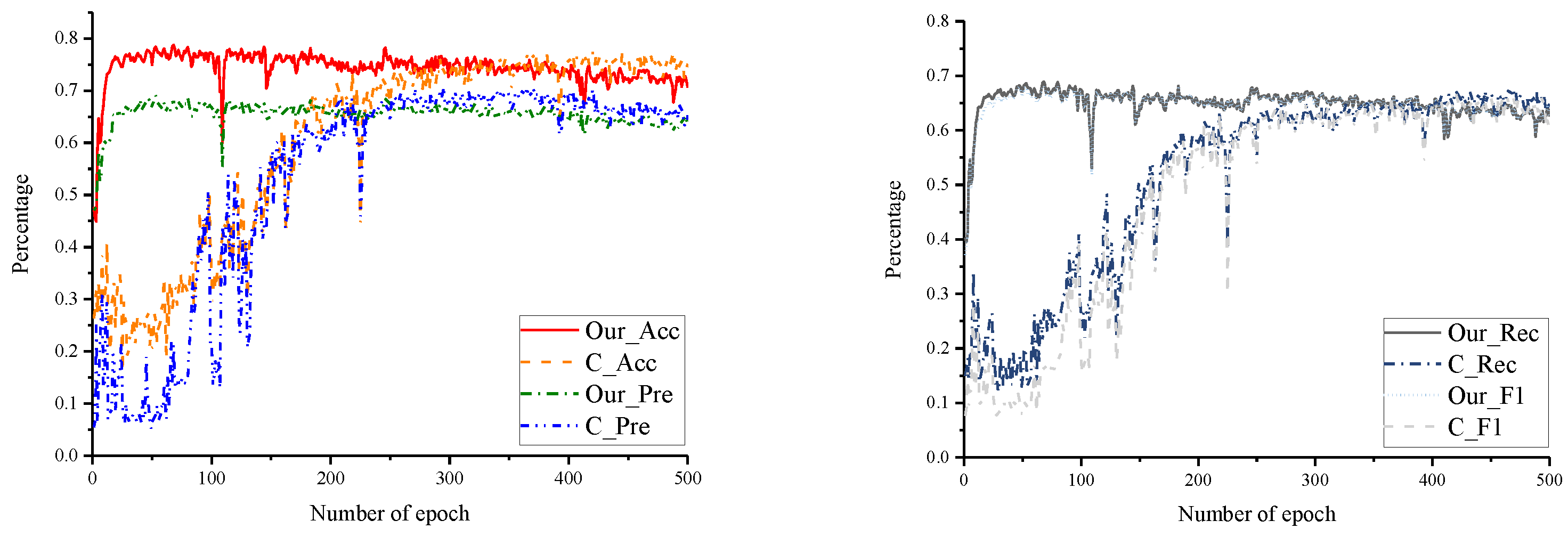
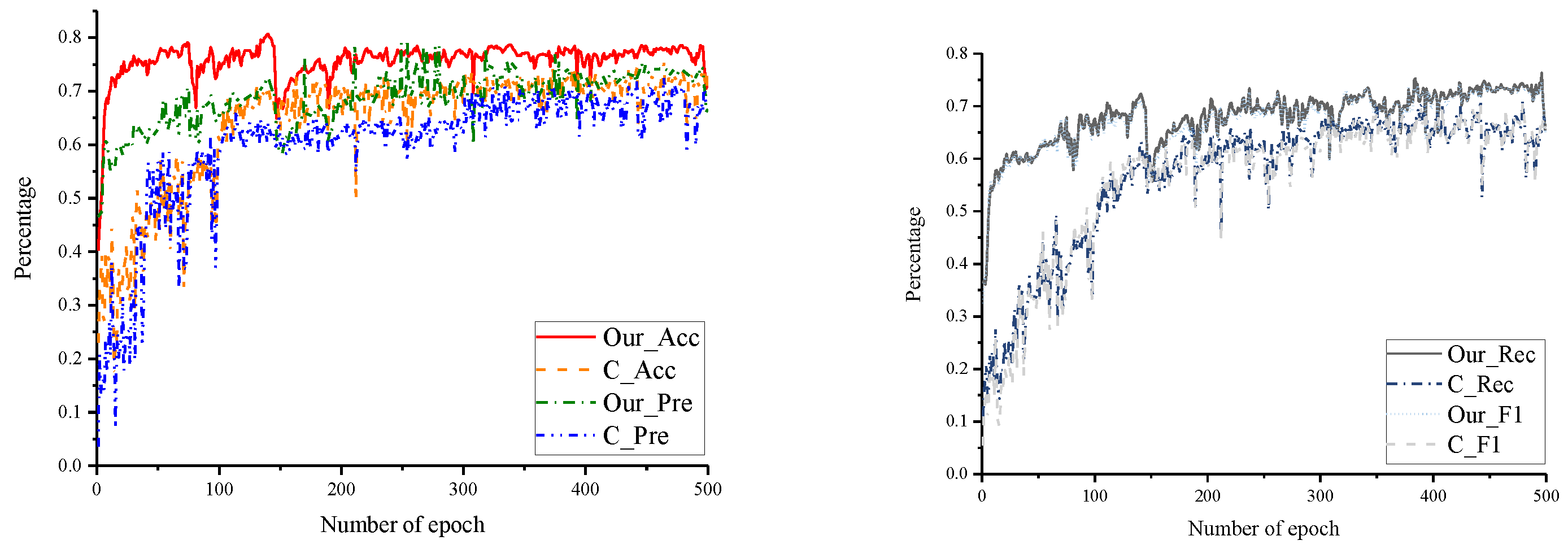
4.3. Experiments and Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Xie, R.; Gong, S. Interaction-Feedback Network for Multi-Task Daily Activity Forecasting. Expert Syst. Appl. 2023, 218, 119602. [Google Scholar] [CrossRef]
- Kasteren, V.; Englebienne, G.; Krose, B.J.A. Recognizing activities in multiple contexts using transfer learning. In Proceedings of the AAAI Symposium, Arlington, VA, USA, 7–9 November 2008; pp. 142–149. [Google Scholar]
- Pan, S.J.; Qiang, Y. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer learning for activity recognition: A survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Hao, Z.; Li, G.; Liu, Y.; Yang, R.; Liu, H. Optimal search mapping among sensors in heterogeneous smart homes. Math. Biosci. Eng. 2023, 20, 1960–1980. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Transfer learning for time series classification. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Chen, Y.; Keogh, E.; Hu, B.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR Time Series Classification Archive. 2015. Available online: https://www.cs.ucr.edu/~eamonn/time_series_data_2018 (accessed on 15 October 2018).
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A smart home in a box. Computer 2013, 46, 62–69. [Google Scholar] [CrossRef]
- Ye, J.; Dobson, S.; Zambonelli, F. XLearn: Learning activity labels across heterogeneous datasets. ACM Trans. Intell. Syst. Technol. 2020, 11, 28. [Google Scholar] [CrossRef]
- Feuz, K.D.; Cook, D.J. Transfer learning across feature-rich heterogeneous feature spaces via feature-space remapping (FSR). Acm Trans. Intell. Syst. Technol. 2015, 6, 1–27. [Google Scholar] [CrossRef]
- Azkune, G.; Almeida, A.; Agirre, E. Cross-environment activity recognition using word embeddings for sensor and activity representation. Neurocomputing 2020, 418, 280–290. [Google Scholar] [CrossRef]
- Chiang, Y.T.; Hsu, Y.J. Knowledge transfer in activity recognition using sensor profile. In Proceedings of the International Conference on Ubiquitous Intelligence and Computing and International Conference on Autonomic and Trusted Computing, Washington, DC, USA, 4–7 September 2012; pp. 180–187. [Google Scholar]
- Hu, D.H.; Yang, Q. Transfer learning for activity recognition via sensor mapping. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1962–1967. [Google Scholar]
- Rashidi, P.; Cook, D.J. Activity Recognition Based on Home to Home Transfer Learning; AAAI Press: New Orleans, LA, USA, 2010. [Google Scholar]
- Hu, D.H.; Zheng, V.W.; Yang, Q. Cross-domain activity recognition via transfer learning. Pervasive Mob. Comput. 2011, 7, 344–358. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 7, 3320–3328. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.-P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Gretton, A.; Sejdinovic, D.; Strathmann, H.; Balakrishnan, S.; Pontil, M.; Fukumizu, K.; Sriperumbudur, B.K. Optimal kernel choice for largescale two-sample tests. Adv. Neural Inf. Process. Syst. 2012, 25, 1205–1213. [Google Scholar]
- Zhuo, J.; Wang, S.; Zhang, W.; Huang, Q. Deep unsupervised convolutional domain adaptation. In Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 261–269. [Google Scholar]
- Long, M.; Wang, J.; Cao, Y.; Sun, J.; Yu, P.S. Deep learning of transferable representation for scalable domain adaptation. IEEE Trans. Knowl. Data Eng. 2016, 28, 2027–2040. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep coral: Correlation Alignment for Deep Domain Adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 443–450. [Google Scholar]
- Wei, P.; Ke, Y.; Goh, C.K. Deep nonlinear feature coding for unsupervised domain adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2189–2195. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised Representation Learning: Transfer Learning with Deep Autoencoders. In Proceedings of the International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 4119–4125. [Google Scholar]
- Luo, Z.; Zou, Y.; Hoffman, J.; Fei-Fei, L.F. Label efficient learning of transferable representations acrosss domains and tasks. Adv. Neural Inf. Process. Syst. 2017, 30, 164–176. [Google Scholar]
- Petitjean, F.; Ganarski, P. Summarizing a set of time series by averaging: From steiner sequence to compact multiple alignment. Theor. Comput. Sci. 2012, 414, 76–91. [Google Scholar] [CrossRef]
- Sun, Y.G.; Kim, S.H.; Lee, S.; Seon, J.; Lee, S.; Kim, C.G.; Kim, J.Y. Performance of End-to-end Model Based on Convolutional LSTM for Human Activity Recognition. J. Web Eng. 2022, 21, 1671–1690. [Google Scholar] [CrossRef]
- Singh, D.; Merdivan, E.; Hanke, S.; Geist, M.; Holzinger, A. Convolutional and Recurrent Neural Networks for Activity Recognition in Smart Environment. In Proceedings of the Banff-International-Research-Station (BIRS) Workshop, Banff, AB, Canada, 24–26 July 2015; pp. 194–205. [Google Scholar]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A sequential deep learning application for recognising human activities in smart homes. Neurocomputing 2020, 396, 501–513. [Google Scholar] [CrossRef]
- Thapa, K.; Mi, Z.M.A.; Sung-Hyun, Y. Adapted Long Short-Term Memory (LSTM) for Concurrent Human Activity Recognition. Cmc Comput. Mater. Contin. 2021, 69, 1653–1670. [Google Scholar] [CrossRef]
- Forbes, G.; Massie, S.; Craw, S.; Fraser, L.; Hamilton, G. Representing Temporal Dependencies in Smart Home Activity Recognition for Health Monitoring. In Proceedings of the International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Bengio, Y.; Glorot, X. Understanding the difficulty of training deep feed forward neural networks. Int. Conf. Artif. Intell. Stat. 2010, 9, 249–256. [Google Scholar]







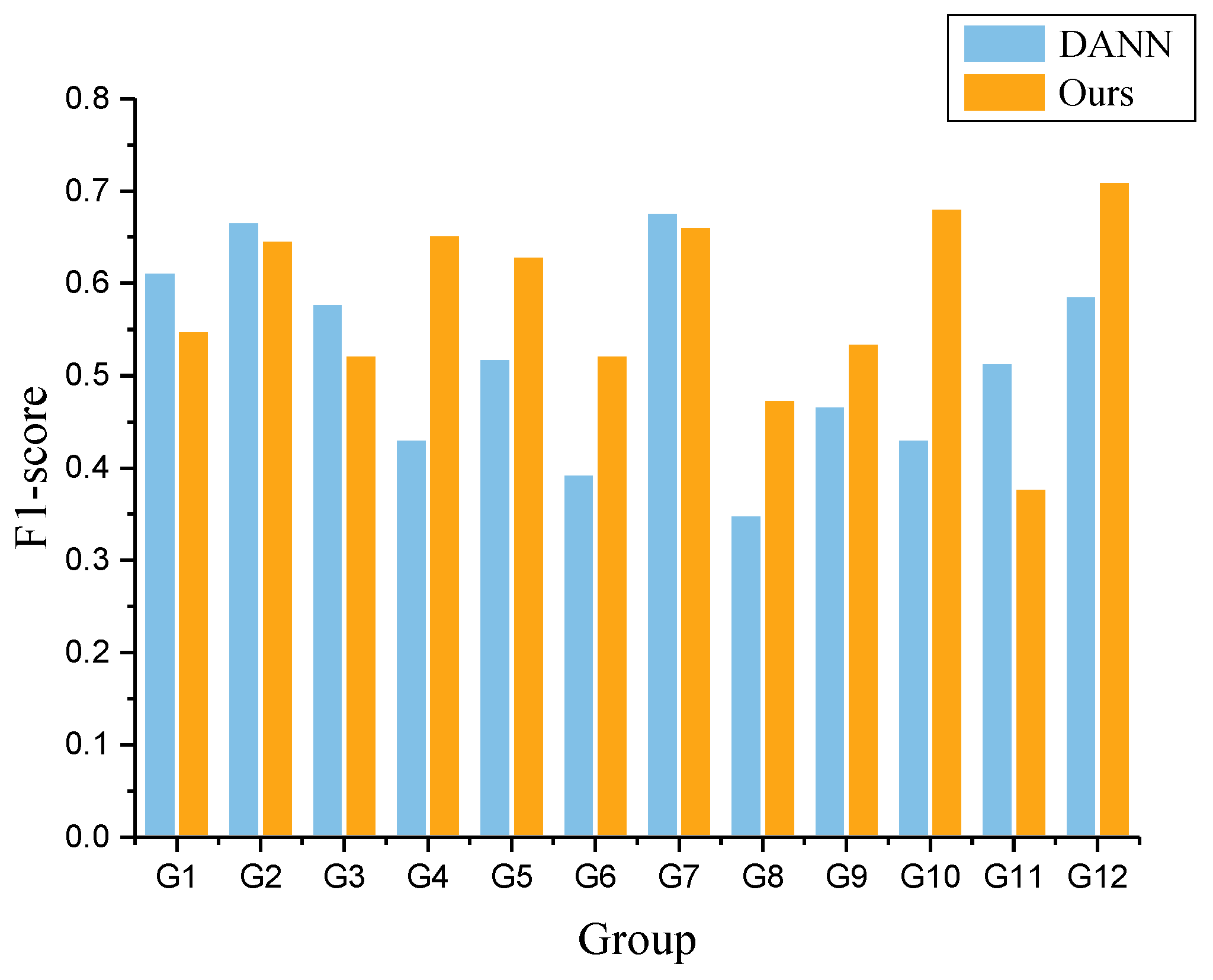

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| d | t | sn | sv | ac |
|---|---|---|---|---|
| 20 July 2012 | 15/04/47. 939431 | M008 | ON | Sleep_Out_Of_Bed |
| 20 July 2012 | 15/04/49. 047095 | LS008 | 38 | |
| 20 July 2012 | 15/04/49. 11856 | M008 | OFF | |
| 20 July 2012 | 15/09/05. 634721 | LS012 | 27 | |
| 20 July 2012 | 15/09/49. 513611 | LS009 | 26 | |
| 20 July 2012 | 15/10/37. 143058 | LS014 | 35 | |
| 20 July 2012 | 15/10/44. 79274 | LS001 | 12 | |
| 20 July 2012 | 15/12/01. 593479 | LS003 | 6 | |
| 20 July 2012 | 15/12/44. 773366 | LS016 | 15 | |
| 20 July 2012 | 15/12/47. 7472 | LS004 | 14 | |
| 20 July 2012 | 15/12/53. 867533 | LS013 | 27 | |
| 20 July 2012 | 15/13/29. 44345 | LS011 | 20 | |
| 20 July 2012 | 15/19/05. 563968 | LS012 | 26 | |
| 20 July 2012 | 15/19/49. 404442 | LS009 | 23 | |
| 20 July 2012 | 15/20/37. 05254 | LS014 | 31 | |
| 20 July 2012 | 15/20/44. 684768 | LS001 | 10 | |
| 20 July 2012 | 15/21/51. 214887 | LS008 | 34 | |
| 20 July 2012 | 15/21/51. 241965 | M008 | ON | |
| 20 July 2012 | 15/21/52. 330604 | M008 | OFF |
| Source Domain | Target Domain | Location | Type | Rename |
|---|---|---|---|---|
| LS009, LS012, LS014 | LS013, LS014, LS015 | Bedroom | Light | Bedroom_Light |
| M002, M003 | M008, M010 | Bedroom | Motion | Bedroom_Motion |
| D003 | D003 | Toilet | Door | Toilet_Door |
| Smart Home | Kitchen | Dining | Parlor | Porch | Toilet | Bedroom | Porch_Toilet |
|---|---|---|---|---|---|---|---|
| HH101 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| HH105 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| HH109 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| HH110 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Window | Learning Rate | Dropout | Optimizer | Batch Size | Epoch | Loss Function | |
|---|---|---|---|---|---|---|---|
| Ours | 100 | Model: 0.001 Fine-tuning: 0.00001 | 0.5 | Adam | 64 | 500 | Cross-entropy |
| Comparison | 100 | 0.001 | 0.5 | Adam | 64 | 500 | Cross-entropy |
| Experiment | Training Set | Test Set | Accuracy | |
|---|---|---|---|---|
| Group 1 | Ours_101to105 | 1 × HH101 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0.6899 |
| Comparison_101to105 | 1 × HH101 + 0.2 × HH105 | 0.8 × HH105 | 0.6592 | |
| Group 2 | Ours_101to109 | 1 × HH101 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.7413 |
| Comparison_101to109 | 1 × HH101 + 0.2 × HH109 | 0.8 × HH109 | 0.7004 | |
| Group 3 | Ours_101to110 | 1 × HH101 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6673 |
| Comparison_101to110 | 1 × HH101 + 0.2 × HH110 | 0.8 × HH110 | 0.6129 | |
| Group 4 | Ours_105to101 | 1 × HH105 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0.7664 |
| Comparison_105to101 | 1 × HH105 + 0.2 × HH101 | 0.8 × HH101 | 0.7238 | |
| Group 5 | Ours_105to109 | 1 × HH105 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.7339 |
| Comparison_105to109 | 1 × HH105 + 0.2 × HH109 | 0.8 × HH109 | 0.6943 | |
| Group 6 | Ours_105to110 | 1 × HH105 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6129 |
| Comparison_105to110 | 1 × HH105 + 0.2 × HH110 | 0.8 × HH110 | 0.5376 | |
| Group 7 | Ours_109to101 | 1 × HH109 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0.7468 |
| Comparison_109to101 | 1 × HH109 + 0.2 × HH101 | 0.8 × HH101 | 0.7131 | |
| Group 8 | Ours_109to105 | 1 × HH109 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0.6256 |
| Comparison_109to105 | 1 × HH109 + 0.2 × HH105 | 0.8 × HH105 | 0.5949 | |
| Group 9 | Ours_109to110 | 1 × HH109 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6631 |
| Comparison_109to110 | 1 × HH109 + 0.2 × HH110 | 0.8 × HH110 | 0.6004 | |
| Group 10 | Ours_110to101 | 1 × HH110 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0.7877 |
| Comparison_110to101 | 1 × HH110 + 0.2 × HH101 | 0.8 × HH101 | 0.7806 | |
| Group 11 | Ours_110to105 | 1 × HH110 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0.5837 |
| Comparison_110to105 | 1 × HH110 + 0.2 × HH105 | 0.8 × HH105 | 0.4776 | |
| Group 12 | Ours_110to109 | 1 × HH110 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.8069 |
| Comparison_110to109 | 1 × HH110 + 0.2 × HH109 | 0.8 × HH109 | 0.7586 |
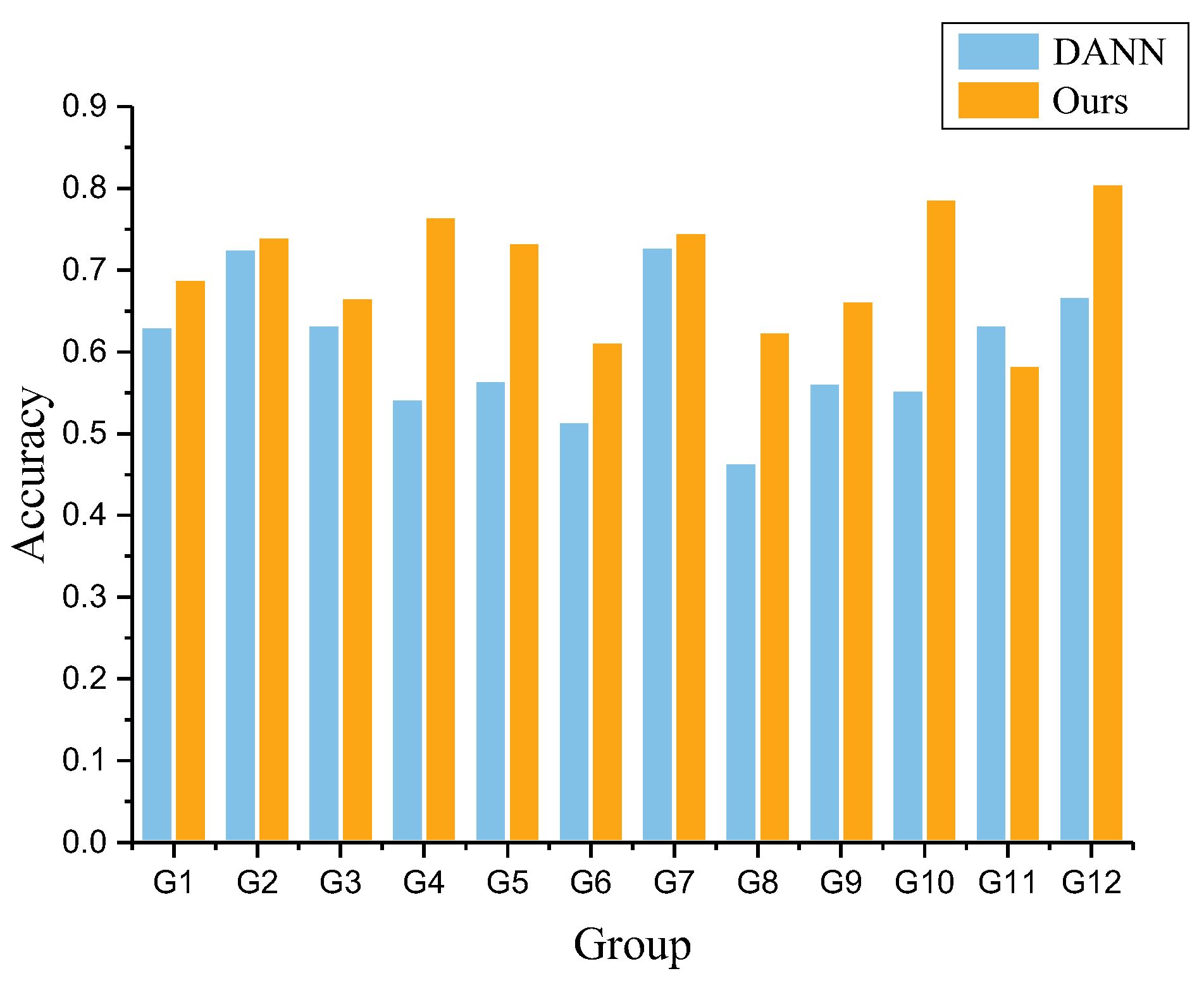
| Group | Experiment | Training Set | Test Set | Accuracy |
|---|---|---|---|---|
| 1 | Ours_101to105 | 1 × HH101 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0.6899 |
| DANN_101to105 | 1 × HH101 + 0.2 × HH105 | 0.8 × HH105 | 0.6312 | |
| 2 | Ours_101to109 | 1 × HH101 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.7413 |
| DANN_101to109 | 1 × HH101 + 0.2 × HH109 | 0.8 × HH109 | 0.7265 | |
| 3 | Ours_101to110 | 1 × HH101 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6673 |
| DANN_101to110 | 1 × HH101 + 0.2 × HH110 | 0.8 × HH110 | 0.6343 | |
| 4 | Ours_105to101 | 1 × HH105 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0.7664 |
| DANN_105to101 | 1 × HH105 + 0.2 × HH101 | 0.8 × HH101 | 0.5437 | |
| 5 | Ours_105to109 | 1 × HH105 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.7339 |
| DANN_105to109 | 1 × HH105 + 0.2 × HH109 | 0.8 × HH109 | 0.5656 | |
| 6 | Ours_105to110 | 1 × HH105 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6129 |
| DANN_105to110 | 1 × HH105 + 0.2 × HH110 | 0.8 × HH110 | 0.5156 | |
| 7 | Ours_109to101 | 1 × HH109 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0.7468 |
| DANN_109to101 | 1 × HH109 + 0.2 × HH101 | 0.8 × HH101 | 0.7296 | |
| 8 | Ours_109to105 | 1 × HH109 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0.6256 |
| DANN_109to105 | 1 × HH109 + 0.2 × HH105 | 0.8 × HH105 | 0.4656 | |
| 9 | Ours_109to110 | 1 × HH109 + Fine-tuning(0.2 × HH110) | 0.8 × HH110 | 0.6631 |
| DANN_109to110 | 1 × HH109 + 0.2 × HH110 | 0.8 × HH110 | 0.5625 | |
| 10 | Ours_110to101 | 1 × HH110 + Fine-tuning(0.2 × HH101) | 0.8 × HH101 | 0. 7877 |
| DANN_110to101 | 1 × HH110 + 0.2 × HH101 | 0.8 × HH101 | 0.5546 | |
| 11 | Ours_110to105 | 1 × HH110 + Fine-tuning(0.2 × HH105) | 0.8 × HH105 | 0. 5837 |
| DANN_110to105 | 1 × HH110 + 0.2 × HH105 | 0.8 × HH105 | 0.6343 | |
| 12 | Ours_110to109 | 1 × HH110 + Fine-tuning(0.2 × HH109) | 0.8 × HH109 | 0.8069 |
| DANN_110to109 | 1 × HH110 + 0.2 × HH109 | 0.8 × HH109 | 0.6687 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Tang, K.; Liu, Y. A Fine-Tuning Based Approach for Daily Activity Recognition between Smart Homes. Appl. Sci. 2023, 13, 5706. https://doi.org/10.3390/app13095706
Yu Y, Tang K, Liu Y. A Fine-Tuning Based Approach for Daily Activity Recognition between Smart Homes. Applied Sciences. 2023; 13(9):5706. https://doi.org/10.3390/app13095706
Chicago/Turabian StyleYu, Yunqian, Kun Tang, and Yaqing Liu. 2023. "A Fine-Tuning Based Approach for Daily Activity Recognition between Smart Homes" Applied Sciences 13, no. 9: 5706. https://doi.org/10.3390/app13095706
APA StyleYu, Y., Tang, K., & Liu, Y. (2023). A Fine-Tuning Based Approach for Daily Activity Recognition between Smart Homes. Applied Sciences, 13(9), 5706. https://doi.org/10.3390/app13095706