
Citrus Pest Identification Model Based on Improved ShuffleNet

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Set Collection and Processing
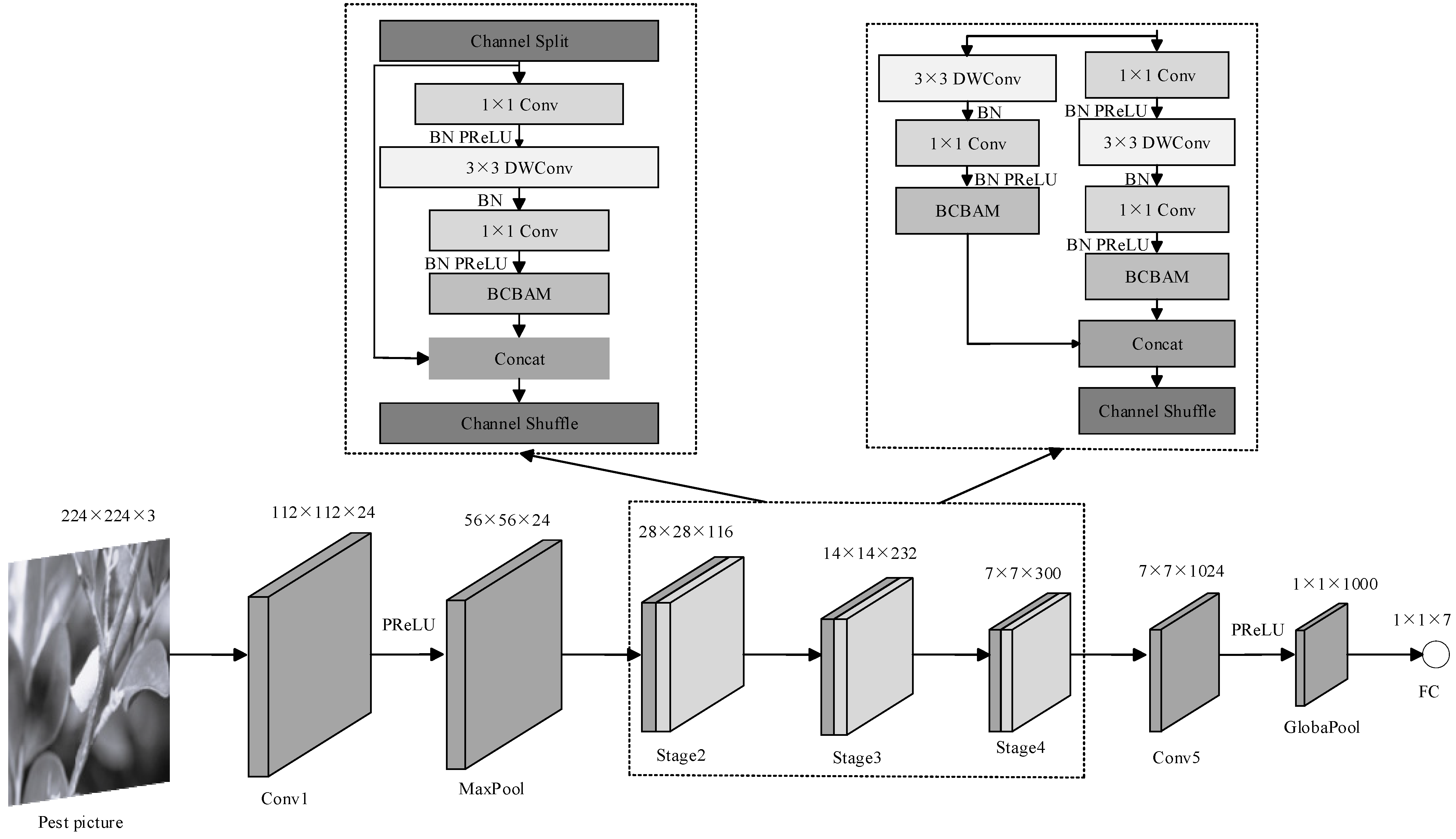
2.2. ShuffleNet V2 Model
2.3. Improved SCHNet Model
2.3.1. Subsubsection Parametric Linear Rectification Function
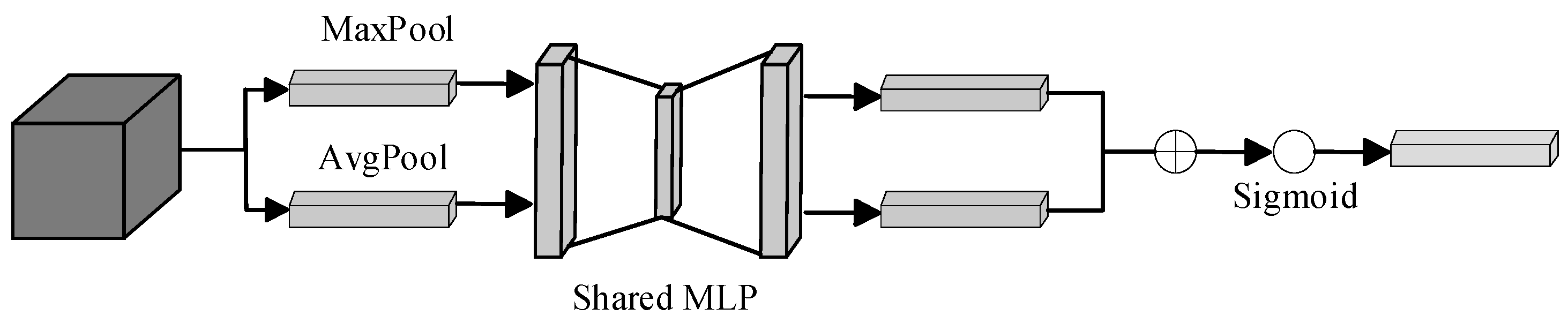
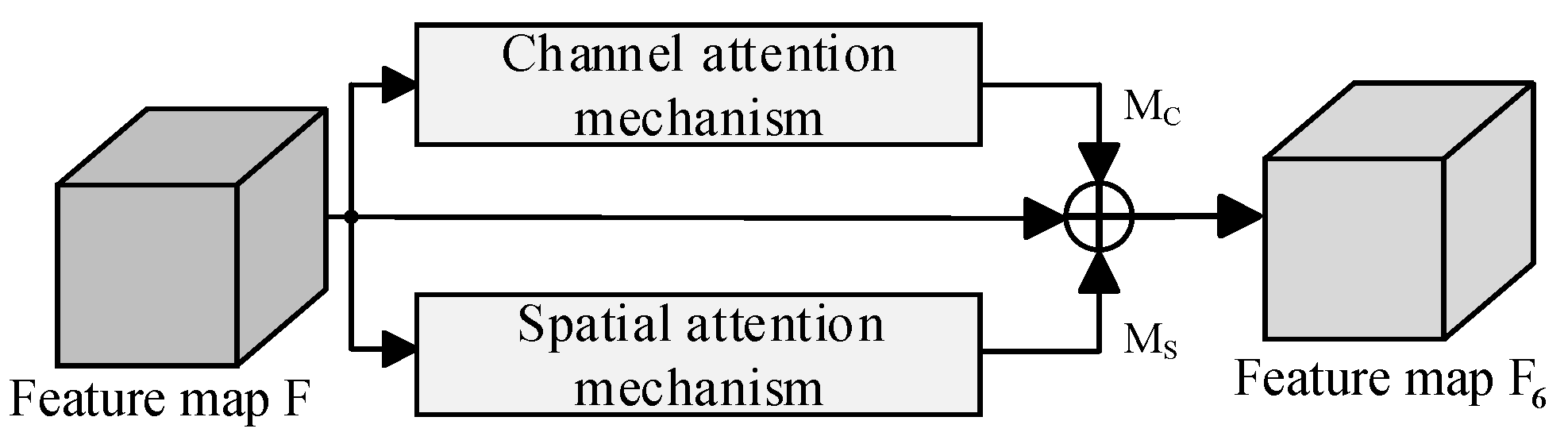
2.3.2. Subsubsection Improved Mixed Attention Mechanism
2.3.3. Adjusting Network Architecture
2.3.4. Transfer Learning
2.4. Experimental Setup and Parameters
3. Results and Discussion
3.1. Experimental Setup and Parameters
3.2. Replacing the ReLU Activation Function
3.3. Impact of the Attention Mechanism on Model Performance
3.4. Ablation Study
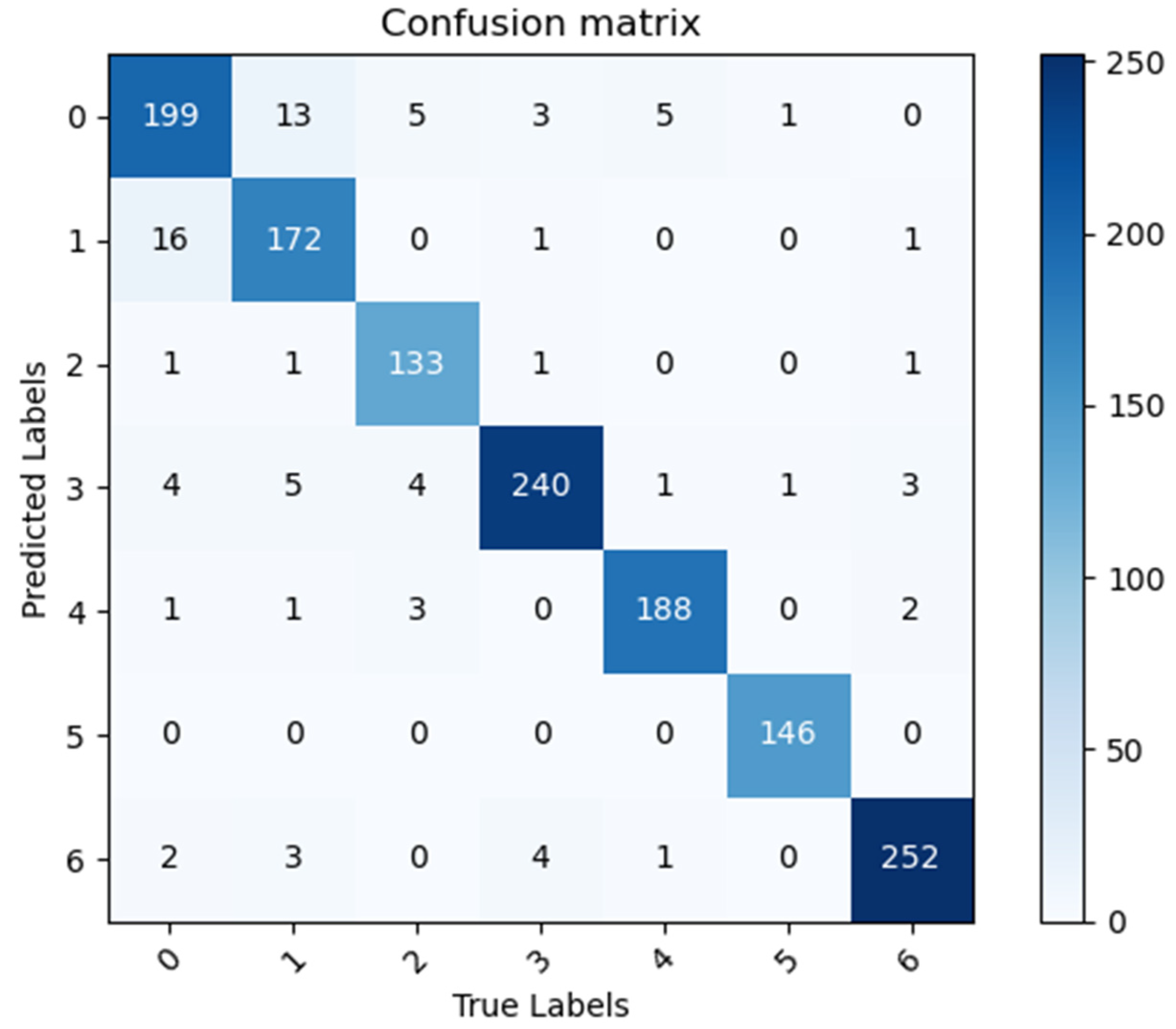
3.5. Heatmaps
3.6. Comparative Experiments with Different Network Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, X.X. Thinking on some problems in the development of fruit industry in China. J. Fruit Sci. 2021, 38, 121–127. (In Chinese) [Google Scholar]
- Qi, C.J.; Gu, Y.M.; Zeng, Y. Research progress of citrus industry economy in China. J. Huazhong Agric. Univ. 2021, 40, 58–69. (In Chinese) [Google Scholar]
- Zhai, Z.Y.; Cao, Y.F.; Xu, H.L.; Yuan, P.S.; Wang, H.Y. Review on key technologies of crop pest identification. Trans. Chin. Soc. Agric. Mach. 2021, 52, 1–18. (In Chinese) [Google Scholar]
- Cai, Y.H.; Guo, J.W.; Li, Y.C.; Chen, F.Y. Citrus disease field image dataset and deep learning model testing. Cent. South Agric. Sci. Technol. 2023, 44, 235–237. (In Chinese) [Google Scholar]
- Huang, L.S.; Luo, Y.W.; Yang, X.D.; Yang, G.J.; Wang, D.Y. Crop disease recognition based on attention mechanism and multi-scale residual network. Trans. Chin. Soc. Agric. Mach. 2021, 52, 264–271. (In Chinese) [Google Scholar]
- Chen, J.; Chen, L.Y.; Wang, S.S.; Zhao, H.Y.; Wen, C.J. Image recognition of garden pests based on improved residual network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 187–195. (In Chinese) [Google Scholar]
- Song, Y.Q.; Xie, X.; Liu, Z.; Zou, X.B. Crop pests and diseases recognition method based on multi-level EESP model. Trans. Chin. Soc. Agric. Eng. 2020, 51, 196–202. (In Chinese) [Google Scholar]
- Wang, M.H.; Wu, Z.X.; Zhou, Z.G. Research on Fine-grain recognition of crop pests and diseases based on improved CBAM. Trans. Chin. Soc. Agric. Mach. 2021, 52, 239–247. (In Chinese) [Google Scholar]
- Ye, Z.H.; Zhao, M.X.; Jia, L. Research on crop disease image recognition with complex background. Trans. Chin. Soc. Agric. Mach. 2021, 52, 118–124+147. (In Chinese) [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations, International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Iandola, F.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. Available online: https://arxiv.org/abs/1602.07360 (accessed on 24 February 2016).
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Pan, C.L.; Zhang, Z.H.; Gui, W.H.; Ma, J.J.; Yan, C.X.; Zhang, X.M. Identification of rice pests and diseases by combining ECA mechanism with DenseNet201. Smart Agric. 2023, 5, 45–55. (In Chinese) [Google Scholar]
- Cen, X. Application of image recognition technology based on deep learning in citrus disease and insect recognition. Equip. Manuf. Technol. 2023, 96–99. (In Chinese) [Google Scholar] [CrossRef]
- Zeba, A.; Sarfaraz, M. Exploring Deep Ensemble Model for Insect and Pest Detection from Images. Procedia Comput. Sci. 2023, 218, 2328–2337. [Google Scholar]
- Su, H.; Wen, G.; Xie, W.; Wei, M.; Wang, X. Research on Citrus Pest and Disease Recognition Method in Guangxi Based on Regional Convolutional Neural Network Mode. Southwest China J. Agric. Sci. 2020, 33, 805–810. [Google Scholar]
- Gan, Y.; Guo, Q.W.; Wang, C.T.; Liang, W.J.; Xiao, D.Q.; Wu, H.L. Crop pest identification based on improved EfficientNet model. Trans. Chin. Soc. Agric. Eng. 2022, 38, 203–211. (In Chinese) [Google Scholar]
- Zhang, P.C.; Yu, Y.H.; Chen, C.W.; Zheng, W.Y.; Li, S.J. Classification and recognition method of citrus pests based on improved MobileNetV2. J. Huazhong Agric. Univ. 2023, 42, 161–168. (In Chinese) [Google Scholar]
- Adhi, S.; Novanto, Y.; Cahya, R.W. Large scale pest classification using efficient Convolutional Neural Network with augmentation and regularizers. Comput. Electron. Agric. 2022, 200, 107204. [Google Scholar]
- Zhon, Y.; Fu, C.J.; Zhai, Y.T.; Li, J.; Jin, Z.Q.; Xu, Y.L. Identification of Rice Leaf Disease Using Improved ShuffleNet V2. Comput. Mater. Contin. 2023, 75, 4501–4517. [Google Scholar]
- Liu, Y.F.; Wei, S.Q.; Huang, H.J.; Lai, Q.; Li, M.S.; Guan, L.X. Naming entity recognition of citrus pests and diseases based on the BERT-BiLSTM-CRF model. Expert Syst. Appl. 2023, 234, 121103. [Google Scholar] [CrossRef]
- Liu, C.Q. Occurrence and control technology of citrus white moth waxhopper. Plant Dr. 2009, 22, 25. [Google Scholar]
- Fu, S.Q.; Zhou, X.W.; Huang, J.J. Effect of different agents on the control of citrus psyllid. China Agric. Ext. 2020, 36, 69–70. [Google Scholar]
- Zhang, X.Q.; Kong, X.Y.; Yang, C.; Liu, W.Q.; Yuan, Y.Y.; Zhou, Z.W.; Xia, B.; Xin, T.R. Cloning of fatty acid binding protein gene and response to starvation stress in the citrus alligator mite. J. Appl. Entomol. 2023, 60, 1–10. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imageNet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, Z.Z.; Liang, K.; Wang, Z.Y.; Zhang, Q.; Guo, Y.X.; Guo, J.Q. Classification of wheat plaques by improved CBAM and MobileNet V2 algorithm. J. Nanjing Agric. Univ. 2023, 1–11. Available online: https://link.cnki.net/urlid/32.1148.S.20231019.1117.002 (accessed on 20 May 2024). (In Chinese).
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. Available online: https://arxiv.org/abs/1511.07122 (accessed on 23 November 2015).
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pest Categories | Training Set | Test Set |
|---|---|---|
| Lawana imitata | 897 | 223 |
| Geisha distinctissma | 779 | 194 |
| Icerya purchasi | 585 | 145 |
| Xenocatantops prachycerus | 1001 | 249 |
| Dialeurodes citri | 783 | 195 |
| Papilio xuthus Linnaeus | 594 | 148 |
| Panonychus citri | 1037 | 259 |
| Total | 5676 | 1413 |
| Activation Function | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| ReLU | 0.9136 | 0.9137 | 0.9114 | 0.9125 |
| PReLU | 0.9242 | 0.9232 | 0.9225 | 0.9229 |
| Model | Accuracy | Precision | Recall | F1 score | Parameters/106 | Floats/106 |
|---|---|---|---|---|---|---|
| Scheme 1 | 0.9235 | 0.9255 | 0.9211 | 0.9233 | 2.48 | 1.5340 |
| Scheme 2 | 0.9345 | 0.9344 | 0.9347 | 0.9345 | 2.48 | 1.5419 |
| Scheme 3 | 0.9377 | 0.9401 | 0.9368 | 0.9384 | 2.48 | 1.5419 |
| Model | BCABM | T L | PReLU | AAd | Acc | F1 Score | Par/106 | Floats/106 | MS/MB |
|---|---|---|---|---|---|---|---|---|---|
| ShuNet | ✗ | ✗ | ✗ | ✗ | 0.9136 | 0.9125 | 2.28 | 152.71 | 4.97 |
| ✓ | ✗ | ✗ | ✗ | 0.9377 | 0.9384 | 2.48 | 154.19 | 5.78 | |
| ✗ | ✓ | ✗ | ✗ | 0.9214 | 0.9212 | 2.28 | 152.71 | 4.97 | |
| ✗ | ✗ | ✓ | ✗ | 0.9242 | 0.9229 | 2.28 | 154.71 | 4.98 | |
| ✓ | ✓ | ✗ | ✗ | 0.9341 | 0.9344 | 2.48 | 154.19 | 5.78 | |
| ✓ | ✓ | ✓ | ✗ | 0.9384 | 0.9385 | 2.48 | 155.03 | 5.80 | |
| SCHNet | ✓ | ✓ | ✓ | ✓ | 0.9448 | 0.9438 | 1.97 | 121.11 | 3.84 |
| Model | Accuracy | Precision | Recall | F1 Score | Parameters/106 | Floats/106 |
|---|---|---|---|---|---|---|
| AlexNet | 0.9016 | 0.9024 | 0.9038 | 0.9031 | 61.10 | 714.21 |
| ResNet50 | 0.9030 | 0.9050 | 0.9044 | 0.9047 | 25.56 | 4133.74 |
| EfficienNet_b2 | 0.8655 | 0.8674 | 0.8592 | 0.8633 | 9.11 | 701.93 |
| SqueezeNet1_0 | 0.7997 | 0.8035 | 0.7894 | 0.7964 | 1.25 | 819.09 |
| MobileNet_v2 | 0.8973 | 0.8952 | 0.8975 | 0.8964 | 3.50 | 327.49 |
| MnasNet1_0 | 0.8457 | 0.8447 | 0.8437 | 0.8442 | 4.38 | 336.24 |
| DenseNet121 | 0.8627 | 0.8658 | 0.8611 | 0.8634 | 7.98 | 2897.01 |
| ShuffleNet V2 | 0.9136 | 0.9137 | 0.9114 | 0.9125 | 2.28 | 152.71 |
| SCHNet | 0.9448 | 0.9440 | 0.9435 | 0.9438 | 1.97 | 121.11 |
| References | Large-Scale Models | Recall | Parameters/106 |
|---|---|---|---|
| Pan Chenlu et al. [15] | yes | 83.52% | >5.38 |
| Cen Xiao et al. [16] | yes | 81.9% | >5.38 |
| Zeba et al. [17] | yes | 82.5% | >5.38 |
| Su Hong et al. [18] | yes | 95.3% | >5.38 |
| Ganyu et al. [19] | no | 69.45% | 5.38 |
| Zhang Pengcheng et al. [20] | no | 93.63% | 3.5 |
| Setiawan et al. [21] | no | 71.32% | 4.2 |
| SCHNet | no | 94.48% | 1.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.-N.; Xiong, C.-L.; Yan, J.-C.; Mo, Y.-B.; Dou, S.-Q.; Wu, Z.-H.; Yang, R.-F. Citrus Pest Identification Model Based on Improved ShuffleNet. Appl. Sci. 2024, 14, 4437. https://doi.org/10.3390/app14114437
Yu Y-N, Xiong C-L, Yan J-C, Mo Y-B, Dou S-Q, Wu Z-H, Yang R-F. Citrus Pest Identification Model Based on Improved ShuffleNet. Applied Sciences. 2024; 14(11):4437. https://doi.org/10.3390/app14114437
Chicago/Turabian StyleYu, Yan-Nan, Chun-Lin Xiong, Ji-Chi Yan, Yong-Bin Mo, Shi-Qing Dou, Zuo-Hua Wu, and Rong-Feng Yang. 2024. "Citrus Pest Identification Model Based on Improved ShuffleNet" Applied Sciences 14, no. 11: 4437. https://doi.org/10.3390/app14114437
APA StyleYu, Y.-N., Xiong, C.-L., Yan, J.-C., Mo, Y.-B., Dou, S.-Q., Wu, Z.-H., & Yang, R.-F. (2024). Citrus Pest Identification Model Based on Improved ShuffleNet. Applied Sciences, 14(11), 4437. https://doi.org/10.3390/app14114437