
ODGNet: Robotic Grasp Detection Network Based on Omni-Dimensional Dynamic Convolution

Abstract
:1. Introduction
- A novel grasp detection network, ODGNet, is proposed, which can output the object’s corresponding grasp configuration by inputting the RGB-D image;
- The ODGNet firstly introduces ODConv to enhance the feature extraction ability of the grasping region; secondly, a GRFEF module is designed, which enhances the feature learning ability of the grasping region and suppresses the non-grasping region features; finally, the multi-scale features are used to improve the grasp detection accuracy;
- The ODGNet was trained and tested on the Cornell dataset and also tested on the multi-object dataset. The test results show that it delivers good detection results for both single and multiple objects;
- Robot grasping experiments were carried out in a simulation environment, and the results demonstrate the feasibility and effectiveness of the proposed method.
2. Related Work
2.1. Deep Learning Methods for Robotic Grasp Detection
2.2. Omni-Dimensional Dynamic Convolution
2.3. Attention Mechanisms
3. Method
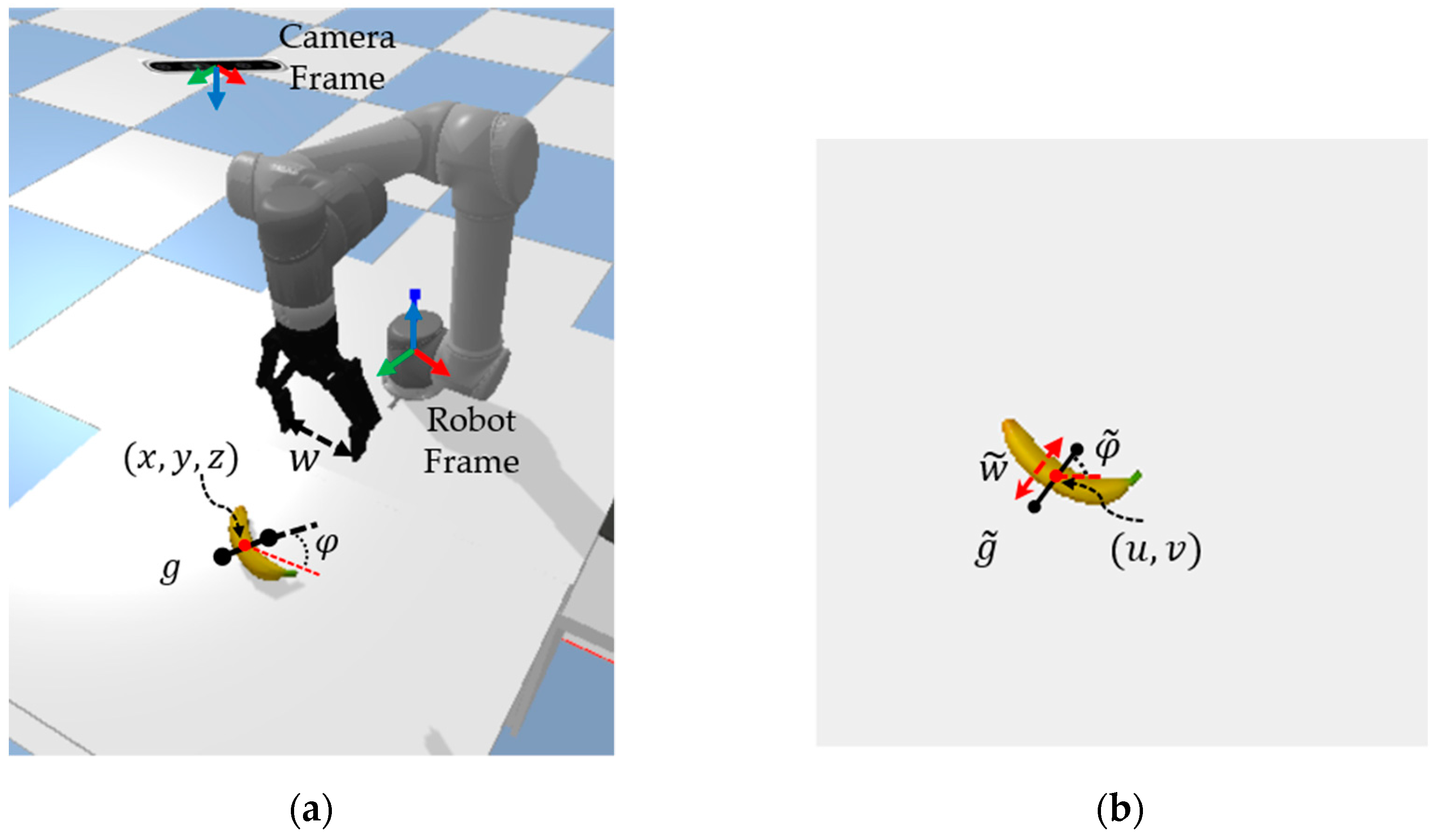
3.1. Grasp Representation
3.2. Network Architecture
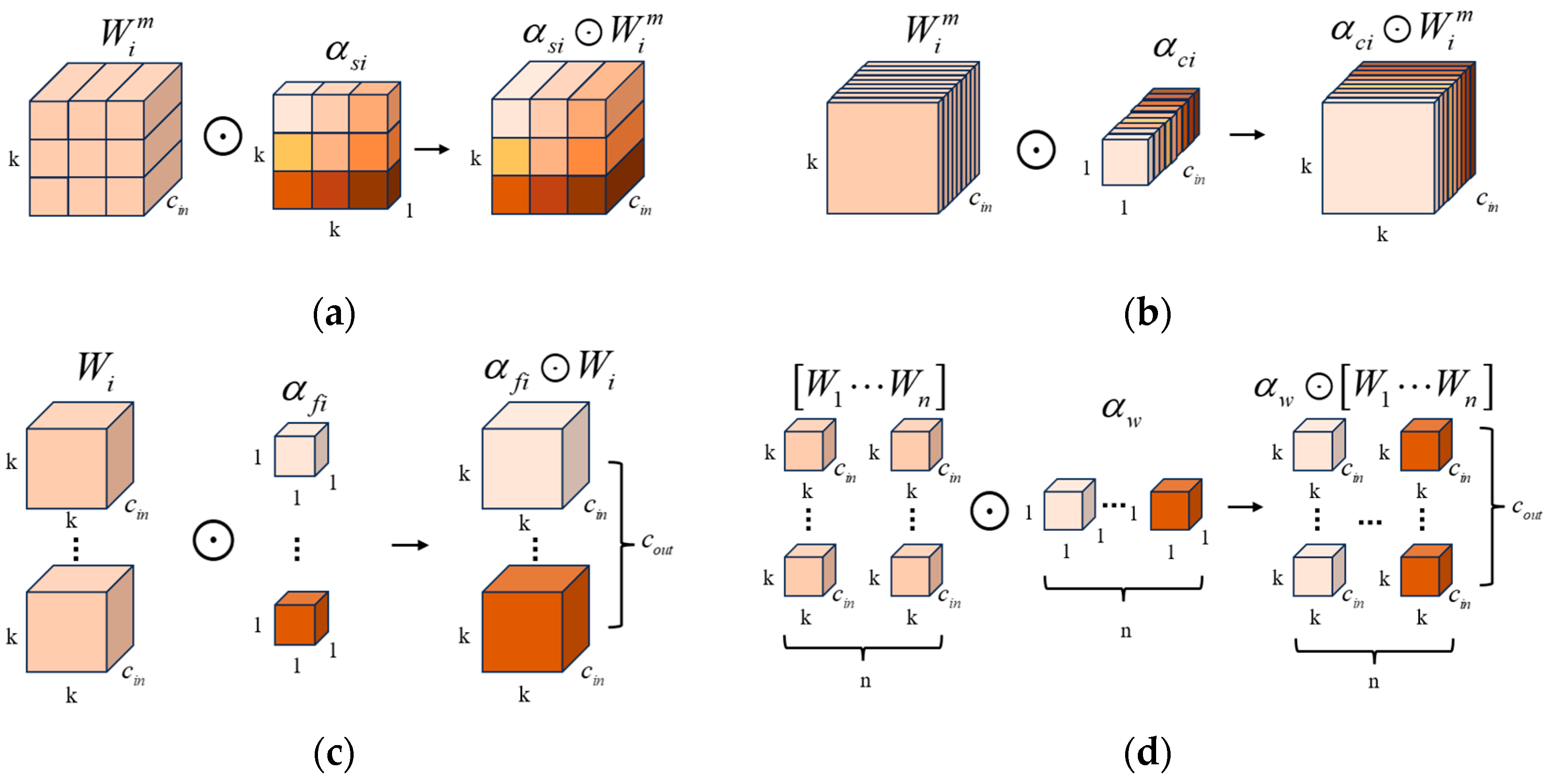
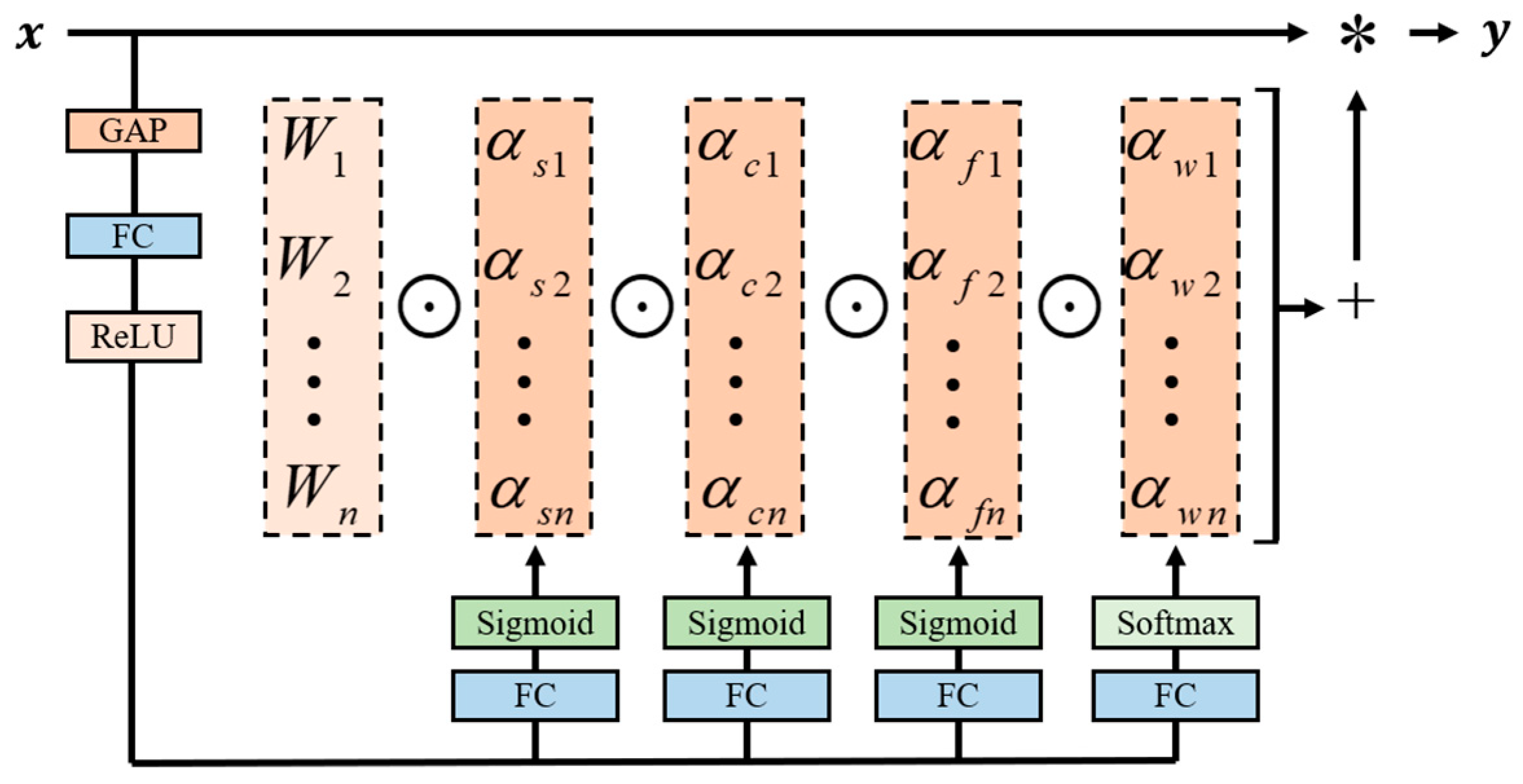
3.2.1. Omni-Dimensional Dynamic Convolutional Layer
3.2.2. Grasping Region Feature Enhancement Fusion Module
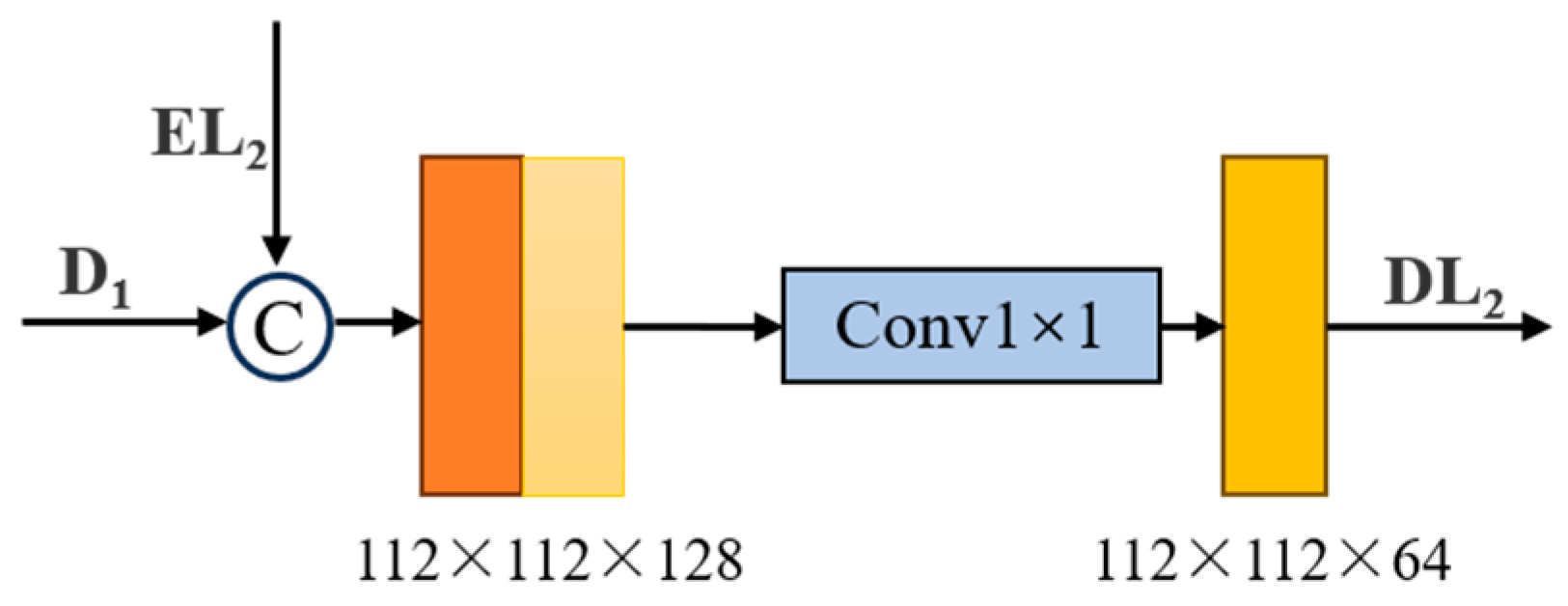
3.2.3. Primary Feature Fusion Module
3.2.4. Output Processing Module
3.3. Loss Function
4. Experimental Validation
4.1. Dataset Preprocessing
4.2. Training Details
4.3. Evaluation Metric
- (1)
- The Jaccard index between the predicted grasping rectangle and the ground truth of grasping rectangle is greater than 0.25, expressed as
- (2)
- The variance between the predicted grasp angle and the ground truth of grasp angle is less than 30°, expressed as
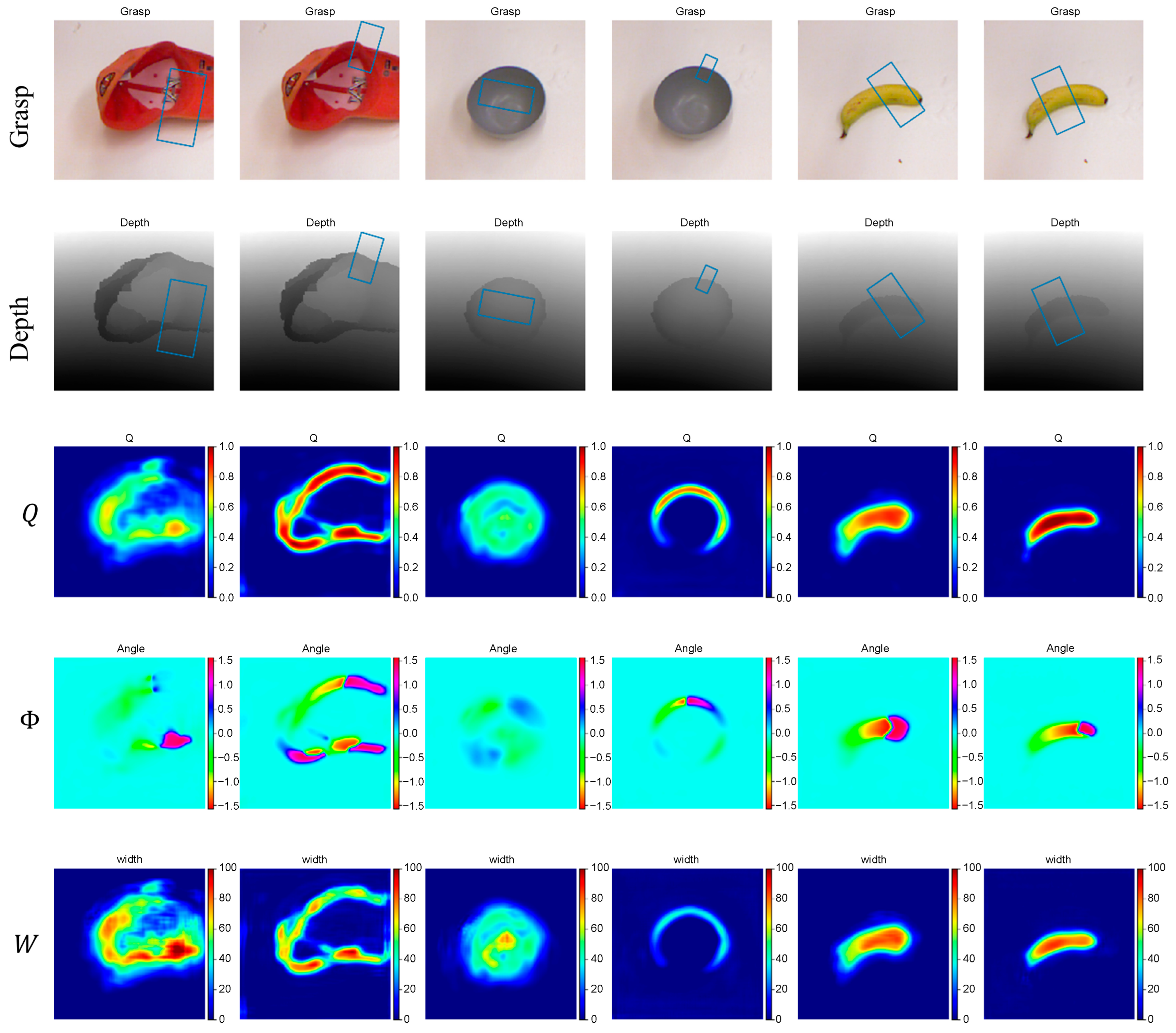
4.4. Experimental Results and Analysis
4.4.1. Comparison Experiments on Cornell Dataset
- (1)
- IW: All images in the Cornell dataset are randomly divided into a training set and a test set. The objects in the test set may have been seen in the training set, but with different positions and orientations. The purpose of splitting by image is to test the network’s grasp detection ability for the same object but at different placement positions.
- (2)
- OW: All the images in the Cornell dataset are divided into training and test sets by object category, and the images of the objects that have been used in the training set are not used again in the test set. Its purpose is to test the network’s grasp detection ability for the unknown objects.
4.4.2. Experiments on Multi-Object Dataset
4.4.3. Ablation Experiments
4.4.4. Experiments in the Simulation Environment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ODConv | Omni-dimensional dynamic convolution |
| ODGNet | Omni-dimensional dynamic convolution grasp detection network |
| SA | Shuffle Attention |
| GRFEF | Grasping region feature enhancement and fusion |
| GR-ConvNet | Generative Residual Convolutional Neural Network |
| GAP | Global Average Pooling |
| FC | Fully connected |
References
- Du, G.; Wang, K.; Lian, S.; Zhao, K. Vision-Based Robotic Grasping from Object Localization, Object Pose Estimation to Grasp Estimation for Parallel Grippers: A Review. Artif. Intell. Rev. 2021, 54, 1677–1734. [Google Scholar] [CrossRef]
- Dong, M.; Zhang, J. A Review of Robotic Grasp Detection Technology. Robotica 2023, 41, 3846–3885. [Google Scholar] [CrossRef]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient Grasping from RGBD Images: Learning Using a New Rectangle Representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep Learning for Detecting Robotic Grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-Time Grasp Detection Using Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic Grasp Detection Using Deep Convolutional Neural Networks. arXiv 2017, arXiv:1611.08036. Available online: https://arxiv.org/abs/1611.08036v3 (accessed on 13 April 2024).
- Zhou, X.; Lan, X.; Zhang, H.; Tian, Z.; Zhang, Y.; Zheng, N. Fully Convolutional Grasp Detection Network with Oriented Anchor Box. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7223–7230. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Closing the Loop for Robotic Grasping: A Real-Time, Generative Grasp Synthesis Approach 2018. arXiv 2018, arXiv:1804.05172. [Google Scholar]
- Yu, S.; Zhai, D.-H.; Xia, Y. SKGNet: Robotic Grasp Detection With Selective Kernel Convolution. IEEE Trans. Autom. Sci. Eng. 2022, 20, 2241–2252. [Google Scholar] [CrossRef]
- Yan, S.; Zhang, L. CR-Net: Robot Grasping Detection Method Integrating Convolutional Block Attention Module and Residual Module. IET Comput. Vis. 2024, 18, 420–433. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-Dimensional Dynamic Convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Chu, F.-J.; Xu, R.; Vela, P.A. Real-World Multiobject, Multigrasp Detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef]
- Bicchi, A. Hands for Dexterous Manipulation and Robust Grasping: A Difficult Road toward Simplicity. IEEE Trans. Robot. Autom. 2000, 16, 652–662. [Google Scholar] [CrossRef]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-Driven Grasp Synthesis—A Survey. IEEE Trans. Robot. 2014, 30, 289–309. [Google Scholar] [CrossRef]
- Pinto, L.; Gupta, A. Supersizing Self-Supervision: Learning to Grasp from 50K Tries and 700 Robot Hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; Volume 25. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Aparicio, J.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Learning Robust, Real-Time, Reactive Robotic Grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping Using Generative Residual Convolutional Neural Network. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 19–25 October 2020; pp. 9626–9633. [Google Scholar]
- Yu, S.; Zhai, D.-H.; Xia, Y.; Wu, H.; Liao, J. SE-ResUNet: A Novel Robotic Grasp Detection Method. IEEE Robot. Autom. Lett. 2022, 7, 5238–5245. [Google Scholar] [CrossRef]
- Geng, W.; Cao, Z.; Guan, P.; Jing, F.; Tan, M.; Yu, J. Grasp Detection with Hierarchical Multi-Scale Feature Fusion and Inverted Shuffle Residual. Tsinghua Sci. Technol. 2024, 29, 244–256. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, Z.; Kan, Z. When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection. IEEE Robot. Autom. Lett. 2022, 7, 8170–8177. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, X. Bilateral Cross-Modal Fusion Network for Robot Grasp Detection. Sensors 2023, 23, 3340. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. CondConv: Conditionally Parameterized Convolutions for Efficient Inference. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Davis, C. The Norm of the Schur Product Operation. Numer. Math. 1962, 4, 343–344. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 21–26 June 2017; pp. 2117–2125. [Google Scholar]
- Johns, E.; Leutenegger, S.; Davison, A.J. Deep Learning a Grasp Function for Grasping under Gripper Pose Uncertainty. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4461–4468. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Asif, U.; Tang, J.; Harrer, S. GraspNet: An Efficient Convolutional Neural Network for Real-Time Grasp Detection for Low-Powered Devices. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13 July 2018. [Google Scholar]
- Calli, B.; Singh, A.; Bruce, J.; Walsman, A.; Konolige, K.; Srinivasa, S.; Abbeel, P.; Dollar, A.M. Yale-CMU-Berkeley Dataset for Robotic Manipulation Research. Int. J. Robot. Res. 2017, 36, 261–268. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Method | Accuracy (%) | Time (ms) | |
|---|---|---|---|---|
| IW | OW | |||
| Lenz [4] | SAE | 73.9 | 75.6 | 1350 |
| Kumra [6] | ResNet-50 | 89.2 | 88.9 | 103 |
| Morrison [8] | GG-CNN | 73.0 | 69.0 | 19 |
| Asif [37] | GraspNet | 90.2 | 90.6 | 24 |
| Kumra [20] | GR-ConvNet | 97.7 | 96.6 | 20 |
| Yu [21] | SE-ResUNet | 98.2 | 97.1 | 25 |
| Wang [23] | TF-Grasp | 98.0 | 96.7 | 42 |
| Our | ODGNet | 98.4 | 97.8 | 21 |
| Method | Splitting | Jaccard Index | |||
|---|---|---|---|---|---|
| 0.25 | 0.30 | 0.35 | 0.40 | ||
| GR-ConvNet [20] | IW (%) | 97.7 | 96.8 | 94.1 | 88.7 |
| Ours | 98.4 | 97.2 | 94.9 | 91.5 | |
| GR-ConvNet [20] | OW (%) | 96.6 | 93.2 | 90.5 | 84.8 |
| Ours | 97.8 | 95.5 | 94.4 | 91.0 | |
| ODConv | √ | √ | √ | √ | ||||
| SA module | √ | √ | √ | √ | ||||
| Primary feature fusion | √ | √ | √ | √ | ||||
| Accuracy (%) | 95.3 | 98.1 | 97.9 | 96.4 | 98.2 | 97.8 | 98.1 | 98.4 |
| Scenario | GR-ConvNet [20] | Our Model | ||
|---|---|---|---|---|
| Grasp | Success Rate (%) | Grasp | Success Rate (%) | |
| Single-object | 232/250 | 92.8 | 238/250 | 95.2 |
| Multi-object | 215/250 | 86.0 | 226/250 | 90.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, X.; Tao, B. ODGNet: Robotic Grasp Detection Network Based on Omni-Dimensional Dynamic Convolution. Appl. Sci. 2024, 14, 4653. https://doi.org/10.3390/app14114653
Kuang X, Tao B. ODGNet: Robotic Grasp Detection Network Based on Omni-Dimensional Dynamic Convolution. Applied Sciences. 2024; 14(11):4653. https://doi.org/10.3390/app14114653
Chicago/Turabian StyleKuang, Xinghong, and Bangsheng Tao. 2024. "ODGNet: Robotic Grasp Detection Network Based on Omni-Dimensional Dynamic Convolution" Applied Sciences 14, no. 11: 4653. https://doi.org/10.3390/app14114653