Abstract
The booming growth of the internet of things has brought about widespread deployment of devices and massive amounts of sensing data to be processed. Federated learning (FL)-empowered mobile edge computing, known for pushing artificial intelligence to the network edge while preserving data privacy in learning cooperation, is a promising way to unleash the potential information of the data. However, FL’s multi-server collaborative operating architecture inevitably results in communication energy consumption between edge servers, which poses great challenges to servers with constrained energy budgets, especially wireless communication servers that rely on battery power. The device-to-device (D2D) communication mode developed for FL turns high-cost and long-distance server interactions into energy-efficient proximity delivery and multi-level aggregations, effectively alleviating the server energy constraints. A few studies have been devoted to D2D-enabled FL management, but most of them have neglected to investigate server computing power for FL operation, and they have all ignored the impact of dataset characteristics on model training, thus failing to fully exploit the data processing capabilities of energy-constrained edge servers. To fill this gap, in this paper we propose a D2D-assisted FL mechanism for energy-constrained edge computing, which jointly incorporates computing power allocation and dataset correlation into FL scheduling. In view of the variable impacts of computational power on model accuracy at different training stages, we design a partite graph-based FL scheme with adaptive D2D pairing and aperiodic variable local iterations of heterogeneous edge servers. Moreover, we leverage graph learning to exploit the performance gain of the dataset correlation between the edge servers in the model aggregation process, and we propose a graph-and-deep reinforcement learning-based D2D server pairing algorithm, which effectively reduces FL model error. The numerical results demonstrate that our designed FL schemes have great advantages in improving FL training accuracy under edge servers’ energy constraints.
1. Introduction
The explosive growth and widespread deployment of internet of things (IoT) devices has brought about unprecedented amounts of data, which contain valuable information that can be used by governments and enterprises in environmental monitoring, event trend prediction, and business decision making [1]. In the past, cloud computing and centralized artificial intelligence have been leveraged to derive hidden knowledge and actionable insight from the data. However, sending all the data to a cloud center causes bandwidth consumption and latency issues. The unprecedented scale and complexity of data generated by ubiquitously connected devices may outpace cloud service capabilities. Furthermore, these devices may belong to different owners who are unwilling to share raw data directly to the cloud center, due to privacy and security concerns.
In the context of edge intelligence, federated learning (FL)-empowered mobile edge computing (MEC) has arisen as a promising paradigm to address the excessive transmission overhead and information privacy issues [2]. MEC distributes multiple servers with powerful processing capabilities to the edges of IoT networks, allowing data analysis to occur near where the data are generated, thereby avoiding large-scale data transmission to the cloud center and reducing transmission costs and delays [3]. In practical IoT application scenarios, these edge servers can be service facilities powered by batteries or green energy sources, such as solar and wind energy, or they can be IoT devices with strong processing capabilities [4].
Serving as an appealing technology for edge computing systems, FL enables multiple edge servers to collaborate on developing shared models, but without directly sharing with one another the privacy-sensitive data that they each collect [5]. In FL, edge servers take their local data to train machine learning models locally. Then, the trained local models are periodically sent to a selected server for aggregation, and the aggregated global model is sent back to the edge servers for further training. The iteration of the collaborative training continues, until the model is fully trained. Servers participating in FL only need to upload local model parameters to the aggregation server rather than directly uploading their collected data, thus protecting user privacy [6]. However, long-term transmission of large amounts of local model data from edge servers to aggregators may bring about considerable energy overheads, especially when an edge server is far away from its aggregation server, with poor channel quality. Since some edge servers deployed in the wild are mostly powered by unstable green energy sources or batteries with limited capacity the energy efficiency of the FL process turns out to be a key issue to be investigated.
There have been extensive studies on energy-aware FL in edge computing environments. Some of these focused on client edge server selection or reducing the update frequency of local model data, thereby saving server energy consumption, while others concentrated on improving transmission energy efficiency through spectrum scheduling and power control. However, these measures either compromise the learning accuracy, due to an insufficient number of data samples, or lead to unsatisfactory performance, due to resource competition for data transmission between adjacent edge servers.
Device-to-device (D2D)-assisted FL has emerged as an appealing solution to lessen the data volume transferred between the edge servers and the aggregation servers while ensuring learning accuracy. That is, edge servers can be combined into cooperative pairs according to their energy availability and locations, where an edge server that is further away from the aggregation server and has a lower energy budget can send its local model data through other edge servers that act as relays and are closer to the aggregator. On the premise of reliable data delivery, shorter distance transmission can reduce the sending power of edge servers. Moreover, for those relay servers with powerful processing capabilities, they can also fuse the received model with their own local models and then upload them to the aggregation servers, thereby further reducing the amount of transmitted data and energy consumption.
One generally accepted benchmark to evaluate an FL solution is the difference between a learned model and its corresponding real model. However, most existing works on D2D-assisted FL only note the impact of the training set size on FL performance when designing FL schemes. They note that more training data sets yield more accurate learning models, but they usually ignore the effect of computing power on the FL results. In fact, for a given dataset, consuming more computing power for multiple learning iterations can also improve local model accuracy. Thus, neglecting or improper computing resource scheduling may seriously undermine FL efficiency.
Moreover, recently designed client pairing strategies in D2D FL only take account of the differences between clients in geographical locations and available energy, while always ignoring the possible differential characteristics of cooperating clients, in terms of training data generation. In some scenarios, such as FL clients training an IoT model based on data collected by sensors, different types of sensors may vary in data collection frequencies, generated data volumes, and information contained in a unit of data. These various characteristics may affect the accuracy of the local model trained by each client, change the collaboration efficiency between different D2D pairs, and further affect the overall performance of the federated learning system. However, the relationship between the features of training datasets and D2D collaboration patterns in FL scheduling is largely unexplored.
To fill these gaps, we propose a D2D-assisted FL mechanism for energy-constrained edge computing. Unlike the previous studies, we incorporate computing power into FL management and adjust the energy allocation between training processing and data transfer for each FL client based on the joint effect of computing power and dataset size on learning accuracy. Furthermore, a dataset-characteristic-aware FL scheme is proposed to exploit the effect of dataset correlation on improving model aggregation efficiency. Catering for complex and dynamic relations between heterogeneous clients, we leverage a graph theoretic approach to designing D2D-pairing and resource-allocation schemes, which maximizes FL accuracy under both energy and delay constraints. The main contributions of this paper are summarized as follows:
- We incorporate D2D communication into FL training so as to meet the energy constraints of edge servers while minimizing the training model error. In addition to the energy consumption of the wireless transmission of FL clients, the energy cost for model training at each client as well as its training performance are also considered in the FL scheduling.
- In order to jointly match FL clients in the training process, in terms of energy budget, computing power, and communication topology, we design a partite graph-based FL scheme with adaptive D2D pairing and aperiodic local iterations of the clients.
- We leverage graph learning to exploit the performance gain of dataset correlation between FL clients in the model aggregation process, and we propose a graph-and-deep reinforcement learning-based D2D pairing algorithm, which effectively reduces the model error of the FL.
The rest of this paper is organized as follows. In Section 2, we review related works. In Section 3, we introduce the system model. In Section 4, we propose a D2D-assisted FL scheme for clients with aperiodic local iterations. In Section 5, we further investigate the FL with correlated training datasets. A performance evaluation is presented in Section 6. Finally, we conclude our work in Section 7.
2. Related Work
Federated learning, as a promising distributed and privacy-preserving machine learning technology, has been explored and applied in various fields. In [7], the authors used FL to exploit the parallel-processing power of multiple servers for training mobile traffic-prediction models, and they devised a server-selection-and-dataset-management scheme for FL participation. In [8], the authors applied FL in radio frequency fingerprinting, and they developed a deep federated learning network, which facilitated distributed fingerprinting learning while ensuring privacy preservation within diverse networks. In [9], FL was utilized for resource allocation and device orchestration in non-orthogonal multiple-access-enabled industrial IoT networks, where a hierarchical FL framework was presented to reduce learning overheads. In [10], the authors designed an FL-based distributed algorithm to predict file popularity for edge caching arrangement, which solved user privacy issues in centralized approaches. With the rise of the new generation of wireless communications, FL has been used for a variety of radio automating, network slicing, and process orchestration. The authors in [11] comprehensively investigated FL-empowered mobile network management from the access to the core of 5G-beyond networks. The authors in [12] applied FL to the medical field, and they developed a privacy infrastructure based on federated learning and blockchain to provide a shared model of the spread of the COVID-19 virus.
As the distributed processing pattern of FL well-matches the multi-server architecture of MEC, the integration of FL and MEC has been extensively studied recently. For example, in [13] the authors introduced a clustered FL for mobile traffic-prediction MEC systems. By clustering the MEC servers based on their geographical location and data patterns, the learning straggler impact caused by the heterogeneity of the MEC servers was alleviated. The authors in [14] focused on the slow convergence of FL caused by learning-community changes, and they proposed a meta-learning-aided FL, where new clients could learn from other ones and quickly perform learning scene migration. In order to obtain accurate machine learning models for time-sensitive applications, the authors in [15] presented an age-aware FL framework, and they reduced the age of the data in MEC networks through data selection and aggregator placement. Considering that model parameters may be lost due to unreliable communication, thereby slowing down the FL training process, the authors in [2] devised a multi-layer computing architecture with dynamic epoch adjustment in FL-enabled MEC systems. To tackle management complexity caused by the continuous growth of user equipment, the authors in [16] proposed a multiple-layer framework with clustered clients to deploy FL algorithms on large-scale MEC networks. In [17], the authors aimed to address the problem that FL may malfunction in MEC systems, due to device heterogeneity, unstable channels, and unpredictable user mobility, and they proposed a multi-core FL framework to help FL algorithms to be implemented in MEC systems. In [18], the authors focused on the incentives for clients participating in FL, and they designed an incentive mechanism that selected high-quality edge nodes to contribute to FL training through a heuristic algorithm.
In order to reduce the energy consumption caused by parameter transmission in the FL training process, the authors in [19] proposed an energy-and-distribution-aware collaborative-clustering algorithm to select multiple IoT devices with sufficient energy as aggregation cluster heads. The authors in [20] developed a weight-quantization scheme to facilitate on-device local training over heterogeneous mobile devices. A mixed-integer programming problem was formulated to jointly determine quantization and spectrum allocation to minimize overall FL energy consumption. In [21], the authors investigated wireless-powered FL networks with non-orthogonal multiple access, and they introduced a two-dimensional search algorithm to minimize total energy consumption. In [22], the authors designed an energy-efficient FL scheme over cell-free IoT networks to minimize the energy consumption of IoT devices participating in FL. A wireless-energy-transfer-enabled hierarchical FL framework for heterogeneous networks with a massive multiple-input–-multiple-output wireless backhaul was developed in [23]. The authors saved energy costs through FL device association and wireless-transmitted energy management. In [24], the authors focused on renewable-energy-driven FL systems, and they leveraged reinforcement learning to adapt devices to intermittent renewable-energy supplies and to improve communication efficiency.
Few studies have investigated D2D-assisted FL mechanisms. In [25], the authors designed a hybrid blockchain architecture to enhance the security and reliability of model parameters sharing between FL D2D pairs, and they improved FL node selection through deep reinforcement learning. In [26], the authors developed a multi-stage hybrid FL approach, which orchestrated the devices on different network layers in a collaborative D2D manner to form consensus on the learning model parameters. The authors in [27] introduced a decentralized FL scheme that took D2D communications and overlapped clustering to enable decentralized device aggregation and to save energy consumption. In [28], the authors focused on the wireless communication efficiency of D2D FL, and they presented theoretical insights into the performance of digital and analog implementations of decentralized stochastic gradient descent in FL systems. To improve the scalability of Fl, the authors in [29] proposed a server-less learning approach that leveraged the cooperation of devices to perform data operations inside the network by iterating local computations and mutual interactions. In [30], the authors investigated energy-aware deep neural network model training, and they formulated an energy-aware and D2D-assisted FL problem to minimize the global loss of the training model.
Although the aforementioned studies have provided some useful insights and promising paradigms for FL scheduling, key factors, such as the impact of computing power on model accuracy and the correlation of training datasets, as well as the latency constraints of model training, have not yet been well-investigated. Furthermore, how to adaptively formulate D2D pairs between heterogeneous FL clients with complex communication topology remains a critical challenge. To fill this gap, in this paper, we leverage graph theoretic approaches to describe the relationships between FL clients and to obtain the joint schemes of D2D pairing and resource allocation, which improves the model accuracy of FL training.
3. System Model and Problem Formulation
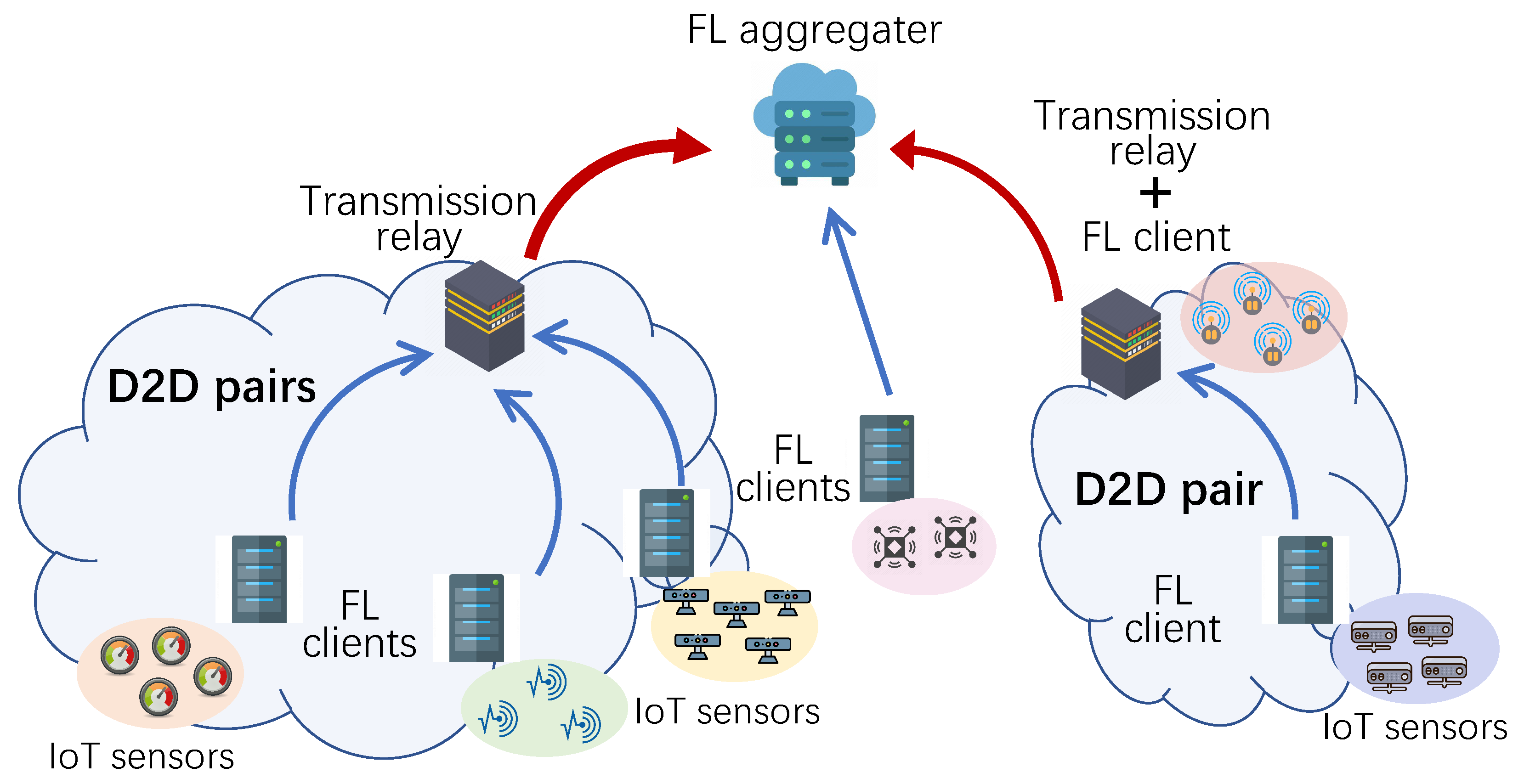
As shown in Figure 1, we consider D2D-assisted federated learning in an edge computing network for IoT applications. There are edge servers that jointly execute FL to obtain an IoT application model, such as traffic flow prediction and environmental monitoring. Servers with indexes 1 to N act as FL clients, and the server indexed with 0 acts as an aggregator. These clients are heterogeneous in terms of energy budget, local dataset generation, data processing capabilities, and geographical location. A deep neural network (DNN) model is deployed in these clients for training the IoT model [30].
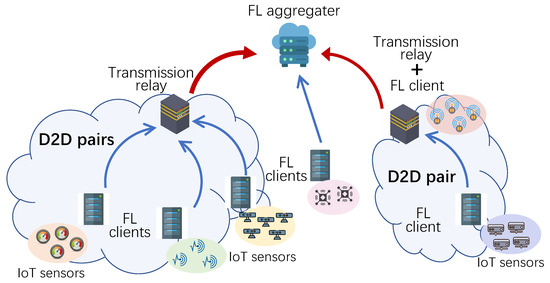
Figure 1.
D2D-assisted federated learning in an edge computing network.
Without loss of generality, the number of rounds for the entire FL system to run is defined as K. In each round, the client servers train their own local model parameters based on the datasets collected from IoT devices and upload them to the aggregation server. In the k-th round, the number of local training iterations taken by client server n before uploading its model parameters is given as . Then, based on these collected model parameters, the aggregation server generates a global model and distributes it back to the client servers.
Let denote the local dataset of server n generated in round k, and let be one data point in , where is the input features, is the label of the data point, and . The learning target of the FL running on server n is to train a DNN to minimize the error between the neural network output and label given input . The loss function training based on dataset can be defined as
where is a d-dimensional vector parameter of the trained DNN model, function l is a mean squared error or cross-entropy, and function is a monotonically increasing function of dataset size and local training iteration time [31].
Due to the constrained energy budget of the servers, energy conservation becomes a critical issue and can be addressed in two ways. The first is to reduce computing power costs—that is, each client server can selectively participate in the local model training process in each round. We adjust the energy consumption of server n participating in model training through variable . Another way to save energy is to reduce communication energy consumption. In each FL training round, a client can either not upload any locally trained model parameters or can directly transfer the parameters to the aggregation server or even use a relay node to submit parameters to the aggregation server in a D2D manner. The relay node is selected from the servers that act as clients in the FL training. We take to indicate that server n delivers parameters to relay m and vice versa, where , , and .
Given the time of client n to process a unit size of dataset, the training time for that client in round k is
The spectrum taken to transmit model parameters between the servers participating in the FL training is divided into Z orthogonal channels with bandwidth B, of which channels are used for the direct delivery of parameters from client or relay servers to the aggregation server, and the remaining channels are leveraged for client servers’ D2D communications. We assume that a channel can only be allocated to at most one server at the same time. Thus, at any given time and among the servers participating in FL, at most servers are allowed to directly upload to the aggregation server without violating bandwidth capacity limitations, while at most servers can conduct D2D interactions. Differently from existing studies that are limited to one-to-one D2D communication, we consider that all servers are equipped with broadband wireless receivers, which can support many-to-one D2D communication and receive model parameters from multiple D2D paired servers simultaneously. When server n obtains a channel to communicate with server m its transmission rate can be expressed as
where and are the transmission power of server n and the distance between server n and m, respectively; is the white noise of the channel; is the channel gain at a reference distance of one meter; and is a constant.
Let the the data amount of the model parameters generated by server n training be . Server n may also act as a relay node in round k. In such a case, it will fuse the parameters passed to it by another client server with the model parameters it has trained and then deliver the fusion result to server 0. The fused model parameter at server n is
where is an indicator function that equals 1 if is true and is 0 otherwise. It is noteworthy that the training and transmission process of server and the local training of server n can be carried out simultaneously. Thus, the time cost for server n in the k-th round of FL, which consists of local model training time, D2D model gathering time, and model parameter transmission time, can be calculated as
When the FL system runs in a synchronous mode, in each round, the aggregation server needs to obtain the uploaded parameters from the latest client before it can aggregate the model. Therefore, the time consumption of the k-th round is expressed as
Next, we discuss the energy cost of these clients. Let denote the energy cost of server n to process a unit size of dataset in one local training iteration. The energy consumption of server n in round k is
Moreover, in addition to the energy consumed by model training, there is also an energy cost when a client transmits model parameters to a relay server or the aggregation server. The transmission energy consumption is expressed as
where is the data size of the model parameters trained by server n, and and . Based on (7) and (8), we can obtain the total energy consumption of server n in the kth round of FL as
In round k, the uploaded local models from both client or relay servers are aggregated at server 0 as
Then, server 0 distributes the aggregated model to all the client servers for the round of training. Since server 0 only takes parameter aggregation its processing cost is negligible. Moreover, model distribution is carried out in the form of a broadcast with a fixed delay. Therefore, we focus on minimizing the expectation of the loss function of these client servers under given constraints by scheduling their model training and parameter transmission. The formulated optimization problem is as follows:
where . In (11), constraints C1 and C2 guarantee that the energy allocated for the model training and parameter transmission of each client server should not exceed its energy budget and that the time cost for K rounds of FL should under maximum delay constraint, respectively. Constraints C3 and C4 ensure that the number of client servers performing direct delivery to server 0 in parallel and the number of client servers performing D2D communication simultaneously cannot exceed their respective maximum channel capacities. Constraint 5 states that for any client server, it cannot communicate with more than one target object at the same time. Constraint C6 indicates the possible value range of and .
4. Partite Graph-Based FL Scheme with Adaptive D2D Pairing and Aperiodic Local Iterations
As (11) is an integer programing problem, it is proved to be NP-complete. To address problem (11), in this section, we leverage the graph theoretic approach, and we propose a partite graph-based FL scheme, which minimizes the learning loss function through adjusting D2D pairing and agent local iterations.
Since the energy budget of edge servers is limited, how to improve learning efficiency under energy constraints has become a key issue in FL scheme design. In a traditional FL mechanism, the edge servers as learning clients always perform fixed numbers of local iterations before each aggregation to a central server. However, in practical edge computing applied to the IoT, the dataset gathered by each edge server may follow non-IID (Identical and Independently Distributed), which always cause differences in the local models trained by the edge servers. The differences vary with time and become worse as the number of iterations increases. If model aggregation is implemented in the early iteration of the edge server, excessive differences between local models may cause serious deviations in the aggregation model, thereby reducing learning accuracy. In addition, the transmission of model parameters in the aggregation process also brings unnecessary communication energy costs. Thus, the aggregation time needs to be optimally selected.
Given the maximum FL rounds K, for server n, subject to its energy limitation, the number of iterations in each round, denoted as , satisfies the following relationship:
We consider the loss function to be -smooth, i.e., for any and ,
This loss function is also -quasi-convexity; that is, for and any , we have
Moreover, the gradient of has an upper bound, which can be described as the existence of and , such that
and
where is a mini-batch dataset sampled from randomly.
For client server , when its loss function meets the above conditions, the server’s local iteration number in K FL rounds is an arithmetic sequence with a tolerance of ; that is, [32]. Therefore, we can obtain the entire iteration sequence of each client server by calculating its first iteration number and .
We have
where H is a positive constant that satisfies and
according to (12). Since the number of FL aggregation rounds affects the values of and , we use an iterative optimization approach to update it. The initial value of the aggregation round K is calculated as
Considering that these client servers may have different iteration times and computing energy consumption in each round of FL aggregation, we select the servers with sufficient energy surplus as the relay nodes in the D2D pairs. Moreover, in order to aggregate as many local models trained by client servers as possible under the condition of limited communication channels, it is also necessary to optimize the organization of D2D pairs and schedule the delivery time of non-relay nodes to relay nodes to support the concurrent communication of multiple D2D pairs while improving spectrum efficiency. Thus, based on the obtained iteration numbers of these client servers, we propose a partite graph-based D2D pairing scheme, as follows.
First, the client servers are divided into clusters through a voting approach. Here, is the maximum number of channels used by the client servers to directly deliver local model parameters to the aggregation server, and limits the number of relay nodes working in parallel. For a given server n in FL round k, we calculate the energy cost of delivering its local model parameters to the aggregation server with the relay help of another server m, where and . The relay node with the smallest energy consumption is recorded as . If
then cast one vote for relay node ; otherwise, no vote will be taken. After traversing all server nodes and completing the voting, we select the nodes with the highest votes as relay servers and divide the client servers that voted for the same relay server into a cluster. For the other servers that did not vote or had lower votes we choose the relay server with the lowest energy consumption to join the corresponding cluster.
Next, we build a complete J-partite graph within each cluster. Let denote this graph, where represents the set of vertices consisting of the servers in the cluster and is the set of edges connecting these nodes. Take any two vertices n and from , and if
then connect n and to form an edge. Then, divide the vertices in into J disjoint subsets to form a complete J-partite graph. In this graph, no two graph vertices within the same set are adjacent but there are edges between vertices that belong to different subsets. The divided subsets satisfy a sequential relationship, in terms of time cost; that is, the sum of the maximum training time of the servers in subset and the time of transmission to the aggregation server should be no more than the minimum training time of the servers in subset , where and . This relationship can be represented as
By dividing such J subsets, client servers with similar model training times belong to the same subset, while server training times in different sets have a sequential relationship. In each round of FL, an edge server can be selected from each subset to aggregate to the relay server in graph . Due to the difference in training time of these edge servers, the communication times between the edge servers and the relay server have no overlap, thereby reducing co-channel communication interference and improving transmission efficiency.
The client servers in these J subsets are selected, based on priority, to train local models and aggregate parameters to relay servers. The priority of server n in FL round k is determined jointly by the server’s remaining energy and its model training efficiency, which can be calculated as
where and are positive coefficients. In order to normalize the priority, we put into a softmax function to obtain the probability of each server being selected, which is depicted as
The server with the highest probability will be selected first, which is denoted as . Let represent the neighbor servers of server n in graph . The next server to be selected is the one with the highest probability belonging to . This server selection process continues until the currently selected server has no available new neighbors. Then, these selected servers train their local models, respectively, according to their specified number of iterations , aggregate their local models on relay server , and, finally, all the relay severs distributed in clusters pass their model parameters to the aggregation server for one global aggregation, thereby completing the kth round of FL.
As the remaining energy of the servers changes and the running time elapses, the total number of FL rounds K also changes. After the kth FL round is completed, the remaining FL round number is updated as
In the th round, the number of iterative training of each server is redetermined, the relay servers and client servers are selected through the constructed partite graph, and the model parameters are aggregated again. The process iterates until the updated FL round reaches 0. The main steps of the proposed partite graph-based FL scheme are summarized as Algorithm 1.
The computational complexity of Algorithm 1 primarily arises from the construction of partite graphs in all FL rounds. From step 1 to step 15, the formation of clusters takes time, as the system consists of N vertices. The construction of partite graphs in each round also takes time, which depends on the number of vertices. Therefore, the computation complexity of Algorithm 1 can be estimated by , since it takes K FL rounds.
| Algorithm 1 Partite graph-based FL algorithm |
|
During the operation of the partite graph-based D2D pairing scheme, when a server fails, it will be handled in two cases. First, if the server has been selected as a relay node, the scheme needs to proceed from step 10 of Algorithm 1 to re-select the relay nodes and further reconfigure the D2D pairing relations. On the other hand, if the server is not acting as a relay node, then the failed server only needs to be removed from the partite graph and stopped from sending its local model to its pairing server. When the network is split and some paired servers lose their pairing relationship due to unreachable communication, it is necessary to perform step 23 of Algorithm 1 to re-match relay servers for these independent client servers.
5. Graph Learning-Enabled D2D Pairing in Dataset-Correlated FL
When taking FL to obtain IoT application models, the information contained in the datasets collected by each agent may seriously affect the training performance. Moreover, the correlation between the datasets used by client agents may also affect the efficiency of the FL model aggregation. For instance, for using sensors to monitor mountainous areas and constructing their environmental models, the model generated by aggregating sensor datasets with overlapping or adjacent monitoring areas is always more accurate than the model corresponding to aggregating non-correlated areas. Based on the above considerations, in this section, we will explore the gain of dataset correlation between client servers in model aggregation process, and leverage graph learning and deep reinforcement learning (DRL) to propose a D2D-assisted FL scheme.
Let denote the model training gain brought about by the aggregation of client server n and relay server m due to their dataset correlation in the k-th round of the FL iteration. Since there exists a complex and implicit relationship between the datasets correlation and the model gains, it is difficult to give an explicit formula for . Thus, we use a graph to present this relationship, which can be denoted as . Here, is the set of vertices, composed of FL client servers, and is the set of edges between the vertices. The edge between any two vertices only exists when their corresponding servers n and satisfy
In graph , is the attribute of vertex n, such as the collection place and collection frequency of the dataset used by the server corresponding to n, and the server’s remain energy budget.
We use to denote the features embedded in vertex n in round k of the FL, which can be calculated as
where and and are parameters of the l-th layer of the graph neural network and is the neighbor vertices of vertex n. Based on the formulated graph, the model training gain is represented as
In (28), is the negative sampling distribution of server n, and
Here, we leverage the cosine embedding loss function to calculate the embedding similarity between server n and m, as well as the negative sample embedding dissimilarity between the server pairs [33]. In the cosine function, and are the norms of vectors and , respectively, where
Next, is normalized to , which is shown as
Based on (31), the loss function defined in (1) can be redefined as
Then, an optimization problem, which concerns the dataset collaboration between the FL client servers, is formulated as
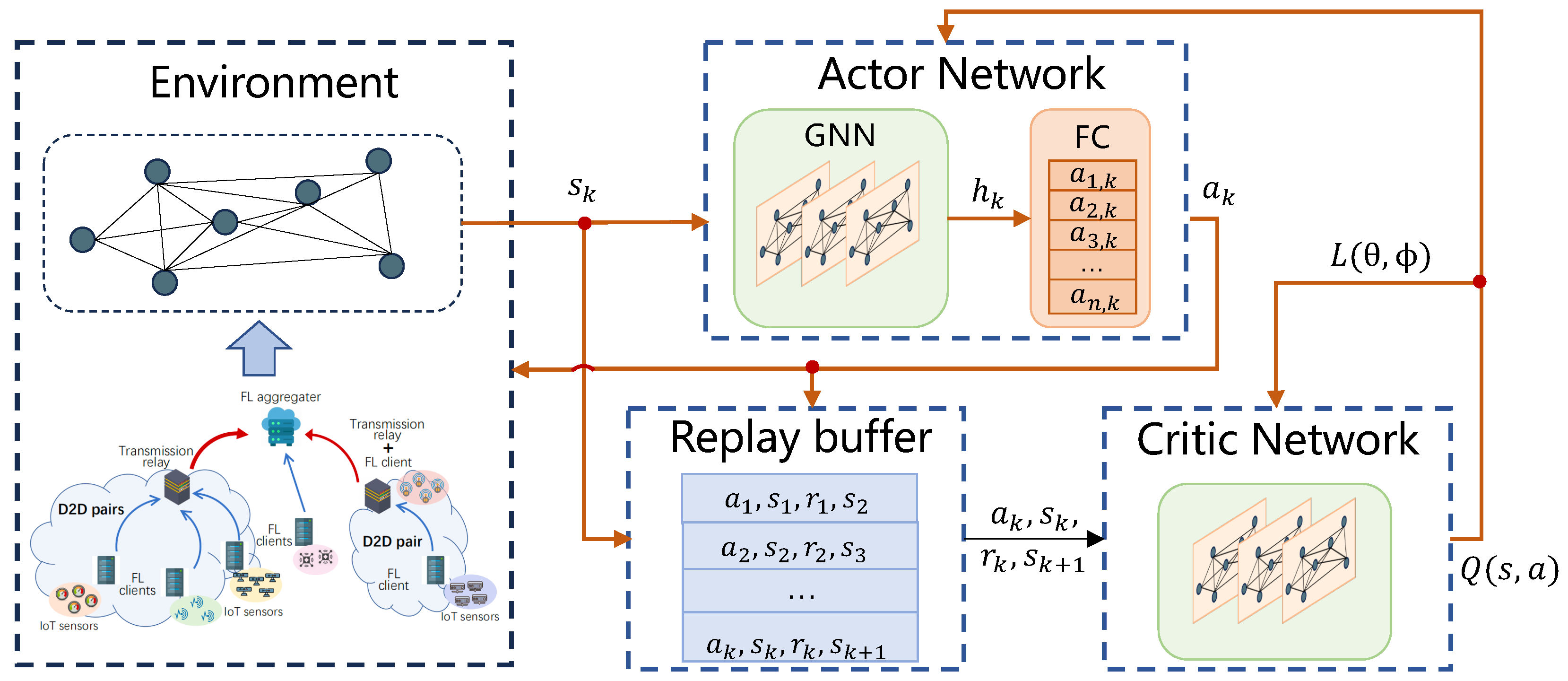
To address (33), we turn to a DRL approach and propose a graph-and-deep reinforcement learning D2D pairing scheme for FL, whose main framework is shown in Figure 2. The framework consists of four parts: environment, actor network, critic network, and replay buffer. The environment is graph reflected from the FL-empowered edge computing network. The actor network is constructed as a graph neutral network (GNN) inference framework, which takes the as input states, realizes reasoning through message forward propagation between vertices in this graph, and helps draw the D2D pairing and local training action of the FL servers. The critic network uses the same GNN structure as the actor network to evaluate the FL server action. The replay buffer stores learning experience, allowing the agents to learn from early memories to speed up learning.
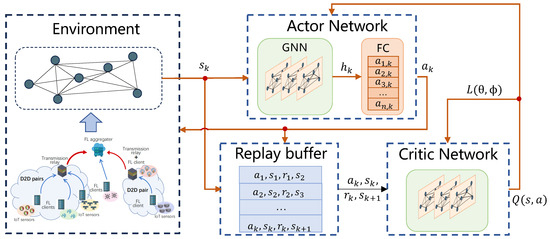
Figure 2.
Graph-and-deep reinforcement learning D2D pairing scheme.
Since the FL running process contains K rounds, and the states of the servers participating in the learning in each round are only related to the states of the previous round, the whole FL operation can be modeled as a Markov process. Let the state of the Markov process be denoted as , where is the attribute of server n in round k and can be obtained from . contains two elements. One is the correlation between the datasets of server n and server , and the other one is the remaining energy of server n in the k-th round, and they are denoted as and , respectively.
The GNN learns the embedded feature of each graph vertex in the next state by aggregating the features of its neighboring vertices. The neighborhood information aggregation of vertex n in layer l can be shown as
where is the neighborhood set of vertex n, is the parameter of the GNN, is an aggregation function, denotes the concat operation that combines the aggregated neighbor information with the features of vertex n itself in to obtain the new embedding , and l is the number of the layers in the GNN. In order to avoid over-fitting during the GNN training process, l is set to 3. The initial embedded feature of the GNN is set as .
The action taken by these servers in round k is represented as . It is noteworthy that in order to reduce the size of the action space we define the server action as , where is the selected head of the cluster where server n belongs to in the k-th round, , and . Here, we take to indicate the D2D pairing relationship of the servers, i.e., server n uses D2D transmission to aggregate its local model parameters to server in the FL round k. Moreover, we should note that action is equivalent to variable in (33), whose value is set to 1. For element in action vector , indicates that server n participates in local model training in the k-th FL round, and vice versa. Subject to the number of D2D communication channels, at most servers in each cluster can participate in training in one FL round. When , the local iteration number of server n in round k, which is denoted as , can be calculated following the arithmetic sequence approach described in Section IV. The size of the action space of is . The reward function of this Markov process in round k is given as
In the deep reinforcement learning, given state s at training time t while taking action a, the Q value is
where is a discount factor. To minimize the optimal action strategy to be chosen is
To obtain in the actor network, after all the vertices in the graph complete neighborhood information aggregation, we use a fully connected layer to obtain the action probabilities. The fully connected layer consists of the MLP function and the softmax function, and it can be written as
In (38), is the probability of taking action , and the action with the highest probability will be considered as the optimal choice.
Based on the chosen optimal action, the state at the next step represented as can be obtained. Then, the action that satisfies all the constraints in (33), the current state, the next state, and the reward form a tuple , which will be stored in the replay buffer. Next, a batch of the experience will be sampled from the replay buffer and will be put into the critic network to evaluate of action executed in state . The PPO (proximal policy optimization) strategy is taken to train the actor network parameter and the critic network parameter , where the loss function is expressed as
where S is an entropy function, is the evaluation of the critic network, , is the discount factor, and . The first term on the right side of (39) is the PPO loss, which is the core optimization target of the PPO strategy; is a ratio that measures the improvement of the new policy over the old policy; is an advantage function, which indicates the superiority of action relative to the average strategy, and can be calculated by the difference between the reward and the value function . The clip function modifies the surrogate objective by clipping the probability ratio, which removes the incentive for moving outside of interval , where is a hyperparameter [34]. The second term is used to update the value function, which represents the difference between the current state and the actual reward , calculated using squared-error loss. The third term is the entropy regularization term; is the entropy of the policy . The larger the value of , the more random and exploratory the policy is, which can help prevent the policy from converging to a suboptimal solution in the early training stage; and are weight coefficients. To sum up, we describe the main procedure of the graph learning-enabled D2D pairing scheme in Algorithm 2. In Algorithm 2, we first initialize the parameters of graph G, the actor network, the critic network, and the clipping ratio , and we clear the replay buffer, which is a data structure for temporarily saving the agents’ observations and allowing our learning procedure to update on them multiple times. Then, the algorithm enters a loop with episodes. Each episode consists of K iterations. In each iteration, given the current state , we obtain action of the actor network according to (37). Then, we calculate the reward and obtain the new state caused by executing action . The tuple is stored in the replay buffer for future parameter updates. If the condition in step 15 of Algorithm 2 is met, it means that the training time or energy consumption exceeds the limit, and the iteration of this episode will be terminated. Otherwise, I tuple records will be randomly selected from the replay buffer as samples for PPO strategy training, and the parameters of the actor and critic networks will be updated by maximizing the value of . The above process is repeated until the preset maximum number of episodes is reached.
| Algorithm 2 GNN-and-DRL-based D2D pairing algorithm |
|
The computational complexity of Algorithm 2 derives from several key parts: policy evaluation (Critic), policy update (Actor), experience replay and sampling, and the FL rounds. In each time step, the Critic network computes the state value or action value through a forward pass. The Critic network is an L layer GNN, and the forward pass and backpropagation complexity is , where the vertex features have two dimensions and the network has parameters. The Actor network computes the policy through a forward pass in each time step using an L layer GNN. The complexity of the forward pass and updating parameters is , where the actor network has parameters. Storing each time step’s state, action, reward, and next state into the experience replay buffer has a complexity of . Sampling a mini-batch from the experience replay buffer for training has a complexity of , where B denotes the batch size. The algorithm runs for K FL rounds and episodes, so the overall complexity is .
It is noteworthy that Algorithm 2 can be applied to large-scale network scenarios. In a sense, this algorithm can be taken as a server clustering approach, in which the relay servers act as cluster heads while the client servers act as cluster members. The models trained by cluster members are distributively aggregated at their corresponding cluster heads and then delivered to the aggregation server. When the number of servers in the network increases, more servers will be selected as cluster heads to share the model aggregation load of the aggregation server.
6. Numerical Results
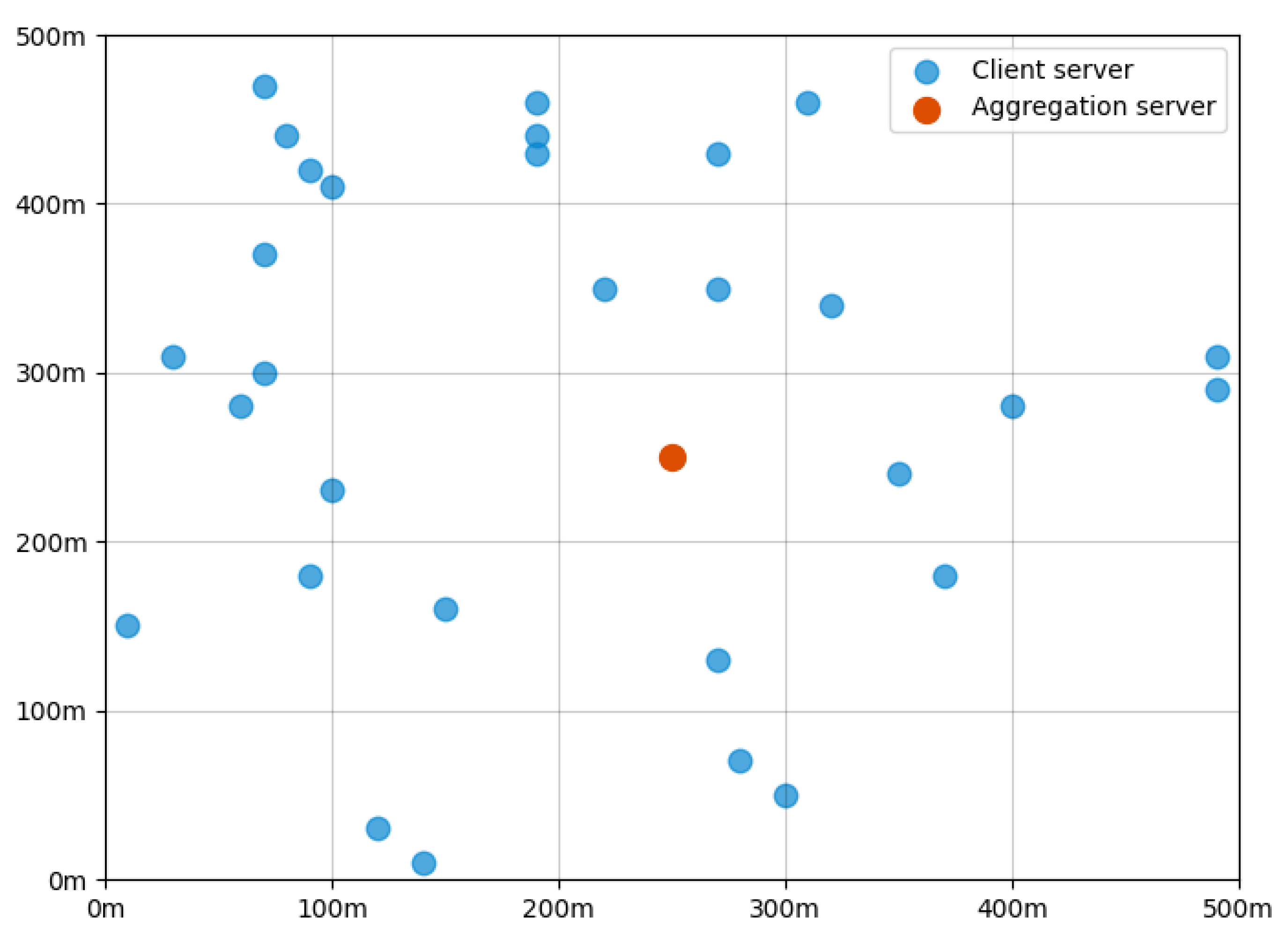
In this section, we evaluate the performance of our proposed D2D-assisted adaptive FL schemes through experimental simulations. We consider an FL-enabled edge network that consists of 30 edge servers randomly deployed in a rectangular area with a side length of 500 m, together with an aggregation server located within the center of the area. The edge network scenario is shown in Figure 3. The energy budget and the energy cost for processing a unit-sized dataset of the servers are randomly selected from and following continuous uniform distributions, respectively. We use the MNIST and CIFAR-10 datasets to evaluate our proposed schemes. MNIST is a large database of handwritten digits and CIFAR-10 is a collection of 60,000 32 × 32 color images, which are commonly used for training various image-processing systems and have been widely leveraged for the performance evaluation of FL schemes [35]. We use the these two datasets instead of IoT images collected through camera sensors to test our designed schemes. The learning task is to identify the objects showing in the dataset images. Moreover, to make the datasets follow non-IID distribution, we sort and divide the datasets into subsets and then randomly assign a number of these shards to each edge server, according to McMahan, B. et al. [36].
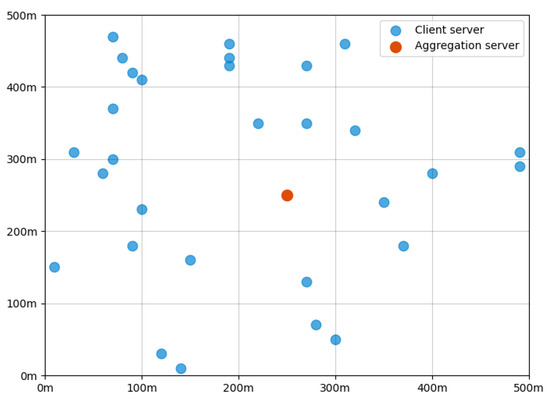
Figure 3.
Deployment of servers in an edge computing network.
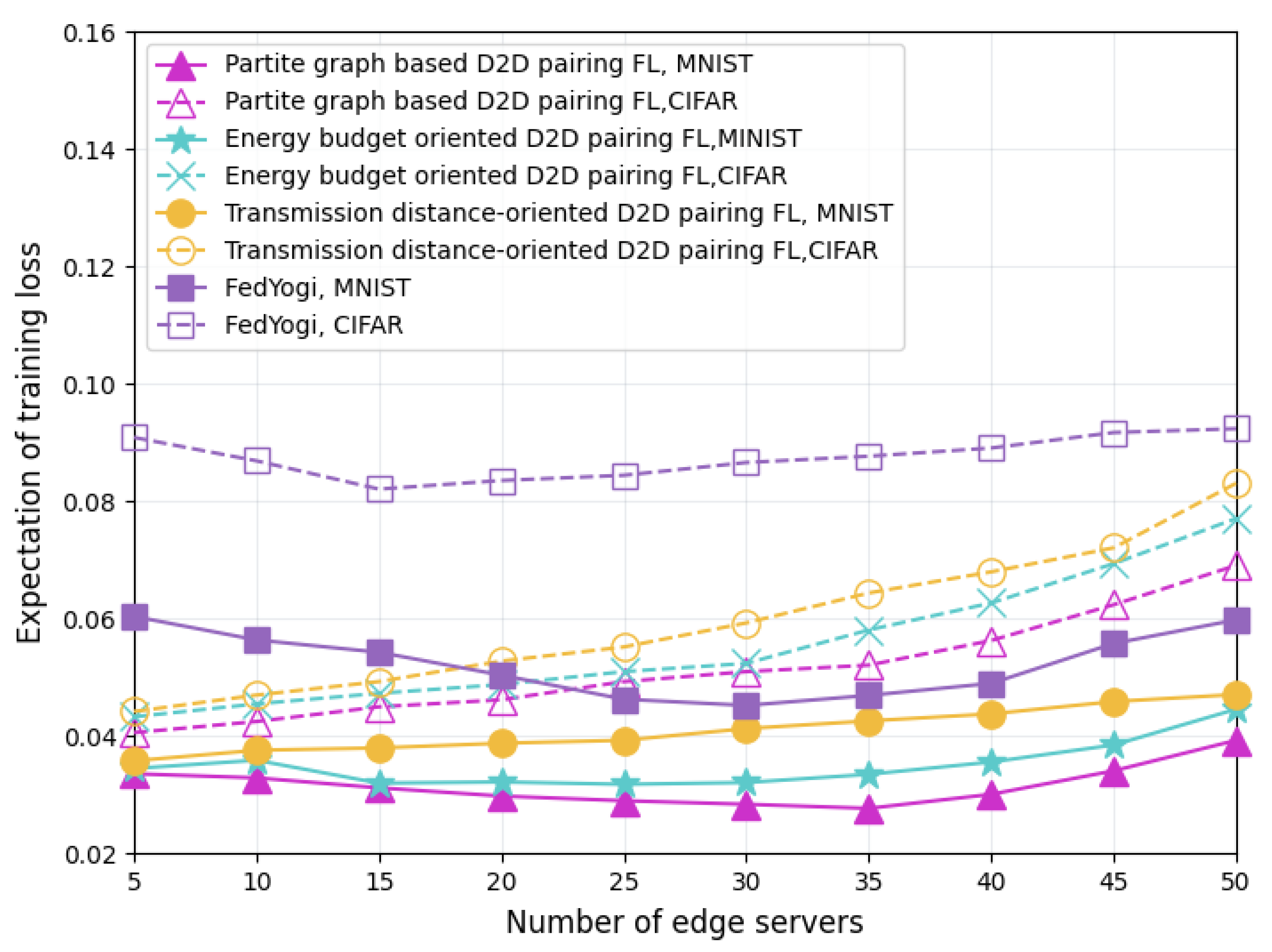
Figure 4 compares the training loss of dataset-uncorrelated FL schemes using the MNIST and CIFAR-10 datasets. The benchmarks selected for this performance comparison are the energy budget-oriented D2D pairing FL scheme, the transmission distance-oriented D2D pairing FL scheme, and the FedYogi FL scheme [37]. Compared with these benchmark schemes, our proposed partite graph-based FL scheme yields the lowest loss expectation when applied to both datasets. Although FedYogi can flexibly adjust the learning rate, its aggregation process does not consider the energy budget constraints and the communication topology of the edge servers participating in the FL. Thus, due to the energy exhaustion caused by intensive model training and long-distance parameter transfer, some servers may exit the FL model aggregation process prematurely and, finally, produce the highest model training loss. The energy budget-oriented FL allocates both local model training and parameter data relay tasks to the servers with the most remaining energy but ignores the impact of communication topology on the transmission energy overhead. It wastes part of the energy available for model training on unnecessary remote data delivery. Contrary to the energy budget-oriented FL, the transmission distance-oriented FL scheme only pays attention to the difference in transmission energy consumption affected by the geographical location of the servers in the designing of its operation process. Therefore, it fails to fully utilize the training capabilities of energy-constrained servers. Unlike the above two D2D-assisted FL mechanisms, our proposed partite graph-based FL jointly matches the edge servers in the training process, in terms of energy budget, computing power, and communication topology. Moreover, we exploit the differential effect of server computing power on model accuracy in different FL iterations, and we further optimize the server computing power allocation, thereby improving server-training energy efficiency and obtaining the lowest loss expectation.
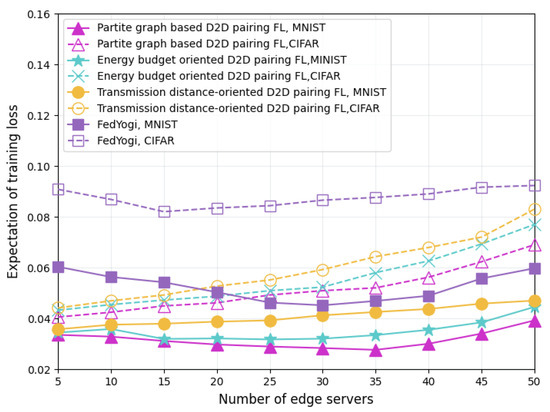
Figure 4.
Comparison of training loss with different FL schemes.
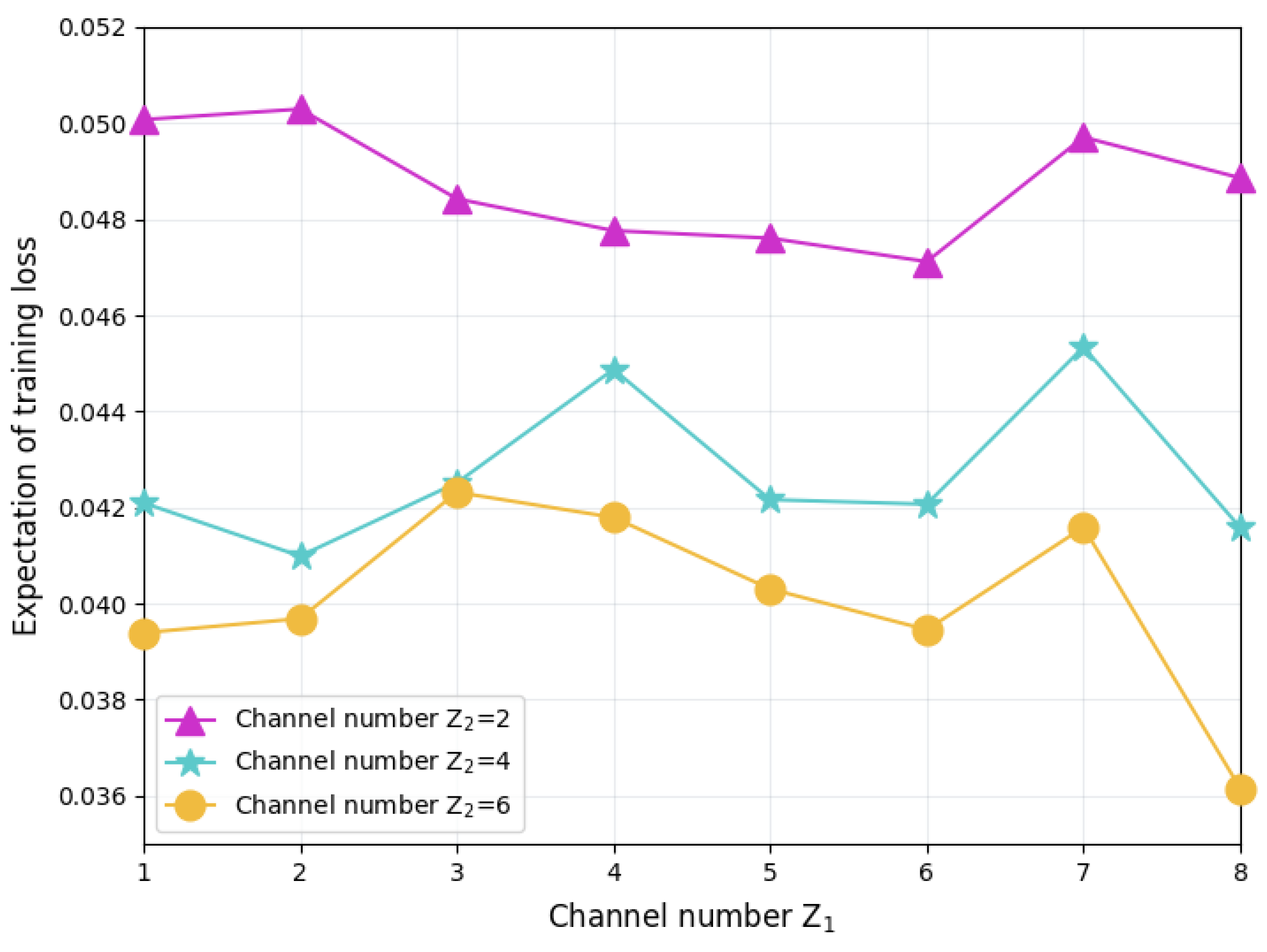
Figure 5 shows the training loss of FL performed in networks with different numbers of wireless channels. Given the number of channels used for direct delivery between client servers and aggregation servers, which is denoted as , the training loss decreases as the number of D2D communication channels increases, but this decreasing trend gradually weakens as increases. When Z2 increases from 2 to 4, although the D2D communication capacity between the FL servers has improved, due to the densely deployed 30 servers, only four channels still have difficulty supporting the complete spatial-division multiplexing of the spectrum resources. However, with six channels, spectrum spatial-division multiplexing in server-dense areas can be achieved, thereby supporting more concurrent D2D model aggregation between servers, thereby reducing the training loss. In contrast to the above phenomenon, when is fixed, the training loss does not show an obvious changing trend with the increase of , and the loss value fluctuates. Since the increase of can promote D2D aggregation between client servers, the results of this figure demonstrate that distributed model aggregation has better training improvement than simply adjusting the central aggregation number.
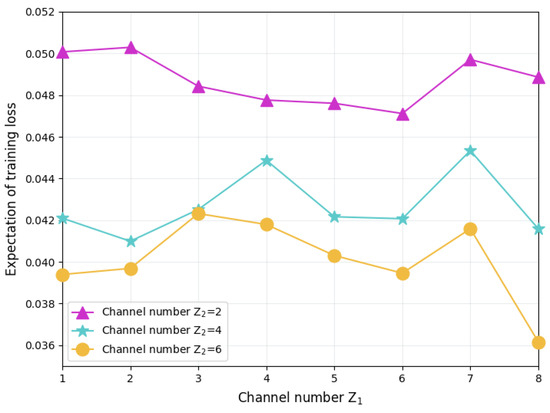
Figure 5.
FL training loss in networks with different numbers of wireless channels.
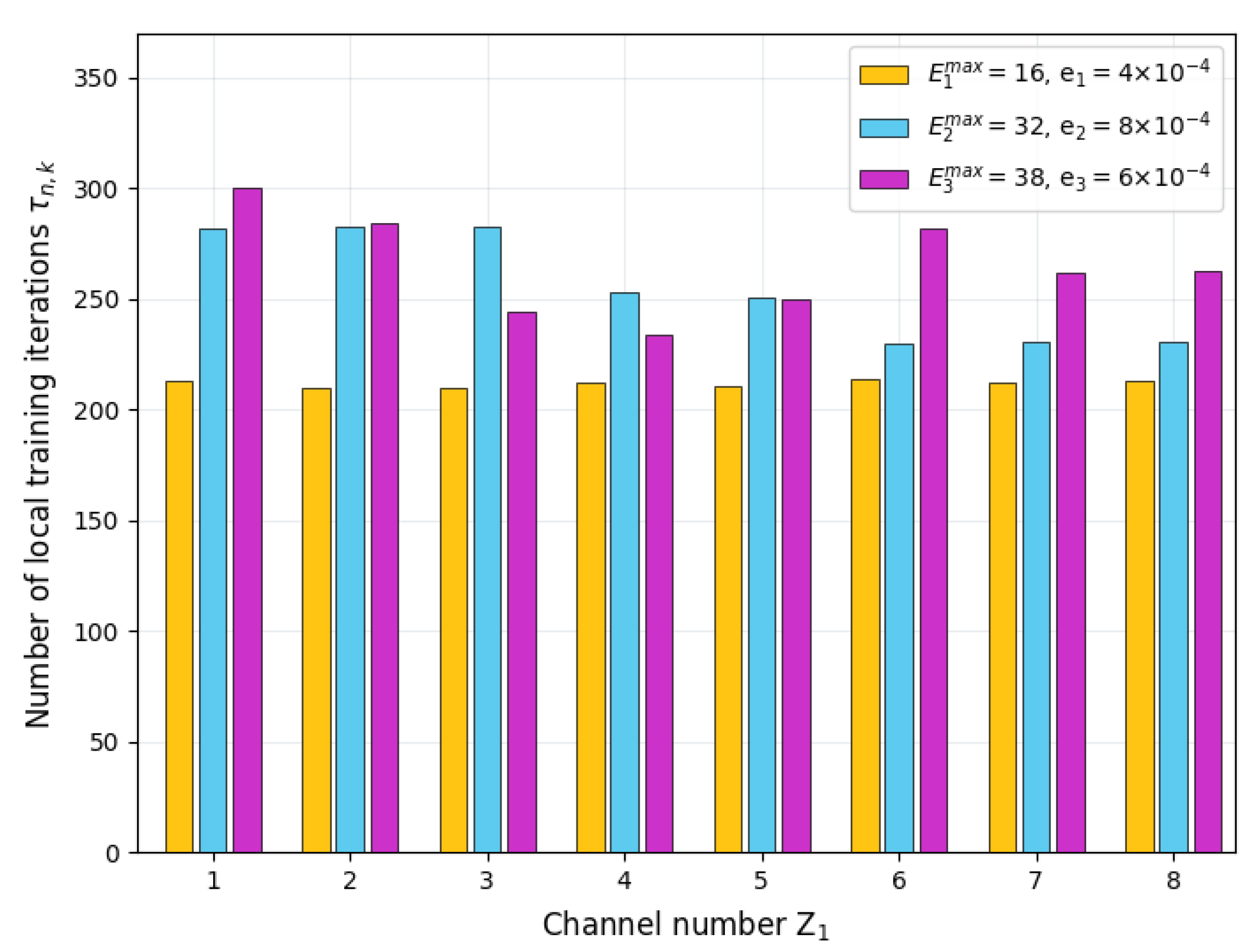
Figure 6 presents the number of local training iterations for the servers with different energy budgets. Without loss of generality, we select three servers with different energy budgets to demonstrate their total number of local training iterations during the entire FL process. For the server with an energy budget value of 16, its total iteration number remains constant as channel number changes. This is because the task of the server with low energy budgets is to train local models and transfer its trained model parameters to adjacent servers with sufficient energy in a D2D manner. The growth of does not affect the server’s tasks or the local training arrangements. For the server with an energy budget of 32, the total number of iterations shows a downward trend as increases. The increase of results in more servers that can serve as relays. The servers with more energy budget but less computation capability may take on the job. Subject to their energy budget, these servers may reduce the number of local training iterations, thereby ensuring energy supply for relay transmission. As the number of relay servers increases, the servers with an energy budget value of 38 are able to deliver model parameters in D2D mode with lower energy costs, so more energy can be used for local training; consequently, the total number of iterations is increased.
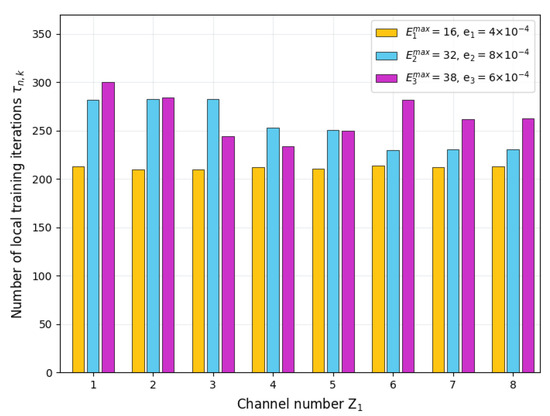
Figure 6.
Number of local training iterations for servers with different energy budgets.
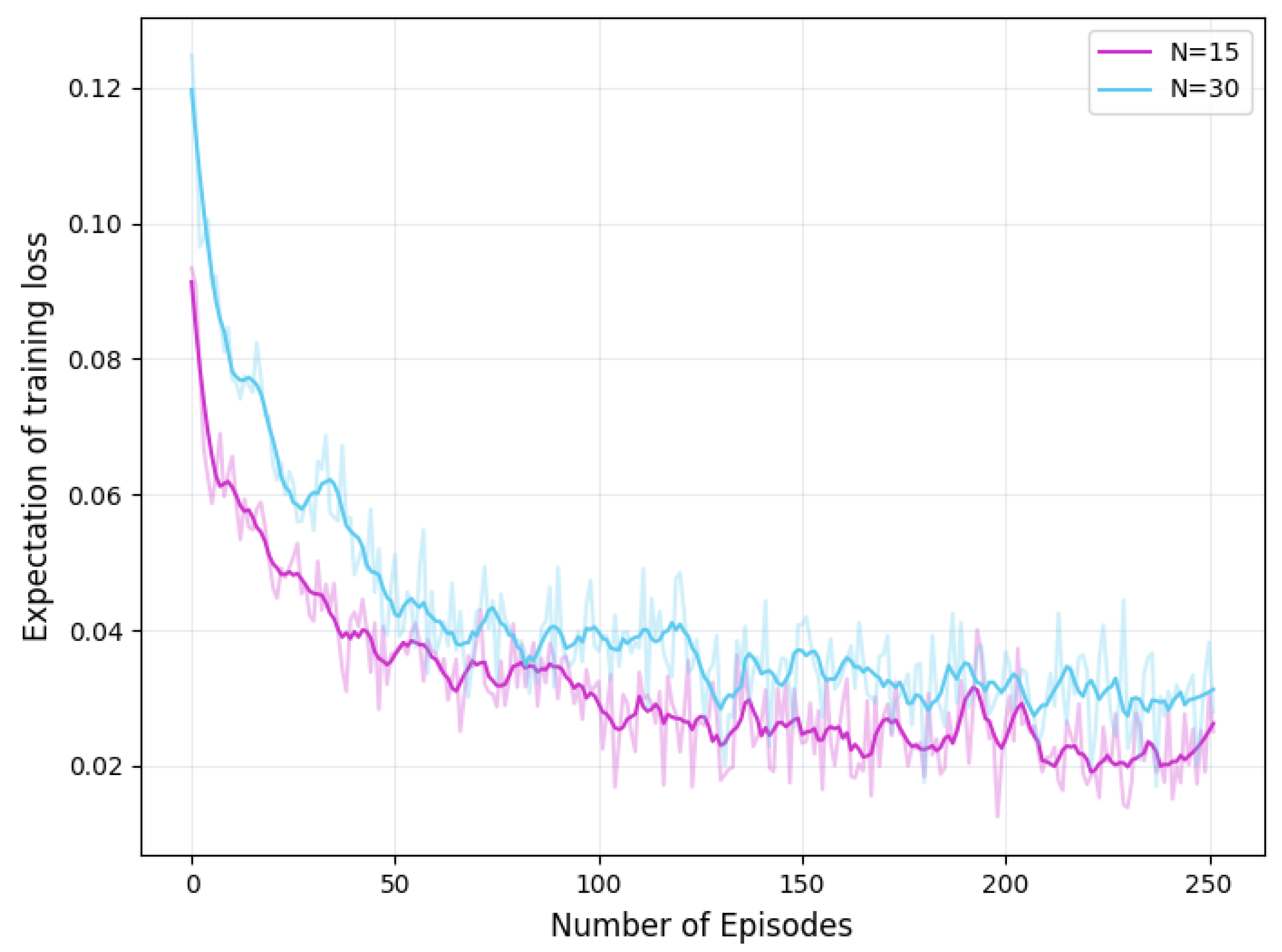
Figure 7 shows the convergence of the proposed GNN-and-DRL-based D2D pairing algorithm in scenarios with different numbers of edge servers, respectively. The varying number may lead to changes in the edge network’s total energy budget, computing power, and dataset distribution among adjacent servers. Despite the difference of edge network size and these varying factors all the FL training loss expectations obtained by our GNN-and-DRL-based D2D pairing algorithm converge around 100 episodes.
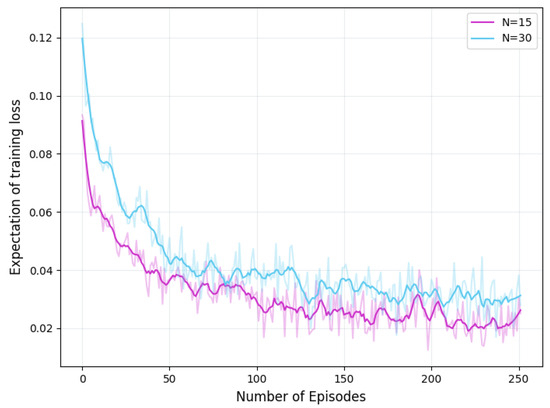
Figure 7.
Convergence of GNN-and-DRL-based D2D pairing algorithm.
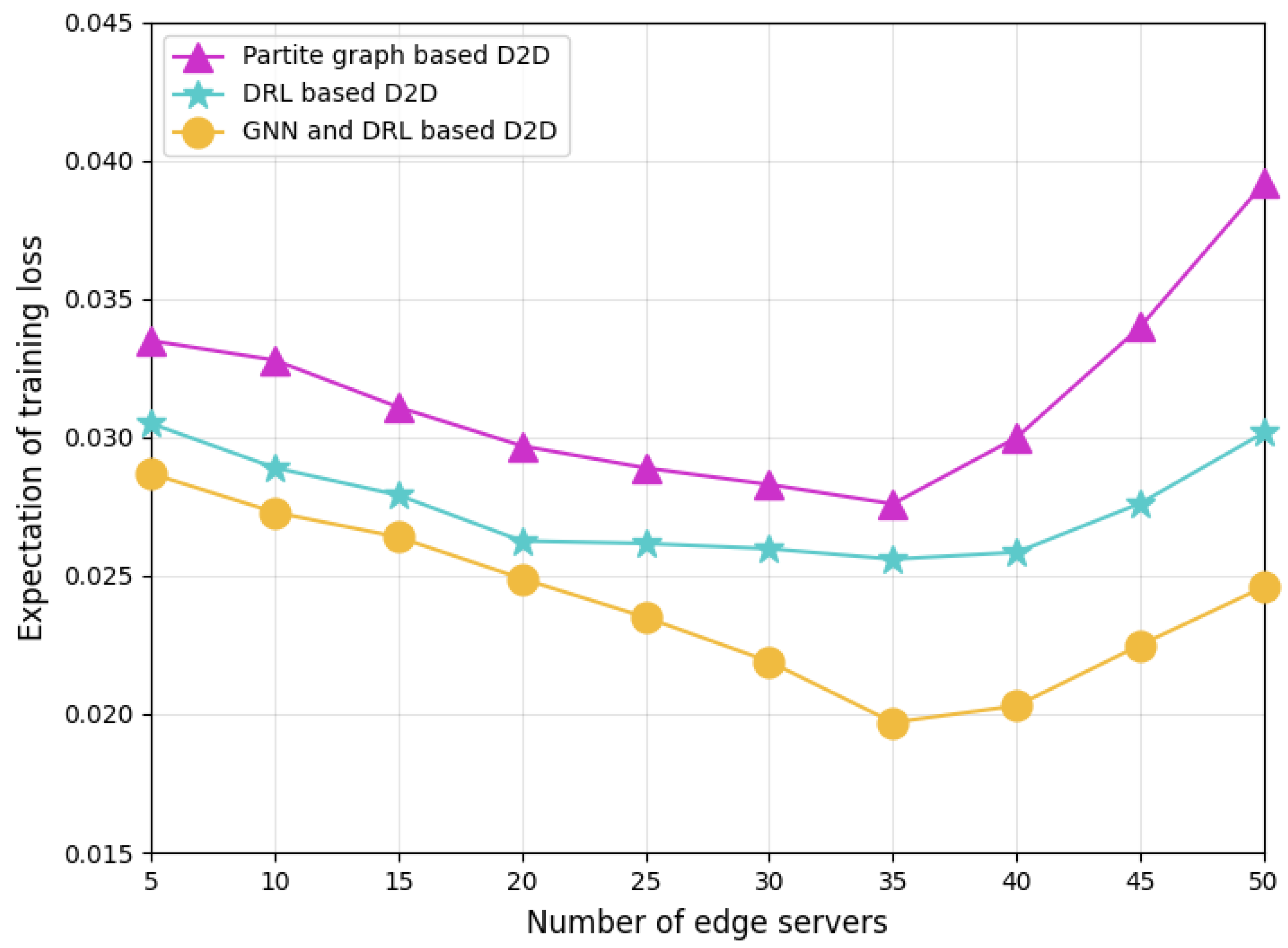
Figure 8 compares the loss performance of different D2D pairing schemes training their models with correlated datasets. Our proposed GNN-and-DRL-based pairing scheme outperforms other baseline schemes with the lowest training loss. The partite graph-based pairing scheme aggregates edge servers only according to servers’ communication topology and energy budget, but ignores the correlation between the datasets used by different servers for local model training. As a result, its training performance is the worst. In FL, as typical distributed multi-agent model training, the correlation of datasets leads to the correlation of the trained models. Therefore, using dataset correlation to guide model aggregation may improve the convergence of the aggregation model, thereby reducing the training loss value. Although the DRL-based scheme considers dataset correlation in the D2D server pairing process, it only maps the correlations to hyper-parameters of an individual DRL agent, whose improvement in FL model training is limited. In our designed GNN-and-DRL-based pairing scheme, the dataset correlation between servers, and the server’s current energy surplus, computing power, and D2D communication characteristics are reflected to the attributes of the nodes and edges of the formulated graph. Benefiting from the diffusion of these attributes across servers through the GNN, our scheme can better coordinate the server pairing, thereby achieving lower training loss, especially in networks with a large number of servers.
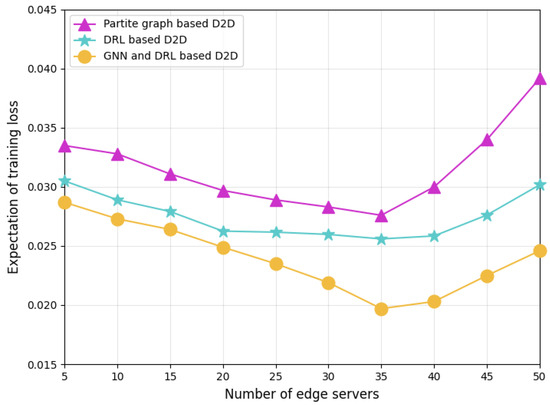
Figure 8.
Training loss comparison of different D2D pairing schemes.
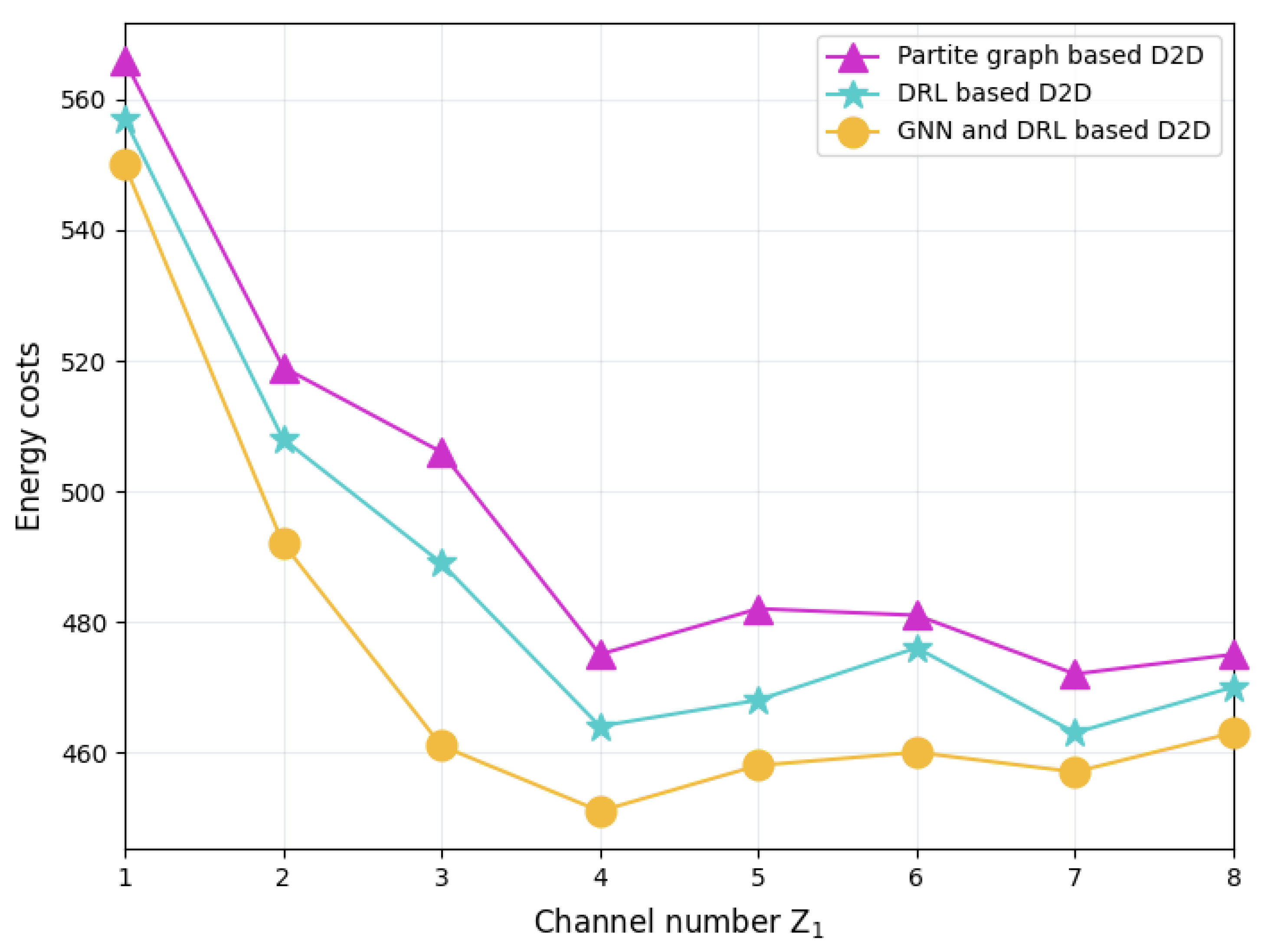
Figure 9 shows the total energy cost of the FL system with different schemes. Compared with the other two schemes, the GNN-and-DRL-based D2D pairing scheme not only achieves optimal training loss performance, but also effectively reduces the total energy consumption of the FL system. The reason is that this scheme takes into account the communication topology between servers as well as the correlation between training datasets in its server aggregation management, thus significantly saving the communication energy cost in model parameter delivery while also reducing the energy consumption for iterative local training before reaching model convergence. Moreover, it can be seen from the figure that the energy costs of all schemes decrease as grows. As the number of channels increases, more edge servers can become relay nodes, aggregate the local models of surrounding servers in a D2D manner, and then report the model parameters to the aggregation server. The newly emerged relay nodes allow the edge servers to choose a closer relay server to deliver its local model, thus saving transmission energy consumption. However, this energy-saving effect gradually weakens as increases. The reason is that when is greater than 4, there are enough relay nodes to provide D2D transmission services for all the edge servers.
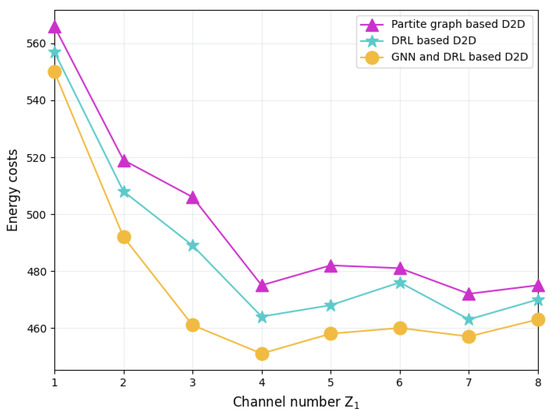
Figure 9.
Total energy cost of FL system with different schemes.
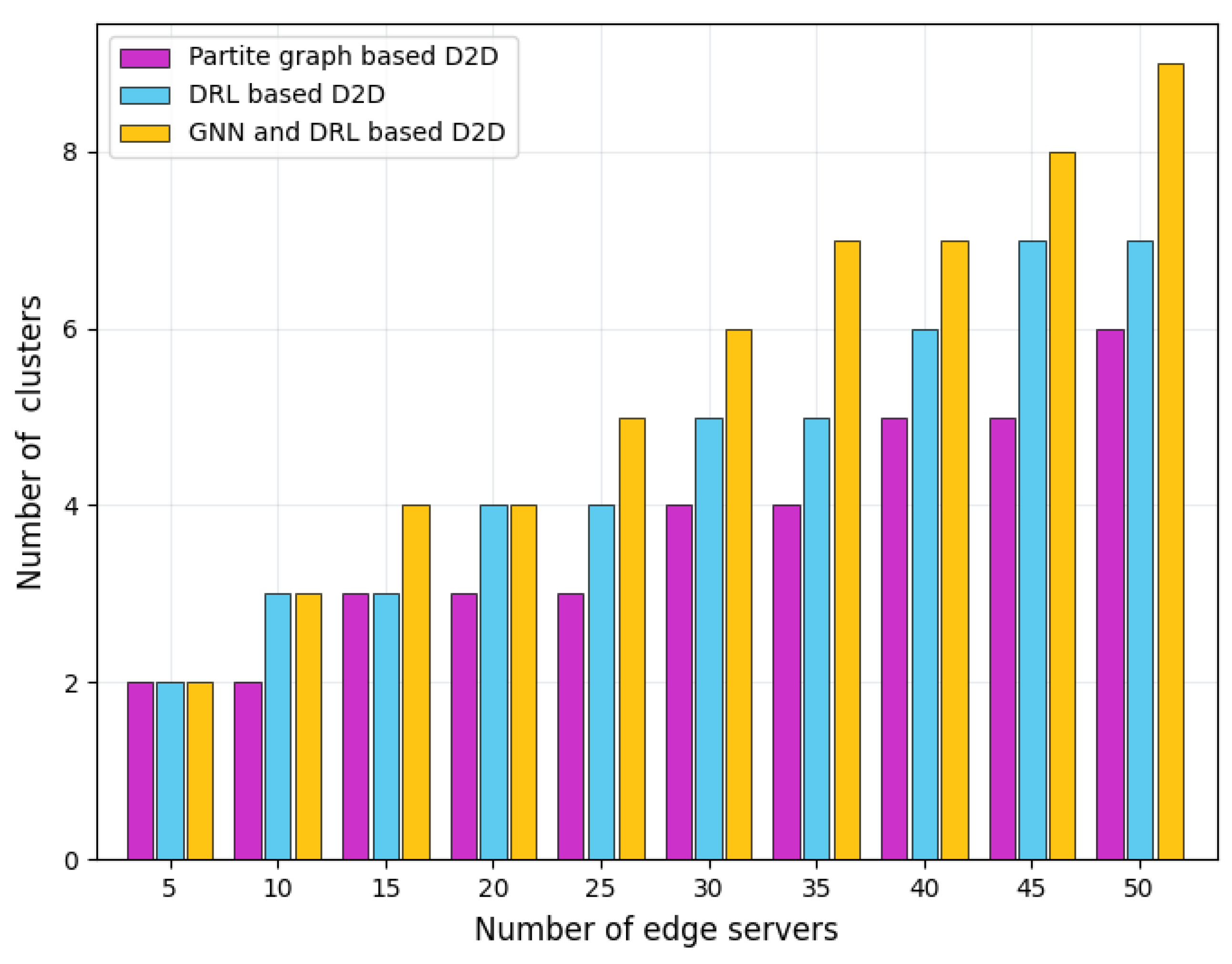
Figure 10 depicts the number of server clusters with different schemes. It is easy to see that with the expansion of the edge computing network scale and the increase in the number of edge servers, the number of clusters formed by these three schemes gradually increases, but at different growth rates. The partite graph-based D2D pairing scheme has the slowest growth in the number of clusters, while our GNN-and-DRL-based scheme has the fastest growth. This is because the partite graph-based scheme mainly focuses on the communication topology between servers. As long as the transmission distance between the servers and the existing relay servers meets the aggregation requirements, the scheme will not trigger the generation of new clusters. In addition to considering the network communication topology, our designed GNN-and-DRL-based scheme further incorporates dataset correlation between different servers into the cluster formulation, thereby optimizing the arrangement of server clusters and improving FL training accuracy. The DRL-based scheme maps the topological relationship between servers and the correlation of datasets into hyperparameters. Some specific features of the correlation may be lost in the mapping process. Therefore, the change in the number of edge servers may not lead to a significant impact on the DRL hyperparameters, which slows down the growth of the number of server clusters.
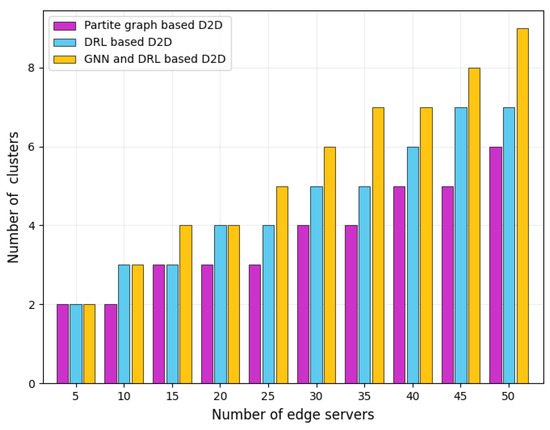
Figure 10.
Number of server clusters with different schemes.
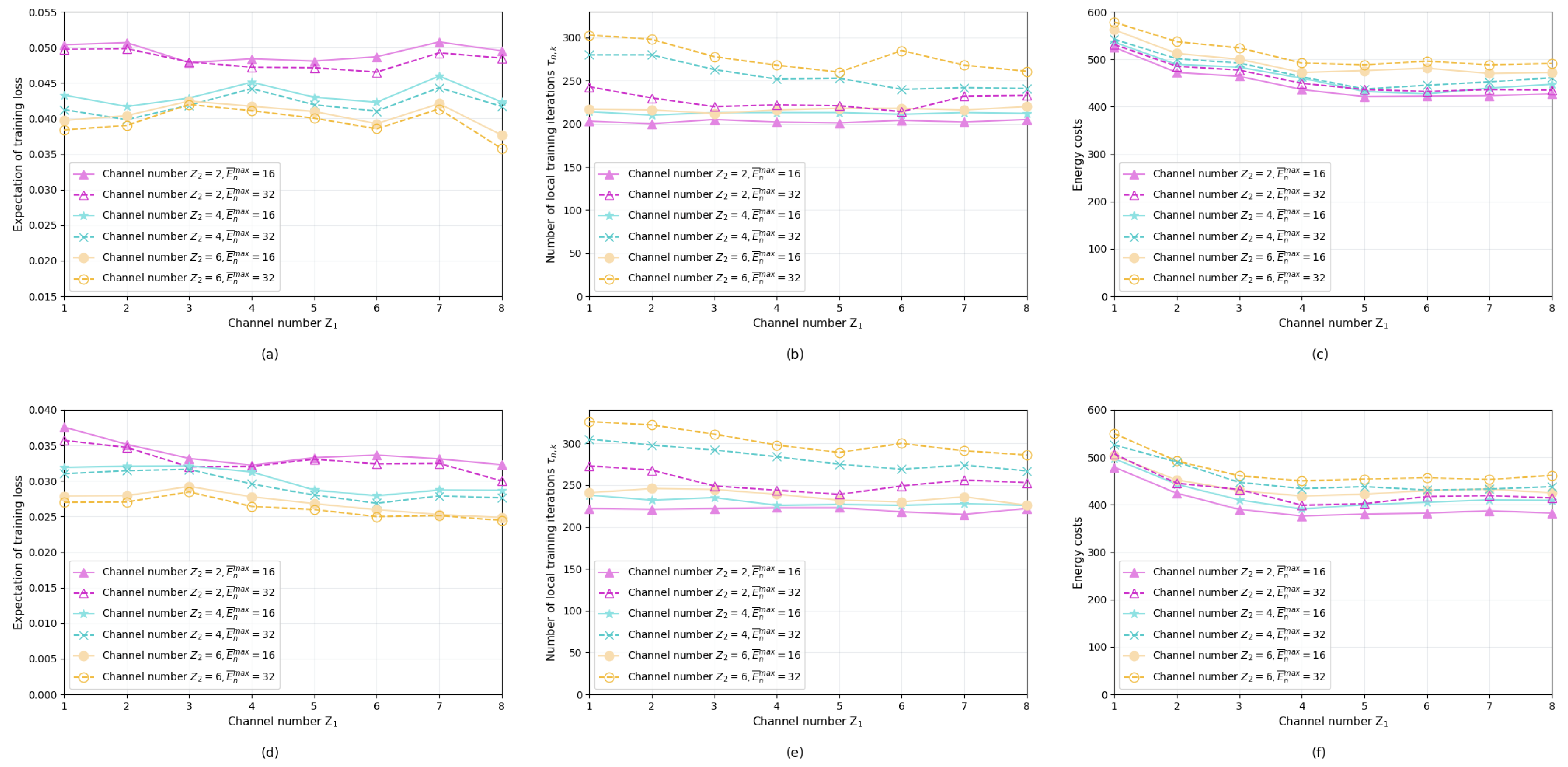
Figure 11 shows the training loss values, the local iteration numbers, and the energy costs of the proposed two schemes alongside the configuration parameters of the wireless channel numbers and energy budget restrictions. Subgraphs (a), (b), and (c) present the performance of Algorithm 1, while subgraphs (d), (e), and (f) correspond to the performance of Algorithm 2. Through the joint comparison of sub-figures (a), (b), and (c) it can be seen that the number of channels has a stronger impact on performance than the number of channels , especially on the training loss value and the number of local training iterations. When the number of is reduced to 2, regardless of the value of energy budget or the value of , the training loss increases significantly compared with when is 4 or 6. This observation suggests that too few channels may limit D2D model aggregation between the servers, thus undermining the overall training performance of the FL. In subgraph (b), when both and are large, the number of local training iterations of the servers increases significantly compared to other scenarios. This is because a rich energy budget and large D2D transmission capacity prompt the servers to conduct sufficient local training before sharing model parameters in a D2D approach. Unlike subgraphs (a) and (b), the energy costs presented by subgraph (c) are less affected by and , but it shows a slow downward trend as increases. The growth number of means that more servers can directly interact with the aggregation server, reducing the energy costs of model parameters’ relay forwarding. In subfigures (d), (e), and (f), the performance of Algorithm 2 with these configuration parameters has characteristics similar to Algorithm 1.
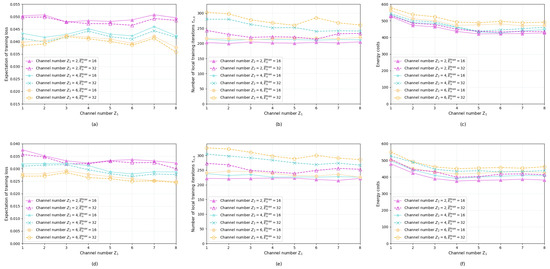
Figure 11.
Training loss, local iteration numbers and energy costs of different schemes. (a) Training loss of Algorithm 1; (b) Iteration number of Algorithm 1; (c) Energy cost of Algorithm 1; (d) Training loss of Algorithm 2; (e) Iteration number of Algorithm 2; (f) Energy cost of Algorithm 2.
7. Conclusions
In this paper, we investigated FL-enabled mobile edge computing networks, and we presented a D2D-assisted FL mechanism that improves learning accuracy for energy-constrained servers. Making use of the time-varying impact of server computing power on model accuracy, we proposed an adaptive FL scheme with energy-aware D2D server pairing and aperiodic local training iterations in a partite graph theoretic approach. Moreover, we leveraged graph learning to exploit the performance gain of dataset correlation between servers in FL training, and we designed a graph-and-deep reinforcement learning-based server pairing algorithm, which further improves model aggregation efficiency. Finally, we evaluated the performance of the proposed algorithms through experimental simulations. The numerical results demonstrate that our designed FL schemes are promising, in terms of both training accuracy improvement and server energy saving compared with the benchmark algorithms.
Author Contributions
System model construction and problem formulation, Z.L. and Y.C.; scheme design, K.Z., Y.Z., Y.C. and Y.L.; performance evaluation, Y.Z. and K.Z.; writing—original draft, K.Z. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key R&D Program of China under Grant 2021YFB3202904.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets presented in this article are not readily available because the data are part of an ongoing study. Requests to access the datasets should be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- De Vito, S.; D’elia, G.; Ferlito, S.; Di Francia, G.; Davidović, M.D.; Kleut, D.; Stojanović, D.; Jovaševic-Stojanović, M. A global multiunit calibration as a method for large-scale IoT particulate matter monitoring systems deployments. IEEE Trans. Instrum. Meas. 2023, 73, 1–16. [Google Scholar] [CrossRef]
- Xiang, T.; Bi, Y.; Chen, X.; Liu, Y.; Wang, B.; Shen, X.; Wang, X. Federated learning with dynamic epoch adjustment and collaborative training in mobile edge computing. IEEE Trans. Mob. Comput. 2024, 23, 4092–41061. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, J.; Hu, T.; Chang, Z.; Zhang, Y.; Min, G. Federated learning-assisted vehicular edge computing: Architecture and research directions. IEEE Veh. Technol. Mag. 2023, 18, 75–84. [Google Scholar] [CrossRef]
- Zhang, X.; Chang, Z.; Hu, T.; Chen, W.; Zhang, X.; Min, G. Vehicle selection and resource allocation for federated learning-assisted vehicular network. IEEE Tran. Mob. Comput. 2024, 23, 3817–3829. [Google Scholar] [CrossRef]
- Zhang, K.; Cao, J.; Zhang, Y. Adaptive digital twin and multiagent deep reinforcement learning for vehicular edge computing and networks. IEEE Trans. Ind. Inform. 2022, 18, 1405–1413. [Google Scholar] [CrossRef]
- Qiang, X.; Hu, Y.; Chang, Z.; Hamalainen, T. Importance-aware data selection and resource allocation for hierarchical federated edge learning. Future Gener. Comput. Syst. 2024, 154, 35–44. [Google Scholar] [CrossRef]
- Kim, D.; Shin, S.; Jeong, J.; Lee, J. Joint edge server selection and dataset management for federated learning-enabled mobile traffic prediction. IEEE Internet Things J. 2024, 11, 4971–4986. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, D.; Ren, P.; Yu, K.; Guizani, M. DFLNet: Deep federated learning network with privacy preserving for vehicular LoRa nodes fingerprinting. IEEE Trans. Veh. Technol. 2024, 73, 2901–2905. [Google Scholar] [CrossRef]
- Zhao, T.; Li, F.; He, L. DRL-based joint resource allocation and device orchestration for hierarchical federated learning in NOMA-enabled industrial IoT. IEEE Trans. Ind. Inform. 2023, 19, 7468–7479. [Google Scholar] [CrossRef]
- Lin, N.; Wang, Y.; Zhang, E.; Yu, K.; Zhao, L.; Guizani, M. Feedback delay-tolerant proactive caching scheme based on federated learning at the wireless edge. IEEE Netw. Lett. 2023, 5, 26–30. [Google Scholar] [CrossRef]
- Lee, J.; Solat, F.; Kim, T.Y.; Poor, H.V. Federated learning-empowered mobile network management for 5G and beyond networks: From access to core. IEEE Commun. Surv. Tutorials 2024, accepted. [Google Scholar] [CrossRef]
- Samuel, O.; Omojo, A.B.; Onuja, A.M.; Sunday, Y.; Tiwari, P.; Gupta, D.; Hafeez, G.; Yahaya, A.S.; Fatoba, O.J.; Shamshirband, S. IoMT: C COVID-19 healthcare system driven by federated learning and blockchain. IEEE J. Biomed. Health Inform. 2023, 27, 823–834. [Google Scholar] [CrossRef] [PubMed]
- Solat, F.; Kim, T.Y.; Lee, J. A novel group management scheme of clustered federated learning for mobile traffic prediction in mobile edge computing systems. J. Commun. Netw. 2023, 25, 480–490. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, Y.; Ma, W.; Guo, B.; Xu, L.; Duong, T.Q. Accelerating convergence of federated learning in MEC with dynamic community. IEEE Trans. Mob. Comput. 2024, 23, 1769–1784. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, L.; Liang, W.; Xia, Q.; Xu, W.; Zhou, P.; Rana, O.F. Age-aware data selection and aggregator placement for timely federated continual learning in mobile edge computing. IEEE Trans. Comput. 2024, 73, 466–480. [Google Scholar] [CrossRef]
- You, C.; Guo, K.; Yang, H.; Quek, T.Q.S. Hierarchical personalized federated learning over massive mobile edge computing networks. IEEE Trans. Wirel. Commun. 2023, 22, 8141–8157. [Google Scholar] [CrossRef]
- Bai, Y.; Chen, L.; Li, J.; Wu, J.; Zhou, P.; Xu, Z.; Xu, J. Multicore federated learning for mobile-edge computing platforms. IEEE Internet Things J. 2023, 10, 5940–5952. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Zeng, R.; Yang, M.; Li, K.; Huang, M.; Dustdar, S. VARF: An incentive mechanism of cross-silo federated learning in MEC. IEEE Internet Things J. 2023, 10, 15115–15132. [Google Scholar] [CrossRef]
- Lee, J.; Ko, H. Energy and distribution-aware cooperative clustering algorithm in Internet of Things (IoT)-based federated learning. IEEE Trans. Veh. Technol. 2023, 72, 13799–13804. [Google Scholar] [CrossRef]
- Chen, R.; Li, L.; Xue, K.; Zhang, C.; Pan, M.; Fang, Y. Energy efficient federated learning over heterogeneous mobile devices via joint design of weight quantization and wireless transmission. IEEE Trans. Mob. Comput. 2023, 22, 7451–7465. [Google Scholar] [CrossRef]
- Alishahi, M.; Fortier, P.; Hao, W.; Li, X.; Zeng, M. Energy minimization for wireless-powered federated learning network with NOMA. IEEE Wirel. Commun. Lett. 2023, 12, 833–837. [Google Scholar] [CrossRef]
- Zhao, T.; Chen, X.; Sun, Q.; Zhang, J. Energy-efficient federated learning over cell-free IoT networks: Modeling and optimization. IEEE Internet Things J. 2023, 10, 17436–17449. [Google Scholar] [CrossRef]
- Hamdi, R.; Ben Said, A.; Baccour, E.; Erbad, A.; Mohamed, A.; Hamdi, M.; Guizani, M. Optimal resource management for hierarchical federated learning over HetNets with wireless energy transfer. IEEE Internet Things J. 2023, 10, 16945–16958. [Google Scholar] [CrossRef]
- Cui, Y.; Cao, K.; Wei, T. Reinforcement learning-based device scheduling for renewable energy-powered federated learning. IEEE Trans. Ind. Inform. 2023, 19, 6264–6274. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Hosseinalipour, S.; Azam, S.S.; Brinton, C.G. Multi-stage hybrid federated learning over large-scale D2D-enabled fog networks. IEEE/ACM Trans. Netw. 2022, 30, 1569–1584. [Google Scholar] [CrossRef]
- Al-Abiad, M.S.; Obeed, M.; Hossain, J.; Chaaban, A. Decentralized aggregation for energy-efficient federated learning via D2D communications. IEEE Trans. Commun. 2023, 71, 3333–3351. [Google Scholar] [CrossRef]
- Xing, H.; Simeone, O.; Bi, S. Federated learning over wireless device-to-device networks: Algorithms and convergence analysis. IEEE J. Sel. Areas Commun. 2021, 39, 3723–3741. [Google Scholar] [CrossRef]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated learning with cooperating devices: A consensus approach for massive IoT networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef]
- Li, Y.; Liang, W.; Li, J.; Cheng, X.; Yu, D.; Zomaya, A.Y.; Guo, S. Energy-aware, device-to-device assisted federated learning in edge computing. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2138–2154. [Google Scholar] [CrossRef]
- Zhang, K.; Cao, J.; Maharjan, S.; Zhang, Y. Digital twin empowered content caching in social-aware vehicular edge networks. IEEE Trans. Comput. Soc. Syst. 2022, 9, 239–251. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, T.; Cheng, S.; Liu, J. Aperiodic local SGD: Beyond local SGD. In Proceedings of the 51st International Conference on Parallel Processing, Bordeaux, France, 29 August 2022. [Google Scholar]
- Xing, P.; Lu, S.; Wu, L.; Yu, H. BiG-Fed: Bilevel optimization enhanced graph-aided federated learning. IEEE Trans. Big Data 2022, accepted. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10 December 2018. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.Y.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2023, arXiv:1602.05629. [Google Scholar]
- Nabavirazavi, S.; Taheri, R.; Ghahremani, M.; Iyengar, S.S. Model poisoning attack against federated learning with adaptive aggregation. In Adversarial Multimedia Forensics; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 1–27. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).