
Investigation of Structural Seismic Vulnerability Using Machine Learning on Rapid Visual Screening



Abstract
1. Introduction
Novelty of the Research
2. Materials and Methods
2.1. Dataset Description
- “Black”: The category suffering the most severe damages. Structures belonging to this label suffered partial or total collapse during the earthquake, crossing the so-called Collapse Limit State (CLS).
- “Red”: While the structures belonging to this label did not cross the CLS, they suffered extensive damages to their structural members and crossed the so-called Ultimate Limit State (ULS).
- “Yellow”: Structures of this category suffered only moderate damages to their structural members. While these structures did not cross the ULS, they did cross the so-called Serviceability Limit State (SLS).
- “Green”: The structures of this class suffered only minor damages.
- Structural type: In general, Seismic Codes distinguish buildings according to their structural type, e.g., framed structures or frames with shear walls [8].
- Significant height: This is an attribute that most Seismic Codes take into consideration. It affects structures whose height exceeds a predefined threshold. However, this threshold varies between Seismic Codes. For example, FEMA sets this threshold at 7 stories, while this threshold for OASP equals 5. In addition to the above, some Seismic Codes, e.g., that of India, distinguish structures with “moderate height” as a separate category.
- Poor condition: This attribute accounts for potential deterioration in the design seismic capacity of the building. This may be due to corroded reinforcement bars or due to poor concrete quality (e.g., aggregate segregation or erosion) [8].
- Vertical irregularity: This attribute pertains to structures with significant variations in their height, which leads to discontinuities in the paths of the vertical loads.
- Horizontal irregularity: This feature affects structures whose floor plans exhibit sharp, re-entrant corners, such as “L”, “T”, or “E”, which have the potential to develop higher degrees of damage [8].
- Soft story: This pertains to structures wherein one story has significantly less stiffness than the rest; for example, due to a discontinuity of the shear walls.
- Torsion: Structures with high eccentricities suffer from torsional loads during an earthquake. This could lead to higher degrees of damage.
- Pounding: This attribute is considered when two adjacent structures do not have a sufficient gap between them and especially when the buildings have different heights, which may lead to the slabs of one structure ramming into the columns of the other.
- Heavy non-structural elements: While they are non-structural, the displacement of such elements during an earthquake can lead to eccentricities and to additional torsion.
- Short columns: This attribute refers to columns wherein modifications have resulted in a reduction in their active length. Such modifications include the addition of spandrel beams, or wall sections that do not cover the full height of the story [8].
- Benchmark year: Various Seismic Codes define the so-called “benchmark years” where an improved version of the Code took effect.
- Soil type: Generally, Seismic Codes classify soil types ranging from rock and semi-rock formations to loose fine-grained silt [19]. The quality of the underlying soil is a significant factor of the overall seismic behavior of the building.
- Lack of Seismic Code design: This attribute pertains to structures that were designed without adhering to the provisions of a dedicated Seismic Code.
- Wall filling regularity: When the infill walls are of sufficient thickness and with few openings, they can support the surrounding frames during an earthquake, leading to improved overall performance.
- Previous damages: This attribute pertains to structures whose previous damages have not been adequately repaired, leading to a deterioration of their overall seismic capacity.
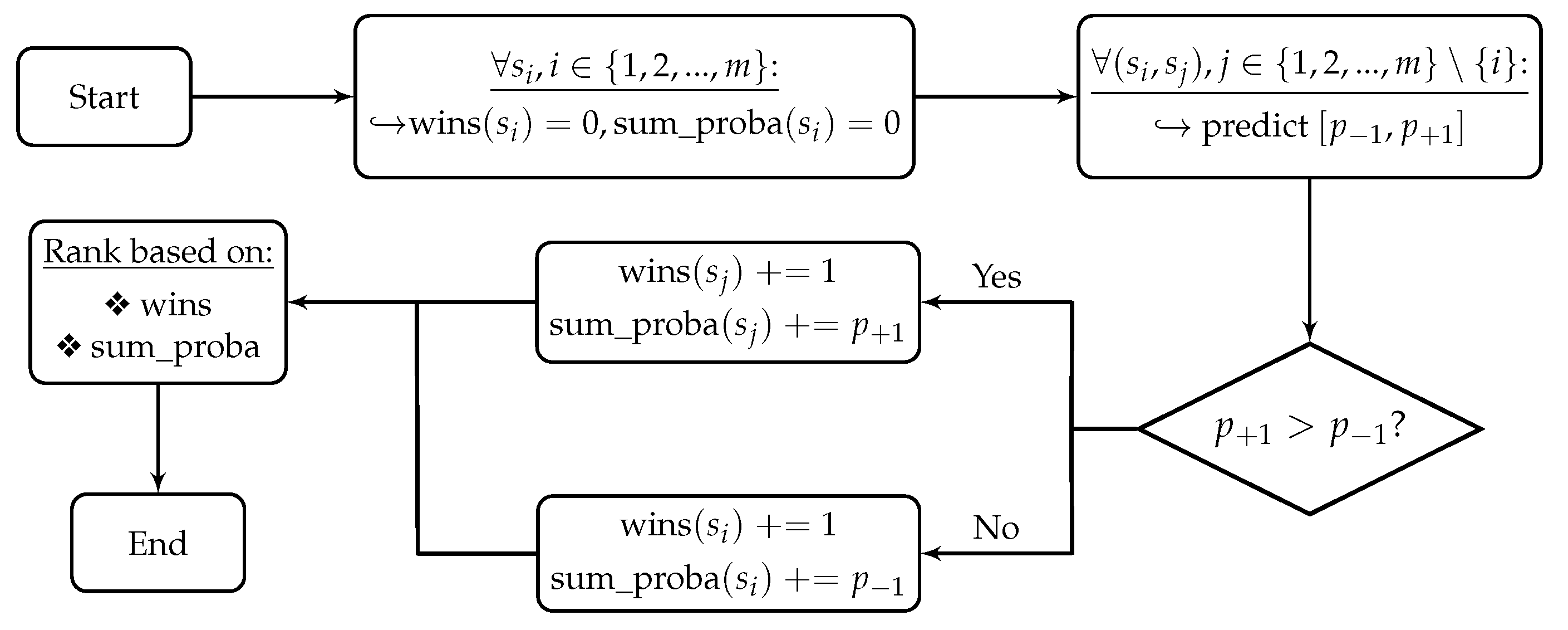
2.2. Overview of the Proposed Formulation
| Algorithm 1 Algorithmic seismic vulnerability ranking process using ML model [20]. |
for do:
end for Rank the given population of structures based on the total number of “wins”, using the running sum of probabilities as a secondary metric. |
2.3. Data Preprocessing
2.4. Machine Learning Algorithm
| Algorithm 2 Gradient Boosting learning process [27]. |
| Initialize for do:
end for |
2.5. Proposed Methodology for the Recalibration of RVS Using Machine Learning
| Algorithm 3 Algorithmic seismic vulnerability ranking process using the proposed recalibration procedure. |
for do:
end for Rank the given population of structures based on the total number of “wins”, using the running sum as a secondary metric. |
2.6. Explainability and SHAP Values
3. Results
4. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RVS | Rapid Visual Screening |
| ML | Machine Learning |
| SHAP | SHapley Additive exPlanations |
| FEMA | Federal Emergency Management Agency |
| OASP | Greek Earthquake Planning and Protection Organization |
| OCIPEP | Office of Critical Infrastructure Protection and Emergency Preparedness |
| CNN | Convolutional Neural Network |
| MLP | Multi-Layer Perceptron |
| SVM | Support Vector Machine |
| k-NN | k-Nearest Neighbors |
| GB | Gradient Boosting |
References
- Vicente, R.; Parodi, S.; Lagomarsino, S.; Varum, H.; Silva, J.M. Seismic vulnerability and risk assessment: Case study of the historic city centre of Coimbra, Portugal. Bull. Earthq. Eng. 2011, 9, 1067–1096. [Google Scholar] [CrossRef]
- Lang, K.; Bachmann, H. On the seismic vulnerability of existing buildings: A case study of the city of Basel. Earthq. Spectra 2004, 20, 43–66. [Google Scholar] [CrossRef]
- Federal Emergency Management Agency (FEMA). Rapid Visual Screening of Buildings for Potential Seismic Hazards: A Handbook, 1st ed.; Technical Report; Applied Technology Council: Redwood City, CA, USA, 1988. [Google Scholar]
- Federal Emergency Management Agency (FEMA). Rapid Visual Screening of Buildings for Potential Seismic Hazards: A Handbook, 3rd ed.; Technical Report; Applied Technology Council: Redwood City, CA, USA, 2002. [Google Scholar]
- Brundson, D.; Holmes, S.; Hopkins, D.; Merz, S.; Jury, R.; Shephard, B. The Assessment and Improvement of the Structural Performance of Earthquake Risk Buildings; Technical Report; New Zealand Society for Earthquake Engineering: Wellington, New Zealand, 1996. [Google Scholar]
- Sinha, R.; Goyal, A. A National Policy for Seismic Vulnerability Assessment of Buildings and Procedure for Rapid Visual Screening of Buildings for Potential Seismic Vulnerability; Technical Report; Indian Institute of Technology, Department of Civil Engineering: New Delhi, India, 2002. [Google Scholar]
- Earthquake Planning and Protection Organization (OASP). Provisions for Pre-Earthquake Vulnerability Assessment of Public Buildings (Part A); Technical Report; Greek Society of Civil Engineers: Athens, Greece, 2000. [Google Scholar]
- Foo, S.; Naumoski, N.; Saatcioglu, M. Seismic Hazard, Building Codes and Mitigation Options for Canadian Buildings; Technical Report; Canadian Office of Critical Infrastructure Protection and Emergency Preparedness (CCIPEP): Ottawa, ON, Canada, 2001. [Google Scholar]
- Madariaga, R.; Ruiz, S.; Rivera, E.; Leyton, F.; Baez, J.C. Near-field spectra of large earthquakes. Pure Appl. Geophys. 2019, 176, 983–1001. [Google Scholar] [CrossRef]
- Alhan, C.; Öncü-Davas, S. Performance limits of seismically isolated buildings under near-field earthquakes. Eng. Struct. 2016, 116, 83–94. [Google Scholar] [CrossRef]
- Rossetto, T.; Elnashai, A. Derivation of vulnerability functions for European-type RC structures based on observational data. Eng. Struct. 2003, 25, 1241–1263. [Google Scholar] [CrossRef]
- Eleftheriadou, A.; Karabinis, A. Damage probability matrices derived from earthquake statistical data. In Proceedings of the 14th World Conference on Earthquake Engineering, Beijing, China, 12–17 October 2008; pp. 07–0201. [Google Scholar]
- Yu, Q.; Wang, C.; McKenna, F.; Yu, S.X.; Taciroglu, E.; Cetiner, B.; Law, K.H. Rapid visual screening of soft-story buildings from street view images using deep learning classification. Earthq. Eng. Eng. Vib. 2020, 19, 827–838. [Google Scholar] [CrossRef]
- Ruggieri, S.; Cardellicchio, A.; Leggieri, V.; Uva, G. Machine-learning based vulnerability analysis of existing buildings. Autom. Constr. 2021, 132, 103936. [Google Scholar] [CrossRef]
- Bektaş, N.; Kegyes-Brassai, O. Development in machine learning based rapid visual screening method for masonry buildings. In Proceedings of the International Conference on Experimental Vibration Analysis for Civil Engineering Structures, Milan, Italy, 30 August–1 September 2023; Springer: Cham, Switzerland, 2023; pp. 411–421. [Google Scholar]
- Harirchian, E.; Kumari, V.; Jadhav, K.; Rasulzade, S.; Lahmer, T.; Raj Das, R. A synthesized study based on machine learning approaches for rapid classifying earthquake damage grades to RC buildings. Appl. Sci. 2021, 11, 7540. [Google Scholar] [CrossRef]
- Karabinis, A. Rating of the First Level of Pre-Earthquake Assessment. 2004. Available online: https://oasp.gr/sites/default/files/program_documents/261%20-%20Teliki%20ekthesi.pdf (accessed on 13 May 2024).
- Karampinis, I.; Iliadis, L.; Karabinis, A. Rapid Visual Screening Feature Importance for Seismic Vulnerability Ranking via Machine Learning and SHAP Values. Appl. Sci. 2024, 14, 2609. [Google Scholar] [CrossRef]
- Greek Code for Seismic Resistant Structures–EAK. 2000. Available online: https://iisee.kenken.go.jp/worldlist/23_Greece/23_Greece_Code.pdf (accessed on 13 May 2024).
- Karampinis, I.; Iliadis, L. A Machine Learning Approach for Seismic Vulnerability Ranking. In Proceedings of the International Conference on Engineering Applications of Neural Networks, León, Spain, 14–17 June 2023; Springer: Cham, Switzerland, 2023; pp. 3–16. [Google Scholar]
- Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 9. [Google Scholar]
- Longadge, R.; Dongre, S. Class imbalance problem in data mining review. arXiv 2013, arXiv:1305.1707. [Google Scholar]
- Liu, B.; Tsoumakas, G. Dealing with class imbalance in classifier chains via random undersampling. Knowl.-Based Syst. 2020, 192, 105292. [Google Scholar] [CrossRef]
- Hasanin, T.; Khoshgoftaar, T. The effects of random undersampling with simulated class imbalance for big data. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 6–9 July 2018; IEEE: New York, NY, USA, 2018; pp. 70–79. [Google Scholar]
- Kumari, R.; Srivastava, S.K. Machine learning: A review on binary classification. Int. J. Comput. Appl. 2017, 160, 11–15. [Google Scholar] [CrossRef]
- Singhal, Y.; Jain, A.; Batra, S.; Varshney, Y.; Rathi, M. Review of bagging and boosting classification performance on unbalanced binary classification. In Proceedings of the 2018 IEEE 8th International Advance Computing Conference (IACC), Greater Noida, India, 14–15 December 2018; pp. 338–343. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef] [PubMed]
- Schapire, R.E. The boosting approach to machine learning: An overview. Nonlinear Estim. Classif. 2003, 171, 149–171. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Shapley, L.S. Notes on the n-Person Game: The Value of an n-Person Game; RAND Corporation: Santa Monica, CA, USA, 1951. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Kapetana, P.; Dritsos, S. Seismic assessment of buildings by rapid visual screening procedures. Earthq. Resist. Eng. Struct. VI 2007, 93, 409. [Google Scholar]

{kind=link}
{kind=link}
| Damage Label | Number of Structures |
|---|---|
| Black | 93 |
| Red | 201 |
| Yellow | 69 |
| Green | 94 |
| Attribute | Seismic Code | |||||
|---|---|---|---|---|---|---|
| FEMA 1988 | FEMA 2002 | OASP (2000–2004) | India | Canada | New Zealand | |
| Structural type | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Significant height | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Poor condition | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ |
| Vertical irregularity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Horizontal irregularity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Soft story | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Torsion | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Pounding | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Heavy non-structural elements | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Short columns | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Benchmark year | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Soil type | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Moderate height | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
| Lack of Seismic Code design | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Wall filling regularity | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Previous damages | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ |
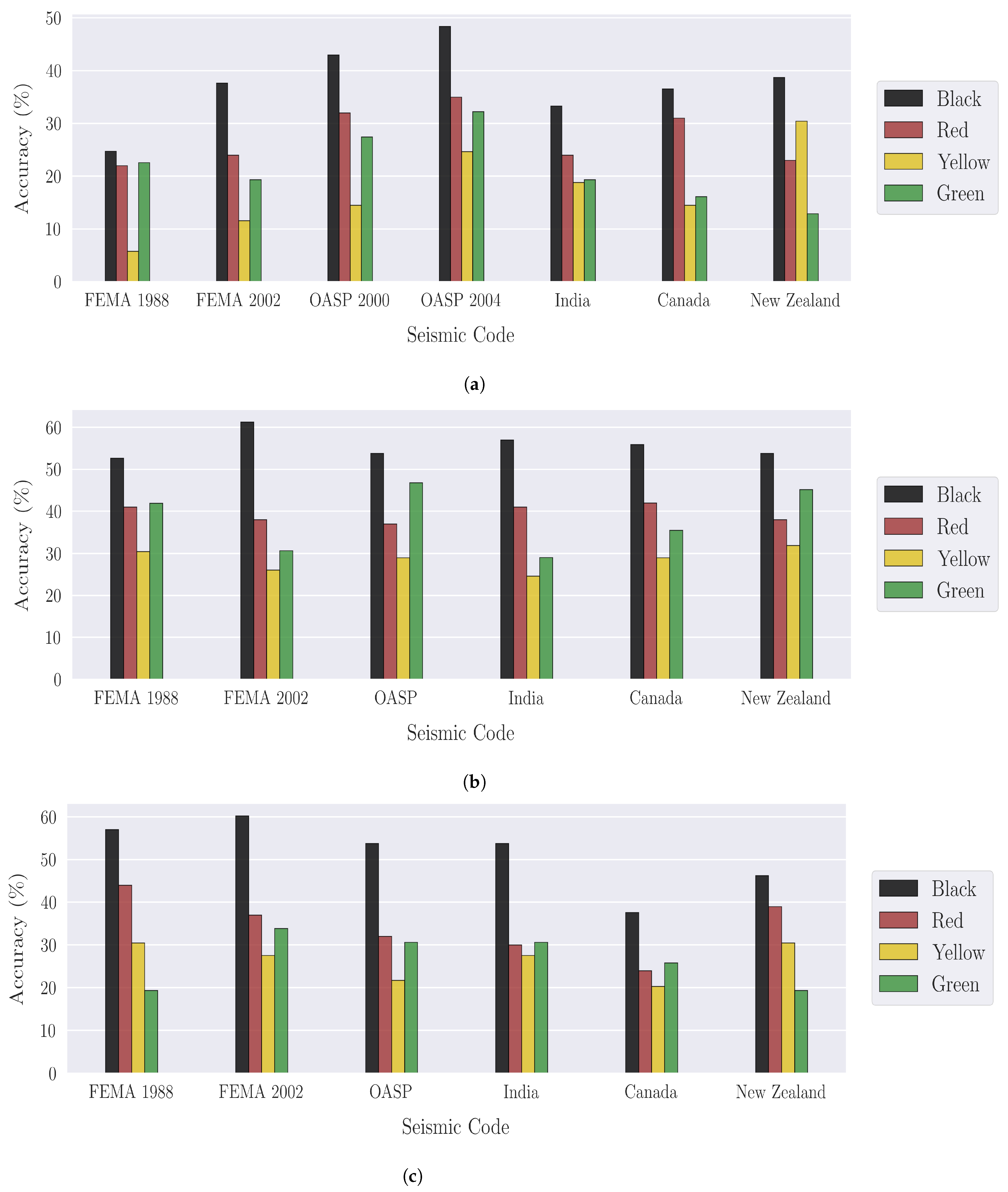
| Seismic Code | Bin Accuracy (%) | |||
|---|---|---|---|---|
| Black | Red | Yellow | Green | |
| FEMA 1988 | 24.73 | 22.00 | 5.80 | 22.58 |
| FEMA 2002 | 37.63 | 24.00 | 11.59 | 19.35 |
| OASP 2000 | 43.01 | 32.00 | 14.49 | 27.42 |
| OASP 2004 | 48.39 | 35.00 | 24.64 | 32.26 |
| India | 33.33 | 24.00 | 18.84 | 19.35 |
| Canada | 36.56 | 31.00 | 14.49 | 16.13 |
| New Zealand | 38.71 | 23.00 | 30.43 | 12.90 |
| Seismic Code | Bin Accuracy (%) | |||
|---|---|---|---|---|
| Black | Red | Yellow | Green | |
| FEMA 1988 | 52.69 | 41.00 | 30.43 | 41.94 |
| FEMA 2002 | 61.29 | 38.00 | 26.09 | 30.64 |
| OASP (2000 and 2004) | 53.76 | 37.00 | 28.99 | 46.77 |
| India | 56.99 | 41.00 | 24.66 | 29.03 |
| Canada | 55.94 | 42.00 | 28.99 | 35.48 |
| New Zealand | 53.76 | 38.00 | 31.88 | 45.16 |
| Seismic Code | Bin Accuracy (%) | |||
|---|---|---|---|---|
| Black | Red | Yellow | Green | |
| FEMA 1988 | 56.99 | 44.00 | 30.43 | 19.35 |
| FEMA 2002 | 60.22 | 37.00 | 27.54 | 33.87 |
| OASP (2000 and 2004) | 53.76 | 32.00 | 21.74 | 30.65 |
| India | 53.76 | 30.00 | 27.54 | 30.65 |
| Canada | 37.63 | 24.00 | 20.29 | 25.81 |
| New Zealand | 46.24 | 39.00 | 30.43 | 19.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karampinis, I.; Iliadis, L.; Karabinis, A. Investigation of Structural Seismic Vulnerability Using Machine Learning on Rapid Visual Screening. Appl. Sci. 2024, 14, 5350. https://doi.org/10.3390/app14125350
Karampinis I, Iliadis L, Karabinis A. Investigation of Structural Seismic Vulnerability Using Machine Learning on Rapid Visual Screening. Applied Sciences. 2024; 14(12):5350. https://doi.org/10.3390/app14125350
Chicago/Turabian StyleKarampinis, Ioannis, Lazaros Iliadis, and Athanasios Karabinis. 2024. "Investigation of Structural Seismic Vulnerability Using Machine Learning on Rapid Visual Screening" Applied Sciences 14, no. 12: 5350. https://doi.org/10.3390/app14125350
APA StyleKarampinis, I., Iliadis, L., & Karabinis, A. (2024). Investigation of Structural Seismic Vulnerability Using Machine Learning on Rapid Visual Screening. Applied Sciences, 14(12), 5350. https://doi.org/10.3390/app14125350