


A New AI Approach by Acquisition of Characteristics in Human Decision-Making Process


Abstract
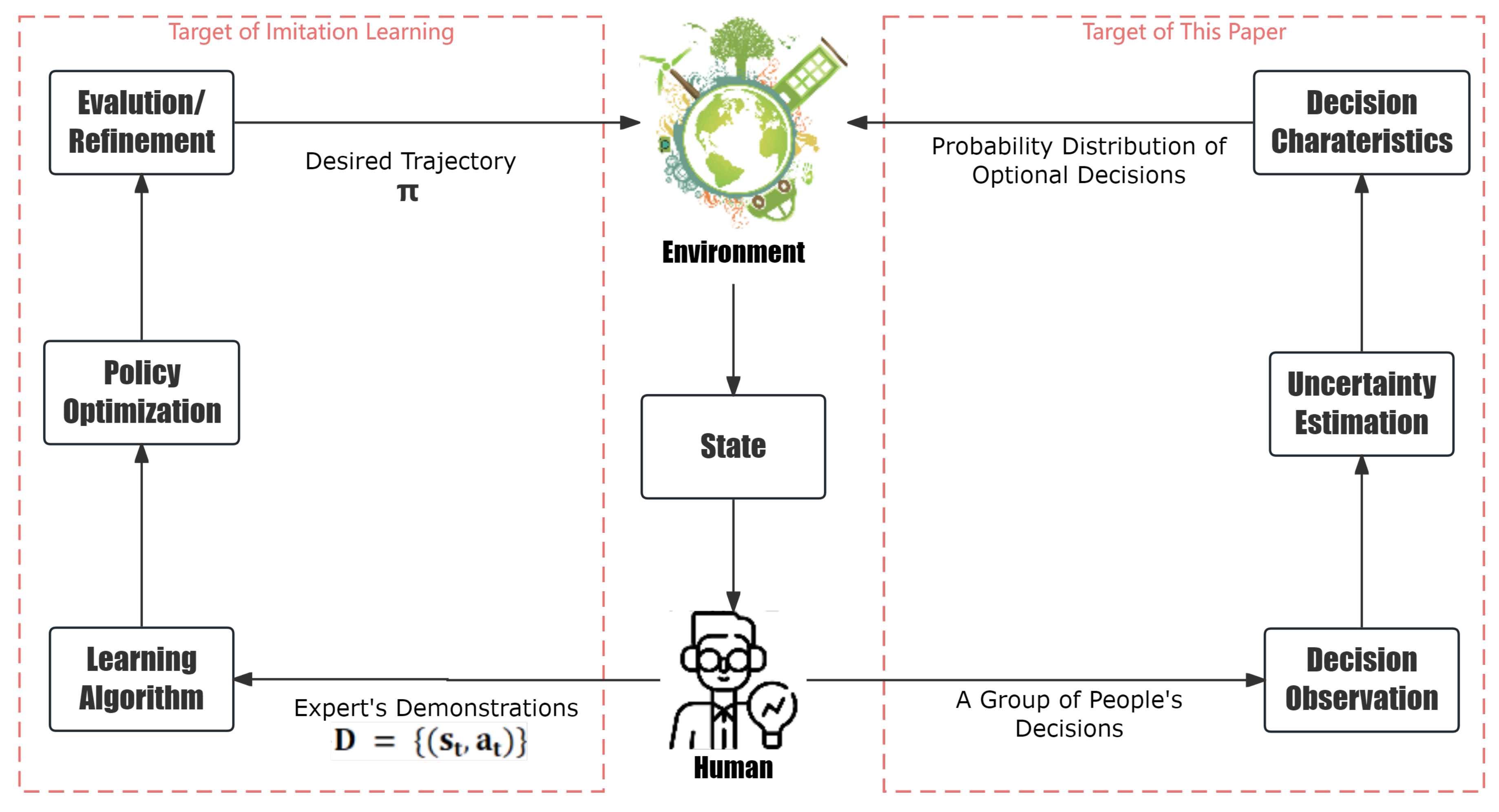
1. Introduction
- Variability and consensus: The spread or variability of decisions within the probability distribution provides insights into the level of agreement or disagreement between decision makers. A narrow distribution indicates a high level of consensus, whereas a broader distribution suggests greater variability in decision preferences [16,17].
- Decision biases: Certain decision biases may manifest as skewed or asymmetric probability distributions. For instance, if decisions tend to cluster around a particular option due to an anchoring bias or status quo bias, it will be reflected in the shape of the probability distribution [18].
- Risk preferences: Decision making often involves trade-offs between risks and rewards. By analyzing the probability distribution of decisions, we can infer the risk preferences of the group. A risk-averse group may exhibit a probability distribution skewed toward safer options, while a risk-seeking group may display a distribution skewed toward riskier alternatives [19,20].
- Decision stability: The stability of decision making over time can also be assessed through changes in the probability distribution. A consistent probability distribution indicates stable decision-making behavior, whereas fluctuations or shifts in the distribution may signify changes in preferences or external influences [21,22].
2. Related Works
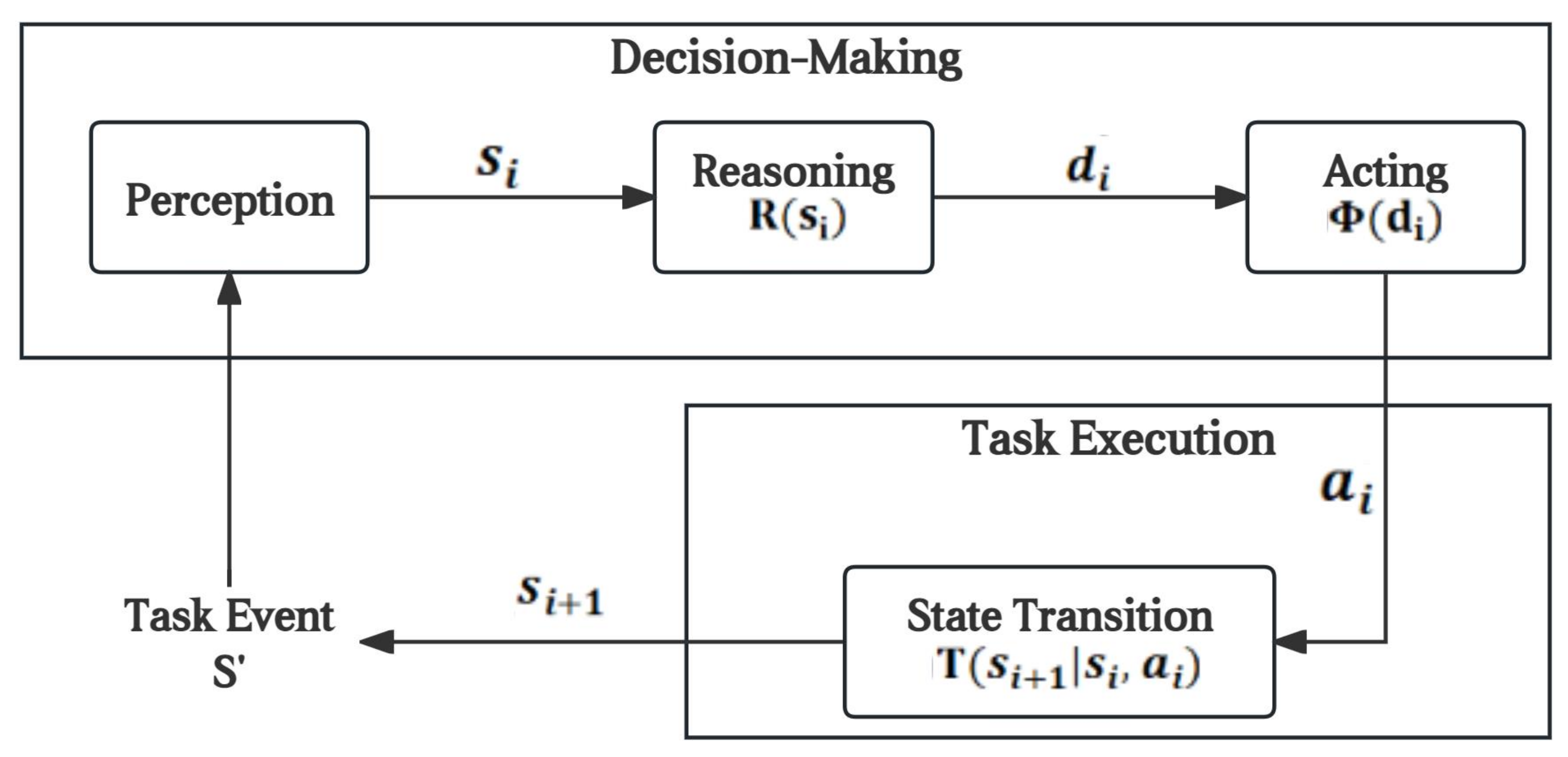
3. Challenges in Imitation Learning
- State space: S, set of all possible states.
- Action space: A, set of all possible actions.
- Reward function: , defines the immediate reward for taking an action in a state.
- Demonstration dataset: , set of state–action pairs from expert demonstrations.
- Policy: , agent’s policy mapping states to actions.
- Generalization: one key challenge in imitation learning is generalizing the learned policy to new, unseen situations that may differ from the demonstrations;
- Distribution mismatch: the distribution of states encountered during the policy execution by the agent may differ from the distribution of states in the demonstration dataset D, leading to challenges in effective learning;
- Bias and variance trade-off: balancing bias (due to approximation error) and variance (due to noisy demonstrations) is critical for successful imitation learning.
4. Method
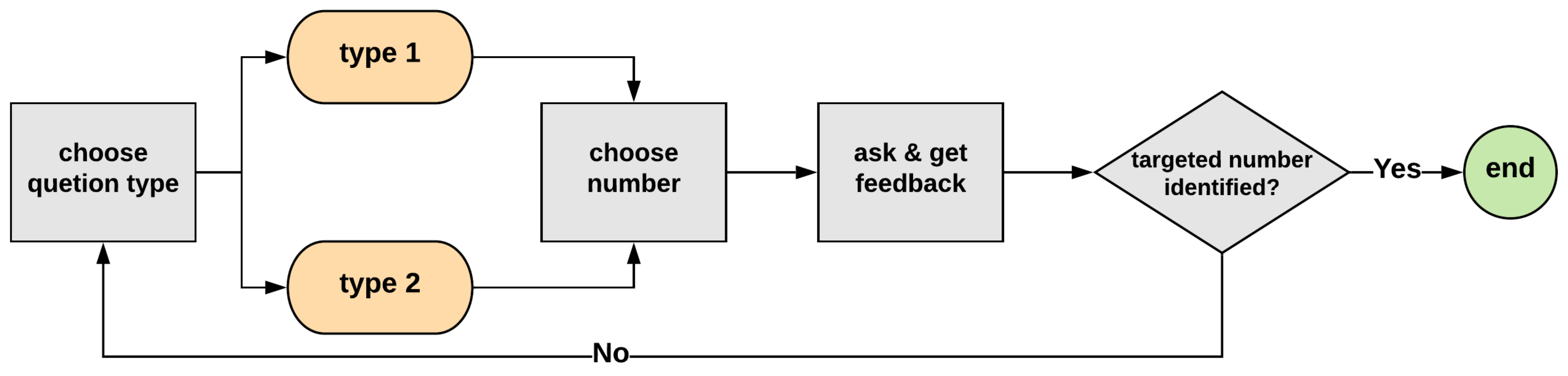
4.1. Application Example
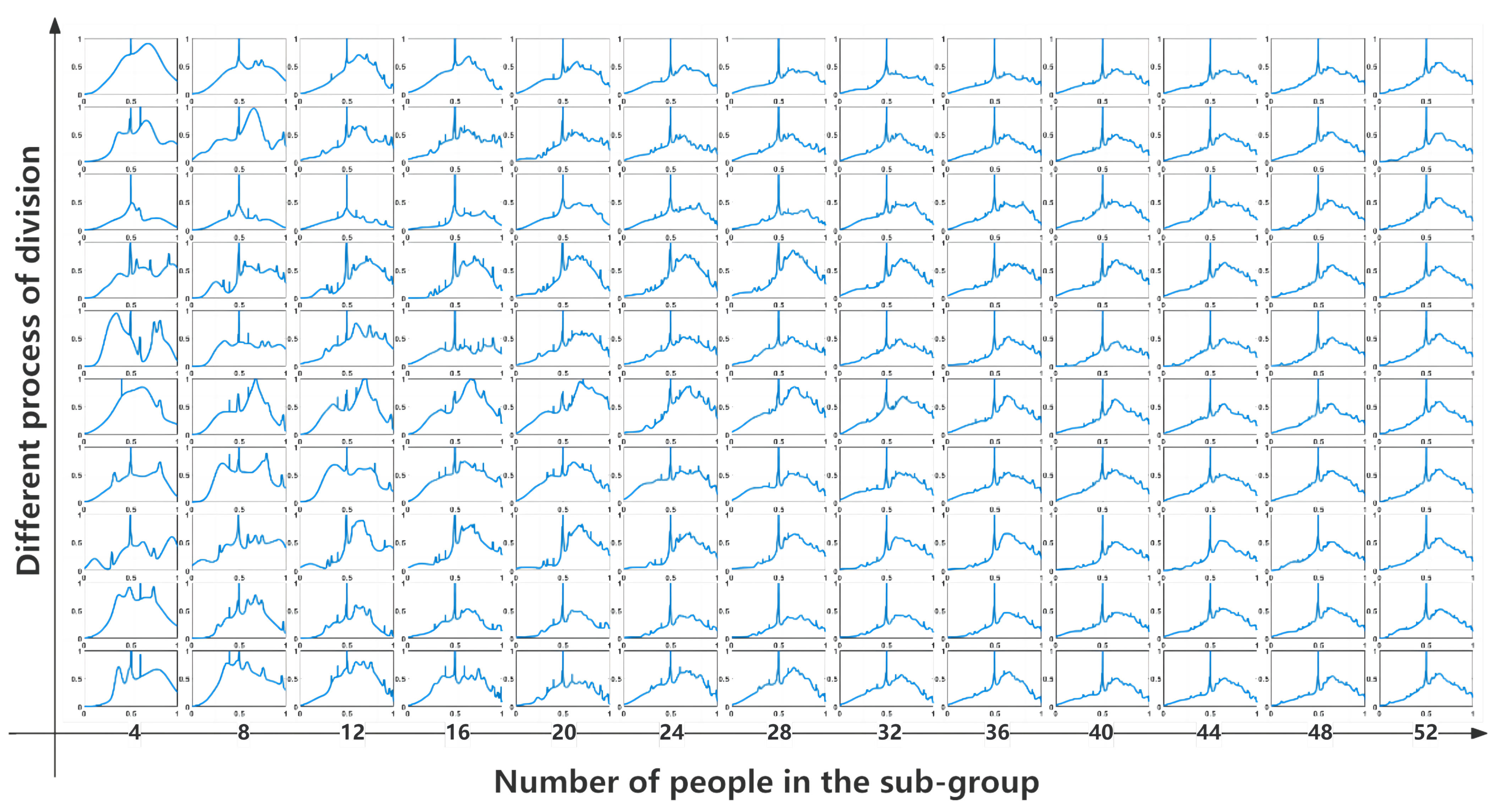
4.2. Method Implementation in Game Application
4.2.1. Feature Space Mapping
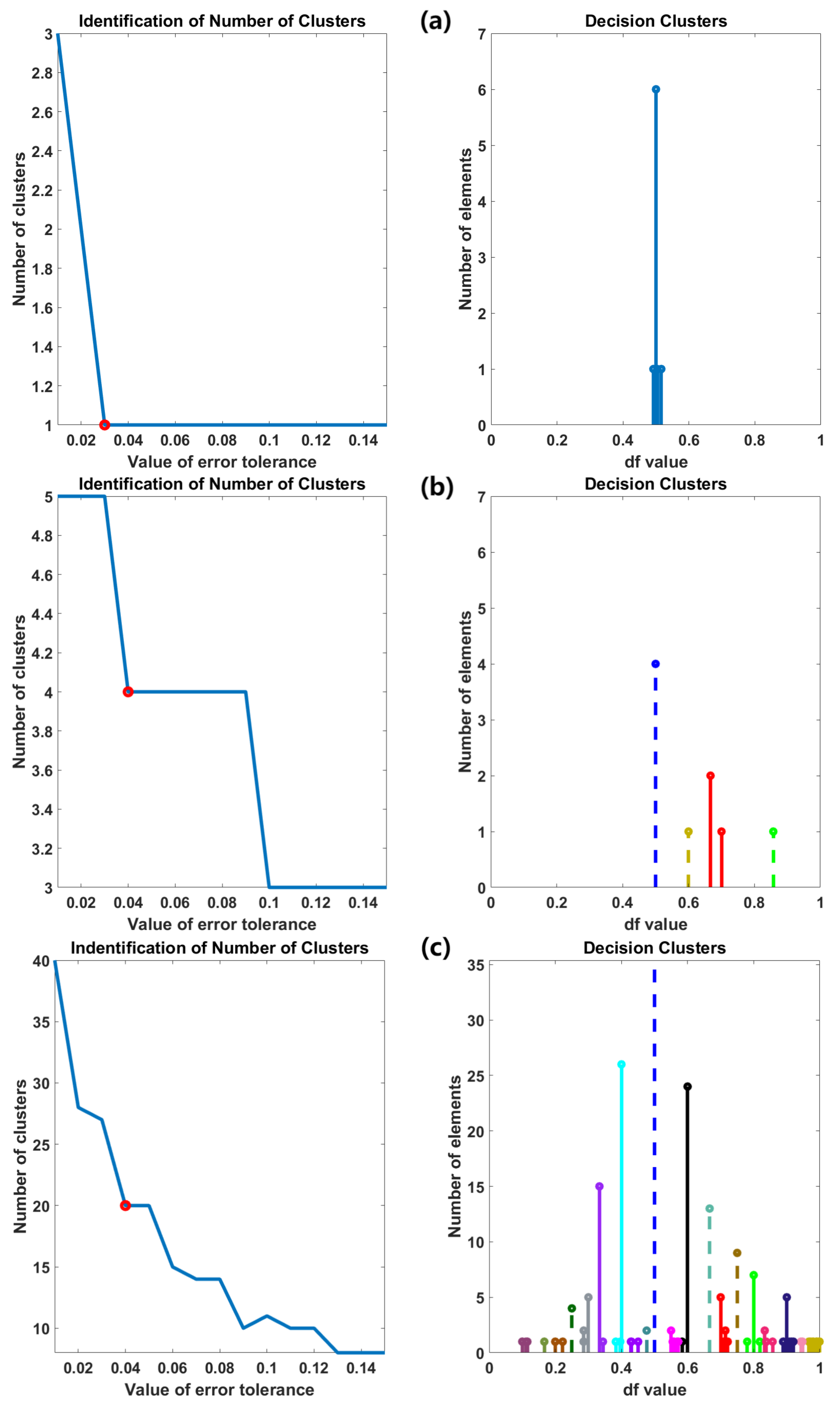
4.2.2. Clustering
| Algorithm 1: Clustering | |
 | |
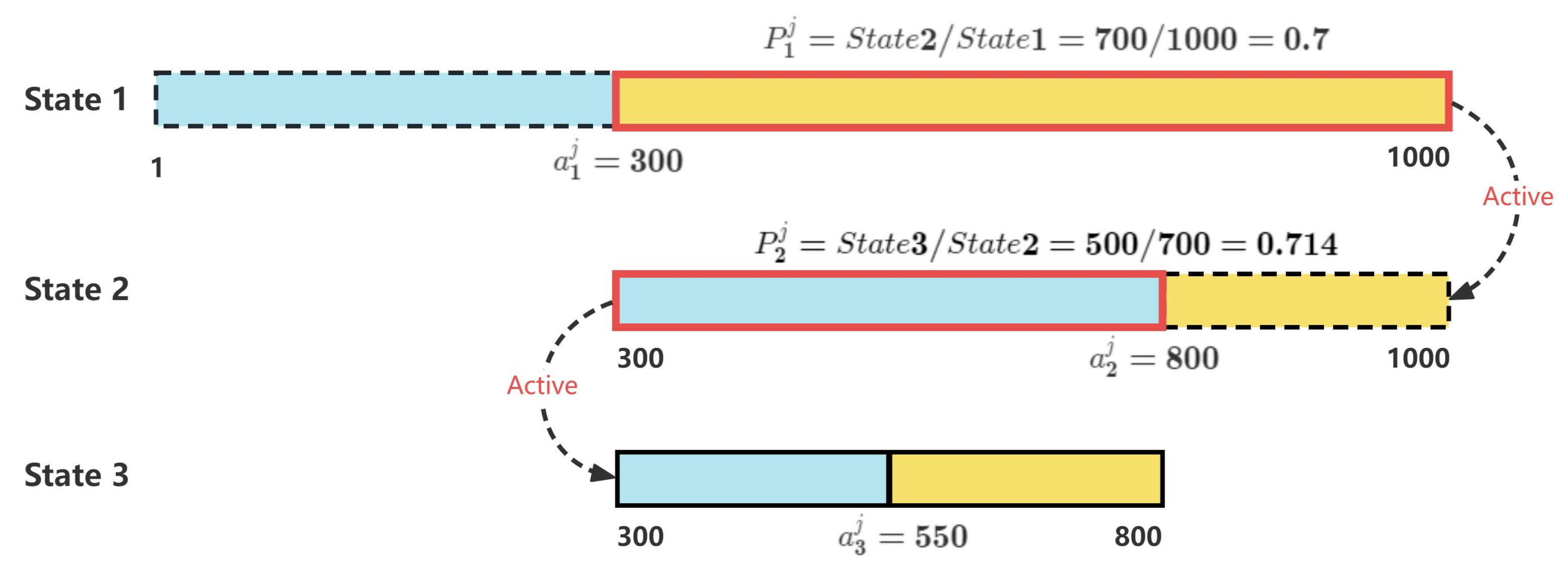
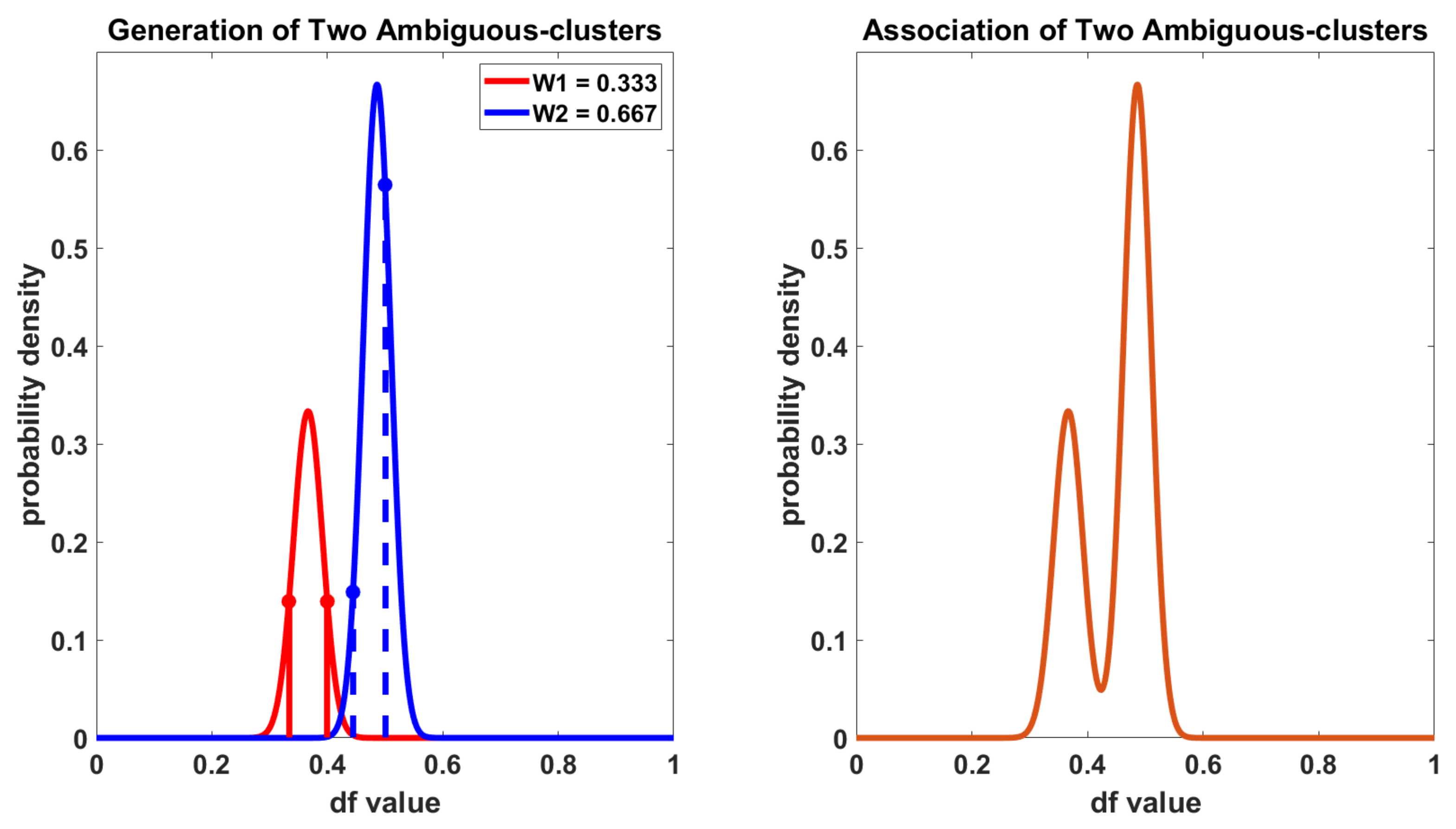
4.2.3. Generation of Ambiguous Clusters
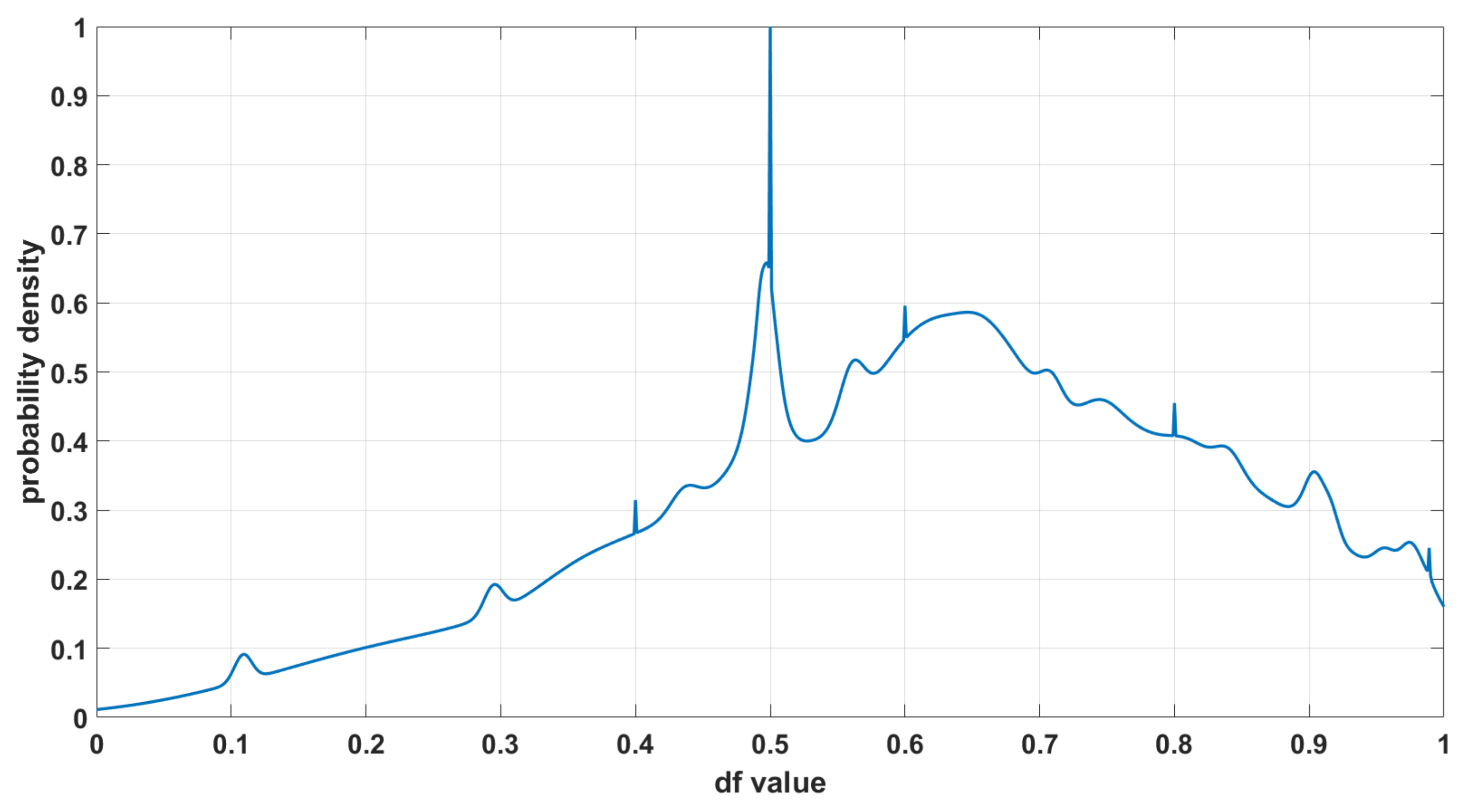
4.2.4. Association and Accumulation
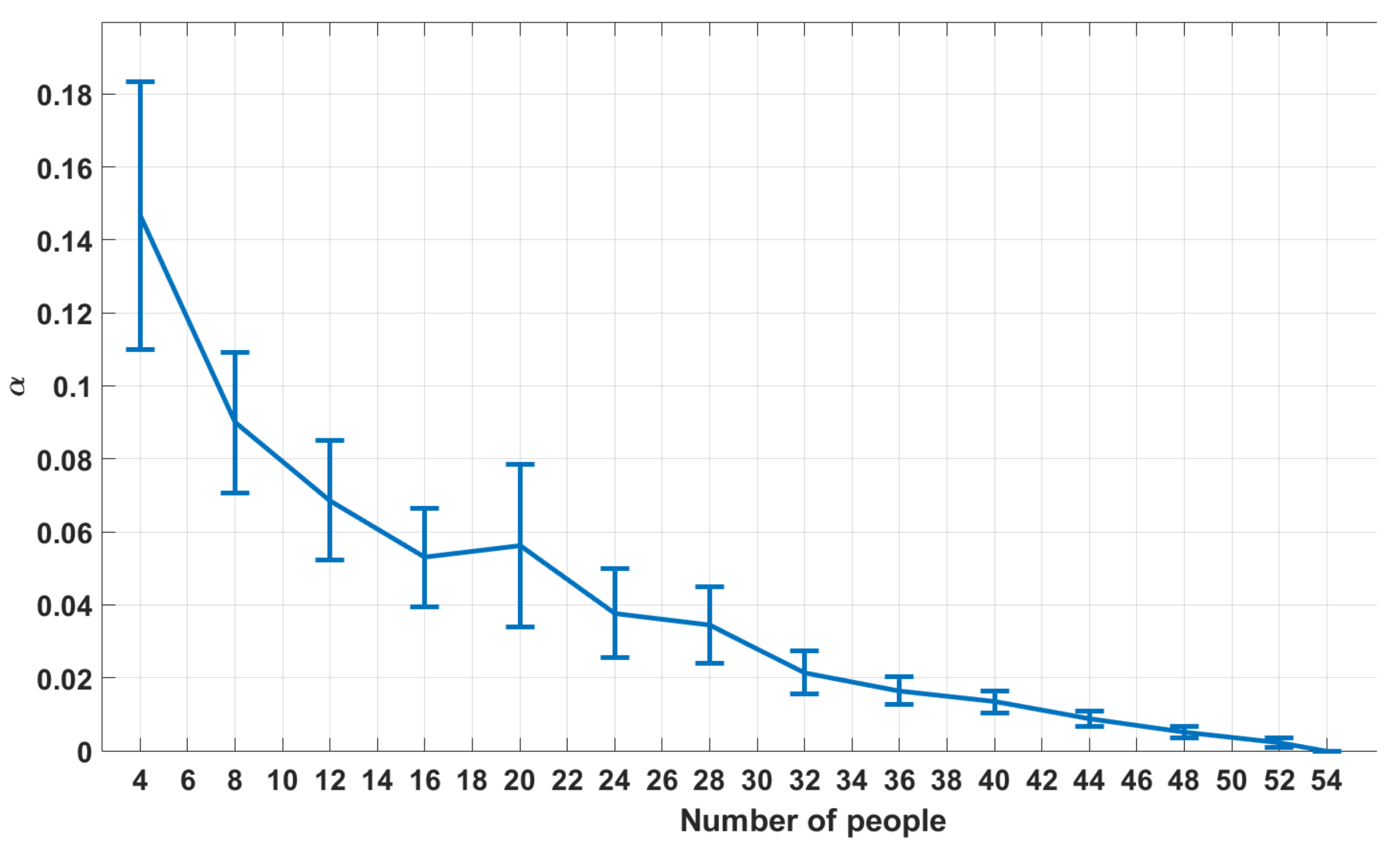
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Daniel, K. Thinking, Fast and Slow; Macmillan: New York, NY, USA, 2011. [Google Scholar]
- Mousavi, S.; Gigerenzer, G. Risk, uncertainty, and heuristics. J. Bus. Res. 2014, 67, 1671–1678. [Google Scholar] [CrossRef]
- Gilovich, T.; Griffin, D.; Kahneman, D. Heuristics and Biases: The Psychology of Intuitive Judgment; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Bazerman, M.H.; Moore, D.A. Judgment in Managerial Decision Making; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Chen, V.; Liao, Q.V.; Wortman Vaughan, J.; Bansal, G. Understanding the role of human intuition on reliance in human-AI decision-making with explanations. Proc. ACM Hum. Comput. Interact. 2023, 7, 1–32. [Google Scholar]
- Zheng, B.; Verma, S.; Zhou, J.; Tsang, I.W.; Chen, F. Imitation Learning: Progress, Taxonomies and Challenges. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 6322–6337. [Google Scholar] [CrossRef]
- Edwards, A.; Sahni, H.; Schroecker, Y.; Isbell, C. Imitating latent policies from observation. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 20109; PMLR: New York, NY, USA, 2019; pp. 1755–1763. [Google Scholar]
- Nair, A.; Chen, D.; Agrawal, P.; Isola, P.; Abbeel, P.; Malik, J.; Levine, S. Combining self-supervised learning and imitation for vision-based rope manipulation. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 2146–2153. [Google Scholar]
- Garg, D.; Chakraborty, S.; Cundy, C.; Song, J.; Ermon, S. Iq-learn: Inverse soft-q learning for imitation. Adv. Neural Inf. Process. Syst. 2021, 34, 4028–4039. [Google Scholar]
- Ding, Z. Imitation learning. In Deep Reinforcement Learning: Fundamentals, Research and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 273–306. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR: New York, NY, USA, 2016; pp. 49–58. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Zhou, Y.; Khatibi, S. Mapping and Generating Adaptive Ontology of Decision Experiences. In Proceedings of the 3rd International Conference on Information Science and Systems, Cambridge, UK, 19–22 March 2020; pp. 138–143. [Google Scholar]
- Kuehnhanss, C.R. The challenges of behavioural insights for effective policy design. Policy Soc. 2019, 38, 14–40. [Google Scholar] [CrossRef]
- Leonard, T.C. Richard H. Thaler, Cass R. Sunstein, Nudge: Improving decisions about health, wealth, and happiness. Const. Political Econ. 2008, 19, 356. [Google Scholar] [CrossRef]
- Kerr, N.L.; Tindale, R.S. Group performance and decision making. Annu. Rev. Psychol. 2004, 55, 623–655. [Google Scholar] [CrossRef]
- Boix-Cots, D.; Pardo-Bosch, F.; Pujadas, P. A systematic review on multi-criteria group decision-making methods based on weights: Analysis and classification scheme. Inf. Fusion 2023, 96, 16–36. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under Uncertainty: Heuristics and Biases: Biases in judgments reveal some heuristics of thinking under uncertainty. Science 1974, 185, 1124–1131. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Advances in prospect theory: Cumulative representation of uncertainty. J. Risk Uncertain. 1992, 5, 297–323. [Google Scholar] [CrossRef]
- Peterson, J.C.; Bourgin, D.D.; Agrawal, M.; Reichman, D.; Griffiths, T.L. Using large-scale experiments and machine learning to discover theories of human decision-making. Science 2021, 372, 1209–1214. [Google Scholar] [CrossRef]
- Hardisty, D.J.; Thompson, K.F.; Krantz, D.H.; Weber, E.U. How to measure time preferences: An experimental comparison of three methods. Judgm. Decis. Mak. 2013, 8, 236–249. [Google Scholar] [CrossRef]
- Tversky, A.; Shafir, E. Choice under conflict: The dynamics of deferred decision. Psychol. Sci. 1992, 3, 358–361. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, Y.; Wang, H.; Zeng, Z.; Liu, H. A knowledge-enhanced framework for imitative transportation trajectory generation. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 30 November–3 December 2022; IEEE: New York, NY, USA, 2022; pp. 823–832. [Google Scholar]
- Zhang, X.; Li, Y.; Zhou, X.; Zhang, Z.; Luo, J. Trajgail: Trajectory generative adversarial imitation learning for long-term decision analysis. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; IEEE: New York, NY, USA, 2020; pp. 801–810. [Google Scholar]
- Abu-Nasser, B. Medical expert systems survey. Int. J. Eng. Inf. Syst. (IJEAIS) 2017, 1, 218–224. [Google Scholar]
- Behzadian, M.; Otaghsara, S.K.; Yazdani, M.; Ignatius, J. A state-of the-art survey of TOPSIS applications. Expert Syst. Appl. 2012, 39, 13051–13069. [Google Scholar] [CrossRef]
- Oh, J.; Yang, J.; Lee, S. Managing uncertainty to improve decision-making in NPD portfolio management with a fuzzy expert system. Expert Syst. Appl. 2012, 39, 9868–9885. [Google Scholar] [CrossRef]
- Campbell, M. Knowledge discovery in deep blue. Commun. ACM 1999, 42, 65–67. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Petrović, V.M. Artificial Intelligence and Virtual Worlds—Toward Human-Level AI Agents. IEEE Access 2018, 6, 39976–39988. [Google Scholar] [CrossRef]
- Pfeifer, R.; Bongard, J. How the Body Shapes the Way We Think: A New View of Intelligence; MIT Press: Cambridge, UK, 2007. [Google Scholar]
- Lenat, D.B.; Guha, R.V.; Pittman, K.; Pratt, D.; Shepherd, M. Cyc: Toward programs with common sense. Commun. ACM 1990, 33, 30–49. [Google Scholar] [CrossRef]
- Olive, J.; Christianson, C.; McCary, J. Handbook of Natural Language Processing and Machine Translation: DARPA Global Autonomous Language Exploitation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Harnad, S. The symbol grounding problem. Phys. Nonlinear Phenom. 1990, 42, 335–346. [Google Scholar] [CrossRef]
- Shanahan, M. Perception as abduction: Turning sensor data into meaningful representation. Cogn. Sci. 2005, 29, 103–134. [Google Scholar] [CrossRef]
- Dinur, A.R. Common and un-common sense in managerial decision making under task uncertainty. Manag. Decis. 2011, 49, 694–709. [Google Scholar] [CrossRef]
- Garnelo, M.; Arulkumaran, K.; Shanahan, M. Towards deep symbolic reinforcement learning. arXiv 2016, arXiv:1609.05518. [Google Scholar]
- Leventhal, H.; Phillips, L.A.; Burns, E. The Common-Sense Model of Self-Regulation (CSM): A dynamic framework for understanding illness self-management. J. Behav. Med. 2016, 39, 935–946. [Google Scholar] [CrossRef]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on MACHINE Learning, Banff, AB, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Bain, M.; Sammut, C. A Framework for Behavioural Cloning. In Proceedings of the Machine Intelligence 15, Oxford, UK, 17 July 1995; pp. 103–129. [Google Scholar]
- Ng, A.Y.; Russell, S. Algorithms for inverse reinforcement learning. In Proceedings of the ICML, San Francisco, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. (CSUR) 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Osa, T.; Pajarinen, J.; Neumann, G.; Bagnell, J.A.; Abbeel, P.; Peters, J. An algorithmic perspective on imitation learning. Found. Trends Robot. 2018, 7, 1–179. [Google Scholar] [CrossRef]
- Pomerol, J.C.; Adam, F. Understanding Human Decision Making—A Fundamental Step Towards Effective Intelligent Decision Support. In Intelligent Decision Making: An AI-Based Approach; Springer: Berlin/Heidelberg, Germany, 2008; pp. 3–40. [Google Scholar]
- Arora, P.; Varshney, S. Analysis of k-means and k-medoids algorithm for big data. Procedia Comput. Sci. 2016, 78, 507–512. [Google Scholar] [CrossRef]
- The Gene Ontology Consortium; Aleksander, S.A.; Balhoff, J.; Carbon, S.; Cherry, J.M.; Drabkin, H.J.; Ebert, D.; Feuermann, M.; Gaudet, P.; Harris, N.L.; et al. The gene ontology knowledgebase in 2023. Genetics 2023, 224, iyad031. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Cluster Index | Rank | Cluster Index | Rank | Cluster Index |
|---|---|---|---|---|---|
| 1 | 2 | 11 | 9 | 21 | 10 |
| 2 | 30 | 12 | 28 | 22 | 24 |
| 3 | 7 | 13 | 20 | 23 | 16 |
| 4 | 23 | 14 | 17 | 24 | 12 |
| 5 | 3 | 15 | 22 | 25 | 5 |
| 6 | 4 | 16 | 29 | 26 | 25 |
| 7 | 14 | 17 | 15 | 27 | 18 |
| 8 | 27 | 18 | 1 | 28 | 26 |
| 9 | 8 | 19 | 13 | 29 | 11 |
| 10 | 21 | 20 | 6 | 30 | 19 |
| Participant 1 | Participant 2 | ||||
|---|---|---|---|---|---|
| Decision Sequence | D.S. Index | Rank | Decision Sequence | D.S. Index | Rank |
| 0.5000 | 2 | 1 | 0.5000 | 2 | 1 |
| 0.4000 | 7 | 3 | 0.6000 | 49 | 57 |
| 0.7500 | 8 | 9 | 0.3333 | 38 | 91 |
| 0.6667 | 23 | 4 | 0.4000 | 38 | 91 |
| 0.5000 | 2 | 1 | 0.5000 | 2 | 1 |
| 0.6000 | 30 | 2 | 0.7500 | 60 | 45 |
| 0.8333 | 53 | 75 | 0.6667 | 49 | 57 |
| 0.8000 | 53 | 75 | 0.5000 | 2 | 1 |
| 0.5000 | 2 | 1 | 0.8000 | 60 | 45 |
| 0.5000 | 2 | 1 | 0.7500 | 60 | 45 |
| Sum of ranks | 172 | Sum of ranks | 434 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Khatibi, S. A New AI Approach by Acquisition of Characteristics in Human Decision-Making Process. Appl. Sci. 2024, 14, 5469. https://doi.org/10.3390/app14135469
Zhou Y, Khatibi S. A New AI Approach by Acquisition of Characteristics in Human Decision-Making Process. Applied Sciences. 2024; 14(13):5469. https://doi.org/10.3390/app14135469
Chicago/Turabian StyleZhou, Yuan, and Siamak Khatibi. 2024. "A New AI Approach by Acquisition of Characteristics in Human Decision-Making Process" Applied Sciences 14, no. 13: 5469. https://doi.org/10.3390/app14135469
APA StyleZhou, Y., & Khatibi, S. (2024). A New AI Approach by Acquisition of Characteristics in Human Decision-Making Process. Applied Sciences, 14(13), 5469. https://doi.org/10.3390/app14135469