

Wearable Voice Dosimetry System


Abstract
:1. Introduction
- -
- -
- -
2. Related Work
2.1. Voice Dosimetry Devices
2.2. Voice Dosimetry Studies
- Teachers and Vocal Load: Rantala and Vilkman noted that teachers with frequent vocal fatigue complaints exhibited a higher fundamental frequency (F0) and intensity (I) at the day’s end and week’s end, indicating significant vocal strain [7]. In contrast, Hunter and Titze found that teachers’ vocal usage during work was substantially higher in duration, intensity, and pitch compared to non-working periods. They documented that speaking constituted 29.9% of work hours compared to 12% during rest, with a higher pitch and intensity of about 2.5 dBSPL [45,46];
- Mitigation Strategies: The use of audio amplification systems has been shown to effectively reduce the vocal load by lowering the need for vocal intensity [8,47,48]. Additionally, classroom acoustics play a crucial role; poor acoustics often lead teachers to increase their voice intensity, further straining their voices [49]. Similarly, a noisy environment forces an increase in voice intensity [50,51];
- Voice Monitoring and Feedback Systems: McGillivray et al. successfully used a voice response/feedback system in children to achieve and maintain lower intensity levels during speech activities [28]. However, Van Stan et al. noted that without the continuous use of such devices, the learned behaviours were not maintained, indicating the need for regular use [52]. These systems have also been applied to study vocal pauses and their effects on vocal health [53,54];
- Clinical Applications: Holbrook et al. reported the use of a voice response dosimetry system that helped avoid surgeries by aiding in the recovery of vocal fold pathologies, such as polyps and nodules, through regular monitoring [24]. Similarly, Horii and Fuller observed that short-term orotracheal intubation increased shimmer and jitter in sustained vowels, affecting vocal quality [55];
- Post-Surgery Voice Rest Monitoring: After laryngeal surgeries, voice rest is crucial. Misono et al. demonstrated that voice dosimetry devices could effectively monitor and enforce voice rest, showing significant reductions in phonation time and intensity [56];
- Innovative Measurement Techniques: Apart from acoustic signal analysis, other methods like using accelerometers to measure skin vibrations at the larynx provide a non-invasive and privacy-respecting way to assess vocal cord activity during phonation. These measurements can be crucial for diagnosing and prognosticating voice disorders [55,57].
3. Materials and Methods
3.1. System Design
3.1.1. Accelerometer
3.1.2. Microcontroller
3.1.3. Accelerometer Placement
3.1.4. Final Device Version
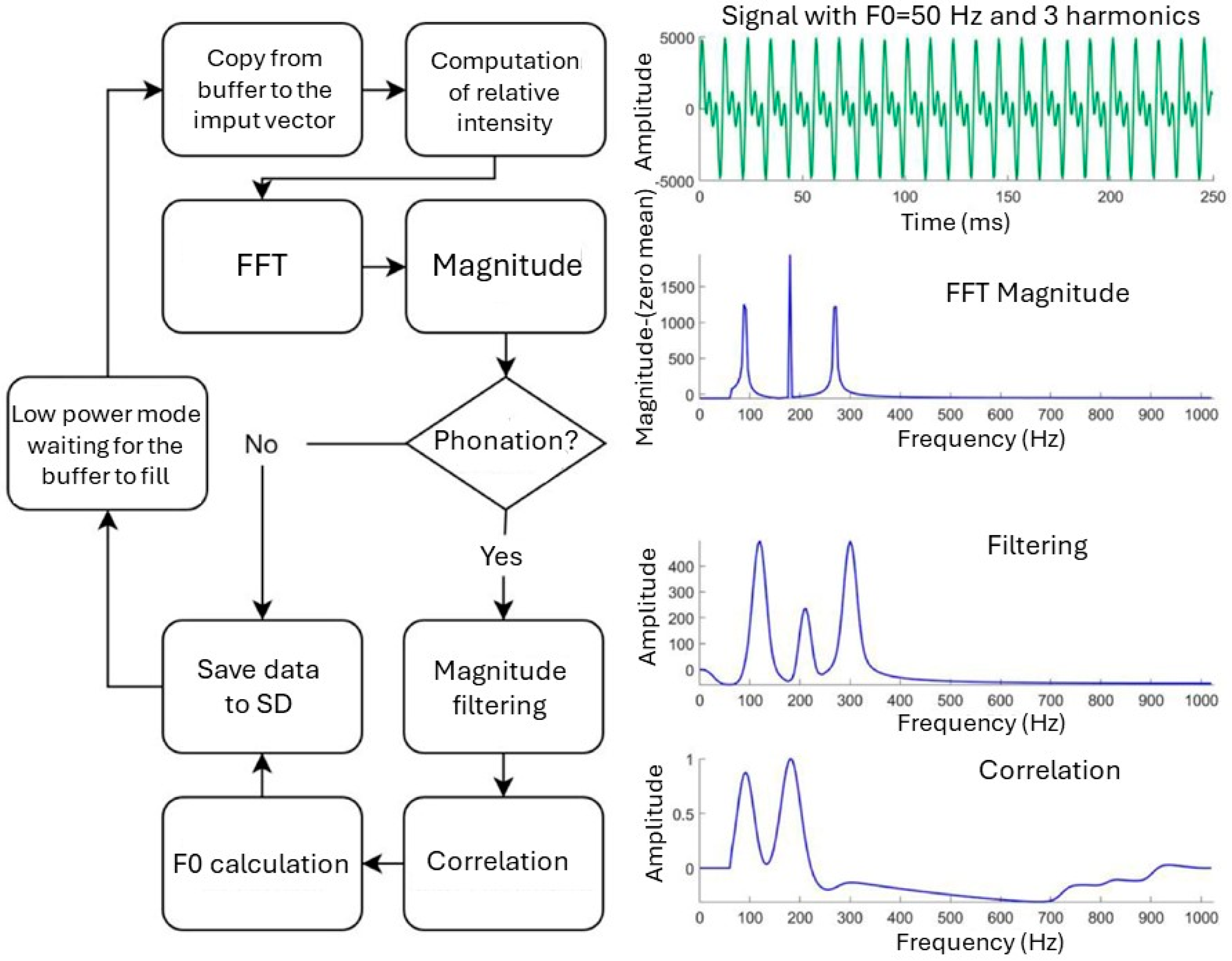
3.2. Signal Processing
3.2.1. Signal Acquisition
3.2.2. Relative Intensity
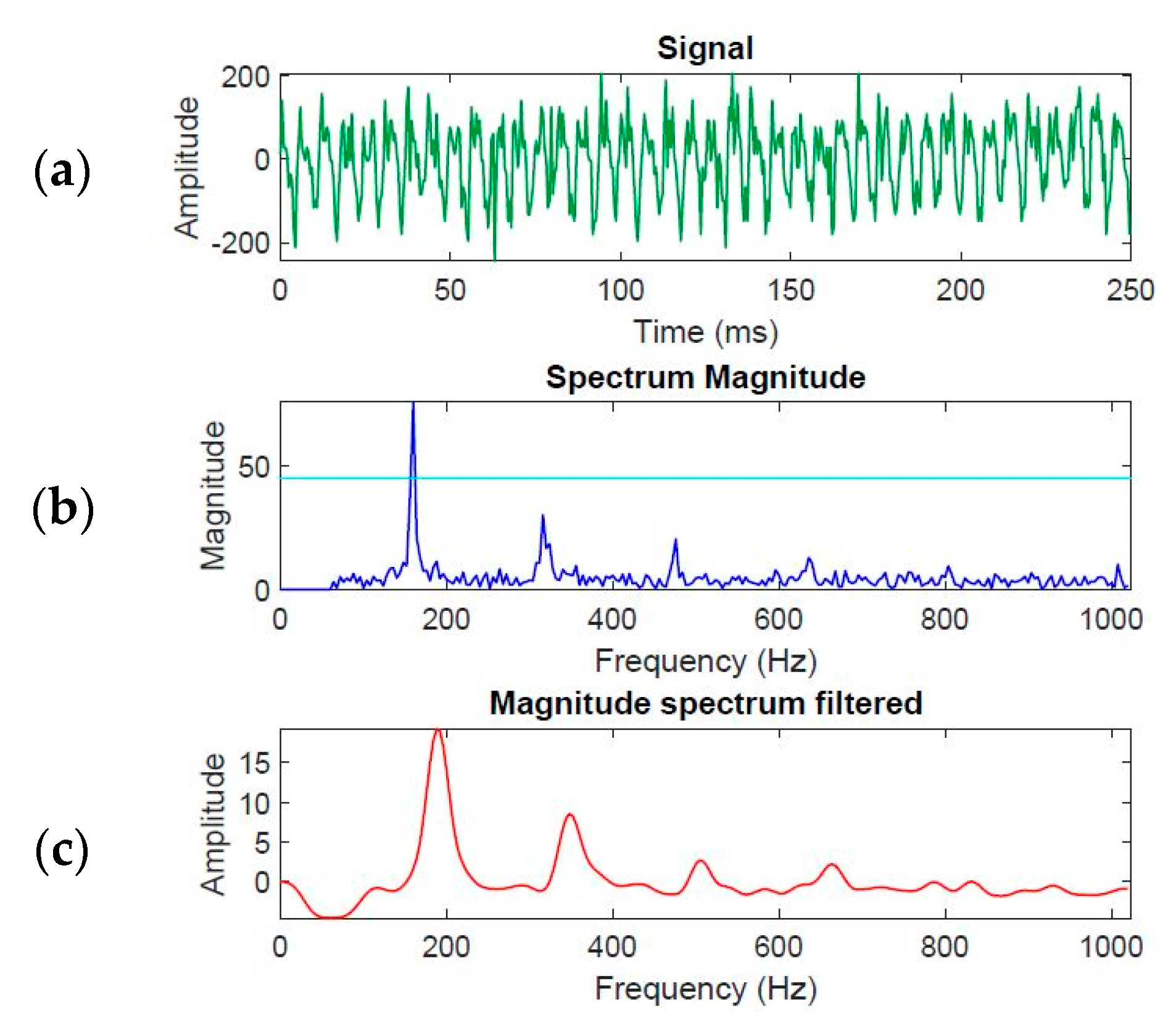
3.2.3. Voiced Activity Detection
3.2.4. Magnitude Spectrum
3.2.5. F0 Estimation
- F0 estimation from magnitude spectrum:
- 2.
- F0 estimation from magnitude spectrum autocorrelation:
- 3.
- Final value of F0:
3.2.6. Data Storage
3.3. Power Consumption
3.4. System Validation
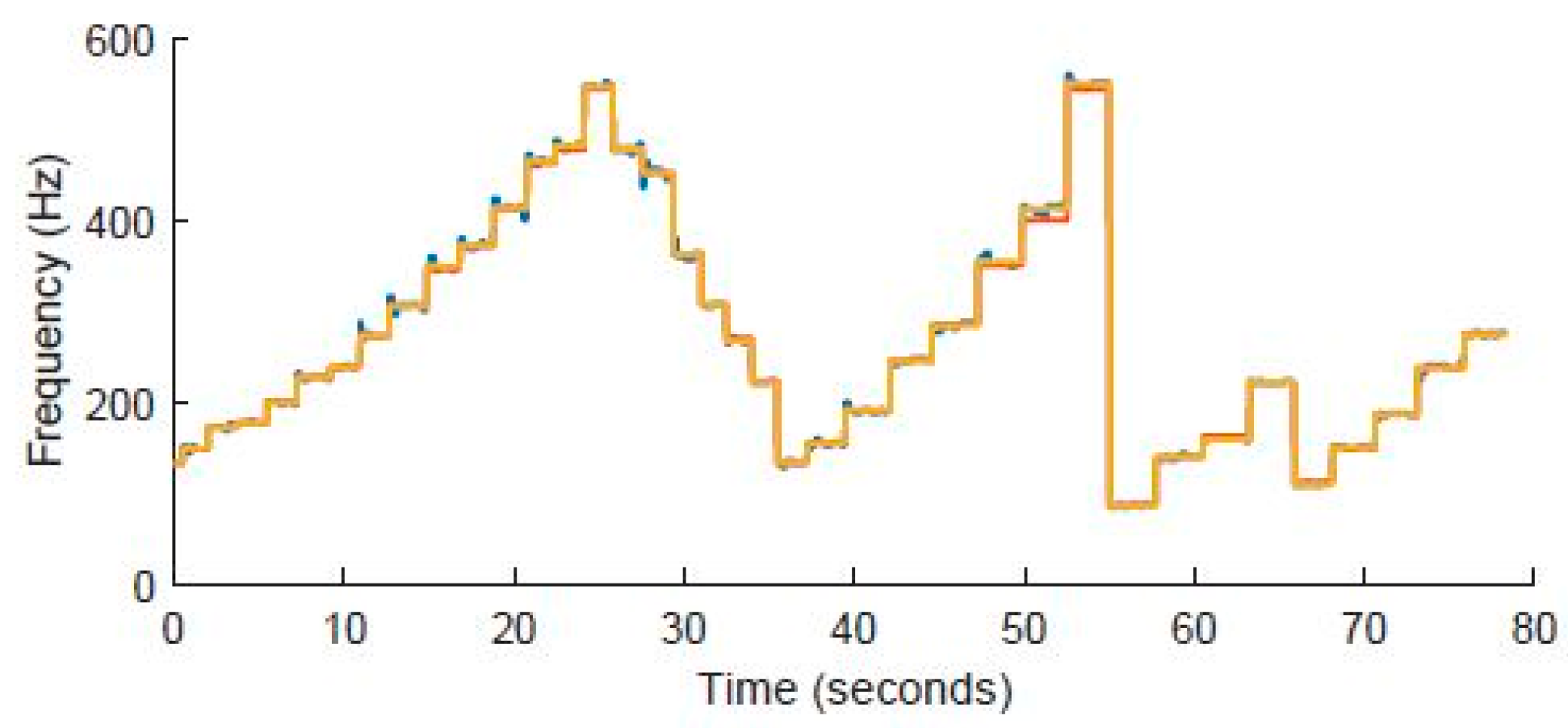
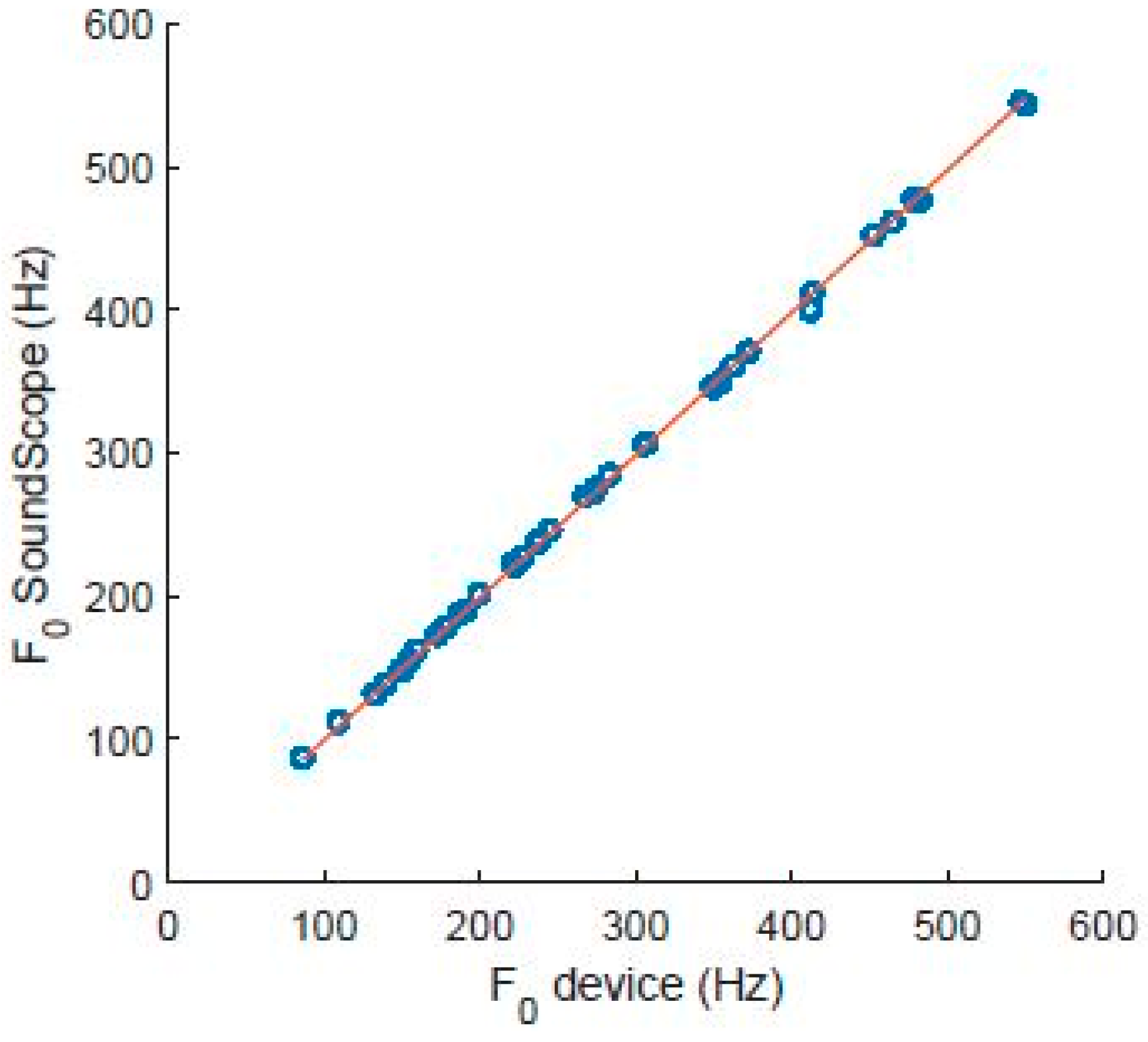
3.4.1. Microcontroller and Algorithm Validation
3.4.2. Validation of the Parameters of Interest in the Human Voice
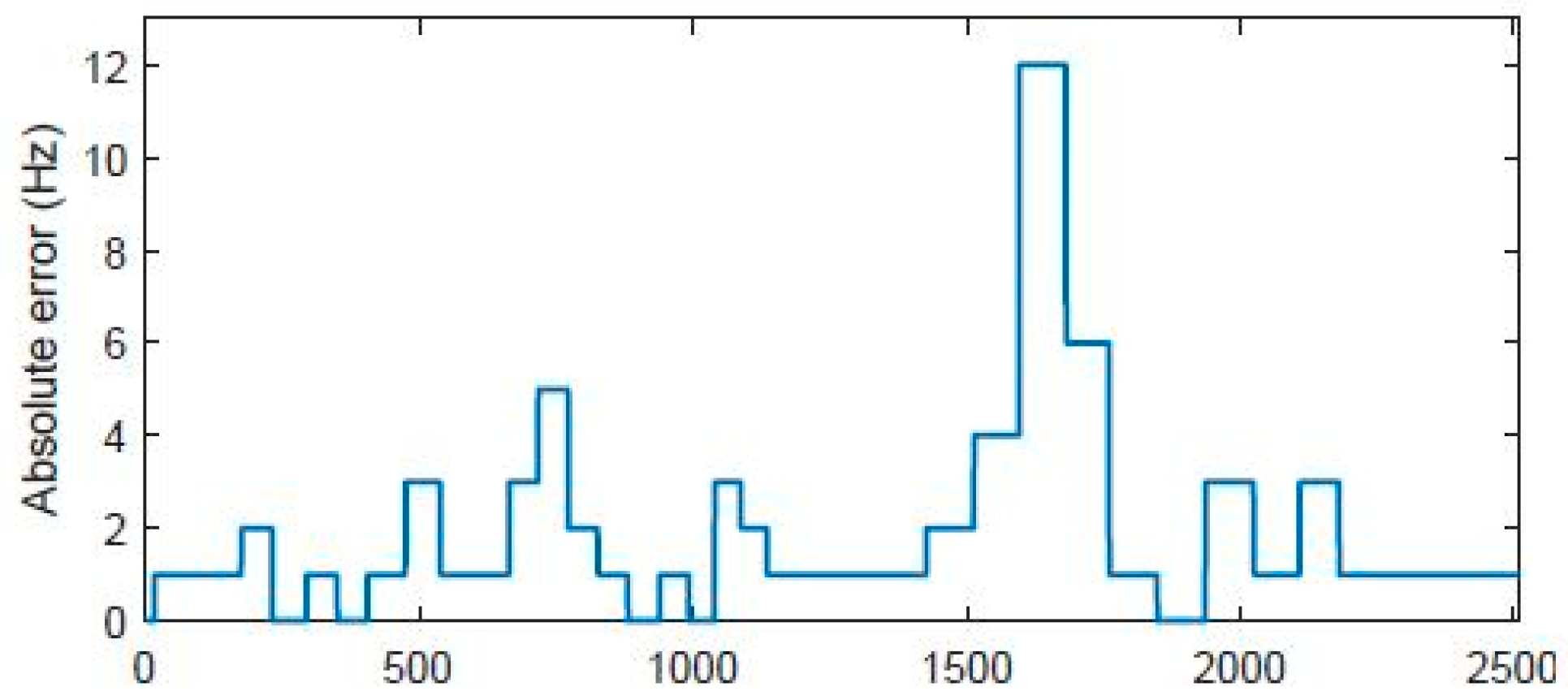
- Validation of F0 estimation:
- 2.
- Relative intensity validation:
- 3.
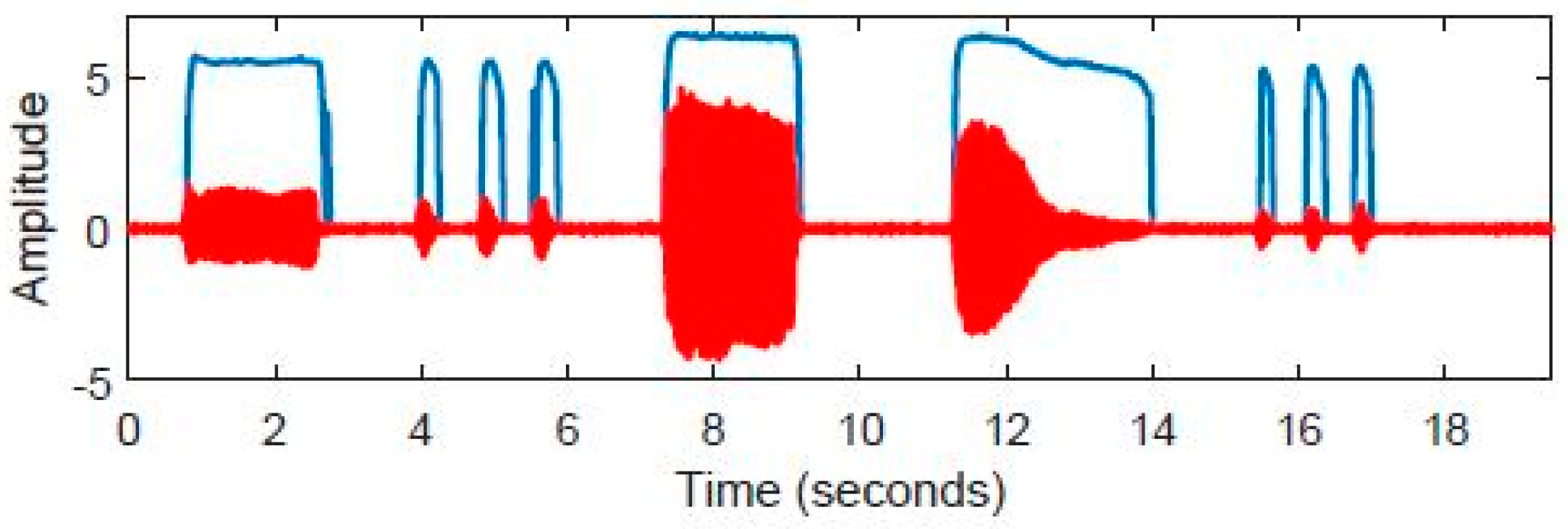
- Phonation time validation:
3.5. Subjects
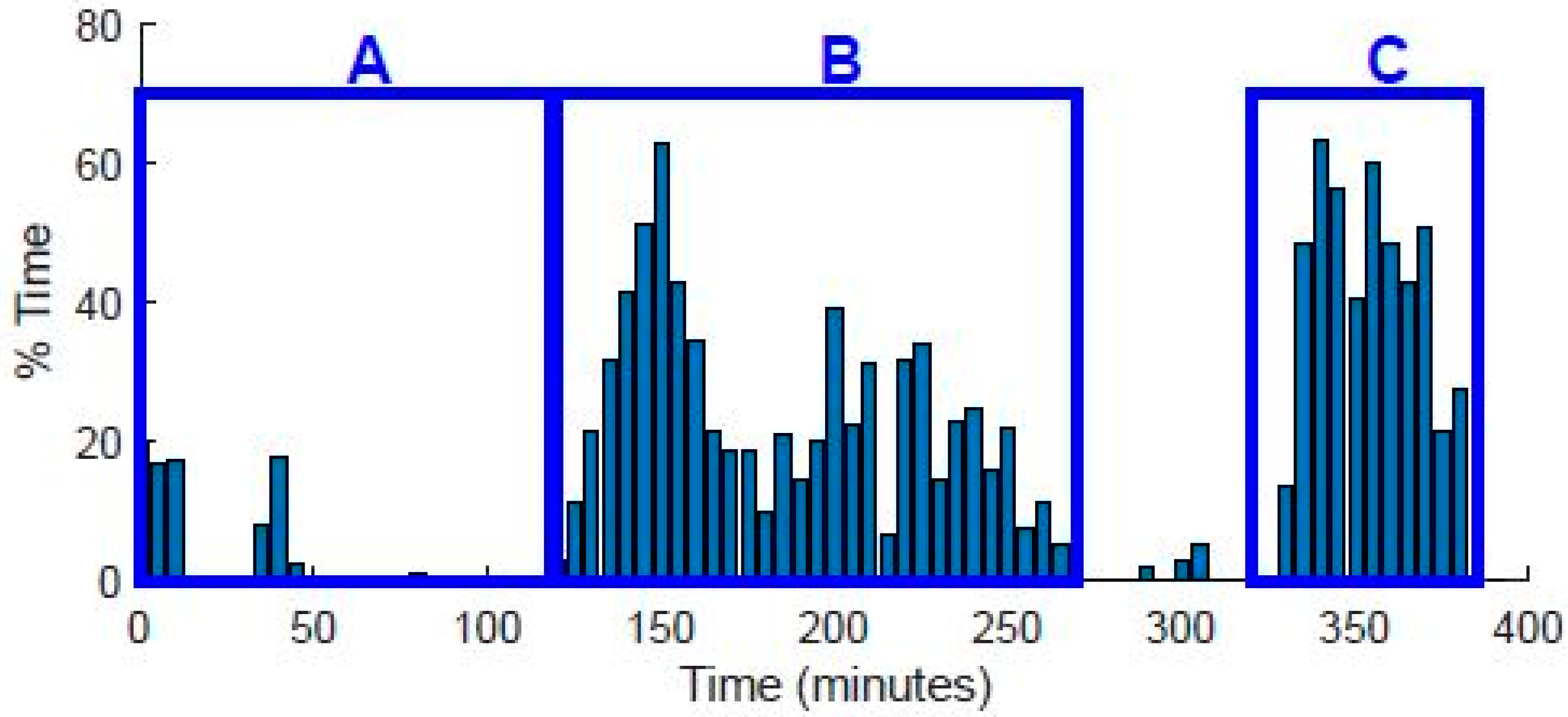
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
Appendix A
| Algorithm A1. estimation from the magnitude spectrum |
| 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: 30: 31: 32: 33: 34: 35: 36: 37: 38: 39: 40: 41: 42: 43: 44: 45: 46: 47: 48: 49: 50: 51: 52: 53: 54: 55: 56: 57: 58: 59: 60: 61: 62: 63: 64: 65: |
References
- Roy, N.; Merrill, R.M.; Gray, S.D.; Smith, E.M. Voice Disorders in the General Population: Prevalence, Risk Factors, and Occupational Impact. Laryngoscope 2005, 115, 1988–1995. [Google Scholar] [CrossRef] [PubMed]
- Vilkman, E. Occupational safety and health aspects of voice and speech professions. Folia Phoniatr. Logop. 2004, 56, 220–253. [Google Scholar] [CrossRef] [PubMed]
- Artkoski, M.; Tommila, J.; Laukkanen, A.M. Changes in voice during a day in normal voices without vocal loading. Logoped. Phoniatr. Vocology 2002, 27, 118–123. [Google Scholar] [CrossRef] [PubMed]
- Laukkanen, A.M.; Ilomäki, I.; Leppänen, K.; Vilkman, E. Acoustic measures and self-reports of vocal fatigue by female teachers. J. Voice 2008, 22, 283–289. [Google Scholar] [CrossRef] [PubMed]
- Lehto, L.; Laaksonen, L.; Vilkman, E.; Alku, P. Changes in objective acoustic measurements and subjective voice complaints in call center customer-service advisors during one working day. J. Voice 2008, 22, 164–177. [Google Scholar] [CrossRef] [PubMed]
- Rantala, L.; Vilkman, E. Relationship between subjective voice complaints and acoustic parameters in female teachers’ voices. J. Voice 1999, 13, 484–495. [Google Scholar] [CrossRef] [PubMed]
- Rantala, L.; Vilkman, E.; Bloigu, R. Voice changes during work: Subjective complaints and objective measurements for female primary and secondary schoolteachers. J. Voice 2002, 16, 344–355. [Google Scholar] [CrossRef] [PubMed]
- Jónsdottir, V.; Laukkanen, A.M.; Vilkman, E. Changes in teachers’ speech during a working day with and without electric sound amplification. Folia Phoniatr. Logop. 2002, 54, 282–287. [Google Scholar] [CrossRef] [PubMed]
- Vilkman, E.; Lauri, E.R.; Alku, P.; Sala, E.; Sihvo, M. Effects of prolonged oral reading on F0, SPL, subglottal pressure and amplitude characteristics of glottal flow waveforms. J. Voice 1999, 13, 303–312. [Google Scholar] [CrossRef]
- Rantala, L.; Lindholm, P.; Vilkman, E. F0 change due to voice loading under laboratory and field conditions. A pilot study. Logop. Phoniatr. Vocology 1998, 23, 164–168. [Google Scholar] [CrossRef]
- Švec, J.G.; Titze, I.R.; Popolo, P.S. Estimation of sound pressure levels of voiced speech from skin vibration of the neck. J. Acoust. Soc. Am. 2005, 117, 1386–1394. [Google Scholar] [CrossRef] [PubMed]
- Zañartu, M. Smartphone-Based Detection of Voice Disorders by Long-Term Monitoring of Neck Acceleration Features. In Proceedings of the 2013 IEEE International Conference on Body Sensor Networks, Cambridge, MA, USA, 6–9 May 2013; Available online: https://www.academia.edu/65461206/Smartphone_based_detection_of_voice_disorders_by_long_term_monitoring_of_neck_acceleration_features (accessed on 8 April 2024).
- Searl, J.; Dietsch, A.M. Tolerance of the VocaLogTM Vocal Monitor by Healthy Persons and Individuals with Parkinson Disease. J. Voice 2015, 29, 518.e13–518.e20. [Google Scholar] [CrossRef] [PubMed]
- Masuda, T.; Ikeda, Y.; Manako, H.; Komiyama, S. Analysis of vocal abuse: Fluctuations in phonation time and intensity in 4 groups of speakers. Acta Otolaryngol. 1993, 113, 547–552. [Google Scholar] [CrossRef] [PubMed]
- Ainsworth, W.A. Clinical Voice Disorders: An Interdisciplinary Approach, 3rd edn. By Arnold E. Aronson.Pp. 394. Thieme, 1990. DM 78.00 hardback. ISBN 3 13 598803 1. Exp. Physiol. 1992, 77, 537. [Google Scholar] [CrossRef]
- Ahlander, V.L.; Garc, D.P.; Whitling, S.; Rydell, R.; Löfqvist, A. Teachers’ Voice Use in Teaching Environments: A Field Study Using Ambulatory Phonation Monitor. J. Voice 2014, 28, 841.e5–841.e15. [Google Scholar] [CrossRef]
- Cheyne, H.A.; Hanson, H.M.; Genereux, R.P.; Stevens, K.N.; Hillman, R.E. Development and testing of a portable vocal accumulator. J. Speech Lang. Hear. Res. 2003, 46, 1457–1467. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Mehta, D.D.; Zeitels, S.M.; Burns, J.A.; Barbu, A.M.; Hillman, R.E. Average Ambulatory Measures of Sound Pressure Level, Fundamental Frequency, and Vocal Dose Do Not Differ Between Adult Females With Phonotraumatic Lesions and Matched Control Subjects. Ann. Otol. Rhinol. Laryngol. 2015, 124, 864–874. [Google Scholar] [CrossRef] [PubMed]
- Zanartu, M.; Ho, J.C.; Mehta, D.D.; Hillman, R.E.; Wodicka, G.R. Subglottal Impedance-Based Inverse Filtering of Voiced Sounds Using Neck Surface Acceleration. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1929–1939. [Google Scholar] [CrossRef]
- Van Stan, J.H.; Gustafsson, J.; Schalling, E.; Hillman, R.E. Direct Comparison of Three Commercially Available Devices for Voice Ambulatory Monitoring and Biofeedback. Perspect. Voice Voice Disord. 2014, 24, 80–86. [Google Scholar] [CrossRef]
- Fryd, A.S.; van Stan, J.H.; Hillman, R.E.; Mehta, D.D. Estimating Subglottal Pressure From Neck-Surface Acceleration During Normal Voice Production. J. Speech Lang. Hear. Res. 2016, 59, 1335–1345. [Google Scholar] [CrossRef]
- Morrow, S.L.; Connor, N.P. Comparison of voice-use profiles between elementary classroom and music teachers. J. Voice 2011, 25, 367–372. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.D.; Van Stan, J.H.; Hillman, R.E. Relationships between vocal function measures derived from an acoustic microphone and a subglottal neck-surface accelerometer. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 659–668. [Google Scholar] [CrossRef] [PubMed]
- Holbrook, A.; Rolnick, M.I.; Bailey, C.W. Treatment of vocal abuse disorders using a vocal intensity controller. J. Speech Hear. Disord. 1974, 39, 298–303. [Google Scholar] [CrossRef] [PubMed]
- Zicker, J.E.; Tompkins, W.J.; Rubow, R.T.; Abbs, J.H. A portable microprocessor-based biofeedback training device. IEEE Trans. Biomed. Eng. 1980, 27, 509–515. [Google Scholar] [CrossRef] [PubMed]
- Ryu, S.; Komiyama, S.; Kannae, S.; Watanabe, H. A newly devised speech accumulator. ORL J. Otorhinolaryngol. Relat. Spec. 1983, 45, 108–114. [Google Scholar] [CrossRef]
- Ohlsson, A.C.; Brink, O.; Lofqvist, A. A voice accumulation--validation and application. J. Speech Hear. Res. 1989, 32, 451–457. [Google Scholar] [CrossRef] [PubMed]
- McGillivray, R.; Proctor-Williams, K.; McLister, B. Simple biofeedback device to reduce excessive vocal intensity. Med. Biol. Eng. Comput. 1994, 32, 348–350. [Google Scholar] [CrossRef] [PubMed]
- Rantala, L.; Haataja, K.; Vilkman, E.; Körkkö, P. Practical arrangements and methods in the field examination and speaking style analysis of professional voice users. Scand. J. Logop. Phoniatr. 1994, 19, 43–54. [Google Scholar] [CrossRef]
- Buekers, R.; Bierens, E.; Kingma, H.; Marres, E.H.M.A. Vocal load as measured by the voice accumulator. Folia Phoniatr. Logop. 1995, 47, 252–261. [Google Scholar] [CrossRef]
- Airo, E.; Olkinuora, P.; Sala, E. A method to measure speaking time and speech sound pressure level. Folia Phoniatr. Logop. 2000, 52, 275–288. [Google Scholar] [CrossRef]
- Szabo, A.; Hammarberg, B.; Håkansson, A.; Södersten, M. A voice accumulator device: Evaluation based on studio and field recordings. Logoped. Phoniatr. Vocology 2001, 26, 102–117. [Google Scholar] [CrossRef] [PubMed]
- Popolo, P.S.; Švec, J.G.; Titze, I.R. Adaptation of a Pocket PC for use as a wearable voice dosimeter. J. Speech Lang. Hear. Res. 2005, 48, 780–791. [Google Scholar] [CrossRef] [PubMed]
- Virebrand, M. Real-Time Monitoring of Voice Characteristics Usingaccelerometer and Microphone Measurements. 2011. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A432959&dswid=-3972 (accessed on 8 April 2024).
- Lindstrom, F.; Waye, K.P.; Södersten, M.; McAllister, A.; Ternström, S. Observations of the relationship between noise exposure and preschool teacher voice usage in day-care center environments. J. Voice 2011, 25, 166–172. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.D.; Zañartu, M.; Feng, S.W.; Cheyne, H.A.I.; Hillman, R.E. Mobile voice health monitoring using a wearable accelerometer sensor and a smartphone platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar] [CrossRef] [PubMed]
- Carullo, A.; Vallan, A.; Astolfi, A. Design issues for a portable vocal analyzer. IEEE Trans. Instrum. Meas. 2013, 62, 1084–1093. [Google Scholar] [CrossRef]
- Carullo, A.; Vallan, A.; Astolfi, A. A low-cost platform for voice monitoring. In Proceedings of the 2013 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Minneapolis, MN, USA, 6–9 May 2013; pp. 67–72. [Google Scholar] [CrossRef]
- Hillman, R.E.; Mehta, D.D. Ambulatory Monitoring of Daily Voice Use. Perspect. Voice Voice Disord. 2011, 21, 56–61. [Google Scholar] [CrossRef]
- Hunter, E.J.; Hunter, E.J. Vocal Dose Measures: General Rationale, Traditional Methods and Recent Advances. 2016. Available online: https://www.researchgate.net/publication/311192575 (accessed on 17 June 2024).
- Bottalico, P.; Ipsaro Passione, I.; Astolfi, A.; Carullo, A.; Hunter, E.J. Accuracy of the quantities measured by four vocal dosimeters and its uncertainty. J. Acoust. Soc. Am. 2018, 143, 1591–1602. [Google Scholar] [CrossRef]
- VocaLog2 Help File. Available online: http://www.vocalog.com/VL2_Help/VocaLog2_Help.html (accessed on 10 April 2024).
- Mehta, D.D.; Chwalek, P.C.; Quatieri, T.F.; Brattain, L.J. Wireless Neck-Surface Accelerometer and Microphone on Flex Circuit with Application to Noise-Robust Monitoring of Lombard Speech. In Proceedings of the 18th Annual Conference of the International Speech Communication Association, Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 684–688. [Google Scholar] [CrossRef]
- Chwalek, P.C.; Mehta, D.D.; Welsh, B.; Wooten, C.; Byrd, K.; Froehlich, E.; Maurer, D.; Lacirignola, J.; Quatieri, T.F.; Brattain, L.J. Lightweight, on-body, wireless system for ambulatory voice and ambient noise monitoring. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Las Vegas, NV, USA, 4–7 March 2018; Volume 2018, pp. 205–209. [Google Scholar] [CrossRef]
- Hunter, E.J.; Titze, I.R. Variations in intensity, fundamental frequency, and voicing for teachers in occupational versus nonoccupational settings. J. Speech Lang. Hear. Res. 2010, 53, 862–875. [Google Scholar] [CrossRef]
- Gama, A.C.C.; Santos, J.N.; Pedra, E.d.F.P.; Rabelo, A.T.V.; Magalhães, M.d.C.; Casas, E.B.d.L. Vocal dose in teachers: Correlation with dysphonia. CoDAS 2016, 28, 190–192. [Google Scholar] [CrossRef] [PubMed]
- Morrow, S.L.; Connor, N.P. Voice amplification as a means of reducing vocal load for elementary music teachers. J. Voice 2011, 25, 441–446. [Google Scholar] [CrossRef]
- Gaskill, C.S.; O’Brien, S.G.; Tinter, S.R. The effect of voice amplification on occupational vocal dose in elementary school teachers. J. Voice 2012, 26, 667.e19–667.e27. [Google Scholar] [CrossRef] [PubMed]
- Astolfi, A.; Puglisi, G.E.; Cantor Cutiva, L.C.; Pavese, L.; Carullo, A.; Burdorf, A. Associations between Objectively-measured Acoustic Parameters and Occupational Voice Use among Primary School Teachers. Energy Procedia 2015, 78, 3422–3427. [Google Scholar] [CrossRef]
- Echternach, M.; Nusseck, M.; Dippold, S.; Spahn, C.; Richter, B. Fundamental frequency, sound pressure level and vocal dose of a vocal loading test in comparison to a real teaching situation. Eur. Arch. Otorhinolaryngol. 2014, 271, 3263–3268. [Google Scholar] [CrossRef] [PubMed]
- Franca, M.C.; Wagner, J.F. Effects of vocal demands on voice performance of student singers. J. Voice 2015, 29, 324–332. [Google Scholar] [CrossRef] [PubMed]
- Van Stan, J.H.; Mehta, D.D.; Hillman, R.E. The Effect of Voice Ambulatory Biofeedback on the Daily Performance and Retention of a Modified Vocal Motor Behavior in Participants With Normal Voices. J. Speech Lang. Hear. Res. 2015, 58, 713–721. [Google Scholar] [CrossRef] [PubMed]
- Titze, I.R.; Hunter, E.J.; Švec, J.G. Voicing and silence periods in daily and weekly vocalizations of teachers. J. Acoust. Soc. Am. 2007, 121, 469–478. [Google Scholar] [CrossRef] [PubMed]
- Astolfi, A.; Carullo, A.; Pavese, L.; Puglisi, G.E. Duration of voicing and silence periods of continuous speech in different acoustic environments. J. Acoust. Soc. Am. 2015, 137, 565–579. [Google Scholar] [CrossRef] [PubMed]
- Yoshiyuki, H.; Fuller, B.F. Selected acoustic characteristics of voices before intubation and after extubation. J. Speech Hear. Res. 1990, 33, 505–510. [Google Scholar] [CrossRef]
- Misono, S.; Banks, K.; Gaillard, P.; Goding, G.S.; Yueh, B. The clinical utility of vocal dosimetry for assessing voice rest. Laryngoscope 2015, 125, 171–176. [Google Scholar] [CrossRef]
- Stevens, K.N.; Kalikow, D.N.; Willemain, T.R. A miniature accelerometer for detecting glottal waveforms and nasalization. J. Speech Hear. Res. 1975, 18, 594–599. [Google Scholar] [CrossRef]
- Castellana, A.; Carullo, A.; Casassa, F.; Astolfi, A. Performance Comparison of Different Contact Microphones Used for Voice Monitoring. 2015. Available online: https://iris.polito.it/handle/11583/2649989 (accessed on 17 June 2024).
- Hunter, E.J. Teacher response to ambulatory monitoring of voice. Logoped. Phoniatr. Vocology 2012, 37, 133–135. [Google Scholar] [CrossRef] [PubMed]
- Klatt, D.H. Linguistic uses of segmental duration in English: Acoustic and perceptual evidence. J. Acoust. Soc. Am. 1976, 59, 1208–1221. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Device Name | Monitor Feedback | Sensor Type | Parameters Measured | Rec. Time | Sampling Rate (Hz) | Analysis Interval (Subinterval) | Dimensions (cm) | Weight (g) | Price |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Holbrook et al. [24] | 1974 | VIC | F | Contact Mic | A, tphon | 12 × 6 × 4 | |||||
| Zicker et al. [25] | 1980 | F | Mic | A | 200 | 0.5 s | 15 × 10 × 8 | 1000 | |||
| Ryu et al. [26] | 1983 | M | Contact Mic | A, tphon | 12 h | 60 s [17] | 9 × 6 × 3 | 150 | |||
| Ohlsson et al. [27] | 1989 | RALOF01 | M | Contact Piezoel. Mic | F0, tphon | 12 h | 1200–1800 | 6 s (200 ms) | 19 × 11 × 5 | 475 | |
| Masuda et al. [14] | 1993 | M | Contact Mic | A, tphon | 12 h | 0.1 s | 13 × 9 × 3 | 400 | |||
| McGillivray et al. [28] | 1994 | F | Mic | A | |||||||
| Rantala et al. [29] | 1994 | M | Mic | F0, A | 1.5 h | 5000 | 70–250 ms (2.5–10 ms) | ||||
| Buekers et al. [30] | 1995 | M | Mic | A, tphon | 12 h | 1 | 1 s | 15 × 9 × 4 | 600 | ||
| Airo et al. [31] | 2000 | M | 2 Mics | A, tphon | 8 h | 100 | 2 s (10 ms) | 120 | |||
| Szabo et al. [32] | 2001 | VACLF1 | M | Contact Mic | F0, tphon | Aprox. 12 h | 1–10 s (50, 100, 200, 500 ms) | 14 × 7 × 3 | 250 | ||
| Cheyne et al. [17] | 2003 | PVA or APM | M, F | Acc | F0, A, tphon | 12 h | 11,025 | 125 ms (25 ms) | 12 × 8.5 × 2 | 200 | $5000 |
| Popolo et al. [33] | 2005 | NCBS | M | Acc | F0, A, tphon | 2–3 h | 30 ms | 13 × 8 × 1.6 | |||
| Virebrand [34] | 2011 | VoxLog | M, F | Acc. Mic | F0, A, tphon | 2–14 (h) 1 | 5–60 s (100–1000 ms) 1 | 12 × 2.5 × 2.5 [29] | |||
| Lindstrom et al. [35] | 2011 | M | Acc, Mic | F0, A, tphon | 48,000 | 30 ms | |||||
| Mehta et al. [36] | 2012 | VHM | M, F [32] | Acc | F0, A, tphon | 18 h | 11,025 | 50 ms (25 ms) | 175 1 | ||
| Carullo et al. [37,38] | 2013 | Voice-Care | M | Contact Mic | F0, A, tphon | 5 h 2, 11 h | 19,230 (M) 38,460 (calbi.) | 30 ms | 15 × 10 × 5 | 400 € 900 € 3 1800 € 4 | |
| Griffin Laboratories, Temecula, USA (Van Stan et al. [20]; Hilman, Mehta [39]; Hunter [40]; Bottalico et al. [41]; Vocalog [42]) | 2014 | Vocalog | M, F | Contact Mic | A, tphon | 3 weeks 5 | 1 s | 7 × 5.5 × 1.5 | $999 | ||
| 2016 | Vocalog2 | M, F | Contact Mic | A, tphon | 3 days [39] | 1 s | $394 | ||||
| Mehta et al. [43]; Chwalek et al. [44] | 2017 | M | Acc Mic | F0, A, tphon | 24 h | 44,100 | 50 ms | 68 × 14 × 5 5 | 14 6 |
| Voice Parameter | APM | VoxLog | VocalLog | Voice-Care |
|---|---|---|---|---|
| Intensity (dBspl) | X | X | X | X |
| Intensity warning | X | X | X | |
| Fundamental frequency (Hz) | X | X | X | |
| Frequency warning | X | X | ||
| Phonation time (hh:mm:ss) | X | X | X | X |
| Ambient noise (dBSPL) | X | |||
| Number of Cycles | X | |||
| Distance travelled by the vocal folds (meters) | X | |||
| Intensity calibration | Daily | Not necessary | Once | Once |
| Component | Dimensions (mm) | Weight (g) | Price (€) |
|---|---|---|---|
| Microcontroller MSP430FR5994 | 16 × 16 × 1.5 | 0.462 | 7.18 |
| Accelerometer BU-27135-000 | 7.92 × 5.59 × 2.28 | 0.28 | 41.25 |
| Molex 504077-1891 micro SD slot | 11.32 × 15.4 × 2.3 | 0.188 | 1.77 |
| Motherboard + SMD components | 20 × 16 × 2 | <1 | <2.00 |
| 400 mAh battery | 37 × 25 × 5.2 | 13 | 4.44 |
| Circuit for battery charging | 37 × 10 × 2.5 | <5 | <10.00 |
| Total | 55 × 36 × 6.5 | <20 | <67 |
| Recording | Audacity (s) | Device (s) | Ratio (%) |
|---|---|---|---|
| Subject 1 | 81 | 35 | 43 |
| Subject 2 | 74 | 60 | 81 |
| Subject 3 | 75 | 69 | 92 |
| Vocals | 7.7 | 7.9 | 103 |
| Day | Recording Time (h) | % Phonation |
|---|---|---|
| 1 | 5.50 | 0.18 |
| 2 | 5.85 | 0.10 |
| 3 | 6.37 | 0.15 |
| 4 | 6.19 | 0.13 |
| 5 | 4.52 | 0.11 |
| 6 | 5.27 | 0.10 |
| 7 | 6.48 | 0.16 |
| 8 | 7.17 | 0.11 |
| 9 | 6.19 | 0.12 |
| 10 | 4.75 | 0.20 |
| 11 | 5.67 | 0.06 |
| 12 | 5.62 | 0.08 |
| 13 | 5.79 | 0.11 |
| 14 | 2.27 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Llorente, M.; Podhorski, A.; Fernandez, S. Wearable Voice Dosimetry System. Appl. Sci. 2024, 14, 5806. https://doi.org/10.3390/app14135806
Llorente M, Podhorski A, Fernandez S. Wearable Voice Dosimetry System. Applied Sciences. 2024; 14(13):5806. https://doi.org/10.3390/app14135806
Chicago/Turabian StyleLlorente, Marcos, Adam Podhorski, and Secundino Fernandez. 2024. "Wearable Voice Dosimetry System" Applied Sciences 14, no. 13: 5806. https://doi.org/10.3390/app14135806
APA StyleLlorente, M., Podhorski, A., & Fernandez, S. (2024). Wearable Voice Dosimetry System. Applied Sciences, 14(13), 5806. https://doi.org/10.3390/app14135806