
Automated Construction Method of Knowledge Graphs for Pirate Events

Abstract
1. Introduction
- (1)
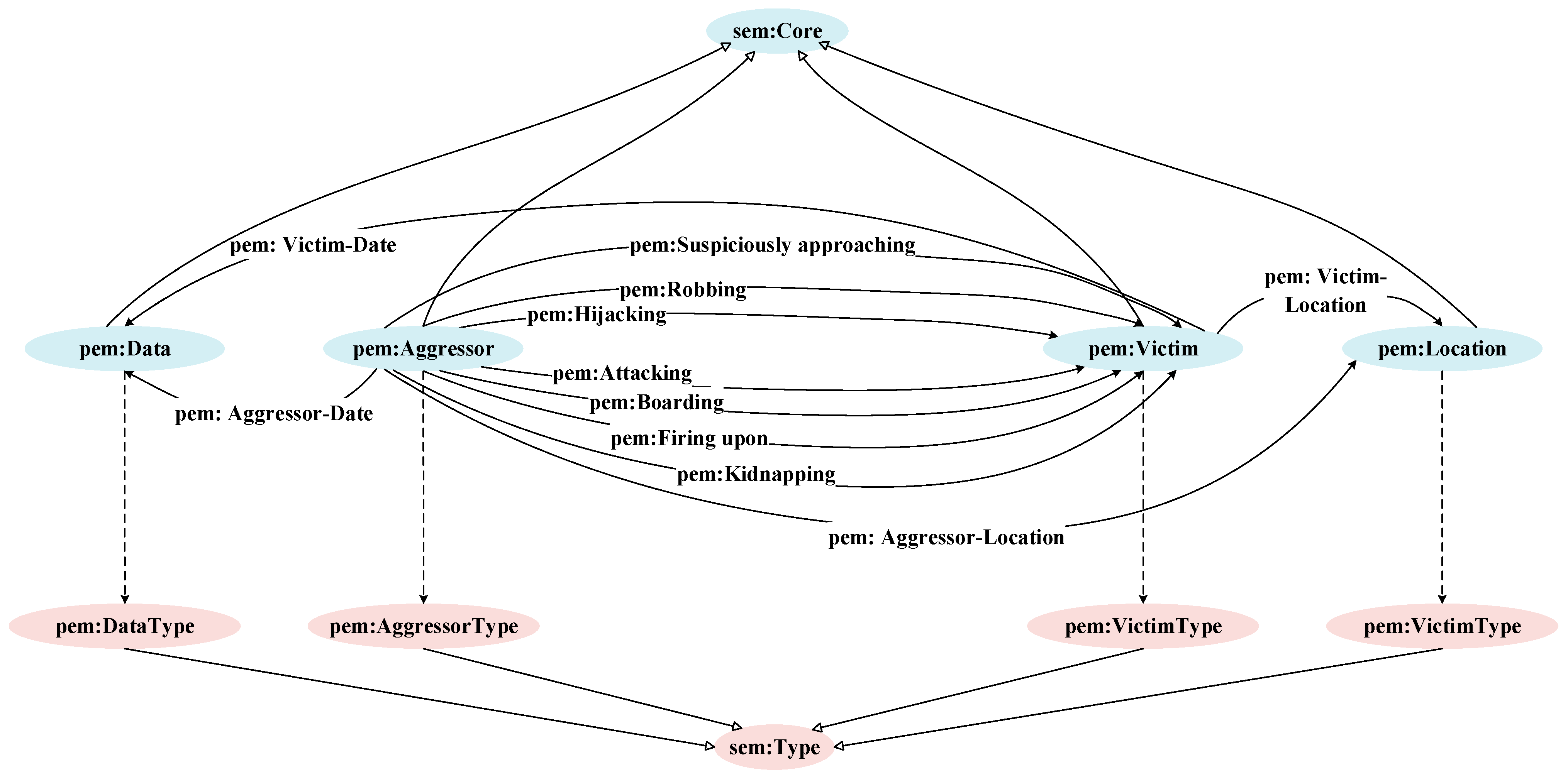
- A Pirate Event Model (PEM) is designed as an ontology model of the knowledge graphs for pirate events. Four types of entities are set: pem: Aggressor, pem: Victim, pem: Location, and pem: Date, alongside the entity attributes of these four types of entities. In addition, two major categories of 11 types of relations among entities are designed.
- (2)
- For entity extraction, the BERT-BiLSTM-CRF model is used for NER from the soft data of pirate events. In the entity linking process, the method of distance learning is introduced for entity linking model training to address the problem of the lack of large amount of labeled text data. In addition, the context attention mechanism is proposed to select the words that are helpful for disambiguation, so as to enhance the performance of entity linking model training.
- (3)
- For RE, based on the traditional sentence-level attention mechanism, a bag-level attention mechanism is further introduced, which emphasizes the sentences that are related to the bag label at the global level by calculating the correlation between sentences. As such, the information of the bag is expressed, while sentences that are not related to the bag label are suppressed. Furthermore, bags with the same labels are assembled as a bag-group, and comprehensive discriminative features are mined at the bag-group-level as high-quality features of the relations between representation entity pairs.
- (4)
- For the algorithms involved in instance layer filling, experiments were designed to verify the effectiveness and superiority of the proposed models, including NER, entity linking, and relation extraction models, at the same time. According to the given pirate event text, using the proposed NER, entity linking, and relation extraction models, knowledge triples can be accurately extracted, and a high-quality knowledge graph for pirate events is constructed.
2. Related Works
2.1. Knowledge Graph Ontology Model
2.2. Entity Extraction and Linking
2.3. Relation Extraction
2.4. Natural Language Processing Applications in the Maritime
3. Construction of Knowledge Graph Ontology Model for Pirate Events
3.1. Entities
3.2. Association Relations
4. Instance Layer Filling of Knowledge Graph for Pirate Events
4.1. Entity Extraction
4.2. Entity Linking
| Algorithm 1: Entity Linking Based on Context Attention Mechanism and Distance Learning. |
| Require: 1. The entity in using word2vec. Event text , and entity mention using the BERT model; 2. The association scores of each word in the event text with the entity are calculated according to Equation (3); 3. The word set corresponding to the top ranked words is selected based on the ranking of the association scores from highest to lowest; 4. Based on the word set and Equation (5), the attention weights are calculated; 5. of entity mention according to Equation (6); 6. into the feedforward neural network and output according to Equation (7); 7. The training loss function is calculated according to Equation (8), and the Adam optimization algorithm is used to minimize the model parameters; 8. , entity linking is achieved according to Equation (9). |
4.3. Relation Extraction
| Algorithm 2: Proposed RE Method. |
| Require: Text sequence containing entity pairs of pem: Aggressor and pem: 1. ; 2. PCNN is used to extract text sequence features ; 3. text sequences containing the same entity pair are encapsulated in bag ; 4. of the bag of all bags are calculated; 5. ; 6. of the bag-group are calculated according to Equation (13); 7. according to Equation (14); 8. is calculated according to Equation (15); 9. The representation vector g of the bag-group G is calculated according to Equation (16); 10. The training loss function is calculated according to Equation (17), and the Adam optimization algorithm is used to minimize the model parameters. 11. After the model training, relation prediction is performed using Equation (18) |
5. Experiment and Analysis
5.1. Data Sources
5.2. Performance Validation of NER
5.3. Performance Validation of Entity Linking
5.4. Performance Validation of Relation Extraction
5.5. Knowledge Graph Generation for Pirate Events
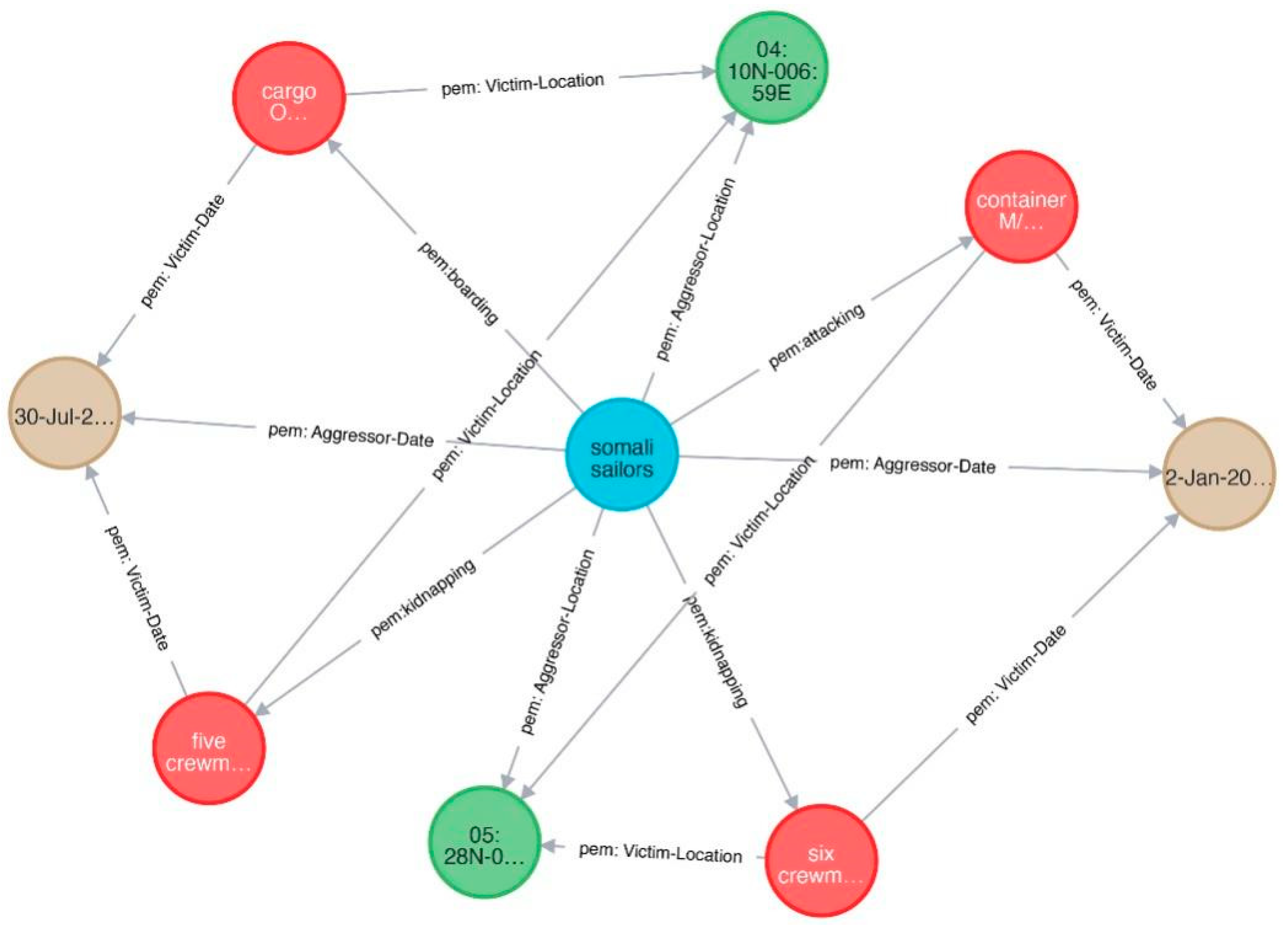
- Pirate event 1: On 30 July 2019, Somali sailors boarded the general cargo ship OYA underway near position 04:10N-006:59E, 15 nm southwest of Bonny Island. The pirates kidnapped five crewmen and escaped.
- Pirate event 2: On 2 January 2019, Somali sailors attacked a small container ship M/V MANDY, near position 05:28N-002:21E, 55 nm south of Cotonou. Six crewmen were kidnapped.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rosenberg, D. The political economy of piracy in the south China sea. Nav. War Coll. Rev. 2009, 62, 43–58. [Google Scholar]
- Hurlburt, K. The human cost of somali piracy. In Piracy at Sea; Springer: Berlin/Heidelberg, Germany, 2013; pp. 289–310. [Google Scholar]
- Jin, J.; Techera, E. Strengthening Universal Jurisdiction for Maritime Piracy Trials to Enhance a Sustainable Anti-Piracy Legal System for Community Interests. Sustainability 2021, 13, 7268. [Google Scholar] [CrossRef]
- Song, H.; Gi, I.; Ryu, J.; Kwon, Y.; Jeong, J. Production Planning Forecasting System Based on M5P Algorithms and Master Data in Manufacturing Processes. Appl. Sci. 2023, 13, 7829. [Google Scholar] [CrossRef]
- Núñez, R.C.; Samarakoon, B.; Premaratne, K.; Murthi, M.N. Hard and soft data fusion for joint tracking and classification/intent detection. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; IEEE: New York, NY, USA, 2013. [Google Scholar]
- Dragos, V.; Lerouvreur, X.; Gatepaille, S. A critical assessment of two methods for heterogeneous information fusion. In Proceedings of the 18th International Conference on Information Fusion (FUSION), Washington, DC, USA, 6–9 July 2015; IEEE: New York, NY, USA, 2015; pp. 42–49. [Google Scholar]
- Abirami, T.; Taghavi, E.; Tharmarasa, R.; Kirubarajan, T.; Boury-Brisset, A.-C. Fusing social network data with hard data. In Proceedings of the 18th International Conference on Information Fusion (FUSION), Washington, DC, USA, 6–9 July 2015. [Google Scholar]
- Burks, L.; Ahmed, N. Collaborative semantic data fusion with dynamically observable decision processes. In Proceedings of the 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Plachkov, A. Soft Data-Augmented Risk Assessment and Automated Course of Action Generation for Maritime Situational Awareness. Ph.D. Dissertation, University of Ottawa, Ottawa, ON, Canada, 2016. [Google Scholar]
- Buffett, S.; Cherry, C.; Dai, C.; Désilets, A.; Guo, H.; McDonald, D.; Su, J.; Tulpan, D. Arctic Maritime Awareness for Safety and Security (AMASS); Final Report; Canadian National Research Council: Ottawa, ON, Canada, 2017. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative KnowledgeBase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. YAGO: A large ontology from wikipedia and wordnet. J. Web Semant. 2008, 6, 203–217. [Google Scholar] [CrossRef]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a health knowledge graph from electronic medical records. Sci. Rep. 2017, 7, 5994. [Google Scholar] [CrossRef]
- Chen, P.; Lu, Y.; Zheng, V.W.; Chen, X.; Yang, B. KnowEdu: A system to construct knowledge graph for education. IEEE Access 2018, 6, 31553–31563. [Google Scholar] [CrossRef]
- Miao, R.; Zhang, X.; Yan, H.; Chen, C. A dynamic financial knowledge graph based on reinforcement learning and transfer learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5370–5378. [Google Scholar]
- Lagoze, C.; Hunter, J. The ABC ontology and model. J. Digit. Inf. 2001, 79, 160–176. [Google Scholar]
- Hage, W.R.V.; Malaisé, V.; Segers, R.; Hollink, L.; Schreiber, G. Design and Use of the Simple Event Model (SEM). J. Web Semant. 2011, 9, 128–136. [Google Scholar] [CrossRef]
- Zahila, M.N.; Noorhidawati, A.; Aspura, M.K.; Idaya, Y. Content extraction of historical Malay manuscripts based on Event Ontology Framework. Appl. Ontol. 2021, 16, 249–275. [Google Scholar] [CrossRef]
- Doerr, M.; Ore, C.E.; Stead, S. The CIDOC conceptual reference model: A new standard for knowledge sharing. In Tutorials, Posters, Panels and Industrial Contributions, Proceeding of the 26th International Conference on Conceptual Modelling, Auckland, New Zealand, 5–9 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; Volume 83, pp. 51–56. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Liu, L.Y.; Shang, J.B.; Ren, X.; Xu, F.; Gui, H.; Peng, J.; Han, J. Empower sequence labeling with task-aware neural language model. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 5253–5260. [Google Scholar]
- Ratinov, L.; Roth, D.; Downey, D.; Anderson, M. Local and global algorithms for disambiguation to Wikipedia. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; ACL: Stroudsburg, PA, USA, 2011; pp. 1375–1384. [Google Scholar]
- Varma, V.; Bysani, P.; Reddy, K.; Reddy, V.B.; Kovelamudi, S.; Vaddepally, S.R.; Nanduri, R.; Kumar, N.; Gsk, S.; Pingali, P. IIIT hyderabad in guided summarization and knowledge base population. In Proceedings of the Text Analysis Conference 2009, Gaithersburg, MD, USA, 16–17 November 2009; TAC: Washington DC, USA, 2009; pp. 213–222. [Google Scholar]
- Gottipati, S.; Jiang, J. Linking entities to a knowledge base with query expansion. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; ACL: Stroudsburg, PA, USA, 2011; pp. 804–813. [Google Scholar]
- Zhang, W.; Sim, Y.C.; Su, J.; Tan, C.L. Entity linking with effective acronym expansion, instance selection and topic modeling. In Proceedings of the 22th International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, 16–22 July 2011; pp. 1909–1914. [Google Scholar]
- Honnibal, M.; Dale, R. DAMSEL: The DSTO/Macquarie system for entity-linking. In Proceedings of the Theory and Applications of Categories, Gaithersburg, ML, USA, 16–17 November 2009; TAC: Washington DC, USA, 2009; pp. 1–4. [Google Scholar]
- Bunescu, R.; Paşca, M. Using encyclopedic knowledge for named entity disambiguation. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; ACL: Stroudsburg, PA, USA, 2006; pp. 9–16. [Google Scholar]
- Han, X.P.; Sun, L. A generative entity-mention model for linking entities with knowledge base. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; ACL: Stroudsburg, PA, USA, 2011; pp. 945–954. [Google Scholar]
- Francis-Landau, M.; Durrett, G.; Klein, D. Capturing semantic similarity for entity linking with convolutional neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 1256–1261. [Google Scholar]
- Wei, C.H.; Lee, K.; Leaman, R.; Lu, Z. Biomedical mention disambiguation using a deep learning approach. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; ACM: New Nork, NY, USA, 2019; pp. 307–313. [Google Scholar]
- Zuheros, C.; Tabik, S.; Valdivia, A.; Martínez-Cámara, E.; Herrera, F. Deep recurrent neural network for geographical entities disambiguation on social media data. Knowl. Based Syst. 2019, 173, 117–127. [Google Scholar] [CrossRef]
- Ganea, O.E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. In Proceedings of the Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 2619–2629. [Google Scholar]
- Sun, Y.M.; Ji, Z.Z.; Lin, L.; Wang, X.; Tang, D. Entity disambiguation with memory network. Neurocomputing 2018, 275, 2367–2373. [Google Scholar] [CrossRef]
- Raiman, J.R.; Raiman, O.M. Deeptype: Multilingual entity linking by neural type system evolution. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: Palo Alto, CA, USA, 2018; pp. 5406–5413. [Google Scholar]
- Bunescu, R.; Mooney, R.J. Subsequence kernels for relation extraction. In Proceedings of the NIPS 2005, Vancouver, BC, Canada, 5–8 December 2005; pp. 171–178. [Google Scholar]
- Culotta, A.; Sorensen, J. Dependency tree kernels for relation extraction. In Proceedings of the ACL 2005, Ann Arbor, MI, USA, 25–30 June 2005; pp. 423–429. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 541–550. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; pp. 148–163. [Google Scholar]
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multiinstance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 455–465. [Google Scholar]
- Yuan, Y.; Liu, L.; Tang, S.; Zhang, Z.; Zhuang, Y.; Pu, S.; Wu, F.; Ren, X. Cross-relation cross-bag attention for distantly-supervised relation extraction. In Proceedings of the AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 419–426. [Google Scholar]
- Christou, D.; Tsoumakas, G. Improving distantly-supervised relation extraction through BERT-based label and instance embeddings. IEEE Access 2021, 9, 62574–62582. [Google Scholar] [CrossRef]
- Zhou, Y.; Pan, L.; Bai, C.; Luo, S.; Wu, Z. Self-selective attention using correlation between instances for distant supervision relation extraction. Neural Netw. 2021, 142, 213–220. [Google Scholar] [CrossRef] [PubMed]
- Gan, L.; Ye, B.; Huang, Z.; Xu, Y.; Chen, Q.; Shu, Y. Knowledge graph construction based on ship collision accident reports to improve maritime traffic safety. Ocean. Coast. Manag. 2023, 240, 106660. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, X.; Xu, Y.; Xiang, B.; Gan, L.; Shu, Y. Knowledge graph for maritime pollution regulations based on deep learning methods. Ocean. Coast. Manag. 2023, 242, 106679. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, X.; Wang, Y.; Fan, S.; Wang, H.; Yang, Z.; Liu, Z.; Wang, J.; Shi, R. Analysis of factors affecting the severity of marine accidents using a data-driven Bayesian network. Ocean. Eng. 2023, 269, 113563. [Google Scholar] [CrossRef]
- Kamal, B.; Cakir, E. Data-driven Bayes approach on marine accidents occurring in Istanbul strait. Appl. Ocean. Res. 2022, 123, 103180. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. Computing Research Repository. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the EMNLP 2015, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Chen, T.; Shi, H.; Liu, L.; Tang, S.; Shao, J.; Chen, Z.; Zhuang, Y. Empower distantly supervised relation extraction with collaborative adversarial training. In Proceedings of the AAAI Conference on Artificial Intelligence 2021, Virtual, 2–9 February 2021; pp. 12675–12682. [Google Scholar]
- Christopoulou, F.; Miwa, M.; Ananiadou, S. Distantly supervised relation extraction with sentence reconstruction and knowledge base priors. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 11–26. [Google Scholar]
- Hao, K.; Yu, B.; Hu, W. Knowing false negatives: An adversarial training method for distantly supervised relation extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9661–9672. [Google Scholar]
- Chen, T.; Shi, H.; Tang, S.; Chen, Z.; Wu, F.; Zhuang, Y. CIL: Contrastive instance learning framework for distantly supervised relation extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual, 1–6 August 2021; pp. 6191–6200. [Google Scholar]
- Rathore, V.; Badola, K.; Singla, P.; Mausam. PARE: A simple and strong baseline for monolingual and multilingual distantly supervised relation extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 340–354. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relation | Subject(s) | Object(s) |
|---|---|---|
| pem: Aggressor-Location | Aggressor | Location |
| pem: Aggressor-Date | Aggressor | Date |
| pem: Victim-Location | Victim | Location |
| pem: Victim-Date | Victim | Date |
| pem: Attacking | Aggressor | Victim |
| pem: Boarding | Aggressor | Victim |
| pem: Firing upon | Aggressor | Victim |
| pem: Kidnapping | Aggressor | Victim |
| pem: Hijacking | Aggressor | Victim |
| pem: Robbing | Aggressor | Victim |
| pem: Suspiciously approaching | Aggressor | Victim |
| Serial Number | Label |
|---|---|
| 1 | B-Aggressor |
| 2 | I-Aggressor |
| 3 | B-Victim |
| 4 | I-Victim |
| 5 | B-Location |
| 6 | I-Location |
| 7 | B-Data |
| 8 | I-Data |
| 9 | O |
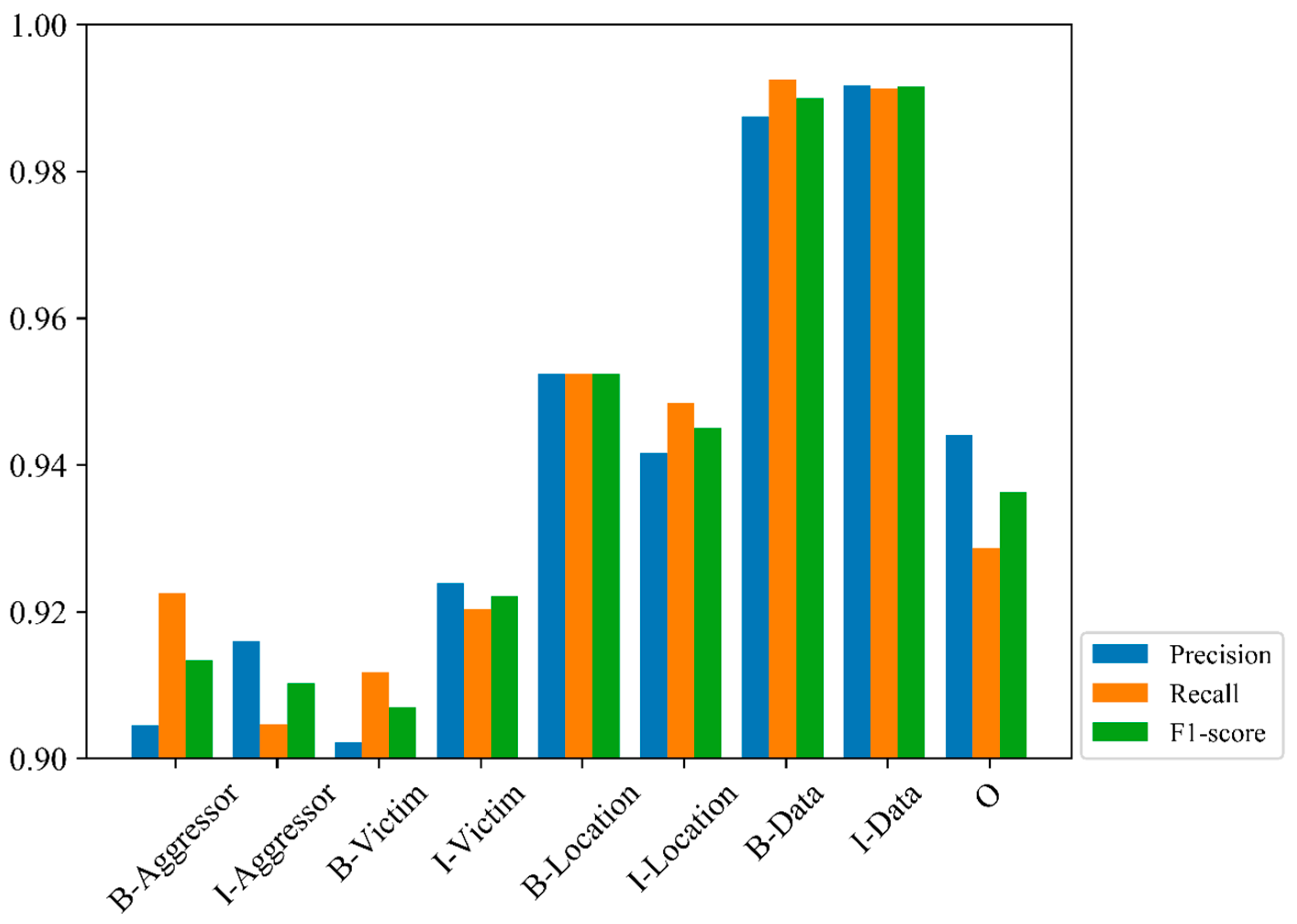
| Serial Number | Label | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | B-Aggressor | 0.9045 | 0.9225 | 0.9134 |
| 2 | I-Aggressor | 0.9160 | 0.9047 | 0.9103 |
| 3 | B-Victim | 0.9022 | 0.9118 | 0.9070 |
| 4 | I-Victim | 0.9239 | 0.9203 | 0.9221 |
| 5 | B-Location | 0.9524 | 0.9524 | 0.9524 |
| 6 | I-Location | 0.9416 | 0.9484 | 0.9450 |
| 7 | B-Data | 0.9875 | 0.9925 | 0.9900 |
| 8 | I-Data | 0.9917 | 0.9913 | 0.9915 |
| 9 | O | 0.9441 | 0.9287 | 0.9363 |
| 10 | Overall | 0.9404 | 0.9414 | 0.9409 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| HMM model | 0.8116 | 0.7961 | 0.8037 |
| CRF model | 0.8436 | 0.8313 | 0.8374 |
| BiLSTM model | 0.8671 | 0.8784 | 0.8664 |
| BiLSTM-CRF model | 0.9029 | 0.8979 | 0.9004 |
| BERT-BiLSTM-CRF model | 0.9404 | 0.9414 | 0.9409 |
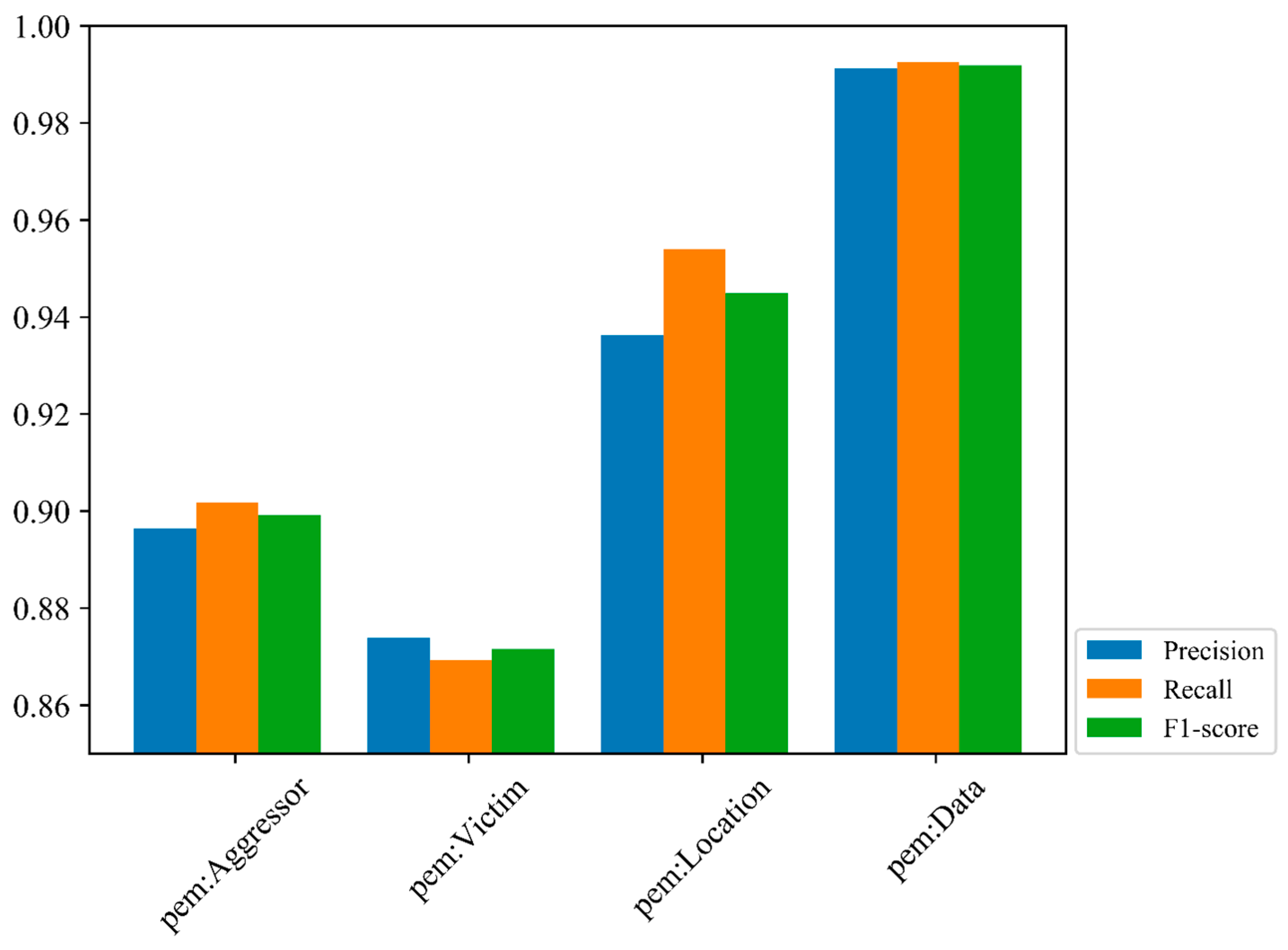
| Entity Types | Precision | Recall | F1-Score |
|---|---|---|---|
| pem: Aggressor | 0.8965 | 0.9017 | 0.8991 |
| pem: Victim | 0.8739 | 0.8693 | 0.8716 |
| pem: Location | 0.9362 | 0.9540 | 0.9450 |
| pem: Data | 0.9912 | 0.9925 | 0.9919 |
| Average | 0.9220 | 0.9244 | 0.9269 |
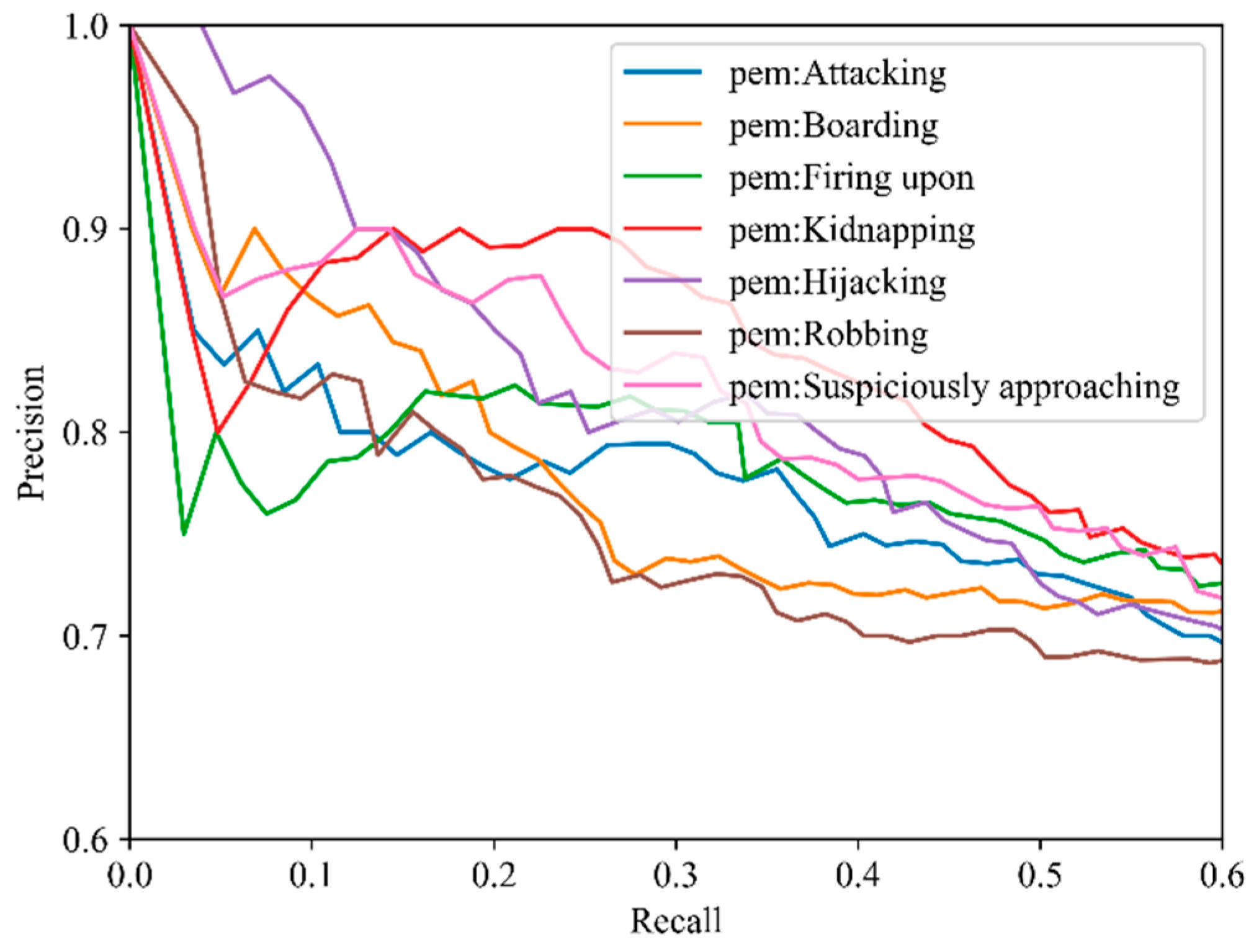
| Relation Types | AUC |
|---|---|
| pem: Attacking | 0.733 |
| pem: Boarding | 0.719 |
| pem: Firing upon | 0.722 |
| pem: Kidnapping | 0.754 |
| pem: Hijacking | 0.744 |
| pem: Robbing | 0.707 |
| pem: Suspiciously approaching | 0.746 |
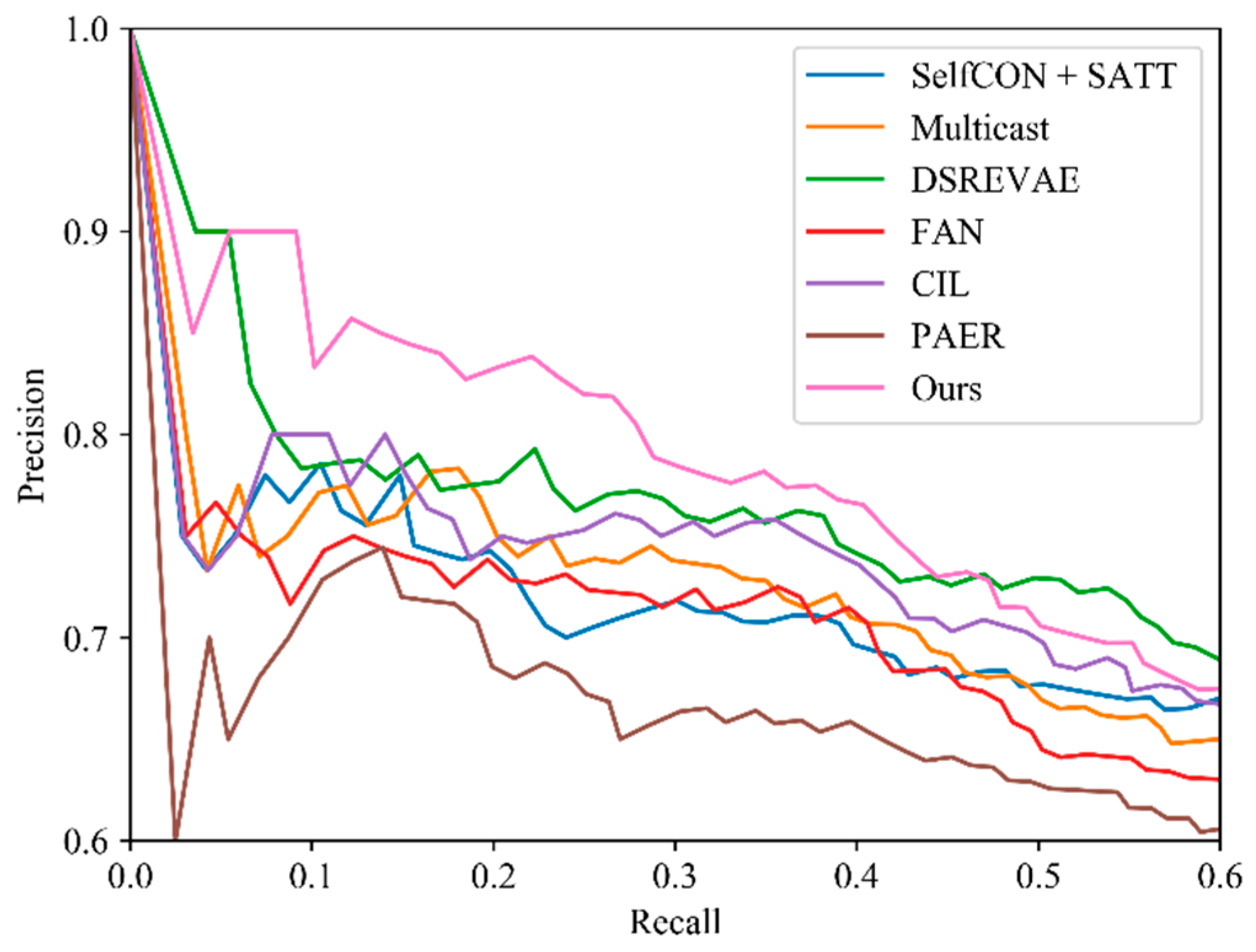
| Model | AUC |
|---|---|
| SelfCON + SATT | 0.672 |
| Multicast | 0.681 |
| DSREVAE | 0.707 |
| FAN | 0.656 |
| CIL | 0.688 |
| PARE | 0.625 |
| Ours | 0.723 |
| Subject | Object | Relation |
|---|---|---|
| Somali sailors | cargo ship OYA | pem: boarding |
| Somali sailors | five crewmen | pem: kidnapping |
| Somali sailors | 30 July 2019 | pem: Aggressor-Date |
| Somali sailors | 04: 10N-006: 59E | pem: Aggressor-Location |
| cargo ship OYA | 30 July 2019 | pem: Victim-Date |
| cargo ship OYA | 04: 10N-006: 59E | pem: Victim-Location |
| five crewmen | 30 July 2019 | pem: Victim-Date |
| five crewmen | 04: 10N-006: 59E | pem: Victim-Location |
| Somali sailors | container ship M/V MANDY | pem: attacking |
| Somali sailors | six crewmen | pem: kidnapping |
| Somali sailors | 2 January 2019 | pem: Aggressor-Date |
| Somali sailors | 05: 28N-002:21E | pem: Aggressor-Location |
| container ship M/V MANDY | 2 January 0219 | pem: Victim-Date |
| container ship M/V MANDY | 05: 28N-002:21E | pem: Victim-Location |
| six crewmen | 2 January 2019 | pem: Victim-Date |
| six crewmen | 05: 28N-002:21E | pem: Victim-Location |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, C.; Zhong, Z.; Zhang, L. Automated Construction Method of Knowledge Graphs for Pirate Events. Appl. Sci. 2024, 14, 6482. https://doi.org/10.3390/app14156482
Xie C, Zhong Z, Zhang L. Automated Construction Method of Knowledge Graphs for Pirate Events. Applied Sciences. 2024; 14(15):6482. https://doi.org/10.3390/app14156482
Chicago/Turabian StyleXie, Cunxiang, Zhaogen Zhong, and Limin Zhang. 2024. "Automated Construction Method of Knowledge Graphs for Pirate Events" Applied Sciences 14, no. 15: 6482. https://doi.org/10.3390/app14156482
APA StyleXie, C., Zhong, Z., & Zhang, L. (2024). Automated Construction Method of Knowledge Graphs for Pirate Events. Applied Sciences, 14(15), 6482. https://doi.org/10.3390/app14156482