
Yolo Based Defects Detection Algorithm for EL in PV Modules with Focal and Efficient IoU Loss
Abstract
:1. Introduction
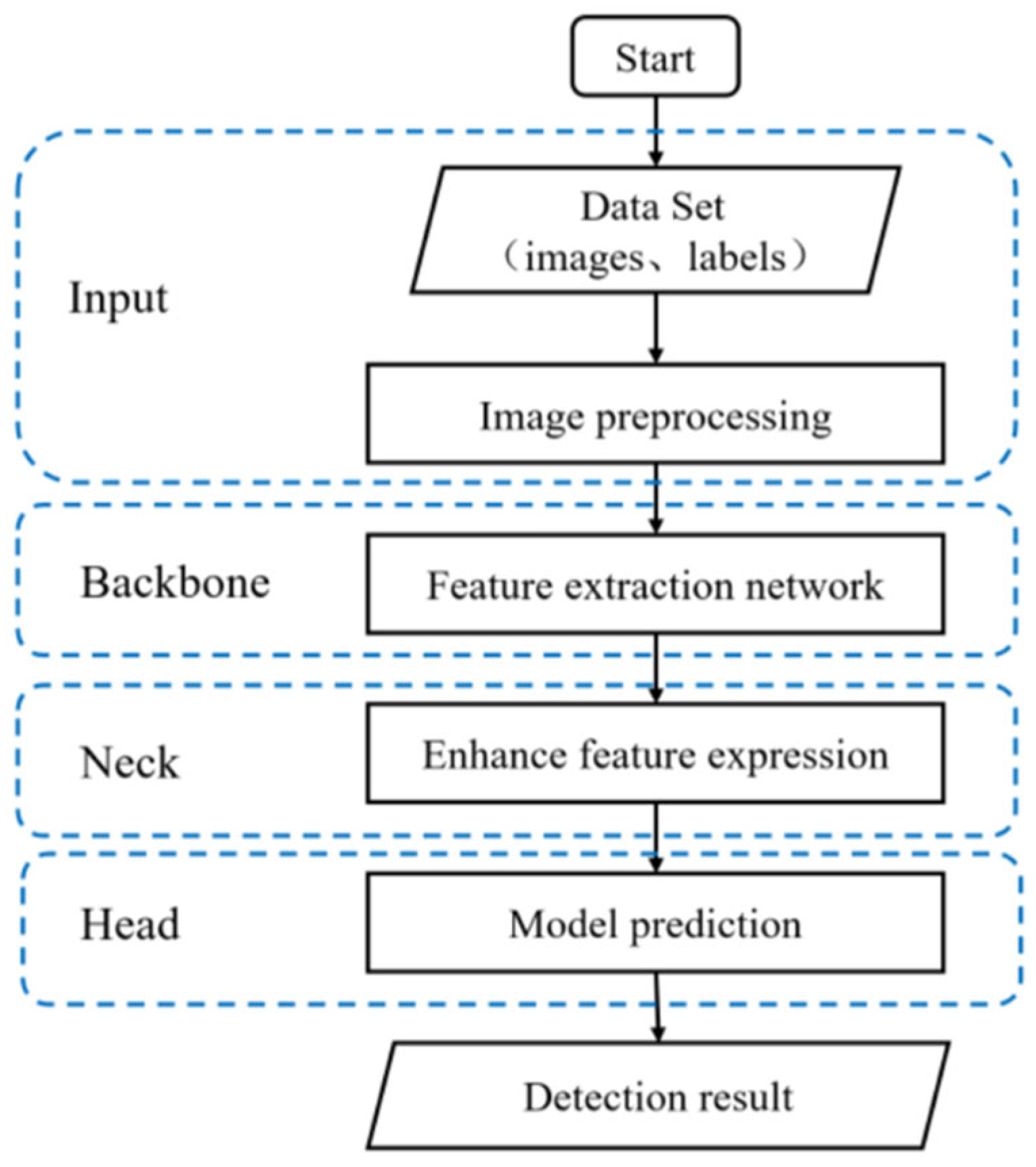
2. Materials and Methods
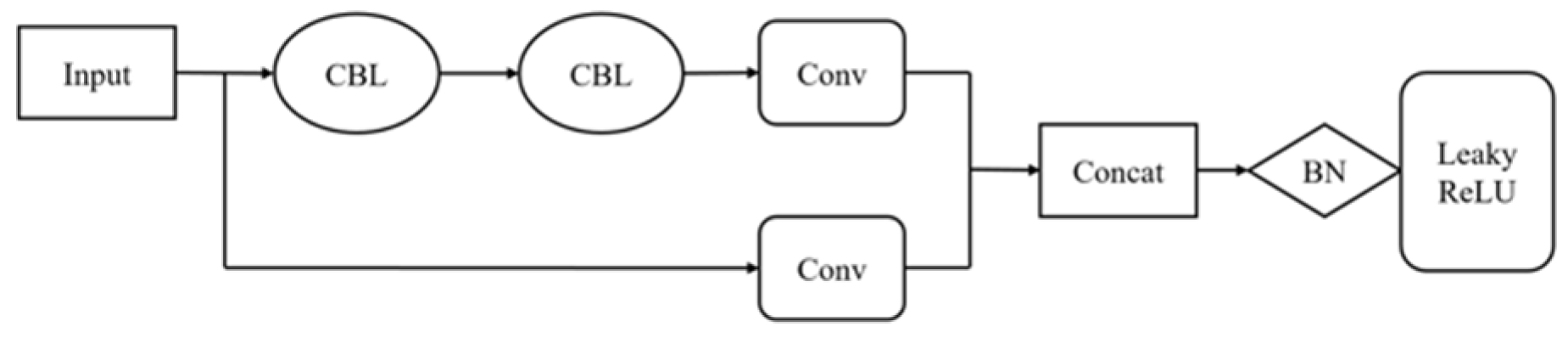
2.1. YOLOv5
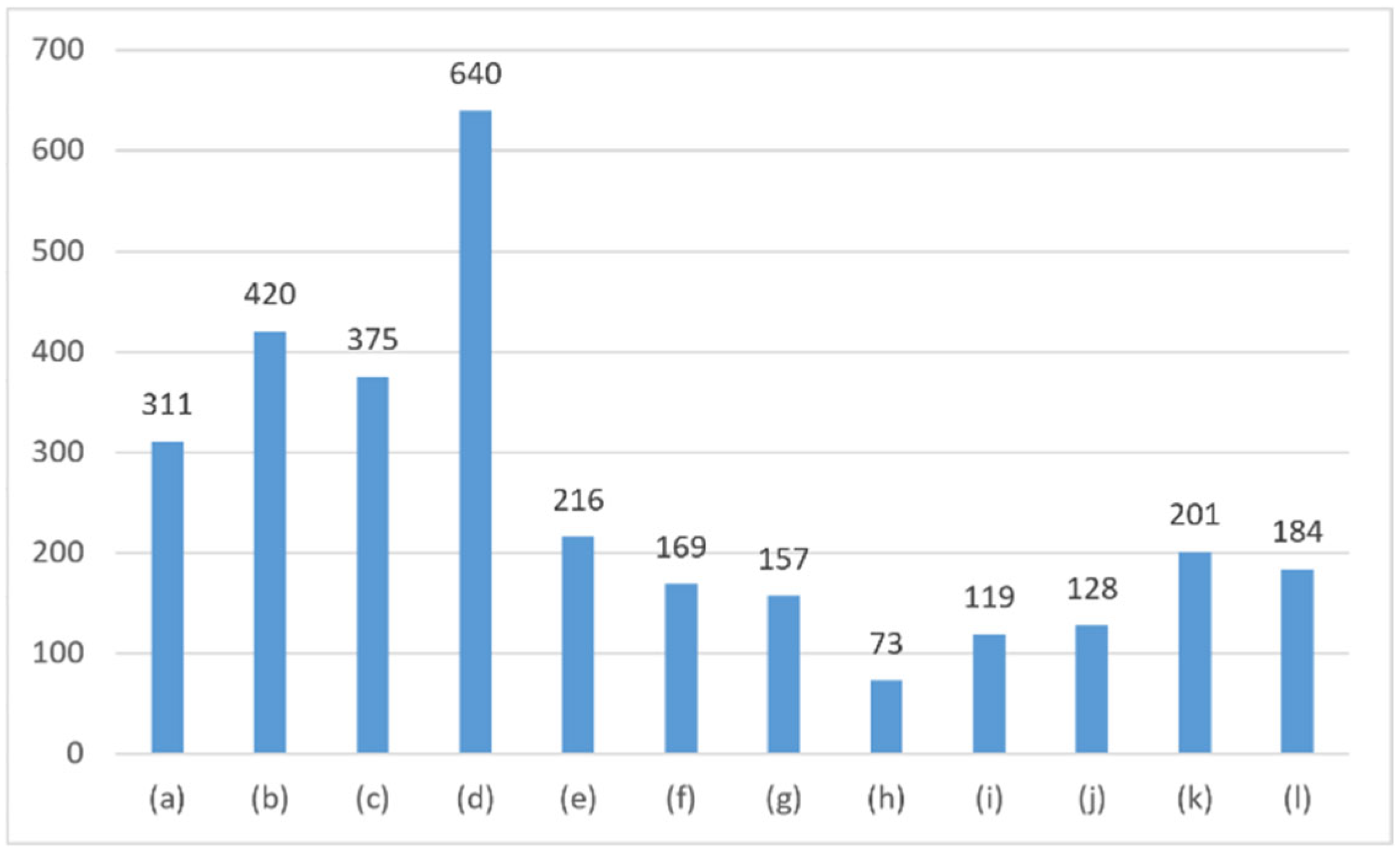
2.2. EL Images
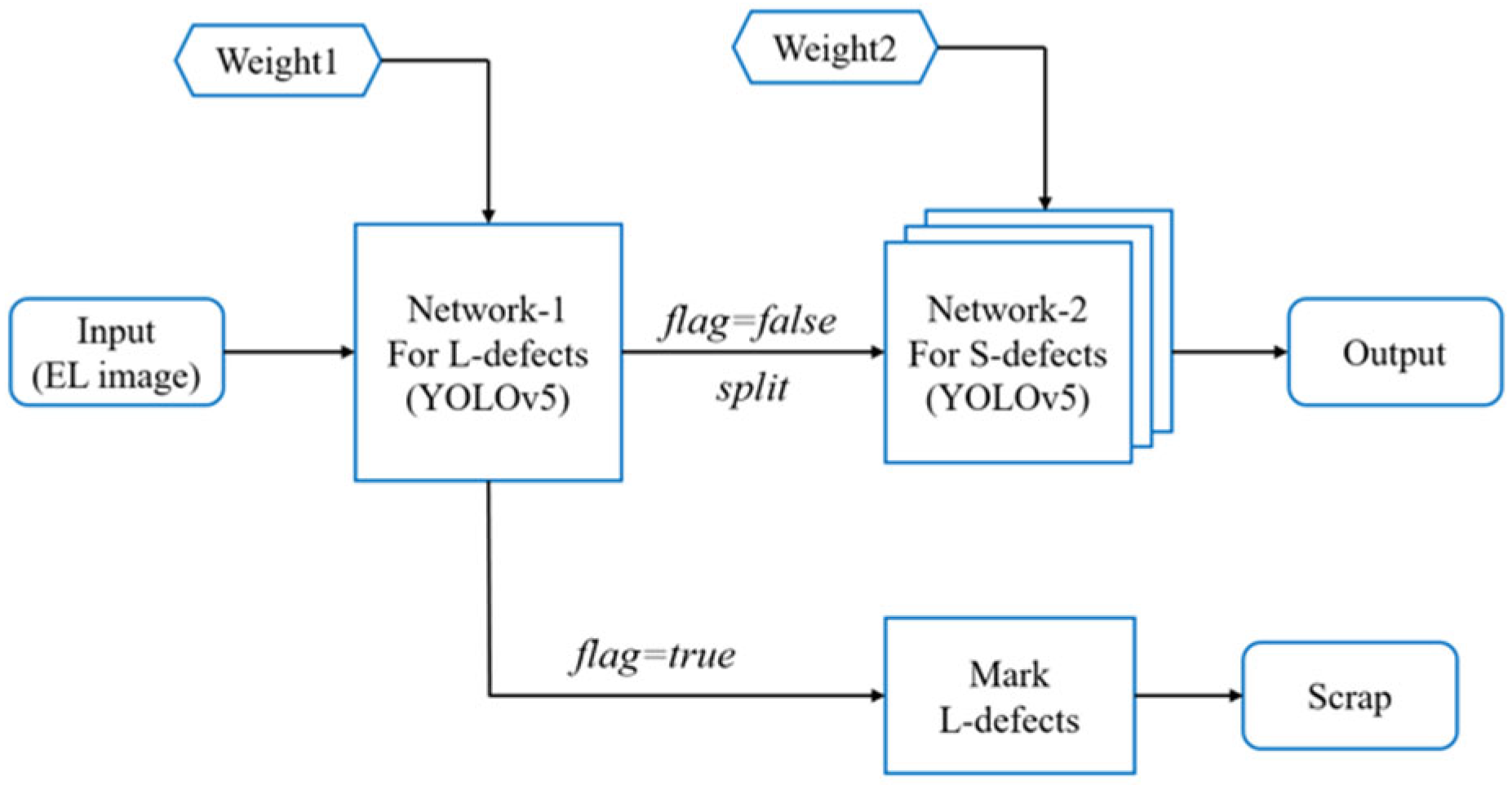
2.3. Cascaded Detection Network
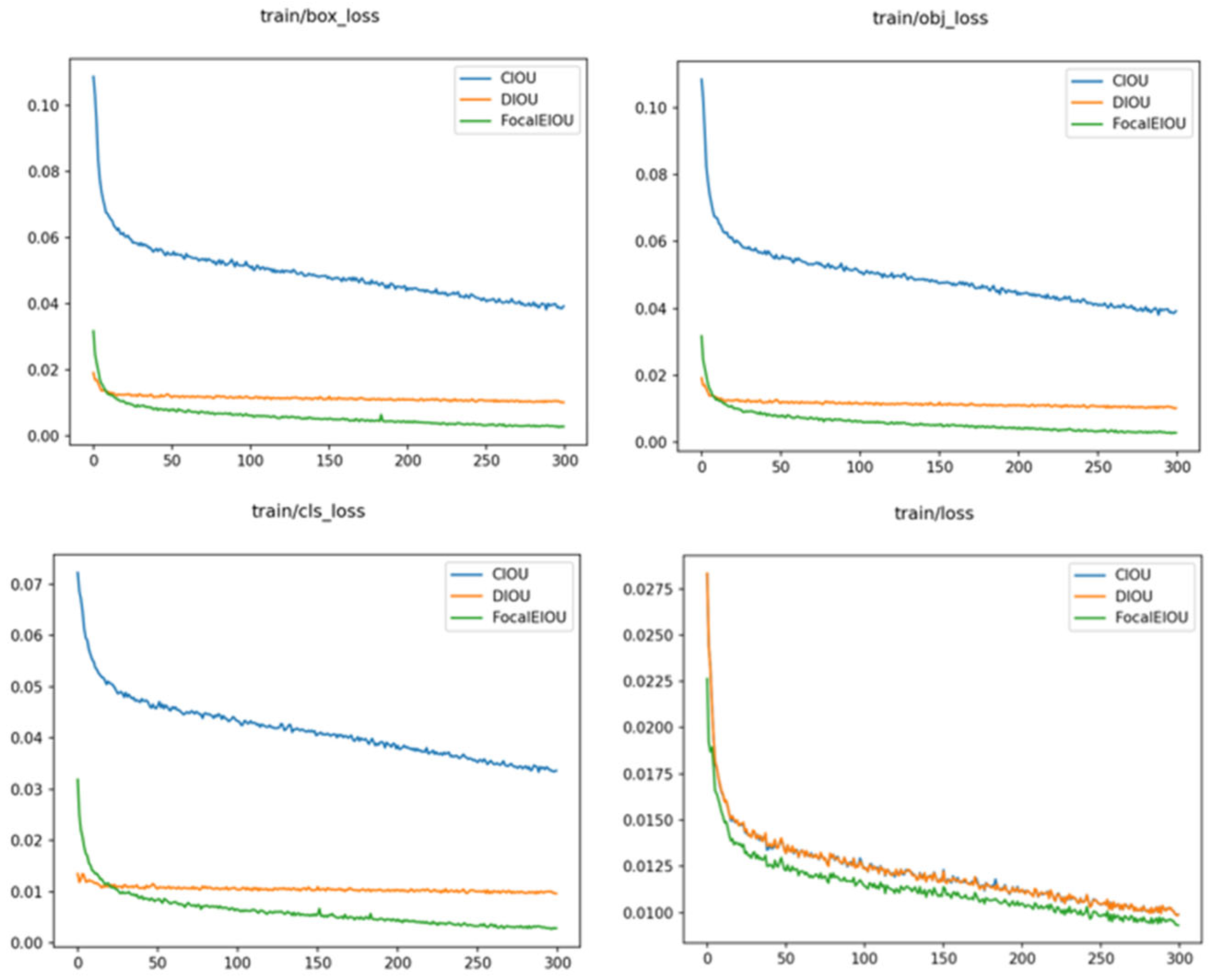
2.4. Focal-EIoU Loss
- Center Point Distance Loss: This component aims to minimize the distance between the center points of the predicted bounding box and the ground truth bounding box. By doing so, it improves the accuracy of localizing the object within the bounding box;
- Consideration of Size Differences: EIoU penalizes discrepancies in width and height between the predicted bounding box and the ground truth bounding box. This penalty mechanism ensures that the predicted bounding box closely aligns with the shape and size of the actual object, thereby refining the detection accuracy;
- Incorporation of Minimum Enclosing Box Size: By integrating the size of the minimum enclosing box that encompasses both the predicted and ground truth bounding boxes into the loss function, EIoU becomes more attuned to the object’s size and position. This inclusion enhances the sensitivity of the loss function to variations in object size and spatial orientation, contributing to more precise object localization.
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, X.; Tang, W.; Bi, J.; Chen, S.; Yan, W. CNN-based model for cell extraction from PV modules with EL images for PV defects detection. In Proceedings of the Chinese Control Conference, Shanghai, China, 26–28 July 2021; pp. 221–225. [Google Scholar]
- Dou, Z. Research of Online Defects Detection for Solar Panel Base on the EL Image. Master’s Thesis, Zhejiang Sci-Tech University, Hangzhou, China, 2013. [Google Scholar]
- Wang, Z. Research on Defect Detection System for Solar Cells. Master’s Thesis, Hebei University of Technology, Tianjin, China, 2014. [Google Scholar]
- Wang, X.; Li, J.; Yao, M.; He, W.; Qian, Y. Solar cells surface defects detection based on deep learning. Pattern Recognit. Artif. Intell. 2014, 27, 517–523. [Google Scholar]
- Yu, Y.; Yin, G.; Yin, Y.; Du, L. Defect recognition for radiographic image based on deep learning network. Chin. J. Sci. Instrum. 2014, 35, 2012–2019. [Google Scholar]
- Chen, T.; Ding, S.; Chen, H.; Chen, C. High accuracy detection strategy for EL defects in PV modules based on machine learning. In Proceedings of the Asia-Pacific Conference on Intelligent Robot Systems, Tianjin, China, 1–3 July 2022; pp. 128–134. [Google Scholar]
- Yang, J.; Guo, J. Image texture feature extraction method based on regional average binary gray level difference co-occurrence matrix. In Proceedings of the International Conference on Virtual Reality and Visualization, IEEE Computer Society, Beijing, China, 4–5 November 2011; pp. 239–242. [Google Scholar]
- Ko, J.; Rheem, J. Defect detection of polycrystalline solar wafers using local binary mean. Int. J. Adv. Manuf. Technol. 2016, 82, 1753–1764. [Google Scholar] [CrossRef]
- Zou, Y.; Du, D.; Chang, B.; Ji, L.; Pan, J. Automatic weld defect detection method based on Kalman filtering for real-time radiographic inspection of spiral pipe. Ndt E Int. 2015, 72, 1–9. [Google Scholar] [CrossRef]
- Niu, Q.; Ye, M.; Lu, Y. Defect detection of small hole inner surface based on multi-focus image fusion. J. Comput. Appl. 2016, 36, 2912–2915. [Google Scholar]
- Frome, A.; Singer, Y.; Sha, F.; Malik, J. Learning globally-consistent local distance functions for shape-based image retrieval and classification. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Zhou, A.; Shao, W.; Guo, J. An image mosaic method for defect inspection of steel rotary parts. J. Nondestruct. Eval. 2016, 35, 60. [Google Scholar] [CrossRef]
- Han, J. Research on Classification and Detection of Solar Cells EL Defects under Class Imbalance Situation. Master’s Thesis, Hebei University of Technology, Tianjin, China, 2020. [Google Scholar]
- Bartler, A.; Mauch, L.; Yang, B.; Reuter, M.; Stoicescu, L. Automated detection of solar cell defects with deep learning. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; IEEE Press: New York, NY, USA, 2018; pp. 2035–2039. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, B.; Huang, X.; Yang, Q. Research on detection technology of photovoltaic cells based on GoogLeNet and EL. Electron. Prod. Reliab. Environ. Test. 2019, 1, 150–155. [Google Scholar]
- Deitsch, S.; Christlein, V.; Berger, S.; Buerhop-Lutz, C.; Maier, A.; Gallwitz, F.; Riess, C. Automatic classification of defective photovoltaic module cells in electroluminescence images. Sol. Energy 2019, 185, 455–468. [Google Scholar] [CrossRef]
- Kaur, A.; Kukreja, V.; Kumar, M.; Choudhary, A.; Sharma, R. A Fine-tuned Deep Learning-based VGG16 Model for Cotton Leaf Disease Classification. In Proceedings of the 2024 5th International Conference for Emerging Technology (INCET), Belgaum, India, 24–26 May 2024; pp. 1–4. [Google Scholar]
- Tang, W.Q.; Yang, Q.; Xiong, K. Deep learning -based automatic defect identification of the photovoltaic module using electroluminescence images. Sol. Energy 2020, 201, 453–460. [Google Scholar] [CrossRef]
- Su, B.; Chen, H.; Zhou, Z. BAF-detector: An efficient CNN-based detector for photovoltaic cell defect detection. IEEE Trans. Ind. Electron. 2022, 69, 3161–3171. [Google Scholar] [CrossRef]
- Dong, M. Research on Yarn-dyed Fabric Defect Detection and Classification based on Convolutional Neural Network. Master’s Thesis, Xi’an Polytechnic University, Xi’an, China, 2018. [Google Scholar]
- Hu, J.; Wang, X.; Liu, H. Defect detection of continuous casting slabs based on deep learning. J. Shanghai Univ. (Nat. Sci. Ed.) 2019, 25, 445–452. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards teal-Time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Ma, S.; Guo, D.; Wang, P.; Lin, M.; Hu, Y. A small object detection method for oil leakage defects in substations based on improved faster-RCNN. Sensors 2023, 23, 7390. [Google Scholar] [CrossRef] [PubMed]
- Gu, C.; Zhe, L.; Shi, J. Detection for pin defects of overhead lines by UAV patrol image based on improved Faster-RCNN. High Volt. Eng. 2020, 46, 3089–3096. [Google Scholar]
- Tang, Y.; Han, J.; Wei, W. Research on part recognition and detection of transmission line in deep learning. Electron. Meas. Technol. 2018, 60–65. [Google Scholar]
- Dai, X.; Chen, H.; Zhu, C. Surface defect detection and realization of mental workpiece based on improved Faster-RCNN. Surf. Technol. 2020, 362–371. [Google Scholar]
- Guo, M.; Xu, H. Hot spot defect detection based on infrared thermal image and faster-RCNN. Comput. Syst. Appl. 2019, 265–270. [Google Scholar]
- Zhu, C.; Yang, Y. Online detection algorithm of automobile wheel surface defects based on improved Faster-RCNN model. Surf. Technol. 2020, 358–365. [Google Scholar]
- Guo, T.; Yang, H.; Shi, L. Self-explosion defect identification of insulator based on faster RCNN. Insul. Surge Arresters 2019, 183–189. [Google Scholar]
- Xu, X. Solar Cell Defect Detection Based on Deep Learning. Master’s Thesis, North University of China, Taiyuan, China, 2019. [Google Scholar]
- Tian, X.; Cheng, Y.; Chan, G. Detect and recognize hidden cracks in silicon chips on deep learning SSD algorithm. Mach. Tool Hydraul. 2019, 36–41. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2999. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Mark-Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1544–1552. [Google Scholar]
- Alahmadi, A.; Rezk, H. A robust single-sensor MPPT strategy for a shaded photovoltaic-battery system. Comput. Syst. Sci. Eng. 2021, 37, 63–71. [Google Scholar] [CrossRef]
- Hong, F.; Song, J.; Meng, H.; Wang, R.; Fang, F.; Zhang, G. A novel framework for intelligent detection for module defects of PV plant combining the visible and infra-red images. Sol. Energy 2022, 236, 406–416. [Google Scholar] [CrossRef]
- Jin, R.; Niu, Q. Automatic fabric defect detection based on an improved YOLOv5. Math. Probl. Eng. 2021, 2021, 7321394. [Google Scholar] [CrossRef]
- Zhu, X. Design of barcode recognition system based on YOLOV5. In Proceedings of the 2021 3rd International Conference on Computer Modeling, Changsha, China, 23–25 July 2021; pp. 346–349. [Google Scholar]
- Jin, S.; Sun, L. Application of enhanced feature fusion applied to YOLOv5 for ship detection. In Proceedings of the 33rd Chinese Control and Decision Conference, Kunming, China, 22–24 May 2021; pp. 8–11. [Google Scholar]
- Dubey, S.; Singh, S.; Chaudhuri, B. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- Wang, S.; Qu, Z.; Gao, L. Multi-spatial pyramid feature and optimizing focal loss function for object detection. IEEE Trans. Intell. Veh. 2024, 9, 1054–1065. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, Y.; Cheng, J. An improved YOLOv7 method for vehicle detection in traffic scenes. In Proceedings of the 2023 35th Chinese Control and Decision Conference (CCDC), Yichang, China, 20–22 May 2023; pp. 766–771. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Configuration |
|---|---|
| CPU | Intel(R) Core(TM) i7-10700 CPU @ 2.90 GHz 2.90 GHz |
| GPU | NVIDIA GeForce GTX 3060 |
| System | Windows 10 |
| Language | Python 3.8 |
| Architecture | Pytorch |
| Loss | P | R | F1 | mAP |
|---|---|---|---|---|
| DIoU | 0.724 | 0.826 | 0.858 | 0.819 |
| CIoU | 0.758 | 0.844 | 0.857 | 0.847 |
| Focal-EIoU | 0.792 | 0.850 | 0.933 | 0.865 |
| Defects | DIoU | CIoU | Focal-EIoU |
|---|---|---|---|
| (a) SE offset | 0.714 | 0.721 | 0.837 |
| (b) Dark spots | 0.728 | 0.758 | 0.850 |
| (c) Black spots | 0.745 | 0.824 | 0.830 |
| (d) Broken girds | 0.822 | 0.765 | 0.866 |
| (e) False marks | 0.798 | 0.847 | 0.843 |
| (f) Linear recessive cracks | 0.743 | 0.775 | 0.827 |
| (g) Branch recessive cracks | 0.703 | 0.752 | 0.858 |
| (h) Fragment | 0.850 | 0.853 | 0.876 |
| (i) Flurry filaments | 0.761 | 0.810 | 0.855 |
| (j) Cleaning traces | 0.755 | 0.768 | 0.823 |
| (k) Current unevenness | 0.812 | 0.841 | 0.906 |
| (l) Black cell | 0.884 | 0.905 | 0.958 |
| Algorithms | mAP | Speed |
|---|---|---|
| SVM [22] | 0.648 | 500 ms |
| Faster RCNN [24] | 0.837 | 50 ms |
| SSD | 0.750 | 90 ms |
| YOLOv3 [36] | 0.671 | 70 ms |
| YOLOv4 [37] | 0.734 | 30 ms |
| YOLOv5s [40] | 0.793 | 20 ms |
| YOLOv6s [46] | 0.782 | 60 ms |
| YOLOv7s [47] | 0.811 | 80 ms |
| Proposed | 0.865 | 20 ms |
| Method | mAP | Speed |
|---|---|---|
| YOLOv5m | 0.791 | 23.8 ms |
| YOLOv5m * | 0.857 | 23.8 ms |
| YOLOv5l | 0.798 | 32.6 ms |
| YOLOv5l * | 0.862 | 32.6 ms |
| YOLOv5x | 0.802 | 46.8 ms |
| YOLOv5x * | 0.867 | 46.8 ms |
| YOLOv5s | 0.793 | 20.0 ms |
| YOLOv5s * | 0.865 | 20.0 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, S.; Jing, W.; Chen, H.; Chen, C. Yolo Based Defects Detection Algorithm for EL in PV Modules with Focal and Efficient IoU Loss. Appl. Sci. 2024, 14, 7493. https://doi.org/10.3390/app14177493
Ding S, Jing W, Chen H, Chen C. Yolo Based Defects Detection Algorithm for EL in PV Modules with Focal and Efficient IoU Loss. Applied Sciences. 2024; 14(17):7493. https://doi.org/10.3390/app14177493
Chicago/Turabian StyleDing, Shen, Wanting Jing, Hao Chen, and Congyan Chen. 2024. "Yolo Based Defects Detection Algorithm for EL in PV Modules with Focal and Efficient IoU Loss" Applied Sciences 14, no. 17: 7493. https://doi.org/10.3390/app14177493