Abstract
With the rapid development of the Internet of Things (IoT) technology, the number and types of devices accessing the Internet are increasing, leading to increased network security problems such as hacker attacks and botnets. Usually, these attacks are related to the type of device, and the risk can be effectively reduced if the type of network device can be efficiently identified and controlled. The traditional network device identification method uses active detection technology to obtain information about the device and match it with a manually defined fingerprint database to achieve network device identification. This method impacts the smoothness of the network and requires the manual establishment of fingerprint libraries, which imposes a large labor cost but only achieves a low identification efficiency. The traditional machine learning method only considers the information of individual packets; it does not consider the timing relationship between packets, and the recognition effect is poor. Based on the above research, in this paper, we considered the packet temporal relationship, proposed the TCN model of the Inception structure, extracted the packet temporal relationship, and designed a multi-head self-attention mechanism to fuse the features to generate device fingerprints for device identification. Experiments were conducted on the publicly available UNSW dataset, and the results showed that this method achieved notable improvements compared to the traditional machine learning method, with F1 reaching 96.76%.
1. Introduction
With the rapid development of the Internet of Things (IoT) technology, the number of connected devices has grown significantly worldwide. These devices cover a wide range of fields, such as smart home devices, industrial devices, medical devices, and so on, and have greatly improved people’s quality of life and the efficiency of their work. According to relevant statistics [1], the number of connected devices worldwide reached 20.35 billion units in 2017, and this number is expected to increase to 75.44 billion units by 2025. With the continuous progress of digital technology, many devices are becoming more intelligent, with correspondingly more stringent requirements on their size and functions. Many devices have defects in their design and configuration which makes them difficult to upgrade and effectively manage. Their lack of security measures also makes them a weak link in network security, and they can be prone to hacking attacks.
Attacks are usually associated with specific types and versions of devices. Once an attacker discovers a vulnerability in a device type, they can launch an attack against that type of device. If the device type can be identified before the attack occurs, the impact range and threat level of the vulnerability can be assessed and the source of the attack can be cut off. This effectively avoids the security risk, safeguarding network security [2]. Therefore, network device identification technology is a key technology to solve security problems, and has important research significance.
Most traditional network device recognition techniques rely on manually constructing fingerprint libraries to extract device fingerprints from network data. Then, based on matching algorithms, such as regular expressions, the extracted features are matched with the rules in the fingerprint libraries, allowing recognition of network devices. These fingerprint libraries are usually constructed by relying on the a priori knowledge of experts, which can introduce errors and make them complicated to update, affecting the accuracy of device identification. With the rise of artificial intelligence, researchers are increasingly using machine learning techniques for network device identification by extracting features from network data and using a large amount of data to train models. Compared with traditional device identification methods, machine learning can identify various devices in the network more efficiently.
Machine learning is usually used to extract features from raw traffic data from communication between devices, which acts as a fingerprint of the device. The fingerprint of the device is then used as input into the machine learning algorithm for network device identification. A fingerprint is a set of features extracted from network data packets to reflect the behavioral patterns of a device. The earliest use of the fingerprinting method was IoT-Sentinel [3], which extracted 23 features from the first 12 packets of each device using network data captured by connected devices at Aalto University, but it was unable to recognize non-IP devices as it performed packet merging from the MAC address. Using traditional machine learning algorithms, 27 devices were finally classified, with an average recognition rate of 95%. IoT-Sense [4] used three payload-related features in addition to 17 protocol features, reflecting the behavior of the devices on top of IoT-Sentinel. On average, every five packets formed a session, and using traditional machine learning, the recall rate of every device reached 93–100%. Although comparisons were made with IoT-Sentinel, the number of devices evaluated was only 10. The IoTDevID [5] method extracted more comprehensive features from the packets, such as more detailed packet static features and multiple dynamic features. Feature selection was carried out using feature importance voting, genetic algorithms, etc. The performance of the traditional machine learning algorithms was compared, and a packet fusion algorithm was proposed. The recognition results were further modified by selecting the F1 score value as the main evaluation index, and the highest achieved recognition effect was 93%. However, this method does not consider the relationship between packets and is less effective at recognizing similar devices.
In addition to the basic features extracted from packets, researchers subsequently added network statistics. Hamad et al. [6] used a fingerprint consisting of 67 statistical features extracted from the headers of 20–21 consecutive packets of Ethernet, IP, UDP, and TCP, which were also classified using a traditional machine learning approach, achieving an accuracy of 90.3%. However, the network statistics change with different networks, and the applicability is poor. Sivanathan [7] monitored the network data generated by 28 devices during normal operation and extracted eight features from them. They used a two-stage classification algorithm, with the first step using the Naïve Bayes (NB) algorithm and the second step using the RF algorithm, and the final classification of 28 devices reached an accuracy of 99.88%. However, the features were too specific and did not focus on device behavior, which made them less applicable.
The development of deep learning has led to its wide application in various fields, and researchers have applied it to extract deeper features of packets, such as temporal and spatial features. Aneja et al. [8] used a packet sniffer to collect packets, focusing on the time interval between two consecutively received packets (Inter Arrival Time (IAT)). Due to differences in hardware and devices, the IAT is unique for each device, so each device’s IAT graph was plotted and the features were extracted using convolutional neural networks, which, in turn, enabled network device identification. DFP [9] operated by selecting two features based on the characteristics of the device (Window_size and IP_len), extracting the values of 100 consecutive packets, and generating the trajectory image to be used as a fingerprint. Using a convolutional neural network architecture, it was then possible to distinguish between known and unknown traffic, IoT devices and non-IoT devices, and individual devices, achieving 98% accuracy on two publicly available datasets. DPLS [10] involved a method for identifying IoT devices based on sequences of directed packet lengths in network traffic. This method first captured network traffic packets from a device by passively capturing them at a local network gateway, and the length and transmission direction (forward or reverse) of each packet were calculated. The length and direction information were then combined into vectors that were used as inputs for a deep convolutional neural network to identify the unknown device type or model. CBBI [11] involved using spatial and temporal features in the raw network traffic generated by IoT devices, avoiding the cumbersome and inefficient feature extraction of traditional methods and reducing the complexity of the IoT device identification task. The EIEI [12] method involved an end-to-end IoT device identification method (IoT ETEI), which automatically identified IoT devices connected to the network. Instead of extracting features manually, the method directly used the raw network traffic generated by the device and extracted spatial and temporal features through convolutional neural networks (CNNs) and Bi-Directional Long and Short-Term Memory Networks (BiLSTMs) to achieve device identification.
Based on the deep learning method, the network traffic data can be processed in a certain way. With the development of deep learning, the fingerprint features of the device can be better extracted and more effectively fused, and better results can be obtained, but this also relies on a large amount of data for training.
In this paper, based on the deep learning method, feature extraction was performed on the original packet using feature importance voting, genetic algorithms, etc. The Inception–TCN model was designed to extract the packet timing features, and feature fusion was performed using the multi-head self-attention mechanism to generate the feature vectors, which were then used as the device fingerprints for the identification of the network devices. The overall process is shown in Figure 1.

Figure 1.
The overall process framework of the methodology.
2. Data Analysis and Feature Engineering
2.1. Data Collection and Feature Extraction
The collection of data within this method mainly utilizes passive probing to collect network data from the network environment, usually by setting up a traffic collection device in the network environment to listen to the communication behavior of the device, and then labeling the raw traffic with the device type. To ensure the independence of the training data and test data, the data are usually divided into the training set and test set from the source.
Network devices use different protocols at different stages of their operation, such as ARP, SSL, LLC, HTTP, etc. The list of protocols used by a network device is a good static characterization of the device’s behavior, so we extracted protocol information such as the data link layer, network layer, transport layer, etc., from the packets. In addition, the dynamic characteristics of the net device are also important features for the identifiability of the device. Here, the dynamic characteristics focused on three indicators: payload entropy, TCP payload length, and TCP window size. The payload entropy indicates the content of the message. To calculate the Shannon entropy of a sequence of m-bytes with a symbol length of 8 bits or 1 byte, the following formula can be used:
where is the probability of the occurrence of byte value i in the m bytes, i.e., . Khakpour et al. [13] concluded that the entropy of the payload is small if the packet carries plaintext, and will be high if the packet carries audio data. The TCP payload length indicates the length of the message sent by the given device and is a device-specific characteristic. The TCP window size depends on the memory and processing speed of the device and was used by Alvin et al. [14] in a fingerprinting study of devices. Additionally, we extracted the source and destination ports and classified them, as shown in Table 1. Finally, we extracted 96 features from the network packets to characterize the communication behavior of the device.

Table 1.
Source and destination port classification.
2.2. Feature Selection
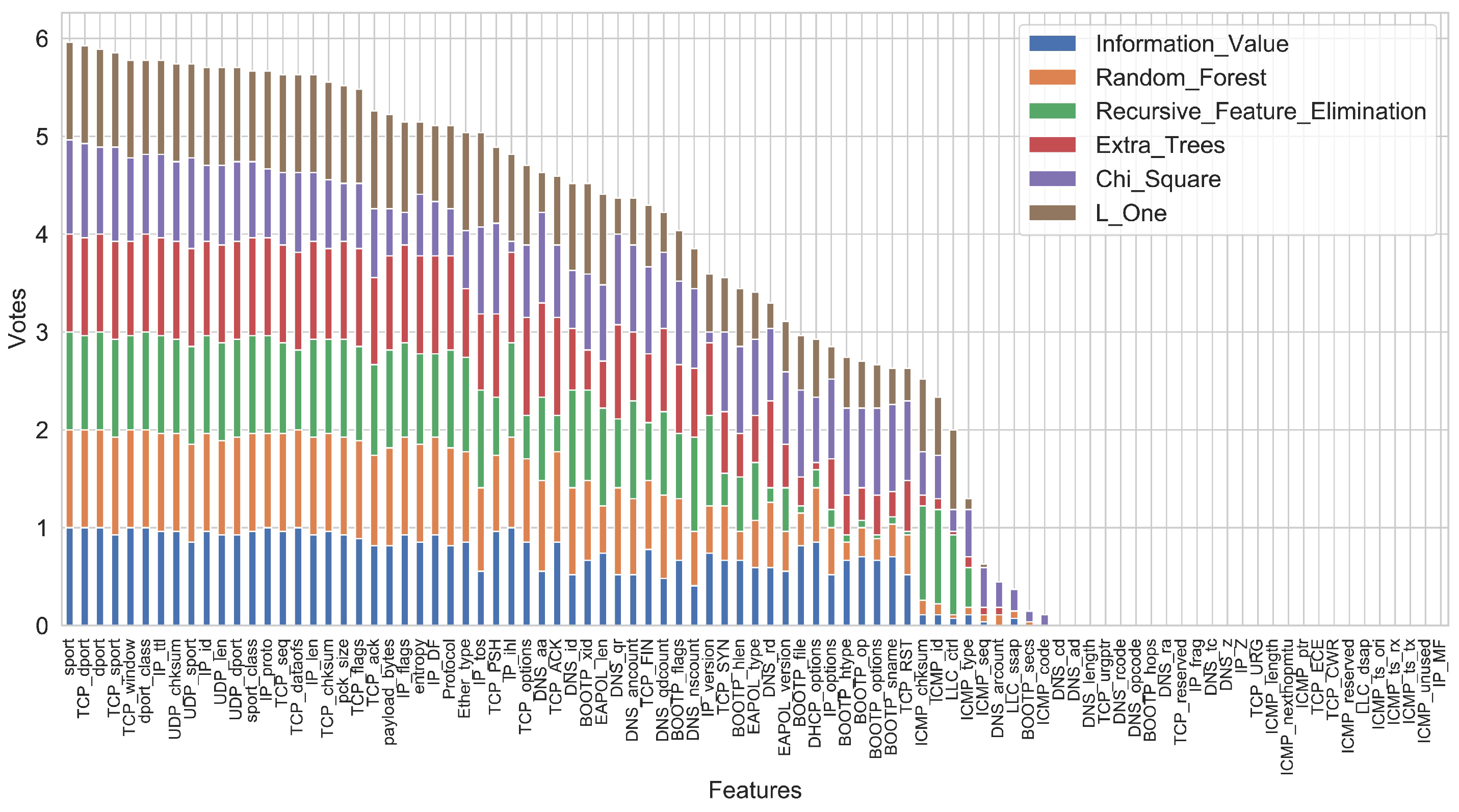
After extracting the initial features, to improve the efficiency of the model, we used the Xverse package to eliminate unnecessary features using a feature importance-based voting method. This method uses six different feature selection methods to calculate the importance scores of all features for each device and then uses voting to decide whether to keep the features in or not. The six scoring techniques used by this method are information value using the weight of evidence, variable importance using RF, recursive feature elimination, variable importance using extra trees classifier, Chi-square best variables, and L1-based feature selection. The result of the feature voting is shown in Figure 2. We removed the features that were voted as 0 by the six methods.
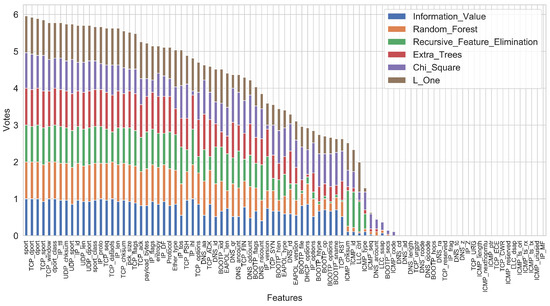
Figure 2.
The features and the average votes the UNSW dataset [7] received.
After removing the features with a vote of 0, we found that some of the remaining features contained information specific to a particular session, e.g., the initial values of the IP ID, TCP sequence, and acknowledgment numbers were randomly assigned, and the next values were consecutive numbers following this initial value. Therefore, these features were not valuable information for identification and we excluded them, eventually selecting 52 features.
Finally, after eliminating redundant features, we used a genetic algorithm to decide the most appropriate set of features from those remaining. Genetic algorithms are heuristic search algorithms, inspired by the theory of biological evolution, that optimize problems by modeling natural selection and genetic mechanisms. The algorithm represents potential solutions as chromosomes, each of which consists of a series of genes that make up an initial population, which then gradually evolve to produce better solutions through an iterative process. By iterating for 100 generations and selecting the optimal result, 27 features were chosen. Using this method, we created a subset of features with higher performance and reduced the complexity of the model by reducing the number of features. The results of each stage of feature selection are shown in Table 2.
Table 2.
Results of the stages of feature selection.
2.3. Modeling Multidimensional Time Series
In order to consider the temporal relationship between packets, we considered N consecutive packets as a time window, and any packet could be considered as a timestamp , where F is the dimension of each packet, and from above, F = 27, i.e., each packet had 27 features. Thus, the problem was transformed into a classification problem for multidimensional time series.
3. Inception-TCN-Attention Model Design
The analysis of multidimensional time series is more difficult than for one-dimensional time series data because of the need to consider the differences and connections between multiple variables and to extract the features of each variable, as well as to fuse multiple features effectively. For this reason, we proposed the Inception-TCN-Attention model to extract the complex time series features of data packets and use them as device fingerprints for device identification. Inception is a special structure in neural networks that was designed by Google’s DeepMind team [15] to improve the performance and efficiency of convolutional neural networks, allowing the network to learn features at different scales simultaneously. A temporal convolutional network (TCN) is a deep learning model specifically designed to process time series data. It mainly consists of convolutional layers that can effectively capture local and long-term dependencies in time series data. An attention mechanism is a technique that has been widely used in the field of deep learning in recent years, especially in the fields of natural language processing (NLP) [16], computer vision (CV) [17], and speech recognition (SR) [18], which enable models to be trained to focus more on features that are critical to the recognition task, thus improving the efficiency and accuracy of feature extraction.
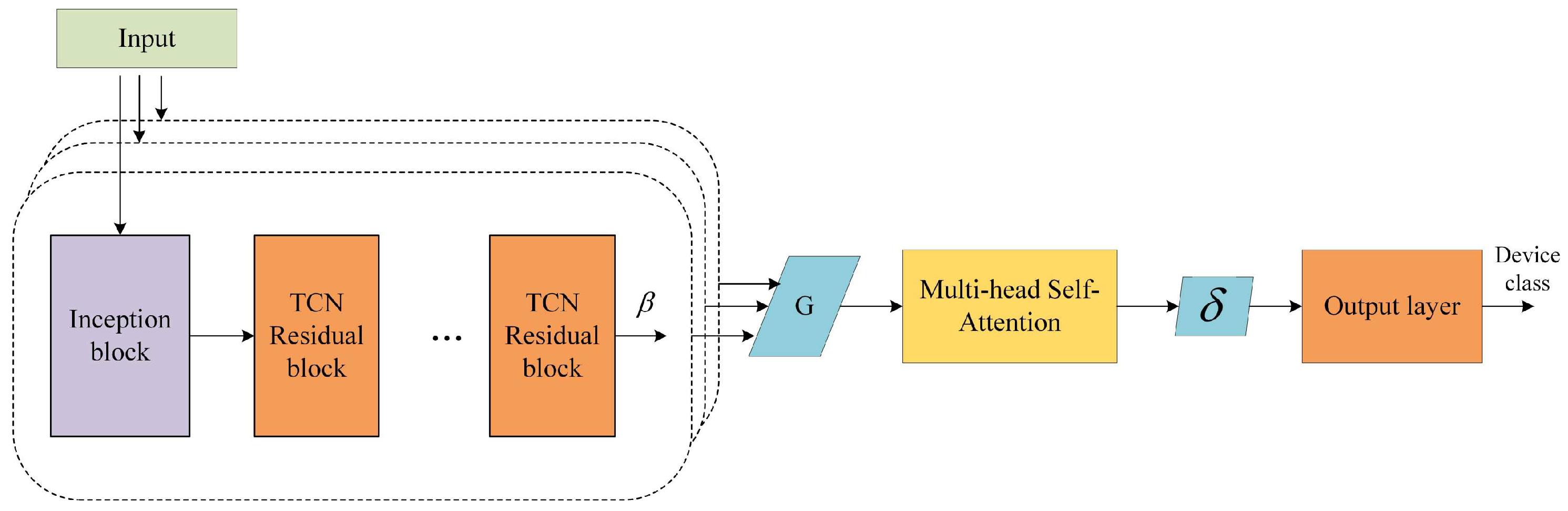
The model can be divided into two stages: the stage of extracting the temporal features of the packet based on the Inception structure of the TCN model, and the stage of fusing and classifying the features using the multi-attention mechanism. The overall framework of the model is shown in Figure 3.
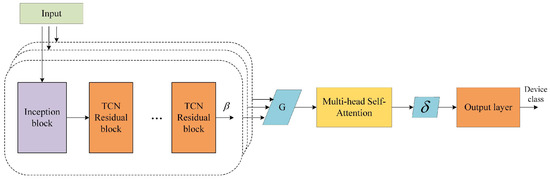
Figure 3.
The Inception-TCN-Attention model.
3.1. Packet Temporal Feature Extraction
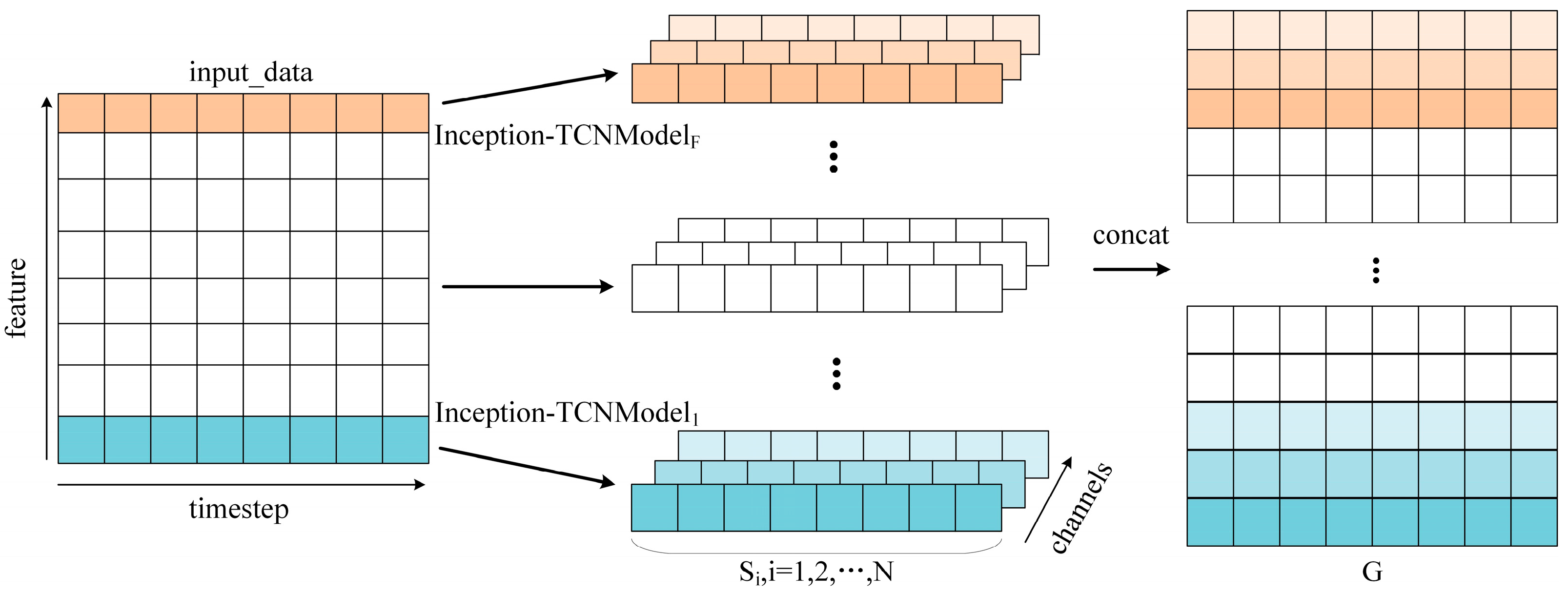
In the temporal feature extraction stage, the input data were a multidimensional time series, and we designed an independent Inception-TCN model for each variable. The features extracted by each sub-model were multi-channel, and the number of channels was correlated with the number of channels computed by the convolution of the TCN model. After obtaining the channel features, to ensure that the features of different abstraction levels were not lost, the algorithm extracted features from each channel, which were spliced to generate a new feature matrix. This not only retained the features of the original data but also increased the dimensionality and depth of the features, thus portraying the nature of the data more comprehensively. This new feature matrix was finally used as the output of the feature extraction stage. Figure 4 shows the process of the multidimensional packet temporal series data from the original input to the formation of the feature matrix.
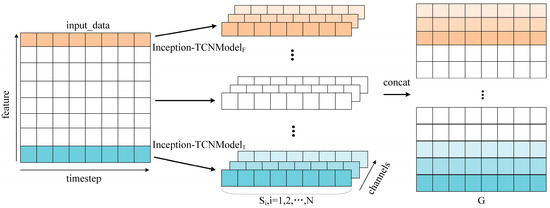
Figure 4.
The feature extraction process. Multidimensional packets from the raw input were used to generate feature matrices.
In Figure 4, the left matrix represents the input data. In this matrix, each row corresponded to a different feature of the packet; here, it was the 27-dimensional feature after feature engineering, where each column represented the time step of the packet. The timestep corresponded to the length of the sequence, and we took the length of the packet to be 100. The Inception-TCN model was the sub-model corresponding to each variable, whose main task was to extract the features from the respective variables. The output of each sub-model was multi-channel, i.e., the output features consisted of multiple sequences that did not exist independently but were related to each other. The features extracted from multiple sequences by each sub-model were spliced together to obtain the feature matrix G. This integrated the feature information of all the variables at different time steps, providing rich fingerprint features for the subsequent data analysis and identification of the network devices. Through this feature extraction process, not only was the key information of the data retained, but the expressiveness and interpretability of the data were enhanced.
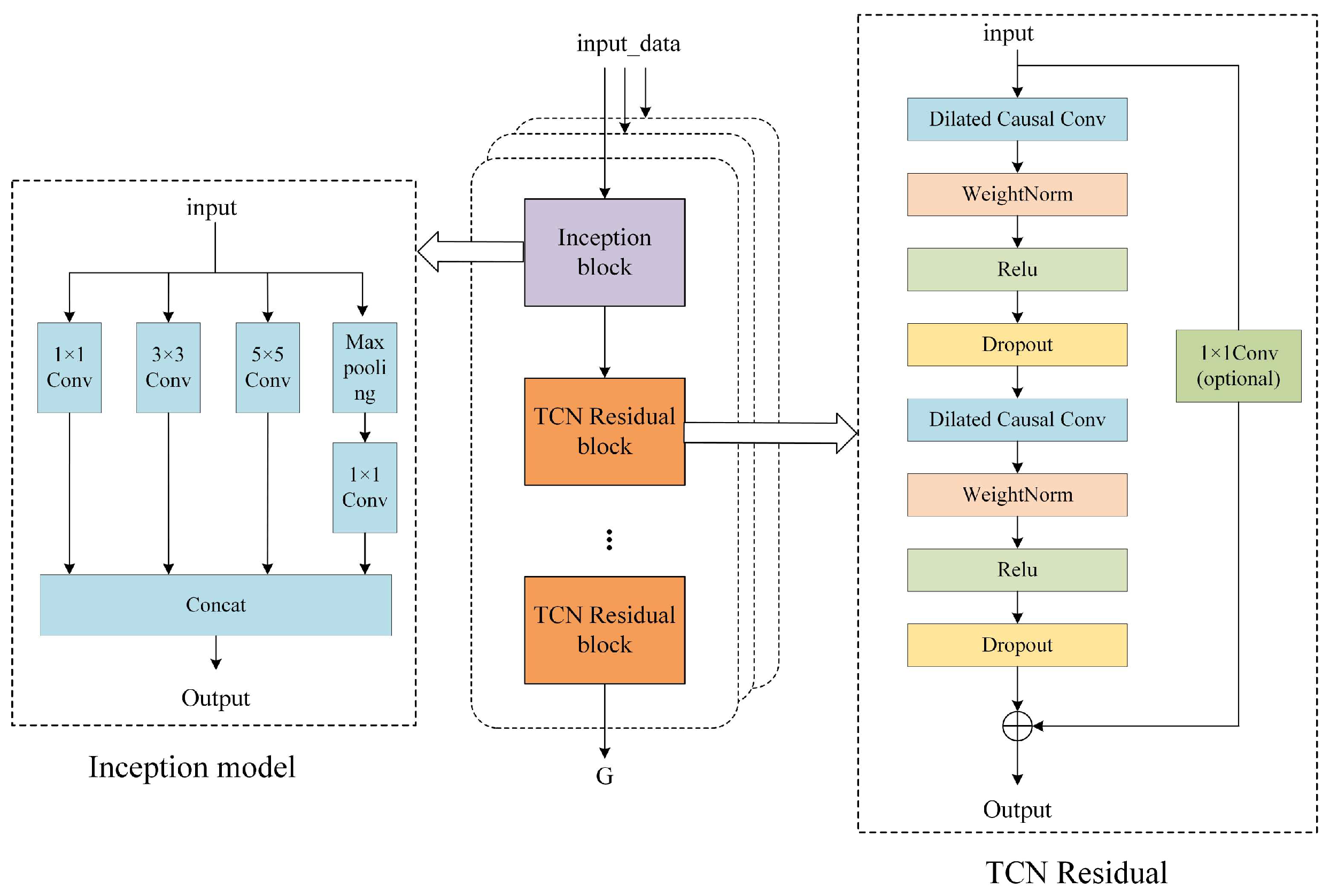
The structure of the sub-model for extracting features for each variable is given in Figure 5. The input data for each sub-model were a single sequence of features from a sequence of multidimensional packets. These sequences were first passed through the Inception structure, where convolutional results of different convolutional kernel sizes were computed to be spliced to extract information at different time scales, and then processed through a series of TCN residual blocks to progressively extract features at different levels of abstraction.
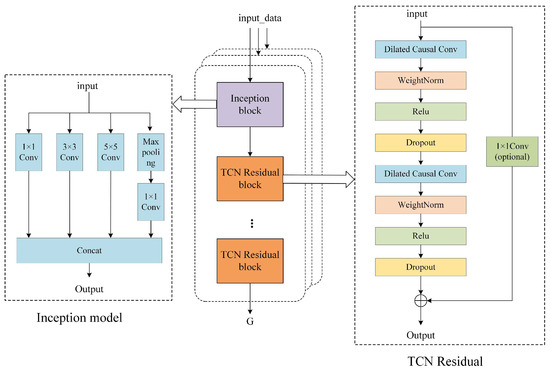
Figure 5.
Inception-TCN model structure.
The Inception structure contains four branches: the convolutional layers with convolutional kernels of 1, 3, and 5, and the branch with the largest pooling layer. The use of a 1 × 1 convolution reduces the number of input channels, which, in turn, reduces the computation demand of the subsequent convolutional layers. This design can effectively reduce the number of parameters and computational complexity of the model, making the model more efficient. The Inception structure uses different sizes of convolution kernels and pooling layers to capture features at different scales, which helps to improve the recognition ability of the model, and multiple parallel convolutional and pooling layers can increase the nonlinearity of the model, which helps to avoid overfitting and improves the generalizability of the model. In addition, the Inception structure can easily extend the depth and width of the model by increasing or decreasing the number and type of Inception modules, which provides flexibility for model optimization.
The structure of the TCN residual block consists of two convolutional layers, the ReLU activation function and the Dropout layer, which use inflated causal convolution to increase the receptive field without increasing the number of parameters. The expansion factor grows exponentially in successive convolutional blocks, which means that the receptive field of each block is larger than the previous one. weight_norm is applied for regularization, which decomposes the weight of the convolutional layer into two parts, size and direction, and normalizes each of these two parts. This technique helps to stabilize the training process, especially for deep networks, and it can help to mitigate the problem of vanishing or exploding gradients, thus speeding up convergence and improving model performance. Hopping layer connections are used to stream gradients during training and allow the model to learn more complex representations. The use of jump-layer connections and ReLU activation functions helps to improve model training and generalization. The number of residual blocks of the sub-model varies according to the number of variables in different datasets and therefore exhibits robustness.
3.2. Feature Fusion and Classification
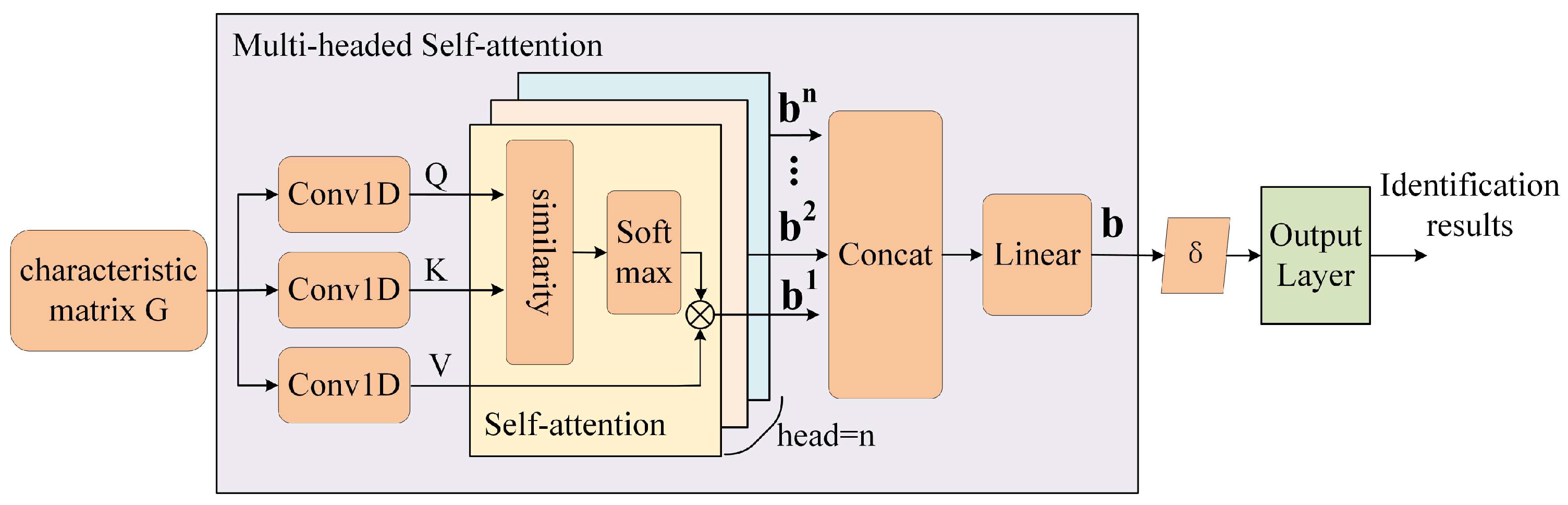
In the previous section, we implemented the splicing of multiple variable features to construct a feature matrix G. This matrix integrated multiple features to be able to comprehensively capture the information in the packet sequence. Next, to achieve effective feature fusion and further improve the performance of the model, we employed a new feature fusion strategy that introduced a multi-head self-attention mechanism to the feature matrix G. The core of this mechanism is to dynamically assign weights to each feature in the feature matrix. In this way, the model can be made to focus more on those features that are crucial to the recognition task during the training process, improving the efficiency and accuracy of feature extraction. The introduction of the attention mechanism can significantly reduce the number of required parameters compared to traditional feature fusion methods, which not only reduces the complexity of the model but also makes the training process of the model more efficient. In addition, the attention mechanism can adaptively adjust the feature weights according to the characteristics of the data and the needs of the task, achieving the identification and exploitation of key features in the multi-feature matrix.
Figure 6 represents the flow of the feature fusion and classification phase. The input of this phase was the feature matrix G, which was the intermediate result obtained from the feature extraction phase. The feature matrix was computed by the multi-head self-attention mechanism to obtain the feature vector δ, and the output was the classification result.
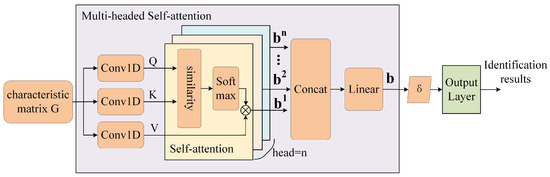
Figure 6.
Feature fusion and classification process based on a multi-head self-attention mechanism.
4. Evaluation
4.1. Experimental Environment and Dataset
Our experimental environment is shown in Table 3. The dataset used for the experiments was the UNSW dataset, which is a collection of network logs of the normal operation of networked devices, recording the data of each device interacting in a real environment over a period of 26 weeks and covering data generated by and independent of human interactions. This method of data collection ensured the authenticity and diversity of the data samples, providing a more objective basis for this research and analysis.
Table 3.
The hardware/software configuration used in the experiment.
4.2. Evaluation Metrics
We chose five evaluation metrics to assess our method: accuracy, balanced accuracy, precision, recall, and F1 score. The calculation formulas are shown in (2)–(6) as follows:
where TP denotes actual true and classifier predicted true; TN denotes actual false and classifier predicted false; FP denotes actual false and classifier predicted true; and FN denotes actual true and classifier predicted false.
4.3. Ablation Study
To verify the contribution of the Inception structure, the multi-head self-attention mechanism, and the design of separate sub-models for the variables to the overall model, we designed an ablation experiment with four models for comparison: INTCN_AT, TCN_AT, INTCN, and INTCN_AT_VAR. INTCN_AT is the algorithm designed in this study, and TCN_AT is a model without the Inception structure, allowing us to test the improvement in the Inception structure on the network device recognition algorithm. INTCN lacked the multi-head self-attention mechanism. INTCN_AT_VAR allowed us to input multiple variables as different channels into the model without designing a separate model for each variable, to test the effect of separate sub-models for the variables on the extraction of features.
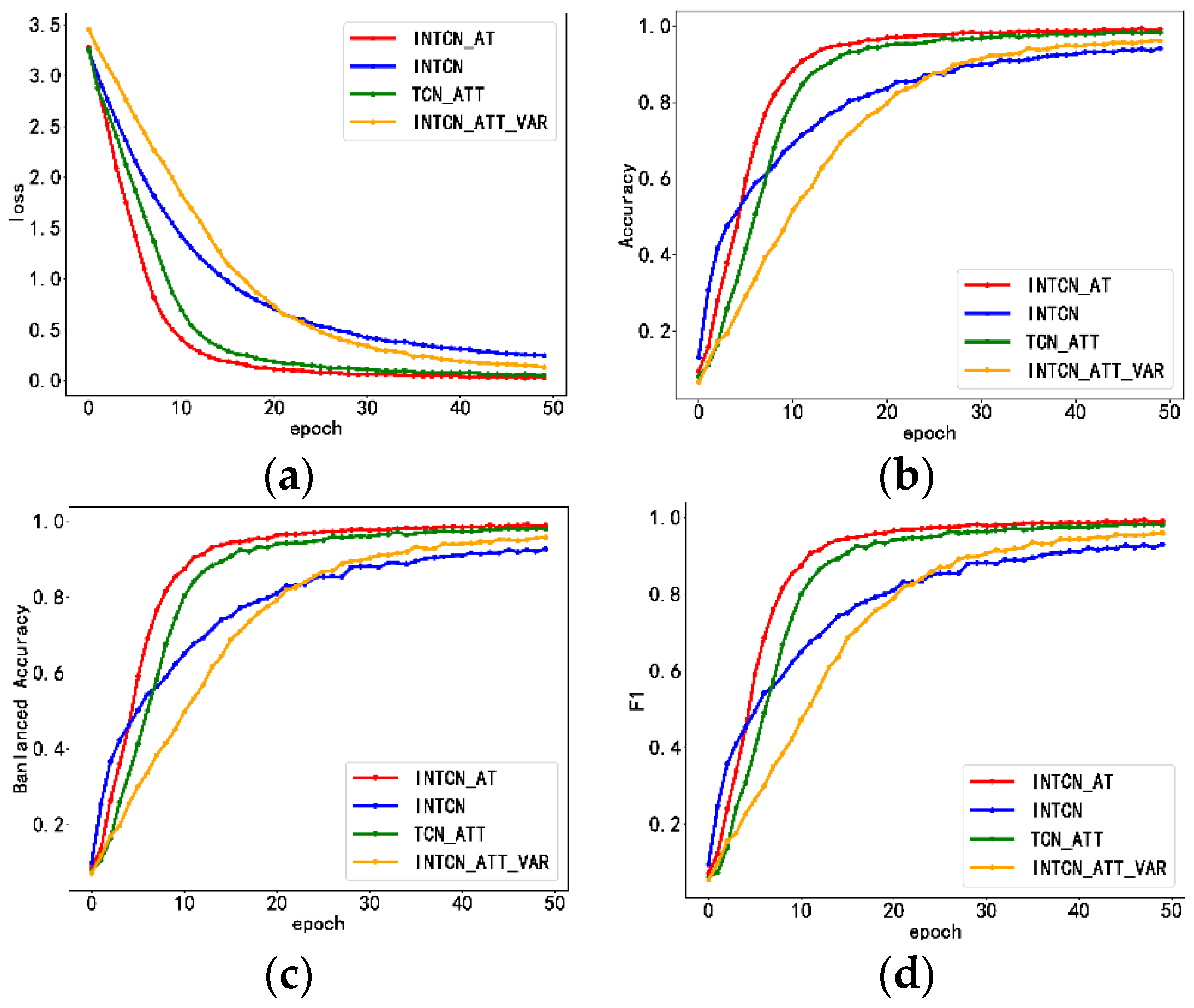
Figure 7a–d show the changes in loss, accuracy, balanced accuracy, and F1 values of the four models in the training set with the increase in iterations, respectively. For the INTCN model without the multi-head self-attention mechanism, during the training set, the loss value was larger than for the INTCN_AT model, and the accuracy value, balanced accuracy value, and F1 value achieved a better performance in the pre-training period. With more iterations, the improvement in the above indexes was not as good as for the INTCN_AT model, which verified that the multi-head self-attention mechanism performs well in feature extraction with training and is capable of extracting the key information in the feature matrix for better device fingerprinting and a more efficient recognition effect.
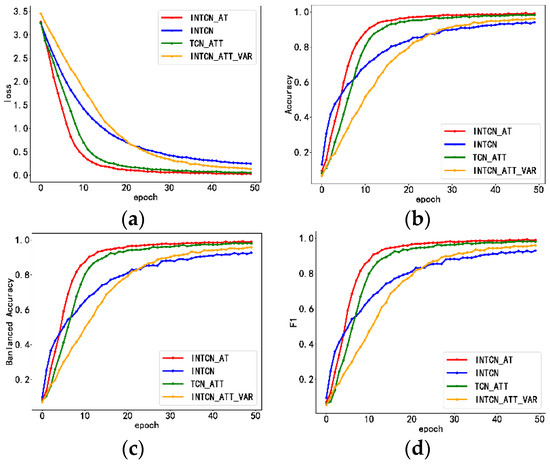
Figure 7.
Plot of changes with the number of iterations during the training of each indicator. (a) Change in loss; (b) change in accuracy; (c) change in balanced accuracy; and (d) change in F1.
For the TCN_ATT model without the Inception structure, the loss value, accuracy value, balanced accuracy value, F1 value, and INTCN_AT model showed similar trends and performances. To reduce the complexity of the overall model, we only applied the simplest Inception structure. With the increase in iterations, the two models converged as the TCN model also had the ability to extract the dependency relationship between the time series, and the data were too long for the connection between the time steps, resulting in the final difference between the two models being small. However, the Inception structure still improved the overall model training efficiency.
For the INTCN_ATT_VAR model without separate sub-models for each variable, all four indicators were lower than in the INTCN_AT model with separate sub-models. This was because separate sub-models can better extract the information of different abstraction levels of different time steps between the present features without interference from other information, which improved the recognition effect.
The performance of the four models on the test set is shown in Table 4. As for the training set, the five indicators for the TCN_AT, INTCN, and INTCN_AT_VAR models were lower than those for the INTCN_AT model, showing that the Inception structure, the mechanism of multiple self-attention, and the individual design of sub-models for each variable had a positive effect, making the overall model more efficient in recognition. Designing a separate sub-model for each variable had the most significant impact, leading to an improvement of about 5%, followed by the multiple self-attention mechanism, with an improvement of about 3%. The improvement effect of the Inception structure was only about 1%. Designing separate sub-models for each variable ensures that the temporal dependency of each feature is extracted and no information is lost, which plays a key role in recognition, while the multi-head self-attention mechanism can effectively fuse the features to generate more recognizable fingerprints, which is highly effective in recognition. The Inception structure is used to extract the information of different time steps, which has the same function as the TCN model to some extent, so less improvement in the recognition effect was observed.
Table 4.
Performance of the four models on the test set.
We compared our results with past research using traditional machine learning algorithms, and the results are shown in Table 5. IoT-Sentinel was the earliest method that used fingerprints, IoT-Sense further improved the fingerprint extraction, IoTDevID adopted more comprehensive features and performed a strict dimensionality reduction, SysID [19] adopted a two-phase classification method, and DOCAT [20] joined the protocol information. All of the above methods were manual feature extraction methods, meaning they suffered from information leakage. INTCN_AT automatically extracts the timing features of packets and extracts more abstract features as device fingerprints, achieving a better device identification effect.
Table 5.
Comparison with previous works.
4.4. Effect Analysis of Single-Class Device Recognition
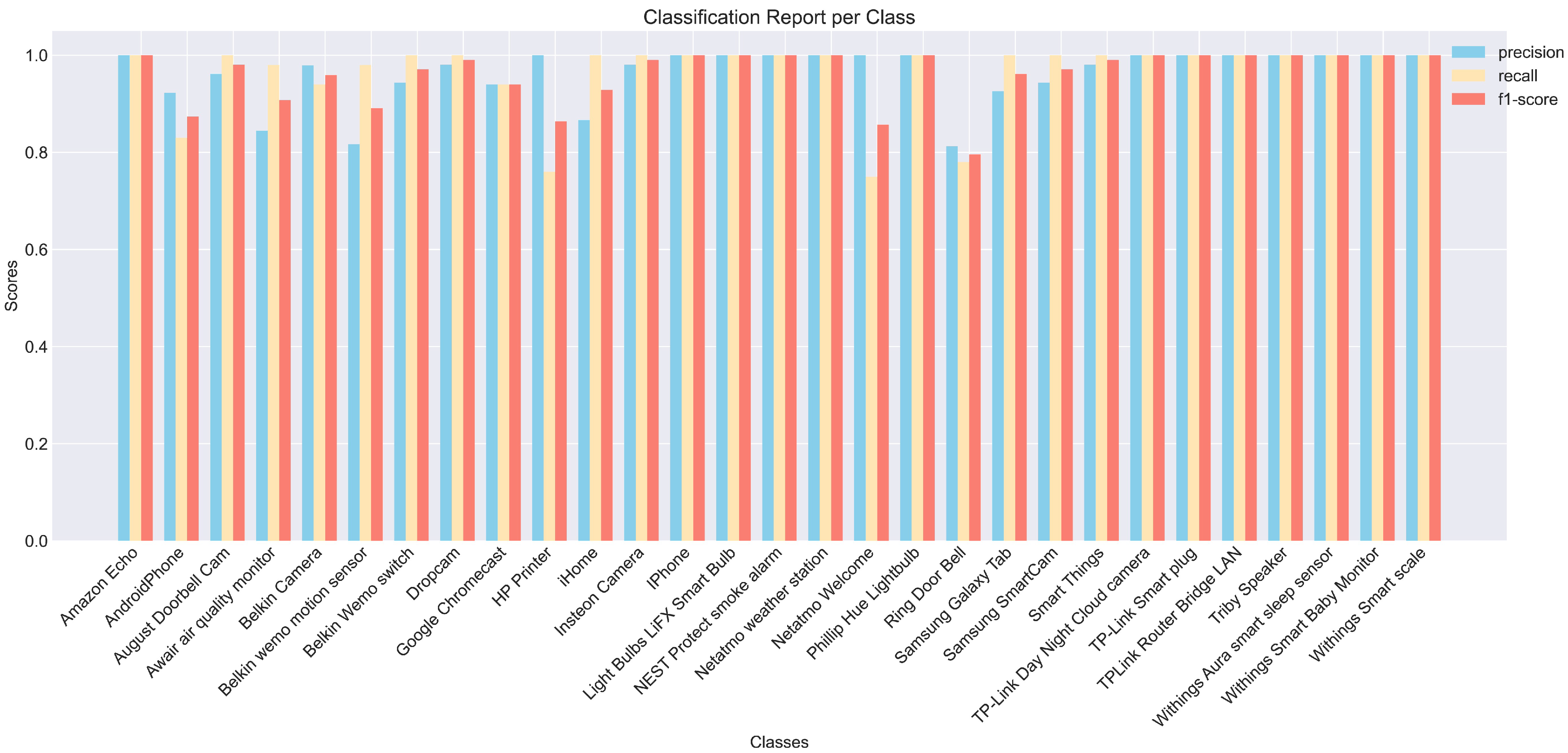
To explore the recognition effect of each device, we studied the precision, recall, and F1 value of each category, and carried out visual processing, as shown in Figure 8. As can be seen from the results, except for a few types of devices with lower indicators, such as Ring Door Bell and Android Phone, the recognition effect of the other devices was higher, verifying the feasibility and effectiveness of this method. We also found that the precision value of some devices was higher, while the recall and F1 values were lower, which was due to the imbalance of the data of each device.
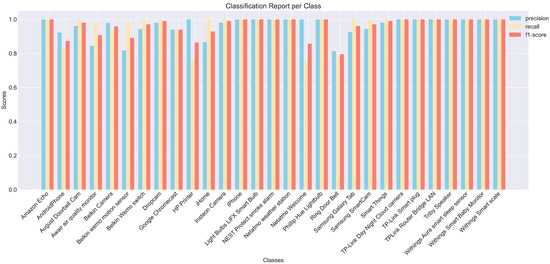
Figure 8.
Classification indicators for each equipment type.
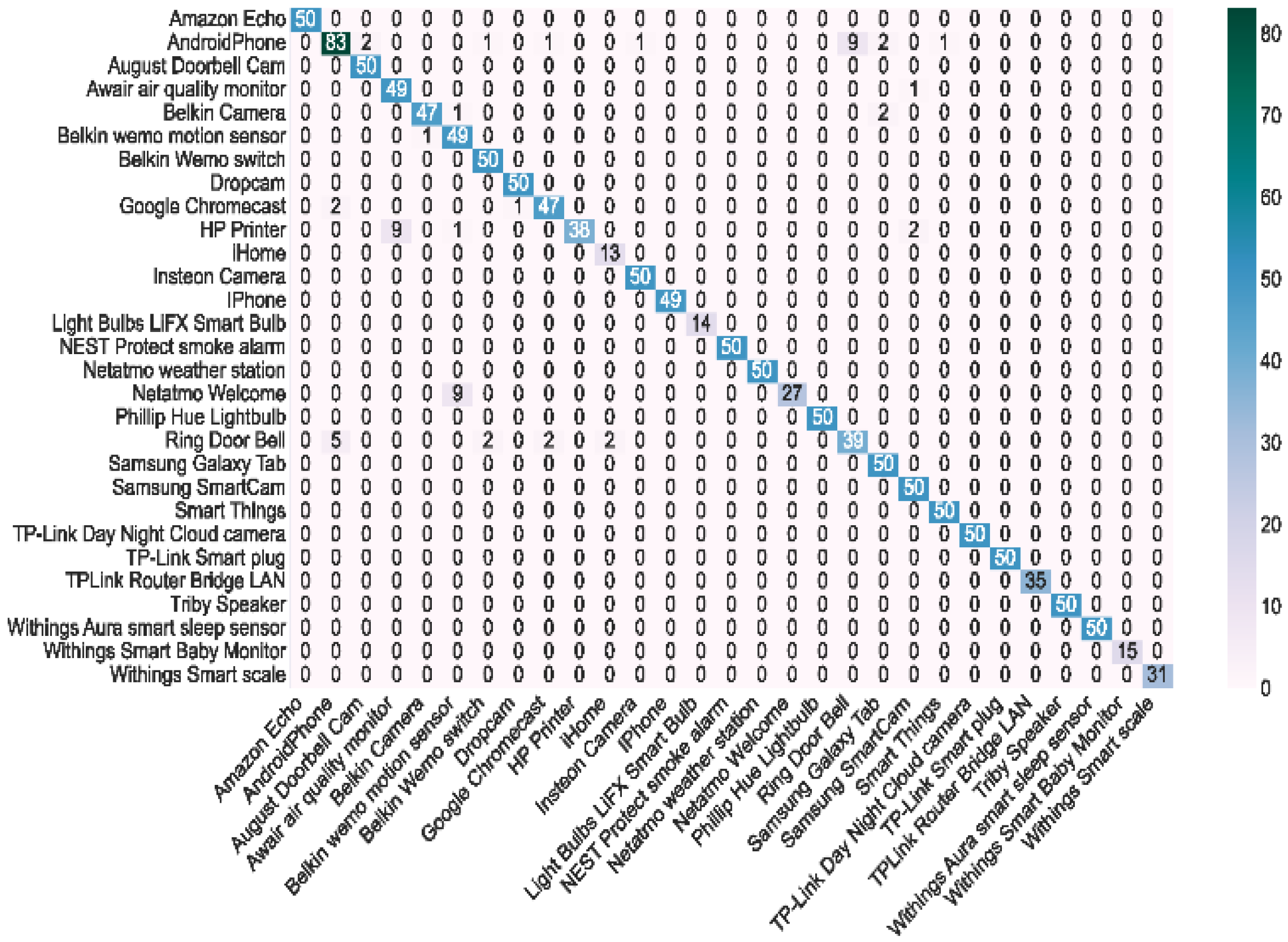
To explore the device misclassification categories, the confusion matrix for the UNSW dataset classification was investigated, as shown in Figure 9. A small fraction of the device types were misclassified as other classes of devices. The results were poor for Android Phone; the vast majority of the misclassified samples were identified as Ring Door Bell, and Ring Door Bell was also misclassified as Android Phone in most of the cases. A possible reason for this is that the features of these two types of devices are similar, and their packets have similar behavioral and timing characteristics.
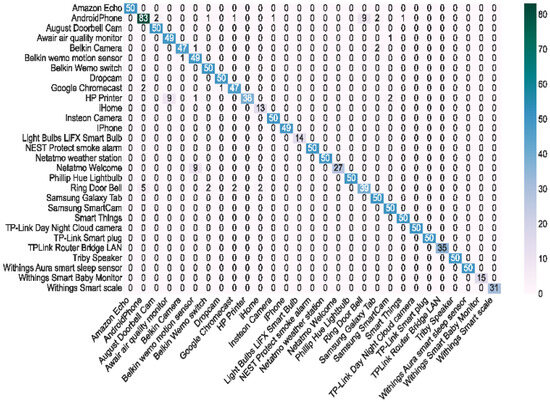
Figure 9.
Confusion matrix for the UNSW dataset.
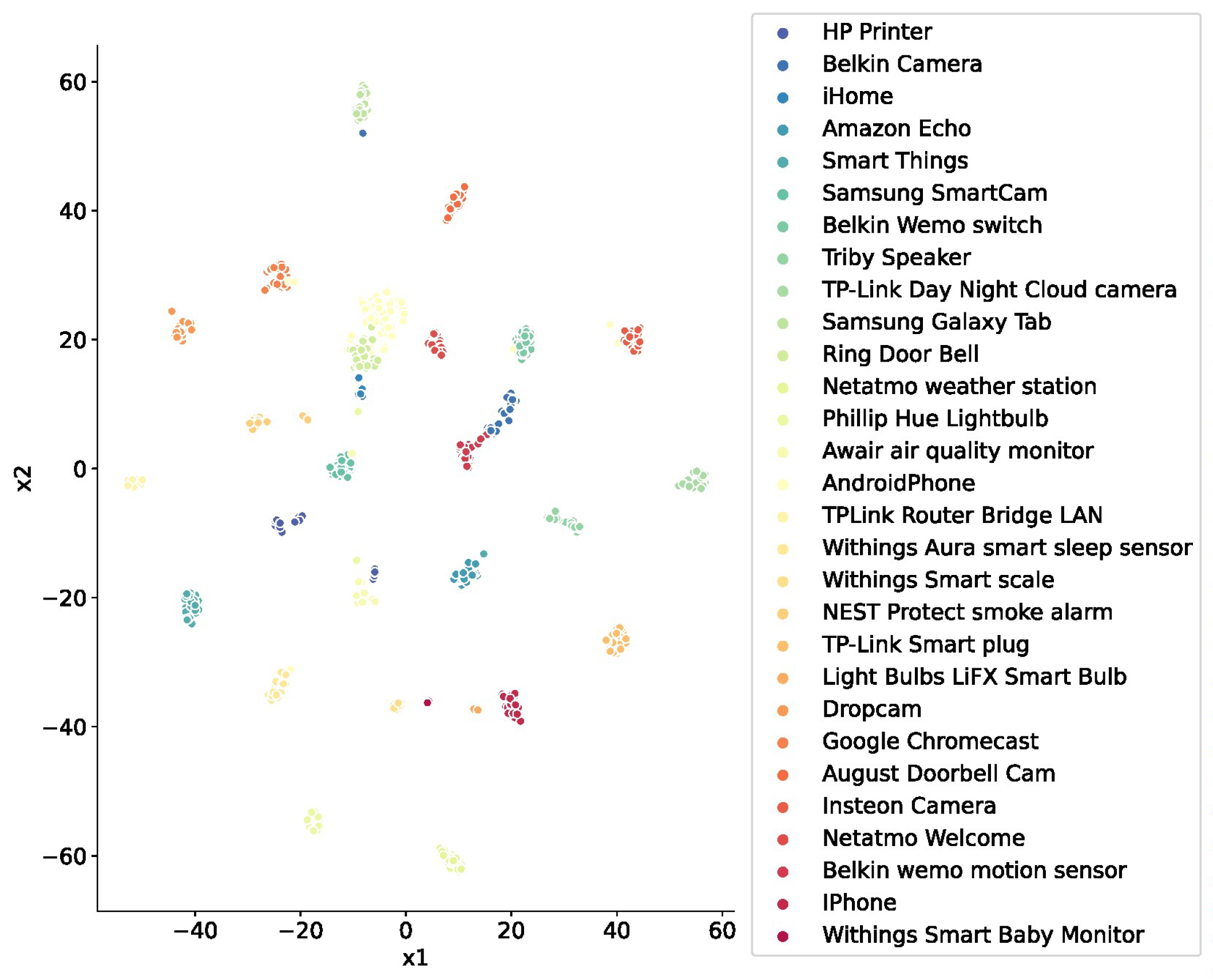
In order to demonstrate the effectiveness of the device fingerprints extracted by this method, in this study we mapped the high-dimensional device fingerprints into a two-dimensional space using the t-SNE dimensionality reduction algorithm. Each type of device was marked with different colors, as shown in Figure 10. From the figure, it can be seen that the different types of data formed a cluster, and most of the clusters had obvious boundaries between them, which indicated the distinguishability of the individual device fingerprints, and verified the validity of the device fingerprints extracted by this method.
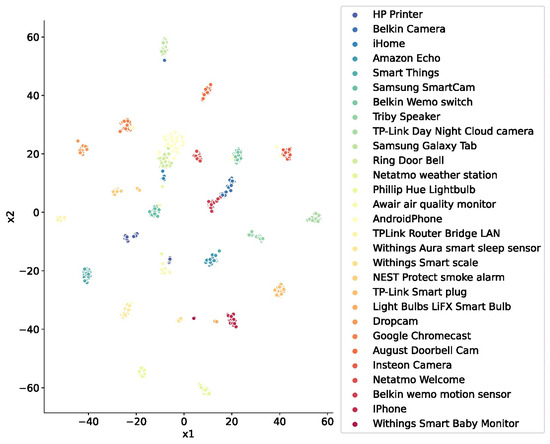
Figure 10.
Visualization of the device fingerprinting effects.
5. Conclusions
In this paper, we proposed a network device identification method based on packet temporal features. This method first extracts the basic behavioral information of the packet, then uses the feature selection method for dimensionality reduction, designs a TCN model with an Inception structure to extract the temporal features of each feature of the packet, and uses the multi-head self-attention mechanism for the fusion of each feature to generate a feature fingerprint for network device identification. This approach added the temporal relationship between the data and increased the discriminative nature of the device fingerprints compared to identification using network packet behavioral information alone. The experimental results on the UNSW dataset showed that our method achieved better accuracy. We analyzed the recognition effect of a single type of device, and the results showed that the classification of devices produced by the same manufacturer or of different models of the same type of device was poor. This should remain a focus of subsequent research.
Author Contributions
Conceptualization, L.H.; methodology, B.Z. and G.W.; investigation, G.W.; formal analysis, B.Z.; writing—original draft preparation, B.Z.; writing—review and editing, L.H. and B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon request.
Conflicts of Interest
Author Guangji Wang was employed by the company Zhejiang Guo Fu Environmental Technology Co. Ltd. The remaining authors declare that the re-search was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Zhou, W.; Jia, Y.; Peng, A.; Zhang, Y.; Liu, P. The effect of iot new features on security and privacy: New threats, existing solutions, and challenges yet to be solved. IEEE Internet Things 2019, 6, 1606–1616. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Wang, H.; Sun, L. Characterizing industrial control system devices on the internet. In Proceedings of the IEEE 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–10. [Google Scholar]
- Miettinen, M.; Marchal, S.; Hafeez, I.; Asokan, N.; Sadeghi, A.R.; Tarkoma, S. Iot sentinel: Automated device-type identification for security enforcement in iot. In Proceedings of the IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 2177–2184. [Google Scholar]
- Bezawada, B.; Bachani, M.; Peterson, J.; Shirazi, H.; Ray, I. Behavioral fingerprinting of iot devices. In Proceedings of the Workshop on Attacks and Solutions in Hardware Security, Toronto, ON, Canada, 15–19 October 2018; pp. 41–50. [Google Scholar]
- Kostas, K.; Just, M.; Lones, M.A. IoTDevID: A Behavior-Based Device Identification Method for the IoT. IEEE Internet Things 2019, 9, 23741–23749. [Google Scholar] [CrossRef]
- Hamad, S.A.; Zhang, W.E.; Sheng, Q.Z.; Nepal, S. Iot device identification via network-flow based fingerprinting and learning. In Proceedings of the 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 103–111. [Google Scholar]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying iot devices in smart environments using network traffic characteristics. IEEE T. Mob. Comput. 2019, 18, 1745–1759. [Google Scholar] [CrossRef]
- Aneja, S.; Aneja, N.; Islam, M.S. Iot device fingerprint using deep learning. In Proceedings of the IEEE International Conference on Internet of Things and Intelligence System (IOTAIS), Bali, Indonesia, 1–3 November 2018; pp. 174–179. [Google Scholar]
- Chowdhury, R.R.; Idris, A.C.; Abas, P.E. A deep learning approach for classifying network connected iot devices using communication traffic characteristics. J. Netw. Syst. Manage. 2023, 31, 21. [Google Scholar] [CrossRef]
- Liu, X.; Han, Y.; Du, Y. Iot device identification using directional packet length sequences and 1d-cnn. Sensors 2022, 22, 8337. [Google Scholar] [CrossRef] [PubMed]
- Yin, F.; Yang, L.; Ma, J.; Zhou, Y.; Wang, Y.; Dai, J. Identifying iot devices based on spatial and temporal features from network traffic. Sec. and Commun. Netw. 2021, 2021, 16. [Google Scholar] [CrossRef]
- Yin, F.; Yang, L.; Wang, Y.; Dai, J. Iot etei: End-to-end iot device identification method. In Proceedings of the IEEE Conference on Dependable and Secure Computing (DSC), Aizuwakamatsu, Fukushima, Japan, 30 January–2 February 2021; pp. 1–8. [Google Scholar]
- Khakpour, A.R.; Liu, A.X. An information-theoretical approach to high-speed flow nature identification. IEEE/ACM Trans. Netw. 2013, 21, 1076–1089. [Google Scholar] [CrossRef]
- Martin, A.; Doddington, G.; Kamm, T.; Ordowski, M.; Przybocki, M. The det curve in assessment of detection task performance. Eurospeech 1997, 4, 1895–1898. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Hu, D. An introductory survey on attention mechanisms in nlp problems. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 3–4 September 2020; pp. 432–448. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; Volume 10, pp. 429–439. [Google Scholar]
- Aksoy, A.; Gunes, M.H. Automated iot device identification using network traffic. In Proceedings of the IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Chowdhury, R.R.; Idris, A.C.; Abas, P.E. Internet of things device classification using transport and network layers communication traffic traces. Int. J. Com. Dig. Sys. 2022, 12, 544–555. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).