Abstract
As one of the early manifestations of road pavement structure degradation, road cracks will accelerate the deterioration of the road if not detected and repaired in time. Aiming at the problems of low recall and incomplete crack detection in current road detection, based on the U-Net network, this paper proposed an Attention-Dynamic Snake Convolution U-Net (ADSC-U-Net) network. Firstly, the dynamic snake-shaped convolution was added to the normal downsampling process to make the network adaptively focus on the slender and curved local features, which can solve the problem of low accuracy of small crack detection. Secondly, the attention mechanism was used to pay better attention to the significant features of positive samples under the condition of a large proportion gap between positive and negative samples, which solved the problem of the poor crack integrity detection effect. Finally, the dataset was expanded by random vertical and horizontal flip operations, which solved the problem of network training overfitting caused by the small-scale datasets. The experimental results showed that, when the input image had a resolution of 480 × 320, evaluation indices P, R, and F1 of ADSC-U-Net on the self-built dataset were 74.44%, 68.77%, and 69.42%, respectively. Compared to SegNet, DeepLab, and DeepCrack, the P was improved by 1.90%, 2.49%, and 11.64%, respectively; the R was improved by 8.01%, 4.70%, and 59.58%, respectively; and the comprehensive evaluation index F1 was improved by 5.73%, 4.02%, and 55.87%, respectively, which proves the effectiveness of the proposed method.
1. Introduction
The continuous growth of highway traffic flow in China and the large-scale construction of roads in the past have entered the restoration period, and the concept of transportation infrastructure construction is constantly changing from “building first” to “placing equal emphasis on construction and maintenance”. As one of the main sources of pavement diseases, if cracks are not detected and repaired in time, they will accelerate the deterioration of pavement, so the generation and severity of cracks are important indicators to be maintained [1]. At present, the road disease detection methods are roughly divided into three categories: image processing-based, machine learning-based, and deep learning-based [2]. The road disease detection method based on image processing includes a variety of technical paths, crack segmentation based on the image threshold [3], sealing crack classification [4] for two-dimensional pavement images based on threshold segmentation, and multi-scale wavelet transform algorithm to identify and segment the heterogeneous background pavement disease model [5]. However, the method based on threshold segmentation is usually difficult to select a correct threshold value for, and there are a large number of distractors on the road surface. The method based on image processing often has some phenomena, such as false detection and missed detection, with low detection accuracy and poor generalization ability. Machine learning (ML)-based methods include artificial neural network (ANN), Support Vector Machine (SVM), and Classification Regression Tree (CRT) [6]. Kyriakou et al. [7] combined smartphones and artificial neural network to realize automatic detection of road diseases, and the application method was simple and low cost. However, due to the low computational power and architecture efficiency, machine learning-based methods can only analyze some crack components [8]. Zhao et al. [9] elaborated on surface defect detection from the three aspects of traditional image processing, machine learning, and deep learning and analyzed that surface defect detection based on machine learning has low efficiency and generalization.
To address the aforementioned issues, we proposed a semantic segmentation of road cracks based on an improved U-Net network. In this study, we use a U-Net [10]-based road crack detection model, and compared to large models, U-Net exhibits reduced overfitting in scenarios with limited data due to its smaller parameter size. Dynamic snake convolution (DSC) [11] and the Channel Spatial Attention Mechanism (CBAM) [12] were added to detect more complete cracks. In comparison to standard convolution, DSC can adapt to the geometries of different targets and can easily capture the characteristics of incomplete cracks. CBAM focuses on the characteristics of both channel and space, so it can learn the characteristics of small cracks. The experimental results showed that the proposed model can better detect the discontinuity between small cracks.
With the rapid development of computer hardware and software, deep learning is considered an effective method for detecting road damage [13]. The deep learning method extracts the input data features layer by layer from the bottom to the top, learns from a large number of datasets to extract the relevant features, and automatically classifies and detects the input data through the learned features. At present, deep learning-based crack detection can be divided into three categories: image classification, target positioning, and semantic segmentation—classification to determine whether there are cracks in the image, target detection and positioning to produce a cover crack detection box, and semantic segmentation for the pixel-level prediction of the cracks in the image [14,15].
In the study of image classification, Zhou et al. [16] developed a deep convolutional neural network (DCNN) for crack detection based on a three-dimensional laser scanning dataset and determined the super parameters of the 36 DCNN system in accuracy and efficiency, but as the system relies on elevation change to detect the crack, the detection of shallow cracks is limited. Fan et al. [17] proposed a road crack detection algorithm based on deep learning and adaptive image segmentation. The experimental results showed that the image classification accuracy of this method was around 98.7%, but some color images with a large number of noisy pixels cannot be segmented correctly. Xu et al. [18] proposed a crack detection network based on the Atrous space pyramid module, which can reduce the computational complexity by acquiring multi-scale context information at a multi-sampling rate.
Target positioning can be more precise, further improving the accuracy of detection. In the related research, Majidifard et al. [19] established a model based on a U-Net model to quantify the severity of the disease and, finally, built a mixed model combining YOLO and U-Net to classify and quantify the severity of the disease, achieving a comprehensive assessment of road conditions. Zhu et al. [20] established a dataset of 3151 road surface images containing six disease types collected by UAV. This dataset was trained with three target detection models. The experimental results showed that the prediction performance of YOLOv3 was the best and most robust, but the detection accuracy of UAV still needed to be improved. Du et al. [21] addressed the issues of incomplete feature extraction in existing road pothole detection models and the practicality of detection equipment by proposing a lightweight object detection algorithm based on the YOLO BV-YOLOv5s. The model adopted a Bidirectional Feature Pyramid Network (BiFPN) structure for multi-scale feature fusion and utilized the Varifocal Loss function to optimize the sample imbalance problem. The experimental results demonstrated that the proposed model exhibited better performance and higher reliability in road defect detection.
However, methods based on classification and object detection fail to reveal the presence and specific details of cracks at the pixel level. The advantage of semantic segmentation is its capability to classify objects at the pixel level, achieving precise segmentation and facilitating comprehensive semantic analysis. Feng et al. [22] proposed a pavement crack identification method based on a deep convolutional neural network fusion model. The experimental results showed that this method can not only obtain pavement crack classification information but also provide accurate positioning and geometric parameters information. In order to identify the cracks in the image from other objects, Liu et al. [23] proposed a two-step method of pavement crack detection, as well as segmentation, based on a convolutional neural network. It combined the improved YOLOv3 and U-Net with the segmentation method. The experimental results showed that this method had the advantage of high accuracy. Hu et al. [24] constructed two network models, VGG Crack U-Net and Res Crack U-Net, to solve the semantic segmentation problem of crack images. The proposed model demonstrated significant advantages in pixel-by-pixel crack detection; however, it exhibited substantial issues with false negatives and false positive errors. Yuan et al. [25] proposed a model with deep convolutional neural network CurSeg as the core and integrated different scale features to obtain more context information. This model effectively suppressed noise propagation with strong robustness but showed limited effectiveness in detecting fine cracks and preserving crack integrity. Li et al. [26] proposed a CrackCLF network based on adversarial networks, embedding closed-loop feedback into the neural network to address the issue of the model’s inability to automatically adapt to environmental changes and effectively extract and detect wave cracks.
The application prospects of road disease detection based on deep learning are promising, yet there are still several problems: (1) the dataset is limited, leading to low efficiency and difficulty in detection, (2) the detection accuracy for small cracks is insufficient, and (3) the detection of crack integrity is unsatisfactory. To address the aforementioned issues, this paper combined several public datasets to train the neural network and expand the dataset by the data augmentation method. Inspired by the U-Net model, we combined U-Net with dynamic serpentine convolution and the attention mechanism to improve the detection accuracy of discontinuous cracks.
2. Base Model and Proposed Model
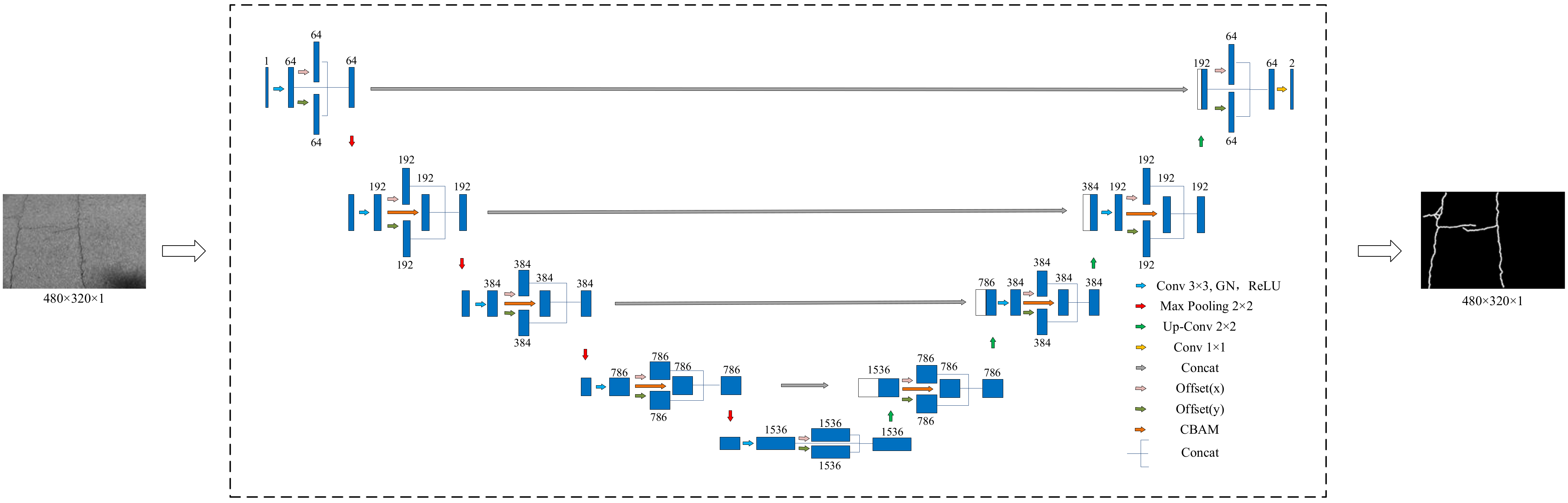
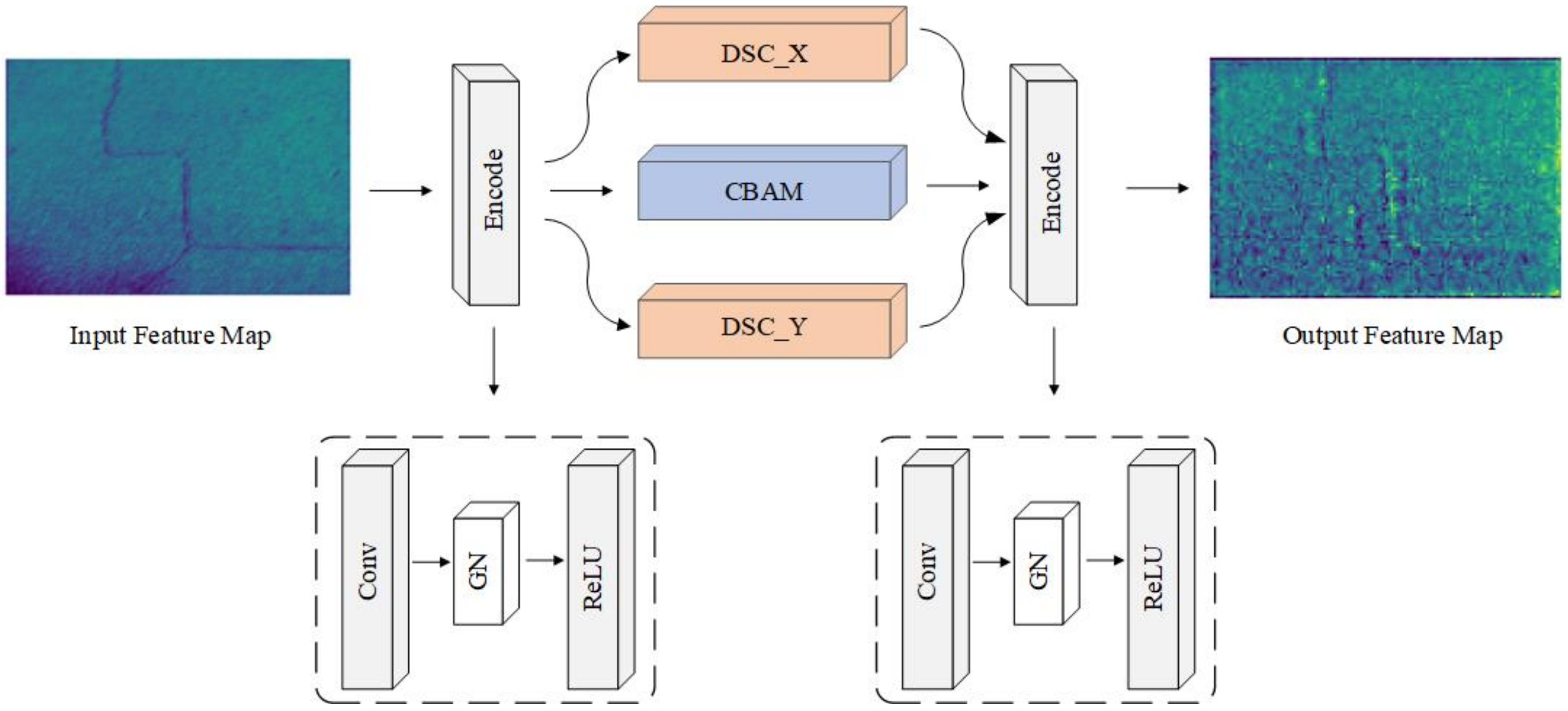
The excellent performance of U-Net in the medical field made it widely used in semantic segmentation. In addition, U-Net still performs well in small datasets. Therefore, we selected U-Net as the basic model in this study. The model mainly includes three parts: downsampling, upsampling, and jump connection. The main focus of this paper’s algorithmic improvements lies in downsampling and upsampling. During the upsampling and downsampling processes, a DSC module was integrated to accommodate the slender and winding pipe pile structure. Additionally, CBAM was embedded into the convolution process to enhance the detection module for small cracks. In the feature fusion stage, the downsampling was in contact with the upsampling feature map of the same size. The improved algorithm network Attention-Dynamic Snake Convolution U-Net (ADSC-U-Net) is illustrated in Figure 1. The network incorporates the DSC module from layer one to layer five, and the attention mechanism module is added in from layer two to layer four. In each downsampled layer on the left part of Figure 1, its feature map is concatenated with the corresponding upsampled feature map on the right, ensuring that the number of channels of these two feature maps is aligned. To provide a detailed explanation of the downsampling process, the third downsampling layer is used as an example here. As illustrated in Figure 2, the encoding process is comprised of three distinct phases: convolution, group convolution, and ReLU activation function. Subsequently, the encoded features are conveyed through the DSC module, which primarily introduces biases in the X and Y axes, and the CBAM module, which transforms them into three distinct components. These three components are then merged into a unified output through concatenation and additional encoding. Therefore, this whole process results in a transformation from an original grayscale representation on the left to an output image on the right. It can be observed that, following downsampling, the semantic information of the original grayscale input becomes more abstract due to the DSC and CBAM modules, while still retaining crack details.
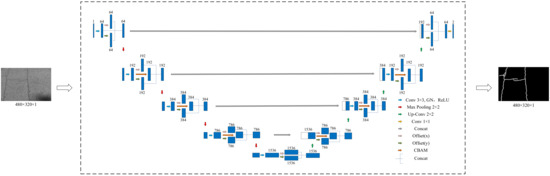
Figure 1.
The architecture of ADSC-U-Net.
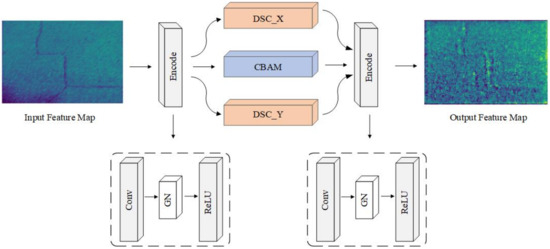
Figure 2.
Downsampling process of the feature maps.
Table 1 presents the modules and channel numbers used in each layer of the ADSC-U-Net network. Due to the inclusion of the DSC and CBAM modules, there has been an increase in the number of channels.

Table 1.
ADSC-U-Net network structure and number of channels.
2.1. Base Model
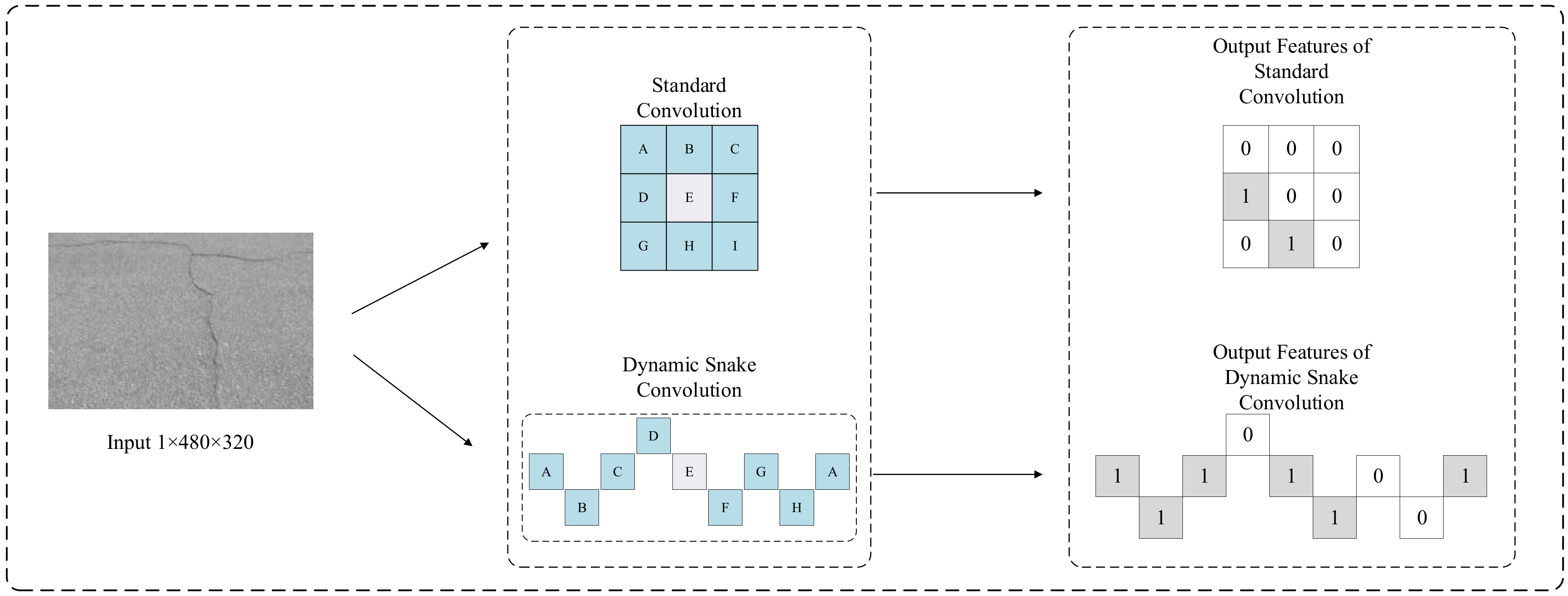
Currently, there are numerous improvements to U-Net, but they perform poorly in detecting crack integrity. To address this issue, this paper introduces a dynamic snake convolution module to enhance crack detection integrity. DSC is a type of dynamic convolution [27] that, unlike standard convolution, employs variable convolution kernels. This strategy enhances its capability to adapt and detect objects of various sizes more effectively. Typically, road cracks are surrounded by fine fissures and can appear indistinct amid complex backgrounds such as shadows, lane markings, and water stains. Standard convolutional neural networks struggle to detect these subsidiary cracks. In contrast, DSC adjusts its convolution kernel shape and size dynamically, adapting to irregular cracks. This flexibility of dynamic convolution enables it to better capture local features in irregular data compared to standard convolution, making it more adept at handling complex noise influences [28]. Furthermore, DSC is specifically enhanced for learning tubular structures, which are common in irregular shapes of road cracks. As shown in Figure 3, adding biases to the input enables the convolution kernel to extract features beyond those captured by standard kernels. Through bias-constrained networks, it achieves adaptive learning within a certain range. After passing through the DSC module, the original feature maps are no longer output in standard square grid shapes but rather in tubular shapes, which better conform to the shape of road cracks.
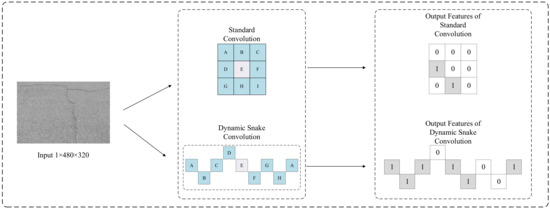
Figure 3.
The difference between using standard and dynamic snake convolutions.
This study integrates the DSC module into the U-Net network, enabling the network to adaptively focus on local features that are slender and curved. When road defect images are input into the DSC, the variable receptive field of DSC allows for the better fitting of irregular crack shapes during the downsampling feature extraction process. As shown in Figure 3, employing DSC enables the convolution kernel to vary horizontally and vertically, thereby capturing more useful information. In contrast, using standard convolutional kernels, the receptive field is limited to the surrounding pixels in the horizontal and vertical directions, whereas road cracks often exhibit tubular features that are more likely to extend horizontally or vertically rather than in the surrounding directions.
2.2. Proposed Model
For road crack datasets, the target pixels are relatively sparse, categorizing road crack detection as a task of detecting small objects. Additionally, an analysis of road crack patterns reveals that cracks often exhibit branching structures, and their color tends to be darker compared to the surrounding environment. To address the characteristics of crack shape, color, and small object detection, this study integrates the CBAM into the foundational U-Net network model and DSC module. This enhancement assists the network in accurately capturing crack features across both channel and spatial dimensions.
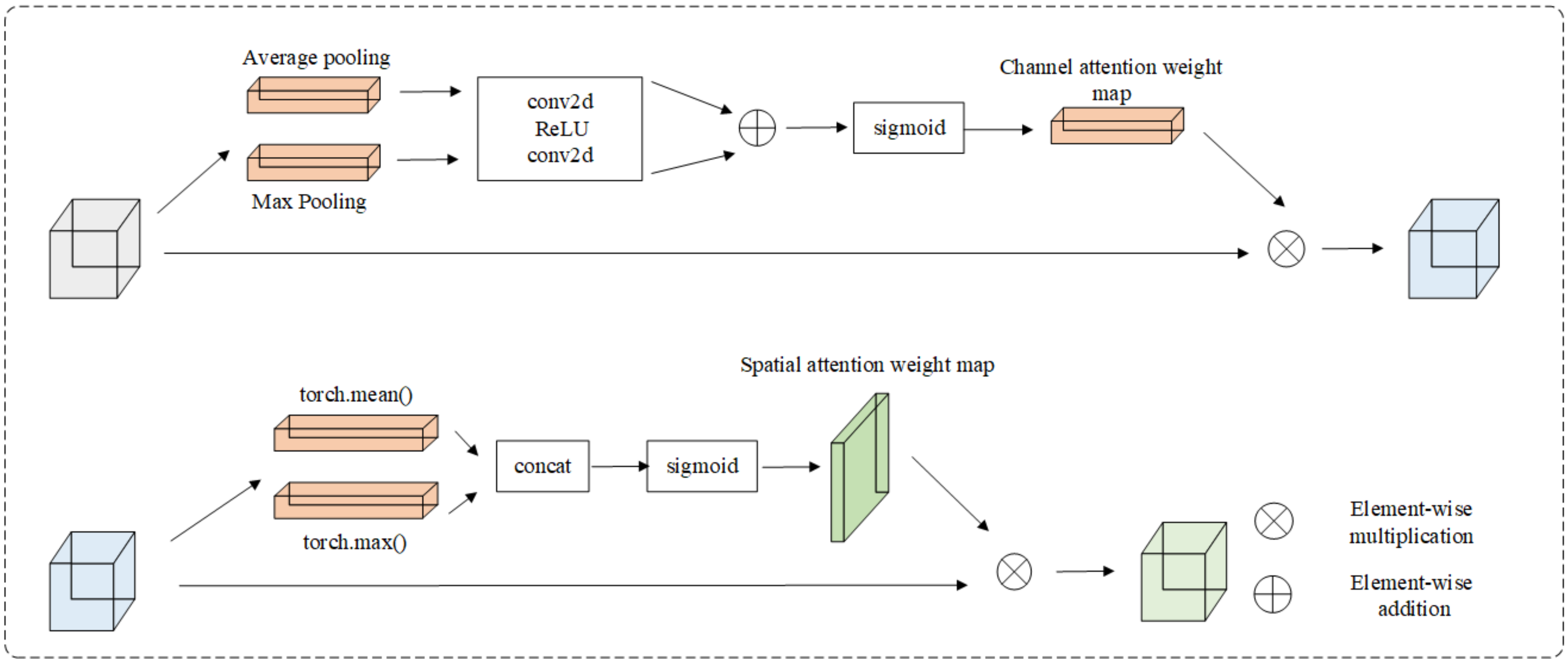
The CBAM module is commonly utilized to enhance the representation capabilities of convolutional neural networks across both channel and spatial dimensions. By adaptively computing and learning attention weights in these two dimensions, the network can better focus on crucial features while suppressing non-essential information. Specifically, in road defect images, this allows the network to prioritize crack features while disregarding extensive road backgrounds. The specific structure and operational processes of CBAM in this network are illustrated in Figure 4.
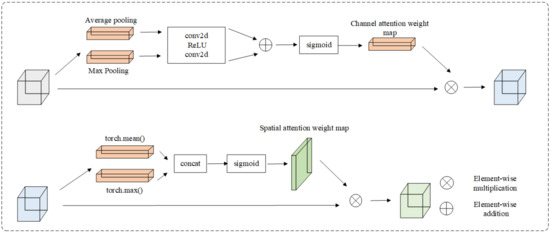
Figure 4.
Attention mechanism module.
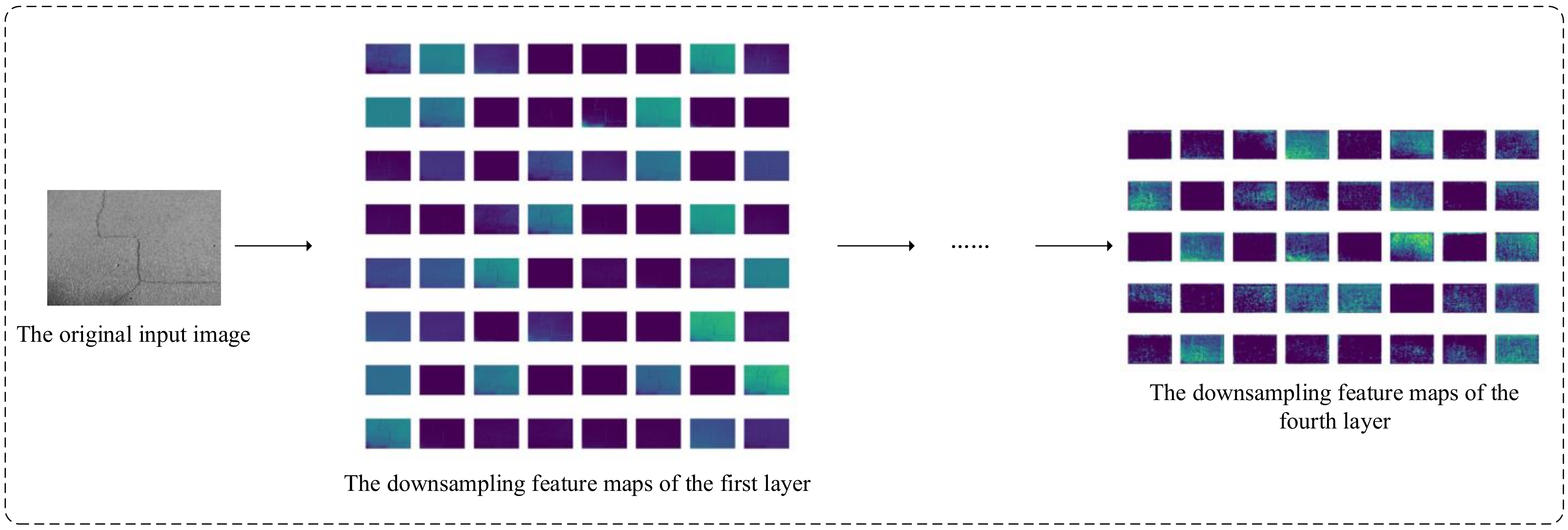
Figure 5 shows partial feature maps during the downsampling process of ADSC-U-Net. From the figure, it is evident that the original input image has a high proportion of background, with the surrounding pixels being lighter in color compared to the target pixels. Additionally, the cracks are predominantly oriented horizontally and vertically. As seen in Figure 2, as downsampling progresses, semantic information becomes increasingly abstract. At this stage, the network needs to allocate more attention to specific spatial locations and channel regions to identify abstract cracks effectively. The CBAM continuously computes and optimizes weights for important features across the channel and spatial dimensions, ensuring the effective preservation of road crack information in the ADSC-U-Net network. This capability enables the network to remain effective in handling high-level semantic information. Furthermore, the CBAM module assigns higher weights to crack features from the initial stages of the network, ensuring continuous focus on minor cracks during the subsequent downsampling processes. This characteristic enhances the network’s ability to detect small cracks effectively.
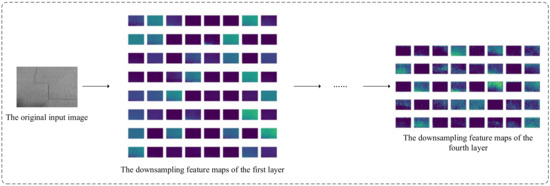
Figure 5.
The part of downsampling feature maps.
3. Dataset Description and Performance Metrics
3.1. Dataset Description and Processing
In this study, road defect data were collected from several datasets and a custom dataset. These include the Crack 500 dataset [29], which comprises 500 images of road surface cracks captured using mobile phones, each annotated with ground truth crack images. The Crack Forest dataset [30] contains 206 images of road defect scenes. Totally, our custom dataset consists of 4699 defect images. The datasets were partitioned in a 7:2:1 ratio for training, validation, and testing purposes. The datasets include images with various disturbances, such as shadows and zebra crossings, as illustrated in Figure 6.

Figure 6.
Images and ground truth from the dataset.
To enhance the network’s translational invariance and robustness, random horizontal and vertical flips, as well as rotations, were applied to the input images during data loading. Due to variations in image sizes and channel numbers across different datasets, all images were resized to 480 × 320 dimensions and converted to a single-channel format for uniformity during network training. Additionally, the entire dataset was standardized to expedite model convergence.
In the original dataset, label pixel values are either 0 or 255. For ease of subsequent processing, pixels with a value of 255 were modified to 1. During the prediction phase, the network assigns a probability value between 0 and 1 to each pixel. If the predicted probability is greater than or equal to 0.5, it is considered a target pixel; otherwise, it is considered a background pixel.
3.2. Experimental Environment and Performance Metrics
The algorithm in this study was implemented on a Windows 10 operating system, utilizing an i9-12900H CPU and a NVIDIA RTX 3090 GPU. The programming language used was Python 3.8, and the development was carried out on PyCharm using the PyTorch framework. During the experiments, the Adam optimizer was employed, with the learning rate set to 0.001, the number of epochs set to 300, and a batch size of 4.
For binary classification problems, the commonly used loss function is the cross-entropy loss function. This function assigns equal attention to each class during each gradient backpropagation, making it highly susceptible to the impact of class imbalance. In the context of road defect detection datasets, cracks (i.e., positive samples) occupy only a small portion of the entire image, with the majority of pixels belonging to the background (i.e., negative samples). The ratio of positive to negative sample pixels is illustrated in Figure 7. In such cases, the trained neural network tends to predict nothing, which is reflected in a low recall value. The formula for the cross-entropy loss function is shown in Equation (1).
where N denotes the total number of samples; represents the label of sample i, where the positive class is labeled as 1 and the negative class as 0; and indicates the probability that sample i is predicted to belong to the positive class.

Figure 7.
Comparison of positive and negative pixels.
This paper evaluates the crack detection algorithm using commonly employed machine learning metrics: precision (P), recall (R), and the harmonic mean F1-score. The F1-score, which is the harmonic mean of precision and recall, provides a comprehensive assessment of the model’s performance. It offers an overall metric that avoids the potential issue of neglecting a model’s performance in one aspect by focusing solely on either precision or recall. The formulas are shown in Equations (2) and (3).
where TP denotes true positive, the number of samples correctly predicted as positive by the model; FP denotes false positive, the number of samples incorrectly predicted as positive by the model; TN denotes true negative, the number of samples correctly predicted as negative by the model; and FN denotes false negative, the number of samples incorrectly predicted as negative by the model.
In crack detection, target pixels constitute only a small portion of the image, with most pixels belonging to the background. Consequently, even if the network predicts the entire image as background, the P metric can still be relatively high, while the R metric would be low. Therefore, in road crack detection tasks, a higher R value indicates a greater likelihood that the network detects cracks and that the detected cracks are more complete.
R is defined as the proportion of actual positive samples that are correctly predicted as positive. In crack detection, this metric reflects how many of the target pixels in actual cracks are correctly identified. Therefore, the higher the R value, the more complete the crack detection.
4. Results and Analysis
The proposed method in this paper utilizes the evaluation metrics mentioned in Section 3.2 for quantitative assessment. Ablation and comparative experiments were conducted to demonstrate the advantages of the proposed method. In the comparative experiments, ADSC-U-Net was compared to U-Net, SegNet [31], DeepLab [32], and DeepCrack [33] to validate the effectiveness of the proposed algorithm.
4.1. Results of the Ablation Experiments
This paper demonstrates the necessity and effectiveness of each module in the proposed model through ablation experiments. Under the same environmental configurations as mentioned in Section 3.2, the model was trained for 300 epochs on the custom dataset. The CBAM module and the DSC module were alternately added and removed to validate the effectiveness of the proposed modules. During the experiments, all other parameters were kept constant, except for the use of the specific modules.
The quantitative analysis results of the ablation experiments are presented in Table 2, where Experiment 1 serves as the baseline network, U-Net, upon which all subsequent experiments are conducted. As evident from the data in the table, the integration of the CBAM module significantly enhances the model’s performance. Specifically, compared to the original network, the network augmented with the attention mechanism experiences a slight decrease in P but achieves a notable 5.39% increase in R, leading to a 3.98% improvement in the comprehensive evaluation metric, F1-score. Furthermore, by comparing Experiment 3 with Experiment 4, it is observed that, while P undergoes a marginal decline, R improves by 2.83%. However, due to the inherent trade-off between precision and recall, maintaining simultaneous growth for both metrics is challenging. This indicates that the incorporation of the CBAM module enhances the network’s recall capability, manifesting in a more comprehensive detection of road cracks within images. Consequently, this approach addresses the issue of incomplete road crack detection, which is the primary objective of this study.
Table 2.
Ablation experiments of ADSC-U-Net.
Through the comparison between Experiment 1 and Experiment 3, it can be observed that the network with the addition of the DSC module exhibits a slight improvement in accuracy, accompanied by a substantial 5.49% increase in recall. This enhancement also translates to a 4.03% improvement in the F1-score. Additionally, by contrasting Experiment 2 with Experiment 4, it becomes evident that the incorporation of DSC enhances both R and F1, albeit with a minor decrease in P. However, this minor decrement in P is deemed tolerable in light of the overall improvement in model performance. Considering the cumulative effects, the inclusion of both modules optimizes the overall performance, and the removal of any of these modules from the model would inevitably impact the segmentation results.
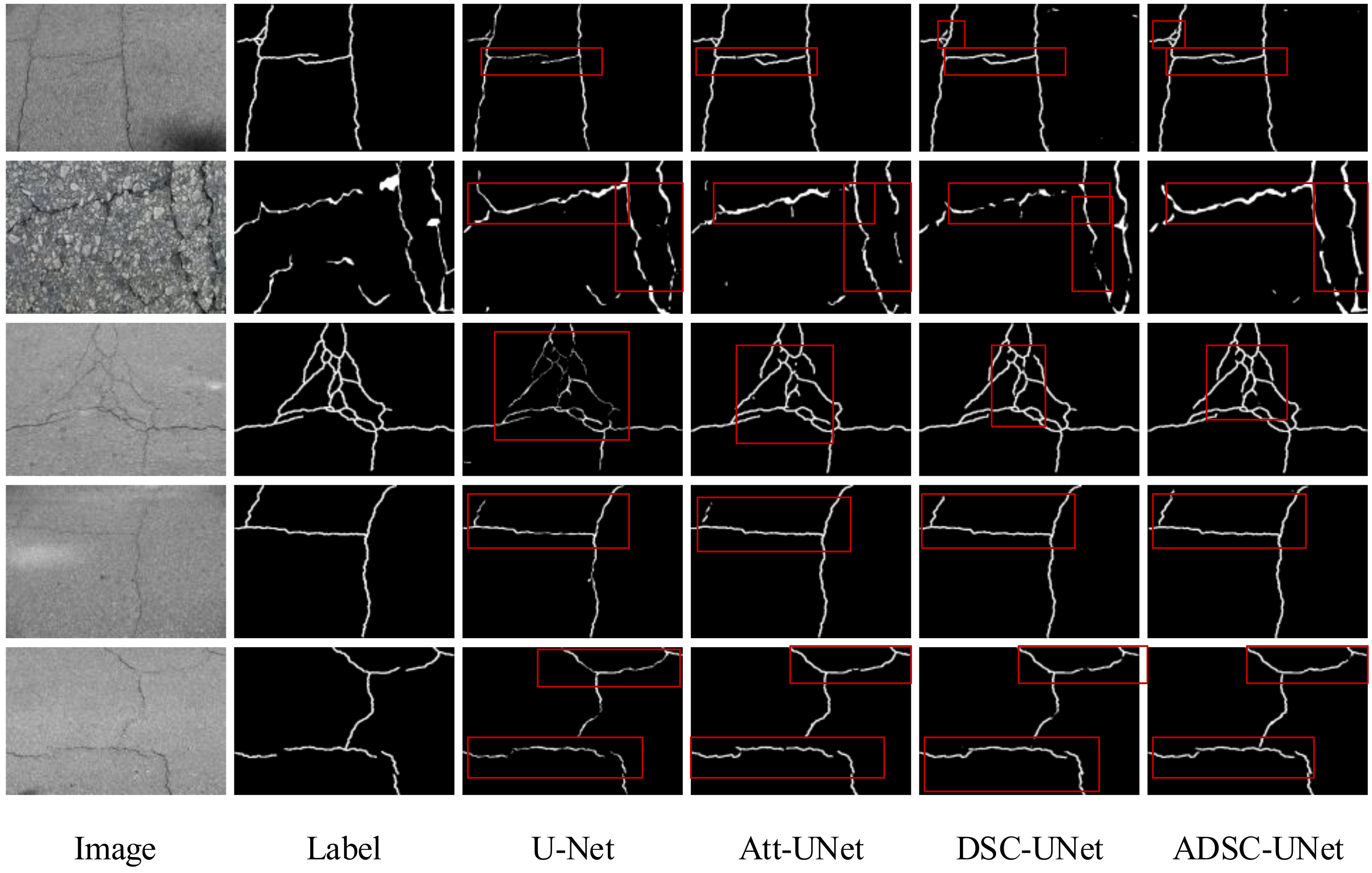
The qualitative results of the ablation experiments are depicted in Figure 8, where the white portions represent the network’s recognition outcomes, the black portions correspond to the background, and the red boxes highlight specific regions. Discernible from the red boxes, the ADSC-U-Net model demonstrates a commendable performance in detecting fine cracks and discontinuous crack regions. In contrast, U-Net exhibits a lesser efficacy in detecting elongated and thin crack segments, resulting in discontinuities. The individual addition of the DSC module in Dynamic Snake Convolution U-Net (DSC-U-Net) and the CBAM mechanism in Attention U-Net (Att-U-Net) enhances the completeness of crack detection to a certain extent. Furthermore, the fusion of both the DSC and CBAM within the model elevates the capability for comprehensive crack detection even further, which is manifested in the elevated R value among the evaluation metrics.
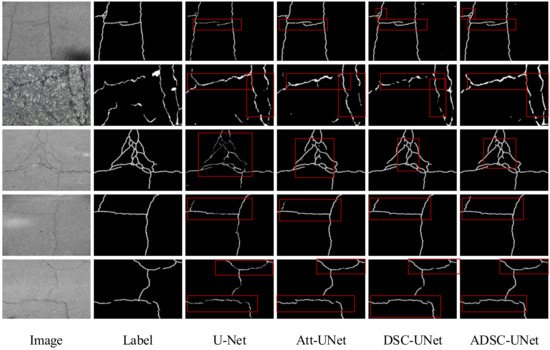
Figure 8.
Results of the ablation experiments.
4.2. Algorithmic Analysis and Comparison
The optimized network model, ADSC-U-Net, is compared to existing mainstream models such as U-Net, SegNet, DeepLab, and the DeepCrack network. According to the experimental results presented in Table 3, the optimized network model exhibits slightly lower P than U-Net but surpasses other algorithms in terms of the average precision, accuracy, and recall. Considered comprehensively, the algorithm proposed in this paper can enhance the integrity and accuracy of road crack detection, thereby contributing to improving road traffic safety levels.
Table 3.
Comparison results of ADSC-U-Net and other algorithms.
As shown in Table 3, the data indicates that the improved network exhibits significant enhancements in the comprehensive metrics of P, R, and F1-score. Compared to U-Net, the algorithm proposed in this paper slightly underperforms in P but demonstrates an 8.32% increase in R and a 5.21% improvement in F1-score. Considering these factors comprehensively, the detection results of ADSC-U-Net are superior to those of U-Net. When compared to SegNet, DeepLab, and DeepCrack, ADSC-U-Net shows improvements of 1.90%, 2.49%, and 11.64% in P, respectively, and enhancements of 8.01%, 4.70%, and 59.58% in R, respectively. Additionally, it exhibits improvements of 5.73%, 4.02%, and 55.87% in the comprehensive evaluation metric F1-score, respectively. DeepCrack performs poorly on the self-built dataset used in this paper, tending to predict targets as background.
Using the dataset divided in Section 3.2 for training, a qualitative evaluation of the proposed algorithm, as well as SegNet, DeepLab, and DeepCrack, is conducted on the validation set. The comparison results between the proposed algorithm and the other networks, including U-Net, SegNet, DeepCrack, and DeepLab, are shown in Figure 9. Specifically, the red boxes highlight the target pixel regions detected by our method that were not detected by the other networks. As can be seen from Figure 9, the proposed method demonstrates superior performance in detecting discontinuous cracks, while U-Net, SegNet, and DeepLab exhibit relatively poorer performance, and DeepCrack tends to predict targets as background in our self-built dataset.

Figure 9.
Comparative experimental results of each network.
5. Conclusions
In this study, we proposed the ADSC-U-Net by improving the base U-Net architecture and integrating the DSC and CBAM modules. The ablation experimental results indicate that the inclusion of both the DSC and CBAM modules enhances the network’s crack detection capabilities. Comparative experimental results demonstrate that our network detects cracks with greater completeness and continuity. Compared to U-Net, SegNet, DeepLab, and DeepCrack, ADSC-U-Net improves R by 8.32%, 8.01%, 4.70%, and 59.58%, respectively, thereby enabling more comprehensive crack detection. Additionally, the proposed network not only increases R but also enhances the overall evaluation metric F1, showing improvements of 5.21%, 5.73%, 4.02%, and 55.87% over U-Net, SegNet, DeepLab, and DeepCrack, respectively. Although the proposed method has a P slightly lower than U-Net, with a decrease of 1.22%, it outperforms SegNet, DeepLab, and DeepCrack, with improvements in precision by 1.90%, 2.49%, and 11.64%, respectively. Considering all the evaluation metrics comprehensively, the proposed method outperforms the other four methods, making it the most optimal approach.
6. Discussion and Future Works
By incorporating the DSC and CBAM modules, the representation capability of the network model for fine road cracks is effectively enhanced, and the loss of feature information is reduced. When compared to the SegNet, DeepLab, and DeepCrack networks, the proposed method in this paper demonstrates superior performance in detecting discontinuous and incomplete cracks. Both quantitative and qualitative evaluation metrics indicate the effectiveness of the proposed method.
However, the incorporation of DSC and the CBAM results in a relatively large network, which requires more memory and training time. Future improvements will focus on reducing the number of parameters. The current output of the network is limited to the morphological characteristics of cracks and does not include geometric parameter information. This limitation poses a certain degree of inconvenience for further analysis and processing by inspection personnel. To enhance the comprehensiveness and practicality of the detection results, future research should focus on improving the algorithm to enable the output to simultaneously encompass both the morphological and geometric information of cracks. This improvement would more effectively support the in-depth work of detection.
Author Contributions
Conceptualization, X.C.; Data curation, S.F. and X.C.; Formal analysis, X.Y.; Funding acquisition, S.F. and X.C.; Investigation, S.F. and X.Y.; Methodology, Y.N.; Resources, X.C., X.Y. and J.Z.; Software, Y.N. and Z.W.; Writing—original draft, Y.N.; Writing—review and editing, Y.N., X.C. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded in part by the Open Project of Shandong Key Laboratory of Smart Transportation (Preparation) under Grant 2021SDKLST004; China Postdoctoral Science Foundation under Grant 2023T160129; Shaanxi Transportation Scientific Research and Development Project under Grant 21-05X; Key Science and Technology Project of Ministry of Transport under Grant 2022-ZD6-079; and the Key Research and Development Program of Shaanxi under Grants 2023-YBGY-120 and 2022QCY-LL-29.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ML | Machine Learning |
| ANN | Artificial Neural Network |
| SVM | Support Vector Machine |
| CRT | Classification Regression Tree |
| DSC | Dynamic Snake Convolution |
| CBAM | Channel Spatial Attention Mechanism |
| DCNN | Deep Convolutional Neural Network |
| BiFPN | Bidirectional Feature Pyramid Network |
| ADSC-U-Net | Attention-Dynamic Snake Convolution U-Net |
| DSC-U-Net | Dynamic Snake Convolution U-Net |
| Att-U-Net | Attention U-Net |
References
- Shi, Y.; Xiang, Y.; Xiao, H.; Xing, L. Joint optimization of budget allocation and maintenance planning of multi-facility transportation infrastructure systems. Eur. J. Oper. Res. 2021, 288, 382–393. [Google Scholar] [CrossRef]
- Nguyen, S.D.; Tran, T.S.; Tran, V.P.; Lee, H.J.; Piran, M.J.; Le, V.P. Deep learning-based crack detection: A survey. Int. J. Pavement Res. Technol. 2023, 16, 943–967. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 2009 17th European Signal Processing Conference (EUSIPCO), Glasgow, UK, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Kamaliardakani, M.; Sun, L.; Ardakani, M.K. Sealed-crack detection algorithm using heuristic thresholding approach. J. Comput. Civ. Eng. 2015, 30, 04014110. [Google Scholar] [CrossRef]
- Sun, L.; Qian, Z. Multi-scale wavelet transform filtering of non-uniform pavement surface image background for automated pavement distress identification. Measurement 2016, 86, 26–40. [Google Scholar] [CrossRef]
- Hoang, N.D. An Artificial Intelligence Method for Asphalt Pavement Pothole Detection Using Least Squares Support Vector Machine and Neural Network with Steerable Filter-Based Feature Extraction. Adv. Civ. Eng. 2018, 2018, 7419058. [Google Scholar] [CrossRef]
- Kyriakou, C.; Christodoulou, S.E.; Dimitriou, L. Smartphone-based pothole detection utilizing artificial neural networks. J. Infrastruct. Syst. 2019, 25, 04019019. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, Y. Research progress of surface defect detection methods based on machine vision. Chin. J. Sci. Instrum. 2023, 43, 198–219. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 6070–6079. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Gemany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Lam, S.K.; He, P.; Li, C. Computer vision framework for crack detection of civil infrastructure—A review. Eng. Appl. Artif. Intell. 2023, 117, 105478. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Zhou, S.; Song, W. Deep learning-based roadway crack classification using laser-scanned range images: A comparative study on hyperparameter selection. Autom. Constr. 2020, 114, 103171. [Google Scholar] [CrossRef]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road crack detection using deep convolutional neural network and adaptive thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 474–479. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic bridge crack detection using a convolutional neural network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Majidifard, H.; Adu-Gyamfi, Y.; Buttlar, W.G. Deep machine learning approach to develop a new asphalt pavement condition index. Constr. Build. Mater. 2020, 247, 118513. [Google Scholar] [CrossRef]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Du, F.J.; Jiao, S.J. Improvement of lightweight convolutional neural network model based on YOLO algorithm and its research in pavement defect detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef]
- Feng, X.; Xiao, L.; Li, W.; Pei, L.; Sun, Z.; Ma, Z.; Shen, H.; Ju, H. Pavement crack detection and segmentation method based on improved deep learning fusion model. Math. Probl. Eng. 2020, 2020, 8515213. [Google Scholar] [CrossRef]
- Liu, J.; Yang, X.; Lau, S.; Wang, X.; Luo, S.; Lee, V.C.S.; Ding, L. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 1291–1305. [Google Scholar] [CrossRef]
- Huyan, J.; Ma, T.; Li, W.; Yang, H.; Xu, Z. Pixelwise asphalt concrete pavement crack detection via deep learning-based semantic segmentation method. Struct. Control Health Monit. 2022, 29, e2974. [Google Scholar] [CrossRef]
- Yuan, G.; Li, J.; Meng, X.; Li, Y. CurSeg: A pavement crack detector based on a deep hierarchical feature learning segmentation framework. IET Intell. Transp. Syst. 2022, 16, 782–799. [Google Scholar] [CrossRef]
- Li, C.; Fan, Z.; Chen, Y.; Lin, H.; Loprencipe, G.; Sheng, W.; Wang, K. CrackCLF: Automatic pavement crack detection based on closed-loop feedback. IEEE Trans. Intell. Transp. Syst. 2023, 25, 5965–5980. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–16 June 2020; pp. 11030–11039. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).