
CEEMDAN-RIME–Bidirectional Long Short-Term Memory Short-Term Wind Speed Prediction for Wind Farms Incorporating Multi-Head Self-Attention Mechanism


Abstract
:1. Introduction
- Aiming at the problem of the large fluctuation in wind speed series with strong nonlinear characteristics, the CEEMDAN of wind speed series is performed to decompose the complex wind speed time series signal into multiple simpler eigenmode functions so that it effectively eliminates the noise and nonlinear perturbations in the signal, improves the robustness of the model to wind speed data noise, and enhances the expressive and generalization abilities of the model;
- The RIME algorithm optimizes the hyperparameters of the BiLSTM model through iteratively updating and adjusting the weights and biases of the BiLSTM layer. This prevents the model from becoming stuck in local optimal solutions and allows it to quickly adjust to changes in the wind speed data, better fit the training data, and enhance its generalization ability;
- A more accurate wind speed prediction model was designed by combining deep learning and machine learning. In order to improve the global feature extraction capability of the model, the BiLSTM model was improved by utilizing the multi-head attention mechanism. The MHSA assigns different attentional weights according to the correlation between the time steps and learns the local and global features in parallel in different representation subspaces. It extracts key information in long sequences and captures time–frequency information and complex dependencies at different scales in wind speed series, which enables the model to capture the dynamic change pattern of the wind speed more accurately, improves the ability to capture wind speed time series data, and enhances the model’s expressiveness.
2. Wind Speed Prediction Research Methodology
2.1. Forecasting Process
- First, wind speed data are collected, followed by data preprocessing and outlier detection to remove anomalies in a timely manner, improving the data’s reliability and stability;
- The dataset is split into training and validation sets. The training set is used to construct the wind speed prediction model by analyzing the historical wind speed data, while the validation set is used to evaluate the performance of the wind speed prediction model;
- The CEEMDAN algorithm decomposes the time series wind speed data to generate multiple intrinsic modal functions (IMFs). The wind speed prediction model is constructed based on the decomposed IMFs;
- The BiLSTM model hyperparameters are automatically tuned via the RIME algorithm, which includes parameters such as the number of neurons in the hidden layer, the learning rate, and the number of training times. The RIME automatically searches the parameter space to quickly identify the optimal parameter combination for the BiLSTM model, which serves as the foundation for constructing prediction models for each component;
- A multi-head self-attention mechanism is introduced based on the BiLSTM model to capture the complex relationship between different subsequence components. Each attention head learns the feature representation of different subspaces, and each subsequence component can be regarded as a different representation subspace;
- The prediction of each modal component is performed using the trained model. By weighting and summing the predicted values of the modal components at different time scales, the overall wind speed prediction is finally obtained. Decomposition and then reconstruction allow the model to capture the trend of the wind speed changes more accurately.
2.2. Fully Adaptive Noise Ensemble Empirical Modal Decomposition
2.3. Bidirectional Long Short-Term Memory Neural Network
2.4. RIME Optimization Algorithm
2.5. The Multi-Head Self-Attention Mechanism
3. Wind Speed Prediction Model Based on CEEMDAN-RIME-MHSA-BiLSTM
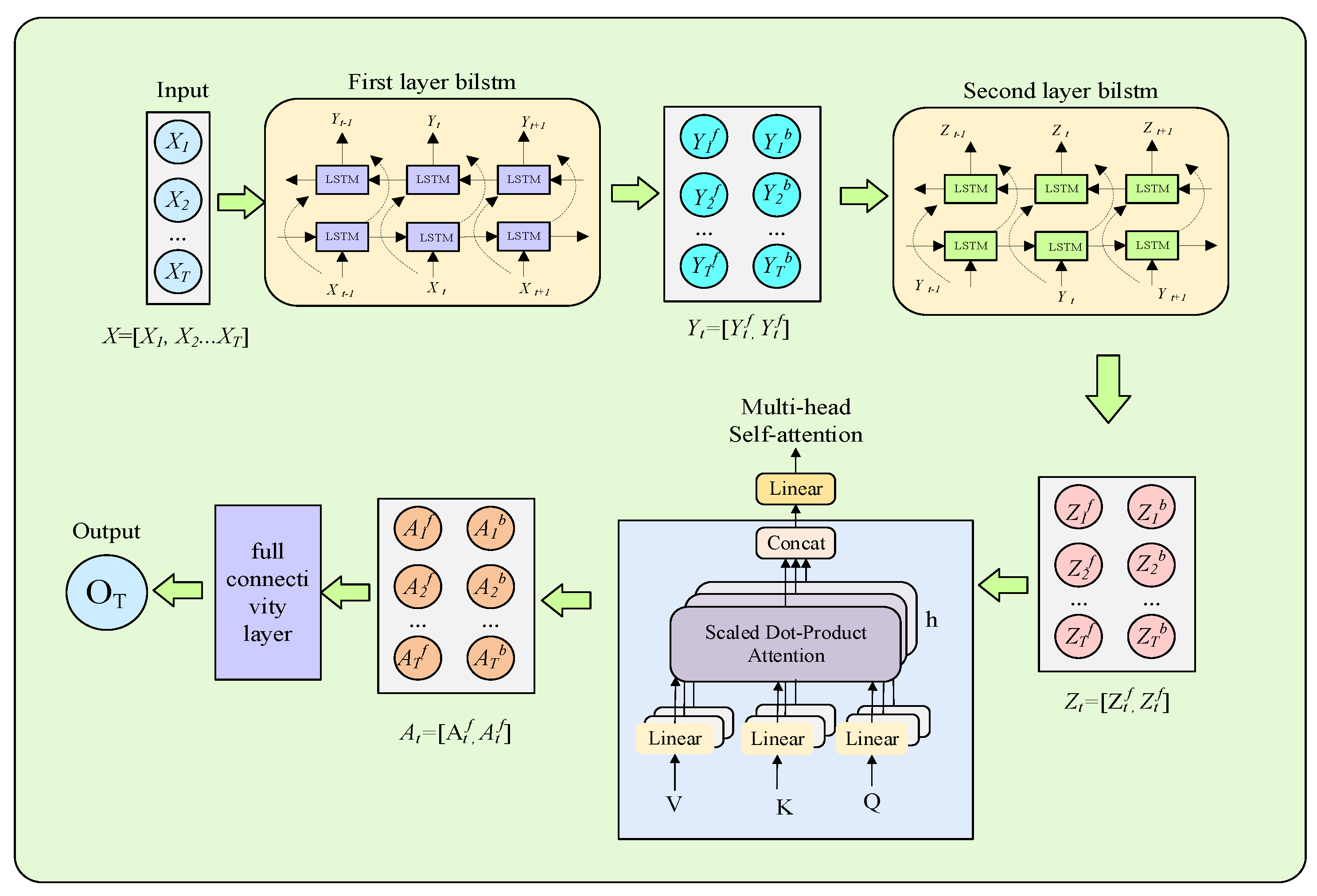
3.1. MHSA-BiLSTM Model Structure
- The decomposed IMFs are fed into the model, and the input layer receives the subseries data (), which represent the eigenvalues of the different time steps in the time series;
- The input data are passed for processing in the first-layer BiLSTM, which has neural units containing both forward and backward LSTM. The first-layer BiLSTM processes the data between the time steps and ; the output of the forward LSTM at time step t is and the output of the backward LSTM is . The outputs of the two directions are concatenated at each time step to form the output of the first layer (i.e., the dimensional vector ());
- The output of the first BiLSTM layer is passed as input to the second BiLSTM layer, which has neural units. This layer further extracts the deeper features of the time series and generates a new output matrix of dimension
- The generated feature matrix goes to the multi-head self-attention mechanism module. This mechanism highlights the most relevant parts of the current prediction by calculating the correlation between each time step and other time steps and assigning them different weights. Outputs of the multiple attention heads are concatenated and linearly combined to generate a weighted feature matrix () that further captures the important dependencies between the time steps;
- Eventually, the feature matrix processed by the self-attention mechanism is passed to the fully connected layer. The fully connected layer maps these high-dimensional features to a final output value (), such as a prediction of the future wind speed. This output value is the prediction made by the model for the input subsequence.
| Algorithm 1. CEEMDAN-BiLSTM with RIME Optimization and MHSA |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2. Projected Evaluation Indicators
4. Experimental Results and Analysis
4.1. Raw Wind Speed Series
4.2. Wind Speed Decomposition
4.3. Validation of Wind Speed Prediction Algorithms
5. Conclusions
- MHSA-BiLSTM, as the core of CEEMDAN-RIME-MHSA-BiLSTM, is good at extracting key information in long series and capturing different time–frequency scale information and complex dependencies in wind speed series, which greatly improves the prediction accuracy of the model. The experimental results show that the KRMSE, KMAE, and KMAPE values of the CEEMDAN-RIME-MHSA-BiLSTM are 0.33, 0.17, and 4.12%, respectively, which are 36% lower in the RMSE, 31% lower in the MAE, and 2.62% lower in the MAPE compared with the EMD-BiLSTM model. Compared with the CNN-BiLSTM model, the RMSE is reduced by 45%, the MAE by 38%, and the MAPE by 3.86%. Compared with the single-model GRU, the R2 and NSE are improved by 28% and 36%, respectively. The combination of the RIME algorithm and CEEMDAN with MHSA-BiLSTM effectively reduces the complexity and improves the performance of long-time wind speed series prediction, which demonstrates the superiority of the combined model in short-term wind speed prediction;
- The original wind speed sequence is decomposed using CEEMDAN, which decomposes the complex wind speed signal into multiple modal components with different frequency characteristics. When the prediction performance of CEEMDAN-BiLSTM is compared with that of the single-model BiLSTM, the and values are improved by 6% and 8%, and the CEEMDAN-BiLSTM exhibits better accuracy. This indicates that the decomposition strategy can improve the prediction accuracy in a limited way, which reduces the noise and nonlinear perturbations in the original data and improves the robustness of the model;
- The RIME algorithm optimizes the pairwise hidden-layer nodes, the number of training times, and the learning rate of the long short-term memory network, which solves the limitations of the traditional BiLSTM model in the parameter selection and significantly improves the prediction performance of the model. According to the experimental results, the optimized BiLSTM model of the RIME algorithm is better than the single prediction model in terms of the RMSE and MAE, which verifies the hypothesis that the optimization algorithm can improve the prediction accuracy of the model;
- CEEMDAN-RIME-MHSA-BiLSTM maintains a stable and highly accurate performance at different wind speeds in different geographic locations and at different time periods. The predictive performances of the KRMSE, KMAE, and KMAPE for the Iowa wind farm in the U.S. are 0.12, 0.08, and 1.09%, respectively, and the R2 and NSE reach 0.99. The predictive performance of the model is greater than those of the other models for any one day in different seasons. As a result, the model proposed in this paper is highly applicable to wind speed prediction in scenarios with different geographical locations and time periods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, N.N.; Xiong, G.J.; Chen, J.L.; Yao, G. Unit commitment of the power system containing wind power via quantum discrete differential evolution. Power Syst. Clean Energy 2022, 38, 89–96. [Google Scholar]
- Wang, D.F.; Zhang, Z.Y.; Gu, Z.Y.; Huang, Y. Wind speed prediction of wind farm based on hybrid copula function and whale optimization algorithm. Electr. Power Sci. Eng. 2022, 38, 33–40. [Google Scholar]
- Sun, P.X.; Wang, J.; Yan, Z.G. Ultra-short-term wind speed prediction based on TCN-MCM-EKF. Energy Rep. 2024, 11, 2127–2140. [Google Scholar] [CrossRef]
- Feng, L.; Zhou, Y.; Luo, Q. Complex-valued artificial hummingbird algorithm for global optimization and short-term wind speed prediction. Expert Syst. Appl. 2024, 246, 123160. [Google Scholar] [CrossRef]
- Xiao, X.Z.; Zi, X.X.; Yu, W.; Gao, X.X.; Huang, X.Y.; Liu, R.Z.; Chen, Y.; Liu, H.X. Research on wind speed behavior prediction method based on multi-feature and multi-scale integrated learning. Energy 2023, 263, 125593. [Google Scholar]
- Jiang, Z.Y.; Jia, Q.S. A Review of Multi-temporal-and-spatial-scale Wind Power Forecasting Method. Acta Autom. Sin. 2019, 45, 51–71. [Google Scholar]
- Sun, R.; Li, Q.; Luo, H.F.; Dou, X.; Deng, Y.H. Wind power forecasting based on error correction using adaptive moving smoothing and time convolution network. J. Glob. Energy Interconnect. 2022, 5, 11–22. [Google Scholar]
- Mark, C.; Liu, S. Distributionally robust model predictive control for wind farms. IFAC-PapersOnLine 2023, 56, 7680–7685. [Google Scholar] [CrossRef]
- Liu, M.D.; Ding, L.; Bai, Y.L. Application of hybrid model based on empirical mode decomposition, novel recurrent neural networks and the ARIMA to wind speed prediction. Energy Convers. Manag. 2021, 233, 113917. [Google Scholar] [CrossRef]
- Liu, X.; Lin, Z.; Feng, Z. Short-term offshore wind speed forecast by seasonal ARIMA—A comparison against GRU and LSTM. Energy 2021, 227, 120492. [Google Scholar] [CrossRef]
- Chen, H.F.; Wang, H.; Li, Y.; Xiong, M. Short-term wind speed prediction by combining two- step decomposition and ARIMA-LSTM. Acta Energiae Solaris Sin. 2024, 45, 164–171. [Google Scholar]
- Tian, Z.D.; Li, J.S.; Wang, Y.H.; Gao, X.W. Short-term wind speed hybrid prediction model based on ARIMA and ESN. Acta Energiae Solaris Sin. 2019, 37, 1603–1610. [Google Scholar]
- Chen, X.H.; Wang, Z.S.; Wu, C. Research on short-term integrated forecasting model of hour-based load in micro-grid based on long-short-term memory network. Chin. J. Manag. Sci. 2023, 1574, 1–12. [Google Scholar]
- Li, Z.; Luo, X.R.; Liu, M.J.; Cao, X.; Du, S.H.; Sun, H.X. Wind power prediction based on EEMD-Tent-SSA-LS-SVM. Energy Rep. 2022, 8, 3234–3243. [Google Scholar] [CrossRef]
- Wang, J.; Niu, X.; Zhang, L.; Liu, Z.; Huang, X. A wind speed forecasting system for the construction of a smart grid with two-stage data processing based on improved ELM and deep learning strategies. Expert Syst. Appl. 2024, 241, 122487. [Google Scholar] [CrossRef]
- Chaka, M.D.; Semie, A.G.; Mekonned, Y.S.; Geffe, C.A.; Kebede, H.; Mersha, Y.; Anose, F.; Benti, N.E. Improving wind speed forecasting at Adama wind farm II in Ethiopia through deep learning algorithms. Case Stud. Chem. Environ. Eng. 2024, 9, 100594. [Google Scholar] [CrossRef]
- He, J.; Wang, X.F. Short-Term wind speed prediction based on ARIMA and LS-SVM composite model. Electr. Eng. Technol. 2023, 52, 30–33. [Google Scholar]
- You, Q. Research on Pridiction of Short Term Wind Speed Based on PSO Optimizing LSSVM. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2022. [Google Scholar]
- Zhu, C.S.; Li, S.H. Random forest regression model based on improved fruit fly optimization algorithm and its application in wind speed forecasting. J. Lanzhou Univ. Technol. 2021, 47, 83–90. [Google Scholar]
- Zhang, J.P.; Yu, X.J.; Chen, D.; Ji, H.P. An improved RCSA-ANN model for the prediction of offshore short-term wind speed. Acta Aerodyn. Sin. 2022, 40, 110–116. [Google Scholar]
- Jonkers, J.; Avendano, D.N.; Wallendael, G.V.; Hoecke, S.V. A novel day-ahead regional and probabilistic wind power forecasting framework using deep CNNs and conformalized regression forests. Appl. Energy 2024, 361, 122900. [Google Scholar] [CrossRef]
- Liu, Z.H.; Wang, C.T.; Wei, H.L.; Zeng, B.; Li, M.; Song, X.P. A wavelet-LSTM model for short-term wind power forecasting using wind farm SCADA data. Expert Syst. Appl. 2024, 247, 123237. [Google Scholar] [CrossRef]
- Zhao, Z.; Yun, S.; Jia, L.; Guo, J.; Meng, Y.; He, N.; Li, X.J.; Shi, J.R.; Ynag, L. Hybrid VMD-CNN-GRU-based model for short-term forecasting of wind power considering spatio-temporal features. Eng. Appl. Artif. Intell. 2023, 121, 105982. [Google Scholar] [CrossRef]
- Duan, J.; Chang, M.; Chen, X.; Wang, W.; Zuo, H.; Bai, Y.; Chen, B. A combined short-term wind speed forecasting model based on CNN–RNN and linear regression optimization considering error. Renew. Energy 2022, 200, 788–808. [Google Scholar] [CrossRef]
- Li, S.Y.; Liu, C. Short-term wind speed forecast based on LSTM by optimized bald eagle search algorithm. Ningxia Electr. Power 2023, 38, 19–24. [Google Scholar]
- Yan, Y.; Wang, X.; Ren, F.; Shao, Z.; Tian, C. Wind speed prediction using a hybrid model of EEMD and LSTM considering seasonal features. Energy Rep. 2022, 8, 8965–8980. [Google Scholar] [CrossRef]
- Ding, R.Q.; Zhou, W.N.; Cheng, H.Y.; Liu, J.L. A novel method based on SSA-BiLSTM networks under deep learning framework for wind speed forecasting. Comput. Digit. Eng. 2020, 48, 45–50. [Google Scholar]
- Liu, T.Y.; Chen, W.; Chang, L.; Gu, T.L. Research advances in the knowledge tracing based on deep learning. J. Comput. Res. Dev. 2022, 59, 81–104. [Google Scholar]
- Zhi, L.H.; Zi, Y.; Xu, K. Combination prediction of wind speed based on variational mode decomposition and neural network. J. Hefei Univ. Technol. 2022, 45, 1505–1510, 1584. [Google Scholar]
- Fu, W.L.; Zhang, X.R.; Zhang, H.R.; Fu, Y.C.; Liu, X.T. Ultra-short-term wind speed prediction based on INGO-SWGMN hybrid model. Acta Energiae Sol. Sin. 2022, 45, 133–143. [Google Scholar]
- Zhang, Y.N.; Shi, J.R.; Li, J.; Yun, S.N. Short-term wind speed prediction based on residual and VDM-ELM-LSTM. Acta Energiae Solaris Sin. 2023, 44, 340–343. [Google Scholar]
- Yi, Y.Y.; Pan, W.H.; Zhao, W.G.; Su, Z.P.; Han, Y. Ultra-short-term wind speed prediction method based on CEEMDAN and BiLSTM-AM. Electr. Meas. Instrum. 2024, 45, 1–9. Available online: http://kns.cnki.net/kcms/detail/23.1202.th.20240617.0943.002.html (accessed on 12 September 2024).
- Phan, B.; Nguyen, T.T. Enhancing wind speed forecasting accuracy using a GWO-nested CEEMDAN-CNN-BiLSTM model. ICT Express 2024, 10, 485–490. [Google Scholar] [CrossRef]
- Xiong, Z.; Yao, J.; Huang, Y.; Yu, Z.; Liu, Y. A wind speed forecasting method based on EMD-MGM with switching QR loss function and novel subsequence superposition. Appl. Energy 2024, 353, 122248. [Google Scholar] [CrossRef]
- Wei, X.; Shi, Q.; Fu, W.X.; Chen, L. Short-term wind speed prediction with CEEMDAN sample entropy and SVR. Water Resour. Power 2020, 38, 207–210. [Google Scholar]
- Song, K.; Yu, Y.; Zhang, T.; Li, X.; Lei, Z.; He, H.; Wang, Y.; Gao, S. Short-term load forecasting based on CEEMDAN and dendritic deep learning. Knowl.-Based Syst. 2024, 294, 111729. [Google Scholar] [CrossRef]
- Liu, F.; Liang, C. Short-term power load forecasting based on AC-BiLSTM model. Energy Rep. 2024, 11, 1570–1579. [Google Scholar] [CrossRef]
- Peng, S.; Zhu, J.; Wu, T.; Yuan, C.; Cang, J.; Zhang, K.; Pecht, M. Prediction of wind and PV power by fusing the multi-stage feature extraction and a PSO-BiLSTM model. Energy 2024, 298, 131345. [Google Scholar] [CrossRef]
- Malakouti, S.M.; Krimi, F.; Abdollahi, H.; Menhaj, M.B.; Suratgar, A.A.; Moradi, M.H. Advanced Techniques for Wind Energy Production Forecasting: Leveraging Multi-Layer Perceptron Bayesian Optimization, Ensemble Learning, and CNN-LSTM Models. Case Stud. Chem. Environ. Eng. 2024, 10, 100881. [Google Scholar] [CrossRef]
- Ma, Y.; Li, J.; Gao, J.; Chen, H. State of health prediction of lithium-ion batteries under early partial data based on IWOA-BiLSTM with single feature. Energy 2024, 295, 131085. [Google Scholar] [CrossRef]
- Ismalle, A.K.; Houssein, E.H.; Khafaga, D.S.; Aldakheel, E.A.; Said, M. Performance of rime-ice algorithm for estimating the PEM fuel cell parameters. Energy Rep. 2024, 11, 3641–3652. [Google Scholar] [CrossRef]
- Abdel-Salam, M.; Hu, G.; Celik, E.; Gharehchopogh, F.S.; El-Hasnony, I.M. Chaotic RIME optimization algorithm with adaptive mutualism for feature selection problems. Comput. Biol. Med. 2024, 179, 108803. [Google Scholar] [CrossRef] [PubMed]
- Pandy, S.B.; Kalita, K.; Jangir, P.; Cep, R.; Migdady, H.; Chohan, J.S.; Abualigah, L.; Mallik, S. Multi-objective RIME algorithm-based techno economic analysis for security constraints load dispatch and power flow including uncertainties model of hybrid power systems. Energy Rep. 2024, 11, 4423–4451. [Google Scholar] [CrossRef]
- Liu, W.; Bai, Y.; Yue, X.; Wang, R.; Song, Q. A wind speed forcasting model based on rime optimization based VMD and multi-headed self-attention-LSTM. Energy 2024, 294, 130726. [Google Scholar] [CrossRef]
- Pourdaryaei, A.; Mohammadi, M.; Mubarak, H.; Abdellatif, A.; Karimi, M.; Gryazina, E.; Terzija, V. A new framework for electricity price forecasting via multi-head self-attention and CNN-based techniques in the competitive electricity market. Expert Syst. Appl. 2024, 235, 121207. [Google Scholar] [CrossRef]
- Chen, Y.; Dono, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Zhang, K.; Zhao, Y.; Bao, Y. Short-term wind speed predicting framework based on EEMD-GA-LSTM method under large scaled wind history. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictive Model | |||||
|---|---|---|---|---|---|
| CEEMDAN-RIME-MHSA-BiLSTM | 0.33 | 0.17 | 4.12% | 0.98 | 0.97 |
| CEEMDAN-BiLSTM | 0.72 | 0.57 | 8.33% | 0.88 | 0.89 |
| RIME-BiLSTM | 0.48 | 0.38 | 5.72% | 0.95 | 0.94 |
| BiLSTM | 0.92 | 0.74 | 11.97% | 0.82 | 0.81 |
| Date | Predictive Model | |||||
|---|---|---|---|---|---|---|
| March 20th (Spring) | CEEMDAN-RIME-MHSA-BiLSTM | 0.33 | 0.17 | 4.12% | 0.98 | 0.97 |
| EMD-BiLSTM | 0.69 | 0.48 | 6.74% | 0.87 | 0.86 | |
| CNN-BiLSTM | 0.78 | 0.55 | 7.98% | 0.85 | 0.83 | |
| GRU | 1.42 | 0.85 | 12.19% | 0.70 | 0.61 | |
| July 9th (Summer) | CEEMDAN-RIME-MHSA-BiLSTM | 0.19 | 0.12 | 2.10% | 0.99 | 0.98 |
| EMD-BiLSTM | 0.64 | 0.45 | 6.43% | 0.90 | 0.88 | |
| CNN-BiLSTM | 0.74 | 0.50 | 7.12% | 0.86 | 0.83 | |
| GRU | 1.21 | 0.78 | 11.12% | 0.72 | 0.65 | |
| November 15th (Fall) | CEEMDAN-RIME-MHSA-BiLSTM | 0.27 | 0.15 | 2.74% | 0.98 | 0.97 |
| EMD-BiLSTM | 0.71 | 0.51 | 6.92% | 0.88 | 0.86 | |
| CNN-BiLSTM | 0.83 | 0.60 | 9.12% | 0.84 | 0.82 | |
| GRU | 1.92 | 1.10 | 15.11% | 0.60 | 0.55 | |
| December 25th (Winter) | CEEMDAN-RIME-MHSA-BiLSTM | 0.21 | 0.14 | 2.71% | 0.99 | 0.98 |
| EMD-BiLSTM | 0.71 | 0.50 | 6.94% | 0.88 | 0.86 | |
| CNN-BiLSTM | 0.75 | 0.55 | 8.13% | 0.85 | 0.83 | |
| GRU | 1.33 | 0.94 | 12.58% | 0.70 | 0.65 |
| Predictive Model | |||||
|---|---|---|---|---|---|
| CEEMDAN-RIME-MHSA-BiLSTM | 0.12 | 0.08 | 1.09% | 0.99 | 0.99 |
| EMD-BiLSTM | 0.54 | 0.32 | 6.17% | 0.93 | 0.92 |
| CNN-BiLSTM | 0.69 | 0.48 | 8.32% | 0.88 | 0.86 |
| GRU | 0.87 | 0.61 | 12.14% | 0.80 | 0.78 |
| Training Set Length | |||||
|---|---|---|---|---|---|
| 50% | 0.37 | 0.23 | 4.72% | 0.97 | 0.96 |
| 60% | 0.43 | 0.34 | 6.57% | 0.94 | 0.94 |
| 70% | 0.33 | 0.17 | 4.12% | 0.98 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Zhang, Z.; Meng, K.; Wang, K.; Wang, R. CEEMDAN-RIME–Bidirectional Long Short-Term Memory Short-Term Wind Speed Prediction for Wind Farms Incorporating Multi-Head Self-Attention Mechanism. Appl. Sci. 2024, 14, 8337. https://doi.org/10.3390/app14188337
Yang W, Zhang Z, Meng K, Wang K, Wang R. CEEMDAN-RIME–Bidirectional Long Short-Term Memory Short-Term Wind Speed Prediction for Wind Farms Incorporating Multi-Head Self-Attention Mechanism. Applied Sciences. 2024; 14(18):8337. https://doi.org/10.3390/app14188337
Chicago/Turabian StyleYang, Wenlu, Zhanqiang Zhang, Keqilao Meng, Kuo Wang, and Rui Wang. 2024. "CEEMDAN-RIME–Bidirectional Long Short-Term Memory Short-Term Wind Speed Prediction for Wind Farms Incorporating Multi-Head Self-Attention Mechanism" Applied Sciences 14, no. 18: 8337. https://doi.org/10.3390/app14188337