Featured Application
Synchromodal optimisation; decision support systems; dynamical transport optimisation.
Abstract
Intermodal freight transport (IFT) requires a large number of optimisation measures to ensure its attractiveness. This involves numerous control decisions on different time scales, making integrated optimisation with traditional methods almost unfeasible. Recently, a new trend in optimisation science has emerged: the application of Deep Learning (DL) to combinatorial problems. Neural combinatorial optimisation (NCO) enables real-time decision-making under uncertainties by considering rich context information—a crucial factor for seamless synchronisation, optimisation, and, consequently, for the competitiveness of IFT. The objective of this study is twofold. First, we systematically analyse and identify the key actors, operations, and optimisation problems in IFT and categorise them into six major classes. Second, we collect and structure the key methodological components of the NCO framework, including DL models, training algorithms, design strategies, and review the current State of the Art with a focus on NCO and hybrid DL models. Through this synthesis, we integrate the latest research efforts from three closely related fields: optimisation, transport planning, and NCO. Finally, we critically discuss and outline methodological design patterns and derive potential opportunities and obstacles for learning-based frameworks for integrated optimisation problems. Together, these efforts aim to enable a better integration of advanced DL techniques into transport logistics. We hope that this will help researchers and practitioners in related fields to expand their intuition and foster the development of intelligent decision-making systems and algorithms for tomorrow’s transport systems.
1. Introduction
The challenges faced by intermodal freight transport (IFT) encompass synchronisation processes between multiple decision-makers, external barriers, and the lack of integration between different modes [1]. The attractiveness and effectiveness of IFT are therefore directly affected by the degree of synchronisation and optimisation across the entire logistics chain. Improving the performance of intermodal transport requires fast optimisation techniques capable of finding solutions for multiple problems simultaneously at various planning levels, taking into account a highly dynamic and uncertain environment.
In general, transport planning problems have been a key area of interest in optimisation science for decades, resulting in a wide range of solution methods. The conventional optimisation techniques from the field of operational research (OR) are known to be computationally expensive, especially when applied in dynamic environments [2]. Furthermore, classical OR mainly focuses on the formulation and solution of isolated combinatorial problems, often abstracted from the complexities of real-world, integrated transport planning applications. For instance, the Job Shop Scheduling Problem (JSSP), a classical combinatorial problem in optimisation science, deals with the efficient allocation of resources to activities under a set of constraints. From the transport planning perspective, JSSP solution methods can be applied in terminals to assign cranes or vehicles to containers, but also in train routing, where a resource denotes a subset of infrastructure elements that are exclusively assigned to a single train at a given time [3]. Obviously, despite different transport planning contexts, the solution methods are often problem agnostic and transferable to different application scenarios. Furthermore, solution methods for operational problems, such as itinerary replanning, demand a combination of different techniques [4]. Today, these problems are mostly handled within the framework of the linear programming paradigm, often encapsulated, and focused on one-dimensional optimisation problems such as the JSSP or the Travelling Salesman Problem (TSP). To improve the overall performance of intermodal transport systems, future optimisation frameworks must be highly integrated, computationally efficient, consider rich context, integrate multiple objectives, and handle uncertainties. Currently, there is a growing effort among scholars to apply learning-based methods into, alongside, or as substitutes for the canonical linear programming paradigm, as these approaches are better suited to the needs posed by modern optimisation tasks [5,6,7,8,9]. In this context, this study aims to address three research questions:
- IFT is a complex, integrated system involving multiple decision-makers with different objectives that need to be optimised in parallel. What are the key operational, tactical, and strategic planning problems in IFT and how can they be mapped to mathematical problem formulations commonly used from an OR perspective? How can these problems be categorised in a structured and systematic manner?
- Learning-based algorithms for combinatorial optimisation problems represent a very promising area for seamless and fast decision-making under uncertainties—a crucial factor for enhancing the overall IFT performance. Over the past five years, research in the area of computer science has converged on methods referred to as Neural Combinatorial Optimisation (NCO), which apply Transformer architecture [10] to combinatorial problems. However, a unified and structured overview of key methods, strategies, and framework setups is lacking in the current State of the Art. This raises the question: what are the key methodological components, algorithm setups and solution strategies in NCO and how can they be structured and abstracted to assist future research in building decision-making tools for integrated transport planning problems?
- The current State of the Art in NCO is highly heterogeneous and primarily involves basic algorithm research with atomic applications to classical OR problems or representative use-cases. To derive insights for more general applications, the question arises: how can the current NCO research be systematised, and what insights can be deduced to support the development of more integrated, generalised NCO frameworks in the future?
To address these questions and explore new directions for advanced optimisation frameworks, this study synthesises recent research from three areas: transport planning in bimodal freight transport (rail and road, referred to as IFT throughout the text), operational research (OR), and Deep Learning (DL) for combinatorial optimisation (referred to as NCO throughout this study). Today, these research streams are mostly conducted in parallel, but are highly interdependent in practice. To the best of our knowledge, despite the rapid growth of NCO applications in computer science, a systematic review from a broad perspective (transport planning, optimisation and DL) involving practical aspects is still lacking.
In the following, the system boundaries together with the key requirements, characteristics, stakeholders, and general operations in IFT will be first defined in Section 2.1. In Section 2.2, we will present a classification of the key optimisation problems in bimodal settings, aiming to identify joint optimisation areas where advanced optimisation techniques may become a key driver in the near future. Section 3 will introduce the methodological preliminaries for the key components and methods and setup strategies needed to design an NCO framework for solving integrated optimisation problems. By organising the State of the Art with respect to the key optimisation domains and framework architectures defined in Section 2 and Section 3, we then extrapolate potential strategies, designs, and future perspectives for advanced NCO frameworks in Section 4. The main findings, challenges, and opportunities for designing NCO algorithms for integrated optimisation problems, together with a discussion on future research directions, will be presented in Section 5. Finally, in Section 6, we will conclude on the objectives and insights drawn from this study.
2. Transport Planning Problems in IFT
In general, each IFT service consists of various discrete transport, loading/unloading, and sorting processes, which occur at different levels and involve multiple decision-makers, sometimes even with conflicting objectives [11]. To establish the system boundaries for this research, this section defines the key decision-makers and their roles and systematically describes the main transport-related processes in bimodal freight transport, as well as the models and objectives, from both a transport planning and optimisation science perspective.
2.1. Intermodal Transport Operations
In the IFT context, the transport process generally involves loading a shipment into a container or transport unit, such as a trailer, which is subsequently transported by truck to a transfer hub connected by railway connections. IFT represents a complex logistics chain that requires careful planning and coordination among multiple stakeholders. Note that, in this study, we only focus on IFT involving two modes, with a freight forwarder acting as the central agent responsible for organising the door-to-door transport. After a shipper delegates freight transport to the freight forwarder, optimising the information and transport flows between multiple stakeholders (such as the road operator, rail operator and terminal operator) becomes necessary. In what follows, we set out a framework for the IFT service and outline the key decisions, operations, and optimisation problems for the transport-related decision entities.
The freight forwarder first selects modes and carriers by comparing intermodal transport services with unimodal road services and develops transport plans. Once the transport service is determined and the transport plan is scheduled, the freight forwarder is notified of any disruptions. A train delay may require the rebooking of road services and, thus, fast optimisation and the rescheduling of planned services. Moreover, the freight forwarder’s decisions on scheduling, modes, the number of containers, and train lengths are impacted by past decisions, which subsequently influence future decisions, resulting in complex and non-linear behaviour. The freight forwarder schedules the road services based on the rail service’s transit time and expected trans-shipment time at the terminals [1]. When scheduling road operations, road operators encounter a complex task of determining the optimal routes and optimising vehicle fleets, considering multiple constraints such as time windows and vehicle capacity, and setting the priority to empty or loaded containers.
The rail operator is responsible for planning decisions regarding the railway network, such as infrastructure, network design, optimal pricing, and train dispatching. The railway undertakings provide the rail haul services according to the schedule of the freight forwarder and the rail operators. The main challenge here is to optimally assign resources such as locomotives, train routes, trailers, and containers. Finally, the terminal operator is responsible for the trans-shipment operations at the terminals such as the classification, consolidation, sorting, and exchange of load units. Although the raw transport costs of multimodal freight transport are generally lower than those for road transport, the handling costs at trans-shipment points make road–rail transport unprofitable for many markets [12]. The coordination and optimisation among all these six stakeholders require simultaneous consideration of multiple objectives such as cost, environmental impact, transit time, service level, delays, and resource utilisation.
In general, planning decisions in IFT can be characterised as long-term (strategic), medium-term (tactical), and short-term (operational). But in practice, companies make decisions for two-time horizons: offline and online [13]. For example, in railway offline decisions involve routing trains in advance, determining the primary path for each train under normal conditions. These decisions are made based on demand, typically every three to six months. The routes and schedules are carefully planned manually, considering regulations, safety measures, demand forecasting, and demand requirements. Online decisions are required when disruptions occur during network operations. As road operations on the road constitute approximately 40% of the total IFT costs [14], the decisions of the road operators are much more critical. Bektas and Crainic [15] categorise the key planning processes in IFT from the operator’s perspective and summarise them under three umbrellas: system design, service network design, and operational planning. In the following, we will briefly describe these three areas and add terminal operations planning as a fourth major area in IFT.
System Design: This mainly encompasses the decisions of the shippers, receivers, freight forwarder, and the road operator regarding the infrastructure and asset planning. This includes network design, network flow planning, and service network design problems [16]. Stakeholders consider long-term planning decisions such as determining the number, capacity and location of terminals, long-term line planning, and assignment of supply and delivery regions. These decisions typically entail the procurements and allocation of physical resources and the selection of geographical locations, spanning a time horizon from several years to even decades [17]. System design models are used to evaluate and rank alternatives for such planning issues. Most of them are often aggregated, static, and deterministic, where the uncertainties are handled based on strategic forecasts within formulated scenarios [15,18,19]. The objectives in this phase are mostly generic, aiming to find the system optimum by minimising the total system cost.
Service Design: Based on the results of the system design phase (i.e., fixed sites, infrastructure, and selection of dispatch/delivery zones, i.e., origin-destination), the freight forwarder plans its transport operations within the available resources and in accordance with the services provided by the rail and road operators. Thus, the main optimisation concern in this phase is to assign and redistribute resources across or within the intermodal network. Specifically, tactical service network design involves determining routes and frequencies, finding the schedule and selecting the modality for each corridor, and assigning transport services given the capacity in that corridor [20,21]. IFT, which involves additional operations such as trans-shipment and consolidation, tends to be slower and less reliable than unimodal road transport, making scheduling with the objective of minimising delays crucial for intermodal networks [22,23]. To operate effectively, decision-makers in this phase are highly dependent on mid-term predictions, such as demand and available resources. Some recent studies introduce stochastic models for service network design problems in order to tackle uncertainties in an integrated manner [24,25].
Operational Planning: This domain includes the near- or real-time decisions of all IFT stakeholders, ensuring efficient use of resources at any given point in time [15]. On this level, the carriers are primarily focused on vehicle routing, fleet management, personnel scheduling, and resource allocation. The routine of the freight forwarders and rail operators consists of delay management and rescheduling the train operations, i.e., dispatching [22]. The road operator redistributes and moves vehicles within the road network. SteadieSeifi et al. [4] classify the operational planning problems in intermodal transport into Resource Management Problems and itinerary replanning. The former class deals with the distribution of the resources and includes problems such as empty loading unit repositioning and fleet management problems. The latter focuses on real-time optimisation of schedules, modal routes, and relevant responses to operational disturbances. Since uncertainties are frequent in operational planning, the solution models usually incorporate high stochasticity and the dynamics of the environment, considering detailed time frames.
Terminal Operations: Terminal operations are highly integrated within service network design and encompass decisions regarding the assignment of resources (e.g., cranes) and sorting (e.g., loading units) under a given capacity and time constraints [15,26]. The objective of the intermodal terminal is to provide a seamless trans-shipment by minimising handling and consolidation costs. Load consolidation at the nodes is particularly important when dealing with heterogeneous cargo and less-than-container loads such as general cargo. Implementing the optimal inventory policy may result in greater vehicle utilisation, impacting routing plans and fleet sizes, which together aim to minimise empty trips or costly empty vehicle repositioning [27]. Planning decisions by the terminal operator are made either offline, using historical information and in coordination with road and rail operators, or online, through operational planning within the terminal. Figure 1 illustrates the main strategic, tactical, and operational planning problems in bimodal transport, highlighting their integration and interaction between three transport decision-makers.
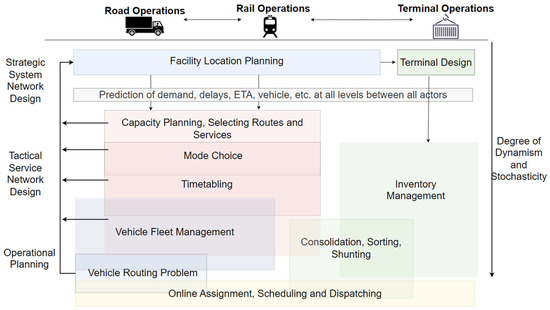
Figure 1.
Overview of key planning problems and areas in bimodal freight transport (Source: Own diagram).
2.2. Optimisation Problems in Transport Planning
In this section, our objective is to establish the link between planning problems described in Section 2.1 and combinatorial optimisation problems from the field of OR where NCO techniques are applicable.
Below, we categorise the most relevant decision problems related to IFT into seven general problem classes. These optimisation problem areas include the following: (i) Network Design Problem [28,29], (ii) Resource Assignment/Scheduling/Dispatching [25,30,31], (iii) Resource Allocation/Rebalancing/Fleet Composition [32,33,34], (iv) Vehicle Routing Problem [24,35,36], (v) Batching/Sequencing Problem [37,38], (vi) Prediction/Forecasting [39,40], and (vii) Online Control Problems with joint decision-making such as inventory management, bidding, and rescheduling [41,42]. We primarily concentrate on the first six problem classes, excluding Online Control and Joint Decision-Making as it relates more to supply chain and logistics science involving negotiations, bidding, storage, ordering, and shipping policies among multiple stakeholders. However, we include the class Predictions and Forecasting as it is closely interconnected with other strategic and tactical transport planning problems, such as the delay and demand prediction for service network design, which are fundamental subproblems in optimisation frameworks for integrated decision-making.
The category Network Design Problem involves optimising the number and locations of various types of facilities (nodes), establishing main transport corridors, and defining routes (arcs). Resource Assignment/Scheduling/Dispatching entails the dynamic assignment, selection, scheduling, and dispatching of activities, jobs, or vehicles to resources. This encompasses activities such as scheduling vehicles, assigning trains to routes in the railway network together with precise arrival and departure times, mode selection, or dispatching vehicles to customers or terminals. Resource Allocation/Rebalancing/Fleet Composition addresses the optimal allocation of resources over time, including the distribution and composition of heterogeneous vehicle fleets and the redistribution of empty vehicles or containers across multiple facilities. Vehicle Routing Problem (VRP) aims to find the sequence of nodes/customers (offline) or predict the next node/customer (online) for vehicles under various constraints. As the VRP naturally incorporates fleet management aspects, such as defining the number and type of vehicles at the starting facility, this class may also cover the Vehicle Fleet Problem (VFP), but is only related to a single facility. Batching/Sequencing Problems encompass the operations concerning the storage, picking, sorting, and processing of a group of resources (such as containers, wagons in shunting yards, or orders) within storage or sorting facilities. The items within each batch are then collectively picked along a single pickup route. In fact, these operations have an impact on vehicle routing and on the entire service network. Prediction Problems involve forecasting future events (e.g., outages), timings (e.g., delays or estimated time of arrival), or future demand. This subclass is critical for adequate network and service design planning. Table A1 provides an overview of the most common optimisation problems related to the IFT and the corresponding variants and formulations from the OR perspective.
3. Methodological Preliminaries
The main methodological components needed to design a universal NCO-based framework for generic application are identified and systematically outlined in this section. Through our study, we refer to NCO as an optimisation framework based on Deep Neural Networks (DNN) and Reinforcement Learning (RL) [43]. In general, two strategies can be derived from the current State of the Art to solve dynamic optimisation problems under uncertainties. One group of researchers focuses on model-based approaches, mathematically modelling stochastic problems, and developing approximation algorithms for dynamic decision-making [44,45,46,47,48]. In particular, Powell [46] advocates that all combinatorial problems can be modelled as sequential decision problems, gathering four ultimate frameworks for solving dynamic and stochastic problems under the umbrella of approximate stochastic optimisation. The second group of researchers in the field of DL develop data-driven methods, applying and tuning DNN models with the state-of-the-art RL algorithms. Based on the State of the Art, we note that the recent advances in NCO are largely attributed to four design patterns: (i) DNN model (i.e., agent policy), (ii) RL algorithm, (iii) agents’ setup, and (iv) simulator setup strategy. The model design is usually established as an encoder–decoder DNN, which generates probabilities over all actions at each step in the agent’s environment. The RL algorithm is then applied to train the encoder–decoder model based on reward, which is either computed directly from the RL environment [49] or is retrieved from an external simulator model. Through our study, we consider the simulator as an external algorithm or external Multi-Agent system plugged into the RL agent to reproduce actions, provide states, and/or calculate rewards. The agents’ setup specifies the number of agent policies and the settings in which RL agents are trained, whether in shared or separate environments. Finally, the simulator setup strategy determines how the RL agent exchanges information with the external simulator. In the following sections, we will examine these design patterns in-depth, providing a comprehensive overview of their setups and features and outline the application domains.
3.1. DNN Model
During the past decade, DL scholars have extensively experimented with various DNNs, including Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM) networks, and Convolutional Neural Networks (CNN) to predict target actions in dynamic systems [50,51,52,53,54]. The breakthrough in this direction was achieved by Vaswani et al. [10], demonstrating that sophisticated encoder–decoder networks can essentially predict the next value based on all previous context information. Today, many state-of-the-art solutions in the field of combinatorial optimisation employ encoder–decoder architecture, which involves training an encoder to learn a meaningful representation of the input problem and a decoder to use this representation to infer a probability over the next actions.
The encoder’s role in the context of combinatorial optimisation is to embed the problem state, including its features (e.g., distance, customer demand, and time windows in context of the VRP), into a fixed vector representation. The encoder thus encodes the input vector into a new extended vector , where is the number of problem state features and is the embeddings size (usually ). Typically, the encoder is represented by multiple feedforward networks containing several Multi-Head Attention (MHA) layers, whose role is to learn a new, extended representation of the input data. The encoder’s output can subsequently be used by the decoder to create a probability distribution for all possible next nodes. Most state-of-the-art encoder–decoder models today rely on the attention or MHA mechanisms at their core [55,56,57]. In general, MHA layers quantify the relationships between two nodes in an embedded space by calculating a dot product. The elements (e.g., node embeddings ) are each multiplied by three matrices: (i) Query , (ii) Key , and (ii) Value , where are trainable parameters, and represents the embeddings of the problem state at timestep . By adjusting the weights , , and during training, the importance of each element (e.g., embedded node) is calculated in relation to itself and to all other problem elements. Concretely, this means that the probability of selecting the next action is derived from the attention score produced by the decoder: , where is the attention score calculated according to [10] as
In Equation (1), represents the softmax function that output the probabilities over the dot product between queries, keys and values, divided by the scaling factor , where indicates the size of the key vector . To learn additional information from the problem context, such as dynamic problem states and implicit information, the context vector can be additionally concatenated and projected in the decoder. In this context, the additional context information from the environment can be added to the vector outputted by the encoder as follows: , where represents a feedforward network (usually with a single hidden layer), defines the problem context added to the learned representation, and denotes concatenation. In fact, by including the context vector we inject additional state information, enabling the encoder–decoder models to capture problem dynamics during the learning episode, such as the remaining vehicle capacity or the remaining number of empty vehicles in VRP.
To prevent the selection of inappropriate actions, practitioners apply masking, a technique which eliminates the probabilities for undesirable actions in the decoder [55,58,59]. In fact, this approach helps to deal with the problem constraints, which are fundamental in the context of combinatorial optimisation. In general, the attention-based encoder–decoder architecture is the State of the Art in many DL applications including prediction and combinatorial optimisation [55,60].
Given that many transport problems, such as network design, vehicle routing, dispatching, and assignment problems, often take the form of graphs, Graph Neural Networks (GNNs) can be applied in the encoder to effectively process input vectors of various sizes [61]. In the graph-based models, node embeddings (e.g., represented by a vector where denotes a batch size and is the number of features) undergo iterative message-passing with their neighbours, effectively capturing structural information about the local neighbourhood [8]. In a graph attention layer, Multi-Head Attention is used to calculate values between node and its neighbourhood in a parallel manner [62]. We particularly outline Graph Attention Transformers (GATs) as a state-of-the-art neural network for practical scenarios, such as forecasting [63] and spatio-temporal predictions [64,65]. For a comprehensive review of the latest GNN advancements, including algorithms, implementations, and taxonomy, refer to the extensive survey by Sun et al. [66]. A typical end-to-end NCO framework with a corresponding simulator for providing rewards to the RL agent is illustrated in Figure 2.
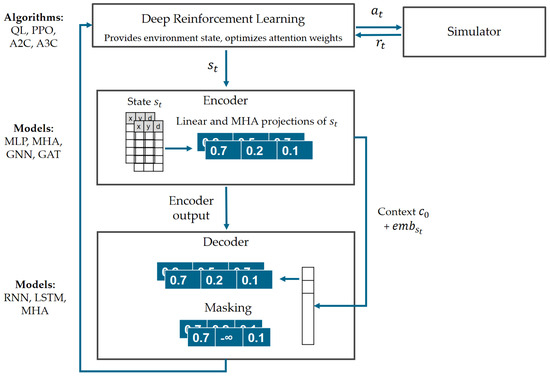
Figure 2.
A prototypical illustration of the NCO framework, including the models typically applied in each NCO design block (Source: Own diagram).
3.2. RL Training Algorithm
DRL is a machine learning (ML) paradigm for learning actions based on observations and feedback information in a dynamic environment. In the context of NCO, DRL is primarily applied to train encoder–decoder Neural Networks (NNs), including MHA layers—usually referred to as a policy network for action selection. The RL algorithms rely on a Markov Decision Process (MDP), representing the problem environment as a tuple of state , action , reward , and transition : The state at each timestep forms the input vector for the policy network. The role of the RL training algorithm is to calculate the loss L—the reward difference between the previous state and the current state after taking action . The backpropagation of the loss enables the encoder–decoder networks to learn a behaviour that maximises the reward.
For example, in the classical VRP using RL, the reward is defined as a negative tour length and the parameters are adjusted during the training, where is a vector of all trainable parameters in embedding, encoder–decoder and attention weighting matrices (e.g., ).
Equation (2) represents the objective function, where is the policy parameters and s defines the current state of the environment. The objective is to maximise the expected reward obtained by following policy . The expected reward is denoted by , and is the reward obtained by executing policy and taking the action in state . Equation (3) denotes the policy parameters optimised by RL that maximise objective function .
In fact, the design choice of DRL algorithm is very problem-specific. Generally, the first choice lies on whether we want to train the policy network directly (policy-based learning) or can evaluate and learn from every state–action tuple (value-based learning or Q-Learning). Policy-based RL is more suitable for problems with a large state and action spaces due to the fact, that it only updates parameters of the policy NN. In contrast, value-based RL learns values for each state or state–action pair, which can lead to insufficient convergence when dealing with vast state–action spaces. Although value-based algorithms traditionally found their application in control problems, such as inventory and supply chain management (see [67]), transport researchers have also applied Q-Learning in train scheduling and dispatching, as demonstrated by [68,69,70]. We note that the majority of the studies in the current State of the Art use hybrid approaches called Actor–Critic (e.g., Proximal Policy Optimisation (PPO), REINFORCE) where policy update (actor) and value-based learning (critic) are performed in a feedback loop. Thus, the goal of (i) an actor network is to estimate the probability of the next action in each state, and (ii) a critic is to predict the reward (value) from a given state. To reduce the variance during training, the researchers subtract a so-called baseline from the loss (i.e., the best value so far, produced by the previous policy [55,56]. For instance, Adi et al. [71] subtract , an additional policy network with less frequent updates, from the current value function to stabilise training. For a comprehensive overview of DRL application in the field of transport, we refer to [72,73,74,75].
3.3. Agents’ Setup
The central challenge in IFT optimisation is to design a model that integrates heterogeneous agent behaviour, capable of reflecting multi-level decision-making processes, on different time scales and with different objectives. For instance, after a shipper decides to send cargo to a receiver, the rail, road, and terminal agents need to schedule their operations to ensure seamless transport. In this context, hybrid approaches are required to model multiple agents interacting together. Generally, designing the operational, highly dynamic transport problem as Multi-Agent RL (MARL) results in a nonstationary environment, reducing convergence and requiring more training steps. From a modelling standpoint, designing such systems offers two choices: either implementing single-agent RL with a centrally trained policy (e.g., [76]) or Multi-Agent RL, where agents learn heterogeneous or shared policies (e.g., [77]). The former approach may result in a larger state–action space, but the training is less computationally demanding. In contrast, the latter approach involves only formulating state actions for each agent, but this also leads to additional dynamics and therefore hampers convergence [78]. The decision regarding the policy update, whether to update only one model with all observations from the environment or to update multiple encapsulated models independently with partial information, is problem-specific and needs to be evaluated at the beginning. Alternatively, agents can operate and gather information independently in the environment, using a shared policy. Centralised Training Decentralised Execution (CTDE) MARL demonstrates a good ability to address highly dynamic Multi-Agent environments, enabling agents to act heterogeneously based on the global problem context [79,80,81]. A further challenge in MARL is to assign rewards to individual actions among multiple heterogeneous agents (credit assignment problem). Due to the collective decision-making, it is often unclear how to design and distribute rewards among many independent agents. Consequently, sophisticated reward distribution techniques are needed. We refer to the following studies that highlight reward shaping and reward distribution as critical steps: [77,82,83].
More recent studies in this field explore Hierarchical Reinforcement Learning (HRL), where an agent (upper policy) at the strategic or tactical level learns to delegate tasks to lower-level agents (lower policies) at the operational decision level. HRL shows great potential, especially for integrated optimisation problems as it can naturally model the asynchronous decision-making between multiple agents [84]. Figure 3 illustrates three main strategies for the MARL setups, which can potentially model integrated decision-making in IFT.
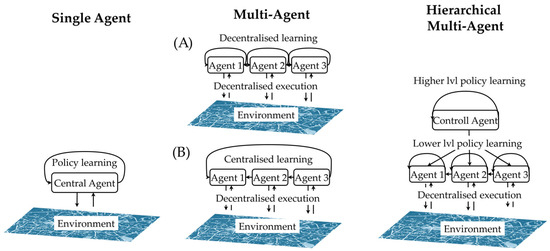
Figure 3.
Three agent setups for solving integrated sequential decision problems with Multi-Agent Reinforcement Learning (MARL). Single agent with centralised learning (left), Multi-Agent with decentralised learning (centre, (A)) and centralised (centre, (B)), and Hierarchical Multi-Agent (HRL) (right). (Source: Own diagram).
3.4. Simulator Setup Strategies
Given the complexity of transport systems, simulators are widely applied. Based on [85], the following three strategies for combining NCO with simulators can be highlighted: (i) end-to-end, where the entire problem is built and solved by NCO independently; (ii) learning-to-configure, where the DRL algorithm parametrises the external model, i.e., computes parameter for an optimisation algorithm and ML alongside optimisation algorithms; or (iii) learn-to-improve, where an algorithm or heuristics iteratively calls the ML model to improve the outcomes.
End-to-end: The first strategy requires the model and the agent implemented in the same environment. Here, the solution search is completely controlled by the RL agent. The simulator, if needed, is used solely to execute actions and provide the reward. This setup strategy is well-suited for one-dimensional combinatorial problems or problems with a comparatively low degree of interdependencies between decision-makers (VRP, JSSP, Facility Location Problem (FLP), network optimisation, prediction), where the model and the RL algorithm can be formulated as a system in one software environment. The end-to-end approach benefits from improved efficiency by treating the entire system as a single entity, allowing for direct learning from input to output without intermediate steps. However, it requires more expert knowledge and a deep problem understanding due to the need to model the entire transport problem as a dynamic MDP, usually formulated in line with the principles outlined in [49].
Learn-to-configure: The second strategy focuses on leveraging DRL as an oracle in scenarios where the environment is already implemented and building a new environment is costly. Using DRL to parametrise the simulator or even to select heuristics can help to encapsulate the entire problem logic and yield an optimal partial solution for each timestep. In this case, the algorithm being optimised is treated as a black box. Here, the DRL model can provide the state (e.g., demand and customer locations at timestep t) and the action (e.g., the number of vehicles or the set of parameters for the simulator). Biedenkapp et al. [86] define this technique as a Dynamic Algorithm Configuration (DAC). When the simulation environment for a certain transport problem is used, the DAC can dynamically determine the set of input parameters (e.g., optimal vehicles, facilities, demand points) for each instance.
Learn-to-improve: The third strategy is well suited for large-scale, one-dimensional combinatorial problems where traditional heuristics are computationally expensive and solution reliability is crucial. By applying DRL, the solution search process conducted by an external algorithm can be enhanced. In this case, the simulator provides an initial solution to the DRL model, which then executes the search and applies search operators based on the rewards received. The learn-to-improve paradigm consumes more computational time but can obtain higher-quality solutions [87]. Figure 4 illustrates these three scenarios in which the simulator is deployed alongside the NCO.
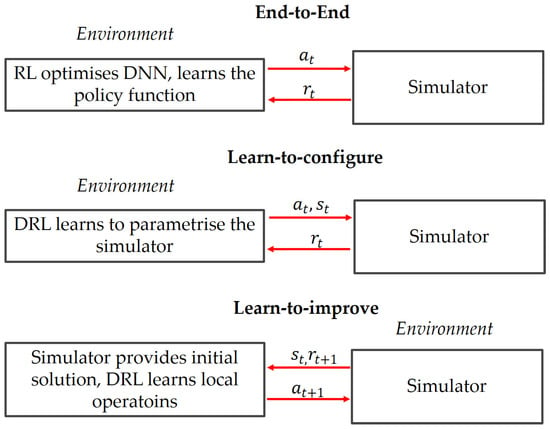
Figure 4.
Illustration of the three NCO implementation strategies (Source: Own diagram).
4. Overview of the State of the Art in the Field of NCO
In the following, we provide an overview of the studies published between 2018 and 2023 related to the six problem classes introduced in Section 2.2 and NCO. We design the main search query for Google Scholar using the following syntax: PUBLICATION NAME (“Arxiv OR Transport OR Logistics”) AND TITLE_WORDS (“(reinforcement OR learn OR neural) AND (freight OR transport OR logistics)”) AND KEYWORDS (problem class name from Table A1). In the first step, we include publishers from the fields of logistics, transport or computer science. In the second step, we narrow the list by including publications that relate to both NCO and transport logistics. Afterwards, we use the problem field keyword from Section 2.2 to further narrow the search space and review selected studies associated with the methods outlined in Section 3. In addition, we also analyse studies from adjacent reviews such as [73] and include articles from the manual search. The reason for the manual search was the broad range of possible topics related to the NCO. For example, Kerkkamp et al. [88] propose RL optimisation of the sewer network. Although this study is not directly related to the transport field, we chose to include it due to its methodological transferability. We explicitly exclude studies having main focus on topics such as signal controlling, supply chain, robotics, navigation, public transport, maritime logistics, and Multi-Agent bidding. This literature review also does not cover the classical RL methods such as simple Q-Learning from the control theory (see, e.g., [70,89]) as our research aims to explore more advanced NCO methods, which usually rely on Transformer architecture. Below, the surveyed studies are organised according to the problem classes outlined in Section 2.2.
Strategic network optimisation in the fields of OR and computer science is traditionally approached through discrete graph optimisation methods. In the reviewed State of the Art, only two studies address network optimisation using NCO. Zhu et al. [90] apply hybrid end-to-end DRL, where an Actor–Critic RL with Graph Convolutional Networks (GCNs) policy first finds the maximum capacity for the web links, and then an Integer Linear Programming (ILP) is applied to improve the final network solution. The authors emphasise that RL-based optimisation offers a more natural solution approach than traditional local search heuristics, as it can generate decisions based on global information and consider delayed outcomes. Kerkkamp et al. [88] propose a DRL framework based on GCNs for dynamic pipe network optimisation, where a centralised agent learns a maintenance plan based on network features for a 100-year period.
Resource assignment, scheduling, and dispatching class covers a broad range of problems related to the railway network and terminal processes. Since this class of problems can be formulated as a sequential decision problem (e.g., Flexible JSSP), the encoder–decoder and end-to-end methods find a natural application here [76,91]. Ren et al. [92] and Han and Yang [93] employ an encoder with LSTM/RNN and a decoder with attention to produce sequence-to-sequence solutions. Oren et al. [94] develop an end-to-end approach that can operate on problems with varying state and action sizes. They first encode the trajectories as a graph (with states as nodes and actions as edges) and process it using a GNN. Subsequently, Q-Learning is employed to select actions (edges). The learning-based approach outperforms benchmark heuristics when applied to various combinatorial optimisation problems, such as Capacitated Vehicle Routing Problem (CVRP) and Job Scheduling. Ni et al. [87] encode a scheduling plan (Gantt chart) as a multi-graph and apply a learn-to-improve strategy, where PPO with a GNN learns search operators to update the MIP solution. A reward shaping technique is employed to avoid local minima and ensure fair reward distribution among selected actions. Trained and evaluated on industrial warehouse scheduling data, the model effectively assigns orders to machines during inventory management, producing high-quality solutions and demonstrating robust generalisation. Multi-Agent (MA) cooperative behaviour plays a crucial role in resource assignment, scheduling, and dispatching. Chen et al. [82] utilise Multi-Agent Reinforcement Learning (MARL) to dispatch couriers with stochastic tasks, assigning each free courier to a task and selecting service times to fulfil requests in a grid world. In order to facilitate the cooperation between agents, the authors additionally introduce reward shaping, i.e., assigning weights to courier’s reward function, determining the extent to which they prioritise their individual rewards versus the average reward of all couriers. Chen et al. [79] propose QMIX, a Multi-Agent model-free DRL framework for the integrated dispatching problem. QMIX is a CTDE approach for environments that require coordinated behaviour among multiple decentralised actors [95]. The dispatch policy determines the sequence of dispatch decisions for each truck, which forms the route network of the fleet.
Resource Allocation/Redistribution and Fleet Composition Problems arise in scenarios, where end customers are served by a fleet of vehicles, and in redistributing vehicles across the network to balance the overall vehicle capacity based on the predicted demand. Advanced end-to-end strategies, such as MARL and HRL receive considerable attention in this area [96]. Ahn and Park [97] develop a decentralised MARL approach to redistribute idle vehicles in a manufacturing system between defined zones, where each zone acts as an agent. The authors address cooperative learning by utilising GCNs. Pan et al. [98] use HRL to optimise pricing schemes for vehicle repositioning in a grid world environment. They decompose actions into temporal and spatial components, with sub-Q-agents assigned to grid cells. Xi et al. [99] design an adaptive HRL solution for the dynamic vehicle redistribution problem. They employ a three-level hierarchical RL approach, dividing the problem into a centralised manager and coordinators. Long short-term memory (LSTM) networks are integrated to predict future demand/supply, and a mixed shared reward is designed to promote cooperation.
In the intermodal context, batching and sequencing problems have a decisive impact on the routes and transport schedule of the road and rail operators. Cals et al. [100] design the order selection process (batch and picking) in a warehouse by treating it as a Semi-Markov Decision Process (SMDP) so that the next step occurs continuously, i.e., as soon as a new order enters the system. Beeks et al. [83] use a similar DRL architecture to find a trade-off between two objectives, time and costs, for an online batching assignment problem. Hottung et al. [101] propose a Deep Learning Heuristic Tree Search, a supervised learn-to-improve strategy for a Container Pre-Marshalling Problem, where the DNN generates probabilities to move containers.
The State of the Art on VRP is dominated by end-to-end NCO techniques. As the most fundamental, this domain has become a playground for many computer scientists experimenting with learning-based optimisation techniques. Vinyals et al. [57] introduce a Pointer Network, attempting to solve the Travelling Salesman Problem (TSP) through supervised learning. Nazari et al. [102] enhance Pointer Networks with embedding and RL, enabling VRP solutions. Khalil et al. [103] use graph embedding and Q-Learning for TSP tours, while Joshi et al. [104] employ a GCN by means of supervised learning to predict edges in TSP. Transformers, introduced by Vaswani et al. [10], replace RNNs in sequential problem solving, including the TSP and VRP. Kool et al. [55], Deudon et al. [56], Li et al. [58], and Li et al. [105] develop advanced models for solving VRPs incorporating encoder–decoder and RL. Falkner and Schmidt-Thieme [106] propose an advanced encoder–decoder model for Capacitated Vehicle Routing Problem with Time Windows (CVRP-TW), extending the encoder with rich context embedding. Foa et al. [107] argue that a Convolutional Network can be suitable in cases where the adjacency matrix of a graph is structured similarly to the pixel image. Li et al. [108] solve the Dynamic Pickup and Delivery Problem (DPDP) with online generated orders. The environment of the dynamic dispatching problem is abstracted as a graph, where each vehicle is a node. Then, the attention network is used to calculate the relationships between the vehicle and all the neighbouring vehicles considering spatial and vehicle features. In this study, the authors tackle the stochastic environment by designing a spatial–temporal network, which can predict the demand for each factory at timestep . Ma et al. [109] tackle the stochasticity in the online Large-scale DPDP by utilising the order buffer, where the n-orders are first cashed and then provided to the policy network designed as HRL. Based on the upper-level policy, the agent decides on the orders to be served from the cash buffer. The lower-level agents aim to serve these orders by assigning them to the most appropriate vehicles and constructing routes similar to classical heuristics. These agents apply four swap actions (inner-exchange, inner-relocate, inter-exchange, and inter-relocate) on the graph nodes of the constructed routes by utilising REINFORCE and GNNs. Thus, we refer to this model as learning-to-configure. We note that this study is among the first to introduce the HRL solution for the real-world large-scale DPDP. Alternatively, Wu et al. [110] adopt a similar architecture to [55], but instead of selecting the next node, two nodes are permuted. To preserve positional information within the tour, authors propose sinusoidal positional encoding. Da Costa et al. [111] extend this approach with dual encoding and pointing attention, allowing faster convergence to a near-optimal solution in TSP and CVRP. Hottung and Tierney [112] combine Ruin-Recreate and neural optimisation for CVRP, improving solution search by leveraging local information. We refer to these studies as learn-to-improve. Li et al. [113] introduce a learn-to-delegate technique for large-scale VRP, integrating attention neural networks and a Multi-Head Attention and VRP solver. This technique demonstrates promising potential for nested problems such as the Location Routing Problem (LRP) or vehicle fleet optimisation with integrated routing problems.
There is a notable trend in the prediction and forecasting domain towards the utilisation of the GNN alongside attention mechanisms. Earlier studies attempted to combine LSTM and Convolutional Neural Network (CNN) techniques to capture temporal and spatial patterns [114]. Hassan et al. [115] use RL to adjust weights in different time-series models to forecast freight demand movements over short- to long-term horizons. More recently, researchers have successfully applied GCNs and attention mechanisms to predict the dynamics of spatial–temporal sequences [116,117]. For instance, Li et al. [23] develop a sophisticated Graph Attention Network (GAN) and supervised learning approach to predict train delays. Interestingly, the authors first formulate the dynamic railway system as a multigraph, where each timestep is a graph containing nodes representing running trains and terminals. Subsequently, they leverage a GNN to dynamically predict delay propagation in the railway network.
From the presented State of the Art, it is evident that classical combinatorial optimisation problems, such as VRP and scheduling problems, are primarily treated using end-to-end attention-based encoder–decoder architectures, which are then trained with Actor–Critic DRL. The most common strategies among researchers to avoid the curse of dimensionality and achieve stability during training include masking actions in the decoder, applying baseline policies, and pruning the state–action space. However, only a few studies explicitly employ learn-to-configure or learn-to-improve paradigms. Zhao et al. [118] use RL to create an initial solution for heuristics, while Ma et al. [109] generate initial solutions using an upper policy, which is then utilised by lower heuristic-based agents to dispatch vehicles in dynamic pickup and delivery problem with MARL. Applying hybrid strategies for complex nested problems appears promising for integrated problems, such as vehicle fleet optimisation with dispatching and integrated vehicle routing. Figure 5 and Table A2 (Appendix B) provide an overview of the reviewed studies, classified according to six major problem classes and their architectural and methodological structures.
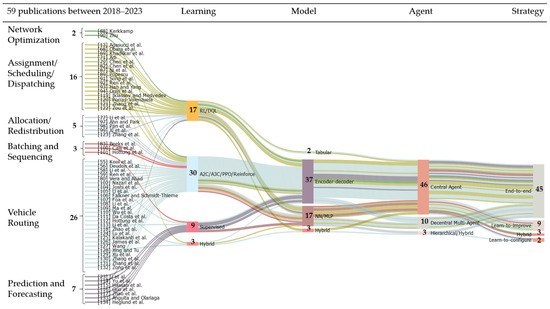
Figure 5.
Fifty-nine reviewed publications between 2018 and 2023 related to the six optimisation classes defined in Section 2.2: Network Optimisation [88,90]; Resource Assignment/Scheduling/Dispatching [13,68,69,71,79,82,87,89,91,92,93,94,119,120,121,122]; Resource Allocation/Balancing/Fleet Composition [77,97,98,99,123]; Batching and Sequencing [83,100,101]; Vehicle Routing Problem [55,56,58,59,80,102,104,105,106,107,108,109,110,111,112,113,118,124,125,126,127,128,129,130,131,132]; Prediction and Forecasting [23,114,115,116,117,133,134]. The reviewed studies were classified according to the learning algorithms, applied model architectures, agent environment, and simulator setup strategy (Source: Own diagram).
5. Discussion
As evident from the reviewed State of the Art, the adoption of encoder–decoder networks in combinatorial problem solving has already resulted in significant advancements in the field of optimisation. The ability of advanced encoder networks (e.g., GNNs and GANs) to process a rich problem context and the fact that they are no longer limited by the fixed input size, suggests that more general frameworks for different combinatorial problems are on the horizon. In fact, the first attempts to develop universal end-to-end NCO frameworks for different types of optimisation problems are already underway (see [135,136,137]).
Nevertheless, strategic system design problems, such as network planning, identification of the customer regions, and strategic mode choice, have not yet been extensively addressed by NCO research. Data-driven solutions, such as RL, have their roots in optimal control, and, as a result, the application of NCO on static, sparse networks appears to be over-sophisticated for the optimisation community. However, problems involving integrated system design and operational planning, such as the dynamic Location Routing Problem (LRP) (see, e.g., [138]), are well-suited candidates for learn-to-improve NCO or HRL. In the first case, simple optimisation heuristics could be used alongside the NCO model. At each step, the algorithm provides suitable terminal locations, while the NCO agent calculates transport costs for each partial solution (e.g., routes). For large LRP problems, replacing the optimisation heuristics with another, higher-level RL agent may be feasible. This would result in an HRL approach for an integrated system design problem. In fact, end-to-end strategies are more suitable for dynamic, online sequential problems (e.g., routing, sorting at terminals, scheduling, and resource assignment) because agent policy constructs decision sequences based on input within the same environment. In contrast, the hybrid learn-to-configure strategy indicates applicability in practical scenarios involving nested problems, such as vehicle fleet optimisation with an integrated assignment to trans-shipment terminals and vehicle routing, where complex sub-problems can be effectively encapsulated within an individual simulation environment. A learn-to-improve strategy is more suitable for strategic and static problems, or for problems requiring fast and precise solutions, where the solution search is guided by an exact method. Generating the initial solution with a simulator and applying NCO to accelerate local search yields more stable and reliable results.
The combination of service network (e.g., determine modes, vehicles or service times) and operational planning problems (e.g., routing), together with terminal-related batching and sequencing (e.g., assign cranes to containers), can be approached using both end-to-end and learn-to-improve strategies with either a single central agent or a Multi-Agent NCO setup. Scheduling, dispatching, vehicle routing, and sorting represent typical sequential decision problems in service and operational planning. If the resources are not redistributed (i.e., optimisation focuses on a single terminal/train/vehicle), a central NCO agent would be a good design choice. If resources are redistributed and optimisation occurs across multiple locations or vehicle fleets simultaneously, MARL approaches such as Qmix [79] or HRL [99] with a central upper policy and decentral lower agents can be employed. However, designing decentralised MARL with central policy poses particular challenges. The State of the Art contains limited insights regarding the established ways to rebalance rewards from multiple agents in order to achieve reasonable interaction in a shared environment. Another interesting practical use-case is optimising transport plans for a service network modelled as a sequential decision process on graphs, where each node represents either a train station, trans-shipment terminal, or port [70]. A synchromodal matching platform for intermodal networks demonstrates the most practical use-case for NCO today, allowing freight forwarders or fourth party logistics (4PL) providers to create sustainable and reliable transport services.
Future Perspectives on NCO
Prediction and forecasting: In future logistics services, prediction and forecasting will play a critical role, especially for designing integrated AI-based decision support systems and smart digital twins. We particularly highlight the ability of GNNs and GANs to embed, process, and predict spatial and temporal information (e.g., vehicles, demand, delays). Today, Graph Attention Transformers (GATs) are already widely used in various forecasting scenarios such as traffic flow predictions [63,64,116,139], stocks [140], and time-series [60,66]. For future optimisation frameworks with NCO, GATs can be employed either as an upper policy in HRL or in a learn-to-configure setup, where the central agent predicts demand and parametrises the simulator for route planning based on the forecasts.
Need for dynamic encoder–decoders: Current encoder–decoder architectures do not directly consider the transition function of the RL agents. In complex environments, each action in step t can implicitly modify other related state information in this environment. For example, after taking action in step , the environment changes dynamically (e.g., the capacity, demand, and time windows of the customers reduce), but these dependencies are only reflected in the mask and additional context embeddings. Embedding the entire graph at the beginning of each episode may reduce solution quality [119,141]. Additionally, once the state information has implicitly changed in state t + 1, the decoder should not rely on embeddings from the previous state t. Boffa et al. [142] suggest that current decoders often overlook this dynamic context information and enhancing decoders will lead to better solution quality.
Accelerating training and increasing solution diversity: Another key factor for achieving better NCO performance, and hence contributing to the development of smart decision support systems, is the training efficiency of the agents’ policies [136]. Xin et al. [141] state that, for most combinatorial problems, the diversity of solutions is critical for the overall performance. While some authors rely on parallel computing and fast matrix multiplication [137,143], other scholars enhance NCO training by developing algorithms with a parallel local search that starts from multiple problem states simultaneously. Proximal Optimisation with Multiple Optima (POMO), proposed by Kwon et al. [144], enables policy training starting from multiple different nodes in parallel (learning on trajectories at each timestep), which effectively enhances the solution search (a Multi-Greedy decoding). However, this approach has only been validated on classical one-dimensional sequential decision problems, like sorting and routing problems, but it is potentially a suitable choice for advanced NCO frameworks with upper and lower policy training [136,145].
Lack of safety, transparency and explainability: Although the majority of the reviewed studies advocate for achieving near-optimal solutions while significantly reducing computational time, a notable drawback of learning-based algorithms is the lack of safety, transparency, and explainability with respect to the decisions (actions) taken. Although building real-world safety-critical systems in the RL domain receives much attention [146,147,148], these efforts mostly address the selection of actions from a defined set of safe actions. In general, evaluating and proving the optimality of the learned policy is challenging, making the practical application of NCO techniques currently questionable. Among the reviewed literature, only Beeks et al. [83] address this issue by proposing decision trees to trace and evaluate actions. To this end, the practical application of NCO paradigms in intermodal scenarios appears limited. Garmendia et al. [149] state that while NCO cannot currently compete with classical metaheuristics in terms of the solution quality and practicability, this is primarily linked to its early stage of development. To achieve further practical advancements, there is a strong need for interdisciplinary research and closer collaboration between the fields of transport and NCO.
6. Conclusions
The central objective of this study was to systematise and synthesise recent research from the fields of transport logistics, optimisation, and DL, focusing on the integrated problems commonly occurring in IFT. Currently, the majority of new DL and transport optimisation models are developed within their own disciplinary domains, resulting in a fragmented perspective and a lack of necessary synergies. Overcoming these limitations could enable future research to design high-performance, intelligent solutions, and smart decision systems that support sustainable freight transport.
The presented study first established the framework for the IFT system, systematically outlining its main operations, decision entities, and problems that need to be addressed in an integrated manner to foster IFT operations and services. From this analysis, we inferred six relevant problem classes and associated them with common OR problems, which are often addressed in isolation. Through the methodological preliminaries, the key principles, strategies, architectures, and algorithms for designing advanced learning-based algorithms were outlined. Finally, an in-depth review of the State of the Art, with a focus on transport-related NCOs and the subsequent discussion was conducted, aimed to derive insights and articulate key principles for designing advanced learning-based frameworks for transport systems in the 21st century.
Author Contributions
Conceptualization, E.D.; methodology, E.D. and P.J.; software, E.D. and P.J.; validation, E.D. and C.K.; formal analysis, E.D.; investigation, E.D.; resources, C.K.; data curation, E.D.; writing—original draft preparation, E.D.; writing—review and editing, E.D. and C.K.; visualisation, E.D.; supervision, C.K.; project administration, C.K.; funding acquisition, C.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the German Federal Ministry for Digital and Transport (BMDV) as part of the mFUND funding initiative “Hyper networks of German Logistics—Using the potentials of hyper networks in freight transport and logistics—HEGEL” under the funding number 19F2201A.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Appendix A

Table A1.
Transport problems and their OR formulations in transport science categorised into six main problem classes related to IFT operations, defined in Section 2.2. We additionally present the most conventional solution techniques from the optimisation point of view associated with these problems.
Table A1.
Transport problems and their OR formulations in transport science categorised into six main problem classes related to IFT operations, defined in Section 2.2. We additionally present the most conventional solution techniques from the optimisation point of view associated with these problems.
| Optimisation Problem Class | Transport Problems | Related Problems in OR and Computer Science | Solution Techniques |
|---|---|---|---|
| Network Optimisation | Network/infrastructure planning, facility location planning, strategical network flow planning, long-term rail-corridors and terminals, assignment of delivery zones or customers to facilities. | Linear Assignment Problem (LAP) and Quadratic Assignment Problem (QAP), Facility Location Problem (FLP), Location Routing Problem (LRP), Hub-Location, Arc-Routing Problem, Clustering, Hub location Problem, Covering, Centre and Median Problem. | Graph optimisation, MIP/MILP, heuristics and metaheuristics, econometric models, aggregated transport models, land-use models, Multi Criteria Decision Analysis (MDCA), analytical methods, Geographic Information System (GIS). |
| Resource Assignment/Scheduling/Dispatching | Capacity planning, mode selection, train routing, occupation time scheduling, timetabling (offline) and train dispatching (online), locomotives/vehicles/containers assignment, drayage scheduling and assignment of pick-up and delivery points. | Linear Assignment Problem (LAP), Dynamic Quadratic Assignment Problems (DQAP), Job-Shop Scheduling and Flexible Job-Shop Problems, Resource Assignment, Scheduling and Allocation Problems, Shipping Point Assignment, Network Flow Problem. | Time-space network, graph optimisation, analytical methods, MIP/MILP, heuristics and metaheuristics, approximate dynamic programming, discrete event simulation, simple dispatching rules (e.g., First in First Out), behavioural models, Multi-Agent Systems (MAS). |
| Resource Allocation/Redistribution and Fleet Composition | Empty/idle vehicle/container repositioning, vehicle-redistribution, vehicle fleet composition at multiple locations, vehicle fleet management | Linear Assignment Problem (LAP), Vehicle Fleet Optimisation, Vehicle Repositioning, Vehicle Fleet Composition. | Discrete event simulation, MIP/MILP, graph optimisation, heuristics and metaheuristics. |
| Batching and Sequencing | Consolidation/shunting/sorting or container/wagons, sorting and batching of orders in terminals, order consolidation, picker routing. | Fixed Time Window Batching (FTWB) and Variable Time Window Batching (VTWB), Bin Packing Problem, (container) Reordering, Resorting, Pre-marshalling Problem, Block(s) Relocation Problem, Load Planning Problem. | Simple sequencing and batching rules, heuristics and metaheuristics, discrete event simulations, MIP/MILP. |
| Vehicle Routing Problem | Scheduling, dispatching of vehicles and vehicle routing. | Shortest Path Problem, TSP, VRP, Heterogeneous Fleet VRP (HF-VRP), VRP with Time Windows, Multi-Depot VRP (VRP with TW), VRP with Pickup and Delivery (VRPPD), Capacitated VRP (CVRP), Two-echelon VRP. | Graph optimisation, MIP/MILP, heuristics and metaheuristics, behavioural models, MAS. |
| Prediction and Forecasting | Prediction of delays, demand, events, vehicles and resource occurrences. | Delay prediction and propagation, demand forecasting, traffic flow forecasting. | Analytical methods, classical and Bayesian statistics methods, regression, time-series analysis, ML and DL, behavioural models, simulation, System Dynamics, MAS. |
Appendix B
Table A2.
The reviewed NCO studies related to the integrated optimisation problems classified according to the six optimisation classes defined in Section 2.2.
Table A2.
The reviewed NCO studies related to the integrated optimisation problems classified according to the six optimisation classes defined in Section 2.2.
| Studies | Problem | Learning | Models | ma * | Solution Strategy |
|---|---|---|---|---|---|
| Network Optimisation | |||||
| Kerkkamp [88] | Network planning | DQL | GCN | End-to-end | |
| Zhu et al. [90] | Network planning | Actor–Critic | GCN | Hybrid end-to-end, where the DRL first prunes the search space and then the heuristics improve the solution | |
| Resource Assignment/Scheduling/Dispatching | |||||
| Agasucci et al. [13] | Train dispatching | Q-Learning | NN | End-to-end. Decentralised and Centralised Deep Q-Learning | |
| Obara et al. [68] | Train dispatching | Q-Learning | MLP | End-to-end. Convert train schedule to graph and apply DQL. | |
| Khadilkar et al. [69] | Train scheduling | Q-Learning | Tabular | End-to-end. Tabular Q-Learning with simulator | |
| Adi et al. [71] | Trucks assignment and dispatching | Q-Learning | Double DQN | End-to-end. Centralised Learning for truck routing/dispatching in intermodal terminals | |
| Chen et al. [79] | Dispatching and package matching | QMIX | DQN | X | QMIX (Multi-agent Q-Learning with centralised training and decentralised execution) |
| Chen et al. [82] | Dispatching (couriers are assigned to tasks) | PPO | MLP | X | End-to-end MARL with decentralised value function for each vehicle and common policy network with parameter sharing + parameter sharing |
| Ni et al. [87] | Generic scheduling problem | RL | GNN + GCN with attention pooling | Learn-to-improve with reward shaping | |
| Popescu [89] | Train dispatching | cross-entropy | NN | RL-agent executes action in a simulator | |
| Song et al. [91] | Generic scheduling problem | PPO | GNN + GAN | End-to-end | |
| Ren et al. [92] | Generic scheduling problem | A3C with baseline | Encoder-decoder with Attention, | End-to-end | |
| Han and Yang [93] | Generic scheduling problem | Model-free DRL | Encoder-decoder with RNN | End-to-end | |
| Oren et al. [94] | Generic scheduling problem | Q-Learning | GNN | End-to-end. DQL for online and offline dispatching problem | |
| Iklassov and Medvedev [119] | Generic assignment | Actor–Critic | GNN, GCN | End-to-end | |
| Porras-Valenzuela [120] | Network flow problem | Q-Learning | GCN | End-to-end. Single agent assigns flow links to warehouses under uncertainties | |
| Zhang et al. [121] | Synchromodal re-planning | Q-Learning | DQN | Learn-to-improve | |
| Zou et al. [122] | Dispatching/assignment | Q-Learning | Double DQN | End-to-end with simulator (SUMO) as environment and single centralised agent | |
| Resource Allocation/Balancing/Fleet Composition | |||||
| Li et al. [77] | Resource balancing | DQL | MLP for each agent | X | End-to-end. Cooperative Multi-Agent RL (MARL) with shared state and rewards |
| Ahn and Park [97] | Assignment and rebalancing | Factorised Actor–Critic | GCN | X | End-to-end. Decentralised policy for each zone with parameters sharing |
| Pan et al. [98] | Vehicle repositioning | Actor–Critic | Q-Network for each agent | X | Hierarchical RL (HRL) where each sub-agent adopts LSTM |
| Xi et al. [99] | Vehicle repositioning | PPO | DQN and LSTM | X | 3-Level HRL. DQN for workers and LSTM for prediction. |
| Zhang et al. [123] | Vehicle fleet reposition | Q-Learning | NN and tabular Q | X | End-to-end |
| Batching and Sequencing | |||||
| Beeks et al. [83] | Order batching and sequence problem | PPO | DNN | End-to-end with reward shaping for two-objective problems | |
| Cals et al. [100] | Batching and sequencing orders | PPO | DNN | Hybrid-method. Heuristics to take sequencing decisions and DRL to take batching decisions. | |
| Hottung et al. [101] | Reordering of containers | Supervised | DNN | Learn-to-improve. Heuristics utilise RL for improvement | |
| Vehicle Routing Problem | |||||
| Kool et al. [55] | TSP | REINFORCE | Encoder-decoder with GNN and attention | End-to-end. Prediction of next nodes using GAN Attention Network, masking and RL-baseline. | |
| Deudon et al. [56] | TSP | REINFORCE | Encoder-decoder with self-attention and Pointer Network | End-to-end | |
| Li et al. [58] | CVRP with heterogeneous vehicle fleet | policy DRL with baseline. | Encoder-decoder Multi-Head Attention | End-to-end | |
| Ren et al. [59] | VRP with TW | Policy gradient method | Encoder-decoder | X | Centralised training with shared parameters and observation |
| Vera and Abad [80] | CMVRP | Actor–Critic | Encoder-decoder | X | End-to-end MARL with centralised training and decentralised execution |
| Nazari et al. [102] | VRP | Policy-based RL | Encoder-decoder with RNN and attention | End-to-end | |
| Joshi et al. [104] | TSP | Supervised | GNN | End-to-end | |
| Li et al. [105] | Pick-up and delivery VRP | policy DRL with baseline. | Encoder-decoder with self-attention | End-to-end | |
| Falkner and Schmidt-Thieme [106] | CVRP-TW | REINFORCE | Encoder-decoder with attention | End-to-end. Extended encoder-decoder to embed rich problem context | |
| Foa et al. [107] | Assignment and routing | modified PPO | CNN | X | End-to-end MARL with two actor-networks for node selection and assignment |
| Li et al. [108] | Dynamic pick-up and delivery | Double Q-Learning | Graph spatial–temporal attention network | End-to-end. Predict demand and formulate environment as a graph. Attention net is used to calculate the relationships between vehicle and all the neighbouring vehicles | |
| Ma et al. [109] | Dynamic pick-up and delivery | Q-Learning (upper policy) and REINFORCE (lower policy) | Upper-level agent: MLP, Lower level agent: GNN | X | Learn-to-configure. Multi-Agent HRL for assigning orders and delivery |
| Wu et al. [110] | TSP/CVRP | Actor–Critic | Encoder-decoder | Learn-to-improve. Heuristics utilise RL for improvement | |
| Da Costa et al. [111] | TSP | Actor–Critic | Encoder-decoder with GCN and LSTM | Learn-to-improve. Heuristics utilise RL for improvement. | |
| Hottung et al. [112] | CVRP | REINFORCE | Encoder-decoder with attention and FNN | Learn-to-improve. Heuristics utilise RL for improvement | |
| Li et al. [113] | Large-scale CVRP | Supervised | Encoder-decoder with self-attention | Learn-to-improve. Clustering heuristics utilise ML for improvement | |
| Zhao et al. [118] | VRP | Actor–Critic | Encoder-decoder with graph embedding and attention layer | Learn-to-configure. RL provides initial-solution to heuristic search | |
| Lu et al. [124] | CVRP | REINFORCE | Encoder-decoder with self-attention | Learn-to-improve. Heuristics utilise RL for improvement | |
| Kalakanti et al. [125] | VRP | Q-Learning | Clustering and tabular | Learn-to-improve. Two phase heuristics with Q-Learning: Clustering to approximate vehicles and tours and then apply Q-Learning to learn routes | |
| James et al. [126] | Dynamic VRP | A3C | Encoder-decoder with graph embeddings and Pointer Network | End-to-end | |
| Wang [127] | VRP | REINFORCE | Encoder-decoder with GNN and Graph Reasoning Network (GRN) | End-to-end. Decomposition and assembling of graphs with GNN and RL | |
| Xing and Tu [128]. | TSP | Monte Carlo Tree Search | GNN | End-to-end | |
| Xu et al. [129] | VRP | policy-based DRL | Encoder-decoder with graph attention and MHA | End-to-end | |
| Zhang et al. [130] | VRP with TW | policy-based DRL | attention-based encoder-decoder | X | End-to-end. Enc.-Dec. MARL with centralised learning. |
| Zhang et al. [131] | Dynamic TSP | policy gradient with rollout baseline | Encoder-decoder with MHA | End-to-end | |
| Zong et al. [132] | Pick-up and delivery | Cooperative A2C | Encoder-decoder with MHA | X | End-to-end MARL. utilise cooperative multi-agent decoders to leverage the decision dependence among different vehicle agents |
| Prediction and Forecasting | |||||
| Li et al. [23] | Delay prediction | Supervised | GNN | End-to-end. GNN applying on temporal multigraph (dynamic railway network) for dynamic spatial–temporal modelling | |
| Yu et al. [114] | Spatial–temporal forecasting | Supervised | GCN | GCN for extracting spatial features and Gated CNN for temporal features | |
| Hassan et al. [115] | Forecasting freight movement | RL | Not specified | Learn-to-configure. RL adjust weights for forecast models. | |
| Guo et al. [116] | Spatial–temporal forecasting | Supervised | Attention-based GCN | Dynamic spatial–temporal forecasting with GCN and attention | |
| Zhao et al. [117] | Spatial–temporal forecasting | Supervised | Attention-based GCN | Dynamic spatial–temporal modelling with GCN and attentions | |
| Anguita and Olariaga [133] | Demand forecasting | Supervised | CNN + LSTM | Hybrid LSTM + CNN for dynamic spatial–temporal modelling to extract spatial (CNN) and temporal (RNN) context | |
| Heglund et al. [134] | Delay prediction | Supervised | GCN | End-to-end. Formulate graph with delays on nodes and edges | |
* ma: Multi-Agent.
References
- Reis, V. Analysis of mode choice variables in short-distance intermodal freight transport using an agent-based model. Transp. Res. Part A Policy Pract. 2014, 61, 100–120. [Google Scholar] [CrossRef]
- Barua, L.; Zou, B.; Zhou, Y. Machine learning for international freight transportation management: A comprehensive review. Res. Transp. Bus. Manag. 2020, 34, 100453. [Google Scholar] [CrossRef]
- Bešinović, N.; Goverde, R.M. Capacity assessment in railway networks. In Handbook of Optimization in the Railway Industry; Springer: Berlin/Heidelberg, Germany, 2018; pp. 25–45. [Google Scholar]
- SteadieSeifi, M.; Dellaert, N.P.; Nuijten, W.; VanWoensel, T.; Raoufi, R. Multimodal freight transportation planning: A literature review. Eur. J. Oper. Res. 2014, 233, 1–15. [Google Scholar] [CrossRef]
- Tang, Y.; Agrawal, S.; Faenza, Y. Reinforcement learning for integer programming: Learning to cut. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: Birmingham, UK, 2020; pp. 9367–9376. [Google Scholar]
- Nair, V.; Bartunov, S.; Gimeno, F.; Von Glehn, I.; Lichocki, P.; Zwols, Y. Solving mixed integer programs using neural networks. arXiv 2020, arXiv:2012.13349. [Google Scholar]
- Kotary, J.; Fioretto, F.; Van Hentenryck, P.; Wilder, B. End-to-end constrained optimization learning: A survey. arXiv 2021, arXiv:2103.16378. [Google Scholar]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement learning for combinatorial optimization: A survey. Comput. Oper. Res. 2021, 134, 105400. [Google Scholar] [CrossRef]
- Karimi-Mamaghan, M.; Mohammadi, M.; Meyer, P.; Karimi-Mamaghan, A.M.; Talbi, E.G. Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art. Eur. J. Oper. Res. 2022, 296, 393–422. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://dl.acm.org/doi/10.5555/3295222.3295349 (accessed on 20 September 2024).
- Agamez-Arias, A.D.M.; Moyano-Fuentes, J. Intermodal transport in freight distribution: A literature review. Transp. Rev. 2017, 37, 782–807. [Google Scholar] [CrossRef]
- Rail-Roadmap. Level Playing Field in the Transport Sector. 2021. Available online: https://www.railroadmap2030.be/wp-content/uploads/2021/09/BRFF-Level-playing-field-in-the-transport-sector.pdf (accessed on 1 June 2023).
- Agasucci, V.; Grani, G.; Lamorgese, L. Solving the single-track train scheduling problem via Deep Reinforcement Learning. arXiv 2020, arXiv:2009.00433. [Google Scholar]
- Escudero, A.; Muñuzuri, J.; Guadix, J.; Arango, C. Dynamic approach to solve the daily drayage problem with transit time uncertainty. Comput. Ind. 2013, 64, 165–175. [Google Scholar] [CrossRef]
- Bektas, T.; Crainic, T. A Brief Overview of Intermodal Transportation; Cirrelt: Montreal, CA, USA, 2007; Volume 3, pp. 1–25. [Google Scholar]
- Giusti, R.; Manerba, D.; Bruno, G.; Tadei, R. Synchromodal logistics: An overview of critical success factors, enabling technologies, and open research issues. Transp. Res. Part E Logist. Transp. Rev. 2019, 129, 92–110. [Google Scholar] [CrossRef]
- Guihaire, V.; Hao, J.-K. Transit network design and scheduling: A global review. Transp. Res. Part A Policy Pract. 2008, 42, 1251–1273. [Google Scholar] [CrossRef]
- Stoilova, S.D.; Martinov, S.V. Selecting a location for establishing a rail-road intermodal terminal by using a hybrid SWOT/MCDM model. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 618, p. 012060. [Google Scholar]
- Wu, X.; Cao, L. Using heuristic MCMC method for terminal location planning in intermodal transportation. Int. J. Oper. Res. 2018, 32, 421–442. [Google Scholar] [CrossRef]
- Newman, A.M.; Yano, C.A. Centralized and decentralized train scheduling for intermodal operations. IIE Trans. 2000, 32, 743–754. [Google Scholar] [CrossRef]
- Behdani, B.; Fan, Y.; Wiegmans, B.; Zuidwijk, R. Multimodal schedule design for synchromodal freight transport systems. Eur. J. Transp. Infrastruct. Res. 2014, 16, 424–444. [Google Scholar] [CrossRef]
- Weik, N.; Bohlin, M.; Nießen, N. Long-Term Capacity Planning of Railway Infrastructure: A Stochastic Approach Capturing Infrastructure Unavailability. RWTH Aachen University. PhD Thesis No.RWTH-2020-06771. Lehrstuhl für Schienenbahnwesen und Verkehrswirtschaft und Verkehrswissenschaftliches Institut. 2020. Available online: https://publications.rwth-aachen.de/record/793271/files/793271.pdf (accessed on 20 September 2024).
- Li, Z.; Huang, P.; Wen, C.; Rodrigues, F. Railway Network Delay Evolution: A Heterogeneous Graph Neural Network Approach. arXiv 2023, arXiv:2303.15489. [Google Scholar]
- Mueller, J.P.; Elbert, R.; Emde, S. Integrating vehicle routing into intermodal service network design with stochastic transit times. EURO J. Transp. Logist. 2021, 10, 100046. [Google Scholar] [CrossRef]
- Mueller, J.P.; Elbert, R.; Emde, S. Intermodal service network design with stochastic demand and short-term schedule modifications. Comput. Ind. Eng. 2021, 159, 107514. [Google Scholar] [CrossRef]
- Jaržemskiene, I. The evolution of intermodal transport research and its development issues. Transport 2007, 22, 296–306. [Google Scholar] [CrossRef][Green Version]
- Baykasoğlu, A.; Subulan, K.; Serdar Taşan, A.; Ülker, Ö. Development of a Web-Based Decision Support System for Strategic and Tactical Sustainable Fleet Management Problems in Intermodal Transportation Networks. In Lean and Green Supply Chain Management; Springer: Berlin/Heidelberg, Germany, 2018; pp. 189–230. [Google Scholar]
- Arabani, A.B.; Farahani, R.Z. Facility location dynamics: An overview of classifications and applications. Comput. Ind. Eng. 2012, 62, 408–420. [Google Scholar] [CrossRef]
- Gupta, A.; Könemann, J. Approximation algorithms for network design: A survey. Surv. Oper. Res. Manag. Sci. 2011, 16, 3–20. [Google Scholar] [CrossRef]
- Cordeau, J.F.; Toth, P.; Vigo, D. A survey of optimization models for train routing and scheduling. Transp. Sci. 1998, 32, 380–404. [Google Scholar] [CrossRef]
- Díaz-Parra, O.; Ruiz-Vanoye, J.A.; Bernábe Loranca, B.; Fuentes-Penna, A.; Barrera-Cámara, R.A. A survey of transportation problems. J. Appl. Math. 2014, 2014, 848129. [Google Scholar] [CrossRef]
- Feeney, G.J. The Distribution of Empty Freight Cars; Columbia University: New York, NY, USA, 1959. [Google Scholar]
- Beaujon, G.J.; Turnquist, M.A. A model for fleet sizing and vehicle allocation. Transp. Sci. 1991, 251, 19–45. [Google Scholar] [CrossRef]
- Baykasoğlu, A.; Subulan, K.; Taşan, A.S.; Dudaklı, N. A review of fleet planning problems in single and multimodal transportation systems. Transp. A Transp. Sci. 2019, 15, 631–697. [Google Scholar] [CrossRef]
- Zhang, H.; Ge, H.; Yang, J.; Tong, Y. Review of vehicle routing problems: Models, classification and solving algorithms. In Archives of Computational Methods in Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–27. [Google Scholar]
- Golden, B.; Wang, X.; Wasil, E. The Evolution of the Vehicle Routing Problem—A Survey of VRP Research and Practice from 2005 to 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–64. [Google Scholar]
- Henn, S. Order batching and sequencing for the minimization of the total tardiness in picker-to-part warehouses. Flex. Serv. Manuf. J. 2015, 27, 86–114. [Google Scholar] [CrossRef]
- Hu, Q.; Corman, F.; Lodewijks, G. A review of intermodal rail freight bundling operations. In Proceedings of the Computational Logistics: 6th International Conference, ICCL 2015, Delft, The Netherlands, 23–25 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 451–463. [Google Scholar]
- Gao, B.; Ou, D.; Dong, D.; Wu, Y. A data-driven two-stage prediction model for train primary-delay recovery time. Int. J. Softw. Eng. Knowl. Eng. 2020, 30, 921–940. [Google Scholar] [CrossRef]
- Babai, M.Z.; Boylan, J.E.; Rostami-Tabar, B. Demand forecasting in supply chains: A review of aggregation and hierarchical approaches. Int. J. Prod. Res. 2022, 60, 324–348. [Google Scholar] [CrossRef]
- Shah, N.H.; Mittal, M. Optimization and Inventory Management; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Perez, H.D.; Hubbs, C.D.; Li, C.; Grossmann, I.E. Algorithmic approaches to inventory management optimization. Processes 2021, 9, 102. [Google Scholar] [CrossRef]
- Bello, I.; Pham, H.; Le, Q.V.; Norouzi, M.; Bengio, S. Neural combinatorial optimization with reinforcement learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Simao, H.P.; Day, J.; George, A.P.; Gifford, T.; Nienow, J.; Powell, W.B. An approximate dynamic programming algorithm for large-scale fleet management: A case application. Transp. Sci. 2009, 43, 178–197. [Google Scholar] [CrossRef]
- Novoa, C.; Storer, R. An approximate dynamic programming approach for the vehicle routing problem with stochastic demands. Eur. J. Oper. Res. 2009, 196, 509–515. [Google Scholar] [CrossRef]
- Powell, W.B. A unified framework for stochastic optimization. Eur. J. Oper. Res. 2019, 275, 795–821. [Google Scholar] [CrossRef]
- Stimpson, D.; Ganesan, R. A reinforcement learning approach to convoy scheduling on a contested transportation network. Optim. Lett. 2015, 9, 1641–1657. [Google Scholar] [CrossRef]
- Goodson, J.C.; Ohlmann, J.W.; Thomas, B.W. Rollout policies for dynamic solutions to the multivehicle routing problem with stochastic demand and duration limits. Oper. Res. 2013, 61, 138–154. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2 (NIPS’14); MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf (accessed on 20 September 2024).
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In ICLR 2015. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Nowak, A.; Bruna, J. Divide and Conquer with Neural Networks. 2016. Available online: https://openreview.net/forum?id=Hy3_KuYxg (accessed on 1 August 2024).
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://papers.nips.cc/paper_files/paper/2015/file/29921001f2f04bd3baee84a12e98098f-Paper.pdf (accessed on 1 September 2024).
- Kool, W.; Van Hoof, H.; Welling, M. Attention, learn to solve routing problems! arXiv 2018, arXiv:1803.08475. [Google Scholar]
- Deudon, M.; Cournut, P.; Lacoste, A.; Adulyasak, Y.; Rousseau, L.M. Learning heuristics for the tsp by policy gradient. In Proceedings of the Integration of Constraint Programming, Artificial Intelligence, and Operations Research: 15th International Conference, Delft, The Netherlands, 26–29 June 2018; pp. 170–181. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order matters: Sequence to sequence for sets. arXiv 2015, arXiv:1511.06391. [Google Scholar]
- Li, J.; Ma, Y.; Gao, R.; Cao, Z.; Lim, A.; Zhang, J. Deep reinforcement learning for solving the heterogeneous capacitated vehicle routing problem. IEEE Trans. Cybern. 2021, 52, 13572–13585. [Google Scholar] [CrossRef]
- Ren, L.; Fan, X.; Cui, J.; Shen, Z.; Lv, Y.; Xiong, G. A multi-agent reinforcement learning method with route recorders for vehicle routing in supply chain management. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16410–16420. [Google Scholar] [CrossRef]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2008, 1050, 10–48550. [Google Scholar]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- He, S.; Shin, K.G. Towards fine-grained flow forecasting: A graph attention approach for bike sharing systems. Proc. Web Conf. 2020, 88–98. [Google Scholar] [CrossRef]
- Fang, X.; Huang, J.; Wang, F.; Zeng, L.; Liang, H.; Wang, H. Constgat: Contextual spatial-temporal graph attention network for travel time estimation at baidu maps. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, Virtual, 6–10 July 2020; pp. 2697–2705. [Google Scholar]
- Sun, C.; Li, C.; Lin, X.; Zheng, T.; Meng, F.; Rui, X.; Wang, Z. Attention-based graph neural networks: A survey. Artif. Intell. Rev. 2023, 56 (Suppl. S2), 2263–2310. [Google Scholar] [CrossRef]
- Oroojlooyjadid, A.; Nazari, M.; Snyder, L.V.; Takáč, M. A deep q-network for the beer game: Deep reinforcement learning for inventory optimization. Manuf. Serv. Oper. Manag. 2022, 241, 285–304. [Google Scholar] [CrossRef]
- Obara, M.; Kashiyama, T.; Sekimoto, Y. Deep reinforcement learning approach for train rescheduling utilizing graph theory. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 4525–4533. [Google Scholar]
- Khadilkar, H. A scalable reinforcement learning algorithm for scheduling railway lines. IEEE Trans. Intell. Transp. Syst. 2018, 20, 727–736. [Google Scholar] [CrossRef]
- Guo, W.; Atasoy, B.; Negenborn, R.R. Global synchromodal shipment matching problem with dynamic and stochastic travel times: A reinforcement learning approach. Ann. Oper. Res. 2022, 1–32. [Google Scholar] [CrossRef]
- Adi, T.N.; Iskandar, Y.A.; Bae, H. Interterminal truck routing optimization using deep reinforcement learning. Sensors 2020, 20, 5794. [Google Scholar] [CrossRef]
- Rolf, B.; Jackson, I.; Müller, M.; Lang, S.; Reggelin, T.; Ivanov, D. A review on reinforcement learning algorithms and applications in supply chain management. Int. J. Prod. Res. 2022, 61, 7151–7179. [Google Scholar] [CrossRef]
- Yan, Y.; Chow, A.H.; Ho, C.P.; Kuo, Y.H.; Wu, Q.; Ying, C. Reinforcement learning for logistics and supply chain management: Methodologies, state of the art, and future opportunities. Transp. Res. Part E Logist. Transp. Rev. 2022, 162, 102712. [Google Scholar] [CrossRef]
- Zong, Z.; Feng, T.; Xia, T.; Jin, D.; Li, Y. Deep Reinforcement Learning for Demand Driven Services in Logistics and Transportation Systems: A Survey. arXiv 2021, arXiv:2108.04462. [Google Scholar]
- Wang, Q.; Tang, C. Deep reinforcement learning for transportation network combinatorial optimization: A survey. Knowl.-Based Syst. 2021, 233, 107526. [Google Scholar] [CrossRef]
- Gokhale, A.; Trasikar, C.; Shah, A.; Hegde, A.; Naik, S.R. A Reinforcement Learning Approach to Inventory Management. In Advances in Artificial Intelligence and Data Engineering: Select Proceedings of AIDE; Springer: Singapore, 2019; pp. 281–297. [Google Scholar]
- Li, X.; Zhang, J.; Bian, J.; Tong, Y.; Liu, T.Y. A cooperative multi-agent reinforcement learning framework for resource balancing in complex logistics network. arXiv 2019, arXiv:1903.00714. [Google Scholar]
- Boute, R.N.; Gijsbrechts, J.; Van Jaarsveld, W.; Vanvuchelen, N. Deep reinforcement learning for inventory control: A roadmap. Eur. J. Oper. Res. 2022, 298, 401–412. [Google Scholar] [CrossRef]
- Chen, J.; Umrawal, A.K.; Lan, T.; Aggarwal, V. DeepFreight: A Model-free Deep-reinforcement-learning-based Algorithm for Multi-transfer Freight Delivery. In Proceedings of the International Conference on Automated Planning and Scheduling, Guangzhou, China, 2–13 August 2021; Volume 31, pp. 510–518. [Google Scholar]
- Vera, J.M.; Abad, A.G. Deep reinforcement learning for routing a heterogeneous fleet of vehicles. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; pp. 1–6. [Google Scholar]
- Liu, X.; Hu, M.; Peng, Y.; Yang, Y. Multi-Agent Deep Reinforcement Learning for Multi-Echelon Inventory Management; SSRN: Rochester, NY, USA, 2022. [Google Scholar]
- Chen, Y.; Qian, Y.; Yao, Y.; Wu, Z.; Li, R.; Xu, Y. Can sophisticated dispatching strategy acquired by reinforcement learning?—A case study in dynamic courier dispatching system. arXiv 2019, arXiv:1903.02716. [Google Scholar]
- Beeks, M.; Afshar, R.R.; Zhang, Y.; Dijkman, R.; van Dorst, C.; de Looijer, S. Deep reinforcement learning for a multi-objective online order batching problem. In Proceedings of the International Conference on Automated Planning and Scheduling, Virtual, 13–24 June 2022; Volume 32, pp. 435–443. [Google Scholar]
- Hutsebaut-Buysse, M.; Mets, K.; Latré, S. Hierarchical reinforcement learning: A survey and open research challenges. Mach. Learn. Knowl. Extr. 2022, 4, 172–221. [Google Scholar] [CrossRef]
- Bengio, Y.; Lodi, A.; Prouvost, A. Machine learning for combinatorial optimization: A methodological tour d’horizon. Eur. J. Oper. Res. 2021, 290, 405–421. [Google Scholar] [CrossRef]
- Biedenkapp, A.; Bozkurt, H.F.; Eimer, T.; Hutter, F.; Lindauer, M. Dynamic algorithm configuration: Foundation of a new meta-algorithmic framework. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 427–434. [Google Scholar]
- Ni, F.; Hao, J.; Lu, J.; Tong, X.; Yuan, M.; He, K. A multi-graph attributed reinforcement learning based optimization algorithm for large-scale hybrid flow shop scheduling problem. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery Data Mining, Virtual, 14–18 August 2021; pp. 3441–3451. [Google Scholar]
- Kerkkamp, D.; Bukhsh, Z.A.; Zhang, Y.; Jansen, N. Grouping of Maintenance Actions with Deep Reinforcement Learning and Graph Convolutional Networks. In Proceedings of the ICAART, Virtual, 3–5 February 2022; pp. 574–585. [Google Scholar]
- Popescu, T. Reinforcement Learning for Train Dispatching: A Study on the Possibility to Use Reinforcement Learning to Optimize Train Ordering and Minimize Train Delays in Disrupted Situations, inside the Rail Simulator OSRD. KTH, School of Electrical Engineering and Computer Science (EECS). Dissertation. 2022. Available online: https://www.diva-portal.org/smash/get/diva2:1702837/FULLTEXT01.pdf (accessed on 20 September 2024).
- Zhu, H.; Gupta, V.; Ahuja, S.S.; Tian, Y.; Zhang, Y.; Jin, X. Network planning with deep reinforcement learning. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Virtual, 23–27 August 2021; pp. 258–271. [Google Scholar]
- Song, W.; Chen, X.; Li, Q.; Cao, Z. Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2022, 19, 1600–1610. [Google Scholar] [CrossRef]
- Ren, J.F.; Ye, C.M.; Yang, F. A novel solution to jsps based on long short-term memory and policy gradient algorithm. Int. J. Simul. Model. 2020, 19, 157–168. [Google Scholar] [CrossRef]
- Han, B.; Yang, J. A deep reinforcement learning based solution for flexible job shop scheduling problem. Int. J. Simul. Model. 2021, 20, 375–386. [Google Scholar] [CrossRef]
- Oren, J.; Ross, C.; Lefarov, M.; Richter, F.; Taitler, A.; Daniel, C. SOLO: Search online, learn offline for combinatorial optimization problems. In Proceedings of the International Symposium on Combinatorial Search, Virtual, 26–30 July 2021; Volume 12, pp. 97–105. [Google Scholar]
- Rashid, T.; Farquhar, G.; Peng, B.; Whiteson, S. Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 10199–10210. [Google Scholar]
- Chen, H.; Li, Z.; Yao, Y. Multi-agent reinforcement learning for fleet management: A survey. In Proceedings of the 2nd International Conference on Artificial Intelligence, Automation, and High-Performance Computing, AIAHPC 2022, Zhuhai, China, 25–27 February 2022; Volume 12348, pp. 611–624. [Google Scholar]
- Ahn, K.; Park, J. Cooperative zone-based rebalancing of idle overhead hoist transportations using multi-agent reinforcement learning with graph representation learning. IISE Trans. 2021, 53, 1140–1156. [Google Scholar] [CrossRef]
- Pan, L.; Cai, Q.; Fang, Z.; Tang, P.; Huang, L. A deep reinforcement learning framework for rebalancing dockless bike sharing systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1393–1400. [Google Scholar]
- Xi, J.; Zhu, F.; Ye, P.; Lv, Y.; Tang, H.; Wang, F.Y. HMDRL: Hierarchical Mixed Deep Reinforcement Learning to Balance Vehicle Supply and Demand. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21861–21872. [Google Scholar] [CrossRef]
- Cals, B.; Zhang, Y.; Dijkman, R.; van Dorst, C. Solving the online batching problem using deep reinforcement learning. Comput. Ind. Eng. 2021, 156, 107221. [Google Scholar] [CrossRef]
- Hottung, A.; Tanaka, S.; Tierney, K. Deep learning assisted heuristic tree search for the container pre-marshalling problem. Comput. Oper. Res. 2020, 113, 104781. [Google Scholar] [CrossRef]
- Nazari, M.; Oroojlooy, A.; Snyder, L.; Takác, M. Reinforcement learning for solving the vehicle routing problem. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://dl.acm.org/doi/10.5555/3327546.3327651 (accessed on 20 September 2024).
- Khalil, E.; Dai, H.; Zhang, Y.; Dilkina, B.; Song, L. Learning combinatorial optimization algorithms over graphs. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://dl.acm.org/doi/10.5555/3295222.3295382 (accessed on 20 September 2024).
- Joshi, C.K.; Laurent, T.; Bresson, X. An efficient graph convolutional network technique for the travelling salesman problem. arXiv 2019, arXiv:1906.01227. [Google Scholar]
- Li, J.; Xin, L.; Cao, Z.; Lim, A.; Song, W.; Zhang, J. Heterogeneous attentions for solving pickup and delivery problem via deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2021, 23, 2306–2315. [Google Scholar] [CrossRef]
- Falkner, J.K.; Schmidt-Thieme, L. Learning to solve vehicle routing problems with time windows through joint attention. arXiv 2020, arXiv:2006.09100. [Google Scholar]
- Foa, S.; Coppola, C.; Grani, G.; Palagi, L. Solving the vehicle routing problem with deep reinforcement learning. arXiv 2022, arXiv:2208.00202. [Google Scholar]
- Li, X.; Luo, W.; Yuan, M.; Wang, J.; Lu, J.; Wang, J.; Zeng, J. Learning to optimize industry-scale dynamic pickup and delivery problems. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2511–2522. [Google Scholar]
- Ma, Y.; Hao, X.; Hao, J.; Lu, J.; Liu, X.; Xialiang, T.; Meng, Z. A hierarchical reinforcement learning based optimization framework for large-scale dynamic pickup and delivery problems. Adv. Neural Inf. Process. Syst. 2021, 34, 23609–23620. [Google Scholar]
- Wu, Y.; Song, W.; Cao, Z.; Zhang, J.; Lim, A. Learning improvement heuristics for solving routing problems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5057–5069. [Google Scholar] [CrossRef]
- Da Costa, P.R.D.O.; Rhuggenaath, J.; Zhang, Y.; Akcay, A. Learning 2-opt heuristics for the traveling salesman problem via deep reinforcement learning. arXiv 2020, arXiv:2004.01608. [Google Scholar]
- Hottung, A.; Tierney, K. Neural large neighborhood search for the capacitated vehicle routing problem. arXiv 2019, arXiv:1911.09539. [Google Scholar]
- Li, S.; Yan, Z.; Wu, C. Learning to delegate for large-scale vehicle routing. Adv. Neural Inf. Process. Syst. 2021, 34, 26198–26211. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Hassan, L.A.H.; Mahmassani, H.S.; Chen, Y. Reinforcement learning framework for freight demand forecasting to support operational planning decisions. Transp. Res. Part E Logist. Transp. Rev. 2020, 137, 101926. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 922–929. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, Z.; Sun, Q.; Li, Q.; Jia, X.; Zhang, R. Attention-based dynamic spatial-temporal graph convolutional networks for traffic speed forecasting. Expert Syst. Appl. 2022, 204, 117511. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, M.; Zhao, X.; Zou, J. A Hybrid of Deep Reinforcement Learning and Local Search for the Vehicle Routing Problems. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7208–7218. [Google Scholar] [CrossRef]
- Iklassov, Z.; Medvedev, D. Robust Reinforcement Learning on Graphs for Logistics optimization. arXiv 2022, arXiv:2205.12888. [Google Scholar]
- Porras-Valenzuela, J.F. A Deep Reinforcement Learning Approach to Multistage Stochastic Network Flows for Distribution Problems. Instituto Tecnológico de Costa Rica; Thesis. 2022. Available online: https://repositoriotec.tec.ac.cr/handle/2238/13949 (accessed on 20 September 2024).
- Zhang, Y.; Negenborn, R.R.; Atasoy, B. Synchromodal freight transport re-planning under service time uncertainty: An online model-assisted reinforcement learning. Transp. Res. Part C Emerg. Technol. 2023, 156, 104355. [Google Scholar] [CrossRef]
- Zou, G.; Tang, J.; Yilmaz, L.; Kong, X. Online food ordering delivery strategies based on deep reinforcement learning. Appl. Intell. 2022, 52, 6853–6865. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Q.; Li, J.; Xu, C. Dynamic fleet management with rewriting deep reinforcement learning. IEEE Access 2020, 8, 143333–143341. [Google Scholar] [CrossRef]
- Lu, H.; Zhang, X.; Yang, S. A learning-based iterative method for solving vehicle routing problems. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Kalakanti, A.K.; Verma, S.; Paul, T.; Yoshida, T. RL SolVeR Pro: Reinforcement Learning for Solving Vehicle Routing Problem. In Proceedings of the 2019 1st International Conference on Artificial Intelligence and Data Sciences (AiDAS), Ipoh, Malaysia, 19 September 2019. [Google Scholar]
- James, J.Q.; Yu, W.; Gu, J. Online vehicle routing with neural combinatorial optimization and deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3806–3817. [Google Scholar]
- Wang, Q. VARL: A variational autoencoder-based reinforcement learning Framework for vehicle routing problems. Appl. Intell. 2021, 52, 8910–8923. [Google Scholar] [CrossRef]
- Xing, Z.; Tu, S. A graph neural network assisted monte-carlo tree search approach to traveling salesman problem. IEEE Access 2020, 8, 108418–108428. [Google Scholar] [CrossRef]
- Xu, Y.; Fang, M.; Chen, L.; Xu, G.; Du, Y.; Zhang, C. Reinforcement learning with multiple relational attention for solving vehicle routing problems. IEEE Trans. Cybern. 2021, 52, 11107–11120. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, H.; Zhou, M.; Wang, J. Solving dynamic traveling salesman problems with deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Systems. 2021, 34, 2119–2132. [Google Scholar] [CrossRef]
- Zhang, K.; He, F.; Zhang, Z.; Lin, X.; Li, M. Multi-vehicle routing problems with soft time windows: A multi-agent reinforcement learning approach. Transp. Res. Part C Emerg. Technol. 2020, 121, 102861. [Google Scholar] [CrossRef]
- Zong, Z.; Zheng, M.; Li, Y.; Jin, D. Mapdp: Cooperative multi-agent reinforcement learning to solve pickup and delivery problems. Proc. AAAI Conf. Artif. Intell. 2022, 36, 9980–9988. [Google Scholar] [CrossRef]
- Anguita, J.G.M.; Olariaga, O.D. Air cargo transport demand forecasting using ConvLSTM2D, an artificial neural network architecture approach. Case Stud. Transp. Policy 2023, 12, 101009. [Google Scholar] [CrossRef]
- Heglund, J.S.; Taleongpong, P.; Hu, S.; Tran, H.T. Railway delay prediction with spatial-temporal graph convolutional networks. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Heydaribeni, N.; Zhan, X.; Zhang, R.; Eliassi-Rad, T.; Koushanfar, F. Distributed constrained combinatorial optimization leveraging hypergraph neural networks. Nat. Mach. Intell. 2024, 6, 664–672. [Google Scholar] [CrossRef]
- Wan, C.P.; Li, T.; Wang, J.M. RLOR: A Flexible Framework of Deep Reinforcement Learning for Operation Research. arXiv 2023, arXiv:2303.13117. [Google Scholar]
- Berto, F.; Hua, C.; Park, J.; Kim, M.; Kim, H.; Son, J.; Kim, H.; Angioni, D.; Kool, W.; Cao, Z.; et al. Rl4co: An extensive reinforcement learning for combinatorial optimization benchmark. arXiv 2023, arXiv:2306.17100. [Google Scholar]
- Zheng, X.; Yin, M.; Zhang, Y. Integrated optimization of location, inventory and routing in supply chain network design. Transp. Res. Part B Methodol. 2019, 121, 1–20. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. Gman: A graph multi-attention network for traffic prediction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 1234–1241. [Google Scholar] [CrossRef]
- Cheng, R.; Li, Q. Modeling the momentum spillover effect for stock prediction via attribute-driven graph attention networks. Proc. AAAI Conf. Artif. Intell. 2021, 35, 55–62. [Google Scholar] [CrossRef]
- Xin, L.; Song, W.; Cao, Z.; Zhang, J. Multi-decoder attention model with embedding glimpse for solving vehicle routing problems. Proc. AAAI Conf. Artif. Intell. 2021, 35, 12042–12049. [Google Scholar] [CrossRef]
- Boffa, M.; Houidi, Z.B.; Krolikowski, J.; Rossi, D. Neural combinatorial optimization beyond the TSP: Existing architectures under-represent graph structure. arXiv 2022, arXiv:2201.00668. [Google Scholar]
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Goldberg, K.; Gonzalez, J.; Jordan, M.; Stoica, I. RLlib: Abstractions for distributed reinforcement learning. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2018; pp. 3053–3062. [Google Scholar]
- Kwon, Y.D.; Choo, J.; Kim, B.; Yoon, I.; Gwon, Y.; Min, S. Pomo: Policy optimization with multiple optima for reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21188–21198. [Google Scholar]
- Fitzpatrick, J.; Ajwani, D.; Carroll, P. A Scalable Learning Approach for the Capacitated Vehicle Routing Problem; SSRN: Rochester, NY, USA, 2023; SSRN 4633199. [Google Scholar]
- Krasowski, H.; Thumm, J.; Müller, M.; Schäfer, L.; Wang, X.; Althoff, M. Provably safe reinforcement learning: Conceptual analysis, survey, and benchmarking. Trans. Mach. Learn. Res. 2023. [Google Scholar] [CrossRef]
- Kochdumper, N.; Krasowski, H.; Wang, X.; Bak, S.; Althoff, M. Provably safe reinforcement learning via action projection using reachability analysis and polynomial zonotopes. IEEE Open J. Control. Syst. 2023, 2, 79–92. [Google Scholar] [CrossRef]
- Berkenkamp, F.; Schoellig, A.P.; Turchetta, M.; Krause, A. Safe model-based reinforcement learning with stability guarantees. Proc. Int. Conf. Neural Inf. Process. Syst. 2017, 30, 908–918. [Google Scholar]
- Garmendia, A.I.; Ceberio, J.; Mendiburu, A. Neural combinatorial optimization: A new player in the field. arXiv 2022, arXiv:2205.01356. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).