
Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model

 ,
,
Abstract
1. Introduction
2. Data Acquisition and Preprocessing
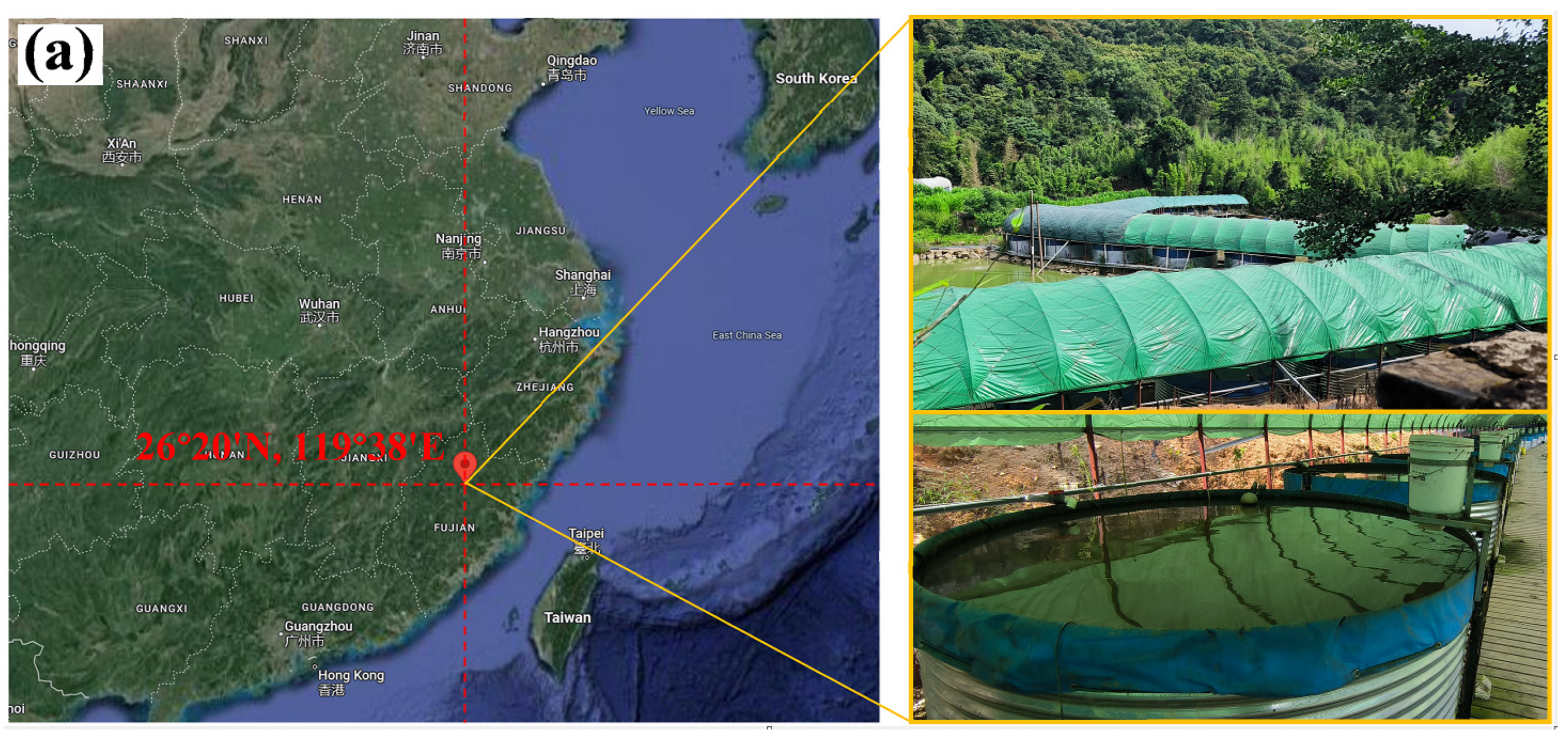
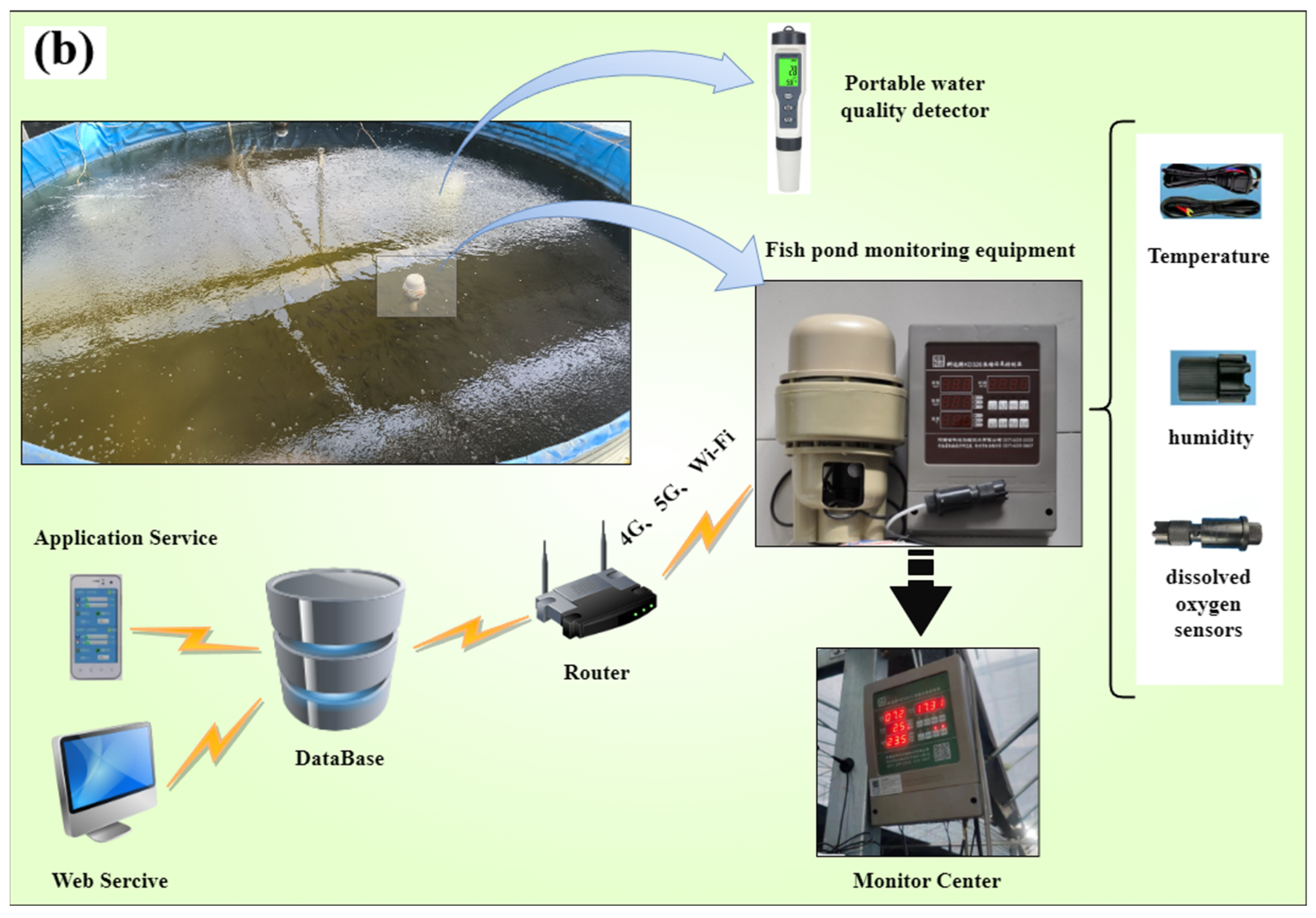
2.1. Experimental Data Collection
2.2. Data Preprocessing
2.2.1. Data Standardization and Normalization
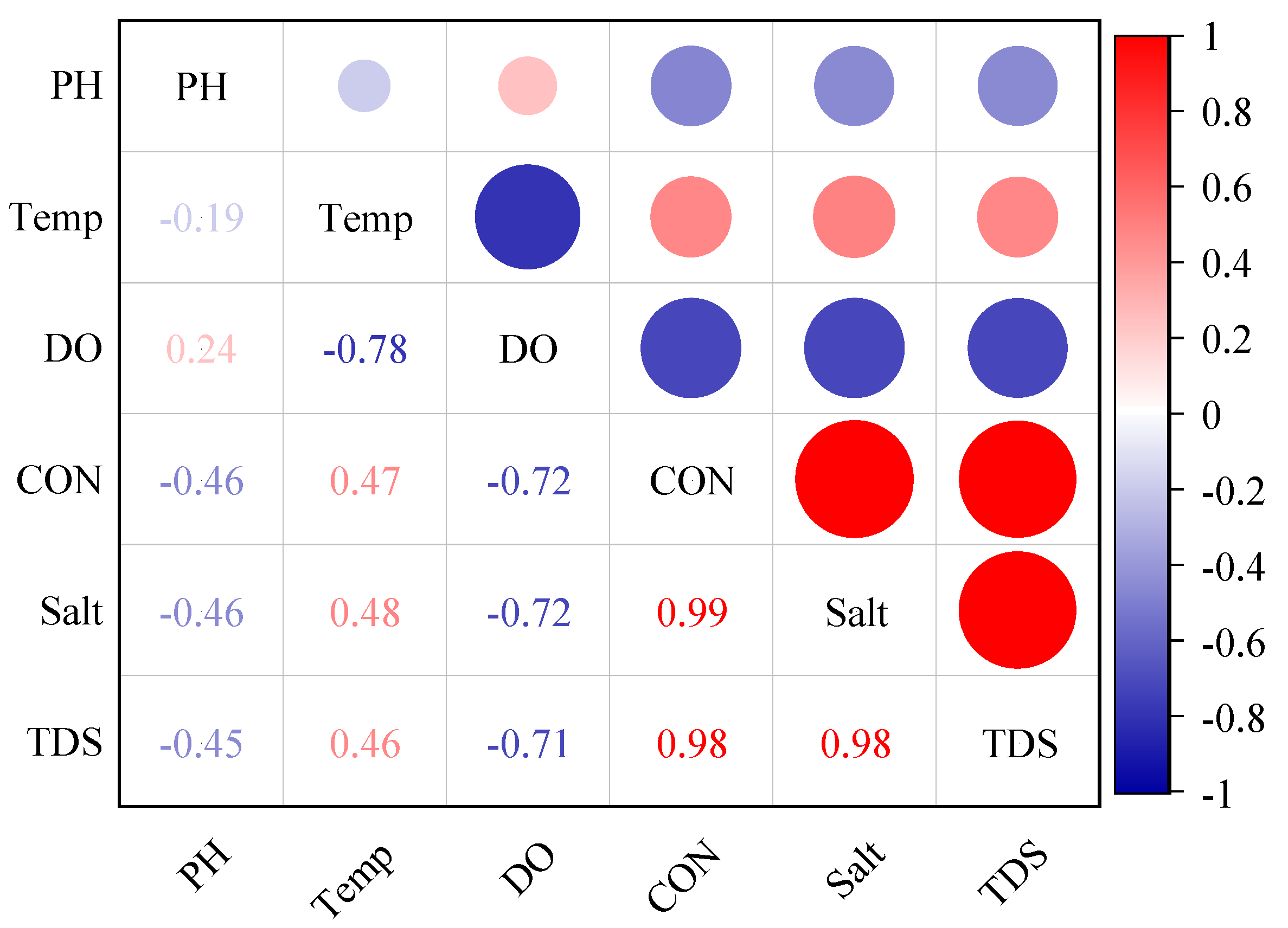
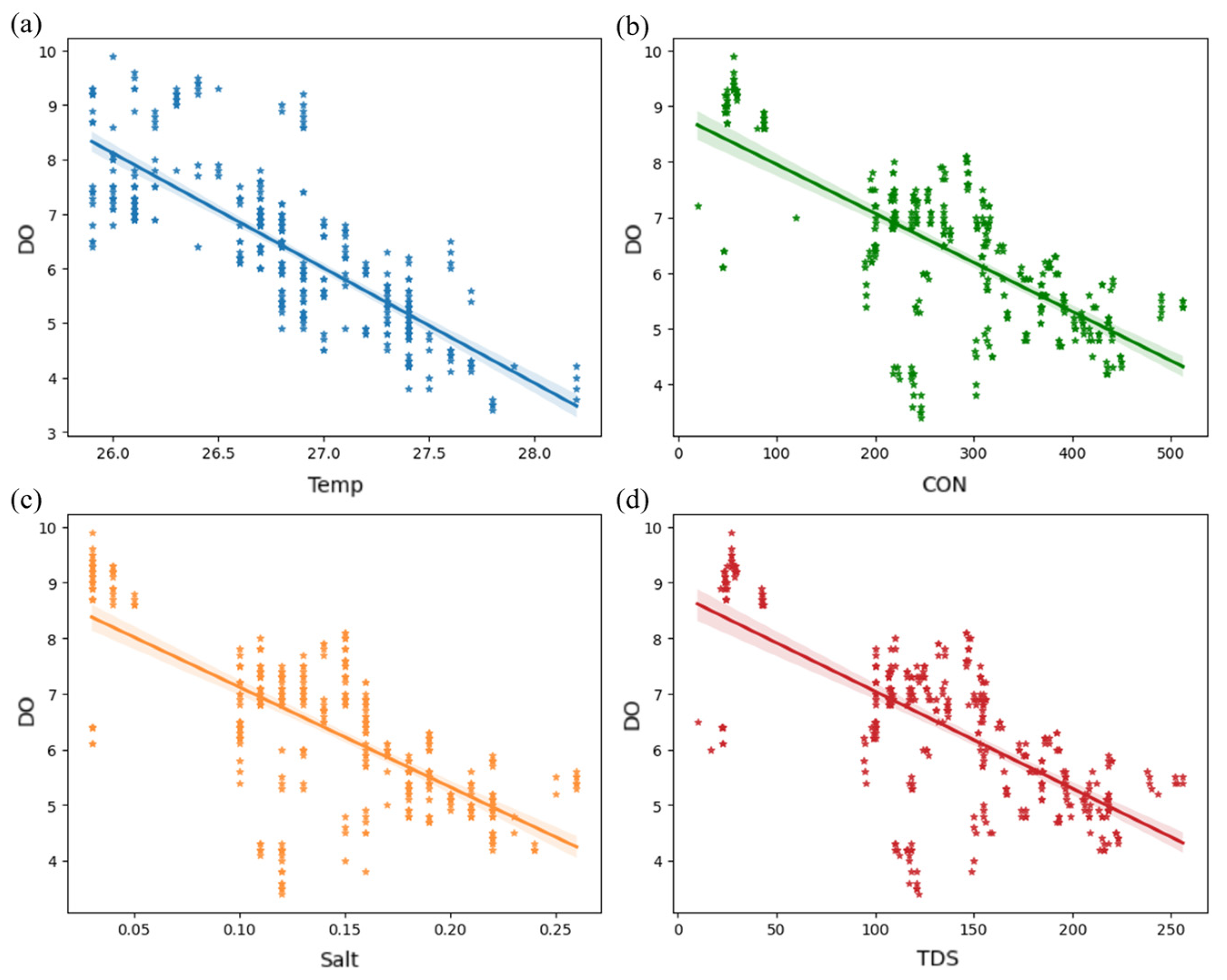
2.2.2. Data Correlation Analysis
3. Data Modeling Methodology
3.1. Support Vector Regression (SVR)
3.2. Differential Evolution (DE)
3.2.1. Population Initialization and Variation
3.2.2. Crossover of Populations
3.2.3. Population Selection
3.3. Gray Wolf Optimization (GWO)
3.4. Hybrid Differential Evolution and Gray Wolf Optimization Algorithm (DE-GWO-SVR)
4. Results and Discussion
4.1. PPMCC Analysis of Water Quality Indicators
4.2. Model Parameter Initialization and Validation of Fitness Function Values
4.3. Comparative Analysis of Residual Values for Water Quality DO Predictions
4.4. Comparative Analysis of Different Optimization Models on DO Prediction Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Zhang, Y.; Zhang, Q.; Liu, P.; Guo, R.; Jin, S.; Liu, Y. Evaluation and analysis of water quality of marine aquaculture area. Int. J. Environ. Res. Public Health 2020, 17, 1446. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Wei, Q.; An, D. Intelligent monitoring and control technologies of open sea cage culture: A review. Comput. Electron. Agric. 2020, 169, 105119. [Google Scholar] [CrossRef]
- Mai, C. Transforming the Growth Mode is the Only Way for the Sustainable Development of Aquaculture in China. Fish. Inf. Strategy 2012, 27, 1–6. [Google Scholar]
- Jiang, X.; Dong, S.; Liu, R.; Huang, M.; Dong, K.; Ge, J.; Zhou, Y. Effects of temperature, dissolved oxygen, and their interaction on the growth performance and condition of rainbow trout (Oncorhynchus mykiss). J. Therm. Biol. 2021, 98, 102928. [Google Scholar] [CrossRef] [PubMed]
- Reddythota, D.; Timotewos, M.T. Evaluation of Pollution Status and Detection of the Reason for the Death of Fish in Chamo Lake, Ethiopia. J. Environ. Public Health 2022, 2022, 5859132. [Google Scholar] [CrossRef] [PubMed]
- Loos, S.; Shin, C.M.; Sumihar, J.; Kim, K.; Cho, J.; Weerts, A.H. Ensemble data assimilation methods for improving river water quality forecasting accuracy. Water Res. 2020, 171, 115343. [Google Scholar] [CrossRef] [PubMed]
- Asadollah, S.B.H.S.; Sharafati, A.; Motta, D.; Motta, D.; Yaseen, Z.M. River water quality index prediction and uncertainty analysis: A comparative study of machine learning models. J. Environ. Chem. Eng. 2021, 9, 104599. [Google Scholar] [CrossRef]
- Su, X.; He, X.; Zhang, G.; Chen, Y.; Li, K. Research on SVR water quality prediction model based on improved sparrow search algorithm. Comput. Intell. Neurosci. 2022, 2022, 7327072. [Google Scholar] [CrossRef] [PubMed]
- Jamroen, C.; Yonsiri, N.; Odthon, T.; Wisitthiwong, N.; Janreung, S. A standalone photovoltaic/battery energy-powered water quality monitoring system based on narrowband internet of things for aquaculture: Design and implementation. Smart Agric. Technol. 2023, 3, 100072. [Google Scholar] [CrossRef]
- Mashala, M.J.; Dube, T.; Mudereri, B.T.; Ayisi, K.K.; Ramudzuli, M.R. A Systematic Review on Advancements in Remote Sensing for Assessing and Mon-itoring Land Use and Land Cover Changes Impacts on Surface Water Resources in Semi-Arid Tropical Environments. Remote Sens. 2023, 15, 3926. [Google Scholar] [CrossRef]
- Prapti, D.R.; Mohamed Shariff, A.R.; Che Man, H.; Ramli, N.M.; Perumal, T.; Shariff, M. Internet of Things (IoT)-based aquaculture: An overview of IoT application on water quality monitoring. Rev. Aquac. 2022, 14, 979–992. [Google Scholar] [CrossRef]
- Rastegari, H.; Nadi, F.; Lam, S.S.; Abdullah, M.I.; Kasan, N.A.; Rahmat, R.F.; Mahari, W.A.W. Internet of Things in aquaculture: A review of the challenges and potential solutions based on current and future trends. Smart Agric. Technol. 2023, 4, 100187. [Google Scholar] [CrossRef]
- Ustaoğlu, F.; Tepe, Y.; Taş, B. Assessment of stream quality and health risk in a subtropical Turkey river system: A combined approach using statistical analysis and water quality index. Ecol. Indic. 2020, 113, 105815. [Google Scholar] [CrossRef]
- Zhi, W.; Feng, D.; Tsai, W.P.; Sterle, G.; Harpold, A.; Shen, C.; Li, L. From hydrometeorology to river water quality: Can a deep learning model predict dissolved oxygen at the continental scale? Environ. Sci. Technol. 2021, 55, 2357–2368. [Google Scholar] [CrossRef]
- Huan, J.; Li, H.; Li, M.; Chen, B. Prediction of dissolved oxygen in aquaculture based on gradient boosting decision tree and long short-term memory network: A study of Chang Zhou fishery demonstration base, China. Comput. Electron. Agric. 2020, 175, 105530. [Google Scholar] [CrossRef]
- Li, W.; Wu, H.; Zhu, N.; Jiang, Y.; Tan, J.; Guo, Y. Prediction of dissolved oxygen in a fishery pond based on gated recurrent unit (GRU). Inf. Process. Agric. 2021, 8, 185–193. [Google Scholar] [CrossRef]
- Tung, T.M.; Yaseen, Z.M. A survey on river water quality modelling using artificial intelligence models: 2000–2020. J. Hydrol. 2020, 585, 124670. [Google Scholar]
- Jiang, Y.; Nan, Z.; Yang, S. Risk assessment of water quality using Monte Carlo simulation and artificial neural network method. J. Environ. Manag. 2013, 122, 130–136. [Google Scholar] [CrossRef]
- Kadam, A.K.; Wagh, V.M.; Muley, A.A.; Umrikar, B.N.; Sankhua, R.N. Prediction of water quality index using artificial neural network and multiple linear regression modelling approach in Shivganga River basin, India. Model. Earth Syst. Environ. 2019, 5, 951–962. [Google Scholar] [CrossRef]
- Zare Abyaneh, H. Evaluation of multivariate linear regression and artificial neural networks in prediction of water quality parameters. J. Environ. Health Sci. Eng. 2014, 12, 40. [Google Scholar] [CrossRef]
- Khan MS, I.; Islam, N.; Uddin, J.; Islam, S.; Nasir, M.K. Water quality prediction and classification based on principal component regression and gradient boosting classifier approach. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4773–4781. [Google Scholar]
- Xu, C.; Chen, X.; Zhang, L. Predicting river dissolved oxygen time series based on stand-alone models and hybrid wavelet-based models. J. Environ. Manag. 2021, 295, 113085. [Google Scholar] [CrossRef]
- Li, Z.; Peng, F.; Niu, B.; Wu, J.; Miao, Z. Water quality prediction model combining sparse auto-encoder and LSTM network. IFAC Pap. 2018, 51, 831–836. [Google Scholar] [CrossRef]
- Paine, A.; Wokingham, U.K. Distribution, and Reproduction in any Medium, Provided the Original Work Is Properly Cited; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar]
- Guo, J.; Dong, J.; Zhou, B.; Zhao, X.; Liu, S.; Han, Q.; Hassan, S.G. A hybrid model for the prediction of dissolved oxygen in seabass farming. Comput. Electron. Agric. 2022, 198, 106971. [Google Scholar] [CrossRef]
- Huang, J.; Liu, S.; Hassan, S.G.; Xu, L.; Huang, C. A hybrid model for short-term dissolved oxygen content prediction. Comput. Electron. Agric. 2021, 186, 106216. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Chen, L.; Wang, Q.; Zhao, M. Water Quality Prediction for Hanjiang with Optimized Support Vector Regression. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 832–837. [Google Scholar]
- Li, T.; Lu, J.; Wu, J.; Zhang, Z.; Chen, L. Predicting Aquaculture Water Quality Using Machine Learning Approaches. Water 2022, 14, 2836. [Google Scholar] [CrossRef]
- Negi, G.; Kumar, A.; Pant, S.; Pant, S.; Ram, M. GWO: A review and applications. Int. J. Syst. Assur. Eng. Manag. 2021, 12, 1–8. [Google Scholar] [CrossRef]
- Deng, W.; Shang, S.; Cai, X.; Zhao, H.; Song, Y.; Xu, J. An improved differential evolution algorithm and its application in optimization problem. Soft Comput. 2021, 25, 5277–5298. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Shrestha, N. Factor analysis as a tool for survey analysis. Am. J. Appl. Math. Stat. 2021, 9, 4–11. [Google Scholar] [CrossRef]
- Zhang, F.; O’Donnell, L.J. Support Vector Regression. In Machine Learning; Academic Press: New York, NY, USA, 2020; pp. 123–140. [Google Scholar]
- Opara, K.R.; Arabas, J. Differential Evolution: A survey of theoretical analyses. Swarm Evol. Comput. 2019, 44, 546–558. [Google Scholar] [CrossRef]
- Sharma, I.; Kumar, V.; Sharma, S. A comprehensive survey on grey wolf optimization. Recent Adv. Comput. Sci. Commun. 2022, 15, 323–333. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Point | PH | Water Temperature (°C) | Dissolved Oxygen (mg/L) | Conductivity (μS/cm) | Salinity | Total Dissolved Solids (mg/L) |
|---|---|---|---|---|---|---|
| 01 | 5.64 | 27.1 | 5.8 | 440 | 0.22 | 220 |
| 02 | 5.39 | 27.1 | 5.9 | 440 | 0.22 | 218 |
| 03 | 5.36 | 27.1 | 5.7 | 438 | 0.22 | 218 |
| 04 | 5.64 | 27.0 | 5.8 | 430 | 0.22 | 220 |
| …… | …… | …… | …… | …… | …… | …… |
| 371 | 5.2 | 27.2 | 5.9 | 353 | 0.18 | 176 |
| Min | 5.17 | 25.9 | 3.4 | 19.7 | 0.03 | 10 |
| Max. | 6.97 | 28.2 | 9.9 | 512 | 0.26 | 256 |
| Mean | 6.04 | 26.8 | 6.4 | 275.7 | 0.14 | 136.7 |
| Std | 0.41 | 0.53 | 1.44 | 0.057 | 0.05 | 58.5 |
| Model\Indicators | R2 | MSE | MAE | RMSE |
|---|---|---|---|---|
| BPNN | 0.73 | 0.484 | 0.5434 | 0.6961 |
| GA-BPNN | 0.81 | 0.334 | 0.3971 | 0.5785 |
| PSO-BPNN | 0.86 | 0.254 | 0.3889 | 0.5043 |
| GWO-BPNN DE-GWO-BPNN | 0.84 0.86 | 0.294 0.245 | 0.4051 0.3391 | 0.5427 0.4952 |
| SVR | 0.78 | 0.396 | 0.4792 | 0.6294 |
| GA-SVR | 0.89 | 0.202 | 0.2696 | 0.4502 |
| PSO-SVR | 0.86 | 0.253 | 0.4221 | 0.5040 |
| GWO-SVR | 0.91 | 0.163 | 0.3076 | 0.4038 |
| DE-GWO-SVR | 0.94 | 0.108 | 0.2629 | 0.3293 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, X.; Jiang, Y.; Zhang, L.; Liu, B.; Chen, L.; Zhang, W.; Xie, L.; Liu, X.; Qu, F.; Wu, R. Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model. Appl. Sci. 2024, 14, 856. https://doi.org/10.3390/app14020856
Bao X, Jiang Y, Zhang L, Liu B, Chen L, Zhang W, Xie L, Liu X, Qu F, Wu R. Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model. Applied Sciences. 2024; 14(2):856. https://doi.org/10.3390/app14020856
Chicago/Turabian StyleBao, Xingsheng, Yilun Jiang, Lintong Zhang, Bo Liu, Linjie Chen, Wenqing Zhang, Lihang Xie, Xinze Liu, Fangfang Qu, and Renye Wu. 2024. "Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model" Applied Sciences 14, no. 2: 856. https://doi.org/10.3390/app14020856
APA StyleBao, X., Jiang, Y., Zhang, L., Liu, B., Chen, L., Zhang, W., Xie, L., Liu, X., Qu, F., & Wu, R. (2024). Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model. Applied Sciences, 14(2), 856. https://doi.org/10.3390/app14020856