
Highway Construction Safety Analysis Using Large Language Models

Abstract
:Featured Application
Abstract
1. Introduction
2. Literature Review
2.1. Status of Construction Safety
2.2. Natural Language Processing in Construction
2.3. Limited Exploration of Generative AI
3. Database and Methods
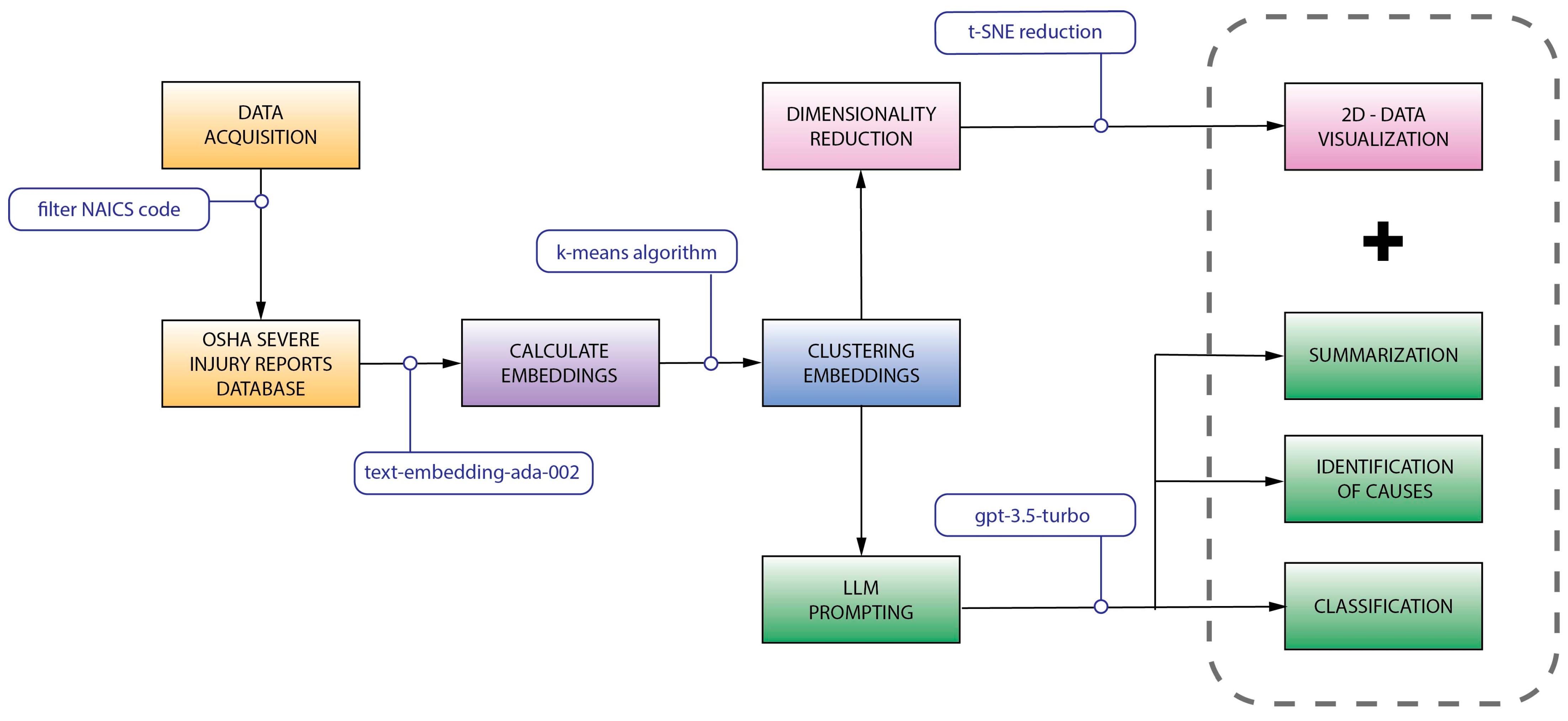
3.1. Research Framework: An Overview
3.2. OSHA SIR Database Acquisition and Description
3.3. Calculating Embeddings
3.4. Clustering Embeddings
3.5. Dimensionality Reduction
3.6. LLM Summarization and Cause Identification
3.7. LLM Classification
4. Results and Discussion
4.1. Clustering Embeddings
4.2. LLM Summarization and Cause Identification
4.3. LLM Classification
4.4. Post-Classification Summary Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Shabbani, Z.; Sturgill, R.; Dadi, G.B. Developing a Pre-Task Safety Briefing Tool for Kentucky Maintenance Personnel. Transp. Res. Rec. 2018, 2672, 187–197. [Google Scholar] [CrossRef]
- Kazan, E.; Usmen, M.A. Worker safety and injury severity analysis of earthmoving equipment accidents. J. Saf. Res. 2018, 65, 73–81. [Google Scholar] [CrossRef]
- Abdolahi, F.H.; Variani, A.S.; Varmazyar, S. Predicting Ability of Dynamic Balance in Construction Workers Based on Demographic Information and Anthropometric Dimensions. Saf. Health Work 2021, 12, 511–516. [Google Scholar] [CrossRef] [PubMed]
- Kaur, H.; Wurzelbacher, S.J.; Bushnell, P.T.; Bertke, S.; Meyers, A.R.; Grosch, J.W.; Naber, S.J.; Lampl, M. Occupational Injuries among construction workers by age and related economic loss: Findings from Ohio workers’ compensation, USA: 2007–2017. Saf. Health Work 2023, 14, 406–414. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Tabesh, M.; Dadashova, B.; Dobrovolny, C. Diagnosis of Encroachment-Related Work-Zone Crashes by Applying Pattern Recognition. Transp. Res. Rec. 2023, 2677, 222–236. [Google Scholar] [CrossRef]
- Hinze, J.; Huang, X.; Terry, L. The Nature of Struck-by Accidents. J. Constr. Eng. Manag. 2005, 131, 262–268. [Google Scholar] [CrossRef]
- Valcamonico, D.; Baraldi, P.; Amigoni, F.; Zio, E. A framework based on Natural Language Processing and Machine Learning for the classification of the severity of road accidents from reports. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022. [Google Scholar] [CrossRef]
- Cambraia, F.B.; Saurin, T.A.; Formoso, C.T. Identification, analysis and dissemination of information on near misses: A case study in the construction industry. Saf. Sci. 2010, 48, 91–99. [Google Scholar] [CrossRef]
- Chokor, A.; Naganathan, H.; Chong, W.K.; Asmar, M.E. Analyzing Arizona OSHA Injury Reports Using Unsupervised Machine Learning. Procedia Eng. 2016, 145, 1588–1593. [Google Scholar] [CrossRef]
- Jeon, J.; Xu, X.; Zhang, Y.; Yang, L.; Cai, H. Extraction of Construction Quality Requirements from Textual Specifications via Natural Language Processing. Transp. Res. Rec. 2021, 2675, 222–237. [Google Scholar] [CrossRef]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.D.; Lu, Z.; Ye, C. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar] [CrossRef]
- Chen, P.; Fu, G.; Wang, Y.; Meng, H.; Lv, M. Accident causation models: A comparison of SCM and 24Model. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 237, 810–822. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is All you Need; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar] [CrossRef]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Fedus, W. Emergent Abilities of Large Language Models. arXiv 2022, arXiv:2206.07682v2. [Google Scholar]
- Dhalmahapatra, K.; Shingade, R.; Mahajan, H.; Verma, A.; Maiti, J. Decision support system for safety improvement: An approach using multiple correspondence analysis, t-SNE algorithm and K-means clustering. Comput. Ind. Eng. 2019, 128, 277–289. [Google Scholar] [CrossRef]
- Alateeq, M.M.; Fathimathul Rajeena, P.P.; Ali, M.A.S. Construction Site Hazards Identification Using Deep Learning and Computer Vision. Sustainability 2023, 15, 2358. [Google Scholar] [CrossRef]
- Shohet, I.M.; Luzi, M.; Tarshish, M. Optimal allocation of resources in construction safety: Analytical-empirical model. Saf. Sci. 2018, 104, 231–238. [Google Scholar] [CrossRef]
- Uddin, S.M.J.; Albert, A.; Ovid, A.; Alsharef, A. Leveraging ChatGPT to Aid Construction Hazard Recognition and Support Safety Education and Training. Sustainability 2023, 15, 7121. [Google Scholar] [CrossRef]
- Li, J.; Wu, C. Deep Learning and Text Mining: Classifying and Extracting Key Information from Construction Accident Narratives. Appl. Sci. 2023, 13, 10599. [Google Scholar] [CrossRef]
- Ballal, S.; Patel, D. Enhancing Construction Site Safety: Natural Language Processing for Hazards Identification and Prevention. J. Eng. Proj. Prod. Manag. 2024, 14, 1–11. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, F.; Gong, G.; Yang, H.; Han, D. Intelligent technologies for construction machinery using data-driven methods. Autom. Constr. 2023, 147, 104711. [Google Scholar] [CrossRef]
- Yoo, B.; Kim, J.; Park, S.; Ahn, C.R.; Oh, T. Harnessing Generative Pre-Trained Transformers for Construction Accident Prediction with Saliency Visualization. Appl. Sci. 2024, 14, 664. [Google Scholar] [CrossRef]
- Ganguli, R.; Miller, P.; Pothina, R. Effectiveness of Natural Language Processing Based Machine Learning in Analyzing Incident Narratives at a Mine. Minerals 2021, 11, 776. [Google Scholar] [CrossRef]
- Shen, Q.; Wu, S.; Deng, H.; Cheng, J.C.P. BIM-Based Dynamic Construction Safety Rule Checking Using Ontology and Natural Language Processing. Buildings 2022, 12, 564. [Google Scholar] [CrossRef]
- Hong, Y.; Xie, H.; Bhumbra, G.; Brilakis, I. Comparing Natural Language Processing Methods to Cluster Construction Schedules. J. Constr. Eng. Manag. 2021, 147. [Google Scholar] [CrossRef]
- Goh, Y.M.; Ubeynarayana, C.U. Construction accident narrative classification: An evaluation of text mining techniques. Accid. Anal. Prev. 2017, 108, 122–130. [Google Scholar] [CrossRef]
- Ricketts, J.; Barry, D.; Guo, W.; Pelham, J. A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports. Safety 2023, 9, 22. [Google Scholar] [CrossRef]
- Prieto, S.A.; Mengiste, E.T.; García de Soto, B. Investigating the Use of ChatGPT for the Scheduling of Construction Projects. Buildings 2023, 13, 857. [Google Scholar] [CrossRef]
- Li, G.; Wang, X. Construction and Path of Urban Public Safety Governance and Crisis Management Optimization Model Integrating Artificial Intelligence Technology. Sustainability 2023, 15, 7487. [Google Scholar] [CrossRef]
- Pothina, R.; Ganguli, R. Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives. Minerals 2023, 13, 770. [Google Scholar] [CrossRef]
- Saka, N.; Taiwo, R.; Salami, B.A.; Ajayi, S.; Akande, K.; Kazemi, H. GPT models in construction industry: Opportunities, limitations, and a use case validation. Dev. Built Environ. 2024, 17, 100300. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Amodei, D. Language Models Are Few-Shot Learners; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar] [CrossRef]
- Dieng, A.B.; Ruiz, F.J.R.; Blei, D.M. Topic Modeling in Embedding Spaces. Trans. Assoc. Comput. Linguist. 2020, 8, 439–453. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks; Association for Computational Linguistics: Toronto, ON, Canada, 2019; Available online: http://arxiv.org/abs/1908.10084 (accessed on 23 May 2023).
- Harris, Z.S. Distributional Structure. WORD 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB: Massive Text Embedding Benchmark; Association for Computational Linguistics: Toronto, ON, Canada, 2023; Available online: http://arxiv.org/abs/2210.07316 (accessed on 11 July 2023).
- Heidarysafa, M.; Kowsari, K.; Barnes, L.; Brown, D. Analysis of Railway Accidents’ Narratives Using Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018. [Google Scholar] [CrossRef]
- Neelakantan, A.; Xu, T.; Puri, R.; Radford, A.; Han, J.M.; Tworek, J.; Weng, L. Text and Code Embeddings by Contrastive Pre-Training. arXiv 2022, arXiv:2201.10005. [Google Scholar] [CrossRef]
- Yassin, S.S. Road accident prediction and model interpretation using a hybrid K-means and random forest algorithm approach. SN Appl. Sci. 2020, 2, 1576. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G.; Cuomo, S. An analytic framework using deep learning for prediction of traffic accident injury severity based on contributing factors. Accid. Anal. Prev. 2021, 160, 106322. [Google Scholar] [CrossRef] [PubMed]
- Deng, F.; Gu, W.; Zeng, W.; Zhang, Z.; Wang, F. Hazardous Chemical Accident Prevention Based on K-Means Clustering Analysis of Incident Information. IEEE Access 2020, 8, 180171–180183. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Viualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. Available online: http://jmlr.org/papers/v9/vandermaaten08a.html (accessed on 24 May 2023).
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 17 July 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. 2019. Available online: https://api.semanticscholar.org/CorpusID:16002553 (accessed on 17 July 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Column * | Unique Values | Top 5 Entries ‡ | Frequency § | |
|---|---|---|---|---|
| SIR | 237310 † | |||
| “NatureTitle” Nature of Injury or Illness | 503 | 58 | Fractures | 35% |
| Amputations | 18% | |||
| Soreness, pain, hurt—unspecified injury | 8% | |||
| Cuts, lacerations | 7% | |||
| Heat (thermal) burns, unspecified | 3% | |||
| “Part_of_Body_Title” Part of Body Affected | 166 | 82 | Multiple body parts, n.e.c. | 9% |
| Leg(s), unspecified | 7% | |||
| Fingertip(s) | 7% | |||
| Finger(s), fingernail(s), n.e.c. | 6% | |||
| Body systems | 6% | |||
| “EventTitle” Event or Exposure | 342 | 460 | Compressed or pinched by shifting objects or equipment | 8% |
| Injured by slipping or swinging object held by injured worker | 5% | |||
| Pedestrian struck by forward-moving vehicle in work zone | 5% | |||
| Exposure to environmental heat | 5% | |||
| Other fall to lower level, unspecified | 4% | |||
| “SourceTitle” Source of Injury or Illness | 1407 | 230 | Highway vehicle, motorized, unspecified | 5% |
| Heat—environmental | 5% | |||
| Nonclassifiable | 4% | |||
| Saw-powered, except chainsaws | 3% | |||
| Dump truck | 3% | |||
| Cluster No. and Title * | Summary † |
|---|---|
| Cluster 1 Struck by Vehicle or Heavy Equipment | The road construction incidents involve a wide range of injuries, including fractures, head injuries, and back injuries, with many employees requiring hospitalization. The incidents highlight the importance of proper safety protocols, such as wearing seat belts and using proper equipment, to prevent accidents and injuries on road construction sites. The incidents also demonstrate the need for ongoing safety training and vigilance in the road construction industry. The incidents involve employees being struck by vehicles or equipment, either while working alongside the road or while performing tasks such as loading or unloading equipment. The incidents emphasize the need for increased safety measures and awareness in the road construction industry to prevent further accidents and injuries, including the importance of proper traffic control and the dangers of distracted driving. The incidents also show the importance of proper footwear, the dangers of working in close proximity to moving vehicles, and the need for proper maintenance of equipment. |
| Cluster 2 Contact with Objects or Equipment | The incidents range from employees being struck by objects or run over by equipment to suffering severe lacerations and fractures, resulting in hospitalization and surgery. Many incidents involve the use of heavy machinery, while others involve slips and trips on uneven surfaces or debris. The incidents emphasize the importance of prioritizing safety in the workplace through ongoing safety training, awareness, supervision, communication, and hazard identification to ensure a safe work environment for all employees. Commonalities between the incidents include employees being struck by equipment, suffering fractures and lacerations, and being hospitalized for their injuries. The incidents also highlight the importance of proper clothing and equipment maintenance, as well as the need for caution when working in trenches or around heavy machinery. |
| Cluster 3 Heat-Related | All of the listed incidents involve employees working in road construction who suffered from heat-related illnesses or dehydration. Many employees were hospitalized due to symptoms such as heat exhaustion, cramping, and dehydration. The incidents occurred during hot weather conditions, with some employees working in temperatures as high as 86 degrees. The affected employees were performing a variety of tasks, including paving, welding, shoveling, and flagging. The incidents highlight the importance of proper hydration and heat safety measures in road construction work. |
| Cluster 4 Falling Objects or Personnel | The road construction incidents involved a variety of tasks and equipment, resulting in a range of injuries from falls, being struck by falling objects, being caught in between objects, and tripping. Safety equipment was not always used properly or was unhooked at the time of the incident, and employees were not always using proper equipment or following proper procedures. Many of the incidents resulted in hospitalization and required emergency surgery, with injuries ranging from broken bones to electrical burns and partial amputations. Commonalities between the incidents include falls from heights, being struck by falling objects, and improper use of equipment or failure to follow proper procedures. |
| Cluster 5 Heated Materials or Equipment | These road construction incidents involve a range of injuries, including burns from hot materials such as asphalt and oil, exposure to chemicals like battery acid and gasoline, and electrical hazards. Many incidents occur while employees are working on or near machinery and are injured due to equipment malfunctions or accidents. Other incidents involve employees being struck by vehicles or falling from heights. Employers must ensure that employees are aware of the potential hazards and are equipped with the necessary protective gear to prevent injuries. Commonalities between the incidents include hot materials causing burns, equipment malfunctions leading to accidents, and employees being exposed to hazardous materials. |
| Cluster 6 Upper Limb Injuries | The road construction incidents continue to involve hand and finger injuries, with many resulting in amputations. The injuries were caused by a variety of tools and equipment, including saws, forklifts, cranes, and excavators. Many of the incidents involved pinch points or kickbacks, where the worker’s hand or finger was caught between two objects or pulled into a dangerous area. The commonalities between the incidents include the use of heavy machinery, pinch points, kickbacks, and human error, emphasizing the importance of proper training, safety protocols, and equipment maintenance to prevent these types of injuries. |
| Cluster No. | Manual Dissemination of Generated Summary |
|---|---|
| Cluster 1 | Incidents pertained to moving vehicles or equipment. Most of these vehicles were passenger vehicles, vans, and SUVs, indicating issues with traffic control at the work zone. It is unclear if the trucks involved in the accidents were passing traffic or construction trucks. Issues within the work zone were observed as well, with 18% of accidents involving construction equipment such as pavers, rollers, scrapers, and others. |
| Cluster 2 | Mainly consisted of incidents resulting in contact with objects, equipment, or equipment parts. Most accidents in this cluster involved struck-by accidents between an object/equipment/equipment part and a worker. These incidents seemed to occur inside the work zone and were not related to passing passenger traffic. |
| Cluster 3 | Almost entirely comprised of heat-related incidents. Some incidents (3 of the 53 cases) were related to heart attacks that do not seem directly heat-induced |
| Cluster 4 | Focused on incidents that were related to falling (either a worker or an object) from a certain height, with a majority of cases involving a worker falling. Some other incidents were related to objects or equipment parts falling onto workers. |
| Cluster 5 | Mostly related to incidents where workers suffer burns from heated materials or equipment, also including incidents related to electrical hazards. |
| Cluster 6 | Consisted of cases where workers suffered injuries to upper limbs, including damage to hands, fingers, or arms. These accidents are less severe in consequence, with approximately half of the accidents requiring some level of hospitalization. However, these accidents tend to result in permanent upper limb damage, with most accidents requiring amputation procedures. |
| Cluster No. and Title * | Top Three Major Causes † |
|---|---|
| Cluster 1 Struck by Vehicle or Heavy Equipment |
|
| Cluster 2 Contact with Objects or Equipment |
|
| Cluster 3 Heat-Related |
|
| Cluster 4 Falling Objects or Personnel |
|
| Cluster 5 Heated Materials or Equipment |
|
| Cluster 6 Upper Limb Injuries |
|
| Field | Precision | Recall | F1Score | Accuracy |
|---|---|---|---|---|
| EventTitle | 97.4 | 96.1 | 96.7 | 93.7 |
| NatureTitle | 96.0 | 94.4 | 95.2 | 90.8 |
| Part_of_Body_Title | 96.8 | 95.1 | 96.0 | 92.2 |
| SourceTitle | 96.8 | 96.6 | 96.7 | 93.6 |
| Hospitalization * | 89.2 | 85.4 | 87.3 | 78.0 |
| Amputation * | 88.4 | 92.3 | 90.3 | 96.5 |
| Hospitalization † | 88.2 | 77.8 | 82.7 | 71.2 |
| Amputation † | 95.6 | 95.6 | 95.6 | 98.4 |
| Hospitalization ‡ | 88.0 | 84.1 | 86.0 | 75.8 |
| Amputation ‡ | 91.5 | 95.0 | 93.2 | 97.6 |
| Hospitalization § | 89.5 | 88.7 | 89.1 | 80.8 |
| Amputation § | 84.5 | 93.4 | 88.7 | 95.8 |
| Cluster | EventTitle | NatureTitle | Part_of_Body_Title | SourceTitle |
|---|---|---|---|---|
| Cluster 1 Cases: 228/1031 Hospitalized: 99.6% Amputation: 1.8% | Pedestrian struck by forward-moving vehicle in work zone (21.9%) | Fractures (49.1%) | Nonclassifiable (11.8%) | Highway vehicle, motorized, unspecified (24.6%) |
| Pedestrian struck by vehicle in work zone, unspecified (9.6%) | Traumatic injuries and disorders, unspecified (7.5%) | Multiple body parts, n.e.c. (10.1%) | Dump truck (9.2%) | |
| Other fall to lower level, unspecified (7.0%) | Internal injuries to organs and blood vessels of the trunk (6.1%) | Leg(s), unspecified (10.1%) | Truck-motorized freight hauling and utility, unspecified (8.8%) | |
| Cluster 2 Cases: 238/1031 Hospitalized: 95.8% Amputation: 8.4% | Injured by slipping or swinging object held by injured worker (9.7%) | Fractures (49.6%) | Leg(s), unspecified (14.7%) | Saw-powered, except chainsaws (10.5%) |
| Pedestrian struck by vehicle in non-roadway area, unspecified (6.7%) | Cuts, lacerations (17.2%) | Lower leg(s) (11.8%) | Excavating machinery, unspecified (9.7%) | |
| Struck by falling object or equipment, n.e.c. (5.9%) | Amputations (8.0%) | Foot (feet), unspecified (10.9%) | Milling machines, cold planers, and road profilers (3.8%) | |
| Cluster 3 Cases: 53/1031 Hospitalized: 100% Amputation: 0% | Exposure to environmental heat (90.6%) | Effects of heat and light, n.e.c. (37.7%) | BODY SYSTEMS (90.6%) | Heat—environmental (90.6%) |
| Fall on same level, n.e.c. (1.9%) | Effects of heat and light, unspecified (26.4%) | Heart (5.7%) | Floors, walkways, ground surfaces, unspecified (1.9%) | |
| Fall through surface or existing opening, less than 6 feet (1.9%) | Heat exhaustion, prostration (13.2%) | Head, unspecified (1.9%) | Nonclassifiable (1.9%) | |
| Cluster 4 Cases: 210/1031 Hospitalized: 99% Amputation: 1% | Struck by falling object or equipment, n.e.c. (10.0%) | Fractures (68.6%) | Multiple body parts, n.e.c. (11.4%) | Bridges, dams, locks (12.9%) |
| Other fall to lower level, unspecified (9.5%) | Soreness, pain, hurt, unspecified injury (6.2%) | Leg(s), unspecified (10.5%) | Structural elements, n.e.c. (6.2%) | |
| Other fall to lower level, less than 6 feet (8.6%) | Internal injuries to organs and blood vessels of the trunk (4.8%) | Lower leg(s) (8.6%) | Beams—unattached metal (5.7%) | |
| Cluster 5 Cases: 89/1031 Hospitalized: 100% Amputation: 1.1% | Contact with hot objects or substances (23.6%) | Heat (thermal) burns, unspecified (25.8%) | Multiple body parts, n.e.c. (25.8%) | Paving asphalt, asphaltic cement (18.0%) |
| Ignition of vapors, gases, or liquids (9.0%) | Second-degree heat (thermal) burns (16.9%) | Nonclassifiable (11.2%) | Nonclassifiable (10.1%) | |
| Exposure through intact skin, eyes, or other exposed tissue (5.6%) | Third- or fourth-degree heat (thermal) burns (11.2%) | Leg(s), unspecified (6.7%) | Gasoline, diesel fuel, jet fuel (9.0%) | |
| Cluster 6 Cases: 213/1031 Hospitalized: 49.8% Amputation: 72.3% | Compressed or pinched by shifting objects or equipment (34.3%) | Amputations (71.4%) | Fingertip(s) (32.9%) | Nonclassifiable (8.9%) |
| Injured by slipping or swinging object held by injured worker (10.3%) | Cuts, lacerations (9.4%) | Finger(s), fingernail(s), n.e.c. (29.6%) | Saw-powered, except chainsaws (4.7%) | |
| Caught in running equipment or machinery during regular operation (8.5%) | Fractures (5.2%) | Finger(s), fingernail(s), unspecified (26.3%) | Cranes, unspecified (4.7%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smetana, M.; Salles de Salles, L.; Sukharev, I.; Khazanovich, L. Highway Construction Safety Analysis Using Large Language Models. Appl. Sci. 2024, 14, 1352. https://doi.org/10.3390/app14041352
Smetana M, Salles de Salles L, Sukharev I, Khazanovich L. Highway Construction Safety Analysis Using Large Language Models. Applied Sciences. 2024; 14(4):1352. https://doi.org/10.3390/app14041352
Chicago/Turabian StyleSmetana, Mason, Lucio Salles de Salles, Igor Sukharev, and Lev Khazanovich. 2024. "Highway Construction Safety Analysis Using Large Language Models" Applied Sciences 14, no. 4: 1352. https://doi.org/10.3390/app14041352