Fault Diagnosis Method of Box-Type Substation Based on Improved Conditional Tabular Generative Adversarial Network and AlexNet


Abstract
:1. Introduction
2. Research Status
2.1. Current Research Status of Fault Diagnosis Methods
- (1)
- Physical models
- (2)
- Statistical models
- (3)
- Artificial intelligence
2.2. Research Status of Small Sample Issues in Fault Diagnosis
- (1)
- Research on methods based on data preprocessing and model structure
- (2)
- Research on methods based on transfer learning
- (3)
- Research on methods based on generative adversarial learning
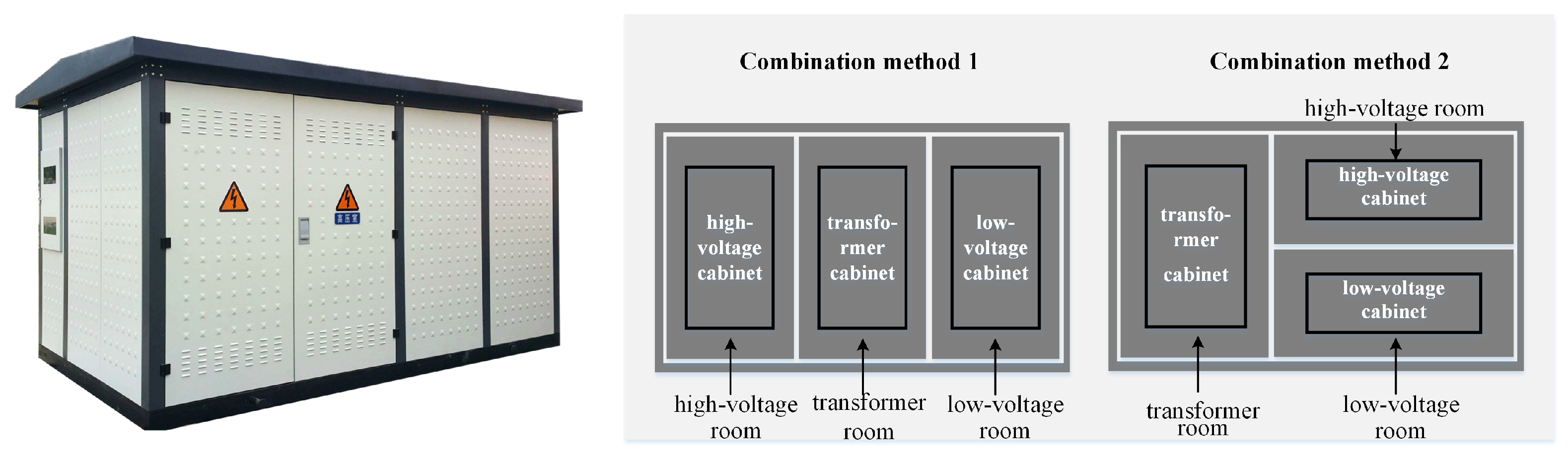
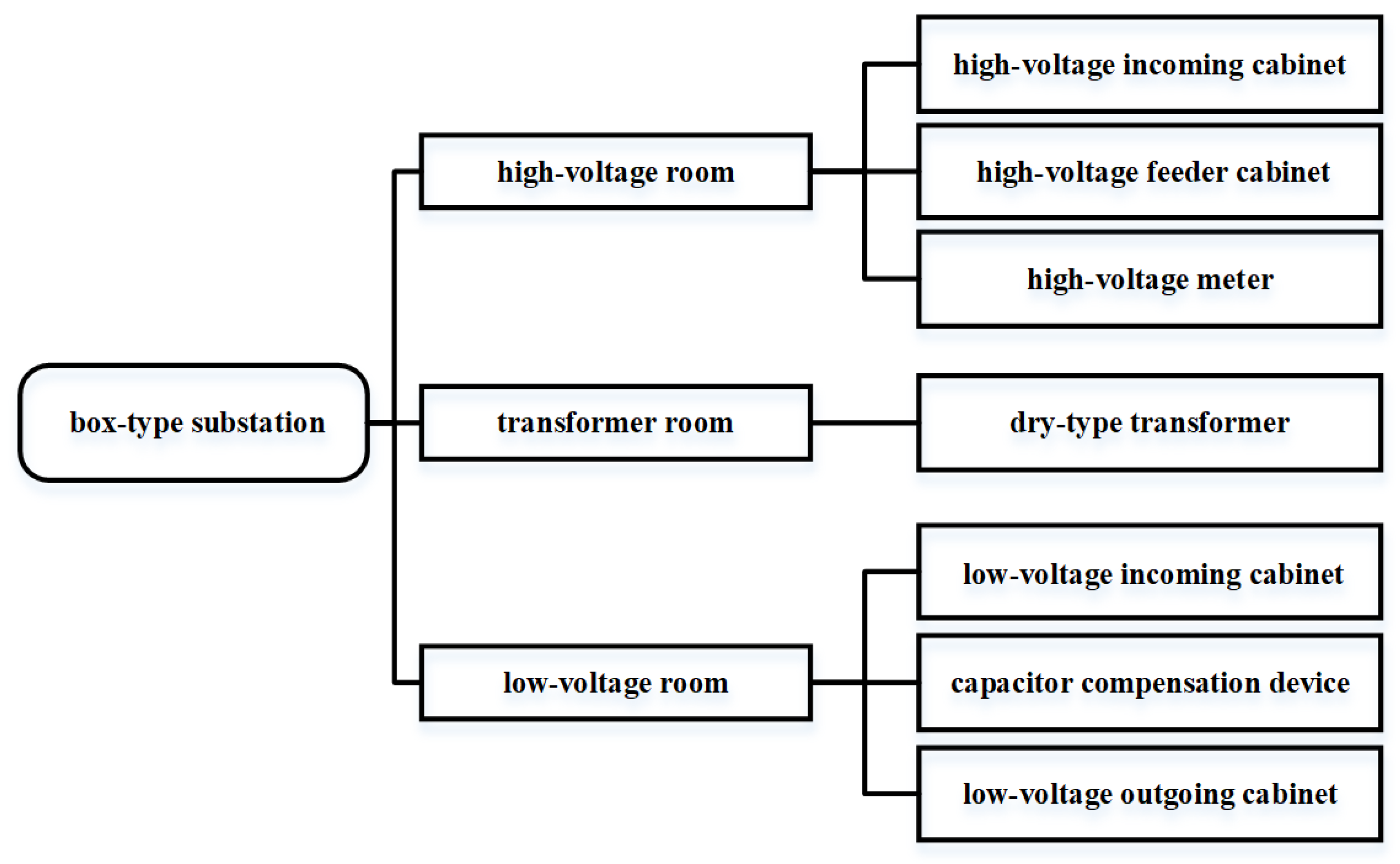
3. Main Fault Analysis of the Box-Type Substation
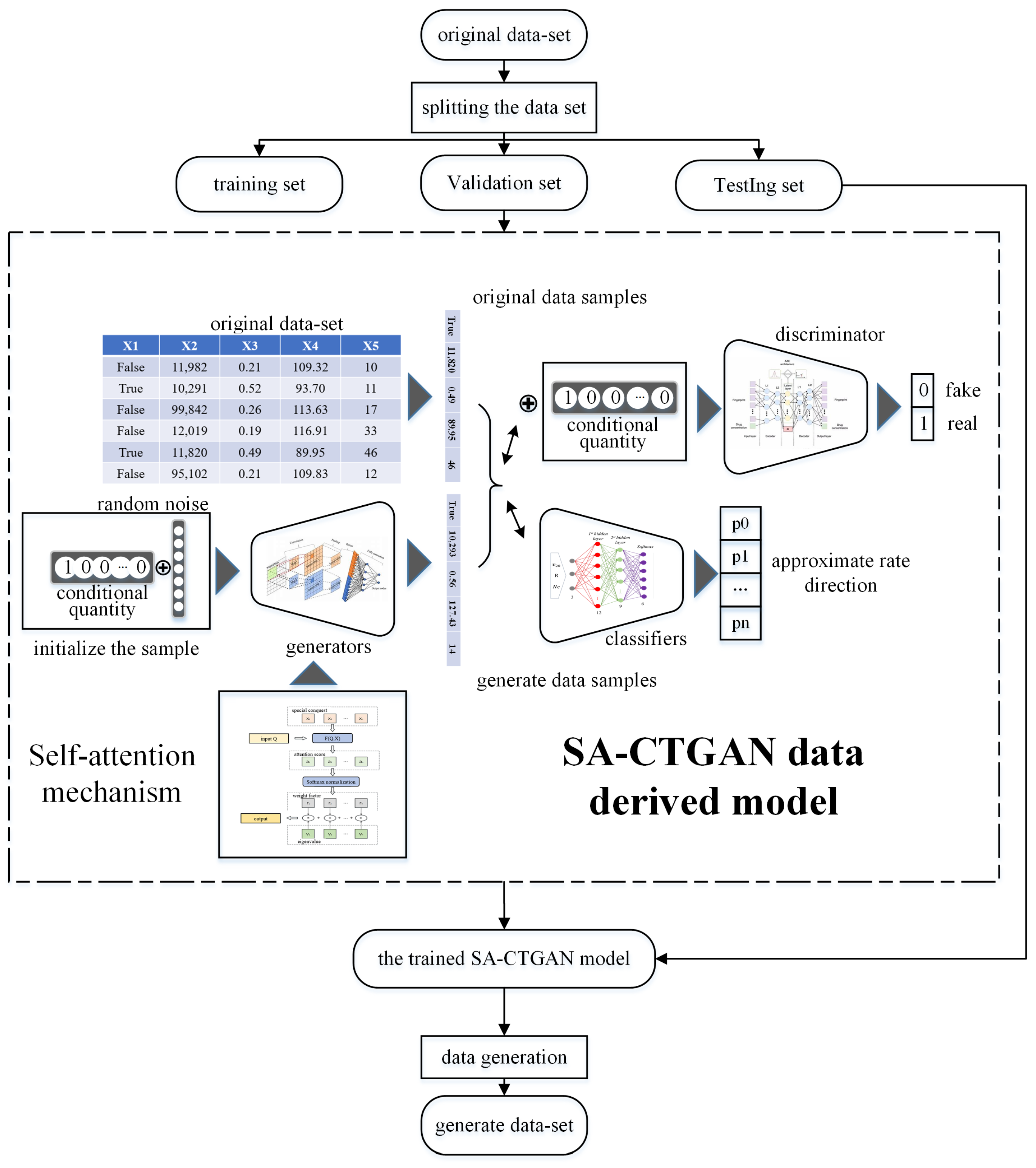
4. Research on the Data Derivation Method Based on CTGAN
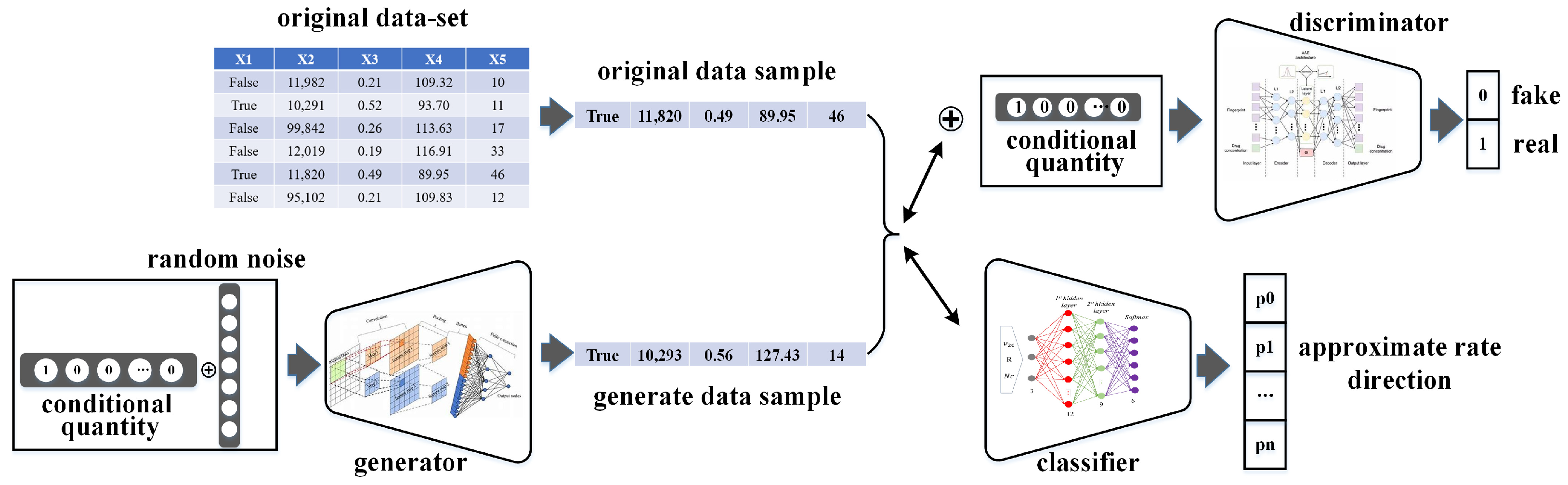
4.1. Principle of CTGAN
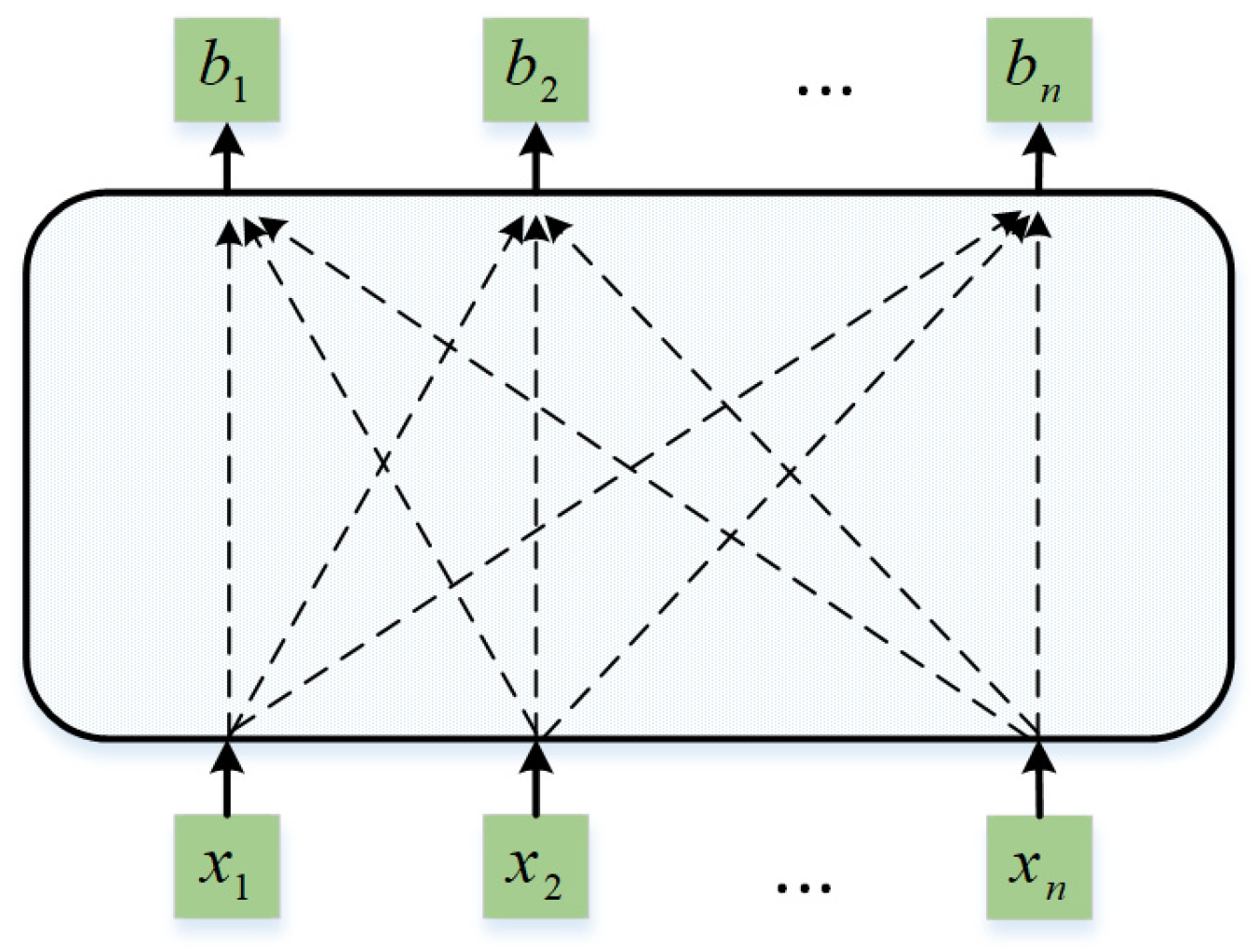
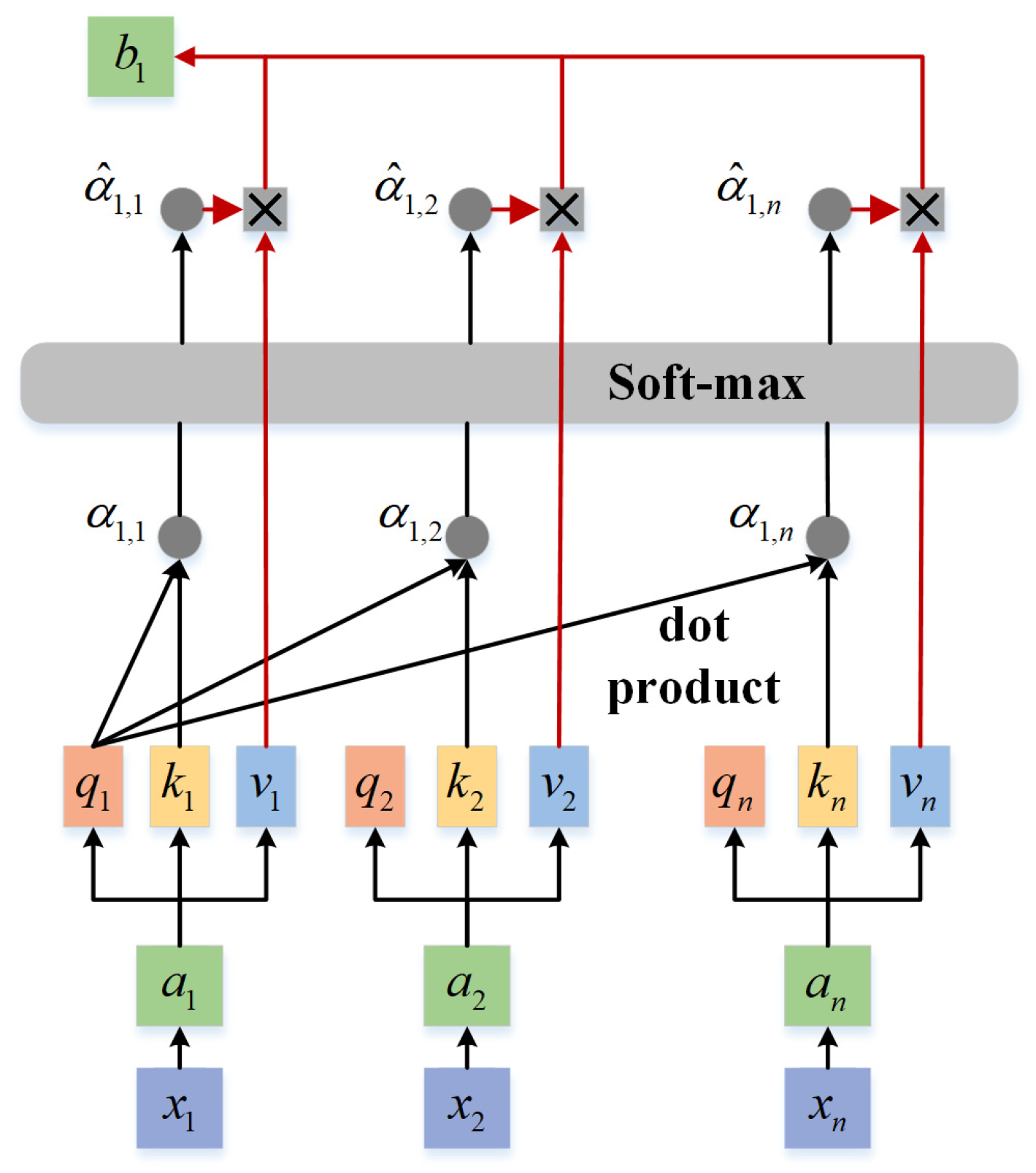
4.2. Principle of the Self-Attention Mechanism
4.3. SA-CTGAN Data-Derived Model
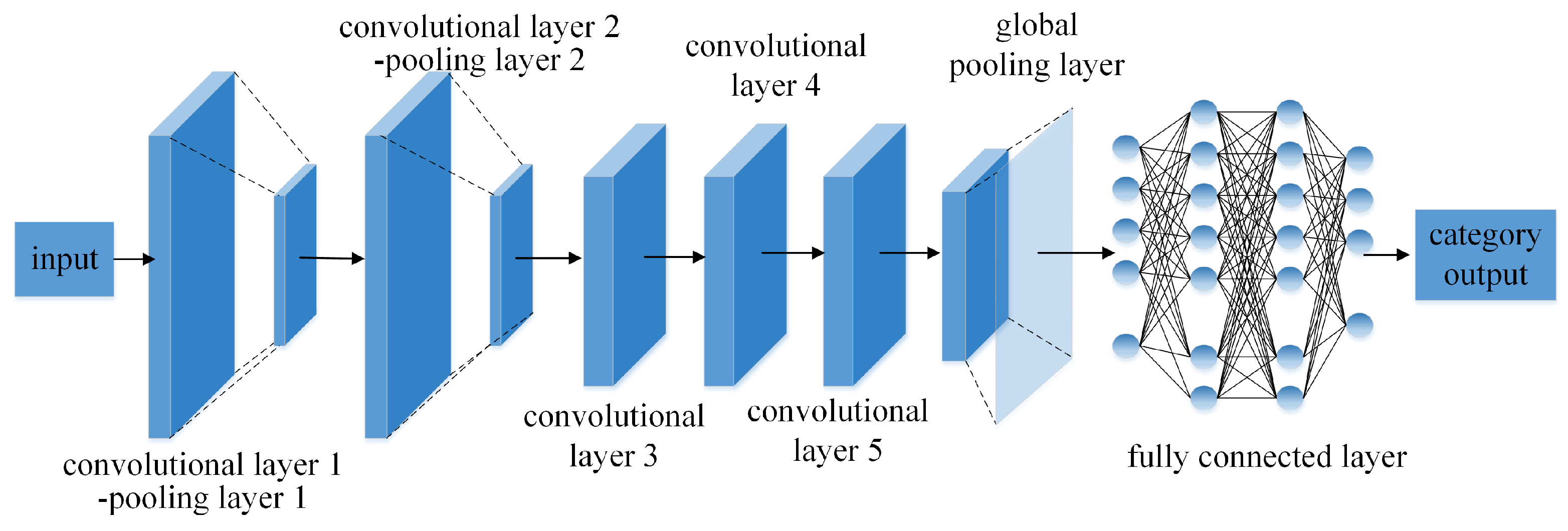
5. AlexNet Fault Diagnosis Model
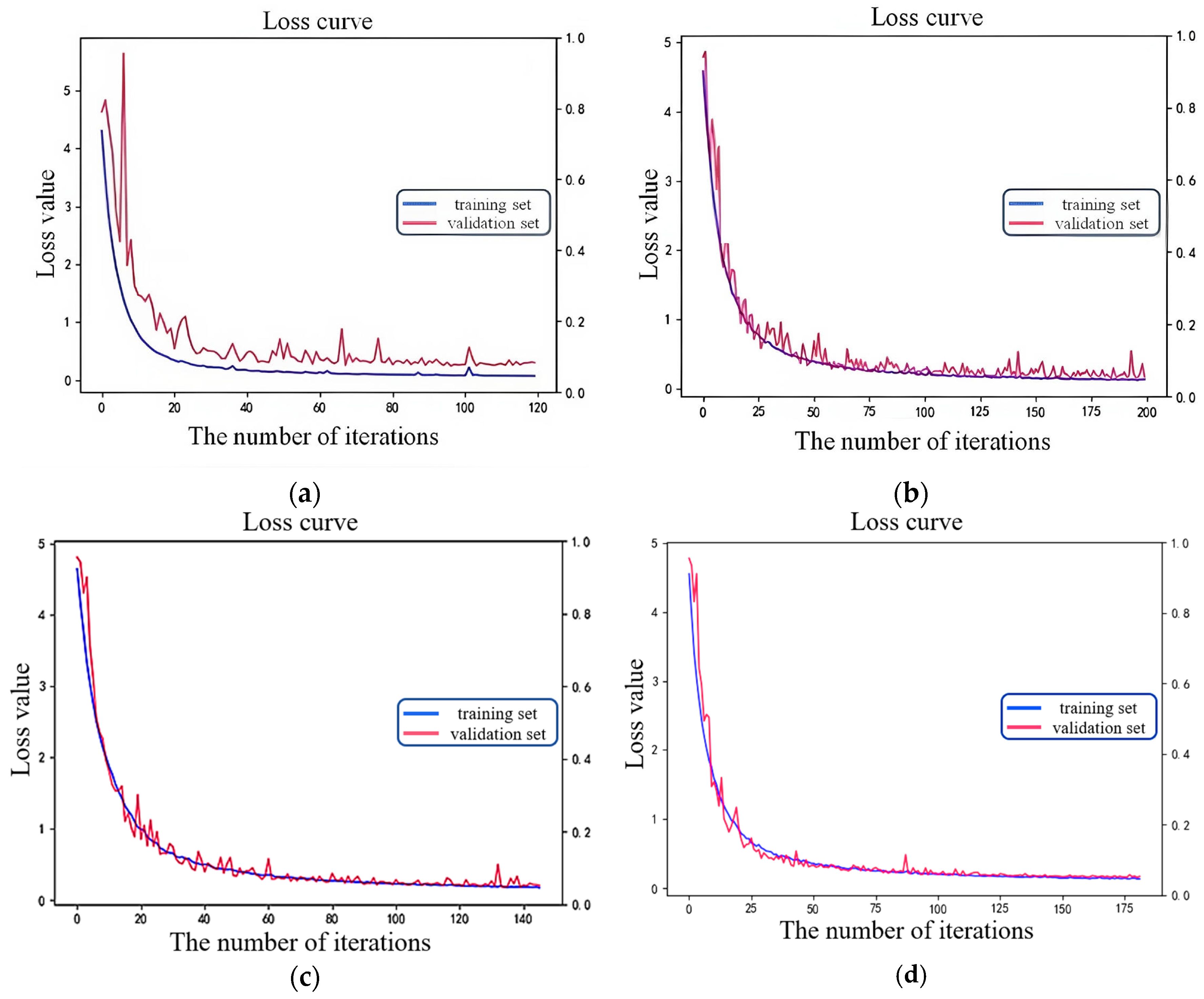
6. Experiment and Result Analysis
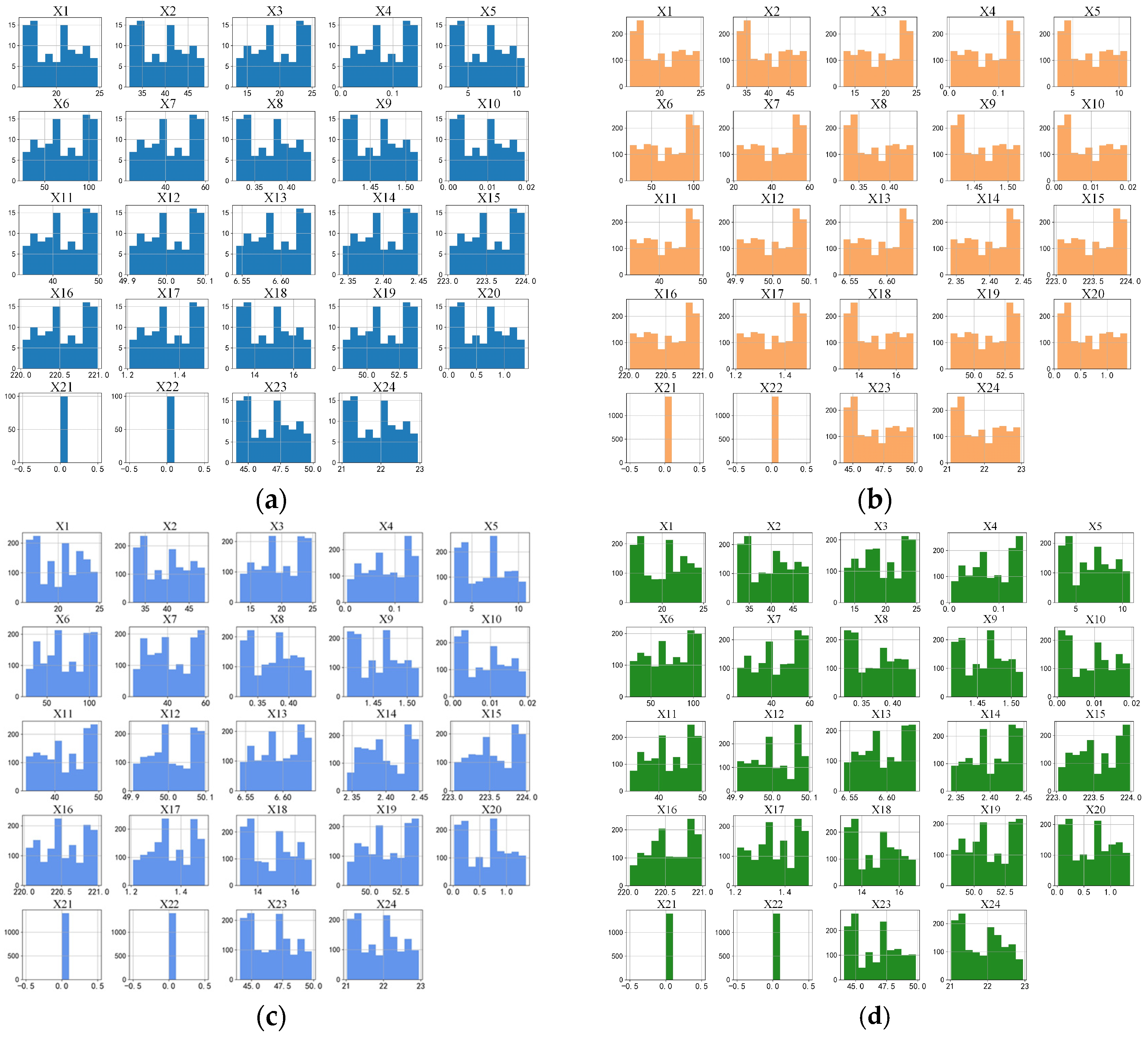
6.1. Evaluation Indicators of the Data-Derived Effect
- (1)
- KL divergence
- (2)
- Mean Cosine Similarity
- (3)
- Cumulative deviation of the correlation coefficient
- (4)
- Heatmap SSIM metric
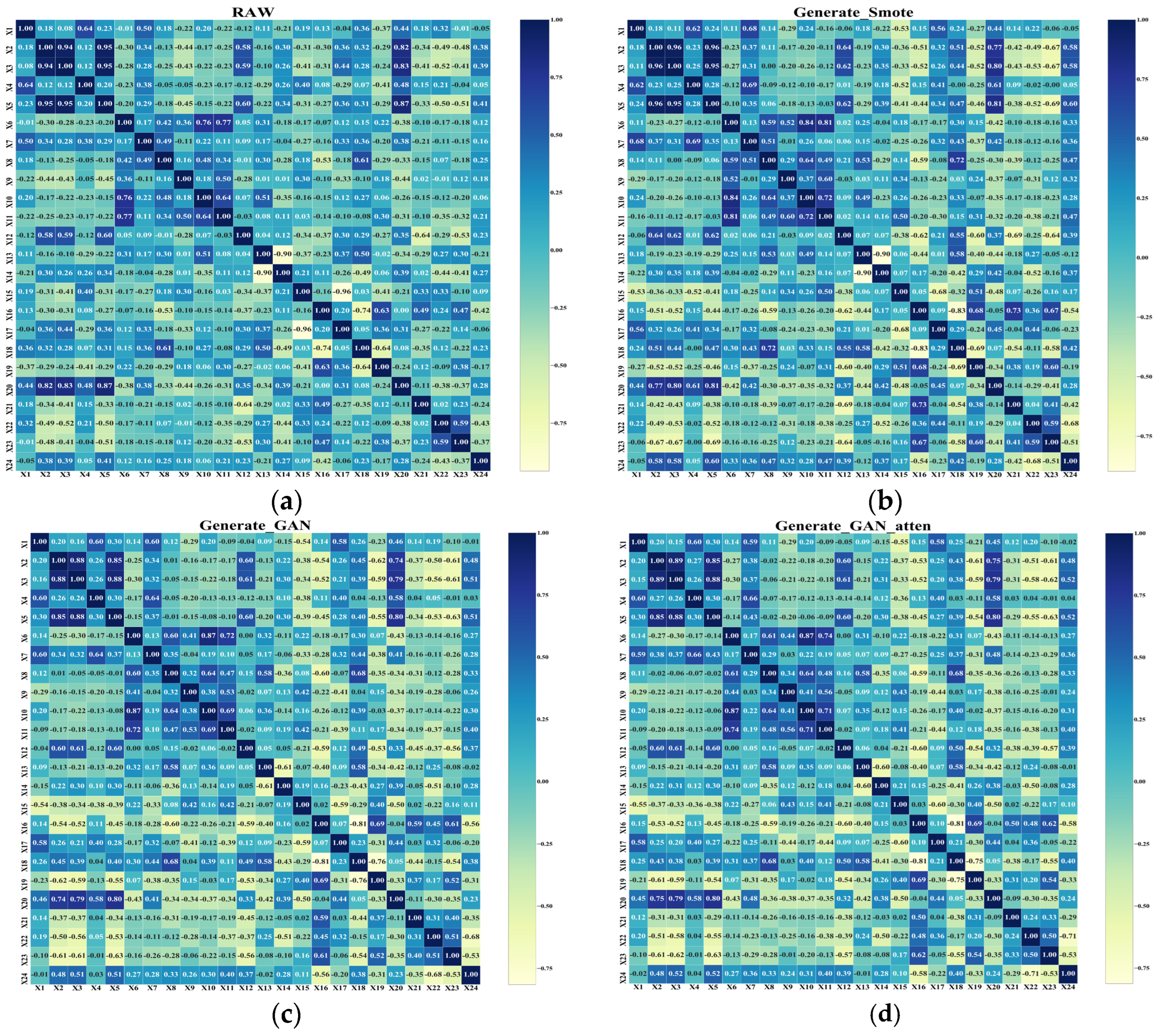
6.2. Comparative Analysis of Data-Derived Models
6.3. Fault Diagnosis Case Analysis of Different Datasets
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- E, D.; Zhang, L. Car Dumper Hydraulic System Fault Diagnosis Based on Multi-block MPCA. Chin. J. Mech. Eng. 2018, 29, 958–964. [Google Scholar]
- Qiu, Z.; Min, R.; Wang, D.; Fan, S. Energy features fusion based hydraulic cylinder seal wear and internal leakage fault diagnosis method. Measurement 2022, 195, 111042. [Google Scholar] [CrossRef]
- Xu, X.; Yan, X.; Sheng, C.; Yuan, C. A Belief Rule-Based Expert System for Fault Diagnosis of Marine Diesel Engines. IEEE Trans. Syst. Man Cybern. Syst. 2017, 50, 656–672. [Google Scholar] [CrossRef]
- Wen, X.; Xu, Z. Wind turbine fault diagnosis based on ReliefF-PCA and DNN. Expert Syst. Appl. 2021, 178, 115016. [Google Scholar] [CrossRef]
- Bai, R.; Meng, Z.; Xu, Q.; Fan, F. Fractional Fourier and time domain recurrence plot fusion combining convolutional neural network for bearing fault diagnosis under variable working conditions. Reliab. Eng. Syst. Saf. 2023, 232, 109076. [Google Scholar] [CrossRef]
- Jia, S.; Li, Y.; Wang, X.; Sun, D.; Deng, Z. Deep causal factorization network: A novel domain generalization method for cross-machine bearing fault diagnosis. Mech. Syst. Signal. Process. 2023, 192, 110228. [Google Scholar] [CrossRef]
- Huang, Y.; Liao, A.; Hu, D.; Shi, W.; Zheng, S. Multi-scale convolutional network with channel attention mechanism for rolling bearing fault diagnosis. Measurement 2022, 203, 111935. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Asoke, K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal. Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, J.; Chen, W. Data-driven fault diagnosis for PEMFC systems of hybrid tram based on deep learning. Int. J. Hydrog. Energy 2020, 45, 13483–13495. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S.; Zhou, H.; Sun, C.; Lu, Y. CHSMOTE: Convex hull-based synthetic minority oversampling technique for alleviating the class imbalance problem. J. Inf. Sci. 2023, 623, 324–341. [Google Scholar] [CrossRef]
- Jia, P.; Wang, C.; Zhou, F.; Hu, X. Trend Feature Consistency Guided Deep Learning Method for Minor Fault Diagnosis. Entropy 2023, 25, 242. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Chen, J.; Zhang, T.; Zhou, Z. A Compact Convolutional Neural Network Augmented with Multiscale Feature Extraction of Acquired Monitoring Data for Mechanical Intelligent Fault Diagnosis. J. Manuf. Syst. 2020, 55, 273–284. [Google Scholar] [CrossRef]
- Zhao, X.; Ma, M.; Shao, F. Bearing fault diagnosis method based on improved Siamese neural network with small sample. J. Cloud Comput. 2022, 11, 79. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, X.; Wang, Z. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines 2023, 11, 277. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, L.; Liu, T.; Li, H.; He, C. Lightweight Network with Variable Asymmetric Rebalancing Strategy for Small and Imbalanced Fault Diagnosis. Machines 2022, 10, 879. [Google Scholar] [CrossRef]
- Pan, S.; Tsang, W.; Kwok, T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. Learn Syst. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Ren, Y. A General Transfer Framework Based on Industrial Process Fault Diagnosis Under Small Samples. IEEE Trans. Industr. Inform. 2021, 17, 6073–6083. [Google Scholar] [CrossRef]
- Dong, Y.; Li, Y.; Zheng, H.; Wang, R.; Xu, M. A new dynamic model and transfer learning based intelligent fault diagnosis framework for rolling element bearings race faults: Solving the small sample problem. ISA Trans. 2021, 121, 327–348. [Google Scholar] [CrossRef] [PubMed]
- Fu, S.; Zhong, S.; Lin, L. Gas turbine fault diagnosis method under small sample based on transfer learning. CSCD 2021, 27, 3450–3461. [Google Scholar]
- Zhang, X.; Yu, D.; Liu, S. Fault Diagnosis Method for Small Sample Bearing Based on Transfer Learning. J. Xi’an Jiaotong Univ. 2021, 55, 30–37. [Google Scholar]
- Xiao, D.; Huang, Y.; Qiu, C.; Liu, Z.; Liu, C. Transfer learning with convolutional neural networks for small sample size problem in machinery fault diagnosis. Proc. Inst. Mech. Eng. C 2019, 233, 5131–5143. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial NetsNeural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- He, Q.; Tang, X.; Li, C.; Lu, J.; Chen, J. Bearing Fault Diagnosis Method Based on Small Sample Data under Unbalanced Loads. Chin. J. Mech. Eng. 2021, 32, 1164–1171+1180. [Google Scholar]
- He, W.; Chen, J.; Zhou, Y.; Xu, X.; Chen, B.; Guo, b. An Intelligent Machinery Fault Diagnosis Method Based on GAN and Transfer Learning under Variable Working Conditions. Sensors 2022, 22, 9175. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Yang, X.; Cai, G. A Deep Adversarial Diagnosis Method for Wind Turbine Main Bearing Fault with Imbalanced Small Sample Scenarios. Proc. CSEE 2020, 40, 563–574. [Google Scholar]
- Xu, L.; Zheng, X.; Fu, B.; Tian, G. Fault Diagnosis Method of Motor Bearing Based on Improved GAN Algorithm. Dongbei Daxue Xuebao Ziran Kexueban 2019, 40, 1679–1684. [Google Scholar]
- Zhang, K.; Chen, Q.; Chen, J.; He, S.; Li, F.; Zhou, Z. A multi-module generative adversarial network augmented with adaptive decoupling strategy for intelligent fault diagnosis of machines with small sample. Knowl. Based Syst. 2022, 239, 107980–107996. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Index | Unit |
|---|---|---|
| X1 | Box internal temperature | °C |
| X2 | Box internal humidity | RH |
| X3 | Water immersion in the box | mL |
| X4 | Smoke detection in the box | ppm |
| X5 | Condensation in the box | mL |
| X6 | Contact resistance | Ω |
| X7 | Partial discharge | pC |
| X8 | Dielectric loss rate | / |
| X9 | Winding absorption ratio | / |
| X10 | Core ground current | A |
| X11 | Core temperature | °C |
| X12 | Frequency | Hz |
| X13 | Voltage of the h-v | KV |
| X14 | Current of the h-v | A |
| X15 | Incoming line voltage of the l-v | V |
| X16 | Outgoing line voltage of the l-v | V |
| X17 | Incoming line current of the l-v | A |
| X18 | Outgoing line current of the l-v | A |
| X19 | Busbar temperature | °C |
| X20 | Neutral current | A |
| X21 | Action rejection message | / |
| X22 | Trip information | / |
| X23 | Temperature of circuit contacts | °C |
| X24 | Circuit breaker current | A |
| Network Layer | Network Layer Structure |
|---|---|
| 1 | One-dimensional convolution (convolution kernel:16, Step:1) → Relu activation → Normalization → Maximum pooling |
| 2 | One-dimensional convolution (convolution kernel:3, Step:1) → Relu activation → Normalization → Maximum pooling |
| 3 | One-dimensional convolution (convolution kernel:3, Step:1) → Relu activation → Maximum pooling |
| 4 | One-dimensional convolution (convolution kernel:3, Step:1) → Relu activation → Maximum pooling |
| 5 | One-dimensional convolution (convolution kernel:3, Step:1) → Maximum pooling |
| 6 | Flatten the layer → Random inactivation (50%) → Fully Connected (Relu) |
| 7 | Fully Connected (Relu) → (Reu) Random inactivation (50%) |
| 8 | SoftMax fully connected layer |
| Index | SMOTE | CTGAN | SA-CTGAN |
|---|---|---|---|
| KL divergence | 0.0101 | 0.0042 | 0.0037 |
| Mean cosine similarity | 0.8494 | 0.8768 | 0.8996 |
| Cumulative deviation of the correlation coefficient | 11.9714 | 11.9682 | 9.8331 |
| Heatmap SSIM metric | 0.8365 | 0.8527 | 0.9135 |
| Accuracy | Original Dataset | SMOTE | CTGAN | SA-CTGAN |
|---|---|---|---|---|
| Training set | 89.32% | 91.47% | 94.46% | 94.91% |
| Validation set | 84.15% | 90.78% | 92.55% | 94.34% |
| Testing set | 82.94% | 89.94% | 92.61% | 94.81% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhou, J.; Zhang, D.; Wei, S.; Yang, M.; Gao, X. Fault Diagnosis Method of Box-Type Substation Based on Improved Conditional Tabular Generative Adversarial Network and AlexNet. Appl. Sci. 2024, 14, 3112. https://doi.org/10.3390/app14073112
Liu Y, Zhou J, Zhang D, Wei S, Yang M, Gao X. Fault Diagnosis Method of Box-Type Substation Based on Improved Conditional Tabular Generative Adversarial Network and AlexNet. Applied Sciences. 2024; 14(7):3112. https://doi.org/10.3390/app14073112
Chicago/Turabian StyleLiu, Yong, Jialin Zhou, Dong Zhang, Shaoyu Wei, Mingshun Yang, and Xinqin Gao. 2024. "Fault Diagnosis Method of Box-Type Substation Based on Improved Conditional Tabular Generative Adversarial Network and AlexNet" Applied Sciences 14, no. 7: 3112. https://doi.org/10.3390/app14073112