The generation of insect sounds represents a complex and multifaceted research field, with the characteristics of these signals closely associated with the morphology [
3], types of sound-producing organs [
21], and habits [
3] of insects. Each insect’s sound signals exhibit monotony and regularity, displaying species-specific traits. Moreover, early monitoring of insect sounds has enhanced the capabilities of researchers who frequently encounter resource constraints when monitoring the distribution of insect populations. Orthoptera insects [
22] produce sound by rubbing their forewings, a mechanism characteristic of the suborder Ensifera. They possess a row of rigid microstructures on the inner surface of the forewings, acting as a file, and a hardened portion on the wing edge, acting as a scraper. Sound is generated through the relative motion of these two structures. The number and arrangement of protrusions on the file, as well as the thickness of the wings and the speed of vibration, vary between species, leading to differences in the rhythms and pitches of their calls. Cicada insects (Hemiptera: Cicadidae) [
23] create sounds using sound-producing organs located on the sides of the first abdominal segment. These organs include the tymbal, the tymbal membrane, the tymbal muscle, and an air chamber. In the field of deep learning, the general principles for processing insect sound classification are shown in
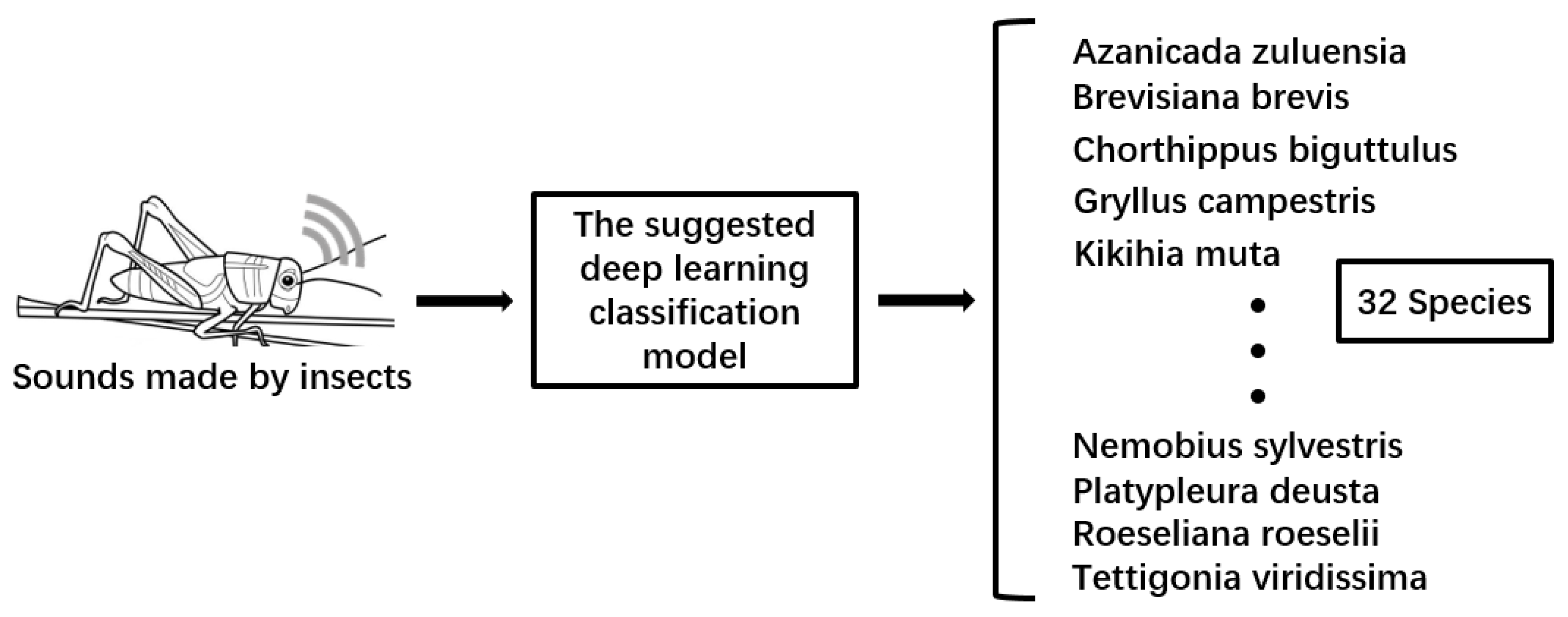
Figure 1.
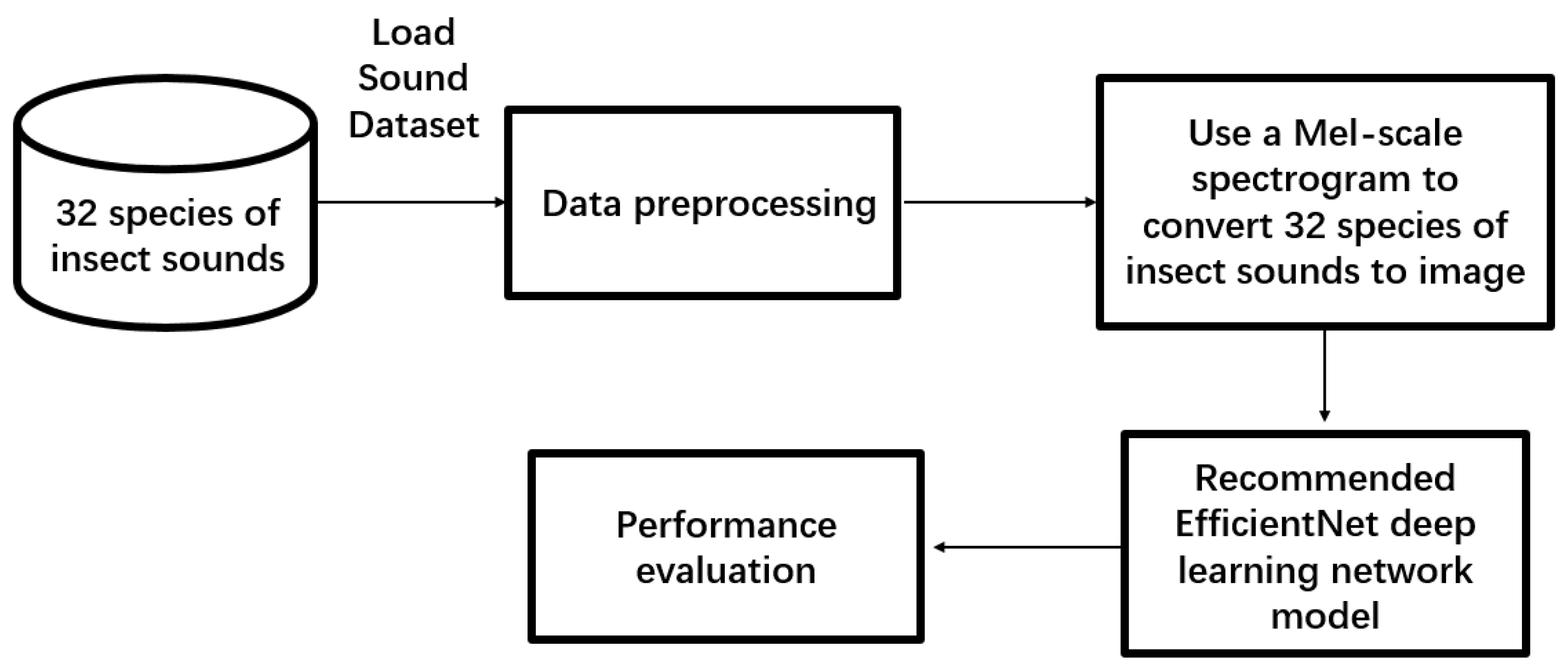
The proposed approach comprises three main components. The initial phase involves preprocessing insect sound data. The second phase employs the Mel-scale spectrogram method to convert raw audio data into an image format. The final phase encompasses feature extraction and classification using the dual-tower network. Insects’ sound clarity may offer vital insights into their species. Hence, this paper employs a series of signal processing techniques and feature extraction methods to acquire sound data that is more distinct and recognizable.
2.2.1. Data Preprocessing
Because insect sounds can vary significantly depending on factors [
25] such as species, environment, behavior, and recording conditions, the limited number of available samples, and the fact that recordings are often affected by environmental noise, changes in recording equipment, and other sources of variation, data augmentation is necessary. Data augmentation of training models on the current dataset involves not only in-modeling but also generating carefully modified copies of new samples. These copies retain similar properties to the original data but are altered to make them appear to come from a different source or subject. This process is critical to ensuring that deep learning models can better handle the diversity of training data.
For audio data, all preprocessing is performed dynamically at runtime. We establish a transformation pipeline to read audio files through the respective library [
26]. Within the dataset, monaural files are duplicated to the second channel, converting them to stereo, and standardizing the channel count for all audio files. Simultaneously, all audio is normalized and sampled at a rate of 44,100 Hz, ensuring uniform dimensions for all arrays. Audio duration is adjusted, either extended or shortened, through methods such as silent padding [
27] or truncation [
28] to match the length of other samples. This guarantees the elimination of feature differences between different audio files, providing uniform data for subsequent data augmentation and model training.
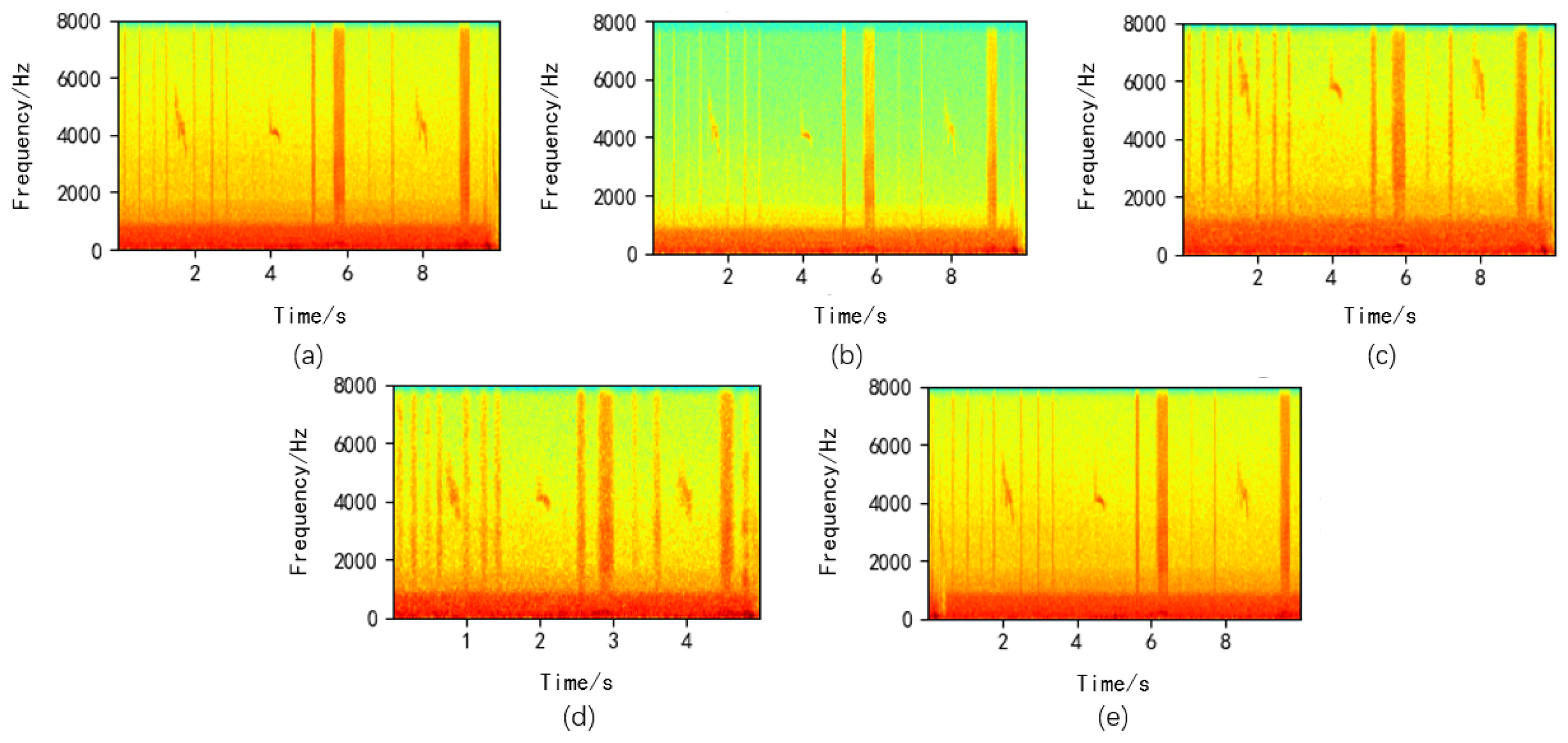
After data standardization, this paper augments insect sound data using noise addition [
29], pitch shifting [
30], time stretching [
31], and time shifting [
32], as shown in
Figure 3. Noise addition entails introducing noise into the original audio signal to enhance the model’s adaptability to noise interference. Pitch shifting alters the signal’s pitch to improve the model’s recognition capabilities. Time stretching, achieved through temporal expansion, broadens the range of temporal variations in the training data, making the model more robust. Time shifting randomly displaces the audio signal to the left or right to augment the original audio data, increasing the diversity of the training data and enabling the model to better accommodate audio inputs at different speeds.
2.2.2. Mel-Scale Spectrogram
The perception of sound by the human ear is highly complex and nonlinear, particularly across different frequency ranges where distinct perceptual differences arise. However, insect sound signals often span a wide frequency range. In addition, human ear perception differs from a linear frequency scale. As frequency increases, human auditory sensitivity decreases, resulting in much smaller perceptual differences for high-frequency sounds compared to low-frequency sounds. To better simulate the auditory behavior of the human ear, we propose using the Mel scale [
33], a nonlinear frequency scale. It converts the ordinary frequency (Hertz) f into the Mel frequency (Mel) m using Equation (
1):
Figure 3.
Data Augmentation Diagram ((a): Original Image, (b): Noise Addition, (c): Pitch Shifting, (d): Time Stretching, (e): Time Shifting).
Figure 3.
Data Augmentation Diagram ((a): Original Image, (b): Noise Addition, (c): Pitch Shifting, (d): Time Stretching, (e): Time Shifting).
To map spectral information to the Mel-scale frequency domain, we utilize a set of Mel filters [
34]. These filters are evenly distributed on the Mel scale. The center frequencies of these Mel filters are configured according to the Mel scale to mimic the way the human ear perceives sound.
Creating the Mel spectrum entails convolving the spectral data obtained through the short-time fourier transform (STFT) [
35] with the response of each Mel filter and computing the energy
within each frequency band of the Mel filter. This step generates an energy value for each frequency band using Equation (
2), resulting in the formation of the Mel spectrum. The STFT, on the other hand, transforms audio data from the time domain to the frequency domain. It decomposes the signal into frequency components within a series of time windows and conducts the transformation of audio data and spectral information as per Equation (
3). Here,
represents the complex representation at time
t and frequency
f,
stands for the input audio signal,
corresponds to the window function, and
denotes the complex exponential term. Spectrograms, or Mel spectrograms, portray the signal’s strength over time at different frequencies by using a variety of colors for visual representation.
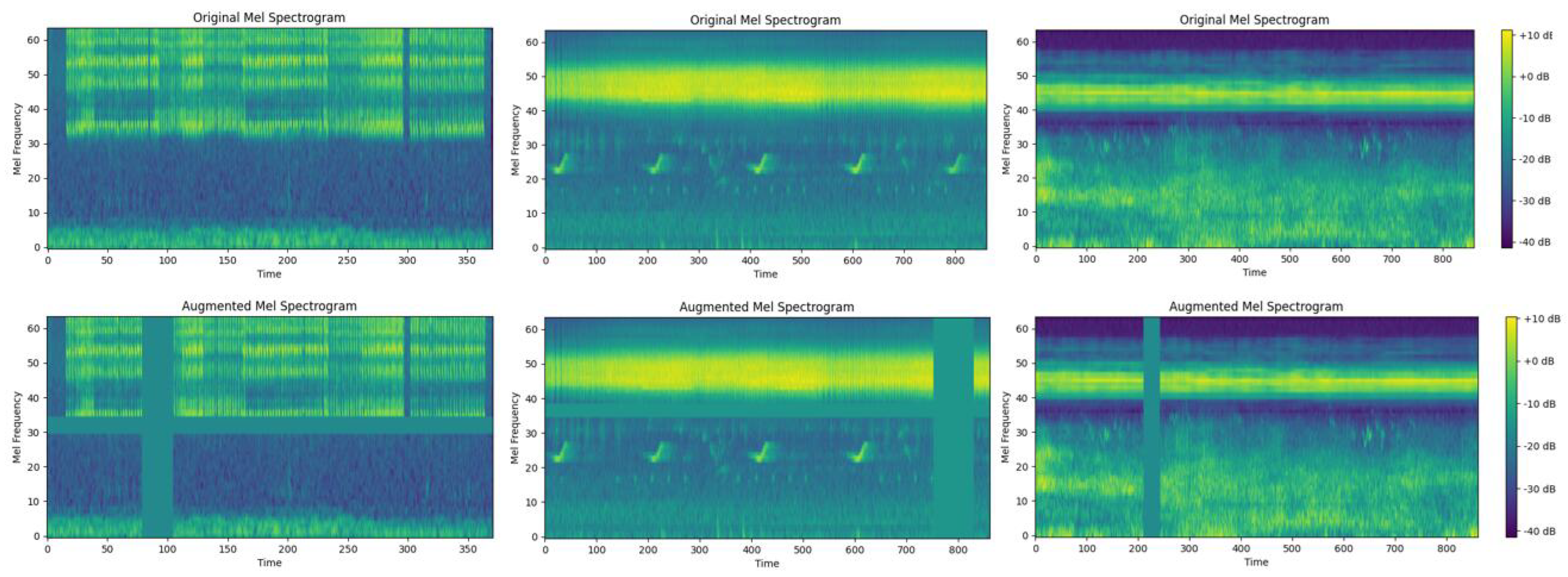
By applying a logarithmic transformation to the Mel spectrogram, we enhance the features and map them to a range more suitable for deep learning models, resulting in the logarithmic Mel spectrogram. This captures the fundamental characteristics of the audio. Building upon this, we apply the SpecAugment technique [
36] to the logarithmic Mel spectrogram, as shown in
Figure 4. Introducing horizontal bars via frequency masking and randomly masking time ranges by blocking vertical lines in the spectrogram. This is used to increase data diversity, simulate noise in different environments, or adjust the spectral characteristics of the signal, further enhancing data augmentation.
2.2.3. Deep Learning Framework
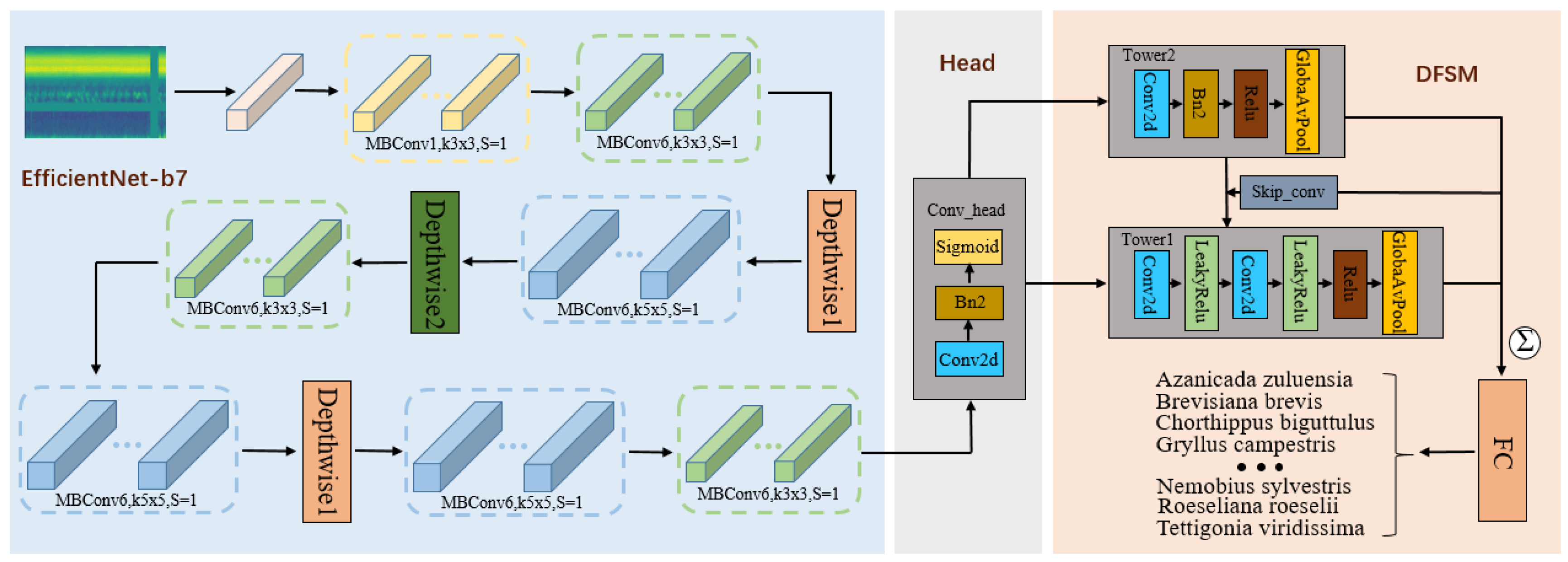
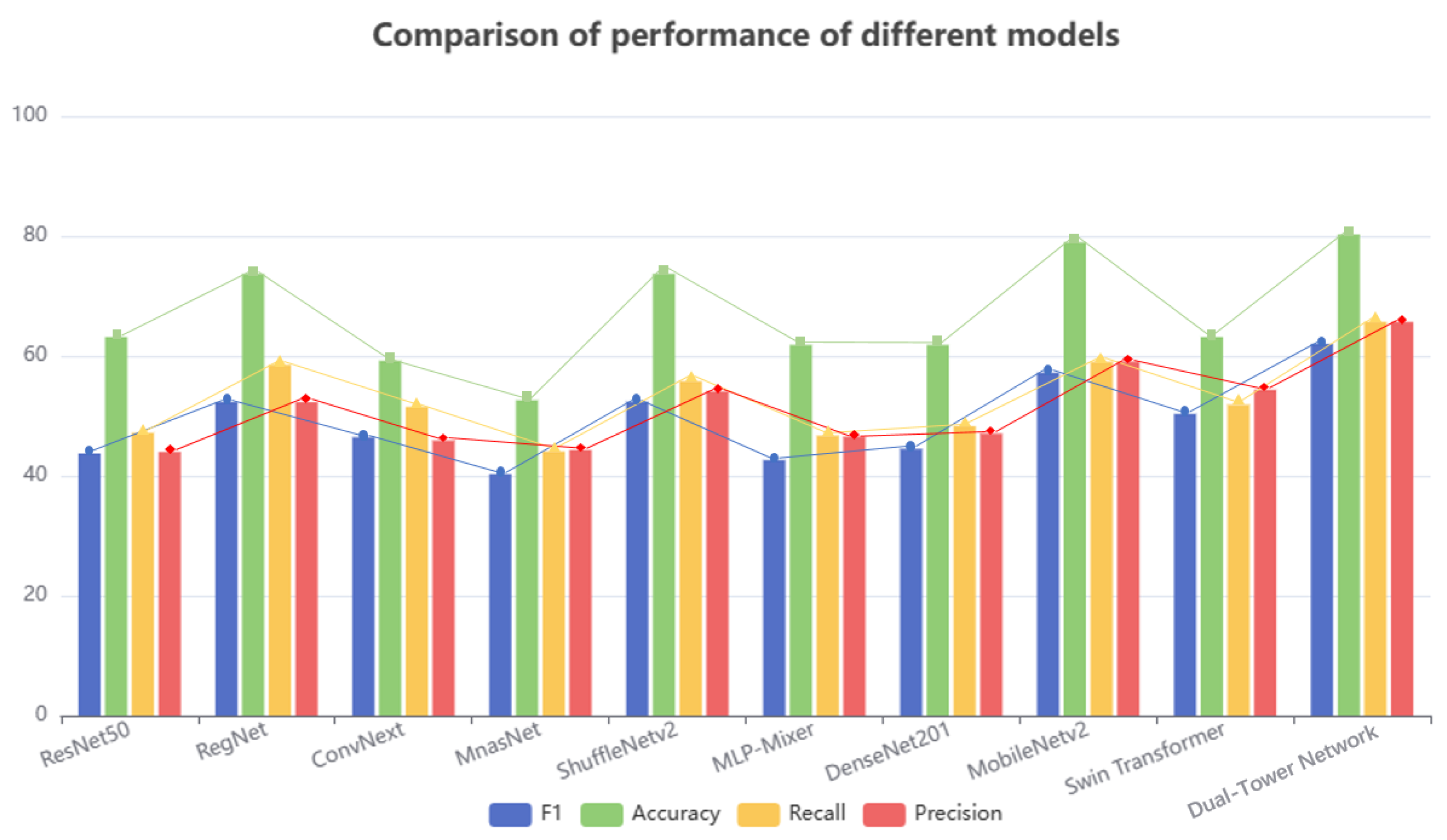
In the field of insect sound classification, a long-standing challenge has been how to accurately extract useful features from complex insect sound recordings for classification. To address this challenge, we conducted a study and introduced the dual-tower network, which comprises two main components: the EfficientNet-b7 module and the “dual-frequency and spectral fusion module (DFSM)”. In our research, we adopted the EfficientNet-b7 model as the foundational network. Its distinctive network architecture and parameter optimization techniques equip the EfficientNet model with superior feature learning capabilities, enabling it to capture intricate data features efficiently. The design concept of DFSM comes from how the insect brain processes sound signals and the mechanism of the insect auditory system. This module amalgamates some technical elements to achieve efficient audio feature classification. By employing depthwise separable convolutions [
37], the model becomes proficient at learning diverse frequency and temporal features. Additionally, the utilization of pooling operations aids in reducing data dimensions while preserving critical information. The incorporation of skip connections fosters interaction and integration among features at different levels, enabling the model to attain a thorough understanding of the complexity of audio signals. Through experimental comparisons with conventional methods, we have demonstrated that the DFSM can improve the accuracy of insect sound classification. The architectural layout of the dual-tower network is illustrated in
Figure 5. This research not only introduces an innovative approach to insect sound classification but also imparts valuable insights into the principles of audio feature extraction, offering robust support for future studies in audio classification.
Unlike traditional image data processing, for audio transformation using Mel spectrograms, we consider the size in terms of the number of Mel frequency bands multiplied by the number of time steps as the input dimensions (as presented in
Table 2). To better adapt to the input of Mel spectrograms, in ‘Stage 1’, we modify the number of channels to 2, and the output channel count is set to 64, while the remaining parts follow the original framework of EfficientNet-b7. We position the head module at the output layer of EfficientNet-b7, connecting it to the DFSM. In the first convolution layer of both tower1 and tower2, we set the output channel count to 2 and establish a skip connection, leaving the final FC layer with an “
” value of 6. Furthermore, since the ‘
’ and ‘
’ methods employ ‘AdaptiveAvgPool2d’ for adaptive average pooling, the dimensions of the feature maps are reduced to 1 in length and width.
EfficientNet [
24] represents a series of convolutional neural network models that rely on automated network scaling techniques. The distinctive feature of it is its network structure, which is determined through an automated search for the optimal configuration. This process involves a delicate balance between complexity and computational resources, as well as the scaling of different network layers. EfficientNet-b7, a deep and high-performance convolutional neural network, was chosen primarily to strike a balance between model depth, computational efficiency, and accuracy. While EfficientNet-b7 indeed delivers improved accuracy, it comes at the cost of an increased number of parameters compared to smaller variants in the EfficientNet series. This often necessitates a trade-off between performance, computational complexity, and model size.
In the case of Mel spectrograms converted from insect sounds, we adapt the input channels of the model’s initial convolutional layer from 3 to 2 to accommodate audio Mel spectrogram input. The backbone network of EfficientNet-b7 is built by stacking MBConv structures, which comprise multiple recurrent convolutional blocks. Each convolutional block includes multiple convolution layers, batch normalization layers, and activation functions, as illustrated in
Figure 6. MBConv1,6 represents the expansion factor of the output channels. Utilizing this deep architecture for extracting rich, high-level features proves instrumental in capturing complex information from insect sounds. These extracted features are subsequently fed into the DFSM for further processing and classification, enabling the network to comprehend more intricate image patterns.
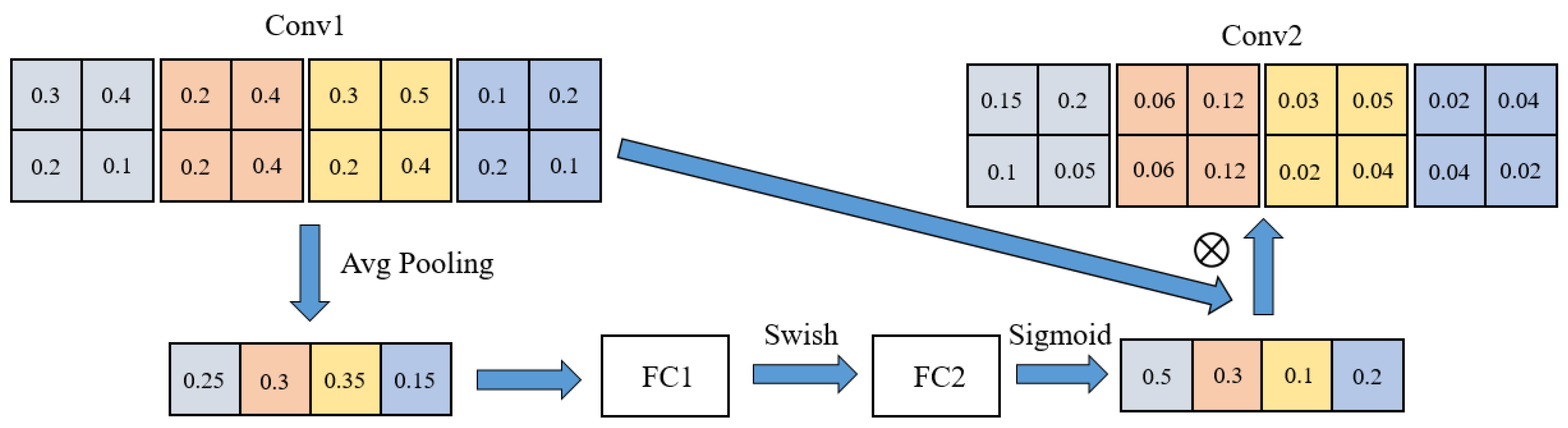
The squeeze-and-excitation (SE) module is an attention mechanism that comprises a global average pooling layer and two fully connected layers (as depicted in
Figure 7). This module enhances the network’s focus on essential features, offering channel-wise adaptive weighting to feature maps, consequently improving the model’s expressiveness and performance. In the case of EfficientNet-B7, the SE module is applied to the output of each residual block [
38] to heighten the network’s attention to critical features, thereby further enhancing the model’s accuracy.
In nature, insect sounds serve various purposes, from mating and warning to navigation. These sounds, produced by these diminutive organisms, serve as a medium of communication, yet they are also influenced by environmental noise and intricate acoustic characteristics. It’s in this context that the research team began contemplating whether inspiration could be derived from insect biology to improve the classification of insect sounds.
A comprehensive exploration of the auditory organs and systems of insects [
39] revealed that they predominantly consist of auditory hairs, Johnston’s organs, and tympanic organs. These systems employ a hierarchical approach when processing sound. Insect brains [
40] contain distinct groups of neurons, each responsible for processing different aspects of sound, such as frequency, temporal, and spectral characteristics. This allows insects to efficiently recognize sounds from companions or potential threats while filtering out noisy background sounds.
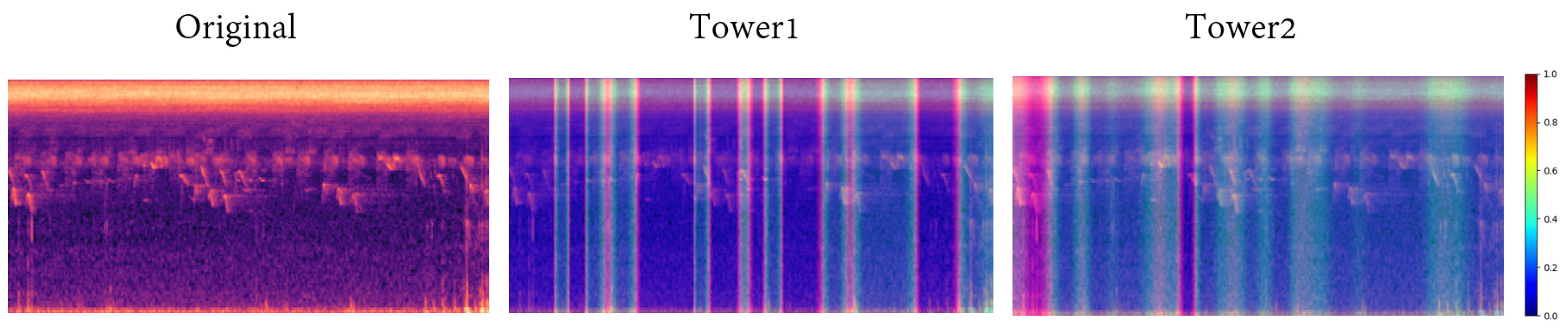
Taking inspiration from this hierarchical processing approach, we designed the DFSM. This module comprises two independent “towers”. Tower 1 consists of three convolutional layers, activation functions, and pooling layers, which function similarly to an insect’s temporal neuron group, focusing on capturing time features. It exhibits multiple dark features, enabling it to keenly discern various sounds. On the other hand, Tower 2 consists of one convolutional layer, an activation function, and a pooling layer; it emulates an insect’s spectral-perceiving neuron group, featuring only one or two dark areas in the CAM (class activation mapping) image [
41]. It concentrates on capturing subtle differences in sound spectra (as shown in
Figure 8), and spectral processing in insects effectively captures the hierarchical nature of insect sound perception. These two towers, along with their skip connections, enable the model to extract audio information from different perspectives, similar to insect neuron groups [
39]. Furthermore, we designed a head module to connect EfficientNet and DFSM. The DFSM not only offers efficient feature extraction (hidden in the DNN(deep neural networks) layers and not accessible to the user) but also helps distinguish the time-frequency locations where subtle differences in insect sounds were extracted by the model. The design of this module draws inspiration from insect auditory systems, aiming to blend biology and deep learning to tackle the challenges of insect sound classification.
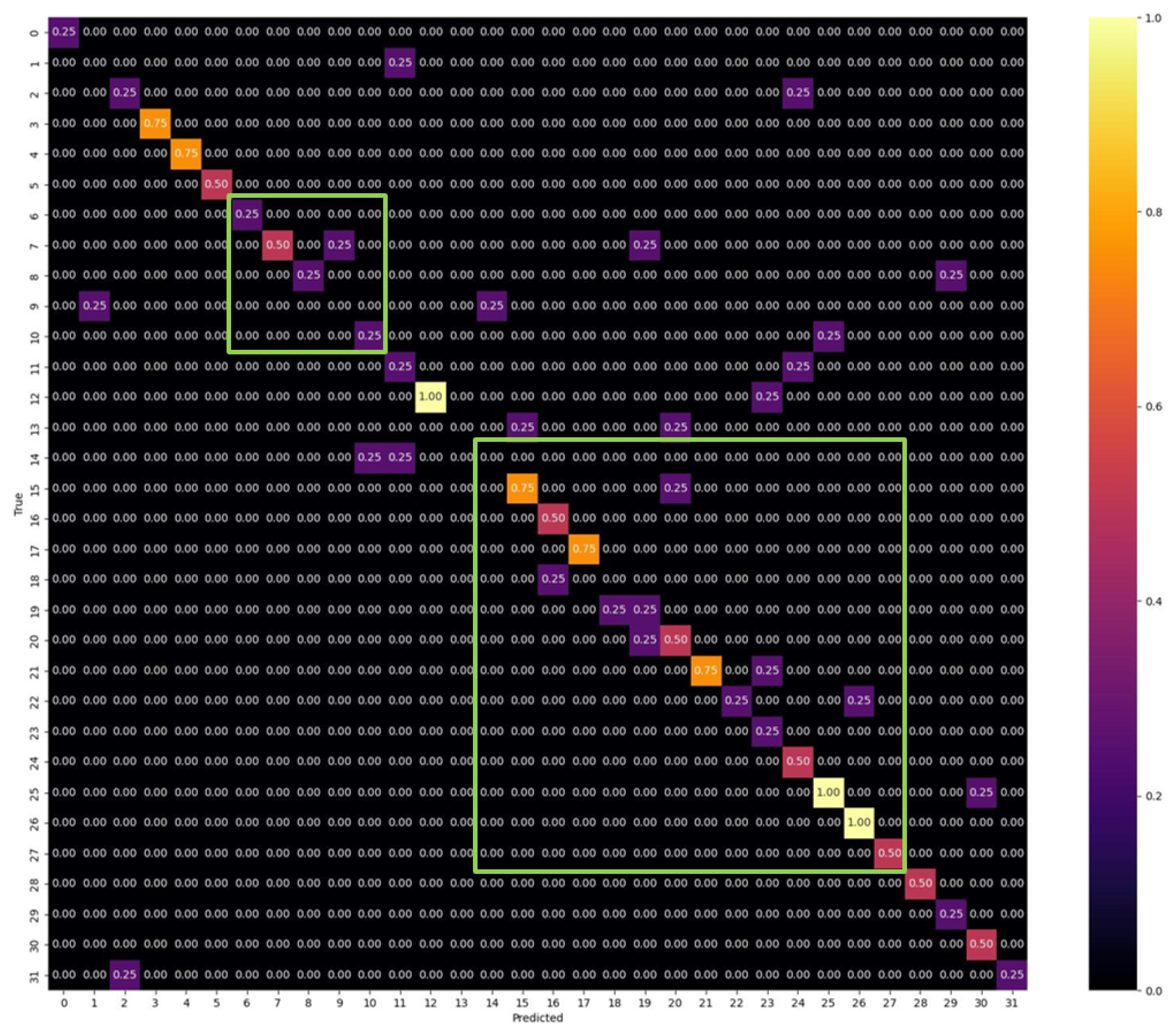
The dual-tower network, as proposed in this paper, standardizes insect sounds during the data preprocessing stage using a dual-channel configuration and a 44,100 Hz sampling rate. Furthermore, we introduce Gaussian noise with a standard deviation of 0.004 to enhance data diversity, ensuring experiment reproducibility with a specific random seed. To fine-tune the dual-tower network, we employ the Adam optimizer and conduct 400 epochs of training. During the training process, the batch size is set to 10, while the learning rate remains at 0.001. All experiments are carried out utilizing an NVIDIA RTX 3070 GPU (NVIDIA, Santa Clara, CA, USA) and an Intel server, thereby fully harnessing computational resources to ensure the stability and reliability of the experiments. These settings and configurations contribute to the good performance of our sound classification tasks. Specific experimental parameters are outlined in
Table 3:


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}