
Improved Convolutional Neural Network–Time-Delay Neural Network Structure with Repeated Feature Fusions for Speaker Verification


Abstract
1. Introduction
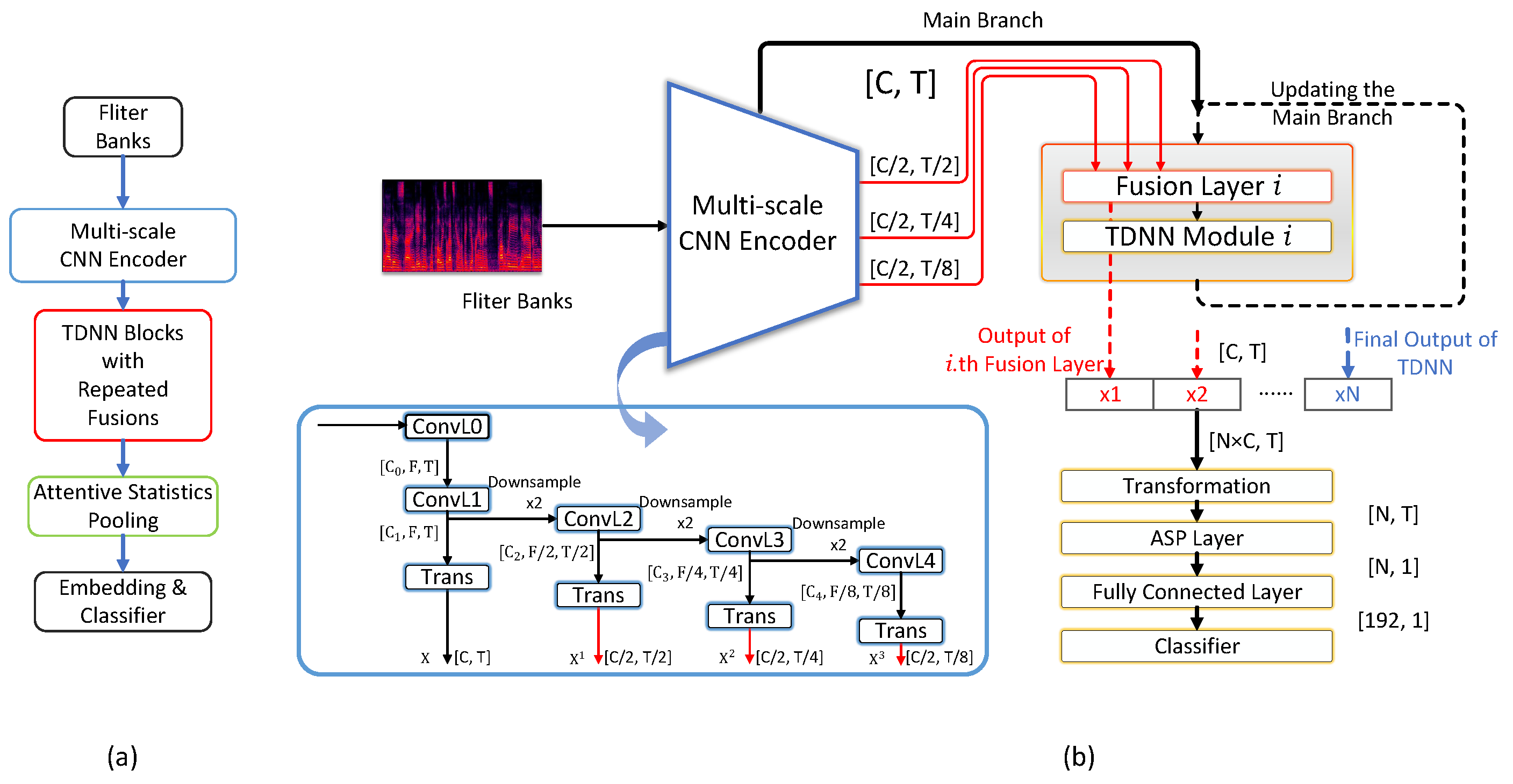
2. Proposed Method
2.1. CNN Encoder for Multi-Scale Features
2.1.1. CNN Backbone
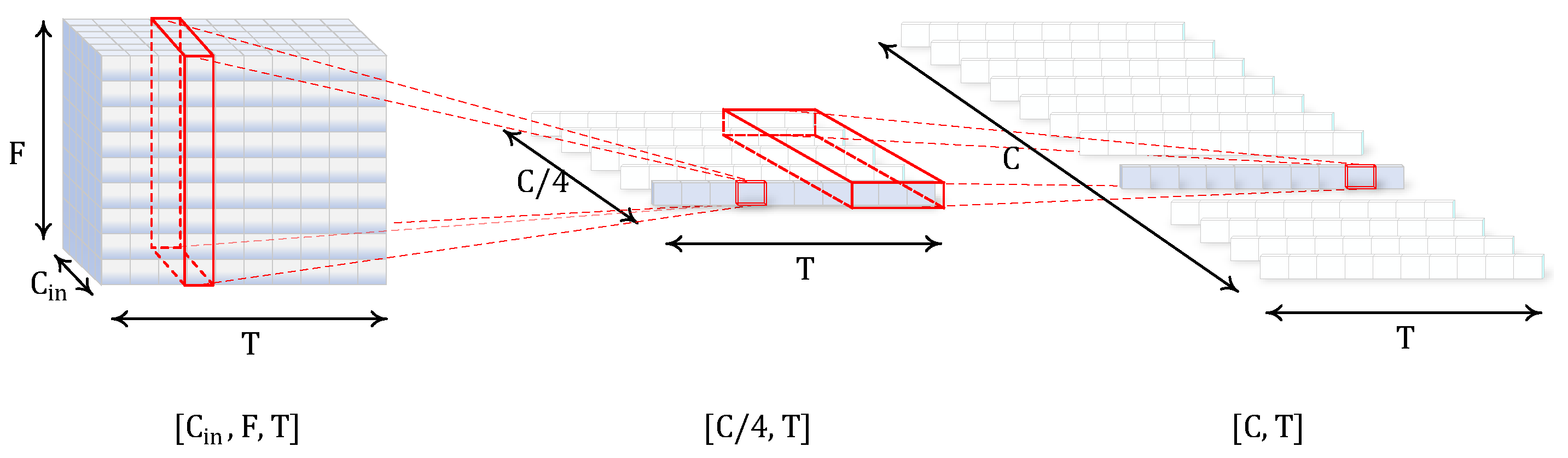
2.1.2. Bottleneck Transformation
2.2. TDNN Blocks with Multiple Fusion Layers
3. Experiments
3.1. Dataset
3.2. Preprocessing and Data Augmentation
3.3. Baseline Systems and Experimental Details
3.3.1. Baseline Systems
3.3.2. Training Strategies and Fine-Tuning Details
- Large-margin fine-tune:The large-margin fine-tune strategy is applied to the pre-trained models on the VoxCeleb dataset. In the fine-tune stage, we reset the batch size to 64. All input utterances are cropped to 6 s, and the margin of AAM-softmax is adjusted to 0.5. The initial learning rate is 2 × with a decay rate of 0.9. SpecAugmentation is disabled, and the other settings remain unchanged.
- Cross-language fine-tune:In addition, we fine-tune the above pre-training models on the cross-language CN-Celeb1&2 dataset [37,38] to compare the cross language SV performance between the models. Taking into account the distribution of duration within the CNCeleb dataset, we made slight adjustments to the training parameters. We crop utterance into 4 s intervals for fine-tuning. The initial learning rate is reset to 1 × with a decay rate of 0.9. While keeping other settings the same above.
3.3.3. Evaluation Protocol
4. Results
4.1. Comparison of Systems
4.2. Comparison with Variants of Stacking
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SV | Speaker verification |
| CNNs | Convolutional neural networks |
| TDNNs | Time-delay neural networks |
| EER | Equal error rate |
| MinDCF | Minimum of the normalized detection cost function |
| RMSFs | Repeated multi-scale feature fusions |
| MAC | Multiply accumulate operations |
References
- Ju, Y.; Rao, W.; Yan, X.; Fu, Y.; Lv, S.; Cheng, L.; Wang, Y.; Xie, L.; Shang, S. TEA-PSE: Tencent-ethereal-audio-lab personalized speech enhancement system for ICASSP 2022 DNS CHALLENGE. In Proceedings of the ICASSP 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 9291–9295. [Google Scholar]
- Sisman, B.; Yamagishi, J.; King, S.; Li, H. An overview of voice conversion and its challenges: From statistical modeling to deep learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 132–157. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep neural network embeddings for text-independent speaker verification. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Lee, K.A.; Wang, Q.; Koshinaka, T. Xi-vector embedding for speaker recognition. IEEE Signal Process. Lett. 2021, 28, 1385–1389. [Google Scholar] [CrossRef]
- Aronowitz, H.; Aronowitz, V. Efficient score normalization for speaker recognition. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 15–19 March 2010; pp. 4402–4405. [Google Scholar]
- Karam, Z.N.; Campbell, W.M.; Dehak, N. Towards reduced false-alarms using cohorts. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4512–4515. [Google Scholar]
- Cumani, S.; Batzu, P.D.; Colibro, D.; Vair, C.; Laface, P.; Vasilakakis, V. Comparison of speaker recognition approaches for real applications. In Proceedings of the Interspeech 2011, Florence, Italy, 28–31 August 2011; pp. 2365–2368. [Google Scholar]
- Matejka, P.; Novotnỳ, O.; Plchot, O.; Burget, L.; Sánchez, M.D.; Cernockỳ, J. Analysis of Score Normalization in Multilingual Speaker Recognition. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1567–1571. [Google Scholar]
- Ioffe, S. Probabilistic linear discriminant analysis. In Computer Vision–ECCV 2006: Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part IV 9; Springer: Berlin/Heidelberg, Germany, 2006; pp. 531–542. [Google Scholar]
- Cai, Y.; Li, L.; Abel, A.; Zhu, X.; Wang, D. Deep normalization for speaker vectors. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 733–744. [Google Scholar] [CrossRef]
- Zeng, C.; Wang, X.; Cooper, E.; Miao, X.; Yamagishi, J. Attention back-end for automatic speaker verification with multiple enrollment utterances. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6717–6721. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Heigold, G.; Moreno, I.; Bengio, S.; Shazeer, N. End-to-end text-dependent speaker verification. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5115–5119. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Gu, B.; Guo, W. Dynamic Convolution With Global-Local Information for Session-Invariant Speaker Representation Learning. IEEE Signal Process. Lett. 2021, 29, 404–408. [Google Scholar] [CrossRef]
- Chung, J.S.; Huh, J.; Mun, S.; Lee, M.; Heo, H.S.; Choe, S.; Ham, C.; Jung, S.; Lee, B.J.; Han, I. In defence of metric learning for speaker recognition. arXiv 2020, arXiv:2003.11982. [Google Scholar]
- Li, L.; Chen, Y.; Shi, Y.; Tang, Z.; Wang, D. Deep speaker feature learning for text-independent speaker verification. arXiv 2017, arXiv:1705.03670. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Thienpondt, J.; Desplanques, B.; Demuynck, K. Integrating frequency translational invariance in tdnns and frequency positional information in 2d resnets to enhance speaker verification. arXiv 2021, arXiv:2104.02370. [Google Scholar]
- Liu, T.; Das, R.K.; Lee, K.A.; Li, H. MFA: TDNN with multi-scale frequency-channel attention for text-independent speaker verification with short utterances. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7517–7521. [Google Scholar]
- Mun, S.H.; Jung, J.W.; Han, M.H.; Kim, N.S. Frequency and multi-scale selective kernel attention for speaker verification. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 548–554. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Wu, Y.; Guo, C.; Gao, H.; Xu, J.; Bai, G. Dilated residual networks with multi-level attention for speaker verification. Neurocomputing 2020, 412, 177–186. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive Statistics Pooling for Deep Speaker Embedding. arXiv 2018, arXiv:1803.10963. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Fan, Y.; Kang, J.; Li, L.; Li, K.; Chen, H.; Cheng, S.; Zhang, P.; Zhou, Z.; Cai, Y.; Wang, D. Cn-celeb: A challenging chinese speaker recognition dataset. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; pp. 7604–7608. [Google Scholar]
- Li, L.; Liu, R.; Kang, J.; Fan, Y.; Cui, H.; Cai, Y.; Vipperla, R.; Zheng, T.F.; Wang, D. Cn-celeb: Multi-genre speaker recognition. Speech Commun. 2022, 137, 77–91. [Google Scholar] [CrossRef]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Thienpondt, J.; Desplanques, B.; Demuynck, K. The idlab voxsrc-20 submission: Large margin fine-tuning and quality-aware score calibration in dnn based speaker verification. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 5814–5818. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parms | Macs | VoxCeleb1-O | VoxCeleb1-H | CNCeleb * | ||
|---|---|---|---|---|---|---|---|
| EER [%] | EER [%] | EER [%] | |||||
| SE-ResNet18 (C = 64) | 11.26 M | 7.53 G | 1.308 | 0.1292 | 2.411 | 0.2334 | 13.281 |
| SE-ResNet34 (C = 64) | 21.04 M | 14.03 G | 1.266 | 0.1281 | 2.289 | 0.2269 | 12.571 |
| MFA-TDNN ( = 32) | 11.01 M | 1.77 G | 0.963 | 0.1006 | 1.982 | 0.1867 | 12.954 |
| ECAPA-TDNN (C = 1024) | 14.73 M | 2.81 G | 0.856 | 0.0845 | 1.912 | 0.1867 | 12.777 |
| ECAPA-C-TDNN (C = 32) | 10.10 M | 2.23 G | 0.846 | 0.0846 | 1.997 | 0.1960 | 12.347 |
| RMSFs C-TDNN (Proposed) | 8.90 M | 1.95 G | 0.744 | 0.0823 | 1.823 | 0.1806 | 11.711 |
| Pre-Trained Model | Fine-Tune * | EER [%] | |
|---|---|---|---|
| ECAPA-TDNN(C = 1024) | ✕ | 7.58 | - |
| ECAPA-TDNN(C = 1024) | ✓ | 7.02 | 0.3882 |
| ECAPA-C-TDNN(C = 32) | ✕ | 7.52 | - |
| ECAPA-C-TDNN(C = 32) | ✓ | 6.99 | 0.3915 |
| Proposed Network | ✕ | 7.28 | - |
| Proposed Network | ✓ | 6.59 | 0.3764 |
| EER [%] | ||
|---|---|---|
| Proposed Network * | 0.744 | 0.0823 |
| ➀ w/o Repeated Fusions | 0.915 | 0.0997 |
| ➁ w/o Branches and | 0.878 | 0.0778 |
| ➂ w/o Bottleneck Trans | 0.978 | 0.1089 |
| ➃ w/o Adjusted MFA | 0.840 | 0.1004 |
| ➄ w/o Res.Sum.Connections | 0.829 | 0.0956 |
| Structure * | Parms | Fusions | EER [%] | |
|---|---|---|---|---|
| [2, 3, 4 | 8.15 M | 1 | 0.915 | 0.0997 |
| [2, 3, 4 | 8.90 M | 3 | 0.744 | 0.0823 |
| [2, 3, 4 | 11.57 M | 3 | 0.877 | 0.1184 |
| [2, 3, 4, 5 | 10.74 M | 4 | 0.718 | 0.0672 |
| [2, 3, 4, 5 | 13.59 M | 4 | 0.745 | 0.1058 |
| [2, 3, 4, 2, 3, 4 | 15.12 M | 6 | 0.766 | 0.0805 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Zhang, X. Improved Convolutional Neural Network–Time-Delay Neural Network Structure with Repeated Feature Fusions for Speaker Verification. Appl. Sci. 2024, 14, 3471. https://doi.org/10.3390/app14083471
Gao M, Zhang X. Improved Convolutional Neural Network–Time-Delay Neural Network Structure with Repeated Feature Fusions for Speaker Verification. Applied Sciences. 2024; 14(8):3471. https://doi.org/10.3390/app14083471
Chicago/Turabian StyleGao, Miaomiao, and Xiaojuan Zhang. 2024. "Improved Convolutional Neural Network–Time-Delay Neural Network Structure with Repeated Feature Fusions for Speaker Verification" Applied Sciences 14, no. 8: 3471. https://doi.org/10.3390/app14083471
APA StyleGao, M., & Zhang, X. (2024). Improved Convolutional Neural Network–Time-Delay Neural Network Structure with Repeated Feature Fusions for Speaker Verification. Applied Sciences, 14(8), 3471. https://doi.org/10.3390/app14083471