

Intelligent Analysis System for Teaching and Learning Cognitive Engagement Based on Computer Vision in an Immersive Virtual Reality Environment


Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
2.1. IVR Environment Learning Investment Analysis Method and System
2.2. IVR Environment Computer Vision Detection Method
2.3. IVR Learning Engagement Measurement and Cognitive Representation Methods
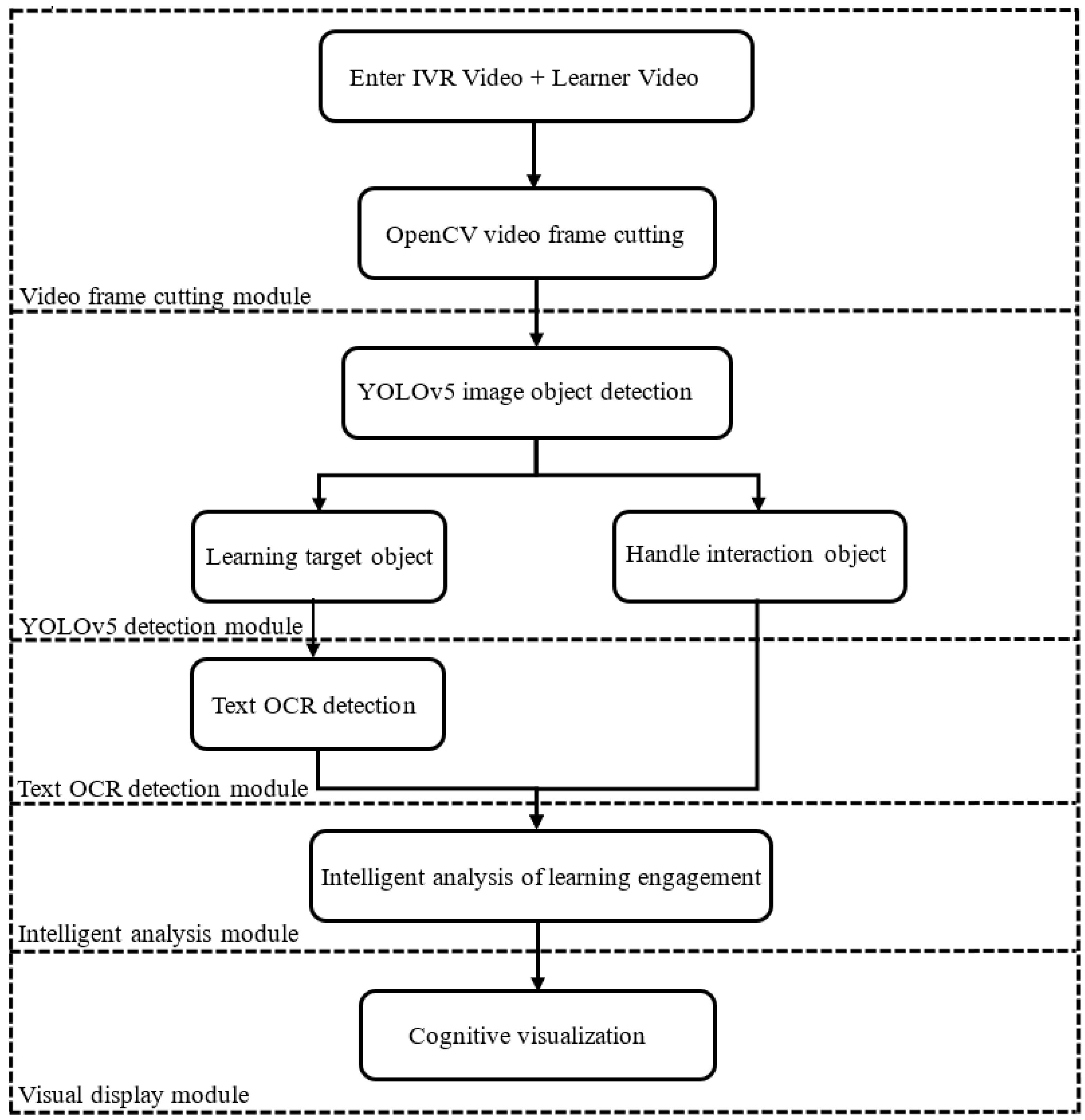
3. System Design
4. Detection Method
4.1. Data Preprocessing
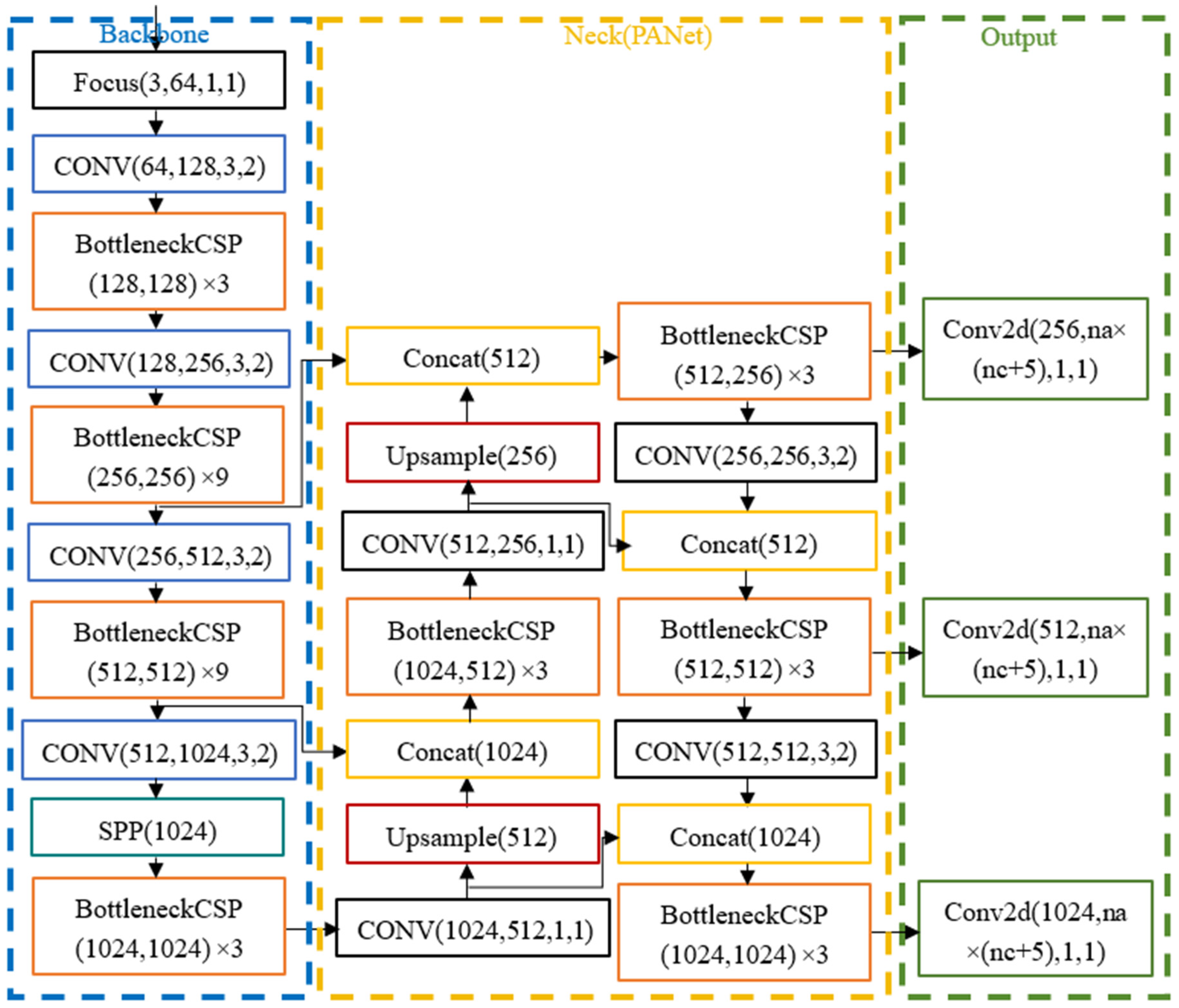
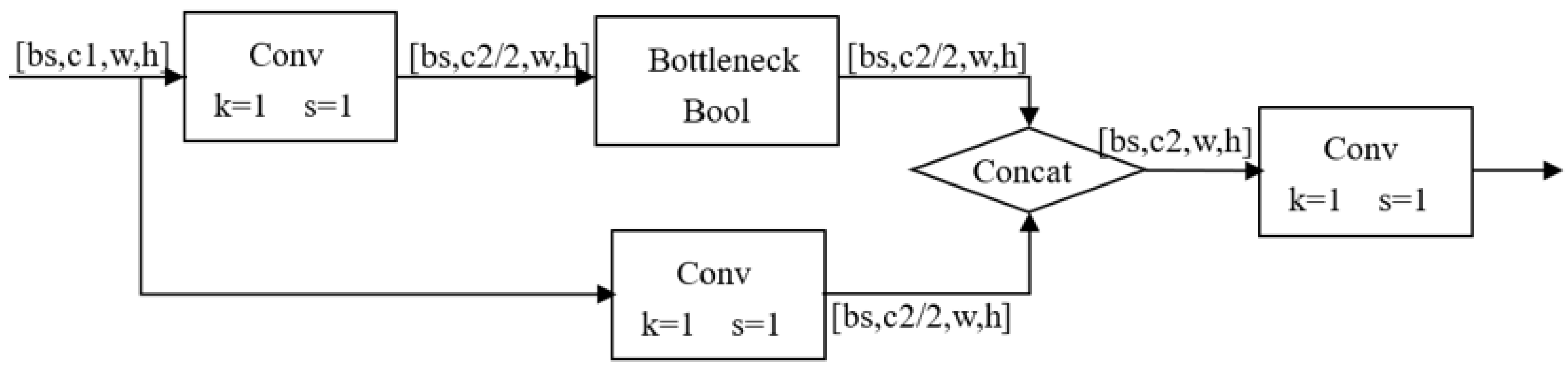
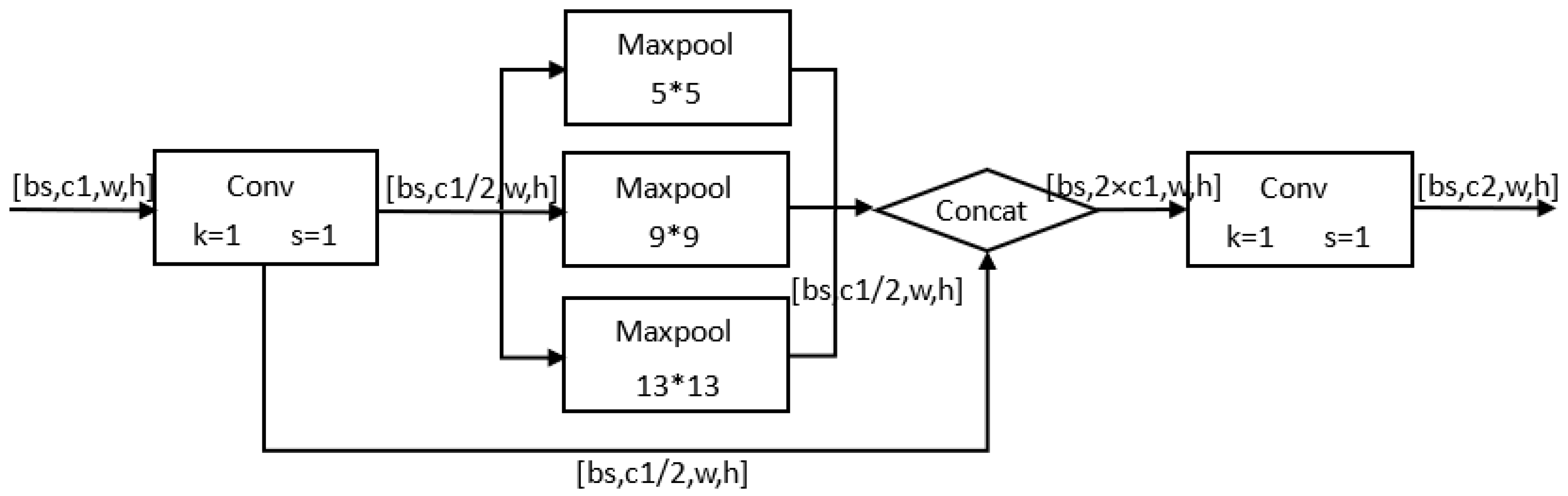
4.2. YOLOv5 Network Architecture
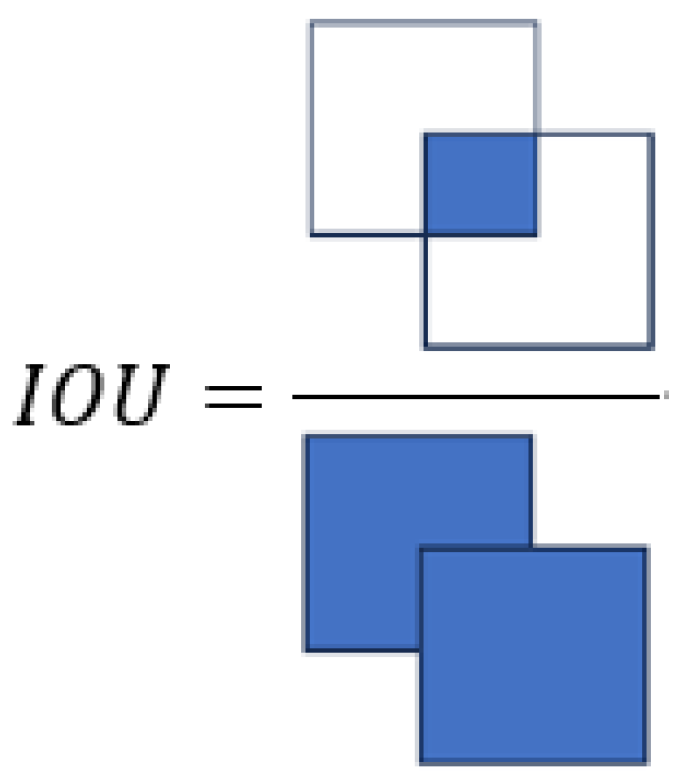
4.3. NMS (Non-Maximum Suppression)
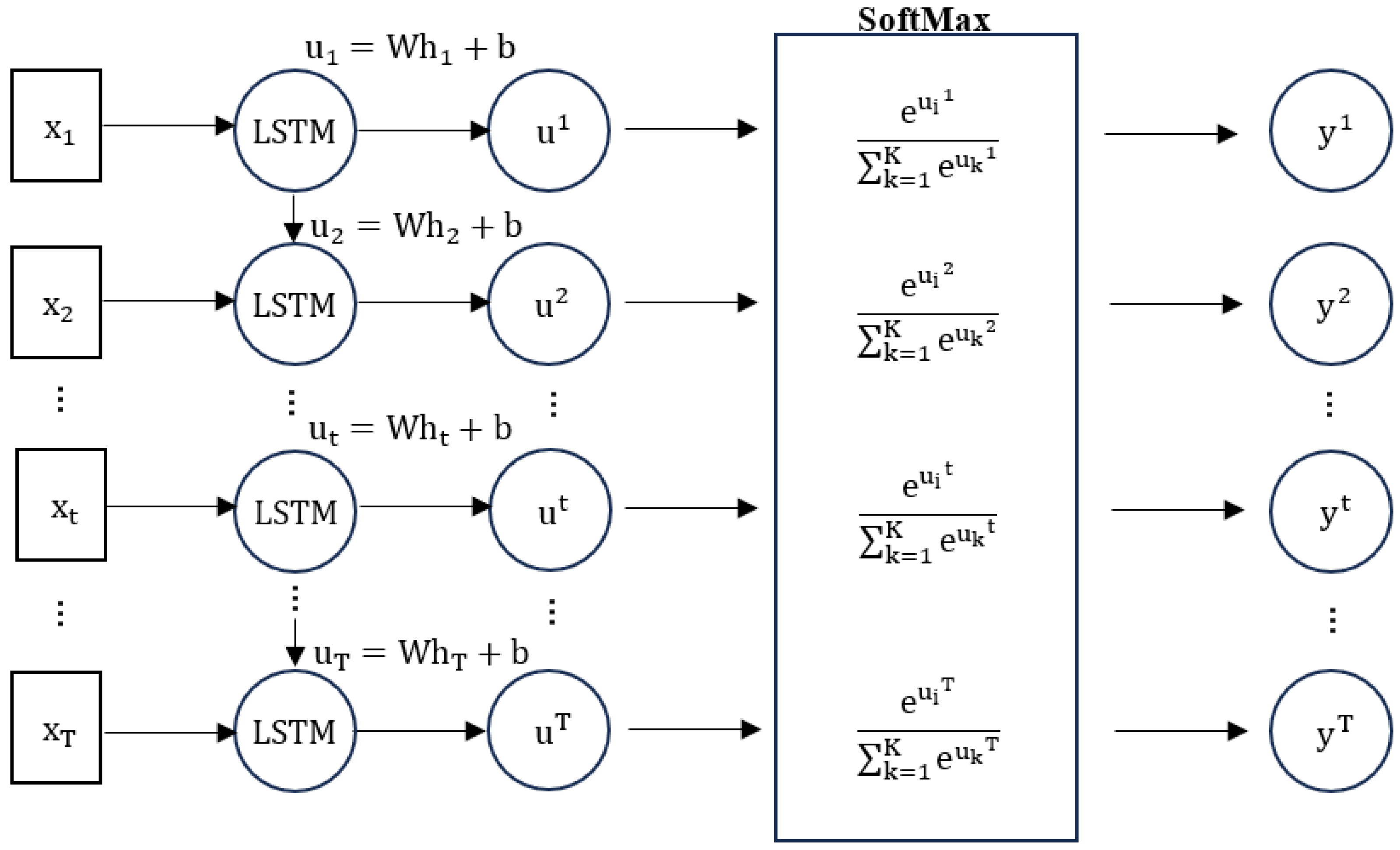
4.4. Text OCR Layer
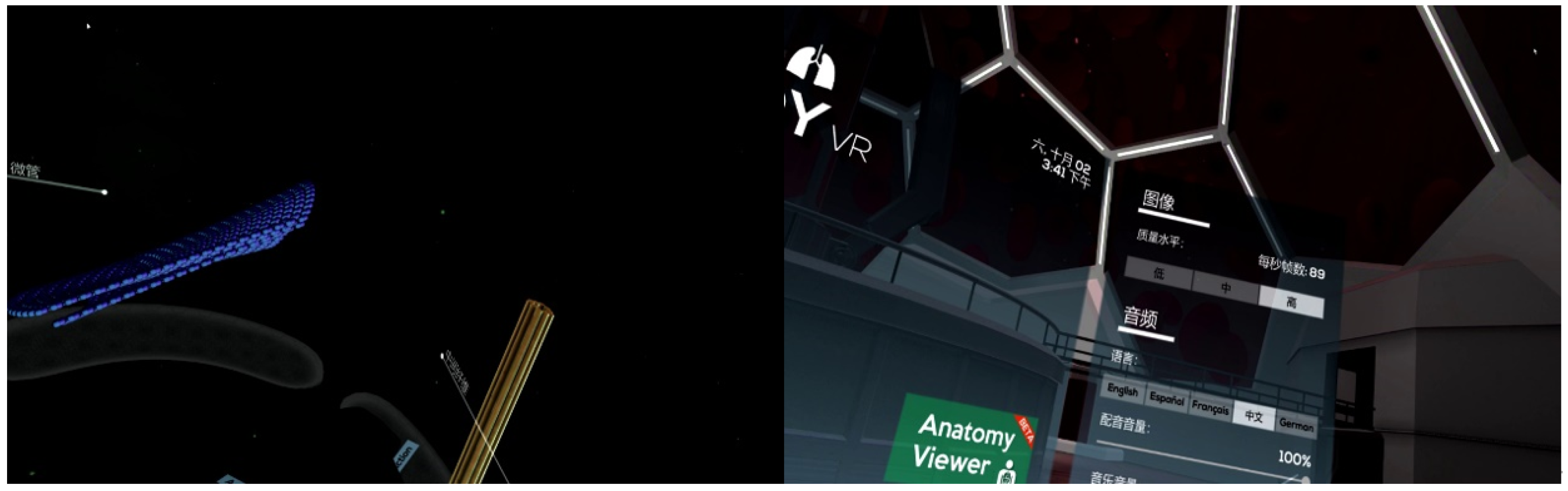
5. Function Implementation and Analysis
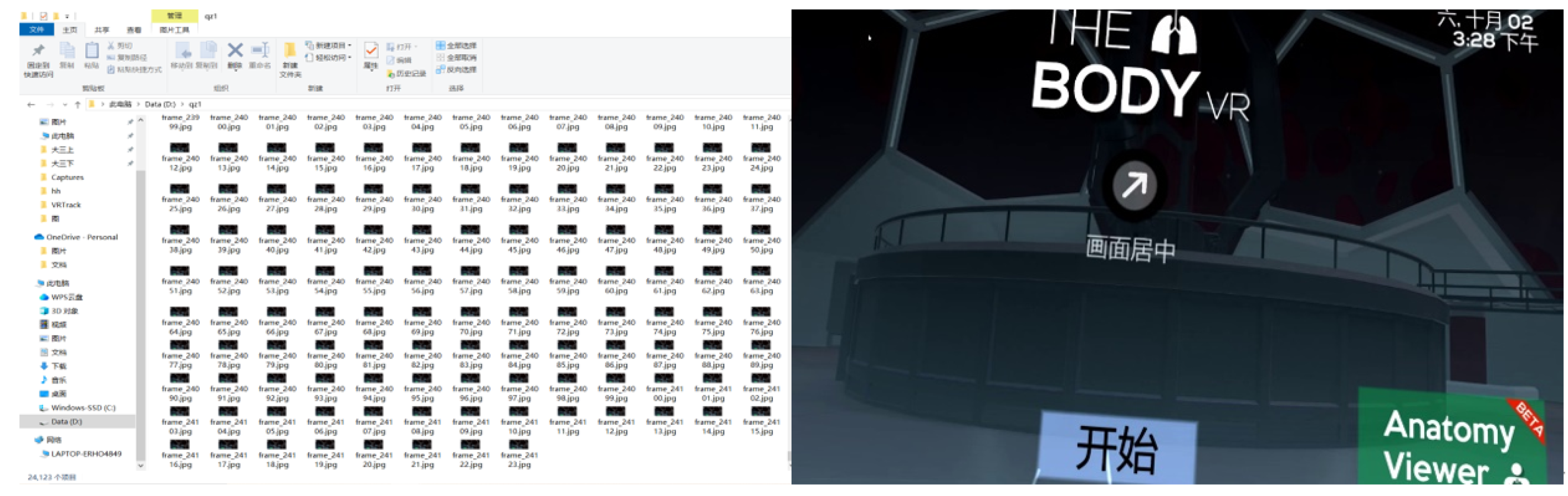
5.1. Video Frame Cutting Module
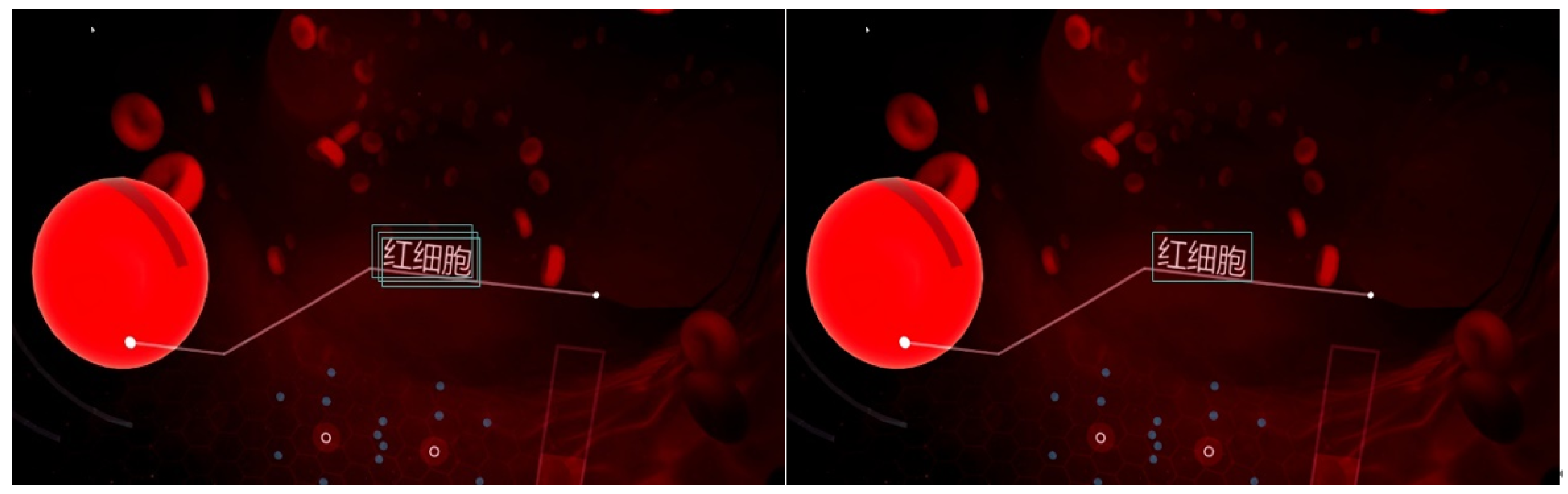
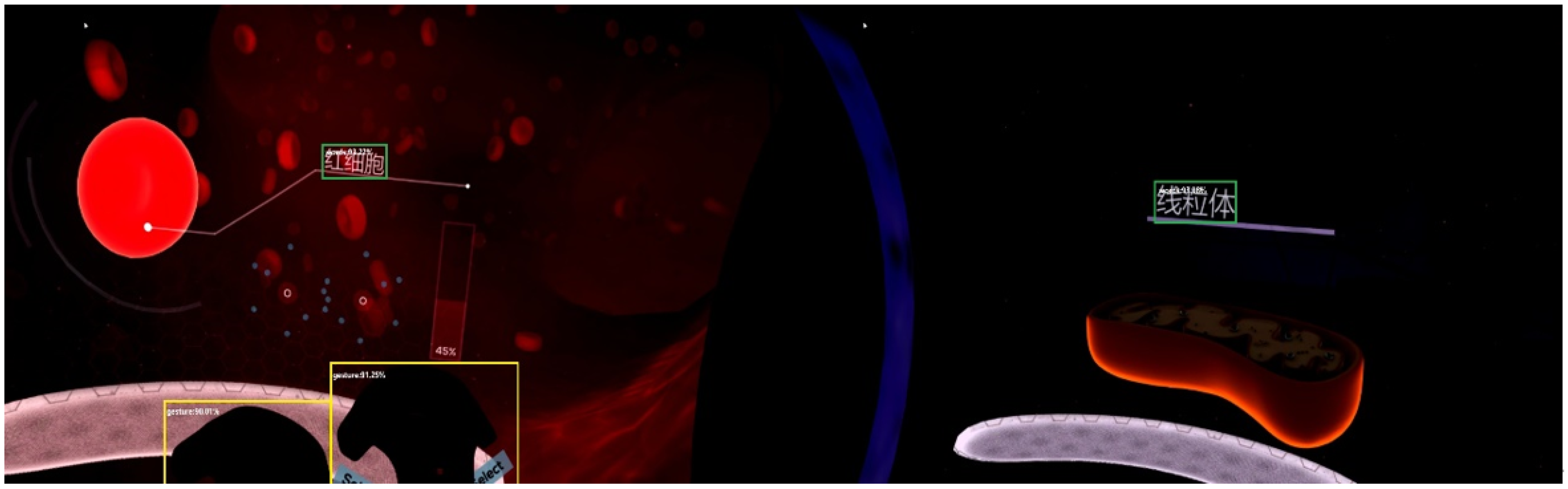
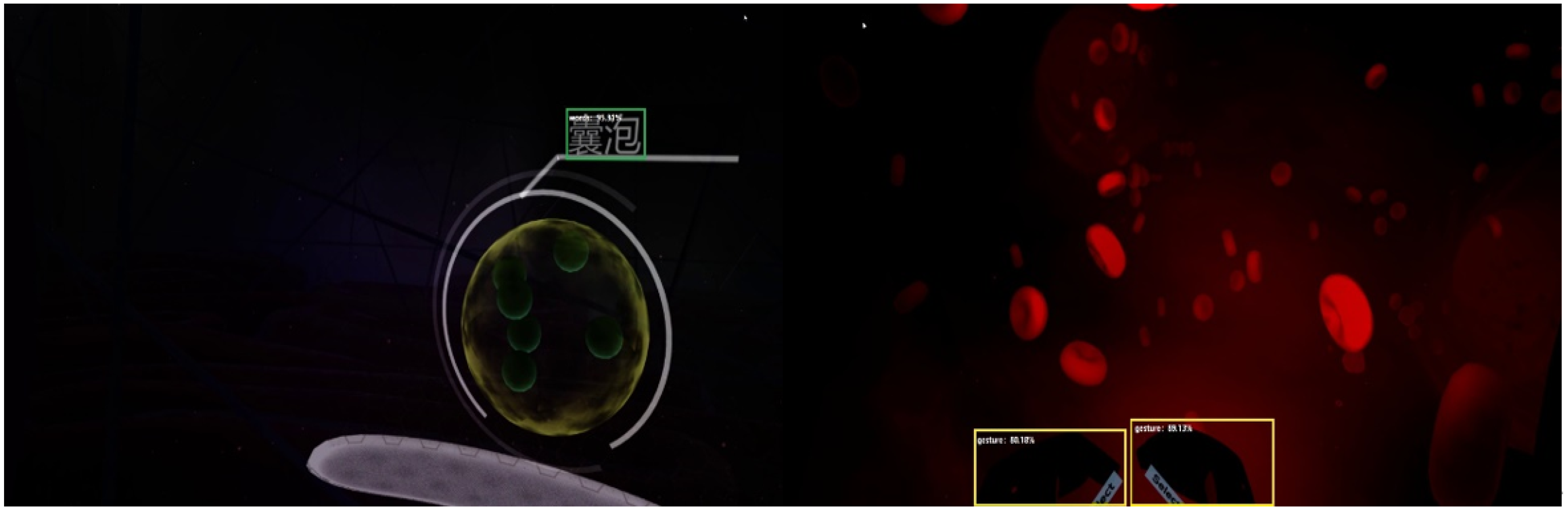
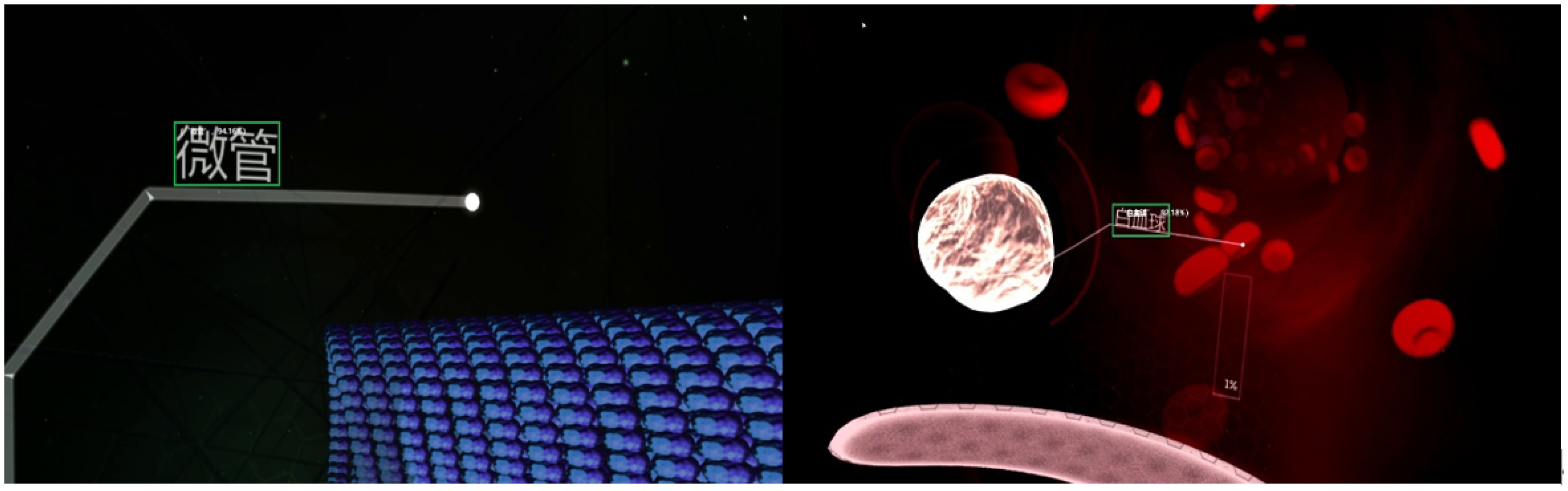
5.2. YOLOv5 Detection Module
5.3. Text OCR Detection Module
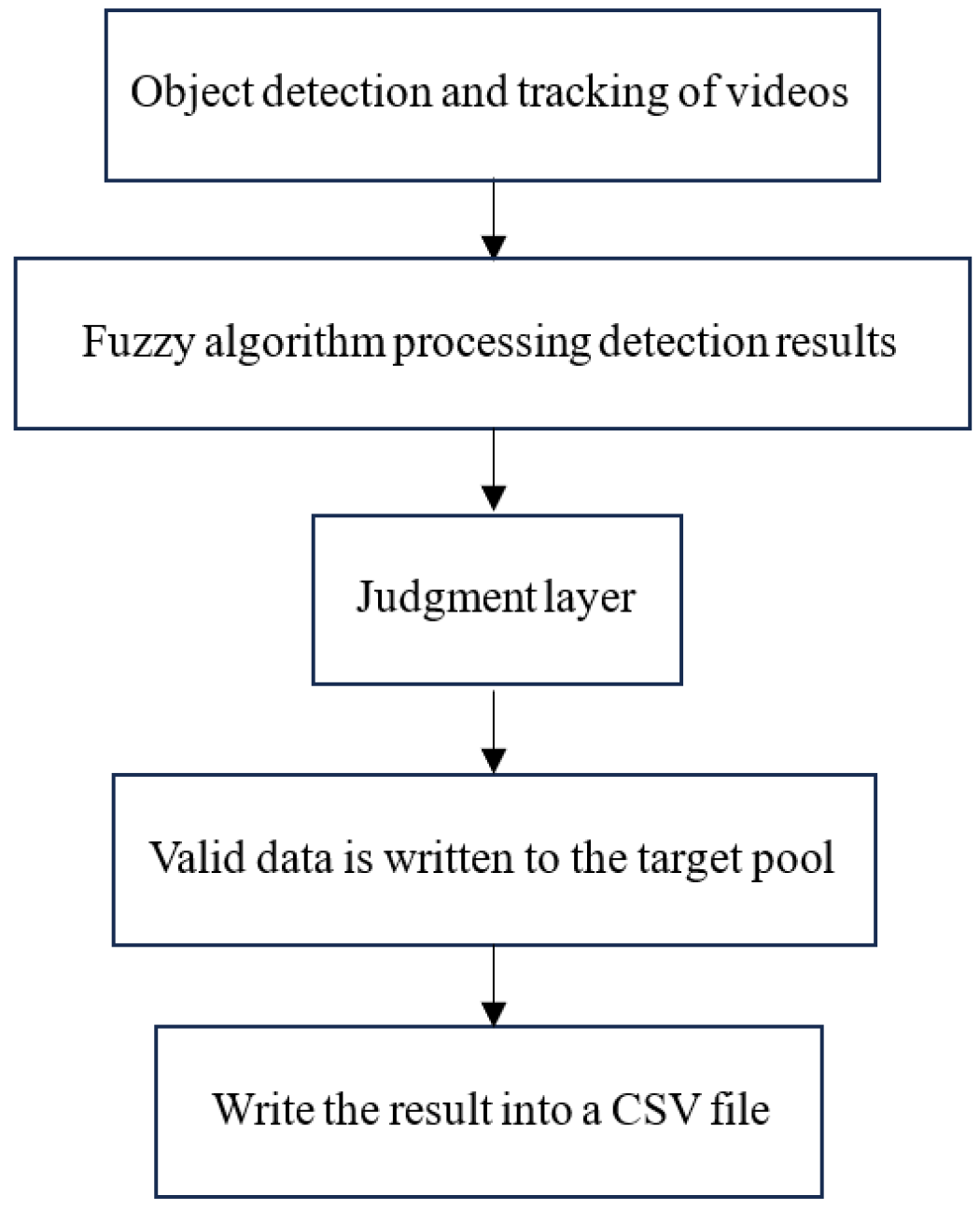
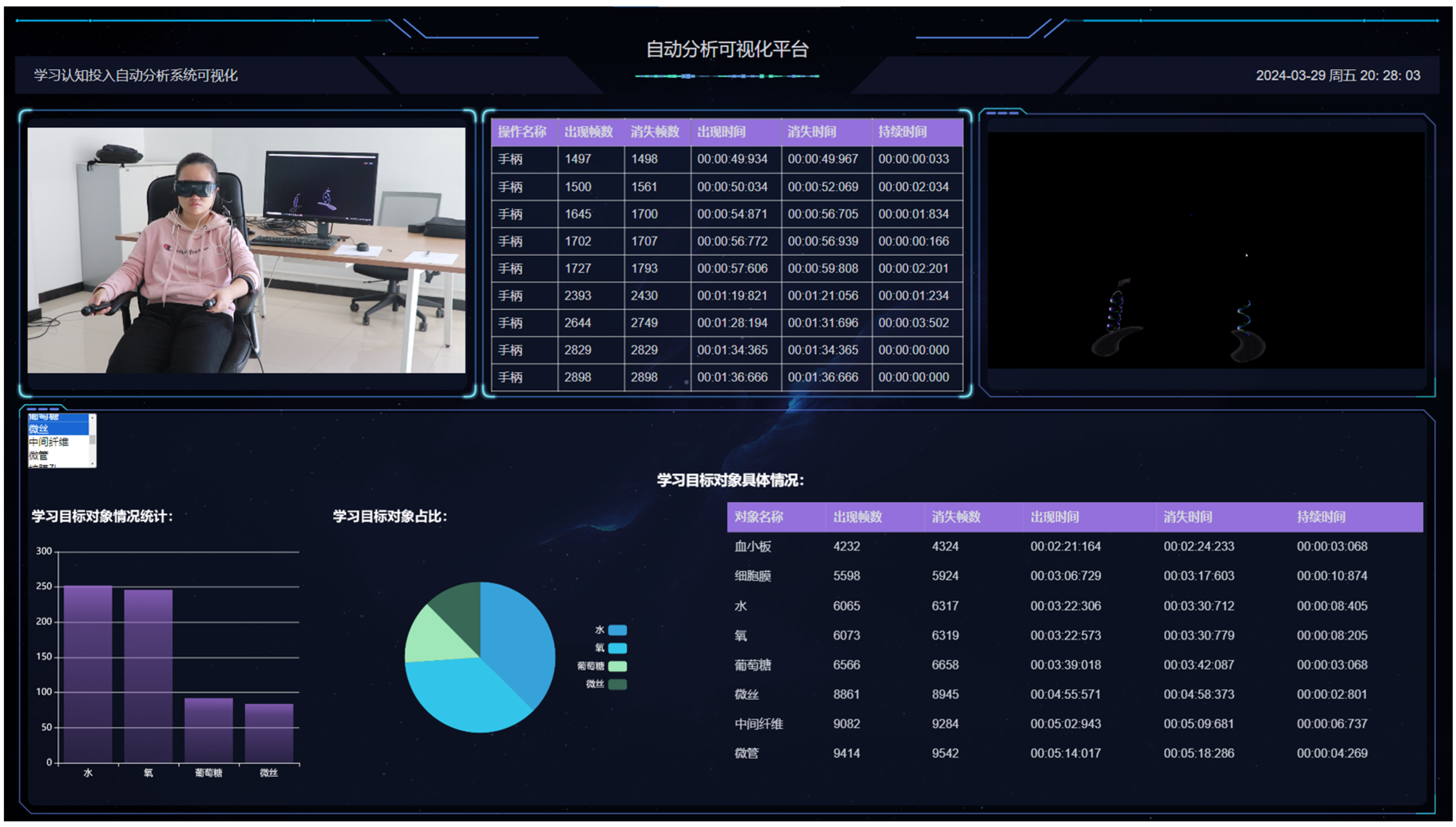
5.4. Intelligent Analysis of Learning Engagement
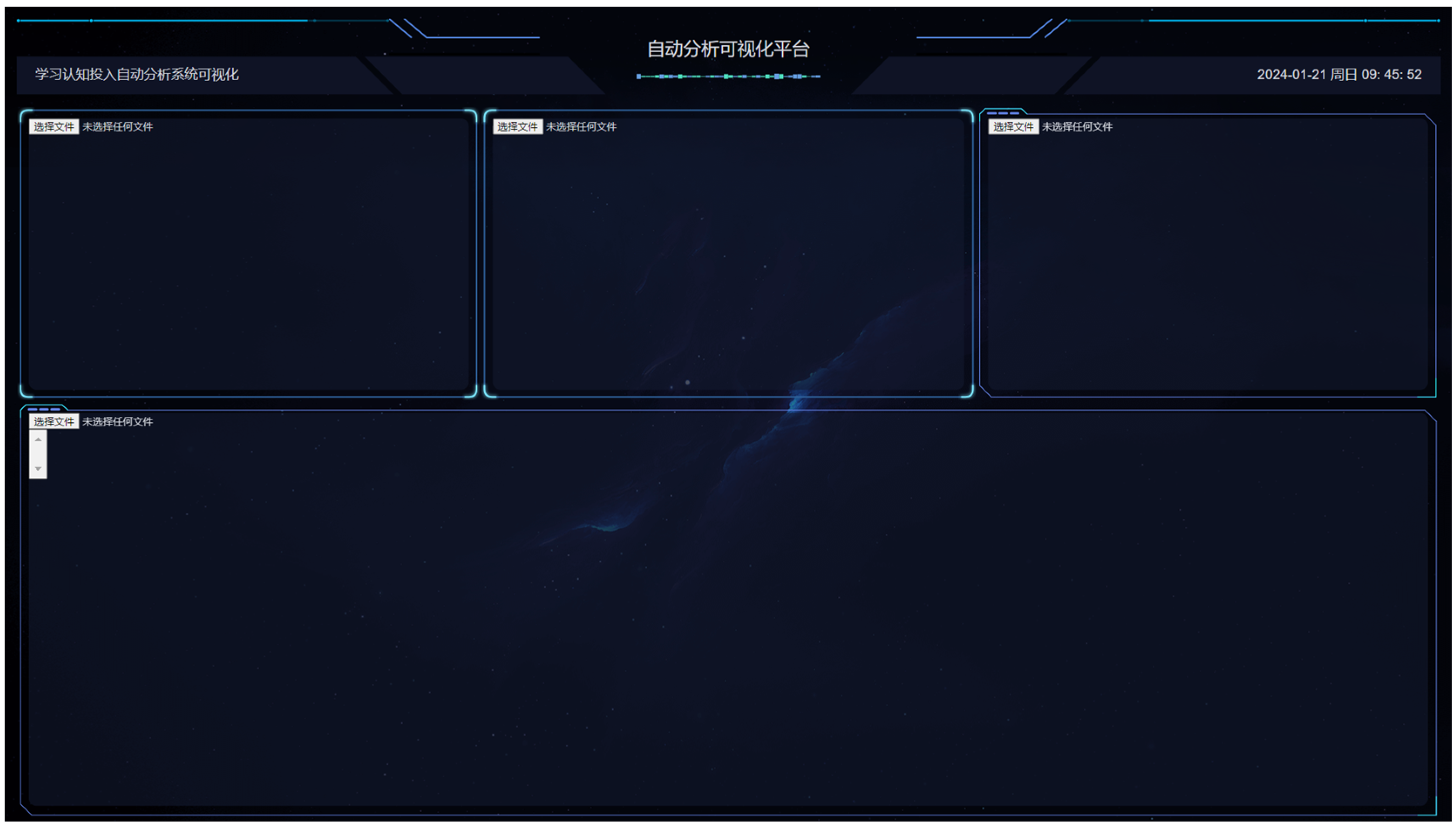
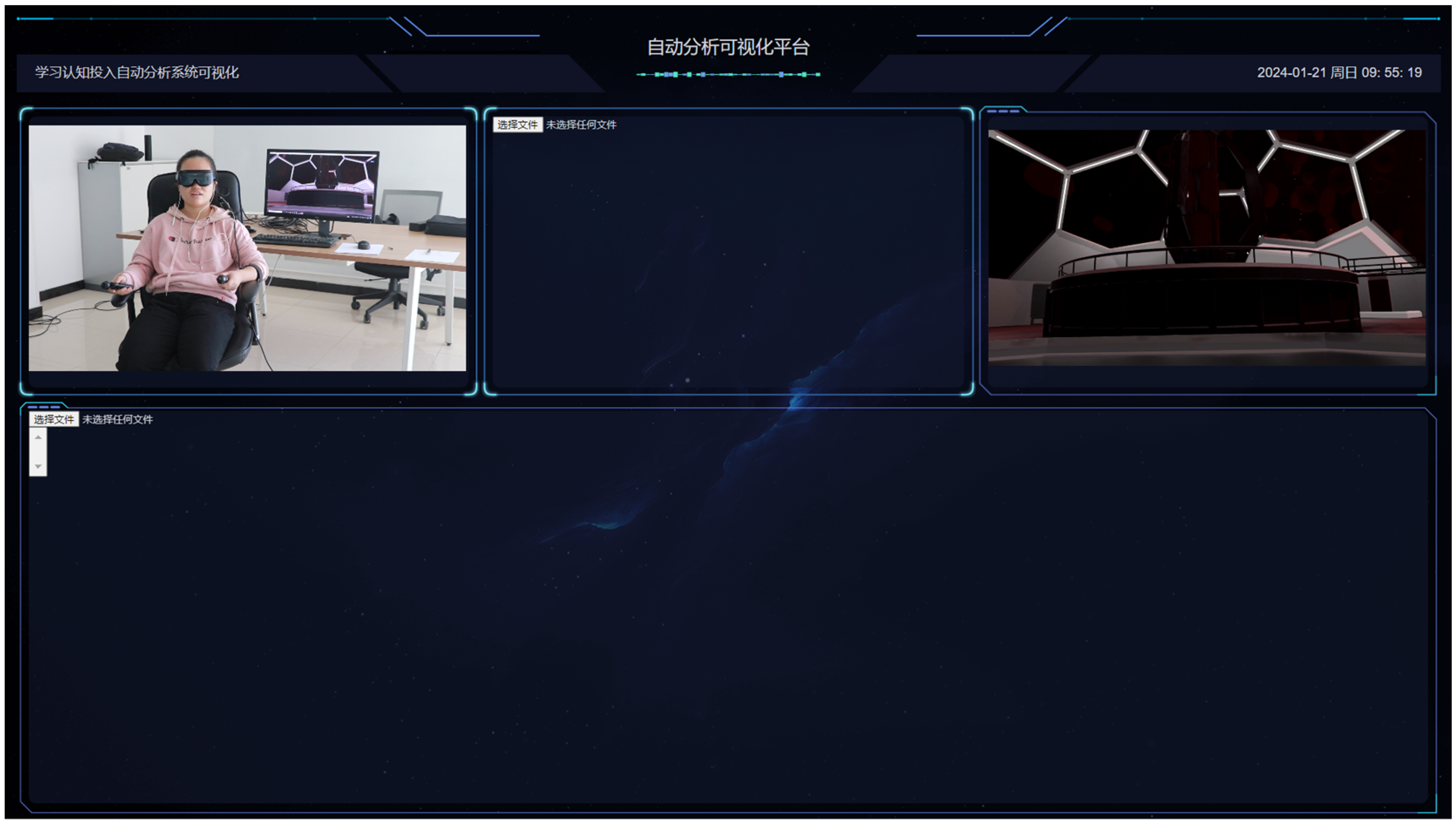
5.5. Visualization of Cognitive Situations
6. Analysis of Experimental Results
6.1. Experimental Environment
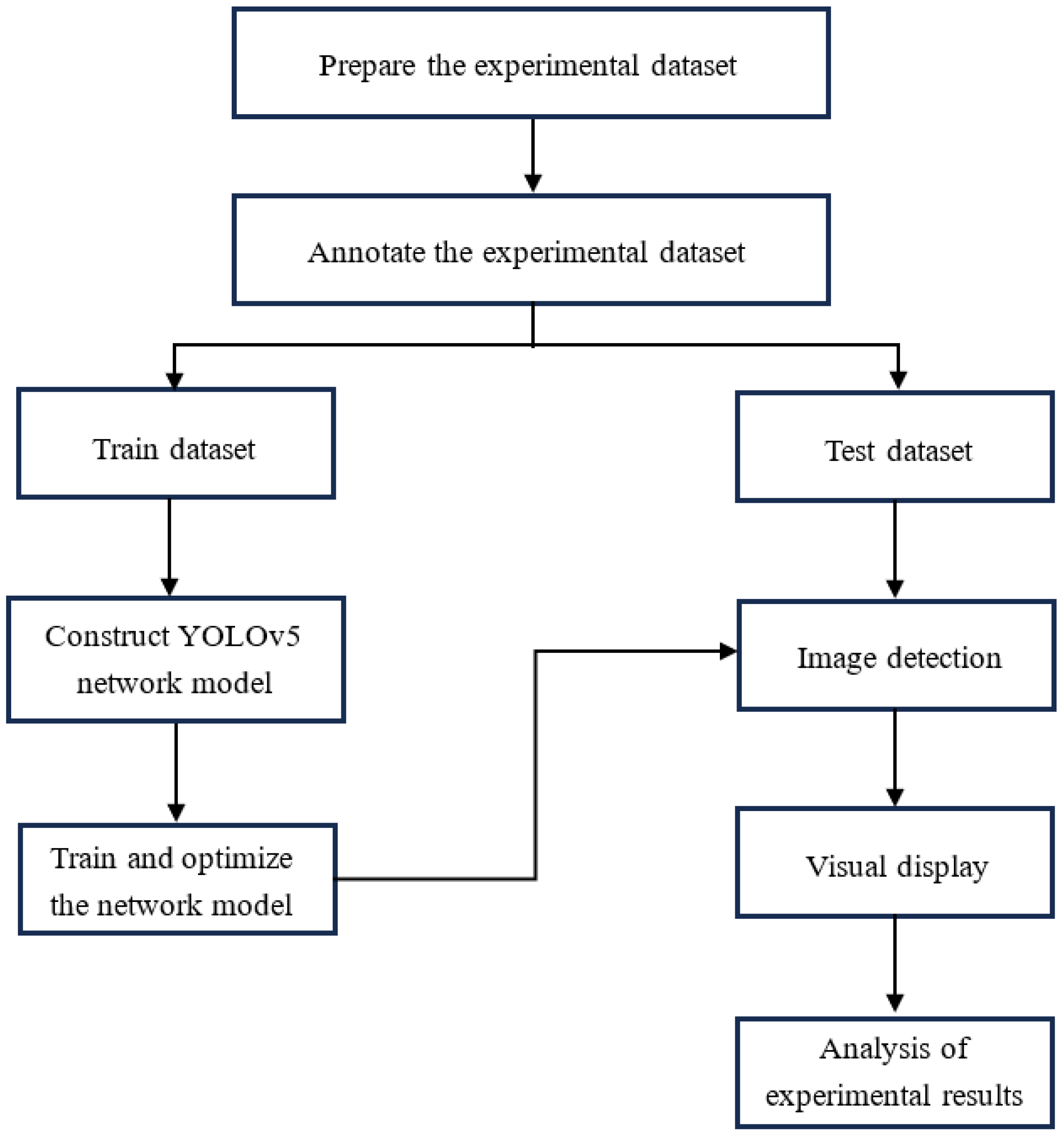
6.2. Experimental Process
- (1)
- Cut the video frames to obtain image data and filter it, use Labelme software v1.0 to manually annotate the images, and obtain training and testing sets.
- (2)
- Designed and built YOLOv5 image target detection model and continuously optimized parameters to complete the adjustment of network structure parameters.
- (3)
- Load the pre-processed training set for network iterative training until the accuracy of the loss rate of the network model becomes stable, then the training ends.
- (4)
- Save the wordsDet.pt model file generated by the final training for calling the test set image data.
- (5)
- Analyze the experimental results to verify the effectiveness and accuracy of the algorithm proposed in this paper.
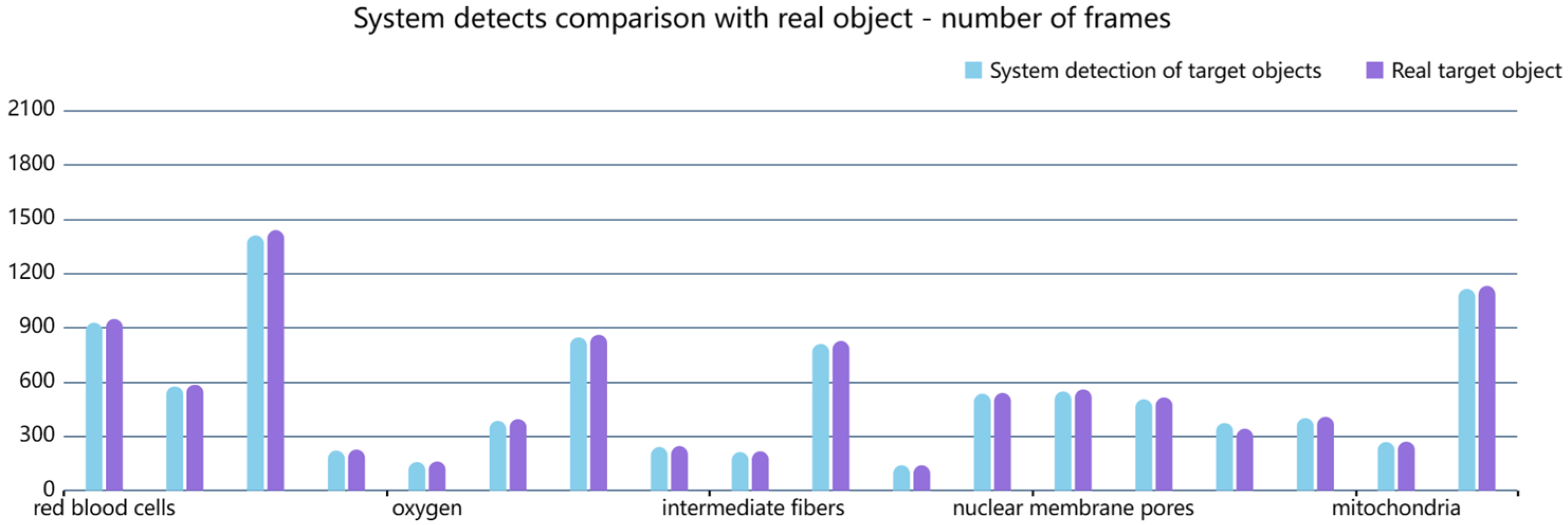
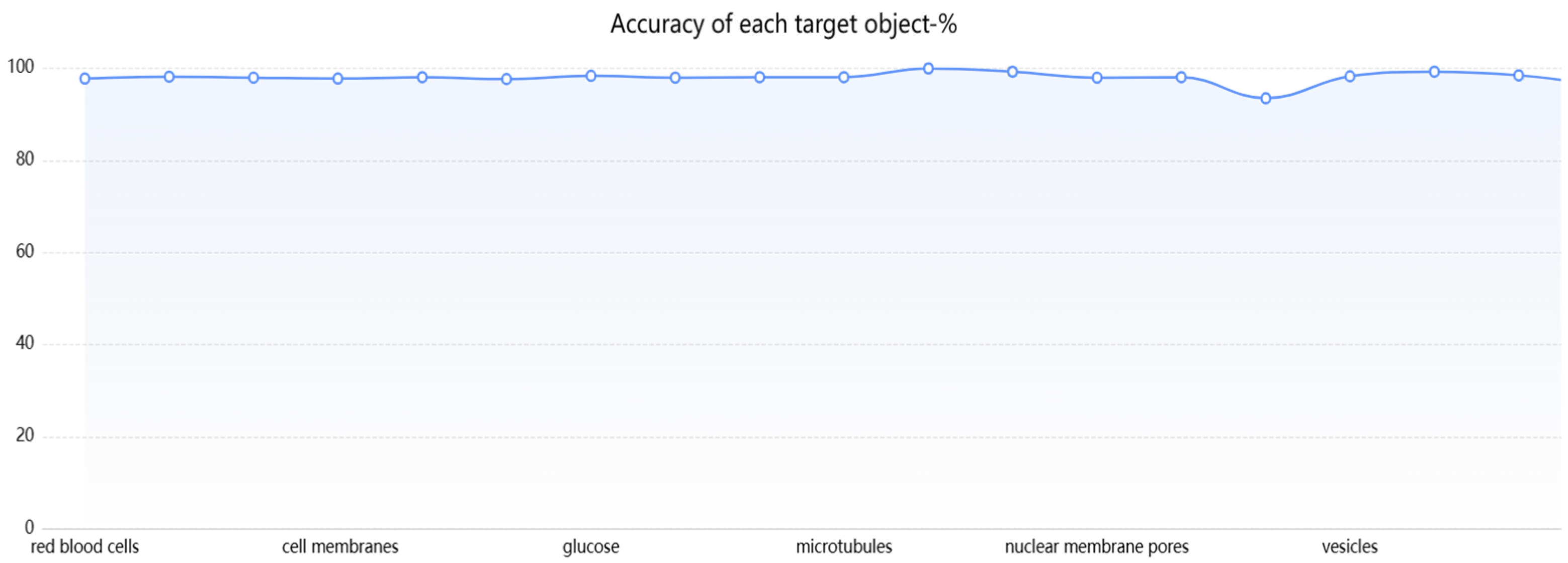
6.3. Analysis of Experimental Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dincă, M.; Berge, T.; Onițiu, A.; Thomassen, M.; Luștrea, A.; Lucheș, D.; Crașovan, M. Immersive Team-Based Learning in Transnational Virtual Classrooms. Eur. Rev. Appl. Sociol. 2023, 16, 51–70. [Google Scholar] [CrossRef]
- Gunawan, A.; Wiranto, N.; Wu, D. Application of virtual reality in diverse fields of study in education sector: A systematic literature review. Procedia Comput. Sci. 2023, 227, 948–957. [Google Scholar] [CrossRef]
- Cho, Y.; Park, K.S. Designing Immersive Virtual Reality Simulation for Environmental Science Education. Electronics 2023, 12, 315. [Google Scholar] [CrossRef]
- Yan, S. The Application of Virtual Reality Technology in Higher Education and Its Impact on Student Learning Performance. Educ. Rev. USA 2023, 7, 1808–1812. [Google Scholar] [CrossRef]
- Predescu, S.L.; Caramihai, S.I.; Moisescu, M.A. Impact of VR application in an academic context. Appl. Sci. 2023, 13, 4748. [Google Scholar] [CrossRef]
- Ferdinand, J.; Gao, H.; Stark, P.; Bozkir, E.; Hahn, J.U.; Kasneci, E.; Göllner, R. The impact of a usefulness intervention on students’ learning achievement in a virtual biology lesson: An eye-tracking-based approach. Learn. Instr. 2024, 90, 101867. [Google Scholar] [CrossRef]
- Wei, Z.; Yuan, M. Research on the Current Situation and Future Development Trend of Immersive Virtual Reality in the Field of Education. Sustainability 2023, 15, 7531. [Google Scholar] [CrossRef]
- Yu, Z. A meta-analysis of the effect of virtual reality technology use in education. Interact. Learn. Environ. 2023, 31, 4956–4976. [Google Scholar] [CrossRef]
- Liao, X. Immersive Learning: Characteristics of Development of VR Education Technology and the Practice. Adv. Educ. Technol. Psychol. 2023, 7, 107–111. [Google Scholar]
- Makransky, G.; Petersen, G.B.; Klingenberg, S. Can an immersive virtual reality simulation increase students’ interest and career aspirations in science? Br. J. Educ. Technol. 2020, 51, 2079–2097. [Google Scholar] [CrossRef]
- Lui, M.; McEwen, R.; Mullally, M. Immersive virtual reality for supporting complex scientific knowledge: Augmenting our understanding with physiological monitoring. Br. J. Educ. Technol. 2020, 51, 2180–2198. [Google Scholar] [CrossRef]
- Wang, H. Exploration of Evaluation Method for Achievement of Learning Effectiveness Based on Virtual Reality Technology. Int. J. Math. Syst. Sci. 2023, 6, 3742. [Google Scholar]
- Mousavi, S.M.; Powell, W.; Louwerse, M.M.; Hendrickson, A.T. Behavior and self-efficacy modulate learning in virtual reality simulations for training: A structural equation modeling approach. Front. Virtual Real. 2023, 4, 1250823. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Zhang, Q.; Zhou, B.; Wang, B. VR-Enhanced Cognitive Learning: Method, Framework, and Application. Appl. Sci. 2023, 13, 4756. [Google Scholar] [CrossRef]
- Chen, J.; Fu, Z.; Liu, H.; Wang, J. Effectiveness of Virtual Reality on Learning Engagement: A Meta-Analysis. Int. J. Web-Based Learn. Teach. Technol. (IJWLTT) 2023, 19, 1–14. [Google Scholar] [CrossRef]
- Kang, J. Effect of Interaction Based on Augmented Context in Immersive Virtual Reality Environment. Wirel. Pers. Commun. 2018, 98, 1931–1940. [Google Scholar] [CrossRef]
- Chen, S.; Li, Q.; Wang, T. Smart Campus and Student Learning Engagement. Int. J. Inf. Commun. Technol. Educ. (IJICTE) 2024, 20, 1–22. [Google Scholar] [CrossRef]
- López-Banet, L.; Martínez-Carmona, M.; Reis, P. Effects of an intervention on emotional and cognitive engagement in teacher education: Scientific practices concerning greenhouse gases. In Frontiers in Education; Frontiers Media SA: Lausanne, Switzerland, 2024; Volume 9, p. 1307847. [Google Scholar]
- Prayogo, A.; Khotimah, K.; Istiqomah, L.; Maharsi, I. Students’ emotional engagement in online classes: A conceptual framework. Int. J. Inf. Learn. Technol. 2024, 41, 61–72. [Google Scholar] [CrossRef]
- Pan, X. Online Learning Environments, Learners’ Empowerment, and Learning Behavioral Engagement: The Mediating Role of Learning Motivation. SAGE Open 2023, 13, 21582440231205098. [Google Scholar] [CrossRef]
- Essoe, J.K.Y.; Reggente, N.; Ohno, A.A.; Baek, Y.H.; Dell’Italia, J.; Rissman, J. Enhancing learning and retention with distinctive virtual reality environments and mental context reinstatement. NPJ Sci. Learn. 2022, 7, 31. [Google Scholar] [CrossRef] [PubMed]
- Parong, J.; Mayer, R.E. Cognitive and affective processes for learning science in immersive virtual reality. J. Comput. Assist. Learn. 2020, 37, 226–241. [Google Scholar] [CrossRef]
- Kim, C.; Cha, H.S.; Kim, J.; Kwak, H.; Lee, W.; Im, C.H. Facial Motion Capture System Based on Facial Electromyogram and Electrooculogram for Immersive Social Virtual Reality Applications. Sensors 2023, 23, 3580. [Google Scholar] [CrossRef] [PubMed]
- Hütten, N.; Alves Gomes, M.; Hölken, F.; Andricevic, K.; Meyes, R.; Meisen, T. Deep Learning for Automated Visual Inspection in Manufacturing and Maintenance: A Survey of Open-Access Papers. Appl. Syst. Innov. 2024, 7, 11. [Google Scholar] [CrossRef]
- Dewan, M.; Murshed, M.; Lin, F. Engagement detection in online learning: A review. Smart Learn. Environ. 2019, 6, 1. [Google Scholar] [CrossRef]
- Yin Albert, C.C.; Sun, Y.; Li, G.; Peng, J.; Ran, F.; Wang, Z.; Zhou, J. Identifying and Monitoring Students’ Classroom Learning Behavior Based on Multisource Information. Mob. Inf. Syst. 2022, 10, 1155. [Google Scholar] [CrossRef]
- Qi, Y.; Zhuang, L.; Chen, H.; Han, X.; Liang, A. Evaluation of Students’ Learning Engagement in Online Classes Based on Multimodal Vision Perspective. Electronics 2023, 13, 149. [Google Scholar] [CrossRef]
- Xie, N.; Liu, Z.; Li, Z.; Pang, W.; Lu, B. Student engagement detection in online environment using computer vision and multi-dimensional feature fusion. Multimed. Syst. 2023, 29, 3559–3577. [Google Scholar] [CrossRef]
- Ling, W. Automatic Recognition of Students’ Classroom Behavior Based on Computer Vision. Acad. J. Comput. Inf. Sci. 2022, 5, 31–34. [Google Scholar]
- Ngoc Anh, B.; Tung Son, N.; Truong Lam, P.; Phuong Chi, L.; Huu Tuan, N.; Cong Dat, N.; Huu Trung, N.; Umar Aftab, M.; Van Dinh, T. A computer-vision based application for student behavior monitoring in classroom. Appl. Sci. 2019, 9, 4729. [Google Scholar] [CrossRef]
- Dubovi, I. Cognitive and emotional engagement while learning with VR: The perspective of multimodal methodology. Comput. Educ. 2022, 183, 104495. [Google Scholar] [CrossRef]
- Zheng, L. Application of Multi-sensory interaction design Based on Machine Learning in Virtual Reality. J. Phys. Conf. Ser. 2023, 2665, 1742–6596. [Google Scholar] [CrossRef]
- Zhang, Z.; Fort, J.M. Facial expression recognition in virtual reality environments: Challenges and opportunities. Front. Psychol. 2023, 14, 1280136. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Chai, C.; Jong, S.M.; Chao, G.C.N. Modeling learners’ self-concept in Chinese descriptive writing based on the affordances of a virtual reality-supported environment. Educ. Inf. Technol. 2021, 26, 6013–6032. [Google Scholar] [CrossRef]
- Liu, R.; Wang, L.; Lei, J.; Wang, Q.; Ren, Y. Effects of an immersive virtual reality-based classroom on students’ learning performance in science lessons. Br. J. Educ. Technol. 2020, 51, 2034–2049. [Google Scholar] [CrossRef]
- Parong, J.; Mayer, R.E. Learning about history in immersive virtual reality: Does immersion facilitate learning? Educ. Technol. Res. Dev. 2021, 69, 1433–1451. [Google Scholar] [CrossRef]
- Sudarma, I.K.; Prabawa, D.; Suartama, I.K. The application of information processing theory to design digital content in learning message design course. Int. J. Inf. Educ. Technol. 2022, 12, 1043–1049. [Google Scholar] [CrossRef]
- Robb, L.; David, D. Viewpoint, embodiment, and roles in STEM learning technologies. Educ. Technol. Res. Dev. 2022, 70, 1009–1034. [Google Scholar]
- Hu, R.; Hui, Z.; Li, Y.; Guan, J. Research on learning concentration recognition with multi-modal features in virtual reality environments. Sustainability 2023, 15, 11606. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics of Detected Visual Learning Object | Knowledge Retention | Knowledge Transfer |
|---|---|---|
| visual coverage | 0.62 | 0.90 |
| visual attention duration | 0.22 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, L.; Li, Q.; Wang, D. Intelligent Analysis System for Teaching and Learning Cognitive Engagement Based on Computer Vision in an Immersive Virtual Reality Environment. Appl. Sci. 2024, 14, 3149. https://doi.org/10.3390/app14083149
Li C, Wang L, Li Q, Wang D. Intelligent Analysis System for Teaching and Learning Cognitive Engagement Based on Computer Vision in an Immersive Virtual Reality Environment. Applied Sciences. 2024; 14(8):3149. https://doi.org/10.3390/app14083149
Chicago/Turabian StyleLi, Ce, Li Wang, Quanzhi Li, and Dongxuan Wang. 2024. "Intelligent Analysis System for Teaching and Learning Cognitive Engagement Based on Computer Vision in an Immersive Virtual Reality Environment" Applied Sciences 14, no. 8: 3149. https://doi.org/10.3390/app14083149
APA StyleLi, C., Wang, L., Li, Q., & Wang, D. (2024). Intelligent Analysis System for Teaching and Learning Cognitive Engagement Based on Computer Vision in an Immersive Virtual Reality Environment. Applied Sciences, 14(8), 3149. https://doi.org/10.3390/app14083149