
An Efficiency Boost for Genetic Algorithms: Initializing the GA with the Iterative Approximate Method for Optimizing the Traveling Salesman Problem—Experimental Insights


Abstract
:1. Introduction
1.1. Initial Population
1.2. TSP
1.3. Proposed Methodology and Contributions
- Improvement of Quality: By using a new method to initialize the GA population, our proposed method guarantees that the beginning point is closer to the optimal solution, resulting in a significant improvement in the quality of the solution.
- Durability: The proposed method shows resilience in generating high-quality solutions in a variety of TSP instances, highlighting its durability and applicability to various scenarios.
- Computational Efficiency: We accomplish computational efficiency by lowering the temporal complexity involved in locating a near-optimal route in TSPs, which improves the GA’s overall performance, allowing it to converge faster. This is made possible by the usage of IAM-TSP+.
2. Related Work
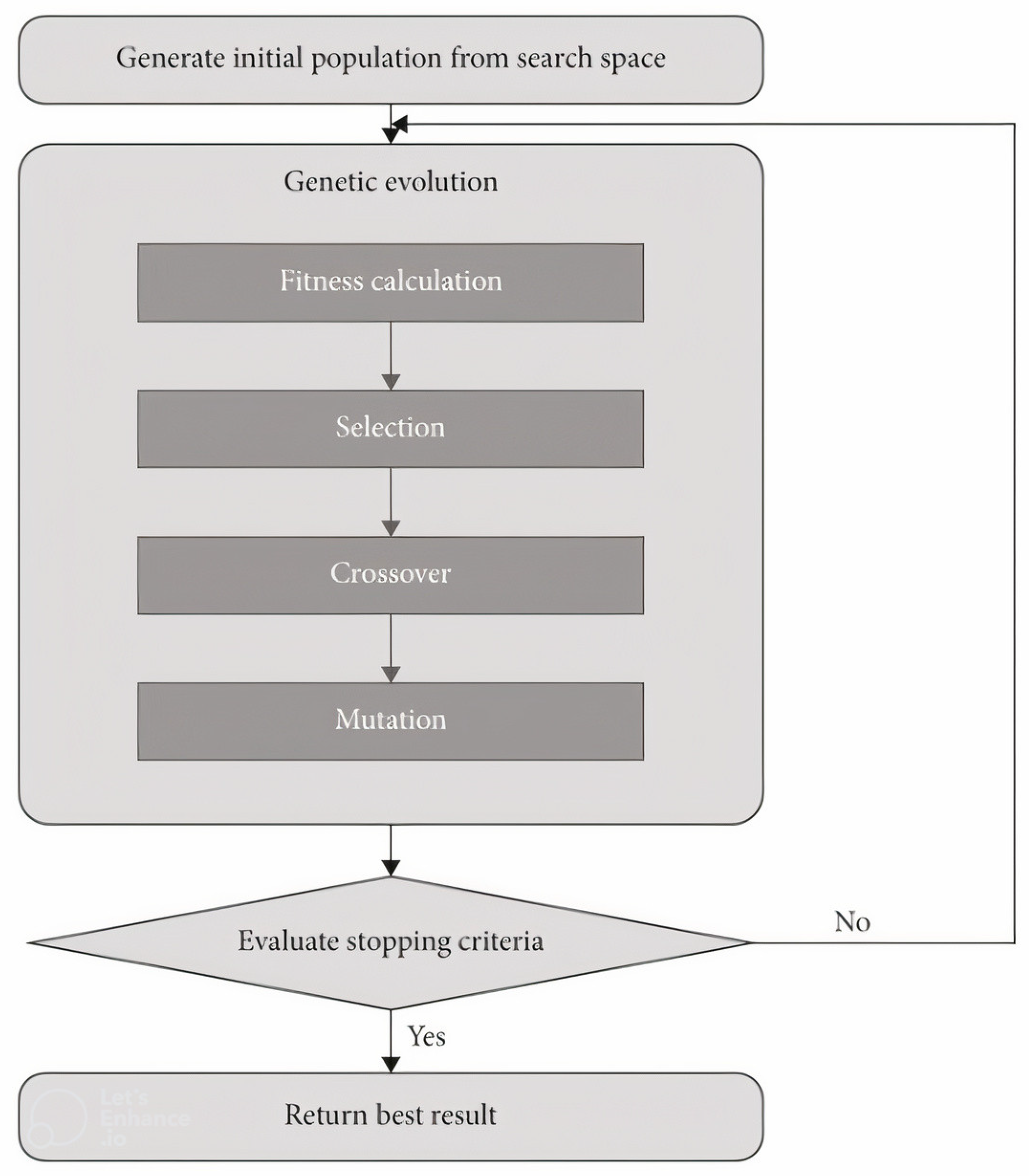
3. Methods
| Algorithm 1 The proposed IAM-TSP algorithm |
|
| Algorithm 2 The proposed IAM-TSP+ algorithm |
|
4. Experimental Settings, Results, and Discussion
4.1. Experimental Setup
- 11th Gen Intel(R) Core (TM) i7-1165G7 @ 80 GHz 2.80 GHz;
- 8.00 GB of RAM;
- Windows 11 Pro, 64-bit operating system.
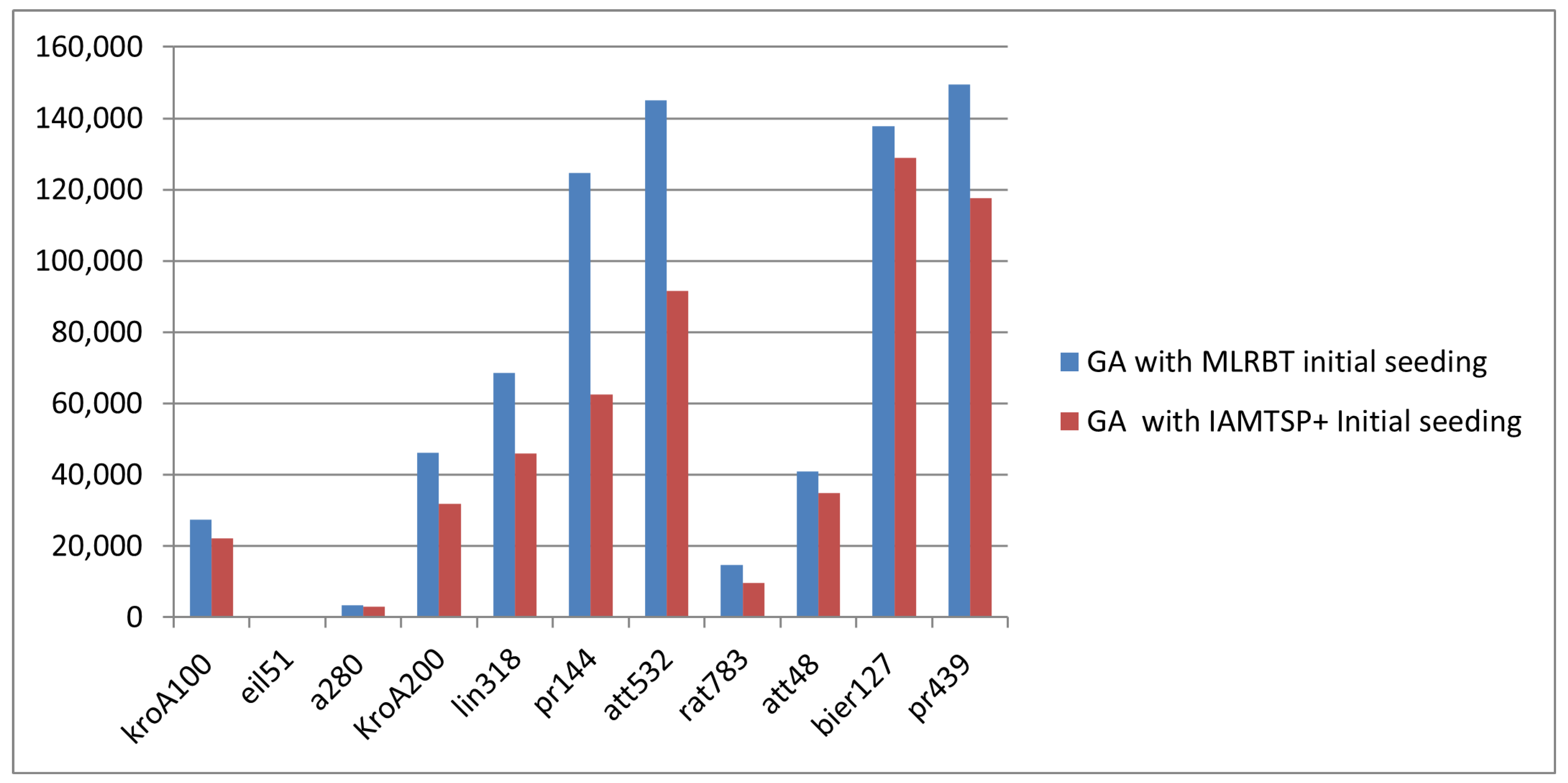
4.2. Experimental Results and Discussion
4.3. Experiments on Simulated Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GA | Genetic algorithm |
| NN | Nearest neighbor |
| TSP | Traveling Salesman Problem |
| IAM-TSP | Iterative Approximate Methods |
| MLRBT | Multi-Linear Regression-Based Technique |
References
- Zhou, G.; Zhu, Z.; Luo, S. Location optimization of electric vehicle charging stations: Based on cost model and genetic algorithm. Energy 2022, 247, 123437. [Google Scholar] [CrossRef]
- Han, S.; Xiao, L. An improved adaptive genetic algorithm. Proc. Shs Web Conf. Edp Sci. 2022, 140, 01044. [Google Scholar] [CrossRef]
- Bi, H.; Lu, F.; Duan, S.; Huang, M.; Zhu, J.; Liu, M. Two-level principal–agent model for schedule risk control of IT outsourcing project based on genetic algorithm. Eng. Appl. Artif. Intell. 2020, 91, 103584. [Google Scholar] [CrossRef]
- Arram, A.; Ayob, M. A novel multi-parent order crossover in genetic algorithm for combinatorial optimization problems. Comput. Ind. Eng. 2019, 133, 267–274. [Google Scholar] [CrossRef]
- Hassanat, A.B.; Alkafaween, E.; Al-Nawaiseh, N.A.; Abbadi, M.A.; Alkasassbeh, M.; Alhasanat, M.B. Enhancing genetic algorithms using multi mutations: Experimental results on the travelling salesman problem. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 785. [Google Scholar]
- Lu, F.; Bi, H.; Huang, M.; Duan, S. Simulated annealing genetic algorithm based schedule risk management of IT outsourcing project. Math. Probl. Eng. 2017, 2017, 6916575. [Google Scholar] [CrossRef]
- Hassanat, A.; Almohammadi, K.; Alkafaween, E.; Abunawas, E.; Hammouri, A.; Prasath, V.S. Choosing mutation and crossover ratios for genetic algorithms—A review with a new dynamic approach. Information 2019, 10, 390. [Google Scholar] [CrossRef]
- Paul, P.V.; Ramalingam, A.; Baskaran, R.; Dhavachelvan, P.; Vivekanandan, K.; Subramanian, R. A new population seeding technique for permutation-coded Genetic Algorithm: Service transfer approach. J. Comput. Sci. 2014, 5, 277–297. [Google Scholar] [CrossRef]
- Shanmugam, M.; Basha, M.S.; Paul, P.V.; Dhavachelvan, P.; Baskaran, R. Performance assessment over heuristic population seeding techniques of genetic algorithm: Benchmark analyses on traveling salesman problems. Int. J. Appl. Eng. Res. (Ijaer) Res. India Publ. 2013, 8, 1171–1184. [Google Scholar]
- Riazi, A. Genetic algorithm and a double-chromosome implementation to the traveling salesman problem. Appl. Sci. 2019, 1, 1397. [Google Scholar] [CrossRef]
- Hassanat, A.B.; Alkafaween, E. On enhancing genetic algorithms using new crossovers. Int. J. Comput. Appl. Technol. 2017, 55, 202–212. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Alkafaween, E.; Hassanat, A.B.; Tarawneh, S. Improving initial population for genetic algorithm using the multi linear regression based technique (MLRBT). Commun. Sci. Lett. Univ. Zilina 2021, 23, E1–E10. [Google Scholar] [CrossRef]
- Alkafaween, E.; Hassanat, A. Improving TSP Solutions Using GA with a New Hybrid Mutation Based on Knowledge and Randomness. Komunikácie 2020, 22, 12. [Google Scholar] [CrossRef]
- Bhandari, A.; Tripathy, B.; Jawad, K.; Bhatia, S.; Rahmani, M.K.I.; Mashat, A. Cancer detection and prediction using genetic algorithms. Comput. Intell. Neurosci. 2022, 2022, 1871841. [Google Scholar] [CrossRef] [PubMed]
- Hassanat, A. Greedy algorithms for approximating the diameter of machine learning datasets in multidimensional Euclidean space: Experimental results. Adcaij Adv. Distrib. Comput. Artif. Intell. J. 2018, 7, 15. [Google Scholar] [CrossRef]
- Paul, V.; Ganeshkumar, C.; Jayakumar, L. Performance evaluation of population seeding techniques of permutation-coded GA traveling salesman problems based assessment: Performance evaluation of population seeding techniques of permutation-coded GA. Int. J. Appl. Metaheuristic Comput. (Ijamc) 2019, 10, 55–92. [Google Scholar] [CrossRef]
- Toğan, V.; Daloğlu, A.T. An improved genetic algorithm with initial population strategy and self-adaptive member grouping. Comput. Struct. 2008, 86, 1204–1218. [Google Scholar] [CrossRef]
- Pan, W.; Li, K.; Wang, M.; Wang, J.; Jiang, B. Adaptive randomness: A new population initialization method. Math. Probl. Eng. 2014, 2014, 975916. [Google Scholar] [CrossRef]
- Maaranen, H.; Miettinen, K.; Penttinen, A. On initial populations of a genetic algorithm for continuous optimization problems. J. Glob. Optim. 2007, 37, 405–436. [Google Scholar] [CrossRef]
- Keedwell, E.; Khu, S.T. A hybrid genetic algorithm for the design of water distribution networks. Eng. Appl. Artif. Intell. 2005, 18, 461–472. [Google Scholar] [CrossRef]
- Hassanat, A.B.; Prasath, V.S.; Abbadi, M.A.; Abu-Qdari, S.A.; Faris, H. An improved genetic algorithm with a new initialization mechanism based on regression techniques. Information 2018, 9, 167. [Google Scholar] [CrossRef]
- Ray, S.S.; Bandyopadhyay, S.; Pal, S.K. Genetic operators for combinatorial optimization in TSP and microarray gene ordering. Appl. Intell. 2007, 26, 183–195. [Google Scholar] [CrossRef]
- Yang, R. Solving large travelling salesman problems with small populations. In Proceedings of the Second International Conference On Genetic Algorithms In Engineering Systems: Innovations and Applications, IET, Glasgow, UK, 2–4 September 1997; pp. 157–162. [Google Scholar]
- Wei, Y.; Hu, Y.; Gu, K. Parallel search strategies for TSPs using a greedy genetic algorithm. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007; Volume 3, pp. 786–790. [Google Scholar]
- Yugay, O.; Kim, I.; Kim, B.; Ko, F.I. Hybrid genetic algorithm for solving traveling salesman problem with sorted population. In Proceedings of the 2008 Third International Conference on Convergence and Hybrid Information Technology, Busan, Republic of Korea, 1–13 November 2008; Volume 2, pp. 1024–1028. [Google Scholar]
- Deng, Y.; Liu, Y.; Zhou, D. An improved genetic algorithm with initial population strategy for symmetric TSP. Math. Probl. Eng. 2015, 2015. [Google Scholar] [CrossRef]
- Li, C.; Chu, X.; Chen, Y.; Xing, L. A knowledge-based technique for initializing a genetic algorithm. J. Intell. Fuzzy Syst. 2016, 31, 1145–1152. [Google Scholar] [CrossRef]
- Laporte, G. The traveling salesman problem: An overview of exact and approximate algorithms. Eur. J. Oper. Res. 1992, 59, 231–247. [Google Scholar] [CrossRef]
- Potvin, J.Y. Genetic algorithms for the traveling salesman problem. Ann. Oper. Res. 1996, 63, 337–370. [Google Scholar] [CrossRef]
- Matai, R.; Singh, S.P.; Mittal, M.L. Traveling salesman problem: An overview of applications, formulations, and solution approaches. In Traveling Salesman Problem: Theory and Applications; BoD–Books on Demand: Norderstedt, Germany, 2010; Volume 1, pp. 1–25. [Google Scholar]
- Paul, P.V.; Dhavachelvan, P.; Baskaran, R. A novel population initialization technique for genetic algorithm. In Proceedings of the 2013 International Conference on Circuits, Power and Computing Technologies (ICCPCT), Nagercoil, India, 20–21 March 2013; pp. 1235–1238. [Google Scholar]
- Hoffman, K.L.; Padberg, M.; Rinaldi, G. Traveling salesman problem. Encycl. Oper. Res. Manag. Sci. 2013, 1, 1573–1578. [Google Scholar]
- Davendra, D. Traveling Salesman Problem: Theory and Applications; BoD–Books on Demand: Norderstedt, Germany, 2010. [Google Scholar]
- Lu, F.; Chen, W.; Feng, W.; Bi, H. 4PL routing problem using hybrid beetle swarm optimization. Soft Comput. 2023, 27, 17011–17024. [Google Scholar] [CrossRef]
- Gülcü, Ş.; Mahi, M.; Baykan, Ö.K.; Kodaz, H. A parallel cooperative hybrid method based on ant colony optimization and 3-Opt algorithm for solving traveling salesman problem. Soft Comput. 2018, 22, 1669–1685. [Google Scholar] [CrossRef]
- Feng, X.; Lau, F.C.; Gao, D. A new bio-inspired approach to the traveling salesman problem. In Proceedings of the Complex Sciences: First International Conference, Complex 2009, Shanghai, China, 23–25 February 2009; Revised Papers, Part 21. Springer: Berlin/Heidelberg, Germany, 2009; pp. 1310–1321. [Google Scholar]
- Hao, Z.; Huang, H.; Cai, R. Bio-inspired Algorithms for TSP and Generalized TSP. In Traveling Salesman Problem; Greco, F., Ed.; InTech Open: London, UK, 2008; pp. 35–62. ISBN 978-953-7619-10-7. [Google Scholar]
- Brady, R. Optimization strategies gleaned from biological evolution. Nature 1985, 317, 804–806. [Google Scholar] [CrossRef]
- Scholz, J. Genetic algorithms and the traveling salesman problem a historical review. arXiv 2019, arXiv:1901.05737. [Google Scholar]
- Alkafaween, E.; Elmougy, S.; Essa, E.; Mnasri, S.; Tarawneh, A.S.; Hassanat, A. IAM-TSP: Iterative Approximate Methods for Solving the Travelling Salesman Problem. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 11. [Google Scholar] [CrossRef]
- Abdallah, W.; Val, T. Genetic-Voronoi algorithm for coverage of IoT data collection networks. In Proceedings of the 2020 30th International Conference on Computer Theory and Applications (ICCTA), Virtual, 12–14 December 2020; pp. 16–22. [Google Scholar]
- Yuan, Q.; Wang, S.; Hu, M.; Zeng, L. SLDChOA: A comprehensive and competitive multi-strategy-enhanced chimp algorithm for global optimization and engineering design. J. Supercomput. 2024, 80, 3589–3643. [Google Scholar] [CrossRef]
- Mnasri, S.; Thaljaoui, A.; Nasri, N.; Val, T. A genetic algorithm-based approach to optimize the coverage and the localization in the wireless audio-sensors networks. In Proceedings of the 2015 International Symposium on Networks, Computers and Communications (ISNCC), Hammamet, Tunisia, 13–15 May 2015; pp. 1–6. [Google Scholar]
- Mnasri, S.; Nasri, N.; Van Den Bossche, A.; Val, T. A hybrid ant-genetic algorithm to solve a real deployment problem: A case study with experimental validation. In Proceedings of the Ad-hoc, Mobile, and Wireless Networks: 16th International Conference on Ad Hoc Networks and Wireless, ADHOC-NOW 2017, Messina, Italy, 20–22 September 2017; Proceedings 16. Springer: Berlin/Heidelberg, Germany, 2017; pp. 367–381. [Google Scholar]
- Nagata, Y.; Soler, D. A new genetic algorithm for the asymmetric traveling salesman problem. Expert Syst. Appl. 2012, 39, 8947–8953. [Google Scholar] [CrossRef]
- Dao, S.D.; Abhary, K.; Marian, R. An effective genetic algorithm for large-scale traveling salesman problems. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 19–21 October 2016; Volume 1. [Google Scholar]
- Reinelt, G. TSPLIB, 1996. 12 2. 2023. Available online: http://comopt.ifi.uni-heidelberg.de/software/TSPLIB95/ (accessed on 22 January 2024).
- Sivanandam, S.; Deepa, S.; Sivanandam, S.; Deepa, S. Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Sun, W. A novel genetic admission control for real-time multiprocessor systems. In Proceedings of the 2009 International Conference on Parallel and Distributed Computing, Applications and Technologies, Higashi Hiroshima, Japan, 8–11 December 2009; pp. 130–137. [Google Scholar]
- Jebari, K.; Madiafi, M. Selection methods for genetic algorithms. Int. J. Emerg. Sci. 2013, 3, 333–344. [Google Scholar]
- Bala, A.; Sharma, A.K. A comparative study of modified crossover operators. In Proceedings of the 2015 Third International Conference on Image Information Processing (ICIIP), Waknaghat, India, 21–24 December 2015; pp. 281–284. [Google Scholar]
- Banzhaf, W. The “molecular” traveling salesman. Biol. Cybern. 1990, 64, 7–14. [Google Scholar] [CrossRef]
- Song, J.; Pu, Y.; Xu, X. Adaptive Ant Colony Optimization with Sub-Population and Fuzzy Logic for 3D Laser Scanning Path Planning. Sensors 2024, 24, 1098. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, P.; Zhang, H.; Song, H.; Bei, J.; Sun, W.; Sun, X. A carnivorous plant algorithm with heuristic decoding method for traveling salesman problem. IEEE Access 2022, 10, 97142–97164. [Google Scholar] [CrossRef]
- Pan, H.; You, X.; Liu, S. High-frequency path mining-based reward and punishment mechanism for multi-colony ant colony optimization. IEEE Access 2020, 8, 155459–155476. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Abdollahzadeh, B.; Arasteh, B. An improved farmland fertility algorithm with hyper-heuristic approach for solving travelling salesman problem. Cmes-Comput. Model. Eng. Sci. 2022, 135, 1–26. [Google Scholar]
- Hussain, A.; Muhammad, Y.S.; Sajid, M.N. A simulated study of genetic algorithm with a new crossover operator using traveling salesman problem. J. Math. 2019, 51, 61–77. [Google Scholar]
- Shahab, M. New heuristic algorithm for traveling salesman problem. Proc. J. Phys. Conf. Ser. Iop Publ. 2019, 1218, 012038. [Google Scholar] [CrossRef]
- Btoush, A.; Tareef, A.; Alkasasbeh, A.A. Network Propagation Loss Models: Effects and Classification. In Proceedings of the 2022 International Conference on Emerging Trends in Computing and Engineering Applications (ETCEA), Karak, Jordan, 23–25 November 2022; pp. 1–6. [Google Scholar]
- Abadleh, A.; Btoush, A.; Alkasasbeh, A.A.; Mahadeen, A.; Al-Hawari, E.; Tareef, A.; Al-Mjali, M.M. Mitigating the Effect of Blackhole Attacks in MANAT. J. Eng. Sci. Technol. Rev. 2022, 15, 107. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value/Method |
|---|---|
| Population size | 100 |
| Generation limit | 3000 |
| Initialization method | IAMTSP method and Multi-Linear Regression-Based Technique (MLRBT) [13] |
| Crossover method | One-point modified |
| Crossover rate | 82% |
| Mutation | Exchange mutation |
| Mutation rate | 100% |
| Selection mechanism | Truncation Selection |
| Termination criterion | Generation limit |
| Instance | Optimal Solution | MLRBT | IAMTSP+ | ||
|---|---|---|---|---|---|
| Best Solution | Average | Best Solution | Average | ||
| kroA100 | 21,282 | 27,493 | 29,440.8 | 22,075 | 22,067.4 |
| eil51 | 426 | 465 | 478.6 | 437 | 437 |
| a280 | 2579 | 3473 | 3539.7 | 2957 | 2964.5 |
| KroA200 | 29,368 | 46,269 | 47,877.4 | 31,788 | 31,818.3 |
| lin318 | 42,029 | 68,490 | 70,237.6 | 46,045 | 46,135.7 |
| pr144 | 58,537 | 124,763 | 131,974.3 | 62,446 | 62,446 |
| att532 | 27,686 | 145,128 | 157,423.6 | 91,627 | 91,992.4 |
| rat783 | 8806 | 14,659 | 15,308.1 | 9725 | 9737 |
| att48 | 10,628 | 40,939 | 41,236.9 | 34,877 | 34,877 |
| bier127 | 118,282 | 137,850 | 141,773.7 | 128,848 | 128,848 |
| pr439 | 107,217 | 149,445 | 154,323.3 | 117,650 | 118,096.7 |
| Instance | MLRBT | IAMTSP+ |
|---|---|---|
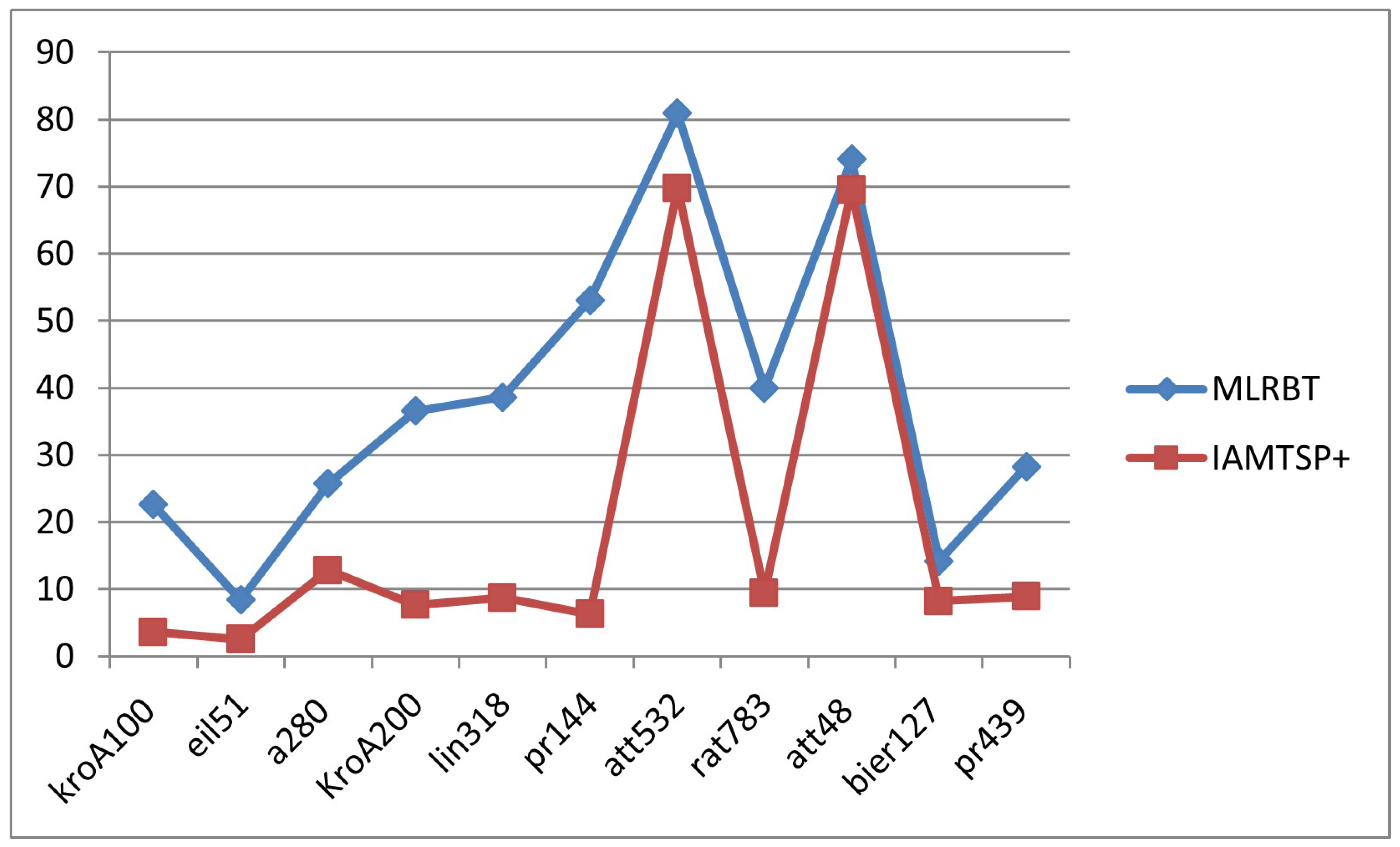
| kroA100 | 22.59121 | 3.592298981 |
| eil51 | 8.387097 | 2.517162471 |
| a280 | 25.74143 | 12.78322624 |
| KroA200 | 36.5277 | 7.612935699 |
| lin318 | 38.63484 | 8.721902487 |
| pr144 | 53.08144 | 6.259808475 |
| att532 | 80.92305 | 69.78401563 |
| rat783 | 39.92769 | 9.449871465 |
| att48 | 74.03942 | 69.52719557 |
| bier127 | 14.19514 | 8.200360114 |
| pr439 | 28.25655 | 8.867828304 |
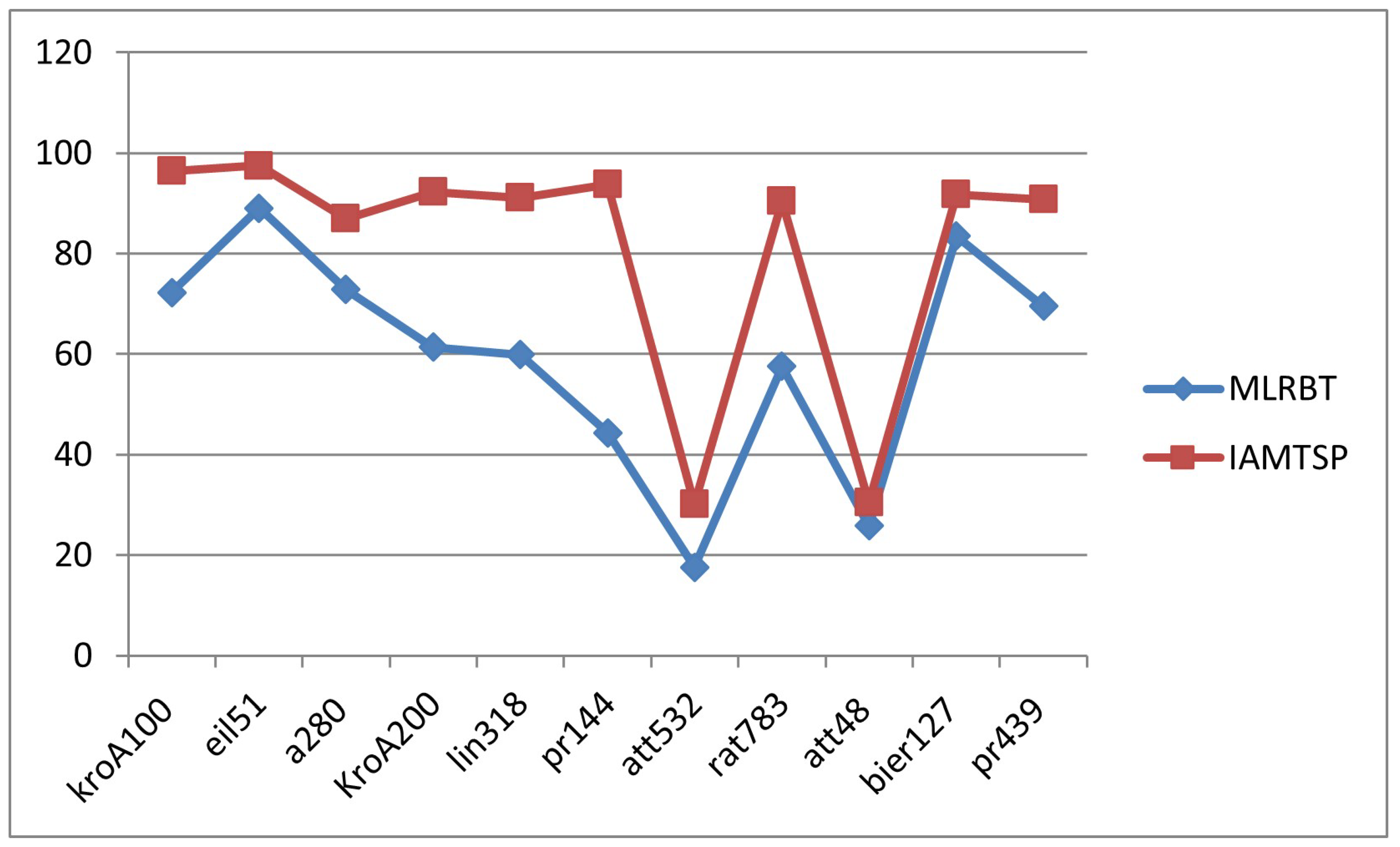
| Instance | MLRBT | IAMTSP+ |
|---|---|---|
| kroA100 | 72.28744 | 96.44090378 |
| eil51 | 89.00961 | 97.48283753 |
| a280 | 72.85928 | 86.99612076 |
| KroA200 | 61.34001 | 92.29908575 |
| lin318 | 59.83832 | 91.09865029 |
| pr144 | 44.35485 | 93.74019153 |
| att532 | 17.58694 | 30.09596445 |
| rat783 | 57.5251 | 90.43853343 |
| att48 | 25.77303 | 30.47280443 |
| bier127 | 83.43014 | 91.79963989 |
| pr439 | 69.47557 | 90.78746485 |
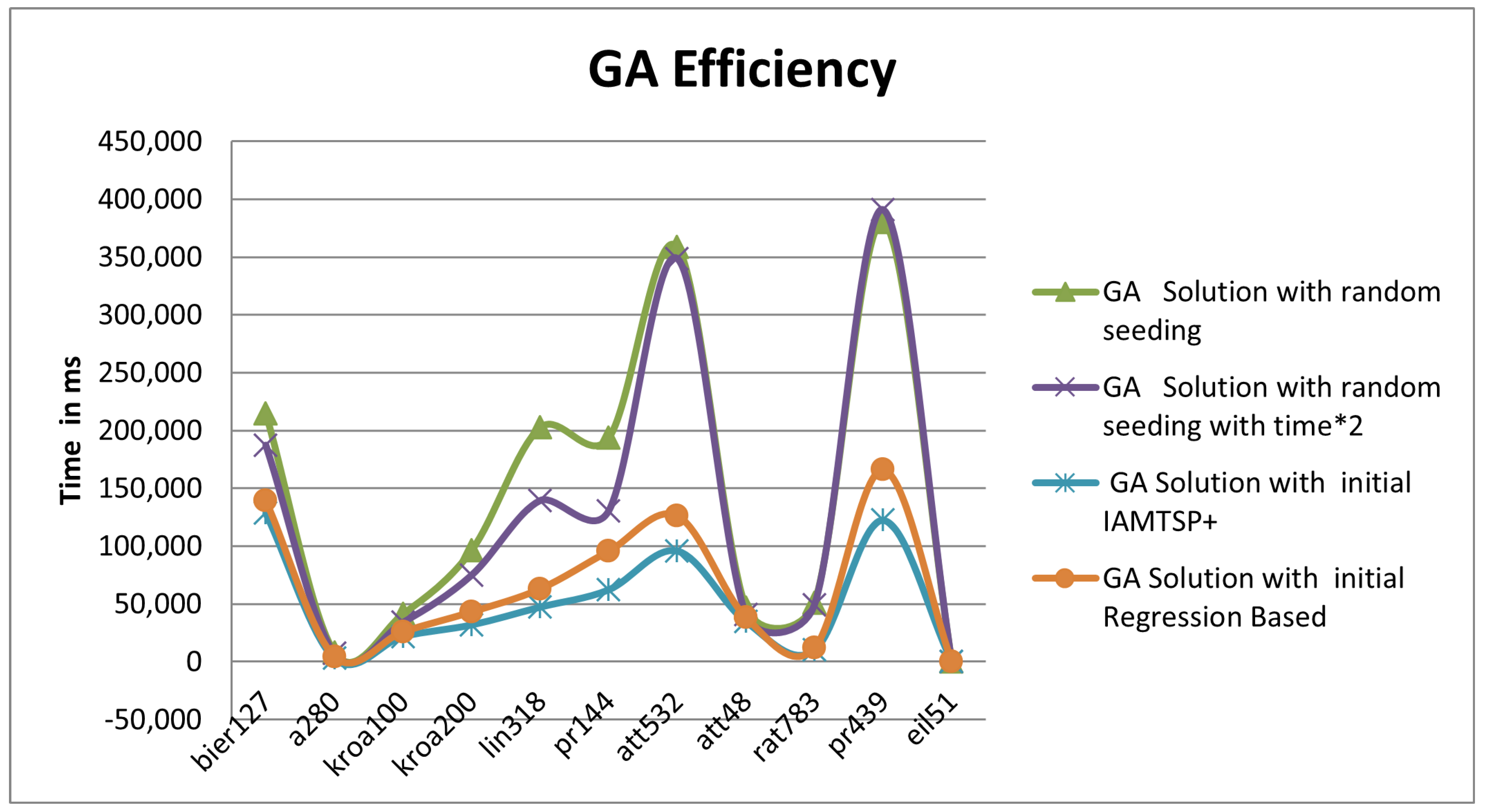
| Instance | Time (ms) | Time ∗ 2 (ms) | GA Solution with Random Seeding | GA Solution with Random Seeding with Time ∗ 2 | GA Solution with Initial IAMTSP+ | GA Solution with Initial Regression Based |
|---|---|---|---|---|---|---|
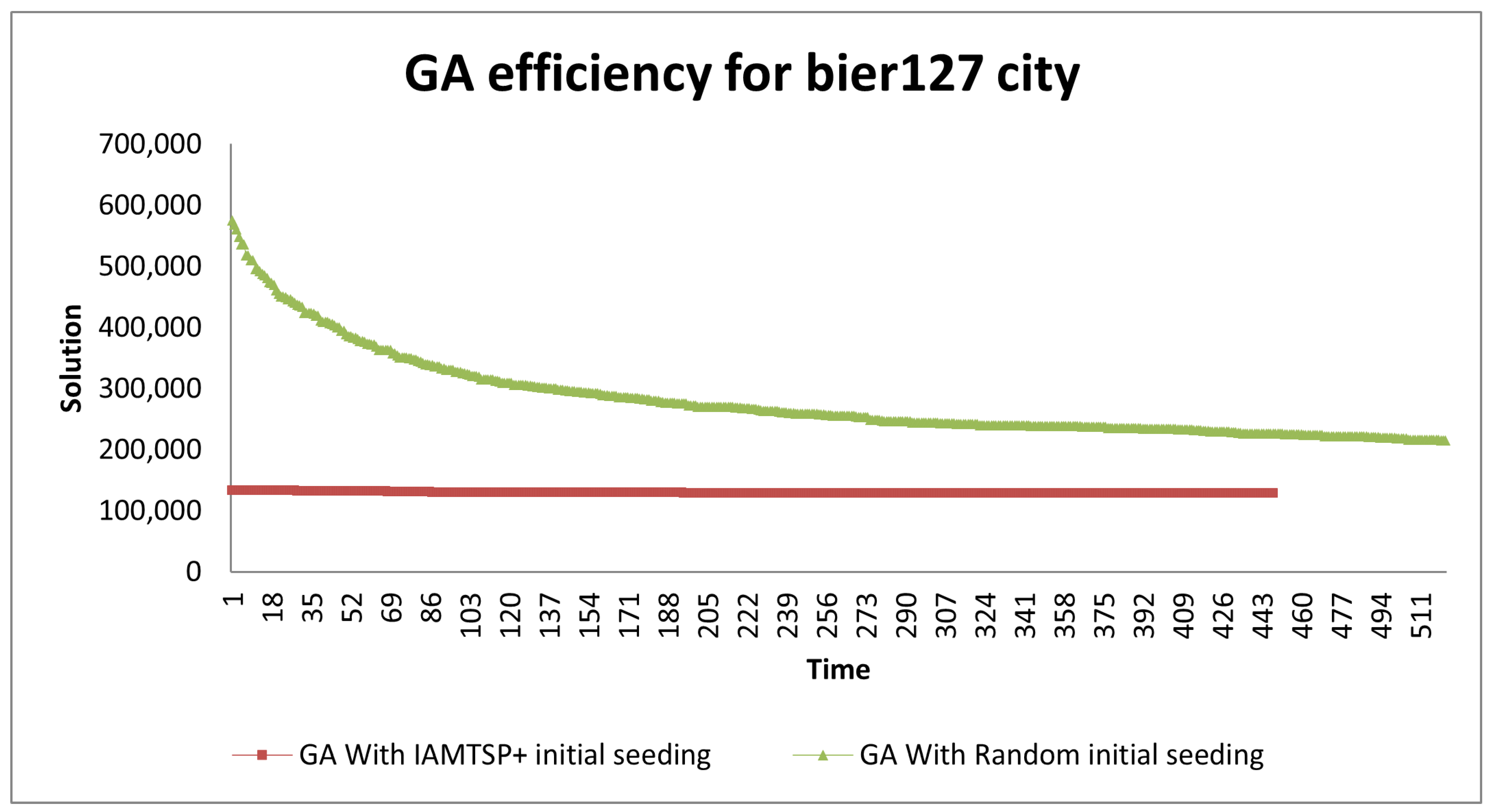
| bier127 | 6023 | 12,046 | 214,928 | 187,452 | 128,678 | 139,460 |
| a280 | 19,399 | 38,798 | 8243 | 7148 | 3018 | 4525 |
| kroA100 | 5565 | 11,130 | 41,233 | 34,176 | 22,057 | 26,040 |
| kroA200 | 9403 | 18,806 | 96,272 | 75,012 | 32,088 | 43,140 |
| lin318 | 27,772 | 55,544 | 202,537 | 139,552 | 47,507 | 63,085 |
| pr144 | 6618 | 13,236 | 193,568 | 130,639 | 62,481 | 95,713 |
| att532 | 173,946 | 347,892 | 358,763 | 348,633 | 96,050 | 126,337 |
| att48 | 5136 | 10,272 | 46,780 | 40,711 | 34,877 | 38,544 |
| rat783 | 803,368 | 1,606,736 | 51,239 | 49,520 | 10,196 | 11,999 |
| pr439 | 89,720 | 179,440 | 380,537 | 390,937 | 122,586 | 166,083 |
| eil51 | 5151 | 10,302 | 493 | 477 | 438 | 463 |
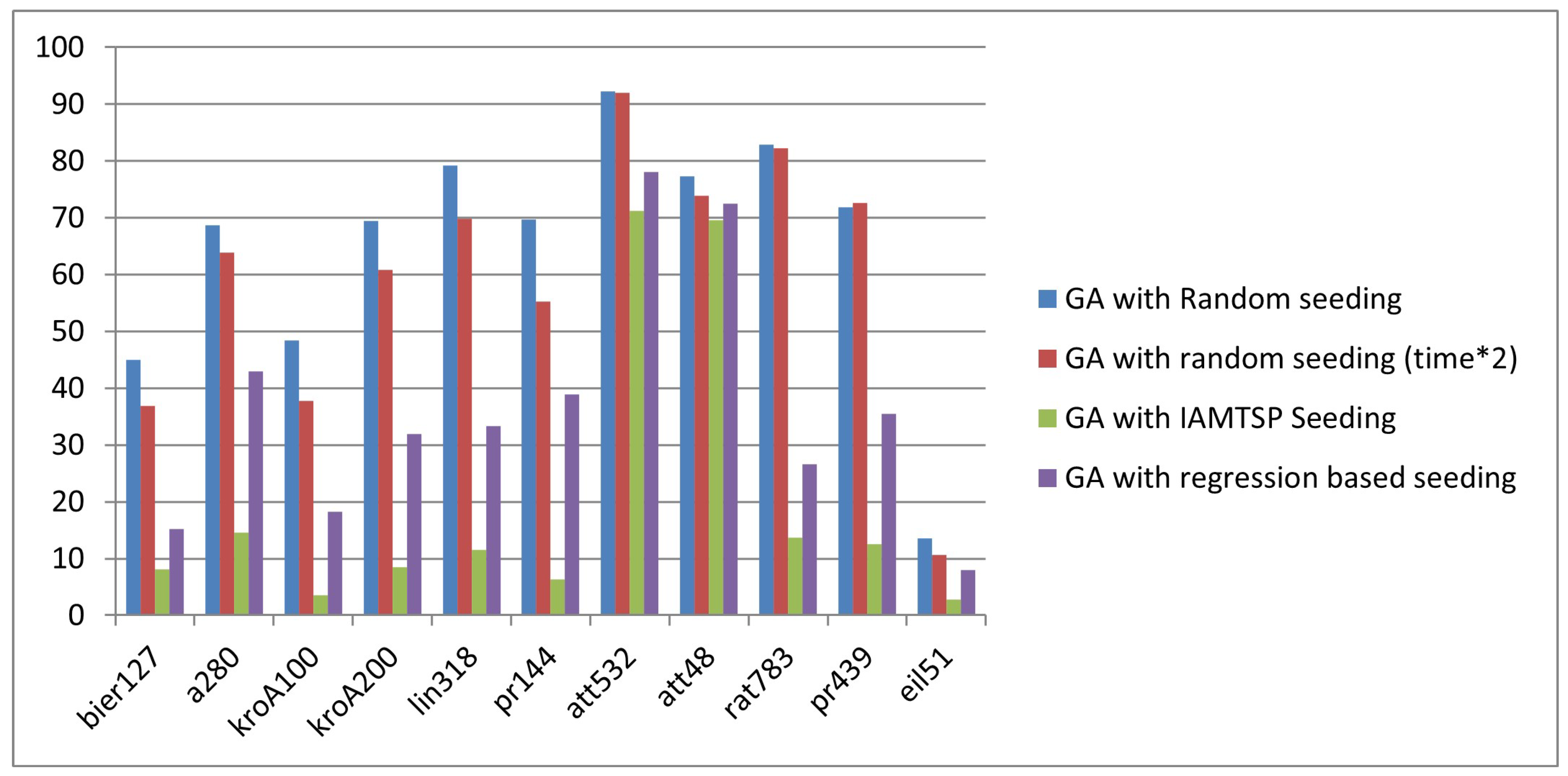
| Instance | GA with Random Seeding | GA with Random Seeding (Time ∗ 2) | GA with IAMTSP+ Seeding | GA with Regression-Based Seeding |
|---|---|---|---|---|
| bier127 | 44.96669 | 36.9001131 | 8.0790811 | 15.18572 |
| a280 | 68.71285 | 63.91997762 | 14.546057 | 43.00552 |
| kroA100 | 48.386 | 37.72823034 | 3.5136238 | 18.27189 |
| kroA200 | 69.49476 | 60.84893084 | 8.4766891 | 31.92397 |
| lin318 | 79.24873 | 69.88291103 | 11.530932 | 33.37719 |
| pr144 | 69.75895 | 55.19178806 | 6.3123189 | 38.84112 |
| att532 | 92.28293 | 92.05869783 | 71.175429 | 78.0856 |
| att48 | 77.28089 | 73.89403355 | 69.527196 | 72.42632 |
| rat783 | 82.81387 | 82.21728595 | 13.632797 | 26.61055 |
| pr439 | 71.82482 | 72.57435341 | 12.537321 | 35.44372 |
| eil51 | 13.59026 | 10.6918239 | 2.739726 | 7.991361 |
| Instance | GA Solution with Random Seeding | GA Solution with Random Seeding with Time ∗ 2 | GA Solution with Initial IAMTSP+ | GA Solution with Regression Based |
|---|---|---|---|---|
| bier127 | 0.009137193 | 0.005238244 | 0.01526165 | 0.014081734 |
| a280 | 0.001612823 | 0.000929945 | 0.004405069 | 0.002938011 |
| kroA100 | 0.009274753 | 0.005594948 | 0.017338073 | 0.014686094 |
| kroA200 | 0.003244202 | 0.002081839 | 0.009733416 | 0.00723982 |
| lin318 | 0.000747201 | 0.00054222 | 0.003185549 | 0.00239892 |
| pr144 | 0.004569515 | 0.003385329 | 0.014156495 | 0.009241294 |
| att532 | 0.0000443648 | 0.0000228269 | 0.00016571 | 0.000125984 |
| att48 | 0.004423503 | 0.002541469 | 0.005933178 | 0.005368708 |
| rat783 | 0.0000213926 | 0.0000110676 | 0.000107506 | 0.0000913522 |
| pr439 | 0.000314035 | 0.00015284 | 0.00097484 | 0.00071953 |
| Instance | Number of Cities | MLRBT | IAMTSP+ | GA with Random | GA with MLRBT | GA with IAMTSP+ |
|---|---|---|---|---|---|---|
| C1 | 100 | 3484 | 3175 | 3813 | 3220 | 3142 |
| C2 | 200 | 6307 | 4514 | 6714 | 5363 | 4418 |
| C3 | 300 | 8630 | 5750 | 12167 | 6510 | 5623 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkafaween, E.; Hassanat, A.; Essa, E.; Elmougy, S. An Efficiency Boost for Genetic Algorithms: Initializing the GA with the Iterative Approximate Method for Optimizing the Traveling Salesman Problem—Experimental Insights. Appl. Sci. 2024, 14, 3151. https://doi.org/10.3390/app14083151
Alkafaween E, Hassanat A, Essa E, Elmougy S. An Efficiency Boost for Genetic Algorithms: Initializing the GA with the Iterative Approximate Method for Optimizing the Traveling Salesman Problem—Experimental Insights. Applied Sciences. 2024; 14(8):3151. https://doi.org/10.3390/app14083151
Chicago/Turabian StyleAlkafaween, Esra’a, Ahmad Hassanat, Ehab Essa, and Samir Elmougy. 2024. "An Efficiency Boost for Genetic Algorithms: Initializing the GA with the Iterative Approximate Method for Optimizing the Traveling Salesman Problem—Experimental Insights" Applied Sciences 14, no. 8: 3151. https://doi.org/10.3390/app14083151