
Research on Grain Moisture Model Based on Improved SSA-SVR Algorithm

Abstract
:1. Introduction
2. Data Sources and Processing
2.1. Data Sources
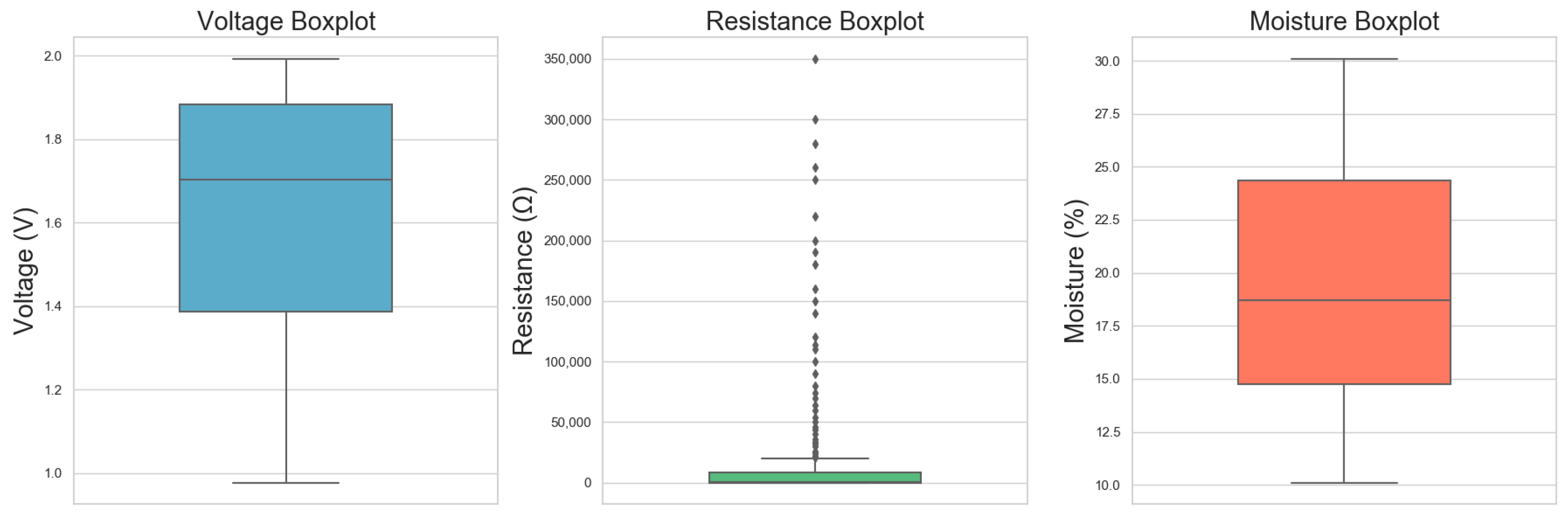
2.2. Data Preprocessing
3. System Modeling Method Construction
3.1. Support Vector Machine SVM Model Method
3.2. Sparrow Search Algorithm
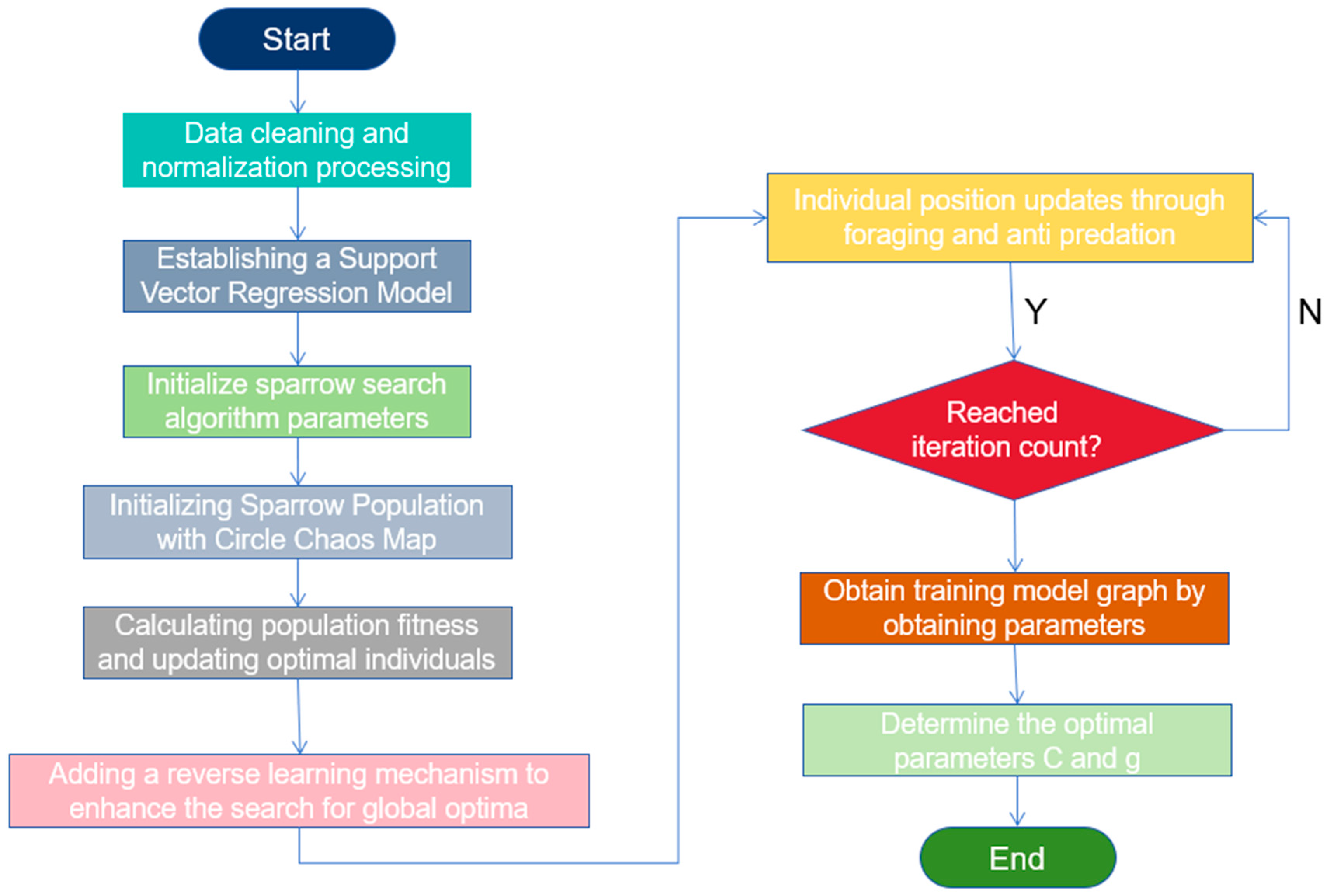
3.3. Improved Sparrow Search Algorithm
4. Results
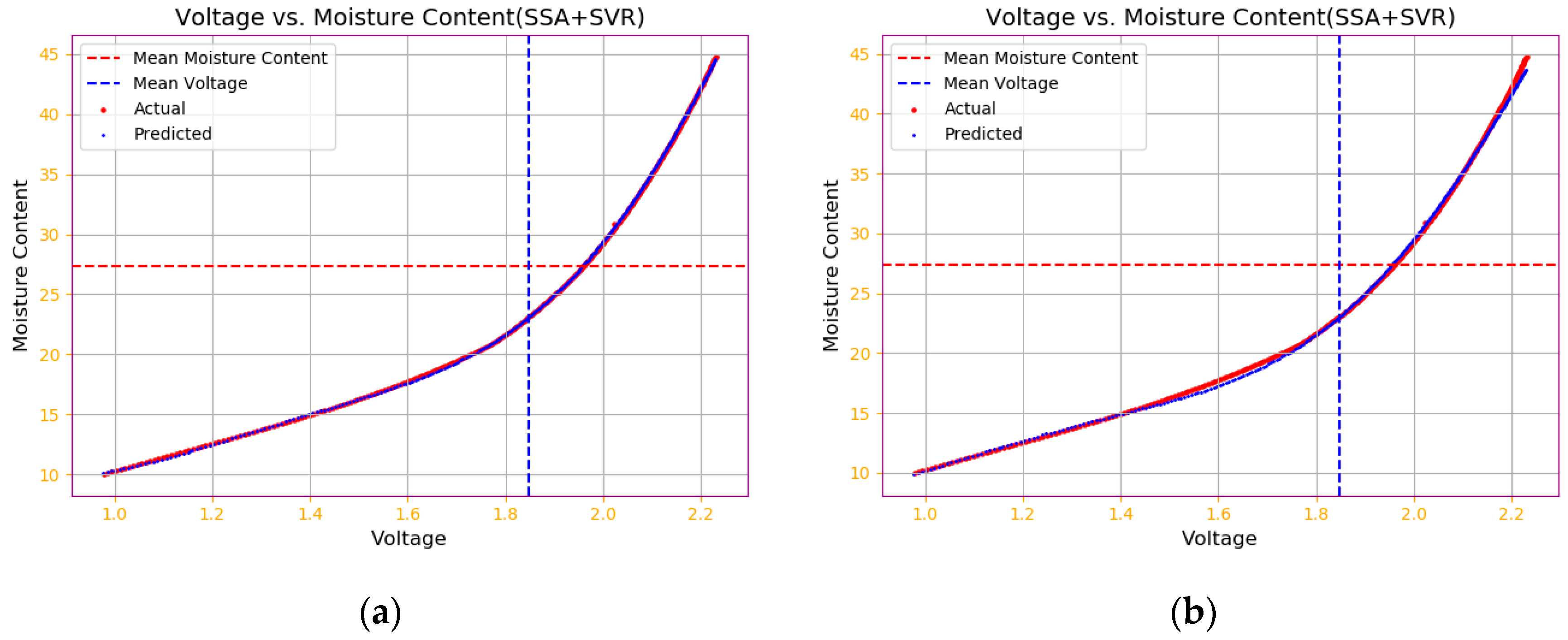
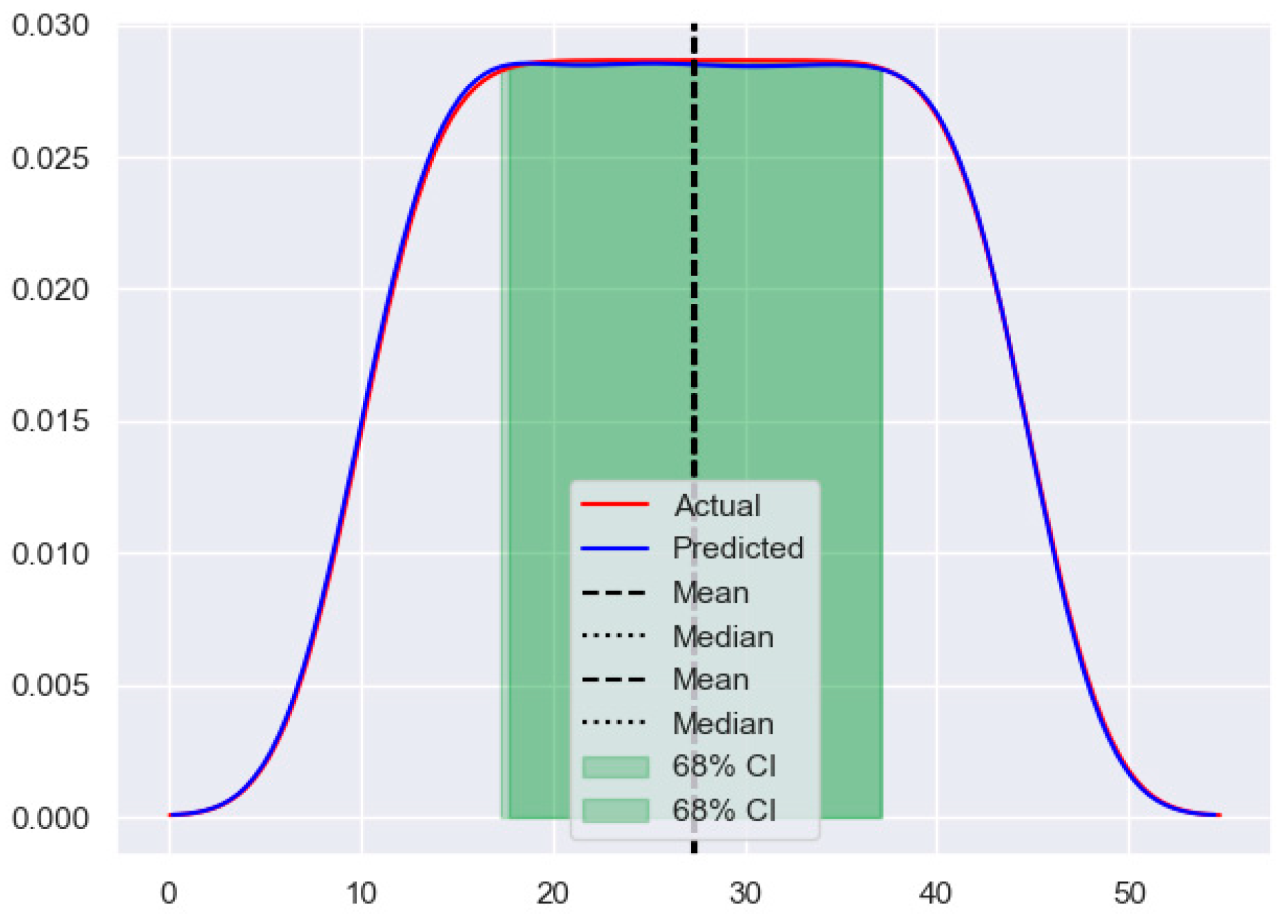
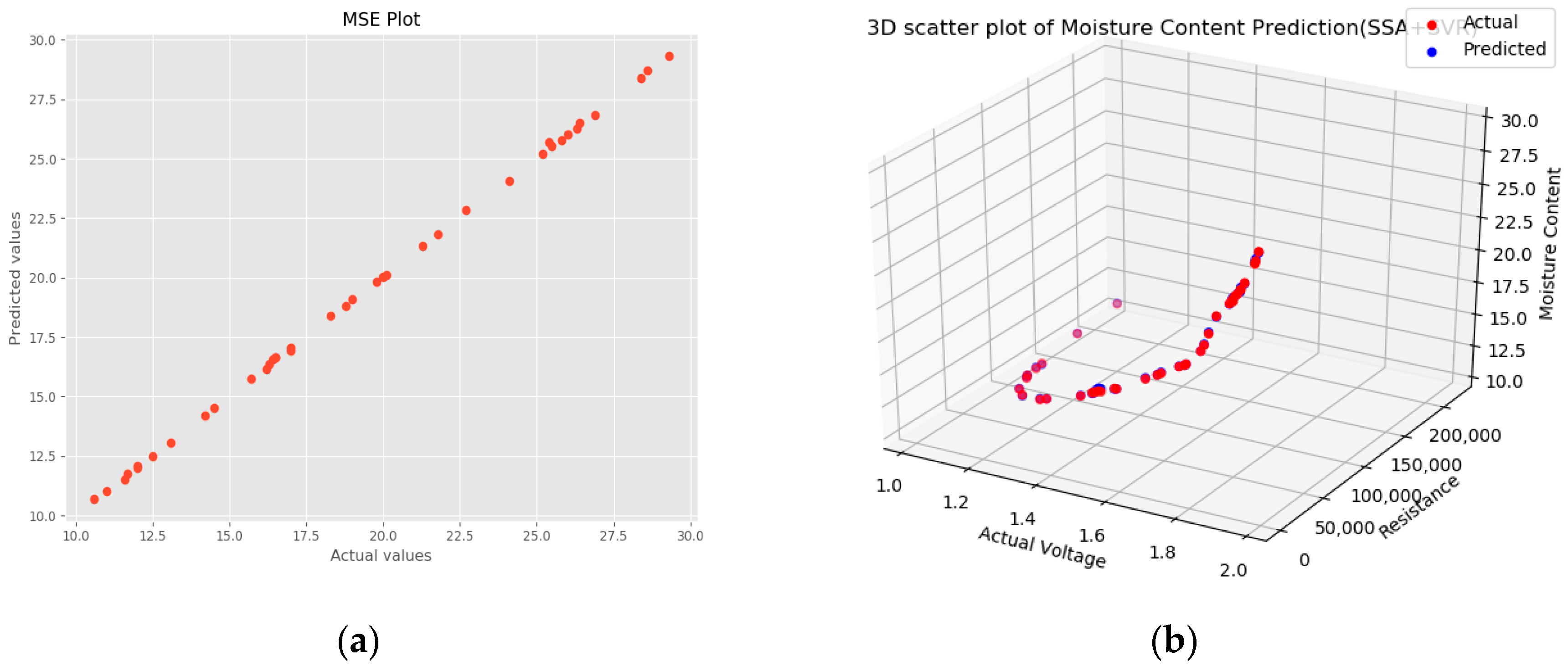
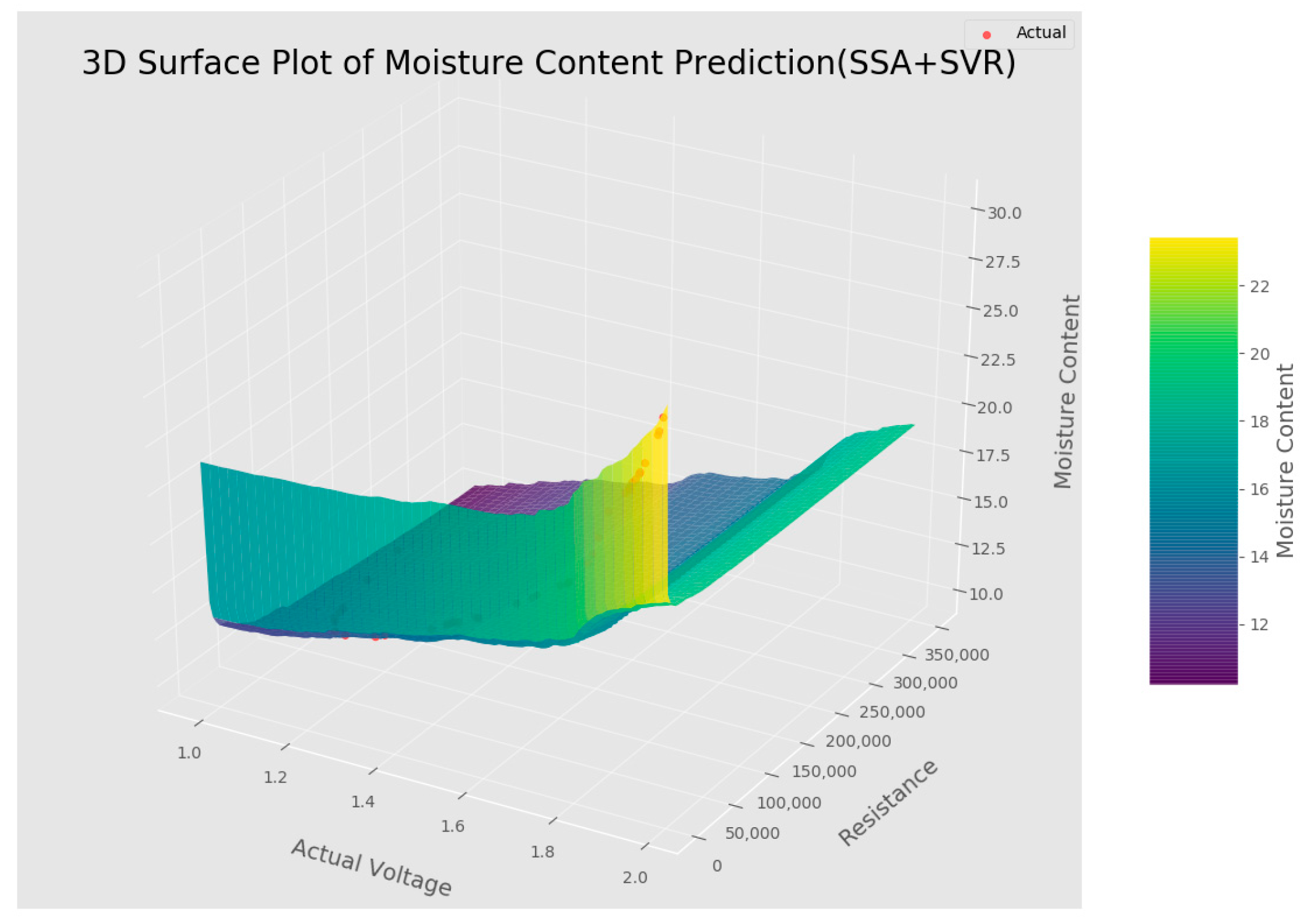
4.1. Improved SSA-SVR Training Model Results
4.2. Other Model Training Results
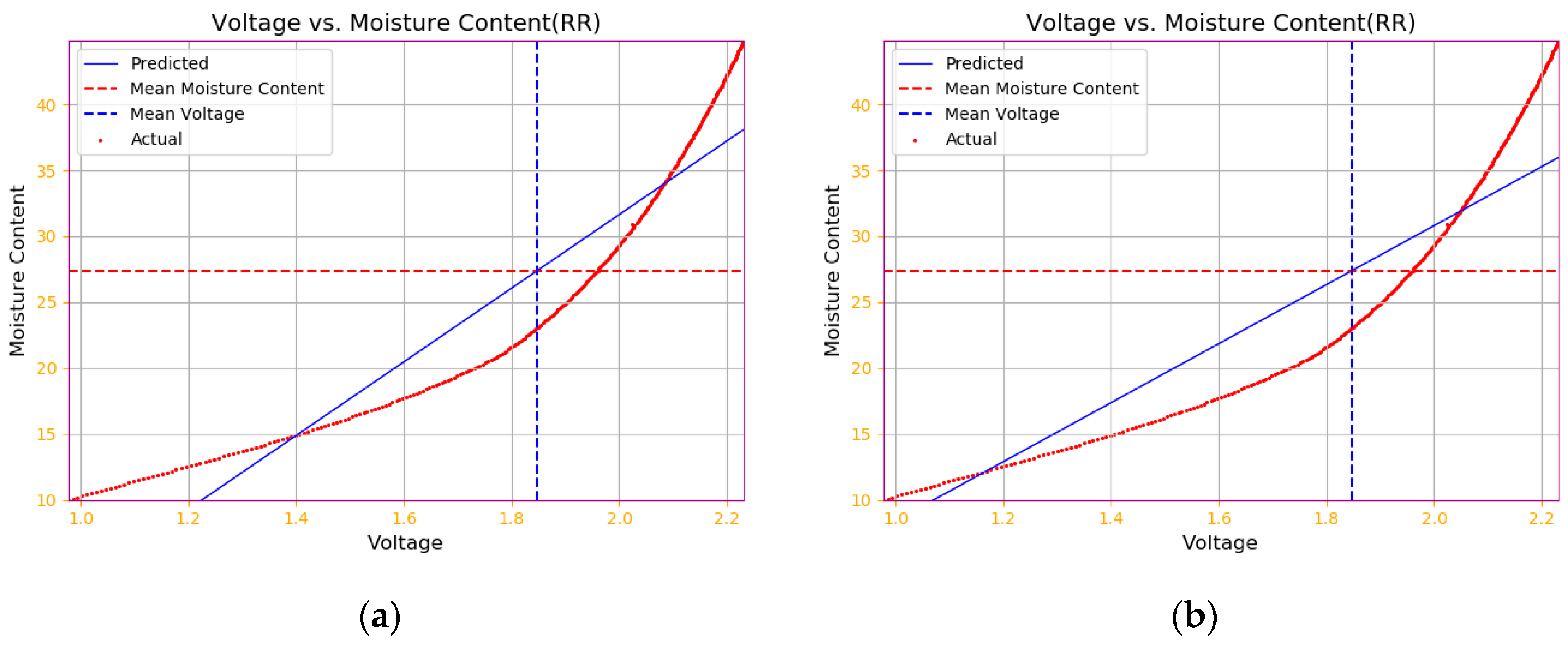
4.2.1. Ridge Regression Model Results
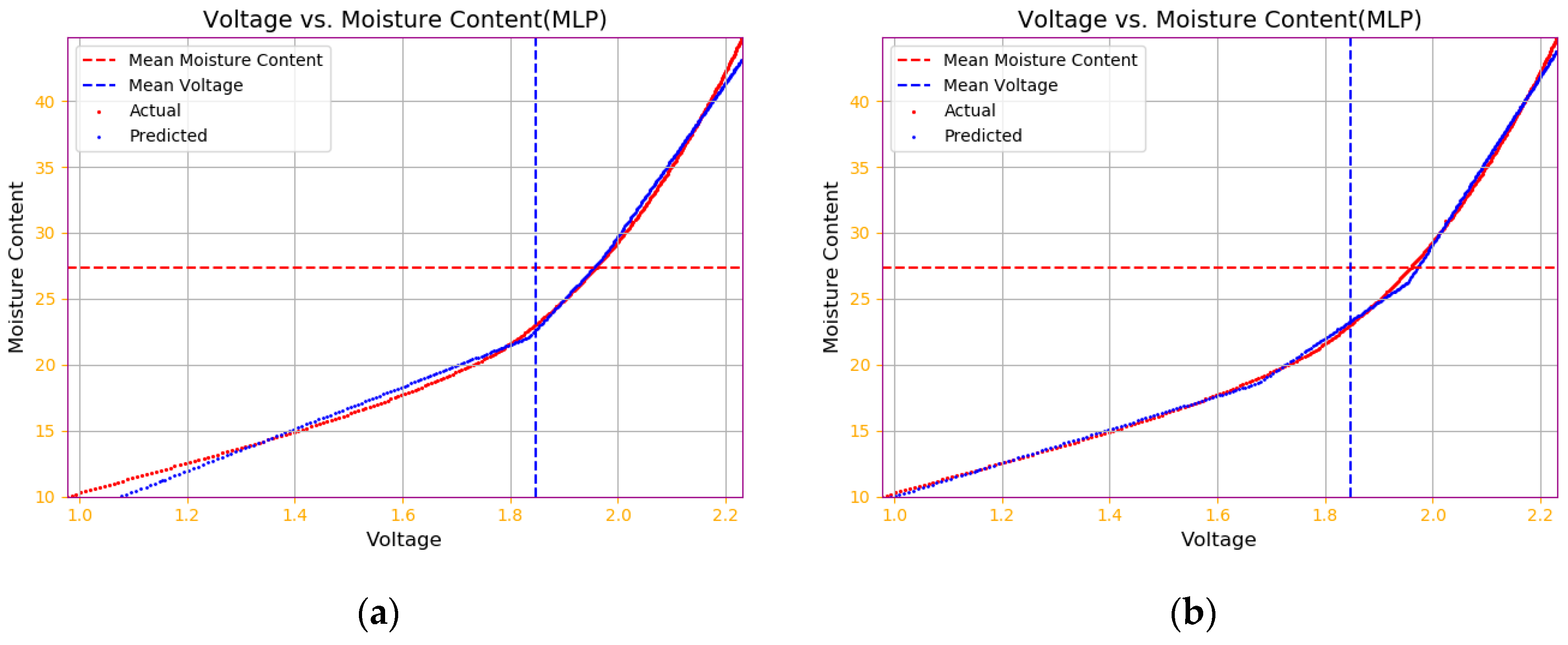
4.2.2. MLP Model Results
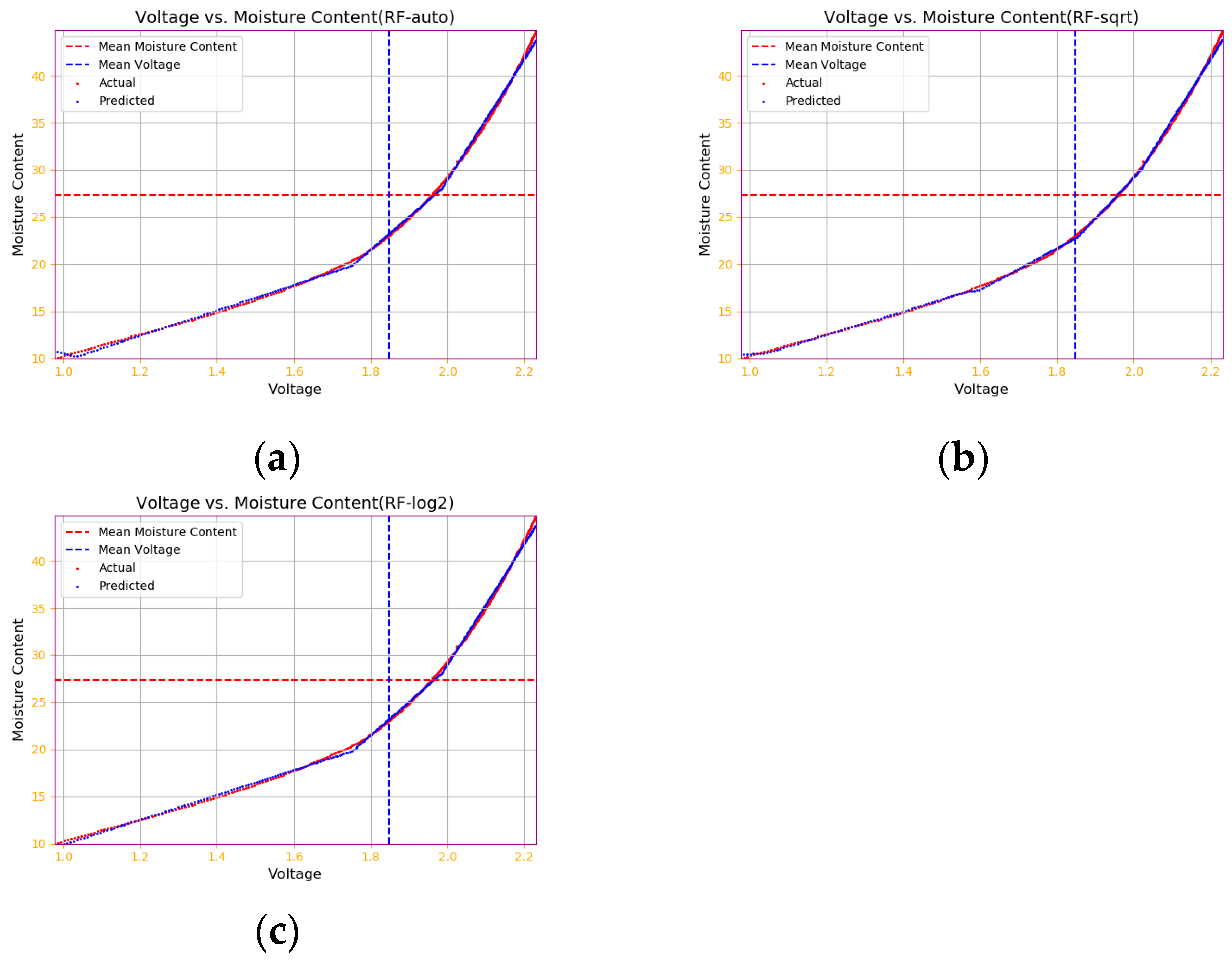
4.2.3. Random Forest Model Results
4.3. Comparison of Algorithm Model Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, G. Research on Online Detection and Control System for Grain Moisture Content; Shenyang University of Technology: Shenyang, China, 2003. [Google Scholar]
- Sun, J.; Zhou, Z.; Tang, H. Research on Rapid Detection Methods for Grain Moisture at Home and Abroad. Grain Storage 2017, 3, 46–49. [Google Scholar]
- Liu, Z. Research on Online Monitoring Instrument for Grain Moisture; Jilin Agricultural University: Changchun, China, 2013. [Google Scholar]
- Sun, Y. Research on Capacitive Grain Moisture Online Detection Instrument; Jilin Agricultural University: Changchun, China, 2014. [Google Scholar]
- Shi, Y. Design and Implementation of a Grain Moisture Measuring Instrument; Jilin University: Changchun, China, 2018. [Google Scholar]
- Ding, Y.; Zhang, X.; Wang, X. Overview of Grain Moisture Measurement Technology. Anal. Instrum. 2005, 2, 5–8. [Google Scholar]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Lyu, X.; Mu, X.; Zhang, J.; Wang, Z. Chaotic sparrow search optimization algorithm. J. Beijing Univ. Aeronaut. Astronaut. 2021, 47, 1712–1720. [Google Scholar]
- Mao, Q.; Zhang, Q. Improved sparrow algorithm combining cauchy mutation and opposition-based learning. J. Front. Comput. Sci. Technol. 2021, 15, 1155–1164. [Google Scholar]
- Tang, Y.; Li, C.; Song, Y.; Chen, C.; Cao, B. Adaptive mutation sparrow search optimization algorithm. J. Beijing Univ. Aeronaut. Astronaut. 2023, 49, 681–692. [Google Scholar]
- Zhang, W.; Liu, S.; Ren, C. Mixed strategy improved sparrow search algorithm. Comput. Eng. Appl. 2021, 57, 74–82. [Google Scholar]
- Boateng, E.Y.; Otoo, J.; Abaye, D.A. Basic tenets of classification algorithms K-nearest-neighbor, support vector machine, random forest and neural network: A review. J. Data Anal. Inf. Process. 2020, 8, 341–357. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE). Geosci. Model Dev. Discuss. 2014, 7, 1525–1534. [Google Scholar]
- Xiang, W. Standardization of Moisture Content in Food and Its Determination Methods. Chin. Foreign Med. 2009, 28, 174–175. [Google Scholar]
- Su, Y. Discussion on the calibration method of the drying method moisture analyzer. Shanghai Metrol. Test. 2009, 4, 9–11. [Google Scholar]
- Hu, J.; Li, Z.; Pan, X. Dispersive Field Capacitive Grain Moisture Sensor and Its Application in Grain Storage. Chin. J. Cereals Oils 2017, 32, 108–111. [Google Scholar]
- Nelson, S.O.; Russell, R.B. Models for Estimating the Dielectric Constants of Cereal Grains and Soybeans. J. Microw. Power Electromagn. Energy 1986, 21, 110–113. [Google Scholar]
- Kraszewski, A.; Nelson, S.O. Composite model of the complex permittivity of cereal grain. J. Agric. Eng. Res. 1989, 43, 211–219. [Google Scholar] [CrossRef]
- Yoav, B. Opening the Box of aBoxplot. Am. Stat. 1988, 42, 257–262. [Google Scholar]
- Pang, X. Algorithm Implementation of Multiple Interpolation Processing Method for Missing Data. Stat. Decis.-Mak. 2012, 24, 18–22. [Google Scholar]
- Lin, C.; Wang, S. Fuzzy Support Vector Machines. IEEE Trans. Neural Netw. 2002, 3, 464–471. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Tyagi, D.; Verma, A.; Sharma, S. An improved method for face recognition using local ternary pattern with GA and SVM classifier. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Noida, India, 14–17 December 2016; pp. 421–426. [Google Scholar]
- Li, D.A. Hybrid Sparrow Search Algorithm. Comput. Knowl. Technol. 2021, 17, 232–234. [Google Scholar]
- He, H.; Ma, X.; Wang, H.; Fan, S.; Han, L. Multi-threshold Segmentation of Forest Fire Image Based on Improved Sparrow Search Algorithm. Sci. Technol. Eng. 2021, 21, 11263–11270. [Google Scholar]
- Mao, Q.; Zhang, Q.; Mao, C.; Bai, J.X. Mixing Sine and Cosine Algorithm With Levy Flying Chaotic Sparrow Algorithm. J. Shanxi Univ. (Nat. Sci. Ed.) 2021, 44, 1086–1091. [Google Scholar]
- Zhang, Z.; He, R.; Yang, K. A Bioinspired Path Planning Approach for Mobile Robots Based On Improved Sparrow Search Algorithm. Adv. Manuf. 2022, 10, 114–130. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, T.; Zhou, H. A Multi Strategy Improved Sparrow Search Algorithm. Comput. Eng. Appl. 2022, 58, 133–140. [Google Scholar]
- Ye, Y.B.; Li, R.C.; Xie, M.; Wang, Z.; Ba, Q. A state evaluation method for a relay protection device based on SSA–SVM. Power Syst. Prot. Control. 2022, 50, 171–178. [Google Scholar]
- Najafzadeh, M.; Niazmardi, S. A Novel Multiple-Kernel Support Vector Regression Algorithm for Estimation of Water Quality Parameters. Nat. Resour. Res. 2021, 30, 3761–3775. [Google Scholar] [CrossRef]
- Lan, Z.; He, Q. Multi-trategy Fusion Algorithm and Its Engineering Optimization. Appl. Res. Comput. 2022, 39, 758–763. [Google Scholar]
- Xu, X.; Peng, L.; Ji, Z. Research on Substation Project Cost Prediction Based on Sparrow Search Algorithm Optimized BP Neural Network. Sustainability 2021, 13, 13746. [Google Scholar] [CrossRef]
- Ren, J.; Cui, J.; Dong, W.; Xiao, Y.; Xu, M.; Liu, S.; Wan, J.; Li, Z.; Zhang, J. Remote Sensing Inversion of Typical Offshore Water Quality Parameter Concentration Based on Improved SVR Algorithm. Remote Sens. 2023, 15, 2104. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Chen, L.; Wang, Q.; Zhao, M. Water Quality Prediction for Hanjiang with Optimized Support Vector Regression. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 832–837. [Google Scholar]
- Sulandari, W.; Subanar, S.; Suhartono, S.; Utami, H.; Lee, M.H.; Rodrigues, P.C. SSA-Based Hybrid Forecasting Models and Applications. Bull. Electr. Eng. Inform. 2020, 9, 2178–2188. [Google Scholar] [CrossRef]
- Tabatabaei, S.M.; Attari, N.; Panahi, S.A.; Asadian-Pakfar, M.; Sedaee, B. EOR Screening Using Optimized Artificial Neural Network by Sparrow Search Algorithm. Geoenergy Sci. Eng. 2023, 229, 212023. [Google Scholar] [CrossRef]
- Xu, X.; Wang, J.; Wu, J.; Qu, Q.; Ran, Y.; Tan, Z.; Luo, M. Full-Waveform LiDAR Echo Decomposition Method Based on Deep Learning and Sparrow Search Algorithm. Infrared Phys. Technol. 2023, 130, 104613. [Google Scholar] [CrossRef]
- Basak, D.; Pal, S.; Patranabis, D.C. Support Vector Regression. Process. Lett. Rev 2007, 11, 203. [Google Scholar]
- Zhang, F.; O’Donnell, L.J. Support Vector Regression. In Machine Learning; Academic Press: New York, NY, USA, 2020; pp. 123–140. [Google Scholar]
- Duan, S.; Liu, S. Research on Temperature Compensation of Fiber Optic Pressure Sensor Based on SSA-SVR. Electron. Devices 2023, 46, 1268–1274. [Google Scholar]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Boonstra, P.S.; Mukherjee, B.; Taylor, J.M. A small-sample choice of the tuning parameter in ridge regression. Stat. Sin. 2015, 23, 1185. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, S. A New Fast Convergent Backpropagation Algorithm. J. Tongji Univ. (Nat. Sci. Ed.). 2004, 32, 1092–1095. [Google Scholar]
- Zhang, G.; Yin, J.; Zhu, E. A New method of calculating the upper limit on multilayer perceptron’s hidden neuron number. Comput. Eng. Sci. 2007, 29, 137–139. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wang, F.; Wang, Y.; Zhang, K.; Hu, M.; Weng, Q.; Zhang, H. Spatial heterogeneity modeling of water quality based on random forest regression and model interpretation. Environ. Res. 2021, 202, 111660. [Google Scholar] [CrossRef]
- Xing, S.; Gao, G.; Zhang, Z. Short-term load forecasting model based on double-layer random forest algorithm. Guangdong Electr. Power 2019, 32, 160–166. [Google Scholar]
- Ülker, E.D.; Ülker, S. Modelling the currency exchange ratesusing support vector regression. In Intelligent Computing: Proceedings of the 2020 Computing Conference; Springer: London, UK, 2020; pp. 326–333. [Google Scholar]
- Zhang, R.; Wang, Y. Research on Machine Learning and Its Algorithms and Development. Commun. Univ. China Newsp. (Nat. Sci. Ed.) 2016, 23, 10–18+24. [Google Scholar]
- Meena, L.; Chaurasiya, V.K.; Purohit, N.; Singh, D. Comparison of SVM and random forest methods for online signature verification. In Proceedings of the 12th International Conference on Intelligent Human Computer Interaction, Daegu, Republic of Korea, 24–26 November 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 288–299. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partial Data Related to Long-Grain Rice at 30 °C | |||
|---|---|---|---|
| Resistance Value (K) | True Voltage Value (V) | Actual Voltage Value (V) | Measured Moisture Value (%) |
| 26,000 | 1.2476 | 1.2481 | 13.3 |
| 8000 | 1.3819 | 1.3812 | 14.6 |
| 1200 | 1.6145 | 1.6153 | 18.1 |
| 460 | 1.7302 | 1.7291 | 19.6 |
| 110 | 1.8699 | 1.8705 | 24.1 |
| 61 | 1.9220 | 1.9221 | 25.6 |
| 16 | 2.0187 | 2.0194 | 30.1 |
| Correlation Coefficient | Coefficient of Determination | RMSE | Training Time | |
|---|---|---|---|---|
| SSA-SVR | 0.94 | 0.93 | 1.42 | 0.32 |
| (Improvement) SSA-SVR | 0.99 | 0.98 | 0.85 | 0.49 |
| RR | 0.92 | 0.86 | 3.84 | 0.57 |
| MLP | 0.94 | 0.93 | 2.99 | 3.84 |
| RF | 0.95 | 0.96 | 1.83 | 0.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, W.; Li, G.; Song, H.; Quan, B.; Liu, Z. Research on Grain Moisture Model Based on Improved SSA-SVR Algorithm. Appl. Sci. 2024, 14, 3171. https://doi.org/10.3390/app14083171
Cao W, Li G, Song H, Quan B, Liu Z. Research on Grain Moisture Model Based on Improved SSA-SVR Algorithm. Applied Sciences. 2024; 14(8):3171. https://doi.org/10.3390/app14083171
Chicago/Turabian StyleCao, Wenxiao, Guoming Li, Hongfei Song, Boyu Quan, and Zilu Liu. 2024. "Research on Grain Moisture Model Based on Improved SSA-SVR Algorithm" Applied Sciences 14, no. 8: 3171. https://doi.org/10.3390/app14083171