
EmoStyle: Emotion-Aware Semantic Image Manipulation with Audio Guidance




Abstract
1. Introduction
- We introduce a sentiment-auxiliary semantic-guided image manipulation framework, termed the Emotion-aware StyleGAN Manipulator (EmoStyle), which efficiently leverages the affective information from music to manipulate images.
- We devise a simple yet effective retrieval approach that selects images with minimal semantic gaps based on the similarity between music and images, which ensures the stability of subsequent image manipulation.
- We introduce an innovative sentiment-assisted guidance module that explicitly extracts sentiment polarity from the music, generates an affective music branch, and aids in image manipulation with a focus on the sentimental dimension.
- We evaluate the proposed EmoStyle with objective methods, confirming the effectiveness of our approach.
2. Related Work
2.1. Cross-Modal Generation
2.2. Text-Driven Image Manipulation
2.3. Audio-Visual Learning
2.4. Audio-Driven Image Manipulation
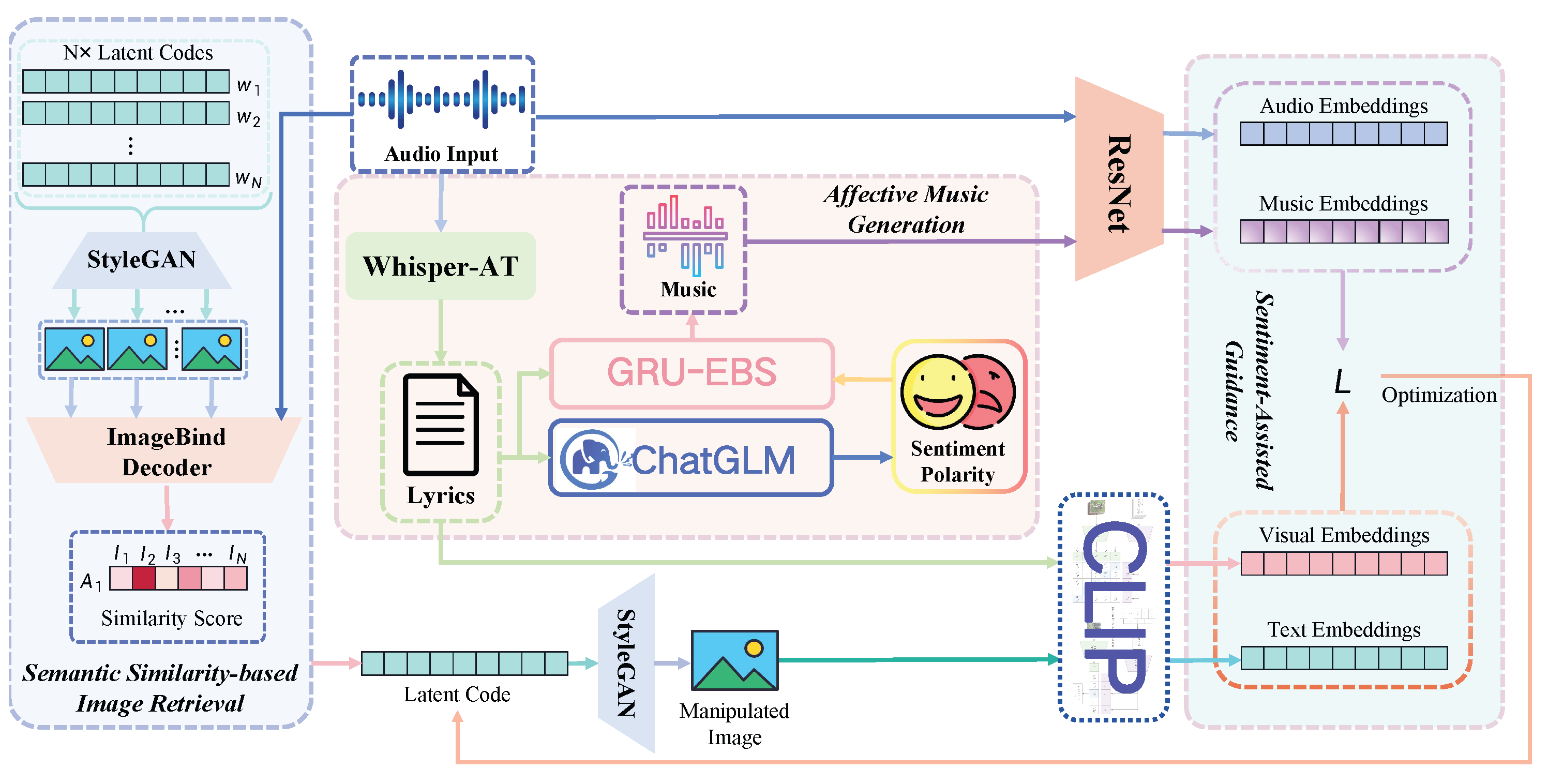
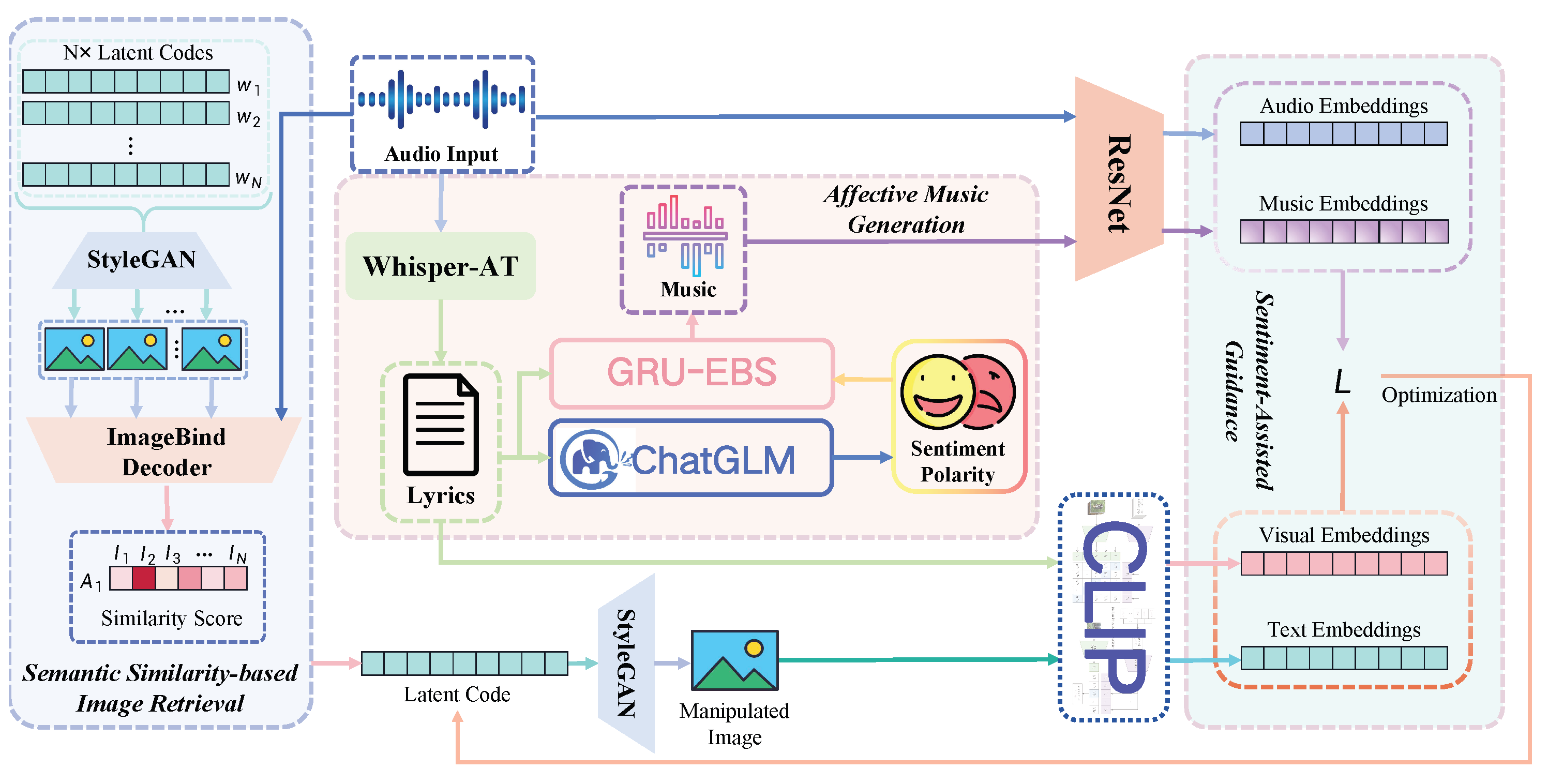
3. Methodology
3.1. Semantic Similarity-Based Image Retrieval
3.2. Affective Music Generation
3.3. Sentiment-Assisted Guidance Module
3.3.1. Multi-Dimension Guidance Loss
3.3.2. Identity Loss
3.3.3. Adaptive Layer Masking
4. Experiments
4.1. Datasets
4.2. Implementation Details
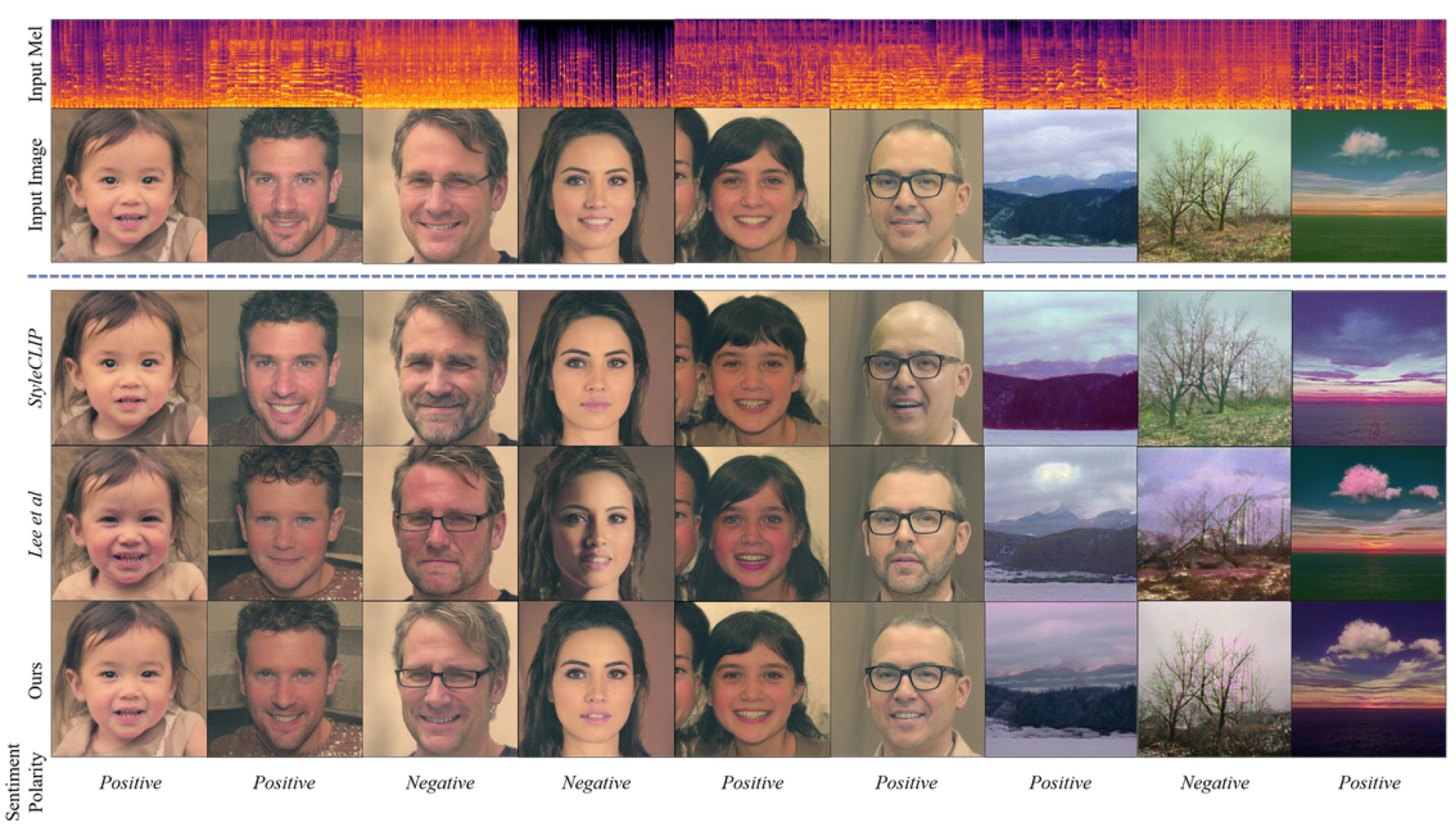
4.3. Qualitative Analysis
4.3.1. Comparison in Lyric-Based Audio Settings
4.3.2. Comparison in Semantically Rich Audio Settings
4.3.3. Ablation Study
4.4. Evaluation of Visual Attractiveness
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Johnson, J.; Gupta, A.; Li, F.-F. Image generation from scene graphs. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1219–1228. [Google Scholar]
- Chen, L.; Srivastava, S.; Duan, Z.; Xu, C. Deep cross-modal audio-visual generation. In Proceedings of the ACM International Conference on Multimedia (ACM MM), Silicon Valley, CA, USA, 23–27 October 2017; pp. 349–357. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2085–2094. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lee, S.H.; Roh, W.; Byeon, W.; Yoon, S.H.; Kim, C.; Kim, J.; Kim, S. Sound-guided semantic image manipulation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3377–3386. [Google Scholar]
- Girdhar, R.; El-Nouby, A.; Liu, Z.; Singh, M.; Alwala, K.V.; Joulin, A.; Misra, I. Imagebind: One embedding space to bind them all. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 15180–15190. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. Cogview: Mastering text-to-image generation via transformers. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021; Volume 34, pp. 19822–19835. [Google Scholar]
- Singer, U.; Polyak, A.; Hayes, T.; Yin, X.; An, J.; Zhang, S.; Hu, Q.; Yang, H.; Ashual, O.; Gafni, O.; et al. Make-a-video: Text-to-video generation without text-video data. arXiv 2022, arXiv:2209.14792. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 23716–23736. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Sun, J.; Li, Q.; Wang, W.; Zhao, J.; Sun, Z. Multi-caption text-to-face synthesis: Dataset and algorithm. In Proceedings of the ACM International Conference on Multimedia (ACM MM), Chengdu, China, 20–24 October 2021; pp. 2290–2298. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1316–1324. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Wu, F.; Tian, Y.; Wang, L.; Tao, D. RiFeGAN: Rich Feature Generation for Text-to-Image Synthesis From Prior Knowledge. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic image synthesis via adversarial learning. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5706–5714. [Google Scholar]
- Kim, G.; Kwon, T.; Ye, J.C. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2426–2435. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H. Manigan: Text-guided image manipulation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7880–7889. [Google Scholar]
- Liu, Y.; De Nadai, M.; Cai, D.; Li, H.; Alameda-Pineda, X.; Sebe, N.; Lepri, B. Describe what to change: A text-guided unsupervised image-to-image translation approach. In Proceedings of the ACM International Conference on Multimedia (ACM MM), Seattle, WA, USA, 16 October 2020; pp. 1357–1365. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-adaptive generative adversarial networks: Manipulating images with natural language. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H.; Wu, B. Tedigan: Text-guided diverse face image generation and manipulation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2256–2265. [Google Scholar]
- Xu, Z.; Lin, T.; Tang, H.; Li, F.; He, D.; Sebe, N.; Timofte, R.; Van Gool, L.; Ding, E. Predict, prevent, and evaluate: Disentangled text-driven image manipulation empowered by pre-trained vision-language model. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18229–18238. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. Soundnet: Learning sound representations from unlabeled video. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. Cooperative learning of audio and video models from self-supervised synchronization. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Owens, A.; Wu, J.; McDermott, J.H.; Freeman, W.T.; Torralba, A. Ambient sound provides supervision for visual learning. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 801–816. [Google Scholar]
- Gan, C.; Huang, D.; Zhao, H.; Tenenbaum, J.B.; Torralba, A. Music gesture for visual sound separation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10478–10487. [Google Scholar]
- Su, K.; Liu, X.; Shlizerman, E. Audeo: Audio generation for a silent performance video. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 3325–3337. [Google Scholar]
- Morgado, P.; Li, Y.; Nvasconcelos, N. Learning representations from audio-visual spatial alignment. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 4733–4744. [Google Scholar]
- Mo, S.; Morgado, P. A Unified Audio-Visual Learning Framework for Localization, Separation, and Recognition. arXiv 2023, arXiv:2305.19458. [Google Scholar]
- Gao, R.; Feris, R.; Grauman, K. Learning to separate object sounds by watching unlabeled video. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–53. [Google Scholar]
- Tian, Y.; Hu, D.; Xu, C. Cyclic co-learning of sounding object visual grounding and sound separation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2745–2754. [Google Scholar]
- Gao, R.; Grauman, K. Visualvoice: Audio-visual speech separation with cross-modal consistency. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscateville, NJ, USA, 2021; pp. 15490–15500. [Google Scholar]
- Tian, Y.; Shi, J.; Li, B.; Duan, Z.; Xu, C. Audio-visual event localization in unconstrained videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 247–263. [Google Scholar]
- Tian, Y.; Li, D.; Xu, C. Unified multisensory perception: Weakly-supervised audio-visual video parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 436–454. [Google Scholar]
- Lin, Y.B.; Tseng, H.Y.; Lee, H.Y.; Lin, Y.Y.; Yang, M.H. Exploring cross-video and cross-modality signals for weakly-supervised audio-visual video parsing. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021; Volume 34, pp. 11449–11461. [Google Scholar]
- Mo, S.; Tian, Y. Multi-modal grouping network for weakly-supervised audio-visual video parsing. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 34722–34733. [Google Scholar]
- Morgado, P.; Nvasconcelos, N.; Langlois, T.; Wang, O. Self-supervised generation of spatial audio for 360 video. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Gao, R.; Grauman, K. 2. 5D visual sound. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 324–333. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Gong, Y.; Khurana, S.; Karlinsky, L.; Glass, J. Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers. arXiv 2023, arXiv:2307.03183. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. GLM-130B: An Open Bilingual Pre-trained Model. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Lee, S.H.; Oh, G.; Byeon, W.; Yoon, S.H.; Kim, J.; Kim, S. Robust sound-guided image manipulation. arXiv 2022, arXiv:2208.14114. [Google Scholar] [CrossRef]
- Skorokhodov, I.; Sotnikov, G.; Elhoseiny, M. Aligning latent and image spaces to connect the unconnectable. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14144–14153. [Google Scholar]
- Ke, J.; Ye, K.; Yu, J.; Wu, Y.; Milanfar, P.; Yang, F. VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 10041–10051. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Q.; Xu, J.; Mei, J.; Wu, X.; Dong, D. EmoStyle: Emotion-Aware Semantic Image Manipulation with Audio Guidance. Appl. Sci. 2024, 14, 3193. https://doi.org/10.3390/app14083193
Shen Q, Xu J, Mei J, Wu X, Dong D. EmoStyle: Emotion-Aware Semantic Image Manipulation with Audio Guidance. Applied Sciences. 2024; 14(8):3193. https://doi.org/10.3390/app14083193
Chicago/Turabian StyleShen, Qiwei, Junjie Xu, Jiahao Mei, Xingjiao Wu, and Daoguo Dong. 2024. "EmoStyle: Emotion-Aware Semantic Image Manipulation with Audio Guidance" Applied Sciences 14, no. 8: 3193. https://doi.org/10.3390/app14083193
APA StyleShen, Q., Xu, J., Mei, J., Wu, X., & Dong, D. (2024). EmoStyle: Emotion-Aware Semantic Image Manipulation with Audio Guidance. Applied Sciences, 14(8), 3193. https://doi.org/10.3390/app14083193