
PadGAN: An End-to-End dMRI Data Augmentation Method for Macaque Brain



Abstract
:1. Introduction
- We introduce the concept of peak information maps and design a corresponding method for calculating peak information maps.
- We propose a novel end-to-end primary-auxiliary dual GAN network to translate high b-value images to low b-value images. In this network, the auxiliary generator extracts latent space features from peak information maps and transfers these features to the primary generator. The primary network integrates the latent space features and multi-scale features to generate low b-value images.
- Through DTI estimation and Xtract probabilistic tractography experiments, we validate the effectiveness of generating low b-value images for augmenting original dMRI data, providing new validation approaches for quality assessment in brain science research and offering optimized dMRI data for brain science studies.
2. Materials and Methods
2.1. Datasets
2.2. Preprocessing
- Head motion correction and eddy current correction were performed using the FSL tool.
- Non-brain tissues were removed from human brain images using the FSL tool, while non-brain tissues were removed from macaque brain images using a deep learning method developed by our research group [37].
- Paired high b-value and low b-value images were extracted from the dMRI images, where the high b-value images served as inputs to the model, and the low b-value images served as reference images. The task of extracting b-value images was accomplished using the FSL tool.
- All high b-value images were scaled to the range of 0 to 1 using the min–max normalization method, and their dimensions were resampled to 256 × 256 × 256.
- The data were divided into pre-training, training, and testing sets: the pre-training set included 96 pairs of human brain images and 467 pairs of UWM images. The remaining data from UWM, AMU, MountSinai-P, MountSinai-S, and UCDavis sites were divided into training and testing sets, with a ratio of 8:2.
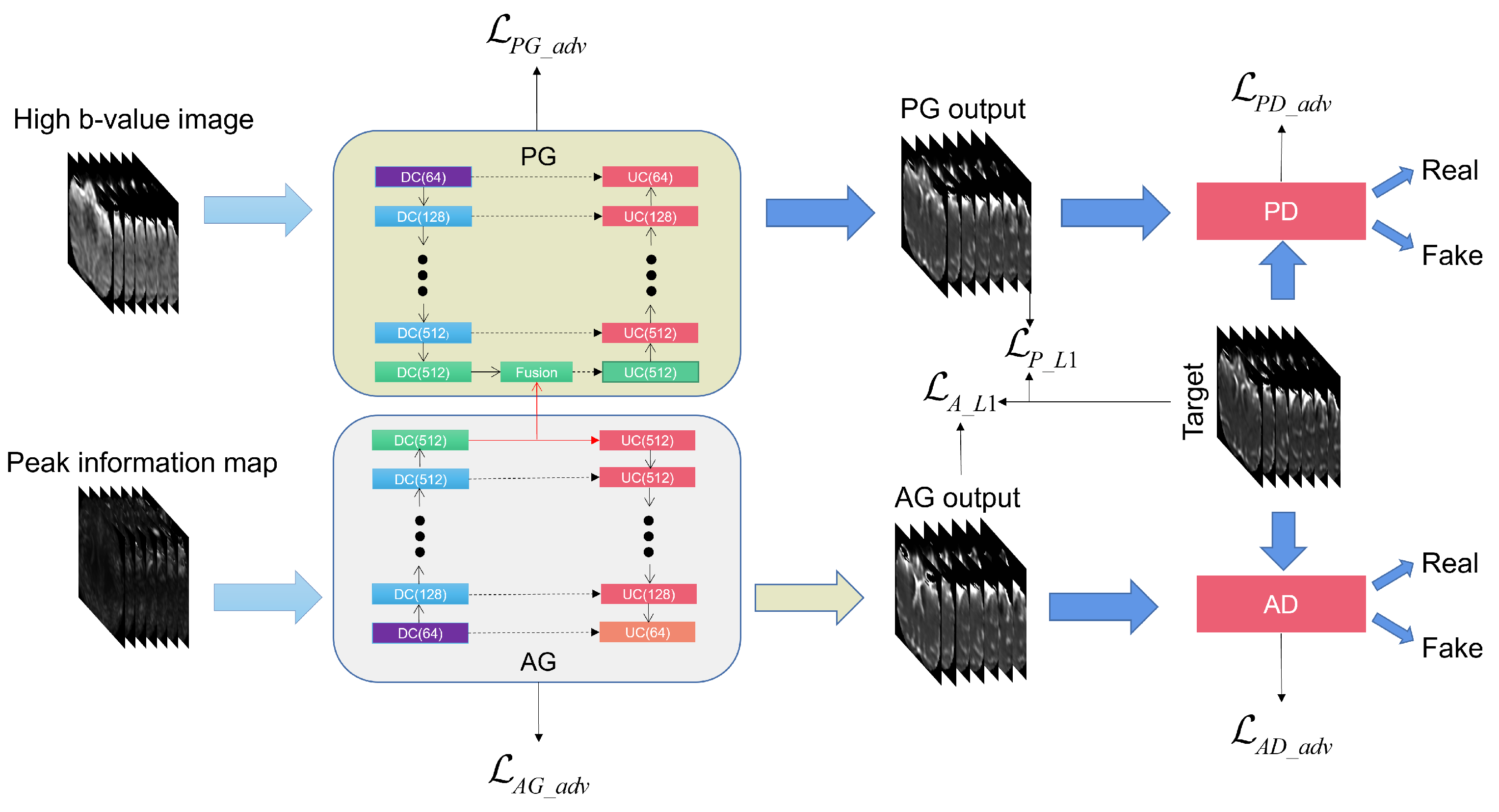
2.3. PadGAN
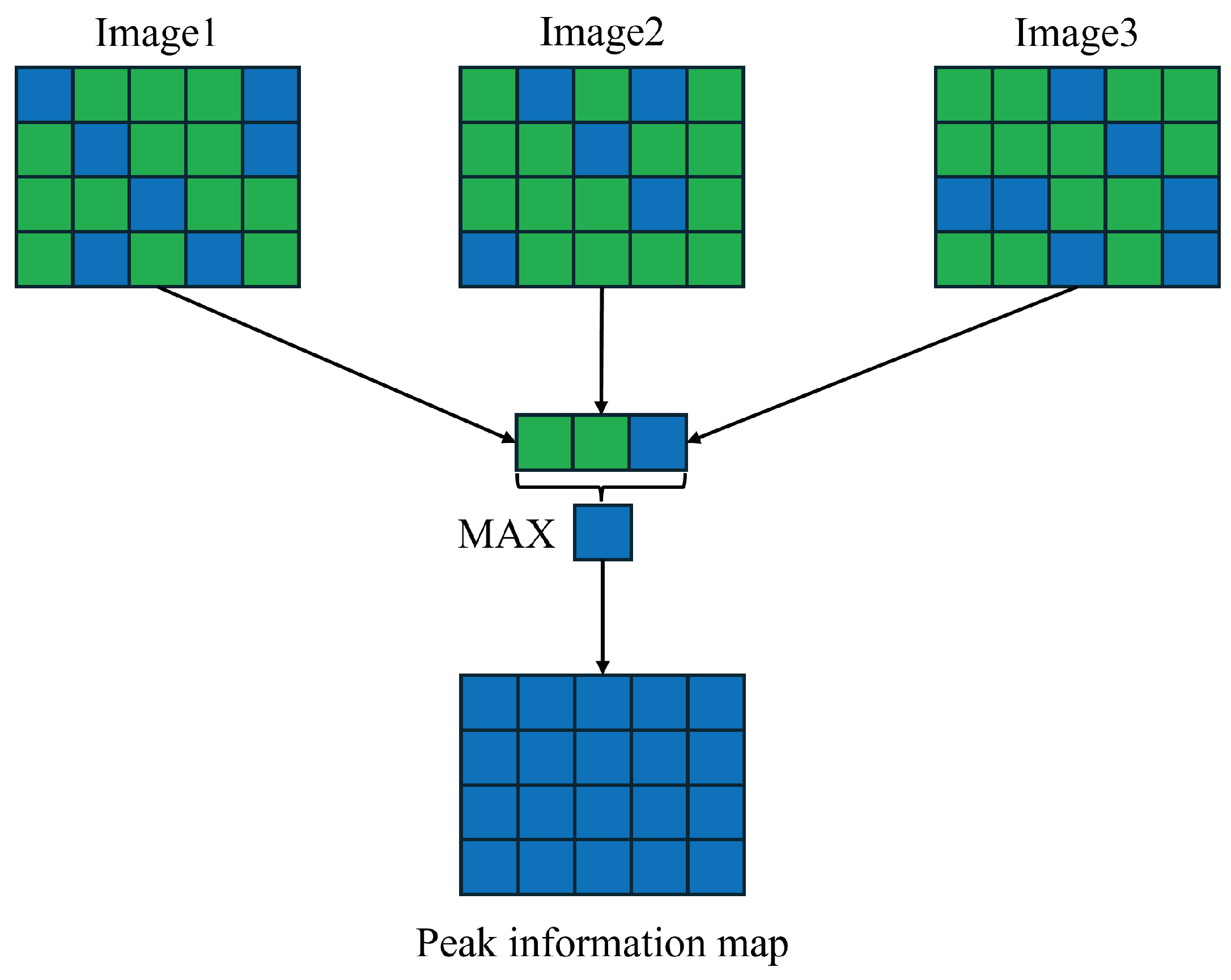
2.3.1. Peak Information Maps
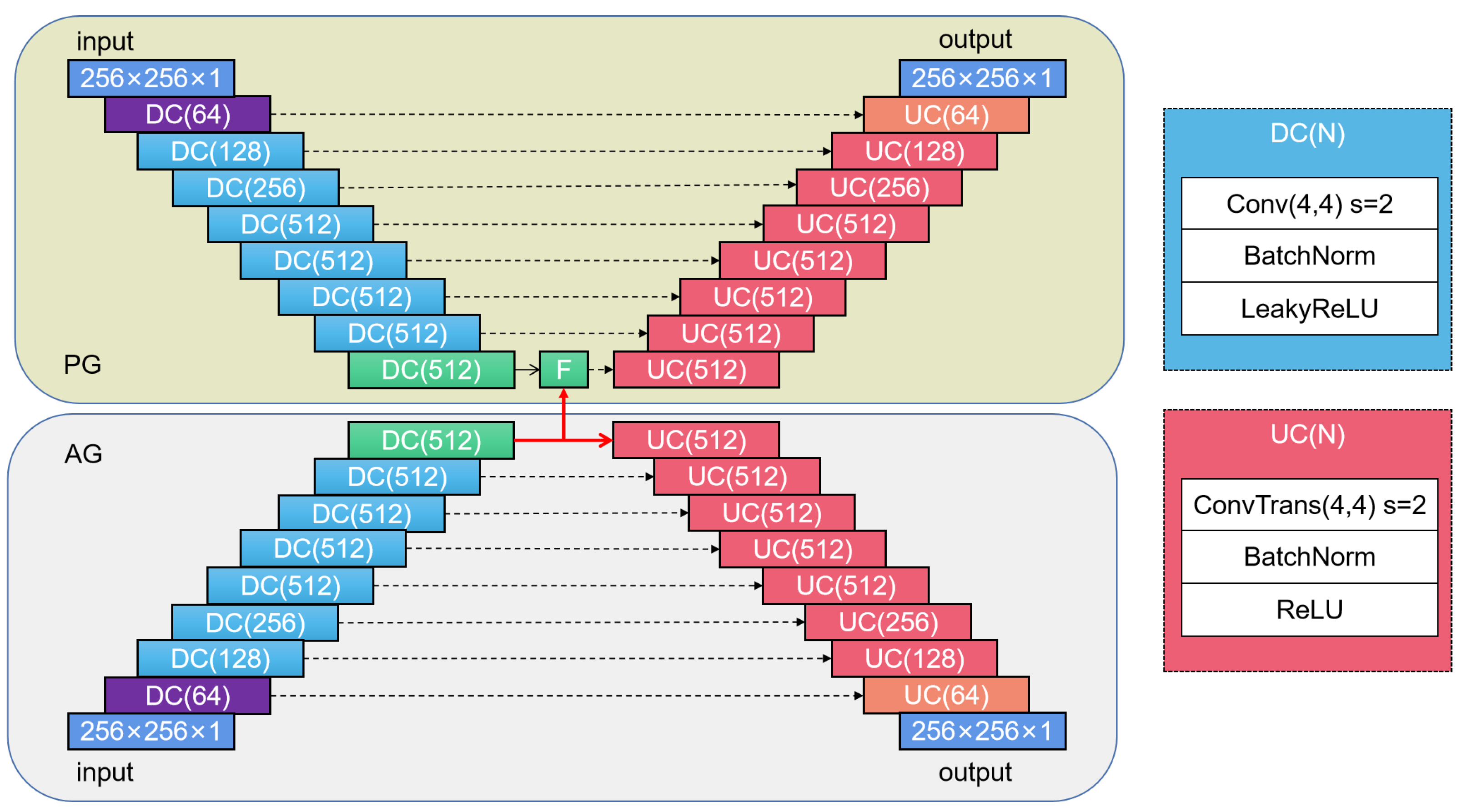
2.3.2. Auxiliary GAN
2.3.3. Primary GAN
2.3.4. Loss
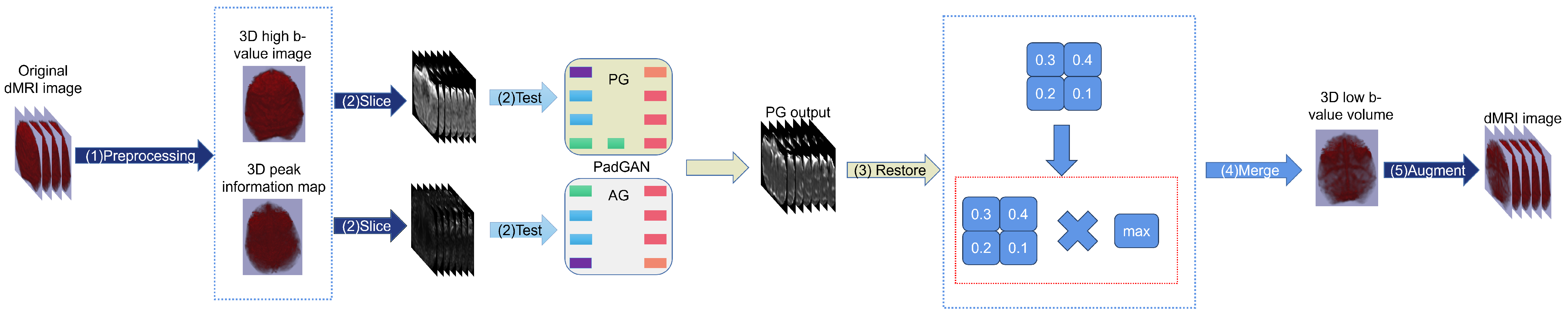
2.4. Process of dMRI Images Augmentation
- Preprocess the dMRI images.
- Segment the data into 2-dimensional images along the second dimension and input them into PadGAN for processing to generate low b-value images.
- Multiply the generated images’ signal intensity values by the maximum value of the images before normalization to restore the original signal intensity range.
- Merge the generated two-dimensional images into three-dimensional images and resample all data to the original size.
- The synthesized three-dimensional images are incorporated into the 4-D dMRI images using FSL tools, effectively improving the quality of the dMRI data. The entire process is illustrated in Figure 4.
3. Results
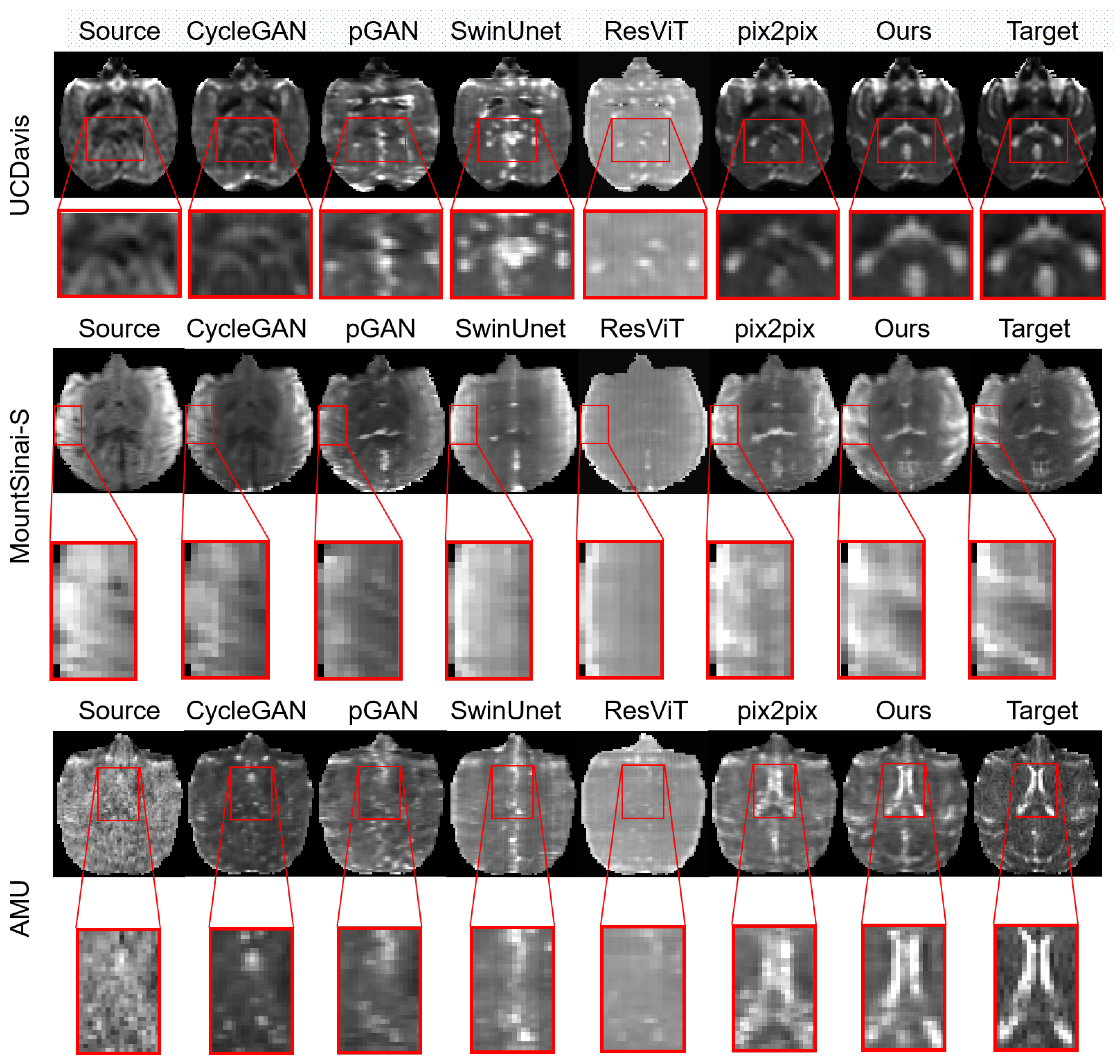
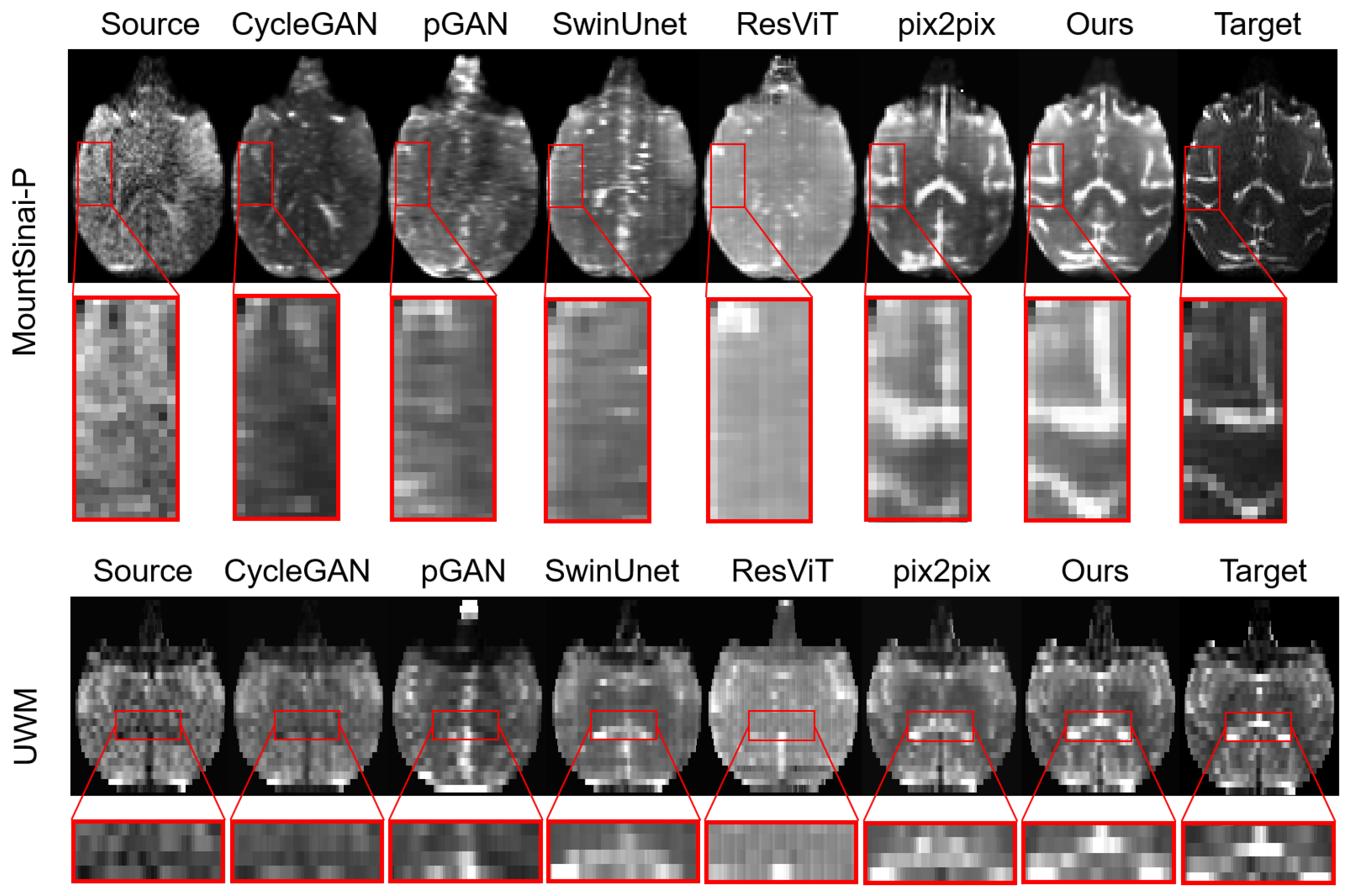
3.1. Comparison Experiments and Results
- Pix2pix [13] network adopts the U-Net architecture as the main framework of the generator.
- CycleGAN [14] network shares the same generator architecture as pix2pix, but it involves two generators and two discriminators for cyclic generation tasks.
- SwinUnet [24] utilizes the Swin Transformer as the main framework for medical image segmentation tasks, adapted for application in this paper.
- ResViT [26] builds upon the Vision Transformer architecture as the main generator framework.
- pGAN [30] adopts ResNet as the main framework.
3.2. Ablation Experiments and Results
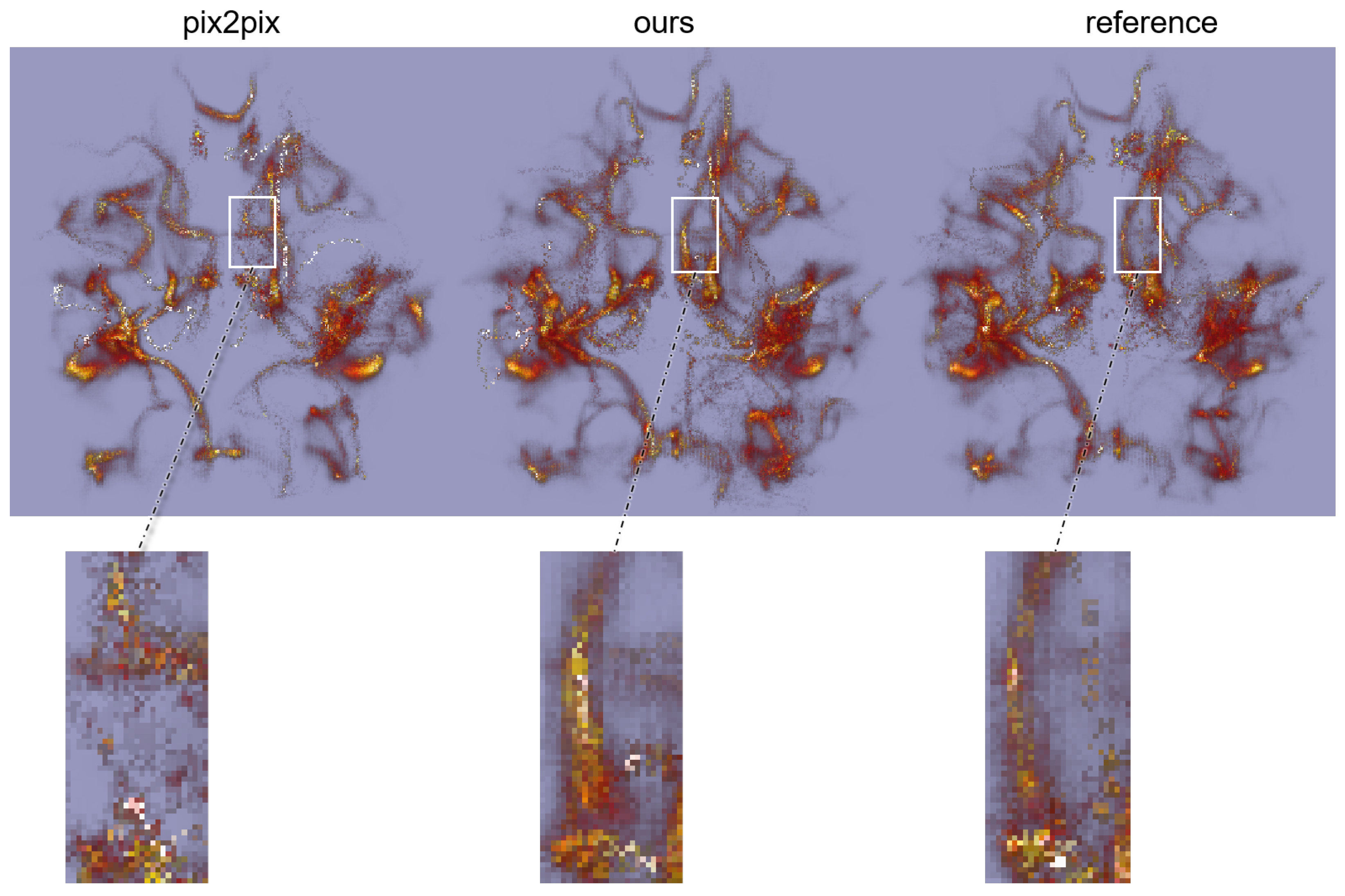
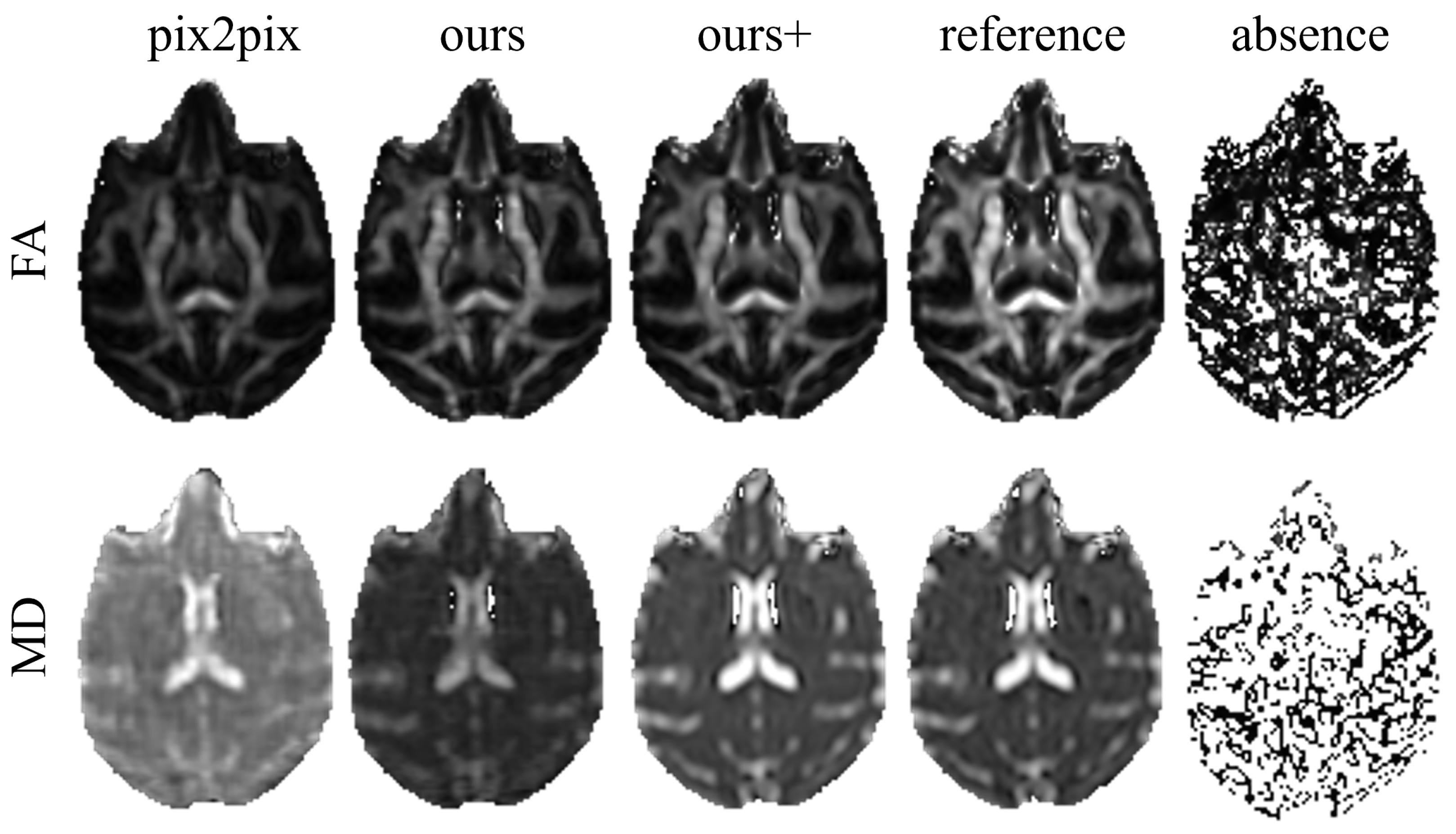
3.3. Xtract and DTI Estimation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Passingham, R. How good is the macaque monkey model of the human brain? Curr. Opin. Neurobiol. 2009, 19, 6–11. [Google Scholar] [CrossRef]
- Neubert, F.X.; Mars, R.B.; Sallet, J.; Rushworth, M.F. Connectivity reveals relationship of brain areas for reward-guided learning and decision making in human and monkey frontal cortex. Proc. Natl. Acad. Sci. USA 2015, 112, E2695–E2704. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, Y.; Chai, J.; Li, B.; Li, H. A review of homologous brain regions between humans and macaques. J. Taiyuan Univ. Technol. 2021, 52, 274–281. [Google Scholar]
- Bauer, M.H.; Kuhnt, D.; Barbieri, S.; Klein, J.; Becker, A.; Freisleben, B.; Hahn, H.K.; Nimsky, C. Reconstruction of white matter tracts via repeated deterministic streamline tracking–initial experience. PLoS ONE 2013, 8, e63082. [Google Scholar] [CrossRef]
- Soares, J.M.; Marques, P.; Alves, V.; Sousa, N. A hitchhiker’s guide to diffusion tensor imaging. Front. Neurosci. 2013, 7, 31. [Google Scholar] [CrossRef]
- Milham, M.P.; Ai, L.; Koo, B.; Xu, T.; Amiez, C.; Balezeau, F.; Baxter, M.G.; Blezer, E.L.A.; Brochier, T.; Chen, A.H. An Open Resource for Non-human Primate Imaging. Neuron 2018, 100, 61–74.e2. [Google Scholar] [CrossRef]
- Yurt, M.; Dar, S.U.; Erdem, A.; Erdem, E.; Oguz, K.K.; Cukur, T. mustgan: Multi-stream generative adversarial networks for mr image synthesis. Med. Image Anal. 2021, 70, 101944. [Google Scholar] [CrossRef]
- Shin, H.C.; Ihsani, A.; Mandava, S.; Sreenivas, S.T.; Forster, C.; Cha, J. Ganbert: Generative adversarial networks with bidirectional encoder representations from transformers for mri to pet synthesis. arXiv 2020, arXiv:2008.04393. [Google Scholar]
- Huang, J.H. Swin transformer for fast mri.Neurocomputing. Neurocomputing 2022, 493, 281–304. [Google Scholar] [CrossRef]
- Sikka, A.; Virk, J.S.; Bathula, D.R. Mri to pet cross-modality translation using globally and locally aware gan (gla-gan) for multi-modal diagnosis of alzheimer’s disease. arXiv 2021, arXiv:2108.02160. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Jiang, Y.F.; Chang, S.Y.; Wang, Z.Y. TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up. arXiv 2021, arXiv:2102.07074. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Welander, P.; Karlsson, S.; Eklund, A. Generative adversarial networks for image-to-image translation on multi-contrast mr images-a comparison of cyclegan and unit. arXiv 2018, arXiv:1806.07777. [Google Scholar]
- Gu, X.; Knutsson, H.; Nilsson, M.; Eklund, A. Generating diffusion mri scalar maps from t1 weighted images using generative adversarial networks. In Image Analysis; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; pp. 489–498. [Google Scholar]
- Abramian, D.; Eklund, A. Generating fmri volumes from t1-weighted volumes using 3d cyclegan. arXiv 2019, arXiv:1907.08533. [Google Scholar]
- Zhao, P.; Pan, H.; Xia, S. Mri-trans-gan: 3d mri cross-modality translation. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 7229–7234. [Google Scholar]
- Armanious, K.; Jiang, C.M.; Abdulatif, S.; Kustner, T.; Gatidis, S.; Yang, B. Unsupervised Medical Image Translation Using Cycle-MedGAN. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Benoit, A.R. Manifold-Aware CycleGAN for High-Resolution Structural-to-DTI Synthesis. In Computational Diffusion MRI: International MICCAI Workshop; Springer: Cham, Switzerland, 2021; pp. 213–224. [Google Scholar]
- Kearney, V.; Ziemer, B.P.; Perry, A.; Wang, T.; Chan, J.W.; Ma, L.; Morin, O.; Yom, S.S.; Solberg, T.D. Attention-Aware Discrimination for MR-to-CT Image Translation Using Cycle-Consistent Generative Adversarial Networks. Radiol. Artif. Intell. 2020, 2, e190027. [Google Scholar] [CrossRef]
- Bui, T.D.; Nguyen, M.; Le, N.; Luu, K. Flow-Based Deformation Guidance for Unpaired Multi-contrast MRI Image-to-Image Translation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020, Lima, Peru, 4–8 October 2020; pp. 728–737.
- Zhang, H.; Li, H.; Parikh, N.A.; He, L. Multi-contrast mri image synthesis using switchable cycle-consistent generative adversarial networks. Diagnostics 2022, 12, 816. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.Y.; Chen, J.; Jiang, D.S.; Zhang, X.P.; Tian, Q.; Wang, M.N. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Huang, J.; Xing, X.; Gao, Z.; Yang, G. Swin Deformable Attention U-Net Transformer (SDAUT) for Explainable Fast MRI for explainable fast mri. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 538–548. [Google Scholar]
- Dalmaz, O.; Yurt, M.; Cukur, T. ResViT: Residual vision transformers for multi-modal medical image synthesis. IEEE Trans. Med. Imaging 2022, 41, 2598–2614. [Google Scholar] [CrossRef]
- Yan, S.; Wang, C.; Chen, W.; Lyu, J. Swin transformer-based GAN for multi-modal medical image translation. Front. Oncol. 2022, 12, 942511. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Schilling, K.G.; Blaber, J.; Hansen, C.; Cai, L.; Rogers, B.; Anderson, A.W.; Smith, S.; Kanakaraj, P.; Rex, T.; Resnick, S.M.; et al. Distortion correction of diffusion weighted MRI without reverse phase-encoding scans or field-maps Distortion correction of diffusion weighted mri without reverse phase-encoding scans or field-maps. PLoS ONE 2020, 15, e0236418. [Google Scholar] [CrossRef]
- Pgan Dar, S.U.; Yurt, M.; Karacan, L.; Erdem, A.; Erdem, E.; Cukur, T. Image synthesis in multi-contrast mri with conditional generative adversarial networks. IEEE Trans. Med. Imaging 2019, 38, 2375–2388. [Google Scholar]
- Yu, B.T.; Zhou, L.P.; Wang, L.; Shi, Y.H.; Fripp, J.; Bourgeat, P. Ea-GANs: Edge-Aware Generative Adversarial Networks for Cross-Modality MR Image Synthesis. IEEE Trans. Med. Imaging 2019, 38, 1750–1762. [Google Scholar] [CrossRef] [PubMed]
- Armanious, K.; Jiang, C.M.; Fischer, M.; Kustner, T.; Hepp, T.; Nikolaou, K.; Gatidis, S.; Yang, B. MedGAN: Medical image translation using GANs. Comput. Med. Imaging Graph. 2020, 79, 101684. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Li, N.; Zhao, Z.; Fan, X.; Chang, E.; Xu, Y. Mri cross-modality image-to-image translation. Sci. Rep. 2020, 10, 3753. [Google Scholar] [CrossRef]
- Warrington, S.; Bryant, K.L.; Khrapitchev, A.A.; Sallet, J.; Charquero-Ballester, M.; Douaud, G.; Jbabdi, S.; Mars, R.B.; Sotiropoulos, S.N. Xtract-standardised protocols for automated tractography in the human and macaque brain. NeuroImage 2020, 217, 116923. [Google Scholar] [CrossRef] [PubMed]
- Jenkinson, M.; Beckmann, C.F.; Behrens, T.E.; Woolrich, M.W.; Smith, S.M. FSL. NeuroImage 2012, 62, 782–790. [Google Scholar] [CrossRef]
- Van Essen, D.C.; Smith, S.M.; Barch, D.M.; Behrens, T.E.; Yacoub, E.; Ugurbil, K. The wu-minn human connectome project: An overview. NeuroImage 2013, 80, 62–79. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Fei, H.; Abdu, N.S.; Xia, X.; Li, H. A Macaque Brain Extraction Model Based on U-Net Combined with Residual Structure. Brain Sci. 2022, 12, 260. [Google Scholar] [CrossRef] [PubMed]
- Abdal, R.; Qin, Y.; Wonka, P. Image2stylegan: How to embed images into the stylegan latent space? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4432–4441. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 4217–4228. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, Y.; Fan, Y.; Wang, J.; Chen, Q. High-Fidelity GAN Inversion for Image Attribute Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11379–11388. [Google Scholar]
- Richardson, E.; Alaluf, Y.; Patashnik, O.; Nitzan, Y.; Azar, Y.; Shapiro, S.; Cohen-Or, D. Encoding in Style: A StyleGAN Encoder for Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2287–2296. [Google Scholar]
- Gholamalinezhad, H.; Khosravi, H. Pooling Methods in Deep Neural Networks, a Review. arXiv 2020, arXiv:2009.07485. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Scanner (3T) | Voxel Resolution (mm) | TE (ms) | TR (ms) | b-Values (s/mm2) |
|---|---|---|---|---|---|
| AMU | Siemens Prisma | 1 × 1 × 1 | 87.6 | 7520 | 5, 500 |
| MountSinai-P | Philips Achieva | 1.5 × 1.5 × 1.5 | 19 | 2600 | 0, 1000 |
| MountSinai-S | Siemens Skyra | 1.0 × 1.0 × 1.0 | 95 | 5000 | 10, 1005 |
| UCDavis | Siemens Skyra | 1.4 × 1.4 × 1.4 | 115 | 6400 | 5, 1600 |
| UWM | GE DISCOVERY_MR750 | 2.1875 × 3.1 × 2.1875 | 94.3 | 6100 | 0, 1000 |
| Datasets | Number of Low b-Value Images | Number of High b-Value Images | Ratio |
|---|---|---|---|
| AMU | 4 | 67 | 1:17 |
| MountSinai-P | 2 | 120 | 1:60 |
| MountSinai-S | 10 | 80 | 1:8 |
| UCDavis | 6 | 60 | 1:10 |
| UWM | 1 | 12 | 1:12 |
| Methods | PSNR | SSIM | MI |
|---|---|---|---|
| pix2pix | 33.7100 | 0.9285 | 1.4313 |
| CycleGAN | 28.7177 | 0.8681 | 1.3716 |
| pGAN | 25.9224 | 0.8534 | 1.3467 |
| SwinUnet | 28.7114 | 0.8799 | 1.3786 |
| ResViT | 24.6464 | 0.8428 | 1.3614 |
| Ours | 38.8700 | 0.9556 | 1.5005 |
| Methods | PSNR | SSIM | MI |
|---|---|---|---|
| pix2pix | 27.6511 | 0.7683 | 1.3144 |
| CycleGAN | 22.7904 | 0.5211 | 1.2528 |
| pGAN | 20.0104 | 0.4600 | 1.2275 |
| SwinUnet | 23.0855 | 0.5583 | 1.2623 |
| ResViT | 18.7379 | 0.4161 | 1.2376 |
| Ours | 32.2587 | 0.8822 | 1.3828 |
| Model | UCDavis | MountSinai-P | MountSinai-S | AMU | UWM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | MI | PSNR | SSIM | MI | PSNR | SSIM | MI | PSNR | SSIM | MI | PSNR | SSIM | MI | |
| pix2pix | 29.0037 | 0.7994 | 1.3353 | 22.4200 | 0.6227 | 1.2560 | 25.9427 | 0.8027 | 1.3347 | 29.6144 | 0.7919 | 1.2938 | 29.0558 | 0.8367 | 1.3045 |
| CycleGAN | 23.1076 | 0.5038 | 1.2514 | 19.4039 | 0.3975 | 1.2299 | 25.2008 | 0.6765 | 1.2872 | 26.2187 | 0.7005 | 1.2778 | 19.1597 | 0.4966 | 1.2367 |
| pGAN | 19.2235 | 0.4242 | 1.2284 | 19.9858 | 0.4199 | 1.2128 | 23.8789 | 0.6279 | 1.2511 | 22.0872 | 0.5719 | 1.2402 | 18.0913 | 0.4958 | 1.2018 |
| SwinUnet | 23.3034 | 0.5619 | 1.2584 | 17.4287 | 0.3400 | 1.2495 | 25.9383 | 0.7381 | 1.2993 | 26.8461 | 0.6911 | 1.2759 | 28.1703 | 0.7316 | 1.2662 |
| ResViT | 17.4558 | 0.3666 | 1.2398 | 20.1088 | 0.4487 | 1.2268 | 23.9303 | 0.5899 | 1.2568 | 20.2219 | 0.4879 | 1.2489 | 16.8820 | 0.4320 | 1.2023 |
| Ours | 35.7479 | 0.9188 | 1.4185 | 24.7701 | 0.8027 | 1.3379 | 30.6730 | 0.9068 | 1.3826 | 28.9085 | 0.8150 | 1.3033 | 29.5930 | 0.8753 | 1.3229 |
| Methods | PSNR | SSIM | MI |
|---|---|---|---|
| PadGAN | 32.3856 | 0.8825 | 1.3857 |
| Setting (1) | 27.2600 | 0.7600 | 1.3121 |
| Setting (2) | 28.1565 | 0.8176 | 1.3412 |
| Setting (3) | 30.5229 | 0.8440 | 1.3486 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhang, L.; Xue, X.; Lu, X.; Li, H.; Wang, Q. PadGAN: An End-to-End dMRI Data Augmentation Method for Macaque Brain. Appl. Sci. 2024, 14, 3229. https://doi.org/10.3390/app14083229
Chen Y, Zhang L, Xue X, Lu X, Li H, Wang Q. PadGAN: An End-to-End dMRI Data Augmentation Method for Macaque Brain. Applied Sciences. 2024; 14(8):3229. https://doi.org/10.3390/app14083229
Chicago/Turabian StyleChen, Yifei, Limei Zhang, Xiaohong Xue, Xia Lu, Haifang Li, and Qianshan Wang. 2024. "PadGAN: An End-to-End dMRI Data Augmentation Method for Macaque Brain" Applied Sciences 14, no. 8: 3229. https://doi.org/10.3390/app14083229
APA StyleChen, Y., Zhang, L., Xue, X., Lu, X., Li, H., & Wang, Q. (2024). PadGAN: An End-to-End dMRI Data Augmentation Method for Macaque Brain. Applied Sciences, 14(8), 3229. https://doi.org/10.3390/app14083229