
Efficient Multi-Source Anonymity for Aggregated Internet of Vehicles Datasets


Abstract
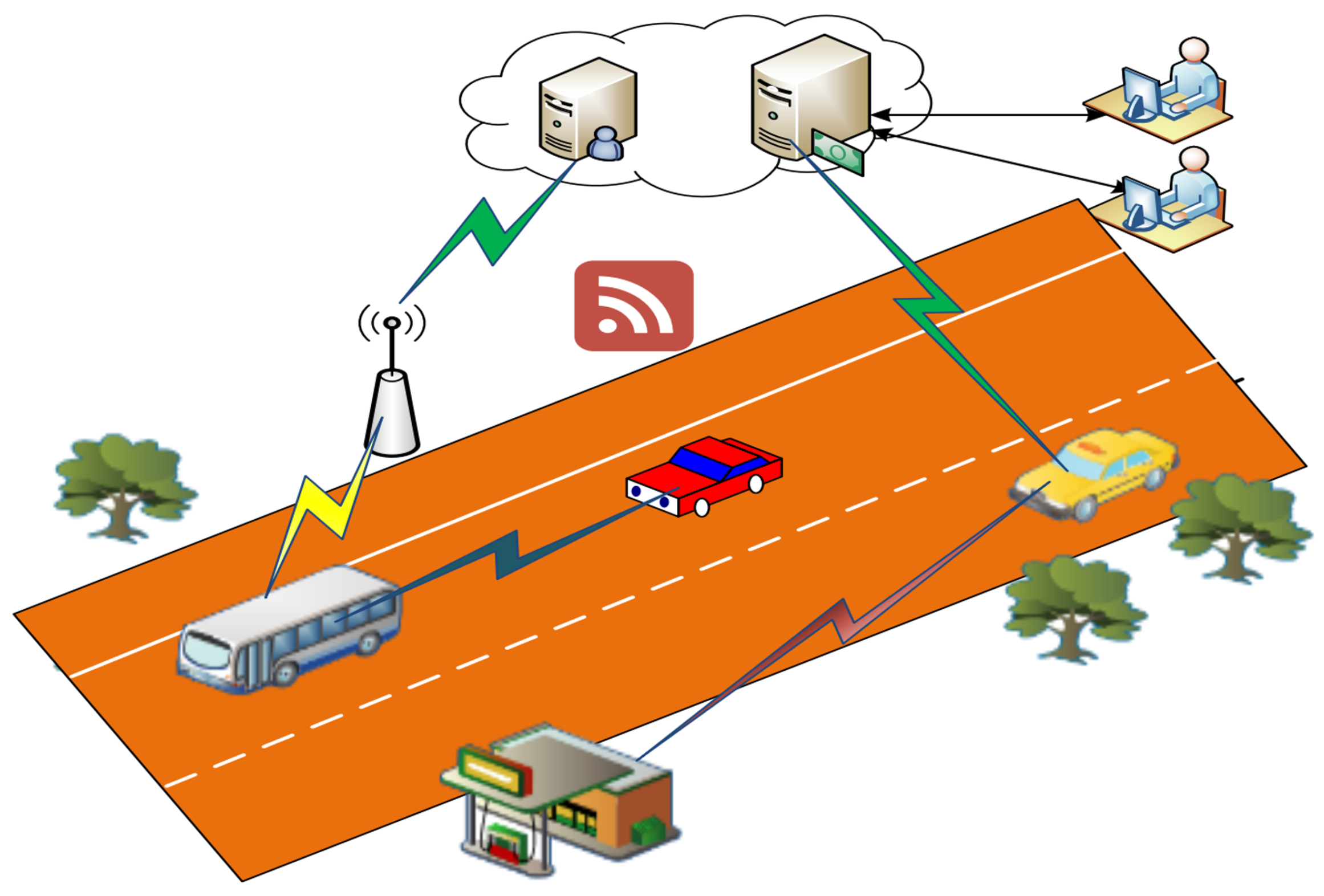
1. Introduction
- We propose a multi-source linkability attack by analyzing the problem of the aggregated dataset in IoV.
- We proposed multi-source (k,d)-anonymity and multi-source (k,l,d)-diversity to protect privacy disclosure in IoV. The former prevents the acquisition of accurate quasi-identifier values when the attacker possesses background knowledge. The latter has a similar privacy capability and can protect sensitive attributes. In addition, we provide heuristically efficient algorithms.
- We experimentally evaluated our algorithms using real datasets. The experimental results demonstrate that our algorithms perform well regarding privacy disclosure, information loss, and efficiency.
2. Related Works
2.1. k-Anonymity
2.2. Anonymity Utility
3. Models
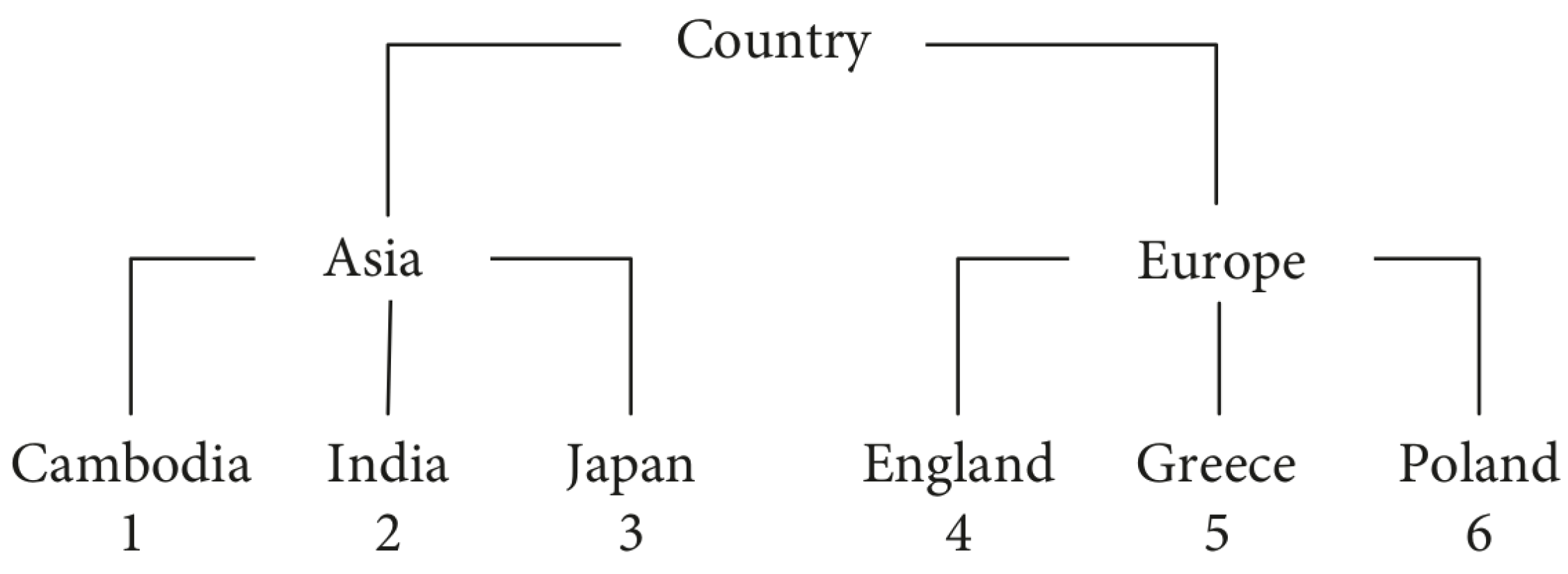
3.1. Notations
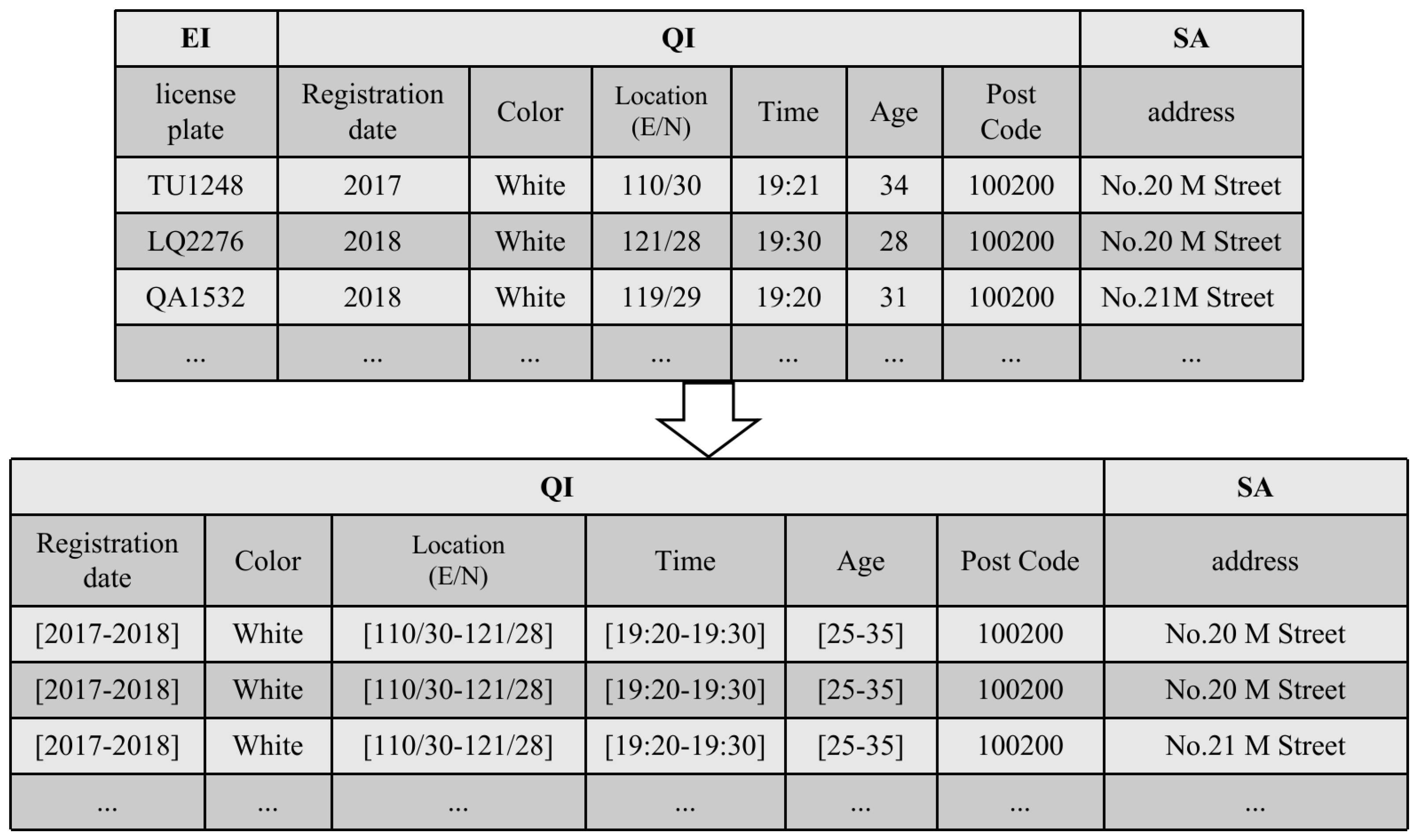
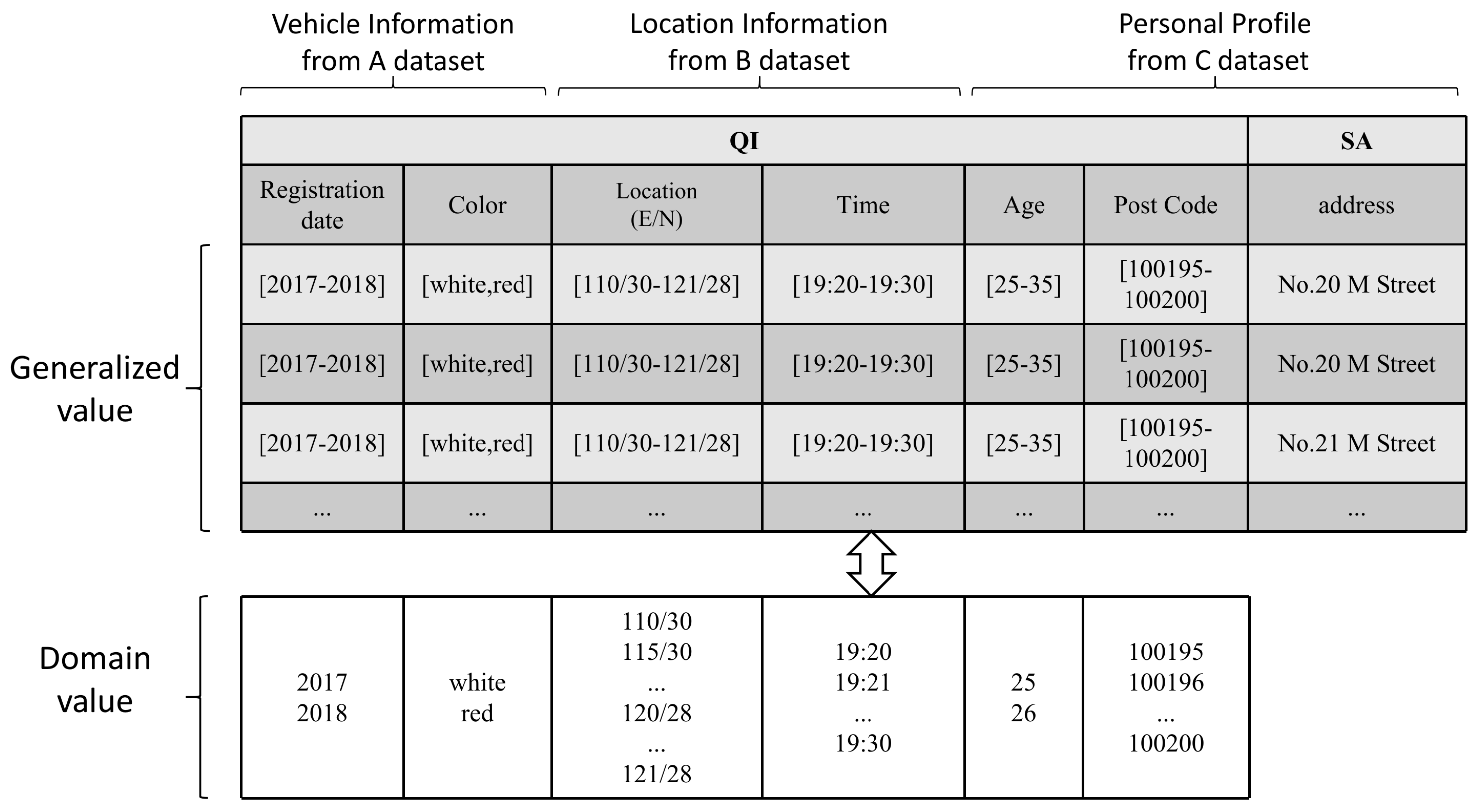
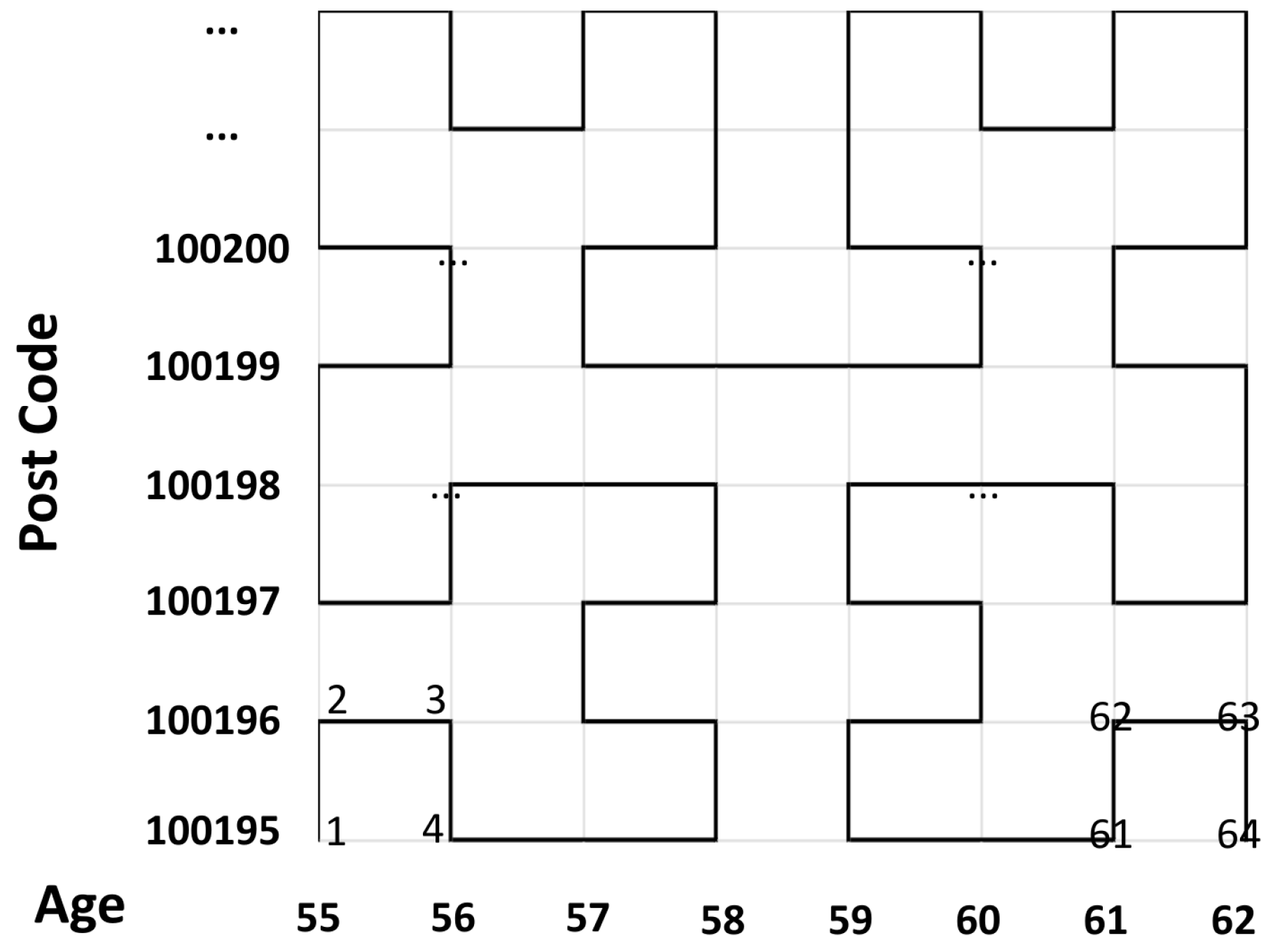
3.2. Motivation
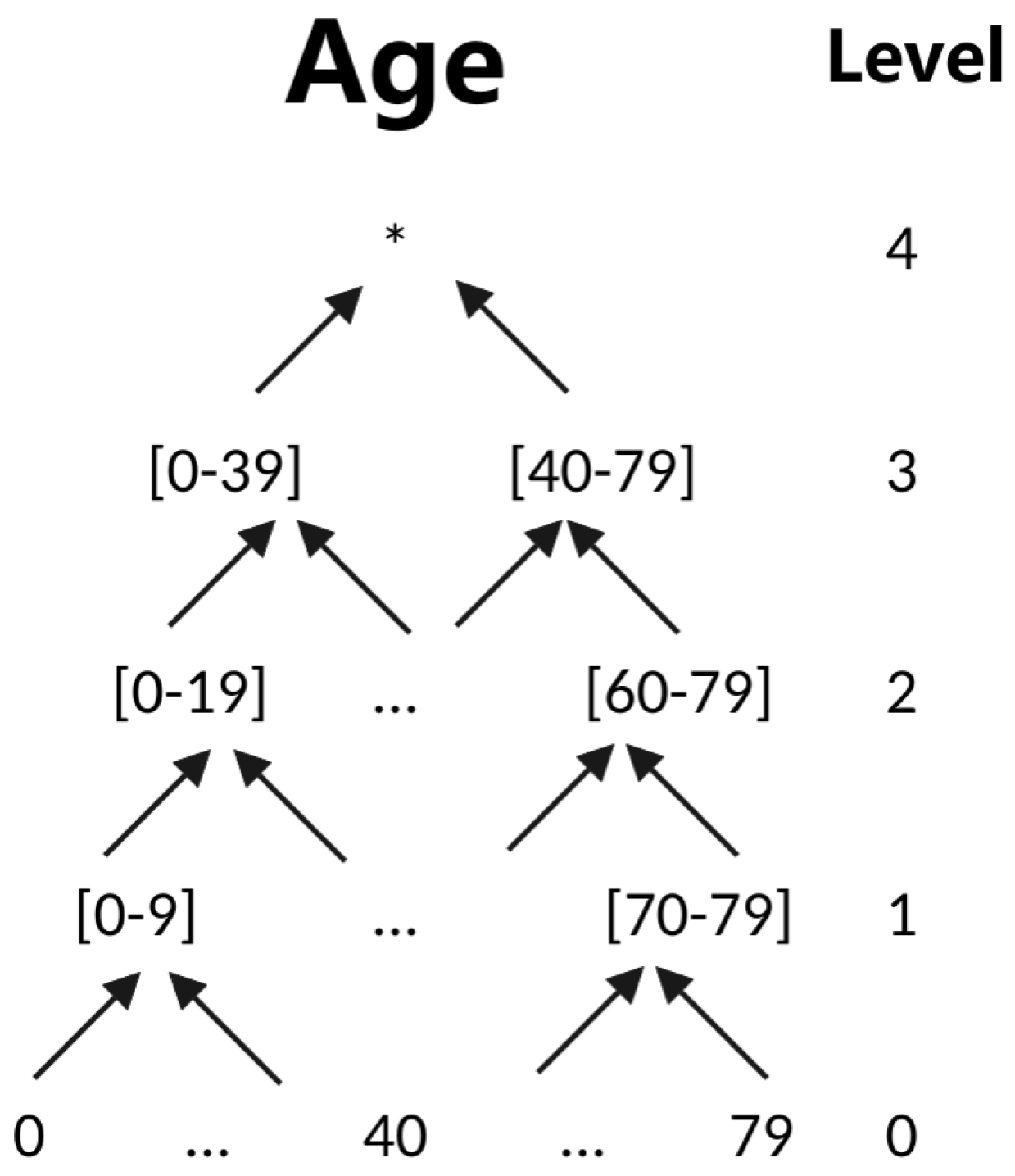
3.3. Proposed Privacy Models
3.3.1. Threat Model
3.3.2. Multi-Source Anonymity
4. Algorithms
| Algorithm 1 The multi-source linkability attack algorithm. |
| Input: , |
| Output: |
|
| Algorithm 2 The multi-source (k,d)-anonymity algorithm. |
| Input: , k, d |
| Output: |
|
| Algorithm 3 The multi-source (k,l,d)-diversity algorithm. |
| Input: , k, l, d |
| Output: |
|
5. Experimental Evaluation
5.1. Experiment Description
5.2. Privacy Disclosure
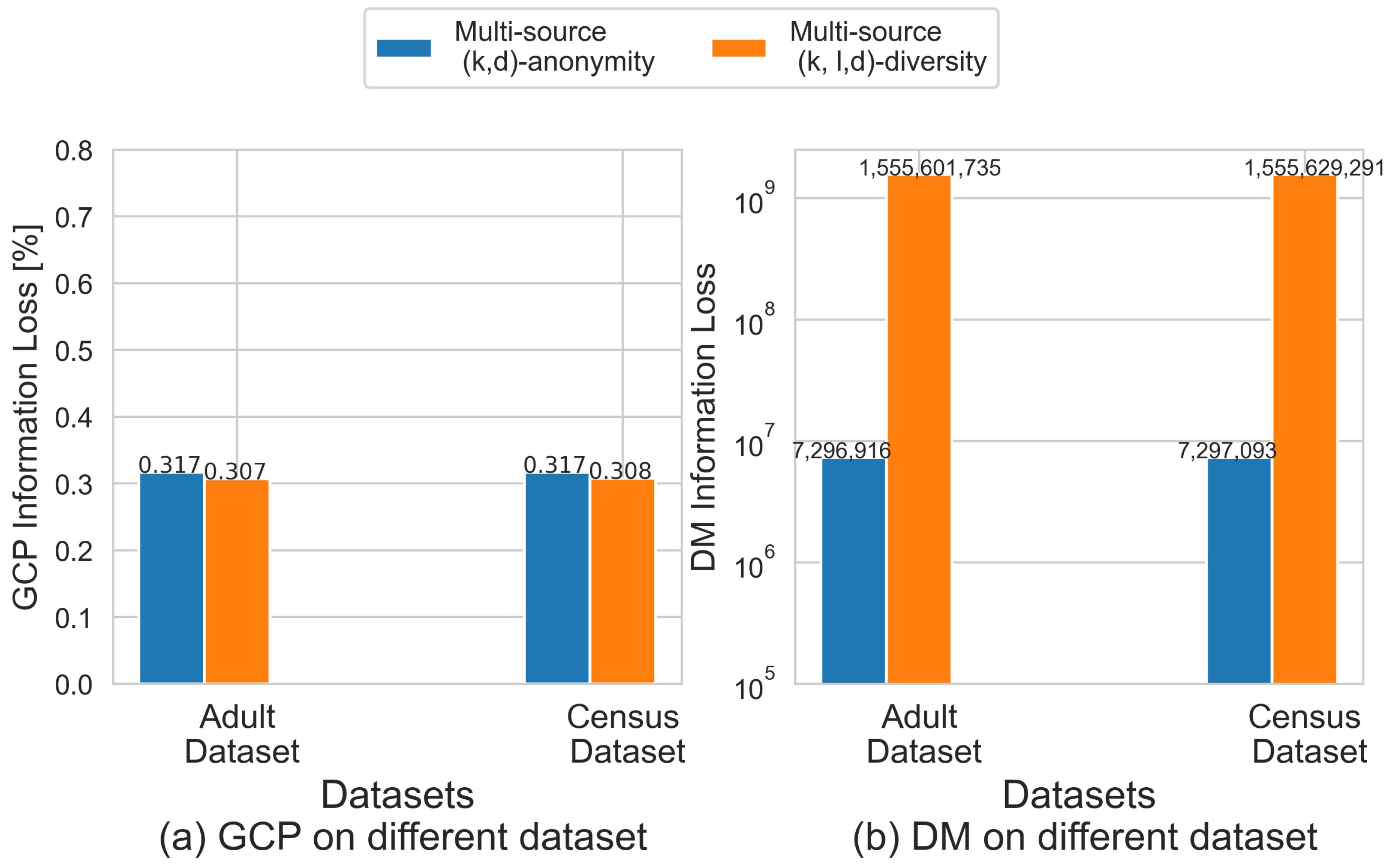
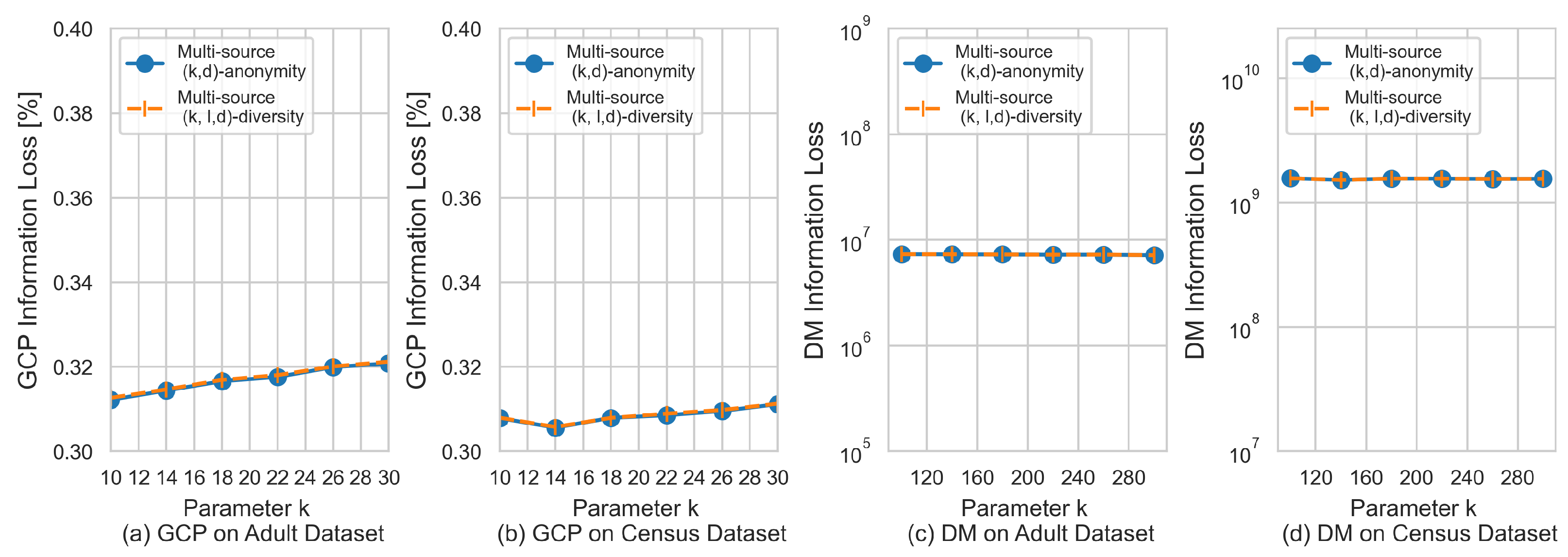
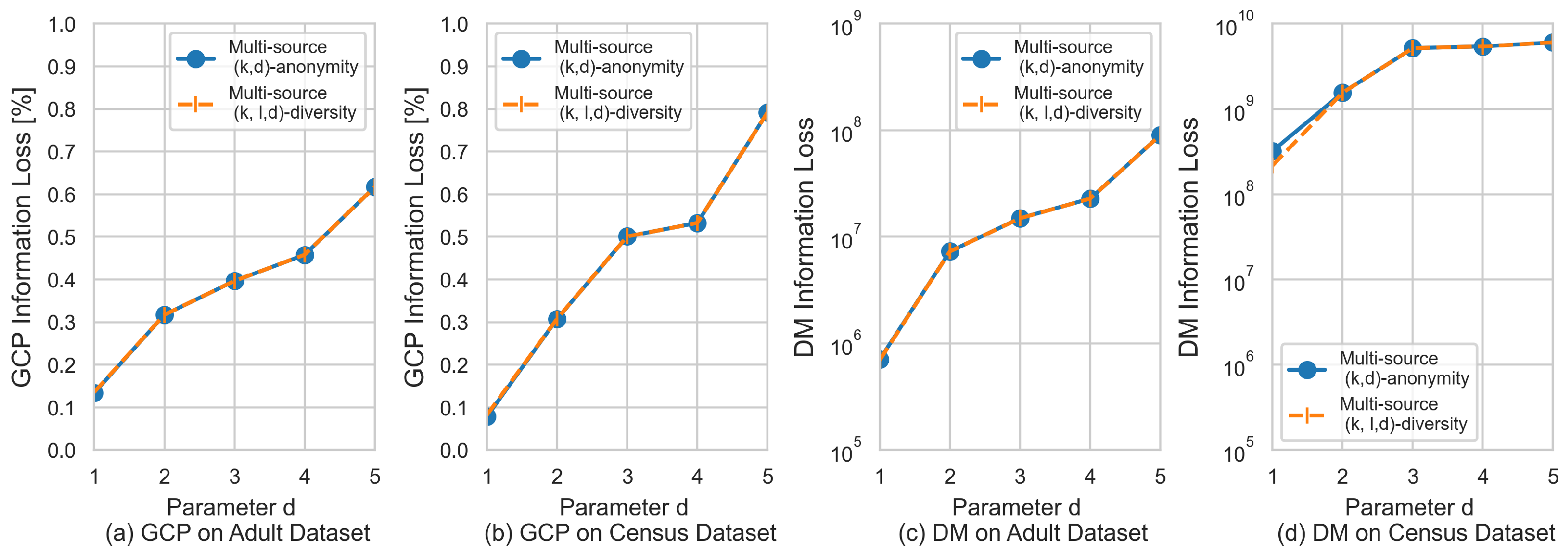
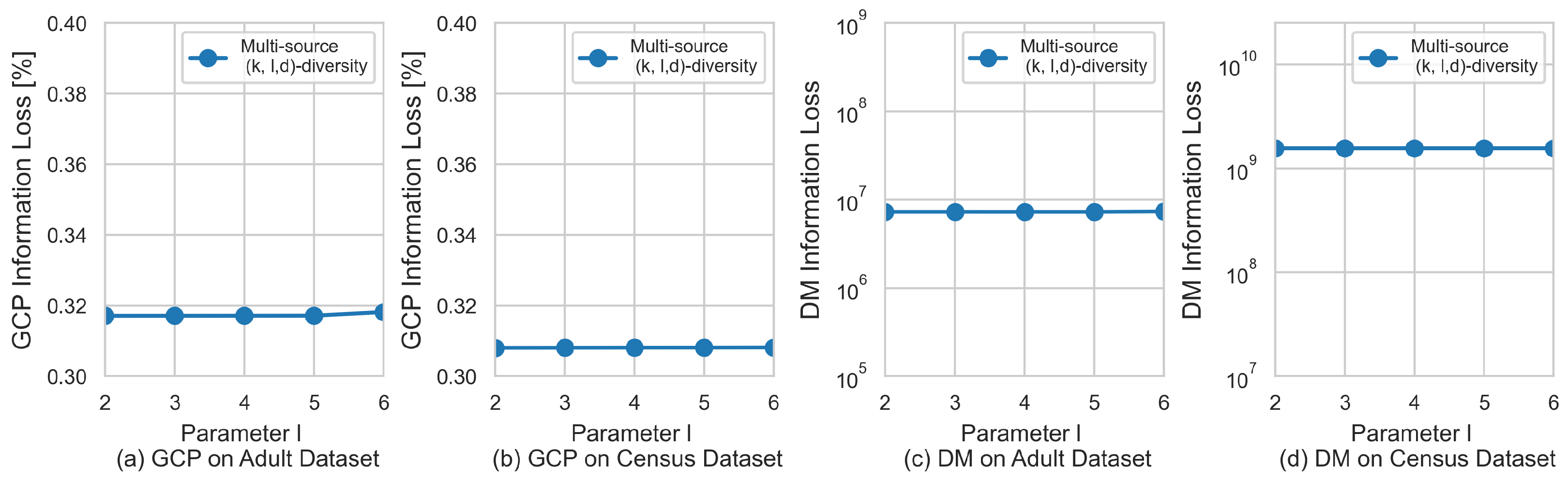
5.3. Data Utility
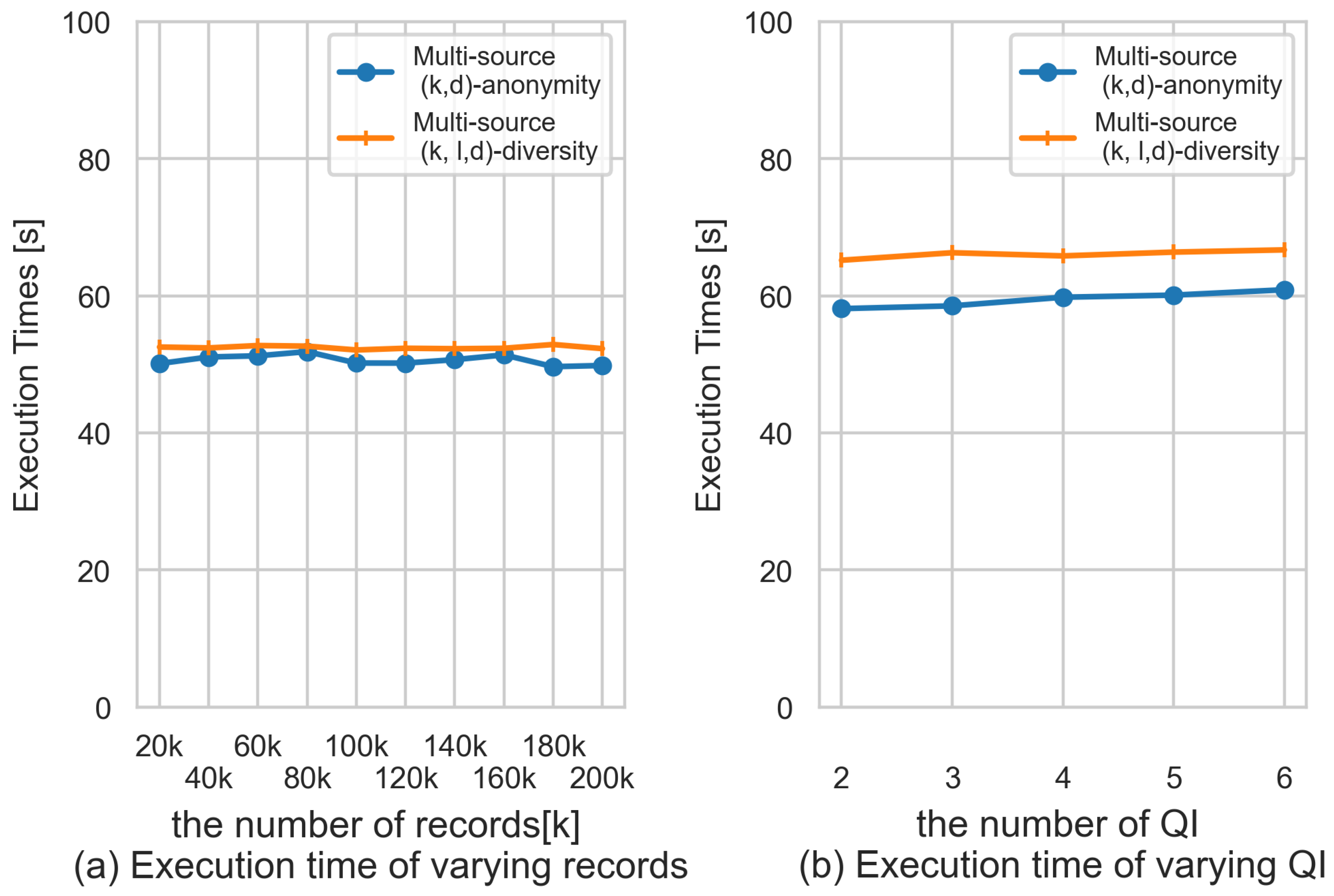
5.4. Efficiency
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sadiku, M.N.; Tembely, M.; Musa, S.M. Internet of vehicles: An introduction. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2018, 8, 11. [Google Scholar] [CrossRef]
- General Data Protection Regulation (GDPR). 2016. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32016R0679 (accessed on 10 September 2023).
- Fung, B.C.; Wang, K.; Fu, A.W.C.; Philip, S.Y. Introduction to Privacy-Preserving Data Publishing: Concepts and Techniques; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Fung, B.C.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. (CSUR) 2010, 42, 1–53. [Google Scholar] [CrossRef]
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Samarati, P. Protecting respondents identities in microdata release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Oh, S.R.; Seo, Y.D.; Lee, E.; Kim, Y.G. A comprehensive survey on security and privacy for electronic health data. Int. J. Environ. Res. Public Health 2021, 18, 9668. [Google Scholar] [CrossRef] [PubMed]
- Olatunji, I.E.; Rauch, J.; Katzensteiner, M.; Khosla, M. A review of anonymization for healthcare data. Big Data, 2022; online ahead of print. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Incognito: Efficient full-domain k-anonymity. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 49–60. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 25. [Google Scholar]
- Liang, Y.; Samavi, R. Optimization-based k-anonymity algorithms. Comput. Secur. 2020, 93, 101753. [Google Scholar] [CrossRef]
- Su, B.; Huang, J.; Miao, K.; Wang, Z.; Zhang, X.; Chen, Y. K-Anonymity Privacy Protection Algorithm for Multi-Dimensional Data against Skewness and Similarity Attacks. Sensors 2023, 23, 1554. [Google Scholar] [CrossRef]
- Shi, P.; Xiong, L.; Fung, B.C. Anonymizing data with quasi-sensitive attribute values. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1389–1392. [Google Scholar]
- Terrovitis, M.; Mamoulis, N.; Liagouris, J.; Skiadopoulos, S. Privacy Preservation by Disassociation. Proc. VLDB Endow. 2012, 5, 944–955. [Google Scholar] [CrossRef]
- Sei, Y.; Okumura, H.; Takenouchi, T.; Ohsuga, A. Anonymization of sensitive quasi-identifiers for l-diversity and t-closeness. IEEE Trans. Dependable Secur. Comput. 2017, 16, 580–593. [Google Scholar] [CrossRef]
- Freudiger, J.; Manshaei, M.H.; Hubaux, J.; Parkes, D.C. Non-Cooperative Location Privacy. IEEE Trans. Dependable Secur. Comput. 2013, 10, 84–98. [Google Scholar] [CrossRef]
- Li, M.; Salinas, S.; Thapa, A.; Li, P. n-CD: A geometric approach to preserving location privacy in location-based services. In Proceedings of the IEEE INFOCOM 2013, Turin, Italy, 14–19 April 2013; pp. 3012–3020. [Google Scholar]
- Ghinita, G.; Kalnis, P.; Khoshgozaran, A.; Shahabi, C.; Tan, K. Private queries in location based services: Anonymizers are not necessary. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, 10–12 June 2008; pp. 121–132. [Google Scholar]
- Hoh, B.; Iwuchukwu, T.; Jacobson, Q.; Work, D.B.; Bayen, A.M.; Herring, R.; Herrera, J.C.; Gruteser, M.; Annavaram, M.; Ban, J. Enhancing Privacy and Accuracy in Probe Vehicle-Based Traffic Monitoring via Virtual Trip Lines. IEEE Trans. Mob. Comput. 2012, 11, 849–864. [Google Scholar] [CrossRef]
- Bamba, B.; Liu, L.; Pesti, P.; Wang, T. Supporting anonymous location queries in mobile environments with privacygrid. In Proceedings of the 17th International Conference on World Wide Web, WWW 2008, Beijing, China, 21–25 April 2008; pp. 237–246. [Google Scholar]
- Pan, X.; Xu, J.; Meng, X. Protecting Location Privacy against Location-Dependent Attacks in Mobile Services. IEEE Trans. Knowl. Data Eng. 2012, 24, 1506–1519. [Google Scholar] [CrossRef]
- Samarati, P.; Sweeney, L. Protecting Privacy When Disclosing Information: k-Anonymity and Its Enforcement through Generalization and Suppression; technical report; SRI International: Menlo Park, CA, USA, 1998. [Google Scholar]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Jayapradha, J.; Prakash, M.; Alotaibi, Y.; Khalaf, O.I.; Alghamdi, S.A. Heap Bucketization Anonymity—An Efficient Privacy-Preserving Data Publishing Model for Multiple Sensitive Attributes. IEEE Access 2022, 10, 28773–28791. [Google Scholar] [CrossRef]
- Onesimu, J.A.; Karthikeyan, J.; Sei, Y. An efficient clustering-based anonymization scheme for privacy-preserving data collection in IoT based healthcare services. Peer-Peer Netw. Appl. 2021, 14, 1629–1649. [Google Scholar] [CrossRef]
- Onesimu, J.A.; J, K.; Eunice, J.; Pomplun, M.; Dang, H. Privacy Preserving Attribute-Focused Anonymization Scheme for Healthcare Data Publishing. IEEE Access 2022, 10, 86979–86997. [Google Scholar] [CrossRef]
- Yao, L.; Wang, X.; Hu, H.; Wu, G. A Utility-aware Anonymization Model for Multiple Sensitive Attributes Based on Association Concealment. IEEE Trans. Dependable Secur. Comput. 2023, 1–12. [Google Scholar] [CrossRef]
- Parameshwarappa, P.; Chen, Z.; Koru, G. Anonymization of Daily Activity Data by Using l-diversity Privacy Model. ACM Trans. Manage. Inf. Syst. 2021, 12, 1–21. [Google Scholar] [CrossRef]
- Srijayanthi, S.; Sethukarasi, T. Design of privacy preserving model based on clustering involved anonymization along with feature selection. Comput. Secur. 2023, 126, 103027. [Google Scholar] [CrossRef]
- Arava, K.; Lingamgunta, S. Adaptive k-anonymity approach for privacy preserving in cloud. Arab. J. Sci. Eng. 2020, 45, 2425–2432. [Google Scholar] [CrossRef]
- Guo, J.; Yang, M.; Wan, B. A Practical Privacy-Preserving Publishing Mechanism Based on Personalized k-Anonymity and Temporal Differential Privacy for Wearable IoT Applications. Symmetry 2021, 13, 1043. [Google Scholar] [CrossRef]
- Mohana Prabha, K.; Vidhya Saraswathi, P. Suppressed K-Anonymity Multi-Factor Authentication Based Schmidt-Samoa Cryptography for privacy preserved data access in cloud computing. Comput. Commun. 2020, 158, 85–94. [Google Scholar] [CrossRef]
- Ma, C.; Yan, Z.; Chen, C.W. SSPA-LBS: Scalable and Social-Friendly Privacy-Aware Location-Based Services. IEEE Trans. Multim. 2019, 21, 2146–2156. [Google Scholar] [CrossRef]
- Kang, J.; Steiert, D.; Lin, D.; Fu, Y. MoveWithMe: Location Privacy Preservation for Smartphone Users. IEEE Trans. Inf. Forensics Secur. 2020, 15, 711–724. [Google Scholar] [CrossRef]
- Cheng, W.; Wen, R.; Huang, H.; Miao, W.; Wang, C. OPTDP: Towards optimal personalized trajectory differential privacy for trajectory data publishing. Neurocomputing 2022, 472, 201–211. [Google Scholar] [CrossRef]
- Bayardo, R.J.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar]
- Iyengar, V.S. Transforming data to satisfy privacy constraints. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 279–288. [Google Scholar]
- Xu, J.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A.W.C. Utility-based anonymization using local recoding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 785–790. [Google Scholar]
- Ghinita, G.; Karras, P.; Kalnis, P.; Mamoulis, N. Fast data anonymization with low information loss. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 758–769. [Google Scholar]
- Prasser, F.; Bild, R.; Eicher, J.; Spengler, H.; Kuhn, K.A. Lightning: Utility-Driven Anonymization of High-Dimensional Data. Trans. Data Priv. 2016, 9, 161–185. [Google Scholar]
- Wuyts, K.; Joosen, W. LINDDUN privacy threat modeling: A tutorial. In CW Reports; KU Leuven: Leuven, Belgium, 2015. [Google Scholar]
- Pfitzmann, A.; Hansen, M. A Terminology for Talking about Privacy by Data Minimization: Anonymity, Unlinkability, Undetectability, Unobservability, Pseudonymity, and Identity Management; TU Dresden: Dresden, Germany, 2010. [Google Scholar]
- Fung, B.C.; Wang, K.; Yu, P.S. Top-down specialization for information and privacy preservation. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 205–216. [Google Scholar]
- Kohlmayer, F.; Prasser, F.; Eckert, C.; Kemper, A.; Kuhn, K.A. Flash: Efficient, stable and optimal k-anonymity. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 708–717. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patient Name | Patient Age | Patient Sex | Patient ZIP Code | Patient Disease |
|---|---|---|---|---|
| Cart | 24 | Male | 17227 | Flu |
| Bob | 23 | Male | 17672 | Hepatitis |
| Gaul | 24 | Female | 17537 | HIV |
| Elle | 48 | Female | 19240 | Hangnail |
| Alice | 51 | Male | 18824 | Bronchitis |
| Helen | 46 | Female | 18824 | Flu |
| Patient Age | Patient Sex (* Denotes the Value is Suppressed) | Patient Address | Patient Disease |
|---|---|---|---|
| [23–24] | * | [17226–17672] | HIV |
| [23–24] | * | [17226–17672] | Hepatitis |
| [23–24] | * | [17226–17672] | Flu |
| [46–51] | * | [18824–19240] | Flu |
| [46–51] | * | [18824–19240] | Hangnail |
| [46–51] | * | [18824–19240] | Bronchitis |
| Symbol | Description |
|---|---|
| T | Original Dataset |
| Aggregated Data | |
| Anonymized Aggregation Data | |
| k | K-Anonymity Parameter |
| r | Record |
| A | Attribute |
| Number of Attributes | |
| n | Number of Records |
| , | Information Loss Metric Function |
| Algorithm | Set | Set | Number of Equivalence Classes | Privacy Leakage of Set | Privacy Leakage of Set | Privacy Leakage | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 | a6 | |||||
| Top-down [44] | 0 | 1206 | 1364 | 1098 | 1242 | 1175 | 1364 | 2570 | 3515 | 6085 |
| Mondrian [11] | 2 | 696 | 646 | 122 | 622 | 538 | 987 | 1344 | 1282 | 2626 |
| Incognito [10] | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 |
| Flash [45] | 1 | 18 | 184 | 18 | 184 | 6 | 184 | 203 | 208 | 411 |
| Our | 0 | 0 | 0 | 0 | 0 | 0 | 388 | 0 | 0 | 0 |
| Algorithm | Set | Set | Number of Equivalence Classes | Privacy Leakage of Set | Privacy Leakage of Set | Privacy Leakage | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 | a6 | |||||
| Incognito [10] | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 |
| Flash [45] | 1 | 18 | 184 | 18 | 184 | 6 | 184 | 203 | 208 | 411 |
| Our | 0 | 0 | 0 | 0 | 0 | 0 | 389 | 0 | 0 | 0 |
| Algorithm | Set | Set | Number of Equivalence Classes | Privacy Leakage of Set | Privacy Leakage of Set | Privacy Leakage | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 | a6 | |||||
| Mondrian [11] | 823 | 1679 | 2467 | 1534 | 1539 | 2583 | 2920 | 4969 | 5656 | 10,625 |
| Incognito [10] | 0 | 0 | 0 | 0 | 76 | 0 | 76 | 76 | 76 | 152 |
| Flash [45] | 1 | 818 | 818 | 818 | 818 | 818 | 818 | 1637 | 2454 | 4091 |
| Our | 0 | 0 | 0 | 0 | 0 | 0 | 137 | 0 | 0 | 0 |
| Algorithm | Set | Set | Number of Equivalence Classes | Privacy Leakage of Set | Privacy Leakage of Set | Privacy Leakage | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 | a6 | |||||
| Incognito [10] | 0 | 0 | 0 | 0 | 76 | 0 | 76 | 76 | 76 | 152 |
| Flash [45] | 1 | 818 | 818 | 818 | 818 | 818 | 818 | 1637 | 2454 | 4091 |
| Our | 0 | 0 | 0 | 0 | 0 | 0 | 138 | 0 | 0 | 0 |
| Dataset\Algorithm | Multi-Source (k,d)-Anonymity | Multi-Source (k,l,d)-Diversity |
|---|---|---|
| Adult | 300 | 332 |
| Census | 61,899 | 67,715 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Song, W. Efficient Multi-Source Anonymity for Aggregated Internet of Vehicles Datasets. Appl. Sci. 2024, 14, 3230. https://doi.org/10.3390/app14083230
Lu X, Song W. Efficient Multi-Source Anonymity for Aggregated Internet of Vehicles Datasets. Applied Sciences. 2024; 14(8):3230. https://doi.org/10.3390/app14083230
Chicago/Turabian StyleLu, Xingmin, and Wei Song. 2024. "Efficient Multi-Source Anonymity for Aggregated Internet of Vehicles Datasets" Applied Sciences 14, no. 8: 3230. https://doi.org/10.3390/app14083230
APA StyleLu, X., & Song, W. (2024). Efficient Multi-Source Anonymity for Aggregated Internet of Vehicles Datasets. Applied Sciences, 14(8), 3230. https://doi.org/10.3390/app14083230